Qwen-VLを試す
LLaVAを試したところ、Qwen-VLもいいよ、みたいなのを見かけたので試してみる。
Qwen-VL (Qwen Large Vision Language Model) is the multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box.
pyenv&pyenv-virtualenv環境で。python-3.10.13。
$ pyenv virtualenv 3.10.13 Qwen-VL
$ git clone https://github.com/QwenLM/Qwen-VL && cd Qwen-VL
$ pyenv local Qwen-VL
パッケージのインストールを普通にやったら、PyTorchでコケた。バージョンにシビアなのかも。最初にCUDAのバージョンに合わせてPyTorchをインストールしておく。(うちの場合は11.8)
$ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
あとは公式の手順通り。
$ pip install -r requirements.txt
$ pip install -r requirements_web_demo.txt
GradioのUIを起動する。初回起動時はモデルがダウンロードされる。モデルを別でダウンロードしておく場合は--checkpoint-pathを指定すれば良い。
$ python web_demo_mm.py --server-name 0.0.0.0 --server-port 7860
普通に日本語は通った。ちょっと漢字が違うかもだけど。

会話を繰り返すとCUDA out of memoryになるのは同じ。この辺はまだこれからなんだろうと思う。
AWSの構成図を読んで内容を説明するってのが出来た。日本語は変だしすべてはカバーできてない(例えばRDSとか)んだけども。
で、そこからCloudFormationのYAMLっぽいものも生成できた。CloudFormationあんま知らないのだけど、NAT Gateway Managerなんてないよねと思うし、上に書いた通りカバーできてないものもあるので、あくまでもそれっぽい出力というだけで、多分正しくはない。ここは本当に画像を認識しているのかはわからない、単に画像を認識したあとのプロンプトから生成してるだけかもしれないし。
ただ、LLaVAではこれは全く出来なかった(頑なにリージョンとAZの概要だけで詳細は説明してくれなかった)ので、ちょっと驚き。
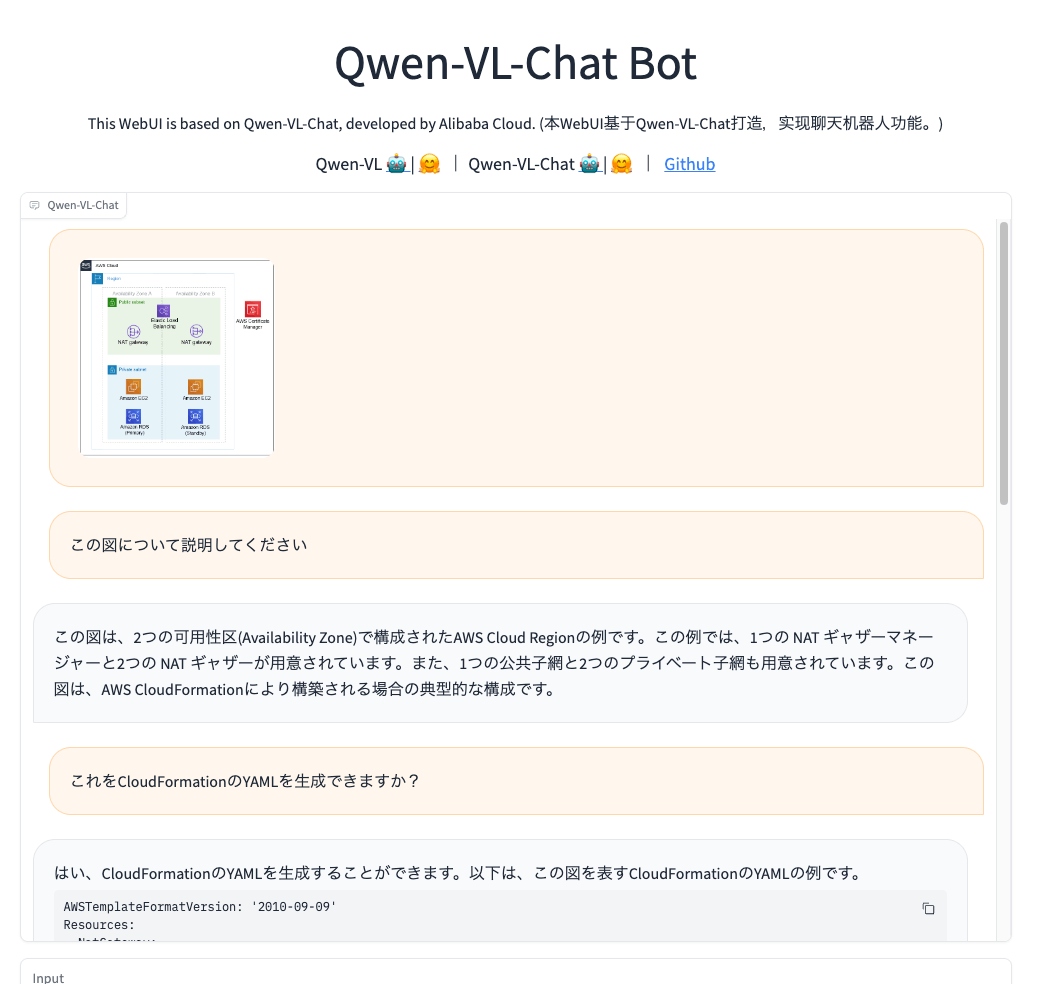

日本語の文字の認識はLLaVAとそんなに変わらない。英数字は認識してくれてるっぽい。
あくまでも個人的な感想。LLaVAはグラフとか図の読み取りは苦手っぽい気がしてたのだけど、その辺はQwen-VLのほうが強い感じがした。
ライセンスはこう
Researchers and developers are free to use the codes and model weights of both Qwen-VL and Qwen-VL-Chat. We also allow their commercial use. Check our license at LICENSE for more details.
なんだけど、たしかにこの辺は気になるかも