改めてLlamaIndexを試してみる
概要
以前からLangChainをずっと触ってきて、最近はフレームワークを使わずに書くことが多くなってきた。LlamaIndexは以前にも少し触っていたことはあるのだが、
- 当時はLangChainの方がメインだったので、LlamaIndexはお試し程度
- 当時はLangChainもLlamaIndexも変化が激しくて、両方キャッチアップするのが難しかった
- フレームワークなしでRAGアプリの開発等をやっているが、
- あらためてフレームワークを使いたい気持ちが強くなってきた
- 実際にRAGアプリを作ってみて、やはり精度を上げるにはどうすればいいか?を強く考えるようになった
という感じで、LlamaIndexの最近の動きを見ているとRAGにすごく力を入れているように見えるので、改めてやり直してみようと思う。
環境
pyenv+pyenv-virtualenvでpython-3.10.13。jupyterlabでやる。
$ pyenv virtualenv 3.10.13 llamaindex
$ mkdir llamaindex && cd llamaindex
$ pyenv local llamaindex
jupyterlabをインストール。
$ pip install jupyterlab ipywidgets
あとOpenAIのAPIキーを.envファイルにセットしておく
$ echo "OPENAI_API_KEY=XXXXXXXXXXXXXXXXX" > .env
jupyter lab起動
$ jupyter-lab --ip='0.0.0.0' --NotebookApp.token=''
以後はjupyterlab上で。
llamaindexインストール。.envを読み込むためのpython-dotenvも。
!pip install llama-index python-dotenv
.envを読み込む
from dotenv import load_dotenv
load_dotenv()
Starter Tutorial
以下に沿って進める。前にもやった気がするが完全に忘れてるので。
サンプルのテキスト(Paul Grahamのエッセイ)を拾ってきてdataディレクトリに入れる。
%%bash
wget https://raw.githubusercontent.com/run-llama/llama_index/main/examples/paul_graham_essay/data/paul_graham_essay.txt
mkdir data
mv paul_graham_essay.txt data
SimpleDirectoryReaderでディレクトリ内のファイルを読み込んでdocumentsオブジェクトに変換、VectorStoreIndexでdocumentsオブジェクトからベクトルインデックスを作成、という感じ。内部でOpenAI Embedding APIを呼んでいる。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
ベクトルインデックスオブジェクトに対して.as_query_engine()メソッドを実行すると、retrieverになるのだろう。このretrieverに対して、.query()メソッドでクエリを投げると、
- クエリのベクトル化
- ベクトルインデックスからの検索
- 検索結果も含めたプロンプトを生成してOpenAI ChatCompletion APIを呼んで、回答を生成する。
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
結果はこんな感じ。
The author worked on writing and programming outside of school before college. They wrote short stories and tried writing programs on an IBM 1401 computer using an early version of Fortran. They later got a microcomputer and started programming on it, writing simple games and a word processor. They also mentioned their interest in philosophy and AI.
ロギングの設定はこんな感じで。ログレベルDEBUGだと詳細なログが大量に出力される。通常はINFOで良さそう。
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
OpenAIへのリクエスト・レスポンスのログを追加するには以下。jupyterだと赤で表示されるのがこれだと思う。
openai.log = "debug"
オフに戻す場合は以下。
openai.log = "None"
デフォルトでは、ベクトルインデックスはオンメモリで展開されている。ディスクに書き出すには以下。
index.storage_context.persist()
データは以下のようなJSONで構成されていた。
$ tree storage/
storage/
├── docstore.json
├── graph_store.json
├── index_store.json
└── vector_store.json
逆にこのデータを読み込む場合。
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
RAGの概念とLlamaIndexのコンポーネント
LlamaIndexの概念というかRAGにおけるLlamaIndexのコンポーネントという感じ。RAGわかってればサラッと流しても良いけど、コンポーネントについては把握しておきたいので、ちょっとまとめておく。
RAG
まず、構成を全体図にまとめてみた。
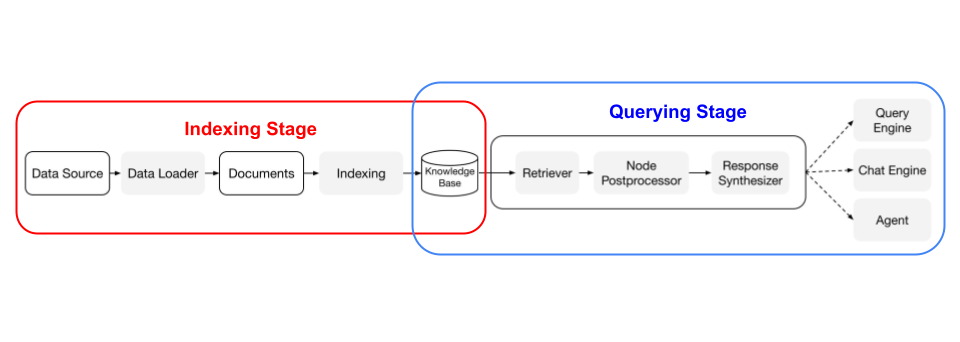
RAGは2つのステージから構成される。
- Indexing Stage
- ナレッジベースを作成
- Querying Stage
- クエリを元にナレッジベースから関連性の高いコンテキストを検索、それを元にLLM二回答を生成させる
アプリケーション単体としてみれば直接クエリを受けて回答を行うQuery StageがRAGのイメージだと思うのだけど、システム全体で見れば当然そのデータを作成するプロセスが必要になるわけで、それがIndexing Stageになる。LlamaIndexに限らず、LangChainなどでも、Querying Stageはもちろん、Indexing Stageのためのツールセットも用意されている。
Indexing Stage
RAGで使用するナレッジベースを作成するプロセス。以下のコンポーネントが用意されている。
-
Data Connectors
- いろいろなデータソースとデータ形式からデータを取り込み、単純なドキュメント表現(テキストと単純なメタデータ)に変換するデータコネクタ。LlamaIndexでは
Readerという言う。
- いろいろなデータソースとデータ形式からデータを取り込み、単純なドキュメント表現(テキストと単純なメタデータ)に変換するデータコネクタ。LlamaIndexでは
-
Dcouments / Nodes
-
Documentは、データソース(たとえばPDF、APIの出力、データベースから取得したデータなど)を含む一般的なコンテナ。 -
Nodeは、LlamaIndexのデータの最小単位であり、ソースとなるDocumentの「チャンク」を表す。これはメタデータと関連性(他のNodeとの関連性)を含む豊富な表現で、正確で表現豊かな検索操作を可能にする。
-
-
Data Indexes
- データ取り込み後に、そのデータを簡単に取得できる形式にインデックス化する。LlamaIndexは、内部でドキュメントを中間表現に解析し、ベクトル埋め込みを計算し、メタデータを推測する。最も一般的に使用されるインデックスは
VectorStoreIndex。
- データ取り込み後に、そのデータを簡単に取得できる形式にインデックス化する。LlamaIndexは、内部でドキュメントを中間表現に解析し、ベクトル埋め込みを計算し、メタデータを推測する。最も一般的に使用されるインデックスは
Querying Stage
作成したナレッジベースを使用して、ユーザクエリに関連性の高いコンテキストを検索し、これをクエリと共にLLMに渡して、回答を「合成」する。この一連の処理を行うのが以下のコンポーネント。
-
Retriever
- ナレッジベースからクエリに最も関連性の高いコンテキストを最も効率よく検索するのがRetriever
- 最も一般的なのはベクトルインデックスを使った密検索
-
Node Postprocessor
- Retrieverが取得したコンテキストはチャンク、つまりNodeの形で取得される。これの前処理を行うのがNode Postprocessor
- 変換したり、フィルタリングしたり、リランキングしたり・・・
-
Response Synthesizer
- ユーザクエリとチャンク化されたコンテキストをLLMに渡して回答を生成する
それぞれ色々な種類のモジュールが用意されており、これらを組み合わせることで、いろんなユースケース、つまりRAGパイプラインを構築できる。たとえば以下。
-
Query Engines
- データに対して質問を行うためのエンドツーエンドのパイプライン。自然言語でクエリを受け取り、検索されたコンテキストをリファレンスとしてLLMに渡して、レスポンスを返す
-
Chat Engines
- 基本的にはQuery Engineと同じだが、単一の質問と回答ではなく、マルチターンでのやりとりが可能
-
Agents
- 予め決められたロジックに従うのではなく、最適なアクションのシーケンスを動的に決定、自律的に動作する。より複雑なタスクに柔軟に対応できる。
上記はあくまでも概念的な話で、実際にはLlamaIndexのドキュメントを見ると、モジュールは以下のような分け方になっている様子。
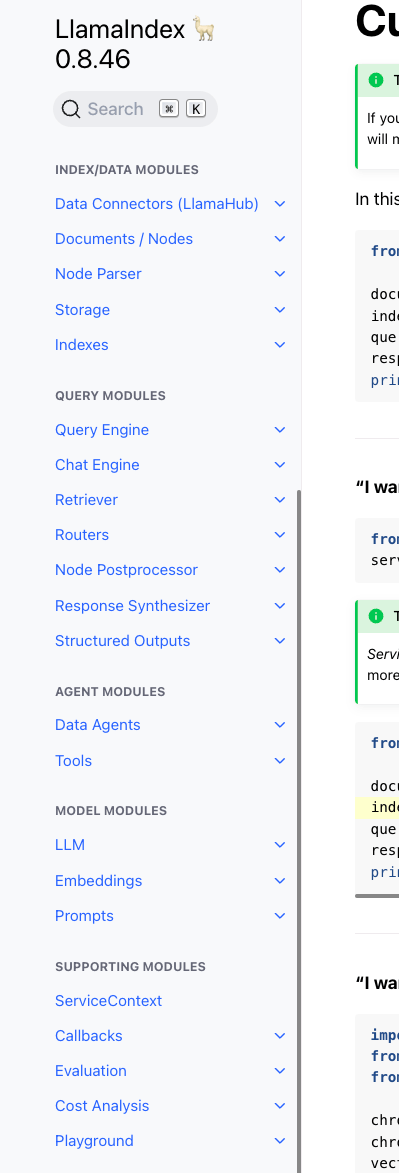
チュートリアルを見るとわかるように、少ない量でシンプルに書ける反面非常に抽象化されているので、このあたりのコンセプトやモジュール構造を理解することがフレームワークを使う場合にはとても重要になると思う。
(そしてそれが大変・・・)
Customization Tutorial
最初のチュートリアルのコードを、モジュールを組み替えたりすることで、色々できるよー、という話。まあフレームワークってそういうもんですよね。
ここはパス
END-TO-END TUTORIALS
色々なチュートリアルが用意されている。
- Basic Usage Pattern
- One-Click Observability
- Principled Development Practices
- Discover LlamaIndex Video Series
- Finetuning
- Building RAG from Scratch (Lower-Level)
- Use Cases
色々見てみたけど、LangChainとかと同じでどこからやればいいのかがさっぱりわからないw。とりあえず今の段階では基本的なところをカバーしたいので、以下あたりをやってみる。
- Basic Usage Pattern
- Building RAG from Scratch (Lower-Level)
- Use Casesのいくつか
END-TO-END TUTORIALS: Basic Usage Pattern
※個人的に↑のチュートリアルドキュメント、章立てがまとまってない感(っていうか読みにくい・・・)を感じたので、オリジナルと多少順番を前後しています。
基本的な流れ
- ドキュメントの読み込み(手動 or data loderrs経由)
- DocumentsをパースしてNodeに変換
- NodeやDocumentsからインデックス作成
- [オプション/上級] 他のインデックス上にインデックスを作成
- インデックスをクエリ
- レスポンスをパース
1. ドキュメントの読み込み(手動 or データローダー経由)
データを読み込む。読み込んだデータはDocumentオブジェクトとなる。様々なdata lodersがあり、load_data関数でドキュメントを読み込める。
以下は最初のチュートリアルの例。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader('./data').load_data()
SimpleDirectoryReaderはディレクトリ内のファイルを読み込む。最初のチュートリアルではPaul Grahamのエッセイのテキストファイルが一つあったので、これがそのままDocumentオブジェクトになっている。
print(len(documents))
print(documents)
1
[
Document(
id_='0f62af38-49aa-4935-b9e3-beb965597f85',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={},
hash='2e2d9629223c077019a6dde689049344ff2293d6c52372871420119ec049f25c',
text='\n\nWhat I Worked On\n\nFebruary 2021\n\nBefore college the two main things I worked on, outside of school, were writing and programming. I didn\'t write essays. (snip) So it seems likely there exists at least one path out of McCarthy\'s Lisp along which discoveredness is preserved.\n\n\n\nThanks to Trevor Blackwell, John Collison, Patrick Collison, Daniel Gackle, Ralph Hazell, Jessica Livingston, Robert Morris, and Harj Taggar for reading drafts of this.\n','
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n')
]
1ファイル1ドキュメントになっていて、Documentオブジェクトのtextとして読み込まれているのがわかる。
data lodersを使わずに直接Documentオブジェクトを作ることもできる。
import glob
import os
from llama_index import Document
text_list = []
for file in glob.glob('data/*'):
with open(file, encoding='utf-8') as f:
c = f.read()
text_list.append(c)
documents = [Document(text=t) for t in text_list]
Document化したら次のステップでNodeに変換する。なお、Documentから直接インデックスを作成することもできるが、ここでは順に進むこととする。
2. ドキュメントをパースしてNodeに変換する
NodeはDocumentをチャンクに分割したもので、メタデータやNode間のリレーションなども定義できる。Nodeは第一級オブジェクトであり、Nodeやその属性を直接定義できる。NodeParserクラスを使ってDocumentをNodeにパースすることもできる。
from llama_index.node_parser import SimpleNodeParser
parser = SimpleNodeParser.from_defaults()
nodes = parser.get_nodes_from_documents(documents)
SimpleNodeParserでパースされたドキュメントは、複数のTextNodeオブジェクトに分割されて配列になっている。
print(len(nodes))
print(nodes)
18
[
TextNode(
id_='55bf4b17-053b-4a6d-bdb2-ed24e7b2a782',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(
node_id='fe4bbbd0-df5c-4ed7-bdff-27c04e60064d',
node_type=None,
metadata={},
hash='2e2d9629223c077019a6dde689049344ff2293d6c52372871420119ec049f25c'
),
<NodeRelationship.NEXT: '3'>: RelatedNodeInfo(
node_id='ee57542d-ee5c-41ec-80c9-67f07a3568df',
node_type=None,
metadata={},
hash='2b076feb45ef9318654997e47fb3b2f2185bcc7e39e0997045fcf755cb2ca6dc'
)
},
hash='004bbb820e2627b96db9a79d93bb1b8a665582ada07e261a6085d2d0b0119ad6',
text='What I Worked On\n\nFebruary 2021\n\nBefore college the two main things I worked on, outside of school, were writing and programming. I didn\'t write essays. (snip) I haven\'t tried rereading The Moon is a Harsh Mistress, so I don\'t know how well it has aged, but when I read it I was drawn entirely into its world. It seemed only a matter of time before we\'d have Mike, and when I saw Winograd using SHRDLU, it seemed like that time would be a few years at most. All you had to do was teach SHRDLU more words.',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
),
TextNode(
id_='ee57542d-ee5c-41ec-80c9-67f07a3568df',
(snip)
relationships={
<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(
node_id='fe4bbbd0-df5c-4ed7-bdff-27c04e60064d',
node_type=None,
metadata={},
hash='2e2d9629223c077019a6dde689049344ff2293d6c52372871420119ec049f25c'
),
<NodeRelationship.PREVIOUS: '2'>: RelatedNodeInfo(
node_id='55bf4b17-053b-4a6d-bdb2-ed24e7b2a782',
node_type=None,
metadata={},
hash='004bbb820e2627b96db9a79d93bb1b8a665582ada07e261a6085d2d0b0119ad6'
),
(snip)
]
テキストが分割されていると同時に、Documentおよび前後のNodeとのリレーションが付与されている。
こちらも直接自分で定義することができる。ここはサンプルそのままだけど、これを見ても、ちゃんとNode間のリレーションが意識していることがわかる。
rom llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(node_id=node2.node_id)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(node_id=node1.node_id)
nodes = [node1, node2]
また、Nodeにメタデータを付与することもできる。
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(node_id=node1.node_id, metadata={"key": "val"})
SimpleNodeParserはLangChainでいうところのTextSplitterをさらにラップしたようなものみたい。SimpleNodeParserのチャンク単位などの制御は以下のように設定できる。
node_parser = SimpleNodeParser.from_defaults(chunk_size=1024, chunk_overlap=20)
また、TextSplitter部分をカスタマイズすることもできる
import tiktoken
from llama_index.text_splitter import SentenceSplitter
text_splitter = SentenceSplitter(
separator=" ",
chunk_size=1024,
chunk_overlap=20,
paragraph_separator="\n\n\n",
secondary_chunking_regex="[^,.;。]+[,.;。]?",
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
これらについてはNode Parserモジュールのドキュメントにあるので、ここでは細かくは追わない。
3. NodeやDocumentからインデックス作成
NodeやDocumentsからインデックスを作成する。
Documentsの場合はfrom_documents経由で作成する。こちらのケースは上のステップ2をスキップしたような形になる。
from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
show_progress=Trueを指定するとプログレスバーが表示される。tmdqを使っていると思う。

Nodeの場合は直接指定する。こちらはDocumentsからNodeを作成した場合。
from llama_index import VectorStoreIndex
index = VectorStoreIndex(nodes)
最初のチュートリアルでOpenAIのAPIキーを設定していたが、VectorStoreIndexの場合は内部でOpenAI Embeddings APIを実行している。インデックスも色々な種類があり、インデックスによって必要な処理が変わる。
インデックスの作成にはいろいろな使い方のバリエーションやオプションがあるのでひと通り見ていく。
複数のインデックスでNodeを使い回す
StorageContextを使う。StorageContextは、Node(ドキュメント)、インデックス、ベクトルデータのストレージとしての抽象化レイヤーっぽい。StorageContextを使わない場合はおそらくそれぞれのインデックスごとに個別に作成されるのだろうと思われる。
from llama_index import StorageContext
from llama_index import VectorStoreIndex, SummaryIndex
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
index1 = VectorStoreIndex(nodes, storage_context=storage_context)
index2 = SummaryIndex(nodes, storage_context=storage_context)
インデックスにDocument/Nodeを追加する
インデックス作成しておいて、insertメソッドでDocumentを直接追加できる。
from llama_index import VectorStoreIndex
index = VectorStoreIndex([])
for doc in documents:
index.insert(doc)
Nodeを追加する場合はinsert_nodesメソッドを使う
from llama_index import VectorStoreIndex
index = VectorStoreIndex([])
index.insert_nodes(nodes)
Document管理については以下も参照
Documentのカスタマイズ
Document二メタデータを追加できる。
document = Document(
text='text',
metadata={
'filename': '<doc_file_name>',
'category': '<category>'
}
)
詳細は以下
LLMのカスタマイズ
デフォルトではLLMはOpenAIのtext-davinci-003を使うようになっているらしいが、これを変更することができる。
from llama_index import VectorStoreIndex, ServiceContext, set_global_service_context
from llama_index.llms import OpenAI
...
llm = OpenAI(model="gpt-4", temperature=0, max_tokens=256)
service_context = ServiceContext.from_defaults(llm=llm)
set_global_service_context(service_context)
index = VectorStoreIndex.from_documents(
documents
)
**ただこれインデックス作成時は直接は関係ないんじゃなかろうか?**そもそもこのタイミングで必要なのはまずはEmbedding APIだし。まあインデックス作成前の前処理とかでLLM使うとかならわからんではないけども、ちょっとここでこの話題が出てくるのは唐突感。
むしろEmbeddingを変更する方法を知りたいと思って調べてみたらこの辺。
こんな感じかな。これならわかる。
from llama_index import VectorStoreIndex, ServiceContext, set_global_service_context
from llama_index.llms import OpenAI
from llama_index.embeddings import OpenAIEmbedding
embed_model = OpenAIEmbedding()
llm = OpenAI(temperature=0.1, model="gpt-4")
service_context = ServiceContext.from_defaults(
embed_model=embed_model,
llm=llm
)
set_global_service_context(service_context)
あとローカルモデルを使うこともできる。
from llama_index import ServiceContext
service_context = ServiceContext.from_defaults(llm="local")
OpenAIのAPIキーがセットされていない場合はデフォルトだとllama.cppを使うようになっているっぽい(APIキーをセットし忘れたらそういうメッセージが出た、まあllama.cppも用意してなかったので結局エラーになったのだけど)。
Global ServiceContext
上で出てきたGlobal ServiceContextだけども、要はデフォルトを置き換えるようなものらしく、一度定義してGlobal ServiceContextにしておけば、以後はキーワード引数で上書きしない限り、それで動作する様子。
Customizing Prompts
Customizing Embeddings
4. [オプション/上級] 他のインデックス上にインデックスを作成
5. インデックスをクエリ
6. レスポンスをパース
しばらくやってないうちに、ドキュメントごっそり更新されてる・・・まあありがちなんだけども。

どうもEnd-To-End Tutorialsが書き換わってUnderstandingというところにまとまった感じかな
Module Guideもだいぶスッキリした感がある。
とりあえずUnderstandingからやり直していくか。
ドキュメント見直してみたのだけど、やっぱり体系的にやるのは難しそう。これは実際に手を動かしながら、適当に調べていくのが良さそうな気がしてきた。
LangChainもしんどそうだけどLlamaIndexも抽象化度合いはエグそう。
コチラでやり直し