LlamaIndexモジュールガイドを試してみる: Storing
RAGではベクトルDBを使うのが一般的なこともあって、インデックス作成=保存というのが個人的な感覚ではあるのだけど、LlamaIndexでは、作成したインデックスをswappableなストレージコンポーネントに永続化する、という意味で別のモジュールとして分かれている様子。
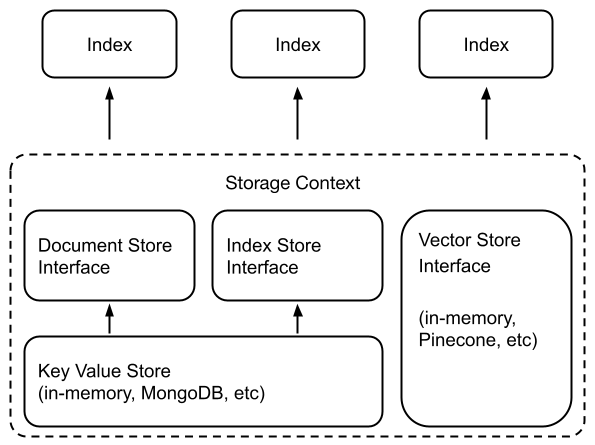
ストレージコンポーネントは以下の4つ。
-
Document stores
- ドキュメントやNodeオブジェクトを保存するKey-Valueストア
-
Index stores
- インデックスのメタデータを保存するKey-Valueストア
-
Vector stores
- Embedding、つまりベクトルデータを保存する
-
Graph stores
- ナレッジグラフを保存する
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
インデックスというのは、ストレージごとに異なる検索や保存等のインタフェースを抽象化するレイヤーだということなんだろう。
じゃあどういうことをやってんの?というところで、色々見ていると以下のページがわかりやすい気がした。
ミニマムなRAGのコードは以下の5行になる。オンメモリなベクトルインデックスを使っている。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("ドウデュースの主な勝ち鞍は?")
print(response)
この中の以下の部分がインデックス化と保存になっている
index = VectorStoreIndex.from_documents(documents)
このインデックスをディスクに永続化する。
index.storage_context.persist(persist_dir="horses_index")
!ls -lt horses_index
total 792
-rw-r--r-- 1 root root 72 Jan 5 01:25 image__vector_store.json
-rw-r--r-- 1 root root 665478 Jan 5 01:25 default__vector_store.json
-rw-r--r-- 1 root root 18 Jan 5 01:25 graph_store.json
-rw-r--r-- 1 root root 1843 Jan 5 01:25 index_store.json
-rw-r--r-- 1 root root 129420 Jan 5 01:25 docstore.json
ざっくり各ファイル見てみたけど、用途はこんな感じみたい。
- index_store.json
- インデックスIDとNode IDの紐づけを保存
- docstore.json
- 各Node IDごとの情報(テキストやメタデータ、Node間の関係性など)を保存
- default__vector_store.json
- 各Node IDごとのテキストのベクトルデータを保存
- graph_store.json
- 各Node IDごとのナレッジグラフのデータを保存
- image__vector_store.json
- 各Node IDごとの画像のベクトルデータを保存、マルチモーダルインデックス用と思う
なので、先程の1行の処理を細かく噛み砕くとと以下のようなコードになる。
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.node_parser import SentenceSplitter
from llama_index import StorageContext
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
storage_context.docstore.add_documents(nodes)
index = VectorStoreIndex(nodes, storage_context=storage_context)
Storage Contextで各データを「どこに・どのように」保存するか?ということを指定しているということみたい。なので、これを外部のベクトルDBなどに保存する場合、Storage Contextのvector_storeを使いたいベクトルDBインタフェースを指定してやればいいということになる。例えばQdrantの場合。
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.node_parser import SentenceSplitter
from llama_index import StorageContext
import qdrant_client
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
client = qdrant_client.QdrantClient(location=":memory:")
vector_store = QdrantVectorStore(client=client, collection_name=" horses")
storage_context = StorageContext.from_defaults(
vector_store=vector_store,
)
index = VectorStoreIndex(nodes, storage_context=storage_context)
ベクトルDBの場合は、ベクトルインデックス以外のデータも保存してくれるので、おそらくDocumentStoreとかIndexStoreとかは意識しなくて良いということだと思う。FAISSにはそういう仕組がない、らしい。
Many vector stores (except FAISS) will store both the data as well as the index (embeddings). This means that you will not need to use a separate document store or index store. This also means that you will not need to explicitly persist this data - this happens automatically. Usage would look something like the following to build a new index / reload an existing one.
ただ、小さなRAGアプリとかであればディスクベースで使えれば別リソースを用意しなくてもいいので、これがメリットになる場合もあるかもしれない。
Persisting & Loading Data
ベクトルストア以外の場合、上でも少し触れたけども、ディスク上に永続化することができる。
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.node_parser import SentenceSplitter
from llama_index import StorageContext, VectorStoreIndex
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
storage_context.docstore.add_documents(nodes)
index = VectorStoreIndex(nodes, storage_context=storage_context)
index.storage_context.persist(persist_dir="horses_index")
これを読み出す場合。
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="horses_index")
index = load_index_from_storage(storage_context)
query_engine = loaded_index.as_query_engine()
response = query_engine.query("ドウデュースの主な勝ち鞍は?")
print(response)
ハルシネーションしてるけど読み出せていることがわかる。
ドウデュースの主な勝ち鞍は、日本ダービー、京都記念、および天皇賞(秋)です。
ちなみにここもざっくり抽象化されているけど、実際にはこんな感じっぽい。
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.vector_stores import SimpleVectorStore
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore.from_persist_dir(persist_dir="horses_index"),
# SimpleVectorStore.from_persist_dirだとvector_store.jsonが見つからないと言われる。
# 保存されいてるのはdefault__vector_store.jsonなので、バグなのかも。
vector_store=SimpleVectorStore.from_persist_path(persist_path="horses_index/default__vector_store.json"),
index_store=SimpleIndexStore.from_persist_dir(persist_dir="horses_index"),
)
index = load_index_from_storage(storage_context)
なお、ローカルファイルしシステム以外に以下のクラウドストレージも使える様子
- Amazon S3
- Cloudflare R2
Vector Store
ベクトルDBを使ったベクトルストア。多数のベクトルDBに対応している。
個人的にはQdrant推しなんだけど、ハイブリッドが使えるベクトルストアが気になるところ。
ざっと上記の表にあるハイブリッドが使えるベクトルストアはこのあたり。
- Azure Cognitive Search
- Elasticsearch
- Jaguar
- Lantern
- MyScale
- Pinecone
- Postgres
- pgvecto.rs
- TencentVectorDB
- Weaviate
知らんやつもめっちゃあるな・・・というか世の中にあるベクトルDB、めっちゃ増えてるんじゃなかろうか
Qdrantはハイブリッド対応してない、と思ったらどうやらできるっぽい
とりあえず気になるやつをいくつか見てみる。
Qdrant Vector Store
個人的に推しなQdrant。以前にも少し試している.
Qdrant Cloudを使ってみる。
!pip install -U qdrant_client
from llama_index import ServiceContext, StorageContext, SimpleDirectoryReader, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.embeddings import OpenAIEmbedding
from llama_index.llms import OpenAI
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
import os
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperarture=0.3),
embed_model=OpenAIEmbedding(),
node_parser=SentenceSplitter(chunk_size=1024, chunk_overlap=50),
)
client = qdrant_client.QdrantClient(
url="https://XXXXXXXXXXXXXXXXXXXX.qdrant.io",
api_key=os.environ["QDRANT_API_KEY"],
)
vector_store = QdrantVectorStore(
client=client,
collection_name="horses"
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
service_context=service_context
)
Qdrantの管理画面にも登録されているのだけども・・・

うーん、_node_contentにUnicodeエンコードされた文字列で入っているのか・・・ベクトルDBの場合、管理画面で何をするってことはないんだけども、運用的に日本語テキストがサラッと見えないのはなかなか辛いものがあるな。。。メタデータ追加するのがよいのかなぁ。。。
とりあえずクエリ
query_engine = index.as_query_engine()
response = query_engine.query("ドウデュースの主な勝ち鞍は?")
print(response)
ドウデュースの主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念です。
あと、Qdrantだとメタデータフィルタが使えたはず、ということで調べてみたけど、LlamaIndexはここも抽象化しているっぽい。
で、Pineconeの場合のドキュメントが以下にあった(これインデックスには載ってなくて検索でしか出てこない。。。。)
Qdrantの場合も同じでいける。
from llama_index.vector_stores.types import (
MetadataFilter,
MetadataFilters,
FilterOperator,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="file_name", operator=FilterOperator.EQ, value="ドウデュース.txt"),
]
)
query_engine = index.as_query_engine(filters=filters)
response = query_engine.query("主な勝ち鞍について教えて。")
print(response)
ドウデュースの主な勝ち鞍は、日本ダービー、京都記念、そして重賞3勝目である有馬記念です。
filters = MetadataFilters(
filters=[
MetadataFilter(key="file_name", operator=FilterOperator.EQ, value="イクイノックス.txt"),
]
)
query_engine = index.as_query_engine(filters=filters)
response = query_engine.query("主な勝ち鞍について教えて。")
print(response)
イクイノックスの主な勝ち鞍は、日本ダービー、ジャパンカップ、宝塚記念、天皇賞(秋)です。
Qdrant公式にも。
Pinecone Vector Store
vector_storeをpineconeに合わせて変えるだけで、それ以外のコードはQdrantのときと全く同じでOK。この辺はStorage Contextが便利なところ。
from llama_index import ServiceContext, StorageContext, SimpleDirectoryReader, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.embeddings import OpenAIEmbedding
from llama_index.llms import OpenAI
from llama_index.vector_stores import PineconeVectorStore
import pinecone
import os
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperarture=0.3),
embed_model=OpenAIEmbedding(),
node_parser=SentenceSplitter(chunk_size=1024, chunk_overlap=50),
callback_manager=callback_manager,
)
pinecone.init(
api_key=os.environ["PINECONE_API_KEY"],
environment="asia-northeast1-gcp"
)
pinecone_index = pinecone.Index("horses")
vector_store = PineconeVectorStore(pinecone_index=pinecone_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
service_context=service_context,
)
Pinecone側にも登録されている。日本語の場合はテキストが見えないのはQdrantと一緒。LlamaIndexだとこれはしょうがないかも。
クエリも全く同じコードで。
query_engine = index.as_query_engine()
response = query_engine.query("ドウデュースの主な勝ち鞍について教えて")
print(response)
ドウデュースの主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念です。
メタデータフィルタについても同じ。
from llama_index.vector_stores.types import (
MetadataFilter,
MetadataFilters,
FilterOperator,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="file_name", operator=FilterOperator.EQ, value="イクイノックス.txt"),
]
)
query_engine = index.as_query_engine(filters=filters)
response = query_engine.query("主な勝ち鞍について教えて。")
print(response)
イクイノックスの主な勝ち鞍は、日本ダービー、ジャパンカップ、宝塚記念、天皇賞(秋)です。
以下については自分のニーズ的にあまり必要なさそうなので割愛
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores
Chat Store
チャットインタフェースの場合の会話履歴の保存に使う。LlamaIndexだとオンメモリで動作するSimpleChatStoreしか対応してなさそう。ここはLangChainとはかなり差があるかもしれない。
ここはQueryingのChat Engineのところで確認する