「olmOCR」を試す
PDFからきれいなプレーンテキストを抽出するオープンソースツール、olmOCRをご紹介します!
規模に合わせて構築されたolmOCRは、多くの種類のドキュメントを高いスループットで処理します。3000トークン/秒以上、100万ページあたり190ドル相当、GPT-4oの1/32のコストです!
PDFはテキストを抽出するのが難しいことで有名です。列、表、数式などの複雑なレイアウトを持つこともあります。標準的なツールでは、読み取り順序に苦労し、特にスキャン文書や手書き✍️のテキストでは、テキストが乱れたり、コンテンツが完全に欠落したりすることがよくあります。
olmOCRを構築するために、我々は100KのクロールされたPDFから260Kページの多様なデータセットを調達し、PDFメタデータとページラスタを組み合わせた*ドキュメントアンカリング*と呼ばれる特殊なプロンプトを使用してGPT-4oを使用してシルバーデータを生成し、効率的で強力な7Bビジョン言語モデルを学習させました。
olmOCRは競合を圧倒しています!トップPDF処理ツールとのペアワイズ判定を用いた私たちの人間による評価は、olmOCRの評価が他のツールを大きく上回っていることを示しています。私たちの言葉を鵜呑みにせず、ご自身でお試しください:
olmOCR はhttps://olmocr.allenai.orgで実際に試すことができます。
ブログ記事: https://olmocr.allenai.org/blog
トレーニングおよびツールキットコード: https://github.com/allenai/olmocr
HuggingFaceコレクション: https://huggingface.co/collections/allenai/olmocr-67af8630b0062a25bf1b54a1
モデルはこちら
olmOCR-7B-0225-preview
これは、Qwen2-VL-7B-InstructをolmOCR-mix-0225データセットを使用して微調整したolmOCRモデルのプレビューリリースです。
(snip)
このモデルを最も効果的に使用するには、olmOCRツールキットを使用します。このツールキットには、膨大な数の文書を処理できるsglangを介した効率的な推論設定が含まれています。使用方法
このモデルは、長い方の辺が1024ピクセルとなるようにレンダリングされた単一の文書画像を入力として想定しています。
プロンプトには、その文書の追加メタデータを含める必要があります。これを生成する最も簡単な方法は、olmOCRツールキットが提供するメソッドを使用することです。
手動でのプロンプト
olmOCRツールキットを使用せずに、このモデルを手動でプロンプトしたい場合は、以下のコードを参照してください。
(snip)
動かす方法としては
- olmOCRツールキットのCLIで実施
- プロンプトを手動で指定してPythonコードから実施
という感じっぽく見える。後者のほうが少し動きが見えるように思えるので、そちらで試してみる。T4だとVRAMが足りなかったので、Colaboratory L4で。
パッケージインストール
!pip install olmocr
!pip freeze | grep -i olmocr
olmocr==0.1.58
PDFを画像化するための依存ライブラリをインストールする
!sudo apt-get update
!sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools
モデルとプロセッサを初期化
import torch
import base64
import urllib.request
import json
from io import BytesIO
from PIL import Image
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from olmocr.data.renderpdf import render_pdf_to_base64png
from olmocr.prompts import build_finetuning_prompt
from olmocr.prompts.anchor import get_anchor_text
model = Qwen2VLForConditionalGeneration.from_pretrained(
"allenai/olmOCR-7B-0225-preview",
torch_dtype=torch.bfloat16
).eval()
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
今回は、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを画像に変換して使用する。
PDFの特徴
- サイズ: 1.8MB
- ページ数: 21
- 縦長レイアウト
- 文字は横書き
- 表・グラフ等含む
参考までに一部抜粋。
ではPDFをダウンロード
urllib.request.urlretrieve(
"https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf",
"./paper.pdf"
)
1ページ目を読み込ませてみる。サンプルコードだとmax_new_tokensが小さすぎて出力が少なすぎるので、大きめに変更してある。
# 1ページ目を画像に変換
image_base64 = render_pdf_to_base64png(
"./paper.pdf",
1,
target_longest_image_dim=1024
)
# ドキュメントのメタデータを使用してプロンプトを構築
anchor_text = get_anchor_text(
"./paper.pdf",
1,
pdf_engine="pdfreport",
target_length=4000
)
prompt = build_finetuning_prompt(anchor_text)
# フルプロンプトを構築
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_base64}"}
},
],
}
]
# チャットテンプレートとプロセッサを適用
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
# 出力を生成
output = model.generate(
**inputs,
temperature=0.8,
max_new_tokens=4096,
num_return_sequences=1,
do_sample=True,
)
# 出力をデコード
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(json.dumps(json.loads(text_output[0]), indent=2, ensure_ascii=False))
{
"primary_language": "ja",
"is_rotation_valid": true,
"rotation_correction": 0,
"is_table": true,
"is_diagram": false,
"natural_text": "令和5年度 神戸市観光動向調査結果について\n\n本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施。\n\n調査員が対面にてアンケート項目を聞き取りする形で実施。\n\n調査日\n\n① 令和5年 5月 13日(土)・20日(土)※\n② 令和5年 9月 9日(土)\n③ 令和5年 11月 25日(土)/12月 2日(土)※\n④ 令和6年 2月 10日(土)・17日(土)・24日/3月 30日(土)※\n\n※雨天等により、一部の調査地点については延期して実施。\n\n| 地区 | NO | 調査地点 | サンプル数 |\n|------|----|----------|------------|\n| 北野 | 1 | 北野町広場 | 246 |\n| | 2 | 北野工房のまち | 154 |\n| | 3 | 南京町広場 | 218 |\n| | 4 | 総合インフォメーションセンター | 198 |\n| | 5 | 旧居留地 | 201 |\n| | 6 | 神戸布引ロープウェイハーブ園山麓駅 | 203 |\n| | 7 | 白鶴酒造資料館内 | 205 |\n| | 8 | 王子動物園内 | 235 |\n| | 9 | 県立美術館前 | 217 |\n| | 10 | さんちか夢広場 | 208 |\n| | 11 | 神戸空港屋上階展望ロビー | 212 |\n| | 12 | IKEA神戸 | 192 |\n| | 13 | 能福寺(兵庫大仏) | 147 |\n| | 14 | 兵庫津ミュージアム | 204 |\n| | 15 | 神戸海洋博物館前及び周辺 | 200 |\n| | 16 | 中突堤中央ターミナル周辺 | 208 |\n| | 17 | umie モザイク | 201 |\n| | 18 | ハーバーランド総合インフォメーション前 | 213 |\n| 市街地 | 19 | 六甲天覧台 | 209 |\n| | 20 | 摩耶山掬星台広場 | 200 |\n| | 21 | 六甲山牧場内 | 215 |\n| | 22 | 六甲ガーデンテラス内 | 211 |\n| | 23 | 有馬温泉観光総合案内所前 | 214 |\n| | 24 | 金の湯前 | 216 |\n| | 25 | 六甲有馬ロープウェイ有馬温泉駅 | 232 |\n| 有馬 | 26 | 須磨離宮公園 | 202 |\n| | 27 | 舞子公園(舞子海上プロムナード) | 230 |\n| 須磨・舞子 | 28 | 神戸ワイナリー(農業公園) | 235 |\n| | 29 | 神戸フルーツ・フラワーパーク大沢園内 | 209 |\n| | 30 | 神戸三田プレミアム・アウトレット | 215 |\n| 西北神 | 合計 | 6,250 |"
}
テキスト部分だけだとこんな感じ。
print(json.loads(text_output[0])["natural_text"])
令和5年度 神戸市観光動向調査結果について
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施。
調査員が対面にてアンケート項目を聞き取りする形で実施。
調査日
① 令和5年 5月 13日(土)・20日(土)※
② 令和5年 9月 9日(土)
③ 令和5年 11月 25日(土)/12月 2日(土)※
④ 令和6年 2月 10日(土)・17日(土)・24日/3月 30日(土)※
※雨天等により、一部の調査地点については延期して実施。
| 地区 | NO | 調査地点 | サンプル数 |
|------|----|----------|------------|
| 北野 | 1 | 北野町広場 | 246 |
| | 2 | 北野工房のまち | 154 |
| | 3 | 南京町広場 | 218 |
| | 4 | 総合インフォメーションセンター | 198 |
| | 5 | 旧居留地 | 201 |
| | 6 | 神戸布引ロープウェイハーブ園山麓駅 | 203 |
| | 7 | 白鶴酒造資料館内 | 205 |
| | 8 | 王子動物園内 | 235 |
| | 9 | 県立美術館前 | 217 |
| | 10 | さんちか夢広場 | 208 |
| | 11 | 神戸空港屋上階展望ロビー | 212 |
| | 12 | IKEA神戸 | 192 |
| | 13 | 能福寺(兵庫大仏) | 147 |
| | 14 | 兵庫津ミュージアム | 204 |
| | 15 | 神戸海洋博物館前及び周辺 | 200 |
| | 16 | 中突堤中央ターミナル周辺 | 208 |
| | 17 | umie モザイク | 201 |
| | 18 | ハーバーランド総合インフォメーション前 | 213 |
| 市街地 | 19 | 六甲天覧台 | 209 |
| | 20 | 摩耶山掬星台広場 | 200 |
| | 21 | 六甲山牧場内 | 215 |
| | 22 | 六甲ガーデンテラス内 | 211 |
| | 23 | 有馬温泉観光総合案内所前 | 214 |
| | 24 | 金の湯前 | 216 |
| | 25 | 六甲有馬ロープウェイ有馬温泉駅 | 232 |
| 有馬 | 26 | 須磨離宮公園 | 202 |
| | 27 | 舞子公園(舞子海上プロムナード) | 230 |
| 須磨・舞子 | 28 | 神戸ワイナリー(農業公園) | 235 |
| | 29 | 神戸フルーツ・フラワーパーク大沢園内 | 209 |
| | 30 | 神戸三田プレミアム・アウトレット | 215 |
| 西北神 | 合計 | 6,250 |
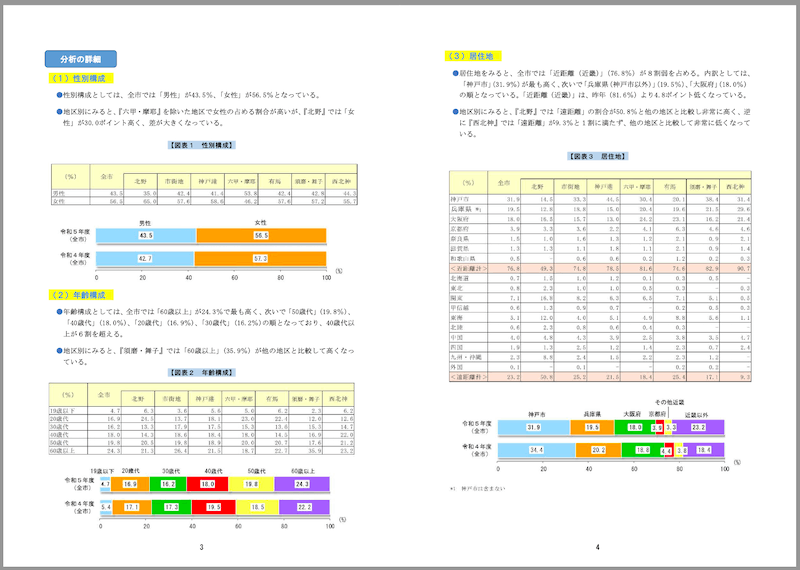
実際の1ページ目はこう

4ページ目も試してみる
image_base64 = render_pdf_to_base64png(
"./paper.pdf",
4,
target_longest_image_dim=1024
)
anchor_text = get_anchor_text(
"./paper.pdf",
4,
pdf_engine="pdfreport",
target_length=4000
)
prompt = build_finetuning_prompt(anchor_text)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_base64}"}
},
],
}
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
output = model.generate(
**inputs,
temperature=0.8,
max_new_tokens=4096,
num_return_sequences=1,
do_sample=True,
)
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(json.loads(text_output[0])["natural_text"])
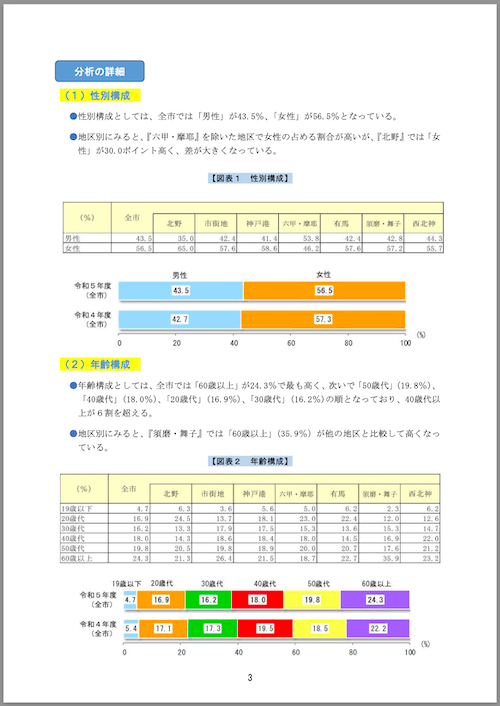
(1)性別構成
●性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
●地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女性」が30.0ポイント高く、差が大きくなっている。
【図表1 性別構成】
| (%) | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 須磨・舞子 | 西北神 |
|-----|------|------|--------|--------|-----------|------|-----------|--------|
| 男性 | 43.5 | 35.0 | 42.4 | 41.4 | 53.8 | 42.4 | 42.8 | 44.3 |
| 女性 | 56.5 | 65.0 | 57.6 | 58.6 | 46.2 | 57.6 | 57.2 | 55.7 |
(2)年齢構成
●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、「40歳代」(18.0%)、「30歳代」(16.9%)、「20歳代」(16.2%)の順となっており、40歳代以上が6割を超える。
●地区別にみると、『須磨・舞子』では「60歳以上」(35.9%)が他の地区と比較して高くなっている。
【図表2 年齢構成】
実際の4ページ目
ここは全部取れなかったようで下の部分が抜け落ちてる。パラメータいじれば取れるのかなと思っていろいろ試してみたけどうまくいかず。
あとは画像には対応していない様子。
でXのポストにもあった「ドキュメントアンカリング」というやつ。
olmOCRを構築するために、我々は100KのクロールされたPDFから260Kページの多様なデータセットを調達し、PDFメタデータとページラスタを組み合わせたドキュメントアンカリングと呼ばれる特殊なプロンプトを使用してGPT-4oを使用してシルバーデータを生成し、効率的で強力な7Bビジョン言語モデルを学習させました。
テクニカルペーパーでは以下とある。
GOT Theory 2.0(Wei et al., 2024)や Nougat(Blecher et al., 2023)などの多くのエンドツーエンドOCRモデルは、文書をプレーンテキストに変換する際にラスタライズされたページのみに依存しています。つまり、文書ページの画像を入力として処理し、自己回帰的にテキストトークンをデコードします。このアプローチは、画像のみの電子化パイプラインとの互換性は高いものの、ほとんどのPDFがデジタルで作成された文書であり、すでに電子化されたテキストや、コンテンツの正確な線形化に役立つその他のメタデータが含まれているという事実を見逃しています。
それに対して、olmOCRパイプラインは文書のテキストとメタデータを活用します。このアプローチを、私たちは「ドキュメントアンカー」と呼んでいます。図2は、私たちの手法の概要を示しています。ドキュメントアンカーは、各ページの目立つ要素(テキストブロックや画像など)の座標を抽出し、PDFバイナリファイルから抽出した生のテキストとともに挿入します。重要なのは、アンカーテキストが、ページのラスタ画像とともに、あらゆるVLMへの入力として提供されることです。
私たちのアプローチは、コンテンツ抽出の品質を向上させます。GPT-4oにシルバートレーニングサンプルを収集させる際、olmOCR-7B-0225-previewを微調整する際、およびolmOCRツールキットで推論を行う際に、ドキュメントアンカーリングを適用します。
referred from https://olmocr.allenai.org/papers/olmocr.pdf

テキストとその座標を抽出して、それを元に作成したデータセットでファインチューニングすることで、より文書構造を的確に捉えることができる、ということになるのかな?
プロンプトはこの部分
anchor_text = get_anchor_text(
"./paper.pdf",
4,
pdf_engine="pypdf",
target_length=10000
)
prompt = build_finetuning_prompt(anchor_text)
こういうプロンプトになっていた。
Below is the image of one page of a document, as well as some raw textual content that was previously extracted for it. Just return the plain text representation of this document as if you were reading it naturally.
Do not hallucinate.
RAW_TEXT_START
Page dimensions: 595.0x842.0
[Image 68x36 to 528x276]
[Image 21x422 to 532x616]
[295x26]3
[68x728](1)性別構成
[79x703]●性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
[79x678]●地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女
[90x662]性」が30.0ポイント高く、差が大きくなっている。
[247x629]【図表1 性別構成】
[68x403](2)年齢構成
[79x379]●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、
[90x362]「40歳代」(18.0%)、「20歳代」(16.9%)、「30歳代」(16.2%)の順となっており、40歳代以
[90x345]上が6割を超える。
[79x320]●地区別にみると、『須磨・舞子』では「60歳以上」(35.9%)が他の地区と比較して高くなっ
[90x304]ている。
[247x287]【図表2 年齢構成】
[85x756]分析の詳細
RAW_TEXT_END
表の部分が抽出できていないのだけど、4ページ目の表は画像になってしまっているせいだと思う。んー、でも抽出結果を見ると上の表は取れてるんだけど。
サンプルコードだと1ページづつ処理する形になっているので、まるっとテキスト化するにはひと手間必要だけども、olmOCRツールキットのCLIだと
- PDFの全ページを1コマンドで処理
- 複数のPDFや、S3バケット内のPDFを一括で処理
- 抽出結果とページ画像を同時に確認できるHTMLでの出力
- マルチノードやクラスタ上で大量のPDFを一括で処理
などもできる様子。またファインチューニング用のコードも公開されている。