aiOlaの高精度なASRモデル「Jargonic V2」
ここで見かけた
公式ブログ
ざっくり要約
- 2025年5月発表のJargonic V2が日本語ASRで新基準
- ひらがな・カタカナ・漢字が混在、空白での区切りなし、敬語・助数詞で音が変わる、という日本語におけるASRの難しさを克服
- CommonVoice v13/ReazonSpeechでCER最大50%改善、OpenAI(Whisper large-v3)・ElevenLabs(Scribe)・AssemblyAI(Best)・Deepgram(Nova 2)を圧倒
- KWS搭載で業界固有語を94.7%リアルタイム検出、追加学習不要
早速試してみようと思ったが、Waitlistらしい。
以下でWaitlistに登録できるようなのでとりあえず登録してみた
使えるようになったら試してみたい。
登録後にメールが来て、Early Accessが許可された。提供されたものは以下。
- 14日間の期限付きSpeech-to−Text・Text-to-Speech無制限利用
- APIエンドポイント・APIキー
- SDKのURL(JavaScript)
うーん、JSかー。最近あんまり触ってないのよな・・・
できればPythonで書きたい、ということで、GitHubレポジトリを調べてみたらPython SDKがある。
aiOla Python SDKs
aiOla Python SDKs リポジトリへようこそ。このリポジトリには、aiOla の Text-to-Speech (TTS) およびストリーミングサービスと統合する各種 SDK のサンプルとドキュメントが含まれています。
サンプルの概要
aiOla Streaming SDK
1. トランスクリプト & イベントのサンプル
このサンプルは、aiOla Streaming SDK を使用してライブトランスクリプトを取得し、バックエンドでトリガーされたイベントを処理する方法を示しています。
- 主な特徴:
- リアルタイム音声書き起こし
- イベント駆動型コールバック
- 内蔵 / 外部マイク
2. キーワードスポッティングのサンプル
このサンプルでは、aiOla Streaming SDK を用いてキーワードスポッティングを設定する方法を示します。
- 主な特徴:
- ライブストリームで事前定義キーワードを検出
- イベント駆動型のキーワードマッチング
3. 対応言語
en-EN, de-DE, fr-FR, zh-ZH, es-ES, pt-PT
んー、STTの方は対応言語に日本語が含まれていないなあ・・・・
aiOla TTS SDK
3. 音声合成サンプル
このサンプルは、aiOla TTS SDK を使用してテキストを音声に変換し、生成された音声ファイルをダウンロードする方法を示します。
- 主な特徴:
- テキストを
.wav音声ファイルに変換- ボイス選択をサポート
4. スピーチストリーミングサンプル
このサンプルでは、リアルタイムにテキスト-トゥ-スピーチをストリーミングし、テキスト全体の処理前に音声再生を開始する方法を示します。
- 主な特徴:
- リアルタイムの TTS ストリーミング
- 即時の音声再生
TTSについてはサービスの内容そのものをあんまり調べてないなぁ・・・
JavaScriptというかTypeScriptのほうは、パッケージは2つに分かれているけど、レポジトリは同じ。
Aiola JavaScript SDK
このリポジトリには、Aiola の音声サービス向け公式 JavaScript/TypeScript SDK が含まれています。
サンプルアプリの実行
開発サーバを起動
npm run serveブラウザでサンプルディレクトリへアクセス
- STT 例:
http://localhost:3000/examples/stt- TTS 例:
http://localhost:3000/examples/tts
お、とりあえずサンプルアプリがあるみたい。まずはこれを試してみる。
レポジトリクローン
git clone https://github.com/aiola-lab/aiola-ts-client-sdk && cd aiola-ts-client-sdk
miseでnode.js-22を使用
mise use node@22
STT・TTSのサンプルアプリの本体はexamples以下にあり、それぞれパッケージのインストールおよびAPIキー等の設定が必要になる。
tree examples/
examples/
├── package-lock.json
├── package.json
├── stt-demo
│ ├── LICENSE
│ ├── README.md
│ ├── app-screenshot.png
│ ├── favicon.ico
│ ├── index.html
│ ├── package-lock.json
│ ├── package.json
│ ├── script.js
│ └── styles.css
└── tts-demo
├── LICENSE
├── README.md
├── favicon.ico
├── index.html
├── main.js
├── package-lock.json
├── package.json
└── styles.css
3 directories, 19 files
まずexamplesディレクトリに移動
cd examples
ここでHTTPサーバをインストール
npm install
次にSTTのディレクトリに移動。
cd stt-demo
ここでSTTのパッケージをインストールするのだが、
npm install
エラー
npm error code E401
npm error Incorrect or missing password.
npm error If you were trying to login, change your password, create an
npm error authentication token or enable two-factor authentication then
npm error that means you likely typed your password in incorrectly.
npm error Please try again, or recover your password at:
npm error https://www.npmjs.com/forgot
npm error
npm error If you were doing some other operation then your saved credentials are
npm error probably out of date. To correct this please try logging in again with:
npm error npm login
npm error A complete log of this run can be found in: /Users/kun432/.npm/_logs/2025-05-15T14_03_19_496Z-debug-0.log
どうもpackage-lock.jsonにプライベートレポジトリが含まれているみたい。一旦package-lock.jsonを削除してインストールすれば良い。
rm package-lock.json
npm install
で、APIエンドポイントとAPIキーをセットする。STTの場合はscript.jsにセットする。
(snip)
const baseUrl = "<BASE_URL>";
const bearer = "<BEARER>";
const flowId = "<FLOW_ID>";
const executionId = "<EXECUTION_ID>";
const langCode = "<LANG_CODE>";
const timeZone = "<TIME_ZONE>";
(snip)
-
baseUrl: メールで送られてきたAPIエンドポイントを指定 -
bearer: メールで送られてきたAPIキーを指定 -
flowId: フローIDが何を指しているのかわからないけど、これもメールで送られているのでそれを指定 -
executionId: これもちょっとよくわからない。 とりあえずtestとした -
langCode:ja_JP -
timeZone:Asia/Tokyo
次にTTSのディレクトリに移動。
cd ../tts-demo
こちらもpackage-lock.jsonを削除してTTSのパッケージをインストール。
rm package-lock.json
npm install
TTSのAPIキー等のセットはmain.jsで行う。
const client = new AiolaTTSClient({
baseUrl: "<BASE_URL>",
bearer: "<BEARER>"
});
-
baseUrl: メールで送られてきたAPIエンドポイントを指定 -
bearer: メールで送られてきたAPIキーを指定
ではサンプルアプリを起動を起動する。examplesディレクトリに戻って、HTTPサーバを起動
npm run serve
> aiola-js-sdk-examples@1.0.0 start
> http-server -p 3000 -c-1 ..
Starting up http-server, serving ..
http-server version: 14.1.1
http-server settings:
CORS: disabled
Cache: -1 seconds
Connection Timeout: 120 seconds
Directory Listings: visible
AutoIndex: visible
Serve GZIP Files: false
Serve Brotli Files: false
Default File Extension: none
Available on:
http://127.0.0.1:3000
http://192.168.XX.XX:3000
http://192.168.XX.X:3000
Hit CTRL-C to stop the server
ブラウザを開いてアクセス。マイクを使うのでlocalhost(127.0.0.1:3000)が良いと思う。STT・TTSそれぞれのURLは以下となる。
- STT:
http://127.0.0.1:3000/examples/stt-demo/ - TTS:
http://127.0.0.1:3000/examples/tts-demo/
まずSTT。こんな画面が開く。

多分左が「接続」で右が「マイクON」だよね。両方有効にする。
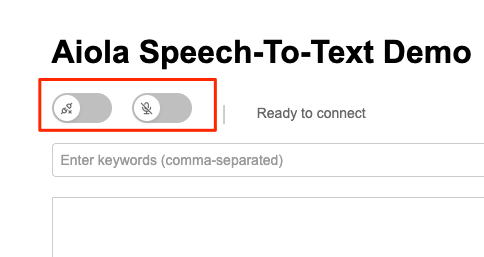
あとはマイクに話しかければリアルタイムで文字起こししてくれる。こんな感じ。
次にTTS。こういう画面。
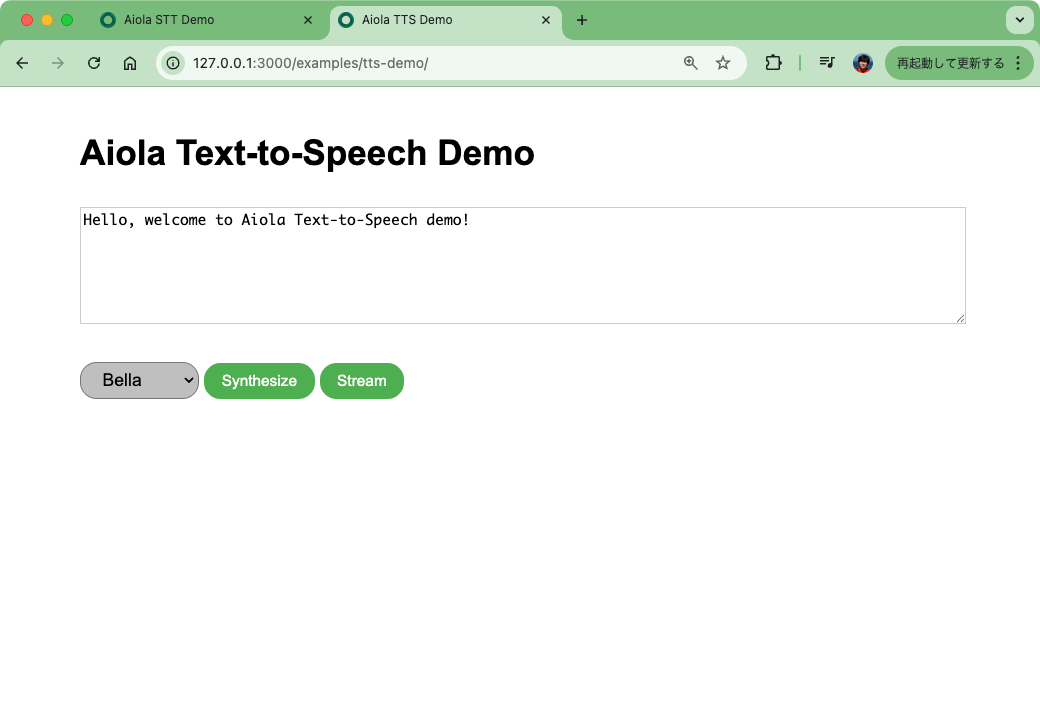
とりあえずデフォルトで生成させてみる。「Synthesize」をクリックすると・・・
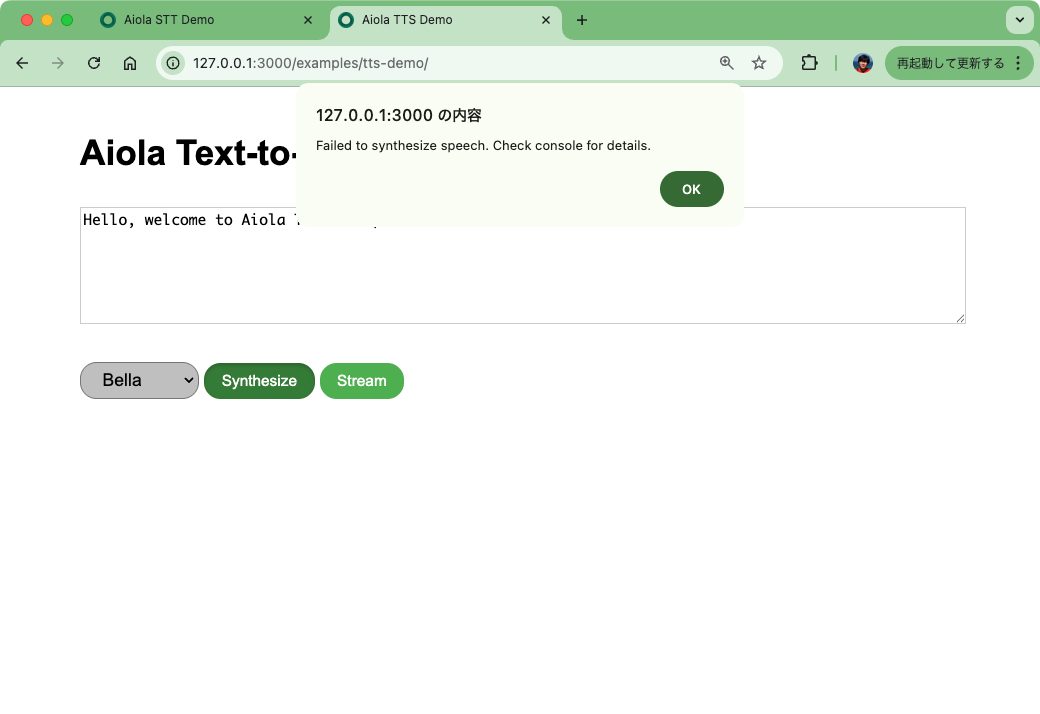
エラー・・・developer toolのコンソールを開くと、APIを叩くところで422 Unprocessable Contentになっているみたい。

音声変えても"Stream"でやってみても同じ。コードも見てみたけど、ちょっとよくわからない。
Python SDKを試してみる。更新時間を見る限りは一番新しそう&若そう。
今回はレポジトリから。
git clone https://github.com/aiola-lab/aiola-python-sdk && cd aiola-python-sdk
ビルド用のスクリプトが用意されている。
ざっと見た感じ
- Python仮想環境を作成して有効化
- ローカルから、aiola_stt・aiola_ttsパッケージをインストール
- デモを動かすのに必要な他のパッケージをインストール
という感じに見えるので、これを実行。
. ./build_and_play.sh
インストールが終わるのを待つ
Progress: [##########################--------------] 66% (4/6)
--> Installing aiOla_tts
仮想環境に入った状態で、完了する。
--> DONE
===== aiOla sdk is ready for playing, enjoy! =====
Hey, try running STT example 'python examples/stt/default_audio_stream_auto_record.py' to get started!
Hey, try running TTS example 'python examples/tts/synthesize.py' to get started!
で、サンプルコード。以下の5ファイルが用意されている。
examples
├── stt
│ ├── custom_audio_stream.py
│ ├── default_audio_stream_auto_record.py
│ └── default_audio_stream_lazy_record.py
└── tts
├── synthesize.py
└── synthesize_stream.py
-
STT
-
default_audio_stream_auto_record.py:- デフォルトのオーディオストリーム(マイク入力)を利用して音声認識を行う例
-
default_audio_stream_lazy_record.py:- デフォルトのオーディオストリームを利用するが、録音開始は明示的に
client.start_recording()を呼び出して開始する遅延録音の例
- デフォルトのオーディオストリームを利用するが、録音開始は明示的に
-
custom_audio_stream.py:- カスタムオーディオストリーム(この例では
wav_sample.wavファイルから読み込み)を利用して音声認識を行う例。
- カスタムオーディオストリーム(この例では
-
-
TTS
-
synthesize.py:- テキストから音声を合成し、
.wavファイルとして保存する基本的な例
- テキストから音声を合成し、
-
synthesize_stream.py- テキストから音声をストリーミングで合成し、
.wavファイルとして保存する例
- テキストから音声をストリーミングで合成し、
-
という感じ。各コードにはAPIキーがハードコード(プレイグラウンド用で実際に使えるが利用回数が限定されているみたい)されているので、これを書き換える必要はありそう。いくつかピックアップして試す。
STT: custom_audio_stream.py
オーディオファイルからの文字起こし。これなら他のSTTとの比較に使えそう。以前も使ったけど、自分が開催した勉強会のYouTube動画から冒頭5分程度の音声を抜き出したオーディオファイルをサンプルとして使う。
custom_audio_stream.pyの以下の箇所を修正する。(コメントなどは省略してる)
使用するファイル名を変更
(snip)
async def audio_stream_handler() -> AsyncGenerator[bytes, None]:
script_dir = os.path.dirname(os.path.abspath(__file__))
wav_path = os.path.join(script_dir, 'my_sample.wav') # 自分のサンプル音声ファイルに変更
(snip)
APIキー等の設定。レポジトリのサンプルコードでは、JSサンプルで使用したフローIDがセットされておらず、そのままだとエラーになるので追加した。
(snip)
async def main():
logger.info("Starting main application")
keywords_input = input("Enter keywords to spot (comma-separated): ")
keywords = [k.strip() for k in keywords_input.split(",") if k.strip()]
# 何でも良い
execution_id_example = "1t2e3m4p"
# 元々のトークンでも使えるが回数制限がある様子。もらったAPIキーに書き換え。
api_key = "XXXXXXXXXX"
# フローIDがないとエラーになるので追加
flow_id = "YYYYYYYYYY"
config = AiolaConfig(
api_key=api_key,
query_params=AiolaQueryParams(
execution_id=execution_id_example,
# 以下の3行を追加
flow_id=flow_id,
lang_code="ja_JP",
time_zone="Asia/Tokyo"
),
events={
"on_connect": on_connect,
"on_disconnect": on_disconnect,
"on_transcript": on_transcript,
"on_events": on_events,
"on_error": on_error
}
)
(snip)
実行
python examples/stt/custom_audio_stream.py
実行するとキーワードスポッティングのキーワード入力を求められる。例えば、一般的に認識されにくい専門用語などを登録しておくと認識率が上がるというものらしい。今回は登録せずにそのままENTERで進める。
Starting application
Starting main application
Enter keywords to spot (comma-separated):
以下のように文字起こしされる。どうやらデフォルトでVADが設定されているみたい。
VAD config is set
Connection parameters: {'execution_id': '1t2e3m4p', 'flow_id': 'XXXXXXXXXX', 'lang_code': 'ja_JP', 'time_zone': 'Asia/Tokyo', 'vad_config': '{"vad_threshold": 0.5, "min_silence_duration_ms": 250}'}
Connection established
Starting recording with custom audio stream
Application is running. Press Ctrl+C to exit.
Audio streaming stopped. Total chunks sent: 1050
Transcript: はい、じゃあ始めます。ちょっとまだ来られてない方もいらっしゃるんですけど。
Transcript: ポイスランチュー。JP始めます。
Transcript: アメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカのアメリカの
Transcript: アイス。
Transcript: はい日曜日にお集まりいただきましてありがとうございますえっと今日久しぶりにですねオフラインということでえっと今日はですねスペシャルなゲストをお二人
Transcript: いただいておりますということで
Transcript: はい今日ちょっとトピックに回りますけれどもボイスローの CEO であるレデンリムさんとあとセールスフォースのカムセジョナルデザインのディレクターであるグレイクベネスさんに来ていただいてます
Transcript: ということで、日本に来ていただいてありがとうございました。
Transcript: はい。
Transcript: で今日はちょっとこのお二人にまた後で色々と聞こうというコーナーがありますのでそこでまた色々と聞きたいと思いますで今日のアジェンダなんですけどもちょっと時間過ぎちゃいましたがまず最初にボイスランチjpについてというところとあと会場のところですね少し
Transcript: ご説明させていただいて一つ目のセッションでまず私の方からvoi soloの二千二十二年の新機能とかですねその辺の話を少しさせていただいてその後二つ目のセッションでグレディさんとグレディさんにいろいろカンバセーショナルデザインですねについて何でも聞こうぜみたいなところを予定しておりますその
Transcript: からえっと十五時で一端は終了という形でさせていただいてちょっと一応ボイスランティレピータースか記念撮影は必須ですよねなのでそれだけさせていただいてそのあとちょっと一時間ぐらいあの簡単にあのお菓子と飲み物を用意してますので懇親会というのをそのままさせていただこうと思っています
Transcript: ボイスランキー・JPについてですけれども、
Transcript: voice launchはvoice uiとか音声関連ですねそういった技術に実際に携わっている人もしくは興味がある人そっちのためのグローバルなコミュニティという形になっていてvoice launchの
Transcript: 日本リージョンという形がボイスランチJPになっています。で、過去もずっとやってますけど、オンラインオフラインでいろんな音声。
Transcript: デザインだったり技術だったりというところで情報とかを共有してみんなで業界盛り上げていこうぜというようなことでやっております今日のハッシュタグですね
Transcript: してください
Transcript: であと会場ですねえっと今回えっとグラニカ様のお声で利用させていただいてますありがとうございますでぜひこちらもシェアをお願いしたいですとで今日と配信のところもいろいろとやっていただいてますって非常に感謝しておりますでちょっと今あのごめんなさい
Transcript: ヴィッタ。
Transcript: 今あのえっとコロナでえっと会場に来られる方とかもうあまりいないということでされてないんですけれどもあの
Transcript: はなく こう で iot 機器 の とか ガジェット とか を 展示 され ている よう な の で えっと そう いった もの が ある とき 今今度 です ね また 体験 し てみ て いただけ れば な と 思っ て い ます と
Transcript: というとこで、あと、すいません、えっと、トイレが。
Transcript: で、あと、煙草吸われる方はこちらのところになってますので、よろしくお願いします。
Transcript: はい、ということで、最初の挨拶はこれで。
Transcript: じゃあまず私の方のセッションから。
Transcript: 分けていただきますというところで、ボイスローアップデート二千二十二と。
Transcript: というところで今年の新知能について少しお話をします自己紹介です清水と申します神戸でインフラのエンジニアをやってますので普段はクバネ鉄とかエダベスとかテラホーンとか
Transcript: をいじってまして最近ちょっとフリーランスになります。
Transcript: ちょっと調べてみたら、ボイスフロー一番最初に始めたのは二千十九年の朝もぐらいなので、大体四年弱ぐらいですね。色々と触ってまして。
Transcript: 音声関連のコミュニティのところでは、ボイスランチJP以外に、AJAG、Amazon、Alexa、Japan User Group、
Transcript: とか、あと、ボイスローの日本語ユーザーグループということで、VFJUJというのをやっています。
Transcript: 日本コミュニティの方はフェイスブックの方でやっていますので、もしよろしければ。
Transcript: 見ていただければなぁと思います。
Transcript: あと二年ぐらい前にですねえっと技術書店の方でここに今日スタッフで聞いていただいている皆さんとですね一緒にあの同人誌作ろうぜということでえっと作ったんですけれどももうこれちょっと二年ぐらい経って中身がだいぶ古くなってしまっているのですでにちょっと販売は終了しております今日ちょっと持ってきたかったんですけどストレスで忘れてしまいました
Transcript: はい、なのでこういうこともやっています。
だいたい20秒ぐらいかな。文字起こしの結果としては、固有名詞っぽいキーワードもある程度は正しく認識されていたりもするし、悪くはないかなぁというところであるんだけども、ガッツリハルシネーションしてるところもあるし、あとVADのせいかもしれないけどちょっと抜け落ちてるところもあるね。デフォルトだとElevenLabsのScribeに比べるとやや劣る印象
参考
ということで、キーワードスポッティングの設定を行って認識率を上げてみる。起動時に以下の単語を登録する。
- VoiceLunch JP
- VoiceFlow
- AWS
- Terraform
- Kubernetes
- 技術書典
Enter keywords to spot (comma-separated): VoiceLunch JP,VoiceFlow,AWS,Kubernetes,技術書典
あと、VADもなるべく細切れにならないように、かつ弱めになるように、以下のような設定を追加してみた。
少し設定をいじってみる。VADの設定はデフォルトでかかるようになっていて、閾値0.5(多分高いほど小さな音を無音と判定するのだと推測)・無音とみなす区間の最小は250msになっている。この最小の無音区間を少し伸ばしてみる。
(snip)
# VadConfigを追加
from aiola_stt import AiolaSttClient, AiolaConfig, AiolaQueryParams, VadConfig
(snip)
config = AiolaConfig(
api_key=api_key,
query_params=AiolaQueryParams(
execution_id=execution_id_example,
flow_id=flow_id,
lang_code="ja_JP",
time_zone="Asia/Tokyo"
),
# VADを明示的に設定
vad_config=VadConfig(
vad_threshold=0.5,
min_silence_duration_ms=500
),
(snip)
結果
Transcript: はい、じゃあ始めます。ちょっとまだ来られてない方もいらっしゃるんですけど。
Transcript: ポイントランチでエピー始めます。皆さん見ております。はーい。
End of stream. Press Ctrl+C to exit.
Transcript: はい日曜日にお集まりいただき ましてありがとうございます今日久しぶりにですねオフライン ということで今日はですねスペシャルなゲストをお二人来ていただいて おりますということで今日ちょっとトピックに回ります けれどもボイスローの CEO であるレデンリムさんとあとセールスフォースのカムセジョナルデザイン のディレクターであるグ
Transcript: いただいてまーす
Transcript: ということで、日本に来ていただいてありがとうございました。
Transcript: はい。
Transcript: 今日はちょっとこのお二人にまた後で色々と聞こうというコーナーがありますのでそこでまた色々と聞きたいと思いますで今日のアジェンダなんですけどもちょっと時間過ぎちゃいましたがまず最初にVoiceLunch JPについてというところとあと解像のところですね少しご説明させていただいて一つ目のセッションでまず私の方から
Transcript: 新機能とかですねその辺の話を少しさせていただいてその後二つ目のセッションでグレイデンさんとグレイドさんにいろいろカンバセーショナルデザインですねについて何でも聞こうぜみたいなところを予定しておりますその後
Transcript: 15時から15時で一旦終了という形でさせていただいてちょっと一応VoiceLunch JP確か記念撮影は必須ですよねなのでそれだけさせていただいてその後ちょっと一時間ぐらい簡単にお菓子と飲み物を用意してますので懇親会というのをそのままさせていただこうと思っていますでVoiceLunch JPについてなんですけどもVoiceLunchはボ
Transcript: ですねそういった技術に実際に携わっている人もしくは興味がある人そっちのためのグローバルなコミュニティという形になっていてvoiceLunchの日本リージョンという形がvoiceLunch JPになっていますとで過去もずっとやってますけどオンラインオフラインでいろんな音声のデザインだったり技術だったりという
Transcript: 今日のハッシュダウルですね。#voiceLunch JPで色々と自由に出演してください。
Transcript: であと会場ですね今回グラニカ様のお声で利用させていただいてますありがとうございますぜひこちらもシェアをお願いしたいですとで今日と配信のところもいろいろとやっていただいてますって非常に感謝しておりますでちょっと今あのごめんなさい抜けた今コロナで会場に来られる方とかもうあまりいないということでされてないんですけれども通常はなんかこうでiot機器
Transcript: とかガジェットとかを展示されているようなのでそういったものがあるとき今度ですねまた体験してみていただければなと思っていますというところであとすいませんトイレがこちらであと茶箱座れる方はこちらのところになってますのでよろしくお願いしますはいということで最初の挨拶はこれで
Transcript: じゃあまず私の方のセッションから。
Transcript: させていただきますというところでボイスフローアップデートというところで今年の新機能について少しお話をします自己紹介です清水と申します神戸でインフラのエンジニアをやってますので普段はクバネテスとかエダベスとかテラフォンとかをいじってまして最近ちょっとフリーランスになりましたちょっと調べてみたらボイ
Transcript: の朝目ぐらいなんで大体四年弱ぐらいですね色々と触ってましてあと音声関連のコミュニティのとこではvoiceLunch JP今回のやつですね以外にエイジャグアマゾンアレクサジャパンユーザーグループ
Transcript: 他、あと、ボイスローの日本語ユーザーグループということでVFJUGというのをやっています。
Transcript: 日本コミュニティの方はフェイスブックの方でやってますので、もしよろしければ見ていただければなと思います。
最初に比べると多少マシかなぁというところ。キーワードも効いてるとこもあれば効いてないところもあったり、逆に途中で切れちゃったりしてるところもあって、このあたりはチューニングが必要な感じかな。
STT: default_audio_stream_auto_record.py
マイクからの音声をリアルタイムに文字起こしするサンプル。これもAPIキーの設定等で修正が必要。
(snip)
async def main():
keywords_input = input("Enter keywords to spot (comma-separated): ")
keywords = [k.strip() for k in keywords_input.split(",") if k.strip()]
execution_id_example = "test"
api_key = "XXXXXXXXXX"
flow_id = "YYYYYYYYYY"
config = AiolaConfig(
api_key=api_key,
query_params=AiolaQueryParams(
execution_id=execution_id_example,
flow_id=flow_id,
lang_code="ja_JP",
time_zone="Asia/Tokyo"
),
events={
"on_connect": on_connect,
"on_disconnect": on_disconnect,
"on_transcript": on_transcript,
"on_events": on_events,
"on_error": on_error
}
)
(snip)
実行
python examples/stt/default_audio_stream_auto_record.py
こちらもキーワードスポッティングの設定ができるが、スキップ。
Starting application
Starting main application
Enter keywords to spot (comma-separated):
以下のように表示されたらマイクで発話する。
VAD config is set
Connection parameters: {'execution_id': 'test', 'flow_id': 'YYYYYYYYYY, 'lang_code': 'ja_JP', 'time_zone': 'Asia/Tokyo', 'vad_config': '{"vad_threshold": 0.5, "min_silence_duration_ms": 250}'}
Connection established
Application is running. Press Ctrl+C to exit.
Microphone is recording 🎤... (🛑Press Ctrl+C to exit)
こんな感じで文字起こしされる。
Transcript: Text-to-Speechのサンプルです。
Transcript: 今日も新幹線をご利用くださいましてありがとうございます。
Transcript: この電車は、望峰、東京行きです。
Transcript: 途中の停車駅は
Transcript: 京都:名古屋。
Transcript: 横浜、品川です。
TTS: default_audio_stream_auto_record.py
TTS。シンプルにテキストから音声を生成してWAVファイルに出力する。これはAPIキーをセットして、発話するテキストを設定するだけでOKのはずなんだけども・・・
(snip)
def main():
bearer_token = "YYYYYYYYYY"
tts_client = AiolaTtsClient(bearer_token=bearer_token)
try:
print("Synthesizing speech...")
text = 'こんにちは。今日はいいお天気ですね。'
(snip)
どうもここにもらったAPIキーをセットするとだめで、PlaygroundのAPIキーじゃないとエラーになる様子・・・
あと、日本語はダメみたいで、"Japanese letter Japanese letter ..." となってしまう様子。
TTSはおいといて、STTについては期待が高かっただけに、うーん、というところなのだけど・・・
ところで、AIolaのSpeech−to−Textのモデルは現行2つ、以前のモデルを加えると3つある様子。
Jargonicは、高精度と適応性を追求した最先端の多言語自動音声認識(ASR)システムです。異なる用途に対応するため、2つのバージョンをご用意しています:
Jargonic-v2: 当社で最も先進的なモデルで、音声からテキストへの変換アプリケーションにおいて最高精度を実現します。
Jargonic-v2-Flash: 低遅延アプリケーション向けに最適化された軽量版で、精度(WER)を若干犠牲にしながら、より高速な文字起こし速度を提供します。
Jargonic-v1: 当社ASRモデルの以前のバージョンで、高い精度と堅牢性を備えています。
で、SDK見ててもモデルを指定する箇所とかが見つからないのよね。自分の探し方が悪いっていう可能性はあるんだけども。
現状、どっちのモデルを使っているのかがわからない。リアルタイム文字起こしがそれなりに高速なところを見ると実は今試しているのはFlashの方だったって可能性はないかなぁ・・・・?
とりあえずドキュメントとか情報はほぼないに等しいので手間はかかるんだけど、コードを見る限りはスッキリわかりやすい印象。リアルタイムも書きやすいのでちょっと期待してる。
とりあえずEarly Access期間中はいろいろサポートも優先的にやってくれるみたいなので、上で詰まったところは質問投げておいたので、その回答を見て、続きをやる予定。
その他の機能について。ドキュメントにあるものをざっと。
文字起こしの内容の要約
文字起こしのコンテンツモデレーション
文字起こしから感情分析
文字起こしからエンティティの抽出。エンティティをあらかじめ決めることもできればお任せもできる
文字起こしからトピックの抽出
文字起こしの自動チャプター化。チャプターごとにタイトルと要約を付与。
文字起こしからキーフレーズの抽出
文字起こしから個人情報に関わる部分のマスク
サポートから回答をもらった。自分の質問に対して完全な回答はもらえていないのだが、概ねこんな感じ。
-
Q: ASRのモデルを選択できるか?SDK等でモデルを指定する箇所が見当たらない。
- A: 現在はできない。
-
Q: TTSで日本語には対応しているか?
- A:無料ユーザの場合は日本語は対応していない
TTSはどうやらKokoro TTSがベースになっているようで、日本語の音声名も"jf_alpha"らしい。ただプランとして無料ユーザには提供されていないということみたい。
ASRは現時点でモデル選択できない、じゃあ現在使用しているモデルはどれ?ということに尽きるんだよな。知りたいのは精度なので。
とりあえず追加質問は投げておいたけど、もう少しいろいろ情報出てきてから、かなぁ。
回答があった。Jargonic-v2とのこと。
うーん・・・ファイルからの推論とストリーミングの推論だと精度は変わってくると思うし、内部的な処理の違いなんかもあるとは思うので、単純な比較は難しいのかもしれないけど、少なくとも自分の試した範囲内だと、Scribeのほうが精度は良いかなぁというところ。
ただベンチマーク結果ではScribeを上回っているということなので、ソースによって変わってくるということじゃないかな?このあたりの判断は自分で実際に確かめて判断したほうがいいと思う。