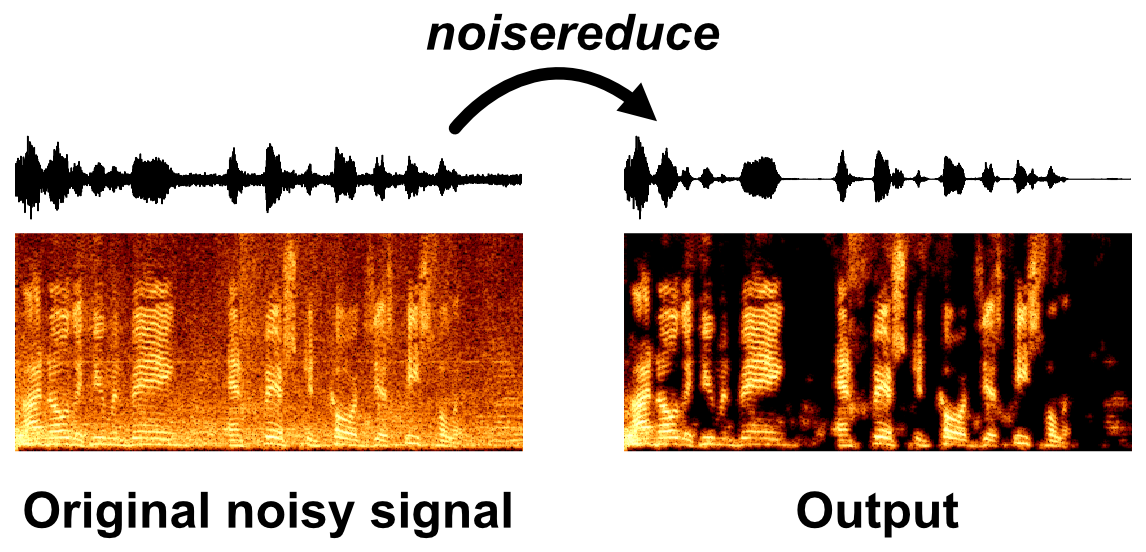
音声データからノイズを除去する「noisereduce」を試す
GitHubレポジトリ
referred from https://github.com/timsainb/noisereducePythonでのスペクトルゲーティングを利用したノイズ低減
Noisereduceは、音声、バイオアコースティック、または生理学的信号などの時間領域信号のノイズを低減するPythonアルゴリズムです。このアルゴリズムはノイズゲートの一形態である「スペクトルゲーティング」と呼ばれる手法を利用しています。信号(およびオプションでノイズ信号)のスペクトログラムを計算し、各周波数帯域のノイズ閾値(またはゲート)を推定します。この閾値を使用してマスクを計算し、周波数ごとに変化する閾値以下のノイズをゲートします。
最新バージョンのNoisereduceは以下の2つのアルゴリズムを含んでいます:
- 定常ノイズ低減:信号全体にわたって推定されたノイズ閾値を一定に保ちます。
- 非定常ノイズ低減:時間の経過とともに推定されたノイズ閾値を継続的に更新します。
バージョン3の更新点
- PyTorchベースのスペクトルゲーティングアルゴリズムが導入され、音声信号のノイズ低減が可能に。
noisereduce nn.Moduleオブジェクトを作成でき、単体モジュールまたは神経ネットワークの一部として使用可能。- アルゴリズムの実行時間が大幅に短縮。
バージョン2の更新点
- スペクトルゲーティングのノイズ低減に「定常ノイズ低減」と「非定常ノイズ低減」を追加。
- 並列処理を導入し、大規模データへの対応を強化。
- 旧バージョンのAPIを変更(以前のバージョンは
from noisereduce.noisereducev1 import reduce_noiseで利用可能)。- 長い録音の一部にノイズ低減を適用可能なオブジェクトを作成可能。
定常ノイズ低減
- 各周波数チャネルで統計を計算し、ノイズゲートを決定。それを信号に適用する。
- Audacityのノイズ低減エフェクトに基づいているが完全に再現しているわけではない。
このアルゴリズムは、Audacityのノイズ低減エフェクトに基づいていますが、完全に再現しているわけではない。エフェクトのC++コードはこちらで確認できる。- 入力:
- ノイズのプロトタイプを含む「ノイズ」クリップ(オプション)
- ノイズを除去したい信号とノイズを含む「信号」クリップ
アルゴリズムのステップ
- ノイズ音声クリップのスペクトログラムを計算。
- ノイズのスペクトログラムに基づいて統計を計算。
- ノイズの統計値(およびアルゴリズムの感度)に基づいて閾値を計算。
- 信号のスペクトログラムを計算。
- 信号のスペクトログラムと閾値を比較してマスクを作成。
- マスクを周波数および時間で平滑化。
- 信号のスペクトログラムにマスクを適用し、反転。ノイズ信号が提供されない場合、信号全体をノイズクリップとして扱いますが、通常はうまく機能します。
非定常ノイズ低減
- 定常ノイズ低減アルゴリズムを拡張し、時間経過でノイズゲートを変化させる。
- 信号の発生タイムスケールがわかっている場合(例: 鳥の鳴き声は数百ミリ秒)、長いタイムスケールのイベントをノイズと見なすことでノイズ閾値を設定可能。
アルゴリズムのステップ
- 信号のスペクトログラムを計算。
- 各周波数チャネルでIIRフィルタを前後方向に適用し、時間平滑化されたスペクトログラムを計算。
- 時間平滑化されたスペクトログラムに基づいてマスクを計算。
- マスクを周波数および時間で平滑化。
- 信号のスペクトログラムにマスクを適用し、反転。
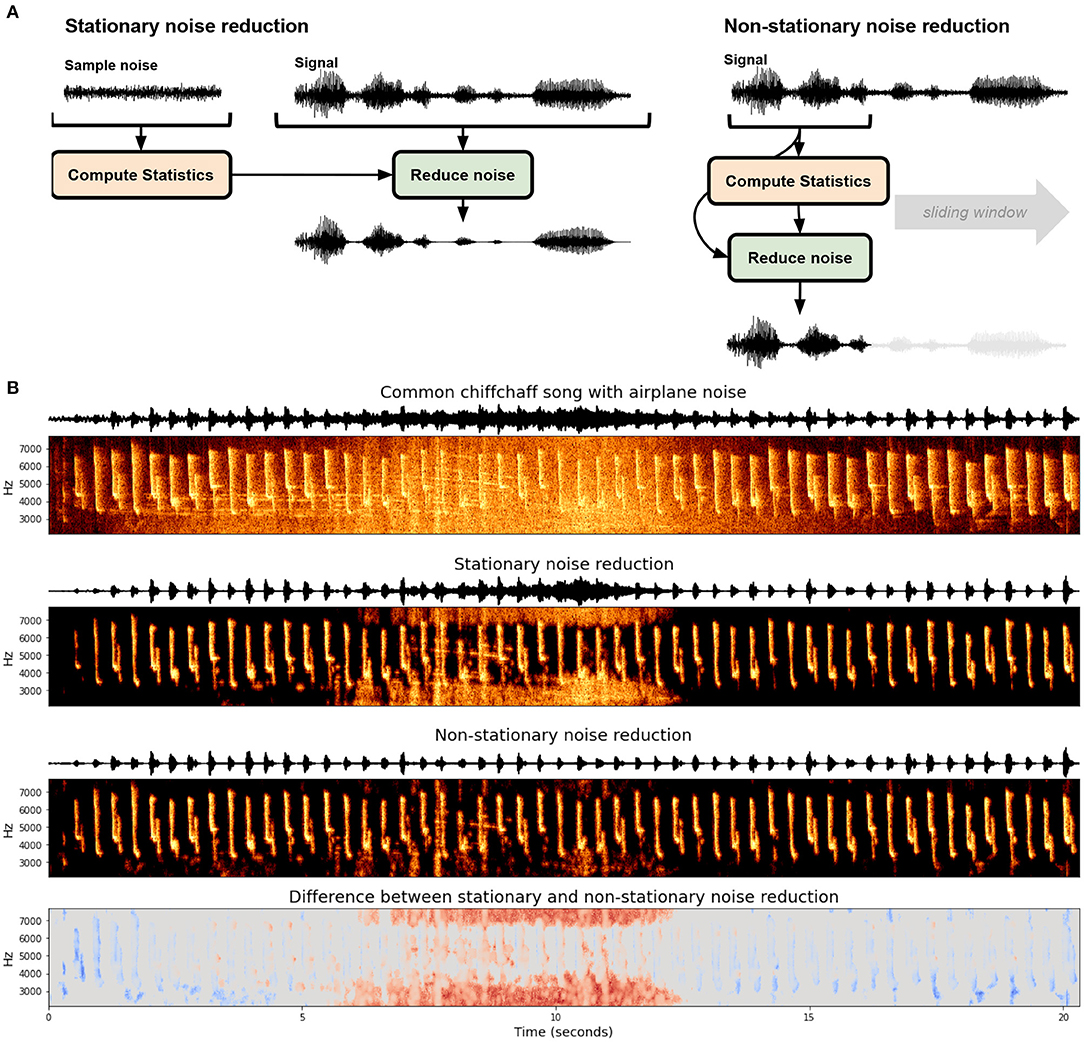
定常ノイズ低減と非定常ノイズ低減の選択
定常ノイズ低減と非定常ノイズ低減については、この論文で詳しく解説しています。
referred from https://github.com/timsainb/noisereduce図の説明: 定常および非定常スペクトルゲーティングによるノイズ低減。(A) 各アルゴリズムの概要。定常ノイズ低減は通常、統計を計算するための明確なノイズ信号を入力として受け取り、信号全体に均一にノイズ低減を適用します。一方、非定常ノイズ低減は、動的にノイズを推定し同時に低減を行います。(B) Noisereduce Pythonパッケージ(Sainburg, 2019)を使用して、飛行機ノイズをバックグラウンドに含むヨーロッパウグイス(Phylloscopus collybita)の歌(Stowellら、2019)に対して適用した場合の結果。下部の枠は、2つのアルゴリズムの違いを示しています。
サンプルのノートブックが3つ用意されている
基本的な使い方だと思う
"Parallel computing example"とあるが、似たようなことは上のノートブックでもやっていて、どうもPyTorchベースの内部処理を使う、というのが上との違いに思える。(ノートブックのタイトルもそうなってるし)
PyTorchのnn.Moduleを使ったサンプル
とりあえず基本的な使い方は最初のものを見ればいいと思うので、それで進める。
Colaboratory T4で。
パッケージインストール
!pip install librosa soundfile noisereduce
!pip freeze | egrep -i "librosa|soundfile|noisereduce"
librosa==0.10.2.post1
noisereduce==3.0.3
soundfile==0.13.0
サンプルで用意されているWAVファイルをダウンロード。44100Hzで4秒程度のWAVファイル。
import urllib.request
import soundfile as sf
import io
url = "https://raw.githubusercontent.com/timsainb/noisereduce/master/assets/fish.wav"
response = urllib.request.urlopen(url)
data, rate = sf.read(io.BytesIO(response.read()))
以下で再生確認できる。男性の演説っぽい音声で、"I know the human being and fish can coexist peacefully." と発話されている。背景に環境音などは特にない。
import IPython
IPython.display.Audio(data=data, rate=rate)
matplotlibで波形を可視化

ノイズリダクションの確認のために、あえてノイズを追加する。noisereduceにはノイズを追加する関数も用意されている。
from noisereduce.generate_noise import band_limited_noise
noise_len = 2 # 秒
noise = band_limited_noise(min_freq=2000, max_freq = 12000, samples=len(data), samplerate=rate)*10
noise_clip = noise[:rate*noise_len]
audio_clip_band_limited = data+noise
ノイズを追加したオーディオの波形。波が小さいところが上よりも太くなっているのがわかる。実際には「サー」というホワイトノイズっぽい音がずっと鳴っている状態。

再生して確認するとよくわかる。
IPython.display.Audio(data=audio_clip_band_limited, rate=rate)
これからノイズを削除する。ノイズの削除には2つのアルゴリズムがある。
-
定常ノイズ低減(Stationary Noise Reduction)
- 信号中のノイズの特徴を 「一定のもの」 として扱う。
- ノイズの量や性質が時間とともに変化しない場合に有効。
- 例:
- 周囲が常に同じ背景音(例えば、エアコンの音)である環境で録音された音声。
- 一度ノイズのレベルを決めたら、そのルールを継続して使用する。
- ポイント: 録音全体で同じ基準を使ってノイズを除去する
-
非定常ノイズ低減(Non-Stationary Noise Reduction)
- 信号中のノイズの特徴が 「時間とともに変わるもの」 として扱う。
- ノイズが時間とともに変動する場合に有効。
- 例:
- 鳥の鳴き声の中にたまに聞こえる飛行機の音。
- ノイズの状況に応じて、その都度新しいルールを作ってノイズを除去する。
- ポイント: 録音中に変化するノイズをリアルタイムで追いかけながら処理する
作成したノイズ入り音声データに対してそれぞれを実行してみる。まず、定常ノイズ低減。
import noisereduce as nr
stationaly_reduced_noise = nr.reduce_noise(
y = audio_clip_band_limited, # 入力信号
sr=rate, # サンプリングレート
n_std_thresh_stationary=1.5, # 定常ノイズ低減でのノイズと信号を区別する閾値(標準偏差の数)
stationary=True # 定常ノイズ低減を使用
)
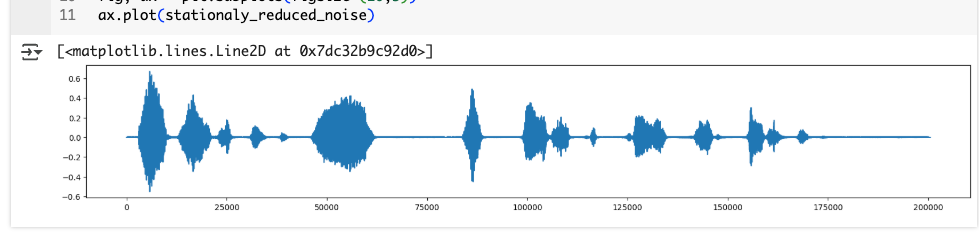
fig, ax = plt.subplots(figsize=(20,3))
ax.plot(stationaly_reduced_noise)
ノイズ追加時に太くなった部分が全体的に細くなっているのがわかる。
実際に聞いてみると、追加したノイズは確かに削減されているが、音声自体もややキンキンとした感じになっているのがわかる。
IPython.display.Audio(data=stationaly_reduced_noise, rate=rate)
次に非定常ノイズ低減。
non_stationaly_reduced_noise = nr.reduce_noise(
y = audio_clip_band_limited,
sr=rate,
thresh_n_mult_nonstationary=2, # 非定常ノイズ低減でのノイズ閾値のスケーリング係数
stationary=False # 定常ノイズ低減を使用しない=非定常ノイズ低減を使用
)
fig, ax = plt.subplots(figsize=(20,3))
ax.plot(non_stationaly_reduced_noise)
こちらも波形を見ると同じようにノイズが削減されているように見える。

ただ実際に聞いてみると、こちらのほうが定常ノイズ低減よりも聞き取りやすく感じる。波形にも少し現れているが、定常ノイズ低減の方は削減すべきではない音声も少し削除されてしまっているような印象を受けた。定常ノイズ低減の場合、パラメータにしたがって一定で削減するようなので、パラメータを変えると変わってくるかもしれない。
IPython.display.Audio(data=non_stationaly_reduced_noise, rate=rate)
このあたりは、元の音声データの特性に合わせつつも、実際に試して確認するのが良さそう。でもってこのノイズ削除済み音声データを、人間が聞くのか、何かしら別のものに食わせるのか、によっても変わってくると思う。そのあたりはやはり実際に評価してみることになるかな。
更に難しい例。上で使用したサンプルの音声に、環境音(カフェ内の音)を追加して、ノイズ削減してみる。
環境音の音声データを取得
url = "https://raw.githubusercontent.com/timsainb/noisereduce/master/assets/cafe_short.wav"
response = urllib.request.urlopen(url)
noise_data, noise_rate = sf.read(io.BytesIO(response.read()))
環境音の波形
fig, ax = plt.subplots(figsize=(20,4))
ax.plot(noise_data)

実際に聞いてみるとわかるのだが、カフェと言っても静かなカフェではなく、結構ノイジーな環境。
IPython.display.Audio(data=noise_data, rate=noise_rate)
最初の発話データとこの環境音をミックスする。
snr = 2 # シグナル・ノイズ比
noise_clip = noise_data/snr
audio_clip_cafe = data + noise_clip
波形を見てみる
fig, ax = plt.subplots(figsize=(20,4))
ax.plot(audio_clip_cafe)
IPython.display.Audio(data=audio_clip_cafe, rate=noise_rate)
上でノイズを追加したときと同じように、波が小さいところが太くなっているのがわかる。

では定常ノイズ低減。あらかじめノイズの特徴が特定できている場合はy_noiseで指定するとそれを踏まえてノイズ低減される。
stationary_reduced_noise_cafe = nr.reduce_noise(
y = audio_clip_cafe,
sr=rate,
y_noise = noise_clip, # ノイズの特徴を計算するための信号データ
n_std_thresh_stationary=1.5,
stationary=True
)
波形データを見てみる。今回は環境音入りのデータと定常ノイズ低減したデータを両方プロットしている。
fig, ax = plt.subplots(figsize=(20,3))
ax.plot(audio_clip_cafe)
ax.plot(stationary_reduced_noise_cafe)
オレンジが定常ノイズ低減された音声データ、つまり、ブルーの部分が低減されたノイズということになる。
実際に聞いてみると、環境音が取り除かれているのがわかる。
IPython.display.Audio(data=stationary_reduced_noise_cafe, rate=rate)
ただ、ちょっとよくわからないのは、ドキュメントには以下とあり、非定常ノイズ低減のみというような記述に読める
y_noise : np.ndarray [shape=(# frames,) or (# channels, # frames)], real-valued
noise signal to compute statistics over (only for non-stationary noise reduction).
stationaryとnon-stationaryのコードはおそらく以下
これを見ると、y_noiseは定常ノイズ低減の場合でのみ参照されいるので、ドキュメントの記載がまちがっているのではないだろうか?
ノートブックでは非定常ノイズ低減の場合はy_noiseは使用されていない。
non_stationary_reduced_noise_cafe = nr.reduce_noise(
y=audio_clip_cafe,
sr=rate,
thresh_n_mult_nonstationary=2,
stationary=False
)
波形と再生
fig, ax = plt.subplots(figsize=(20,3))
ax.plot(audio_clip_cafe)
ax.plot(non_stationary_reduced_noise_cafe, alpha = 1)
IPython.display.Audio(data=non_stationary_reduced_noise_cafe, rate=rate)

こちらのほうがノイズを多く低減しているように見える。ただ、実際に聞いてみても、多少そういう感はあるかなぁ、というぐらい。自分の耳では違いがわからなかった。その意味では波形データで可視化するのは重要だな。
prop_decreaseでノイズ低減の強度を設定できる。
prop_decrease : float, optional
The proportion to reduce the noise by (1.0 = 100%), by default 1.0
で、これを0にした場合、ノイズ低減は行われず、元の信号に対して歪みが引き起こさないことが保証される、らしい。
noise_reduced_prop_decrease_0 = nr.reduce_noise(
y=data,
sr=rate,
prop_decrease=0,
stationary=False
)
fig, ax = plt.subplots(nrows=2, figsize=(20,3))
ax[0].plot(noise_reduced_prop_decrease_0)
ax[1].plot(data)
fig, ax = plt.subplots(nrows=2, figsize=(20,3))
ax[0].plot(noise_reduced_prop_decrease_0[3000:5000])
ax[1].plot(data[3000:5000])

ほぼ影響しないと考えて良さそう(数値的誤差はあるので、全く同一というわけではない)
長い音声データの場合、これを分割して並列でノイズ低減を行うことにより、パフォーマンス向上を図れる可能性がある、ということだと思う。
元の音声データを10回繰り返して10倍の長さにする。
long_data = np.tile(data, 10)
print(len(long_data)/rate)
fig, ax = plt.subplots(figsize=(20,4))
ax.plot(long_data)
IPython.display.Audio(data=long_data, rate=rate)
約45秒

これにノイズを被せる
noise = band_limited_noise(min_freq=2000, max_freq = 12000, samples=len(long_data), samplerate=rate)*10
audio_clip_band_limited = long_data+noise
fig, ax = plt.subplots(figsize=(20,3))
ax.plot(audio_clip_band_limited)
IPython.display.Audio(data=audio_clip_band_limited, rate=rate)

以下のようにn_jobsを指定する
non_stationary_reduced_noise_with_parallel = nr.reduce_noise(
y=audio_clip_band_limited,
sr=rate,
thresh_n_mult_nonstationary=2,
stationary=False,
n_jobs=2, # 並列処理に使用するスレッド数
)
fig, ax = plt.subplots(figsize=(20,3))
ax.plot(audio_clip_band_limited)
ax.plot(non_stationary_reduced_noise_with_parallel)
IPython.display.Audio(data=non_stationary_reduced_noise_with_parallel, rate=rate)

これぐらいの長さだとあまり効果を感じないかも。
その他ノートブックには
- 長い音声データの途中の一部分だけノイズ低減する
- マルチチャネルのノイズを低減する
といった例も書かれている。
まとめ
地味ではあるが、環境によってはこういうものが必要になるケースはありそう。個人的に、ノイズを低減するだけじゃなくて、ノイズを追加する処理も用意されているのは、評価やテストなどでも役に立つと思うので良いと思った。