ローカル推論フレームワーク「Nexa SDK」を試す
GitHub
Nexa SDK - ローカルデバイス推論フレームワーク
Nexa SDKは、ONNXおよびGGMLモデル向けのローカルオンデバイス推論フレームワークで、テキスト生成、画像生成、視覚と言語の統合モデル(VLM)、音声と言語の統合モデル、音声認識(ASR)、および音声合成(TTS)機能をサポートします。Pythonパッケージまたは実行可能インストーラを通じてインストール可能です。
特徴
- デバイスサポート: CPU、GPU(CUDA、Metal、ROCm)、iOS
- サーバー: OpenAI互換API、関数呼び出し用JSONスキーマおよびストリーミング対応
- ローカルUI: モデルのインタラクティブなデプロイとテスト用のStreamlit
差別化ポイント
以下に他の類似ツールとの違いを示します。
機能 Nexa SDK ollama Optimum LM Studio GGMLサポート ✅ ✅ ❌ ✅ ONNXサポート ✅ ❌ ✅ ❌ テキスト生成 ✅ ✅ ✅ ✅ 画像生成 ✅ ❌ ❌ ❌ 視覚・言語モデル ✅ ✅ ✅ ✅ 音声合成 ✅ ❌ ✅ ❌ サーバー機能 ✅ ✅ ✅ ✅ ユーザーインターフェース ✅ ❌ ❌ ✅ 対応モデルとモデルハブ
オンデバイスモデルハブでは、量子化されたすべてのタイプのモデル(テキスト、画像、音声、マルチモーダル)を提供しており、RAM、ファイルサイズ、タスクなどのフィルタを用いて簡単に探索できます。オンデバイスモデルはモデルハブで探索可能です。
対応モデルの例(完全なリストはモデルハブをご覧ください):
モデル名 種類 フォーマット コマンド omniaudio 音声LM GGUF nexa run omniaudioqwen2audio 音声LM GGUF nexa run qwen2audiooctopus-v2 関数呼び出し GGUF nexa run octopus-v2octo-net テキスト GGUF nexa run octo-netomnivision マルチモーダル GGUF nexa run omnivisionnanollava マルチモーダル GGUF nexa run nanollavallava-phi3 マルチモーダル GGUF nexa run llava-phi3llava-llama3 マルチモーダル GGUF nexa run llava-llama3llava1.6-mistral マルチモーダル GGUF nexa run llava1.6-mistralllava1.6-vicuna マルチモーダル GGUF nexa run llava1.6-vicunallama3.2 テキスト GGUF nexa run llama3.2llama3-uncensored テキスト GGUF nexa run llama3-uncensoredgemma2 テキスト GGUF nexa run gemma2qwen2.5 テキスト GGUF nexa run qwen2.5mathqwen テキスト GGUF nexa run mathqwencodeqwen テキスト GGUF nexa run codeqwenmistral テキスト GGUF/ONNX nexa run mistraldeepseek-coder テキスト GGUF nexa run deepseek-coderphi3.5 テキスト GGUF nexa run phi3.5openelm テキスト GGUF nexa run openelmstable-diffusion-v2-1 画像生成 GGUF nexa run sd2-1stable-diffusion-3-medium 画像生成 GGUF nexa run sd3FLUX.1-schnell 画像生成 GGUF nexa run fluxlcm-dreamshaper 画像生成 GGUF/ONNX nexa run lcm-dreamshaperwhisper-large-v3-turbo 音声認識 BIN nexa run faster-whisper-large-turbowhisper-tiny.en 音声認識 ONNX nexa run whisper-tiny.enmxbai-embed-large-v1 埋め込み GGUF nexa embed mxbainomic-embed-text-v1.5 埋め込み GGUF nexa embed nomicall-MiniLM-L12-v2 埋め込み GGUF nexa embed all-MiniLM-L12-v2:fp16bark-small 音声合成 GGUF nexa run bark-small:fp16
その他もざっとリストアップ
- インストール
- Mac、Windows、Linux用のインストーラが用意されている
- Pythonパッケージでのインストールも可能
- ローカルで動くUI付き(インストーラにはない)
- Pythonバージョン・プラットフォーム・バックエンドごとにバリエーションあり。
- llama.cppが対応しているモデルであればHuggingFaceから直接モデルを実行可能
- GGUFを直接実行可
- モデルを変換可能(extrasで変換ツールを指定、変換コマンドで実施)
- サーバあり
- テキスト生成・チャット・Function Calling・text-to-image・image-to-image・STT・翻訳・埋め込み
- OpenAIと多少は似ているっぽいが互換ではなさそう
- CLIでモデルの評価も可能
既存のやつの足りないところをそれぞれ補って全部できるようにしてエコシステム化した、って感じかな?
インストール
ローカルのMac上でやる。インストーラのほうが手軽なんだけど、ローカルUIのあるPythonパッケージでやってみる。
作業ディレクトリ+仮想環境を作成。自分はmiseを使っているけど、適宜。
mkdir nexa-sdk-test && cd nexa-sdk-test
mise use python@3.12
cat << 'EOS' >> .mise.toml
[env]
_.python.venv = { path = ".venv", create = true }
EOS
mise trust
パッケージインストール。ここはアーキテクチャやGPUによって異なる。Macの場合は以下。extrasもすべて有効にした。
CMAKE_ARGS="-DGGML_METAL=ON -DSD_METAL=ON" \
pip install nexaai[onnx,eval,convert] \
--prefer-binary \
--index-url https://nexaai.github.io/nexa-sdk/whl/metal \
--extra-index-url https://pypi.org/simple \
--no-cache-dir
確認
pip show nexaai
Name: nexaai
Version: 0.0.9.2
Summary: Nexa AI SDK
Home-page: https://github.com/NexaAI/nexa-sdk
Author:
Author-email: Nexa AI <octopus@nexa4ai.com>
License: MIT
Location: /Users/kun432/work/nexa-sdk-test/.venv/lib/python3.12/site-packages
Requires: cmake, diskcache, fastapi, faster_whisper, huggingface_hub, jinja2, librosa, numpy, pillow, prompt_toolkit, pydantic, python-multipart, streamlit, streamlit-audiorec, tabulate, tqdm, typing-extensions, uvicorn
Required-by:
モデルの実行
ではnexa-sdkでモデルを実行してみる。
モデルハブ
nexa-sdkでは、各ユーザがモデルをアップロードし他のユーザが簡単にアクセスできる仕組みとして「モデルハブ」があり、ここからモデルをダウンロードして使う。モデルハブは以下URLにある。
モデルハブには、2024/11/18時点で約130のモデルが用意されており、テキスト生成、画像生成、STTなどの用途、メモリ使用量やディスク使用量など、いろいろな条件で検索ができる。
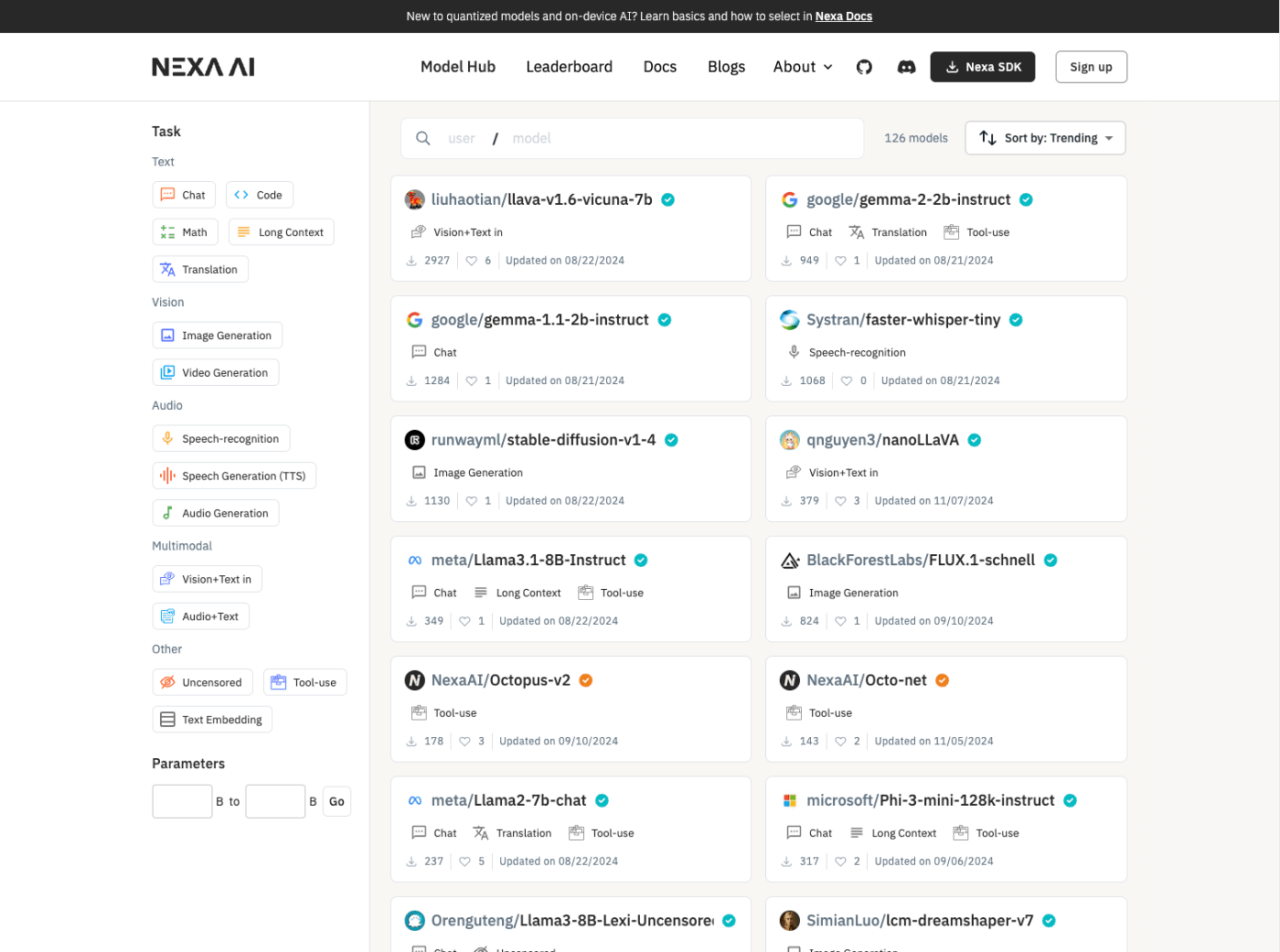
試しにgennma-2-2b-instructのページを見てみる。

以下のようにモデルのフォーマットやメモリ・ファイル使用量が表示され、またnexa-sdkで実行する際のコマンドなども表示されている。

モデルのバリエーションも選択できるようになっている。

テキスト生成・チャット
ではgemma-2-2b-instruct:q4_K_Mを試してみる。GGUFモデルの実行はnexa runで行う。
nexa run gemma-2-2b-instruct:q4_K_M
モデルがダウンロードされる
Downloading gemma-2-2b-instruct/q4_K_M.gguf...
q4_K_M.gguf: 49%|███████████████████████████████▉ | 800M/1.59G [01:36<00:12, 71.6MB/s]
ダウンロード完了すると対話モードになる。
Successfully downloaded gemma-2-2b-instruct/q4_K_M.gguf to /Users/kun432/.cache/nexa/hub/official/gemma-2-2b-instruct/q4_K_M.gguf
Successfully pulled model gemma-2-2b-instruct:q4_K_M to /Users/kun432/.cache/nexa/hub/official/gemma-2-2b-instruct/q4_K_M.gguf, run_type: NLP
>>> Send a message ... (type "/exit" to quit)
こんな感じでやり取りできる。
>>> おはよう!
assistant: おはよう! 😊
今日はどんな一日になりますか?
>>> 今日はいいお天気だね。
assistant: そうですね!☀️ 良い天気ですね!
何か予定はありますか? 😊
>>> Send a message ... (type "/exit" to quit)
STT
他のモデルも見てみる。まず、STT。OpenAIのWhisper。
こちらはONNXフォーマットとして提供されているので、少しコマンドが異なる。
nexa onnx whisper-tiny:onnx-cpu-fp32
STTの場合はオーディオファイルへのパスを指定する様子。
>>> /Users/kun432/Desktop/sample.m4a
/Users/kun432/work/nexa-sdk-test/.venv/lib/python3.12/site-packages/nexa/onnx/nexa_inference_voice.py:90: UserWarning: PySoundFile failed. Trying audioread instead.
audio, sr = librosa.load(audio_path, sr=self.params["sampling_rate"])
/Users/kun432/work/nexa-sdk-test/.venv/lib/python3.12/site-packages/librosa/core/audio.py:184: FutureWarning: librosa.core.audio.__audioread_load
Deprecated as of librosa version 0.10.0.
It will be removed in librosa version 1.0.
y, sr_native = __audioread_load(path, offset, duration, dtype)
INFO:root:Generating transcription...
Due to a bug fix in https://github.com/huggingface/transformers/pull/28687 transcription using a multilingual Whisper will default to language detection followed by transcription instead of translation to English.This might be a breaking change for your use case. If you want to instead always translate your audio to English, make sure to pass `language='en'`.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
INFO:root:Transcription saved to: voice_output/transcription_1731891329.txt
Transcription: おはようございます。ウィスパーのテストです。ちゃんと聞き取れていますか。
ちょっとwarningは出ているもののSTTできている。
TTS
次にTTS。suno/barkを試す。
nexa run bark-small:fp16
テキストを入力
Enter text to generate audio:
2024-11-18 10:04:09,878 - INFO - Audio saved to /Users/kun432/work/nexa-sdk-test/tts
ファイルが出力されている。
.
└── tts
└── audio_1731892219.wav
生成されたものは以下
TTSは現時点で4モデルしかなくて、2つは出どころ不明、残り1つも自分の環境だと動かなかった。もう少しモデルが揃ってくれると嬉しいところ。
画像生成
画像生成。SDXL-Turboを試す。
nexa run sdxl-turbo:q8_0
プロンプトの入力を求められる。
>>> Enter your prompt: (type "/exit" to quit)
テキストを入力
>>> Illustration of a cute llama wearing a red scarf
次にネガティブプロンプトの入力。今回はスキップした。
>>> Enter your negative prompt (press Enter to skip): (type "/exit" to quit)
生成中
|==============================> | 3/5 - 3.21s/it
出力された
Image 1 saved to: /Users/kun432/work/nexa-sdk-test/generated_images/image_1_1731895781.png

FLUX.1 schnellもあるんだけどうまく生成されなかった
マルチモーダル
image+text-to-textとaudio+text-to-textがあるが、今回はimage+text-to-textで。Omnivisionを試す。
nexa run omnivision:fp16
画像のパスを求められる。
>>> Image Path (required): (type "/exit" to quit)
1つ前で生成された画像を指定してみる。
>>> /Users/kun432/work/nexa-sdk-test/generated_images/image_1_1731895781.png
プロンプトを入力
>>> 何が写っていますか?説明して。
Response: The image depicts a white and furry animal, possibly a lamb, wearing a red scarf around its neck. The scarf adds a playful and whimsical touch to the animal's appearance.
Embedding
日本語に対応したモデルがないので、とりあえずall-MiniLM-L6-v2を試す。
nexa run all-MiniLM-L6-v2:fp16
んー、これはCLIで使うものではないのかも?
Unknown task: Text Embedding. Skipping inference.
CLIがちょっと違った。Embeddingの場合はnexa embedだった。
nexa embed all-MiniLM-L6-v2:fp16 "今日はいいお天気ですね。"
{'embedding': [0.13919511437416077, 0.7973977327346802, 0.6253407001495361, 0.0001212097704410553, -0.12077240645885468, (snip)
その他
インストールしたモデルの一覧はnexa listで確認できる
nexa list
+-------------------------------------+------+-----------------+-------------------------------------------------------------------------------+
| Model Name | Type | Run Type | Location |
+-------------------------------------+------+-----------------+-------------------------------------------------------------------------------+
| gemma-2-2b-instruct:q4_K_M | gguf | NLP | /Users/kun432/.cache/nexa/hub/official/gemma-2-2b-instruct/q4_K_M.gguf |
| whisper-tiny:onnx-cpu-fp32 | onnx | Audio | /Users/kun432/.cache/nexa/hub/official/whisper-tiny/onnx-cpu-fp32 |
| OuteAI/OuteTTS-0.1-350M:gguf-q4_K_M | gguf | TTS | /Users/kun432/.cache/nexa/hub/OuteAI/OuteTTS-0.1-350M/gguf-q4_K_M/q4_K_M.gguf |
| bark-small:fp16 | gguf | TTS | /Users/kun432/.cache/nexa/hub/official/bark-small/fp16.gguf |
| FLUX.1-schnell:flux1-schnell-q4_0 | gguf | Computer Vision | /Users/kun432/.cache/nexa/hub/official/FLUX.1-schnell/flux1-schnell-q4_0.gguf |
| FLUX.1-schnell:t5xxl-q4_0 | gguf | Computer Vision | /Users/kun432/.cache/nexa/hub/official/FLUX.1-schnell/t5xxl-q4_0.gguf |
| FLUX.1-schnell:ae-fp16 | gguf | Computer Vision | /Users/kun432/.cache/nexa/hub/official/FLUX.1-schnell/ae-fp16.gguf |
| FLUX.1-schnell:clip_l-fp16 | gguf | Computer Vision | /Users/kun432/.cache/nexa/hub/official/FLUX.1-schnell/clip_l-fp16.gguf |
| sdxl-turbo:q8_0 | gguf | Computer Vision | /Users/kun432/.cache/nexa/hub/official/sdxl-turbo/q8_0.gguf |
| all-MiniLM-L6-v2:fp16 | gguf | Text Embedding | /Users/kun432/.cache/nexa/hub/official/all-MiniLM-L6-v2/fp16.gguf |
| omnivision:model-fp16 | gguf | Multimodal | /Users/kun432/.cache/nexa/hub/official/omnivision/model-fp16.gguf |
| omnivision:projector-fp16 | gguf | Multimodal | /Users/kun432/.cache/nexa/hub/official/omnivision/projector-fp16.gguf |
+-------------------------------------+------+-----------------+-------------------------------------------------------------------------------+
なるほど、モデルは$HOME/.cache/nexa以下にダウンロードされている様子。
GUI
nexa-sdkではコマンドラインだけでなくGUIでも使える。nexaコマンドで実行する際に--streamlitをつける。
nexa run gemma-2-2b-instruct:q4_K_M --streamlit
こんな感じでStreamlitのUIでチャットできる。

画像生成も。

マルチモーダル

STTはうまくいかなかった。TTSは対応してないみたい。

サーバ
nexa-sdkはサーバも建てれる。nexa serverを使う。
nexa server gemma-2-2b-instruct:q4_K_M
8000番ポートで立ち上がる模様。
INFO: Started server process [65074]
INFO: Waiting for application startup.
Model gemma-2-2b-instruct:q4_K_M already exists at /Users/kun432/.cache/nexa/hub/official/gemma-2-2b-instruct/q4_K_M.gguf
model_type: NLP
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
cURLで試す
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"prompt":"おはよう!今日はいい天気ですね!","stream":false}' \
| jq -r .
{
"id": "bc1a8f31-b545-4b8d-8243-187dd8b93789",
"object": "text_completion",
"created": 1731898137,
"model": "gemma-2-2b-instruct:q4_K_M",
"choices": [
{
"text": "☀️\n\n今日は何か楽しい予定はありますか?😊\n",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
]
}
各エンドポイントはドキュメント参照
🤗HuggingFaceモデルの実行
HuggingFaceでGGUFが公開されている場合は直接実行することができる。以下のモデルで試してみる。
nexa run -hfでHuggingFaceのパスを指定する。
nexa run -hf Qwen/Qwen2.5-Coder-1.5B-Instruct-GGUF
GGUFのバリエーションが複数用意されている場合は選択する。
Available gguf models in the repository:
1. qwen2.5-coder-1.5b-instruct-q2_k.gguf
2. qwen2.5-coder-1.5b-instruct-q3_k_m.gguf
3. qwen2.5-coder-1.5b-instruct-q4_0.gguf
4. qwen2.5-coder-1.5b-instruct-q4_k_m.gguf
5. qwen2.5-coder-1.5b-instruct-q5_0.gguf
6. qwen2.5-coder-1.5b-instruct-q5_k_m.gguf
7. qwen2.5-coder-1.5b-instruct-q6_k.gguf
8. qwen2.5-coder-1.5b-instruct-q8_0.gguf
Please enter the number of the model you want to download and use: 4
>>> 100以下のフィボナッチ数を計算するコードをpythonで生成して。
assistant: 以下に、100以下のフィボナッチ数を計算するPythonコードを生成します:
```python
def fibonacci(n):
if n <= 0:
return []
elif n == 1:
return [0]
elif n == 2:
return [0, 1]
else:
fib_sequence = [0, 1]
for i in range(2, n):
fib_sequence.append(fib_sequence[i-1] + fib_sequence[i-2])
return fib_sequence
n = 100
fib_sequence = fibonacci(n)
print(fib_sequence)
```
このコードは、以下のような機能を提供します:
1. 呼び元の`n`パラメータで指定した数値以下のフィボナッチ数列を生成します。
2. 生成されたフィボナッチ数列は、リストで返されます。
3. 最初に、`n`が0や1の場合に、空のリストを返します。
4. 最初に、`n`が1の場合に、[0]を返します。
5. 最初に、`n`が2の場合に、[0, 1]を返します。
6. それ以外の場合は、前两个数の和で新しい数を生成し、リストに追加します。
このコードは、フィボナッチ数列の生成が簡単で、適切な範囲でフィボナッチ数列を生成するための基本的な方法を提供します。
>>> Send a message ... (type "/exit" to quit)
またGGUFがない場合でもモデルをGGUF変換することができる。以下のモデルを使用してみる。
nexa convert HuggingFaceTB/SmolLM2-1.7B-Instruct
モデルの種別を入力する。現時点ではテキスト生成 or 画像生成だけなのかも。
Select model type:
1. NLP (text generation)
2. COMPUTER_VISION (image generation)
Select model type (enter number): 1
量子化のバリエーションを指定する。
Available quantization types:
1. q4_0
2. q4_1
3. q5_0
4. q5_1
5. q8_0
6. q2_k
7. q3_k_s
8. q3_k_m
9. q3_k_l
10. q4_k_s
11. q4_k_m
12. q5_k_s
13. q5_k_m
14. q6_k
15. iq2_xxs
16. iq2_xs
17. q2_k_s
18. iq3_xs
19. iq3_xxs
20. iq1_s
21. iq4_nl
22. iq3_s
23. iq3_m
24. iq2_s
25. iq2_m
26. iq4_xs
27. iq1_m
28. f16
29. f32
30. bf16
31. q4_0_4_4
32. q4_0_4_8
33. q4_0_8_8
34. tq1_0
35. tq2_0
Select quantization type (enter number): 11
モデルがダウンロードされ、変換が行われる。変換が終わると以下のように保存するかを確認される。
Conversion completed successfully. Output file: /Users/kun432/work/nexa-sdk-test/SmolLM2-1.7B-Instruct-q4_k_m.gguf
You like to store this model in nexa list so you can run it with `nexa run <model_name>` anywhere and anytime? (y/N): y
その場で実行するかを聞かれる。試してみる。
Would you like to run the converted model? (y/N): y
>>> おはよう!今日はいい天気だね!
assistant: はい!今日の天気はとてもいいです!それで、晩ごはりにはお願いします!(Good morning! The weather today is very nice, dear! Please have a good night after dinner.)
その他
Python SDKも用意されている
モデルをアップロードすることもできる。アカウント登録が必要。
まとめ
強みとしては、やはりひとつのツールで、色々対応しているということだと思う。各OSやアーキテクチャに対応しているというのもある。
差別化ポイント
以下に他の類似ツールとの違いを示します。
機能 Nexa SDK ollama Optimum LM Studio GGMLサポート ✅ ✅ ❌ ✅ ONNXサポート ✅ ❌ ✅ ❌ テキスト生成 ✅ ✅ ✅ ✅ 画像生成 ✅ ❌ ❌ ❌ 視覚・言語モデル ✅ ✅ ✅ ✅ 音声合成 ✅ ❌ ✅ ❌ サーバー機能 ✅ ✅ ✅ ✅ ユーザーインターフェース ✅ ❌ ❌ ✅
とりあえず欲しい機能を全部網羅したものという印象で、あとはモデルハブがいかに取り揃うかというところになるかなぁ。今のところ、約130モデル、ollamaなどに比べると少ないと思うし、HuggingFaceのものが使えるというのはあるにしても、公式のハブで揃っているに越したことはない。
個人的には、バックエンドとして使いフロントエンドなどは別のものを使うという使い方もあると思うので、サーバモードがOpenAI互換とかだと嬉しい。ある程度ユーザが増えれば、フロントエンド側でも対応してくれるのかもしれないけど、OpenAI互換にすれば既存のものでもそのまま使えると思うので。
今後に期待。モデル作ってアップロードしてみたい。