高速なText Embeddings用推論サーバ「text-embeddings-inference」を試す
Text Embeddings Inference
テキスト埋め込みモデルのための超高速推論ソリューション。
Nvidia A10でシーケンス長512トークンのBAAI/bge-base-en-v1.5のベンチマーク:
refered from https://github.com/huggingface/text-embeddings-inference
refered from https://github.com/huggingface/text-embeddings-inference
refered from https://github.com/huggingface/text-embeddings-inference
refered from https://github.com/huggingface/text-embeddings-inference
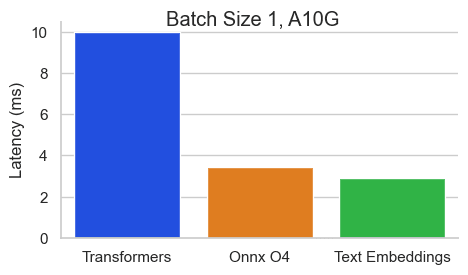
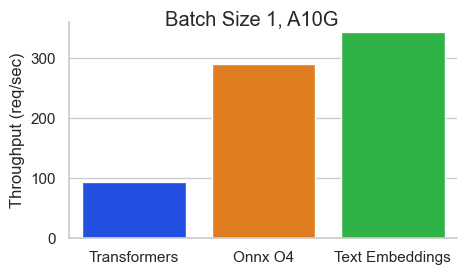
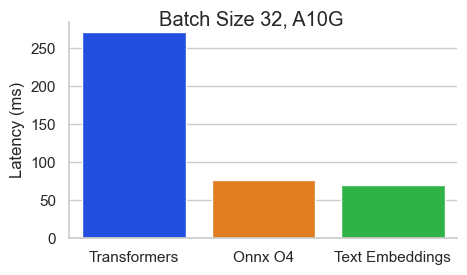
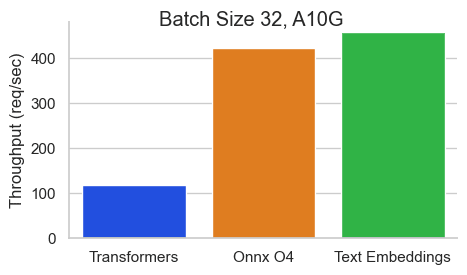
Text Embeddings Inference (TEI) は、オープンソースのテキスト埋め込みおよびシーケンス分類モデルを展開し、提供するためのツールキットです。TEI を使用すると、FlagEmbedding、Ember、GTE、E5 など、最も人気の高いモデルの高性能抽出が可能になります。TEI は、以下のような多くの機能を備えています。
- モデルグラフのコンパイルステップなし
- Macでのローカル実行のためのメタルサポート
- 小さなDockerイメージと高速な起動時間。真のサーバーレスの準備は万端です!
- トークンベースの動的バッチ処理
- Flash Attention、Candle、cuBLASLtを使用した推論のための最適化されたトランスフォーマーコード
- Safetensorsによる重み付け
- 実稼働環境向け(Open Telemetryによる分散トレース、Prometheusメトリクス
ドキュメントはこちら
Quick Tourに従って進めてみる
前提
- Ubuntu 22.04
- RTX4090(VRAM 24GB)
- NVIDIA Container Toolkitはインストール済み
- CUDA-12.6
作業ディレクトリ作成
mkdir tei-work && cd tei-work
ではモデルを指定して起動。使用可能なモデルはここにあるが、書いていないものでも動かせるものはある模様。今回はサポートされている"intfloat/multilingual-e5-large-instruct"を使う。
model="intfloat/multilingual-e5-large-instruct"
volume=$PWD/data
docker run --gpus all -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model
起動後にモデルがダウンロードされる。以下のような出力がされればOKっぽい。
2024-10-29T06:01:21.429302Z INFO text_embeddings_router::http::server: router/src/http/server.rs:1779: Ready
エンドポイントにアクセスしてみる。instructだから入力の指定は正しくないと思うけど、とりあえず。
curl 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":"ディープラーニングとは何?"}' \
-H 'Content-Type: application/json'
結果
[[0.01910246,0.0037706823,-0.019749112,-0.041840155,0.02378632,0.0059072566,0.010564901,0.050368976,0.051592372,(snip)
バッチもできる
curl 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":["おはよう", "おやすみ"]}' \
-H 'Content-Type: application/json'
[[0.04562383,0.03425249,0.0104540195,-0.046523847,(snip),0.023192693,0.002501003,-0.009147267,0.0046904623],[0.045070745,0.049269885,0.00072883477,-0.055603586,(snip),0.030811174,0.047135323,-0.01821376,-0.016446624,0.009430564]]
続いてリランカー。サポートされているとは書かれていないけども、"BAAI/bge-reranker-v2-m3"で試してみる。使ったことがないのだけども。
model="BAAI/bge-reranker-v2-m3"
volume=$PWD/data
docker run --gpus all -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model
リランカー用エンドポイントにアクセス
curl 127.0.0.1:8080/rerank \
-X POST \
-d '{"query":"日本の食文化の特徴を教えて。", "texts": ["美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。","日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。","天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。","気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用します。"], "raw_scores": false}' \
-H 'Content-Type: application/json'
出力
[{"index":1,"score":0.25870037},{"index":0,"score":0.0049245106},{"index":2,"score":0.000016571452},{"index":3,"score":0.000016442495}]
curl 127.0.0.1:8080/rerank \
-X POST \
-d '{"query":"天気予報はどれぐらい当たる?", "texts": ["美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。","日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。","天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。","気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用します。"], "raw_scores": false}' \
-H 'Content-Type: application/json'
出力
[{"index":2,"score":0.012970387},{"index":3,"score":0.0016549242},{"index":1,"score":0.000016442495},{"index":0,"score":0.000016442495}]
結果だけ見ると、ちゃんと出来てるっぽい。
分類。これはちょっと日本語モデルが見つけられなかったので、Quick Tour通りに。
model=SamLowe/roberta-base-go_emotions
volume=$PWD/data
docker run --gpus all -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model
curl 127.0.0.1:8080/predict \
-X POST \
-d '{"inputs":"I like you."}' \
-H 'Content-Type: application/json'
出力
[{"score":0.986065,"label":"love"},{"score":0.0065028323,"label":"admiration"},{"score":0.0019988068,"label":"approval"},{"score":0.0008381231,"label":"neutral"},{"score":0.0005737873,"label":"joy"},{"score":0.0005163527,"label":"optimism"},{"score":0.00047383187,"label":"gratitude"},{"score":0.0003035481,"label":"realization"},{"score":0.00027638368,"label":"disapproval"},{"score":0.00026475935,"label":"desire"},{"score":0.0002536239,"label":"annoyance"},{"score":0.00025263513,"label":"caring"},{"score":0.00021274011,"label":"disappointment"},{"score":0.00019985084,"label":"excitement"},{"score":0.00018628147,"label":"sadness"},{"score":0.0001784467,"label":"anger"},{"score":0.00017295648,"label":"amusement"},{"score":0.00016763517,"label":"confusion"},{"score":0.00010865701,"label":"curiosity"},{"score":0.000105726176,"label":"disgust"},{"score":0.000091498376,"label":"surprise"},{"score":0.00007887654,"label":"remorse"},{"score":0.000046188346,"label":"fear"},{"score":0.000032752443,"label":"pride"},{"score":0.000028567187,"label":"embarrassment"},{"score":0.000024916744,"label":"nervousness"},{"score":0.000023134415,"label":"relief"},{"score":0.000022075012,"label":"grief"}]
なるほど、ラベルがそのまま出力されるのか。日本語でそういうモデルあるかな???
ここまでの例では起動時にモデルをダウンロードしていた。あらかじめダウンロードしたモデルをコンテナでマウントさせて使うこともできる。
mkdir models && cd models
git lfs install
git clone https://huggingface.co/intfloat/multilingual-e5-large-instruct
volume=$PWD
docker run --gpus all -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/multilingual-e5-large-instruct
当然ながら起動が早い
2024-10-29T06:38:47.617729Z INFO text_embeddings_router: router/src/main.rs:175: Args { model_id: "/dat*/************-**-*****-*****uct", revision: None, tokenization_workers: None, dtype: None, pooling: None, max_concurrent_requests: 512, max_batch_tokens: 16384, max_batch_requests: None, max_client_batch_size: 32, auto_truncate: false, default_prompt_name: None, default_prompt: None, hf_api_token: None, hostname: "070f8aa97b10", port: 80, uds_path: "/tmp/text-embeddings-inference-server", huggingface_hub_cache: Some("/data"), payload_limit: 2000000, api_key: None, json_output: false, otlp_endpoint: None, otlp_service_name: "text-embeddings-inference.server", cors_allow_origin: None }
(snip)
2024-10-29T06:38:54.988726Z INFO text_embeddings_router::http::server: router/src/http/server.rs:1779: Ready
curl 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":"ディープラーニングとは何?"}' \
-H 'Content-Type: application/json'
結果
[[0.01910246,0.0037706823,-0.019749112,-0.041840155,0.02378632,0.0059072566,(snip)
なお、最初のやり方でもカレントディレクトリにモデルはダウンロードされるので、次回以降は恐らくそこからロードされるのではないかと思われる。
tree -L 1 data
出力
data
├── models--BAAI--bge-reranker-v2-m3
├── models--SamLowe--roberta-base-go_emotions
├── models--intfloat--multilingual-e5-large-instruct
└── tmp
サポートされているモデルとアーキテクチャ。モデルはここに書いていないものでも動くものはあるみたい。GPUの種類はイメージタグで変えれるみたいだけど、自分の場合(RTX4090)では特に指定せずとも使えてた。
その他のドキュメント
CPUで使う場合
GPUで使う場合
Macで使う場合(Metal)
HuggingFace上に置いた自分のプライベートなモデルを使う場合
自分でコンテナをカスタムで作る場合
サンプル。RAGのエンドポイントを作る、それのコンテナを作る、例が紹介されている模様。
CLIのUsage
まとめ
高速かどうかまでは確認できていないけど、コンテナでお手軽に建てれることがわかって、使い勝手は良さそうに思う。これなら商用環境でも建てれそう。選択肢の一つとして持っておければ。
LangChainやLlamaIndexなどの主要フレームワークでもサポートされている様子。
日本語SPLADEモデルでも使える。