[論文] STORM & Co-STORM
まず「STORM」の論文
Claude-3.5-Sonnetによる落合プロンプトの結果
大規模言語モデルを用いたWikipedia風記事のイチからの執筆支援
1. どんなもの?
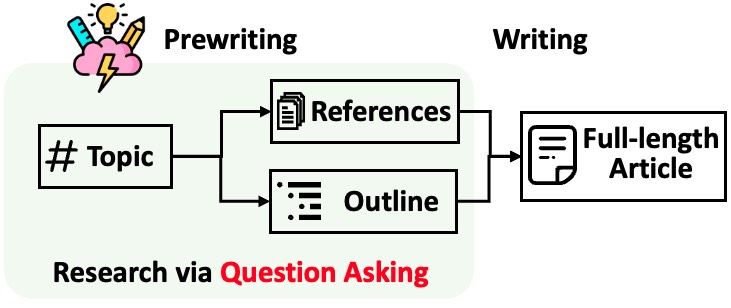
この研究は、大規模言語モデル(LLM)を使用してWikipediaのような長文記事を一から作成するシステム「STORM」を提案しています。STORMは、記事作成の「プレライティング」段階に焦点を当て、トピックの調査、アウトライン作成、実際の執筆という3段階のプロセスを経て記事を生成します。特に、システムは多様な視点からの質問生成と対話シミュレーションを通じて情報を収集し、それを基に包括的なアウトラインを作成します。また、評価のために、最近の高品質なWikipedia記事を集めた「FreshWiki」データセットを構築しています。この研究は、LLMを使用した長文生成において、事前調査とアウトライン作成の重要性を強調し、それを自動化する新しいアプローチを提示しています。
2. 先行研究と比べてどこがすごい?
従来のWikipedia記事生成に関する研究では、参考文献やアウトラインが事前に提供されていることを前提としていました。例えば、Liu et al. (2018)は記事生成を複数文書要約問題として扱い、Fan and Gardent (2022)はアウトラインが既に存在することを前提としています。これに対してSTORMは、トピックのみを入力として受け取り、必要な参考文献の収集からアウトライン作成、そして最終的な記事生成までの全プロセスを自動化している点が革新的です。また、単純なプロンプトによる質問生成や検索ベースの情報収集と比較して、複数の視点を考慮した対話形式での情報収集を行うことで、より包括的で深い調査を可能にしています。
3. 技術や手法の肝はどこ?
STORMの核となる技術は、多様な視点に基づく質問生成と対話シミュレーションです。具体的には、まず類似トピックのWikipedia記事を分析して異なる視点(例:イベントプランナーの視点)を特定します。次に、それぞれの視点からLLMに質問を生成させ、インターネット上の信頼できる情報源を基に回答を生成します。この対話プロセスは最大M回繰り返され、各回の回答は次の質問生成に活用されます。収集された情報は、LLMの内部知識と組み合わせてアウトラインの作成に使用され、最終的にそのアウトラインに沿って記事が生成されます。また、記事生成時には各セクションタイトルを使用して関連文書を検索し、適切な引用付きの文章を生成する仕組みも実装されています。
4. どうやって有効だと検証した?
研究チームは、自動評価と人間による評価の両方を実施しています。自動評価では、アウトラインの品質をheading soft recallとheading entity recallで測定し、記事の品質をROUGEスコア、エンティティ再現率、引用品質などで評価しました。人間による評価では、10名の経験豊富なWikipediaエディターが、興味深さ、構成、関連性、網羅性、検証可能性の5つの観点から記事を評価しました。評価結果では、STORMは最良のベースラインである outline-driven RAG と比較して、特に記事の構成(25%向上)と網羅性(10%向上)において優れた性能を示しました。また、Wikipediaエディターの全員が、STORMがプレライティング段階で役立つと評価しています。
5. 議論はある?
主な議論点として、以下の課題が挙げられています:
- インターネット上の情報源のバイアスが生成記事に転移する問題(7名のエディターが記事が「感情的」または「中立的でない」と指摘)
- 無関係な事実間の不適切な関連付けや過度な推論の問題(事実の誤りではなく、検証可能性の観点での課題)
- 人間が執筆した記事と比較した際の情報量の不足。
また、現在のシステムは自由形式のテキストのみを生成対象としており、構造化データやマルチモーダル情報を含む本格的なWikipedia記事の生成には至っていない点も制限事項として挙げられています。
6. 次に読むべき論文は?
本研究の発展として以下の論文が参考になります:
- Balepur et al. (2023) "Expository text generation: Imitate, retrieve, paraphrase" - 複数の情報源からの情報統合に関する研究
- Shen et al. (2023) "Beyond summarization: Designing ai support for real-world expository writing tasks" - 情報源に対する意味理解とアウトライン計画の重要性に関する研究
- Gao et al. (2023) "Enabling large language models to generate text with citations" - 引用付きテキスト生成に関する研究
- Min et al. (2023) "FActScore: Fine-grained atomic evaluation of factual precision in long form text generation" - 長文生成の事実性評価に関する研究
なお、「STORM」については以下
STORMは論文中で "Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking" の略語として定義されています。
日本語に訳すと「検索と多視点質問生成によるトピックアウトラインの統合」となります。この名称は、システムの主要な特徴を表しています:
- Synthesis (統合) - 収集した情報を統合してアウトラインを作成する
- Topic Outlines (トピックアウトライン) - 記事のアウトライン作成が主目的
- Retrieval (検索) - インターネットからの情報検索を行う
- Multi-perspective (多視点) - 複数の視点から情報を収集する
- Question Asking (質問生成) - 質問生成による情報収集を行う
このシステム名は、その機能と目的を適切に表現していると言えます。
次に「Co-STORM」
大規模言語モデルを活用したユーザー参加型の共同学習支援システム「Co-STORM」の提案
1. どんなもの?
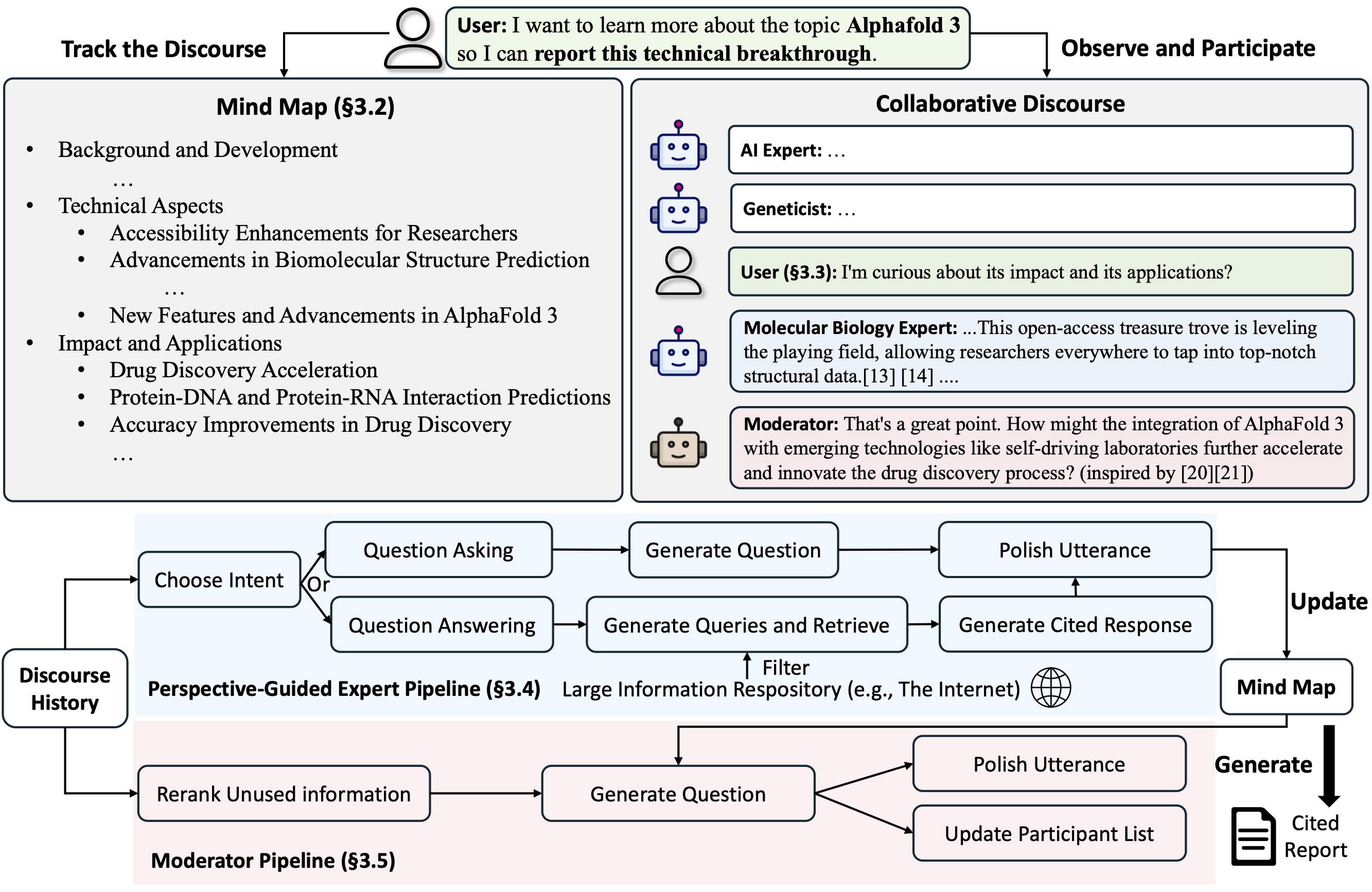
本研究は、大規模言語モデル(LLM)を活用して、ユーザーが「知らないことを知らない」領域(unknown unknowns)を発見することを支援するシステム「Co-STORM」を提案しています。Co-STORMは、子供が親や教師との会話を通じて学ぶように、ユーザーがLMエージェント間の対話を観察し、時には参加することで学習できる環境を提供します。具体的には、複数のLMエージェントがユーザーの代わりに質問を生成し、ユーザーはその対話を観察しながら、必要に応じて介入して議論の方向性を変更することができます。システムは収集された情報を動的なマインドマップとして整理し、最終的には包括的なレポートとして出力します。このアプローチにより、ユーザーは自身が知らなかった情報や視点を発見することができ、より効果的な情報探索が可能になります。
2. 先行研究と比べてどこがすごい?
従来の情報探索支援システムには、以下の3つの主要な制約がありました:
- チャットボットや生成的検索エンジンは、ユーザーの具体的な質問に応答することに優れているものの、ユーザーが知らない情報を発見する機能が限られていた
- 従来の検索エンジンや情報検索モデルは、予め知識を持っているユーザーしか効果的に利用できなかった
- 自動記事生成システムは静的なレポートを生成するのみで、ユーザーとの対話的な情報探索をサポートしていませんでした。
これに対してCo-STORMは、複数のLMエージェントによる対話をシミュレートし、ユーザーがその対話に参加できる環境を提供することで、これらの制約を克服しています。また、動的なマインドマップを用いて情報を整理し、最終的なレポート生成まで一貫してサポートする点も革新的です。
3. 技術や手法の肝はどこ?
Co-STORMの技術的な特徴は、以下の3つの要素から構成されています:
- 複数のLMエージェントによる協調的な対話プロトコル - 「エキスパート」と「モデレーター」という2つの異なる役割を持つエージェントが対話を行い、ユーザーはいつでも参加可能です。モデレーターは未使用の情報を基に新しい方向性の質問を生成し、対話を活性化させます。
- 動的マインドマップによる情報管理 - 収集された情報を階層的に整理し、ユーザーの理解を支援します。情報は適切な概念ノードに挿入され、必要に応じて再構成されます。
- ユーザー参加の柔軟性 - ユーザーはいつでも質問を投げかけることができ、システムはそれに応じて専門家リストを更新し、対話を継続します。
これらの要素により、ユーザーは効果的に新しい知識を発見・学習することができます。
4. どうやって有効だと検証した?
評価は自動評価と人間による評価の2段階で実施されました。自動評価では、実際のユーザーの情報探索記録から構築された「WildSeek」データセットを使用し、生成されたレポートの品質(関連性、広さ、深さ、新規性)と対話の質を評価しました。ベースラインとして検索エンジンとRAGチャットボットを使用し、Co-STORMが特に情報の深さと新規性の面で優れていることを示しました。人間による評価では、20名のボランティアを募り、システムの使用体験を比較しました。その結果、70%のユーザーが検索エンジンよりもCo-STORMを好み、78%がRAGチャットボットよりもCo-STORMを好むと評価しました。特に、Co-STORMは新しい情報の発見を促進し、ユーザーの認知負荷を軽減する点で高く評価されました。
5. 議論はある?
研究チームは以下の3つの主要な制限事項を指摘しています:
- ユーザーの事前知識レベルに応じた対話の調整が必要 - 既に知識のあるユーザーには基本的な事実を省略し、初心者には段階的な概念の導入が必要です。
- 対話管理の柔軟性の向上が必要 - ユーザーは専門家の視点や発話の長さなどをより細かく制御したいと考えています。
- 多言語対応の必要性 - 現在のシステムは英語のみに対応しており、多言語ソースへのアクセスや言語間のコンテンツ管理が課題となっています。
また、RAGチャットボットと比較して、意図の決定やマインドマップの更新に時間がかかるという技術的な課題も指摘されています。
6. 次に読むべき論文は?
本研究の発展として、以下の論文群が特に重要です:
- Belkin et al. (1982) "Ask for information retrieval: Part i. background and theory" - 情報探索における質問生成の理論的基礎に関する研究
- Nussbaum (2008) "Collaborative discourse, argumentation, and learning" - 協調的対話による学習効果の理論研究
- Park et al. (2023) "Generative agents: Interactive simulacra of human behavior" - LMエージェントによる対話シミュレーションの先駆的研究
- Shao et al. (2024) "Assisting in writing Wikipedia-like articles from scratch with large language models" - 情報の収集と整理に関する基礎研究
GitHubレポジトリ
STORM: 検索と多視点質問によるトピックアウトラインの統合
概要
referred from https://github.com/stanford-oval/stormSTORMは、インターネット検索に基づいてゼロからWikipediaのような記事を作成するLLMシステムです。Co-STORMはさらに機能を強化し、人間と協力してより適合した情報検索や知識のキュレーションをサポートできるようになりました。このシステムは、多くの編集が必要となるため、すぐに出版可能な記事を作成することはできませんが、経験豊富なWikipedia編集者たちは執筆前の段階で役立つと感じています。
これまでに70,000人以上が私たちのライブリサーチプレビューを試しました。ぜひ試してみて、STORMがあなたの知識探索の旅にどのように役立つか確認し、システム改善のためにフィードバックをお寄せください🙏!
STORM & Co-STORMの仕組み
STORM
STORMは、引用付きの長い記事を生成するプロセスを以下の2つのステップに分けて行います。
- 執筆前の段階: システムはインターネットを使ってリサーチを行い、参考文献を収集し、アウトラインを作成します。
- 執筆段階: システムは、収集したアウトラインと参考文献をもとに、引用付きの全体記事を生成します。
referred from https://github.com/stanford-oval/stormSTORMは、リサーチプロセスを自動化するために、優れた質問を自動で生成することを核心にしています。しかし、言語モデルに直接質問を生成させてもあまり効果的ではありません。質問の深さと幅を向上させるために、STORMは2つの戦略を採用しています。
- 視点に基づく質問生成: 入力されたトピックに基づき、STORMは類似トピックの記事を調査して異なる視点を発見し、それを使って質問生成プロセスをコントロールします。
- シミュレートされた会話: STORMは、Wikipediaのライターとトピック専門家との会話をシミュレートし、インターネット上の情報を基に言語モデルがトピックの理解を更新し、フォローアップの質問をすることができるようにします。
Co-STORM
Co-STORMは、スムーズな協力をサポートするためのターン管理ポリシーを実装した協力的なディスコースプロトコルを提案しています。
- Co-STORM LLM専門家: このエージェントは、外部の知識ソースに基づいた回答を生成したり、会話履歴に基づいてフォローアップの質問を行います。
- モデレーター: このエージェントは、リトリーバーが発見したがこれまでのターンで直接使われていない情報に触発された質問を生成し、議論を深めます。質問生成は情報に基づいて行われます。
- 人間ユーザー: 人間ユーザーは、(1) 議論を観察してトピックの理解を深めるか、(2) 発言を加えることで議論の焦点を積極的に方向づけるかのいずれかを選択できます。
referred from https://github.com/stanford-oval/stormさらに、Co-STORMは、収集された情報を階層的な概念構造に整理する動的なマインドマップを維持します。これにより、人間とシステムの間で共有された概念空間を構築し、長く深い議論が続く際の負担を軽減する効果があります。
STORMとCo-STORMの両方は、dspyを使用して高度にモジュール化された方法で実装されています。

DSPyが使用されているってのがポイントかな。
ちょっと面白そうではあるんだけど、検索に you.com 使ってて、無料枠に制限あるんだよなぁ・・・