Gemini 2.5 の Speech Generation を試す
Google I/OのGeminiまとめは以下
気になっていたのはSpeech Generationで、ドキュメントなども公開されているようなので試してみる。
ドキュメント
2025/05/22追記
Quickstart用のnotebookが追加されていた
ポイント
- Gemini API でTTS を生成可能
- 単一話者・複数話者の音声を生成可能
- プロンプトでスタイル・アクセント・速度・トーン を制御可能
- 30種類の声が利用可能
- 24種類の言語に対応(日本語含む)
- 対応モデル(現在はプレビュー)
gemini-2.5-pro-preview-ttsgemini-2.5-flash-preview-tts
- Live API で使えるTTSとは異なる。
- Live APIは対話的な音声とマルチモーダル入出力向け。
- TTS はスタイルやサウンドを細かく制御しながら、正確なテキスト読み上げに最適
- 例: ポッドキャスト・オーディオブック等
- Google AI Studioで試すことができる
ドキュメントでは
- 単一話者の音声生成
- 複数話者の音声生成
- ストリーミング
- プロンプトによる発話の制御
- LLMとTTSの連携
についてサンプルコードが載っている。
あと注意すべき点としてはTTSのセッションはコンテキストが最大32Kらしい。
まずはGoogle AI Studioで。「Chat」メニューにモデルが見当たらなかったのでどこで使えるのかな?と思ったけど、「Generative Media」なのね。

Generative Speechの画面。
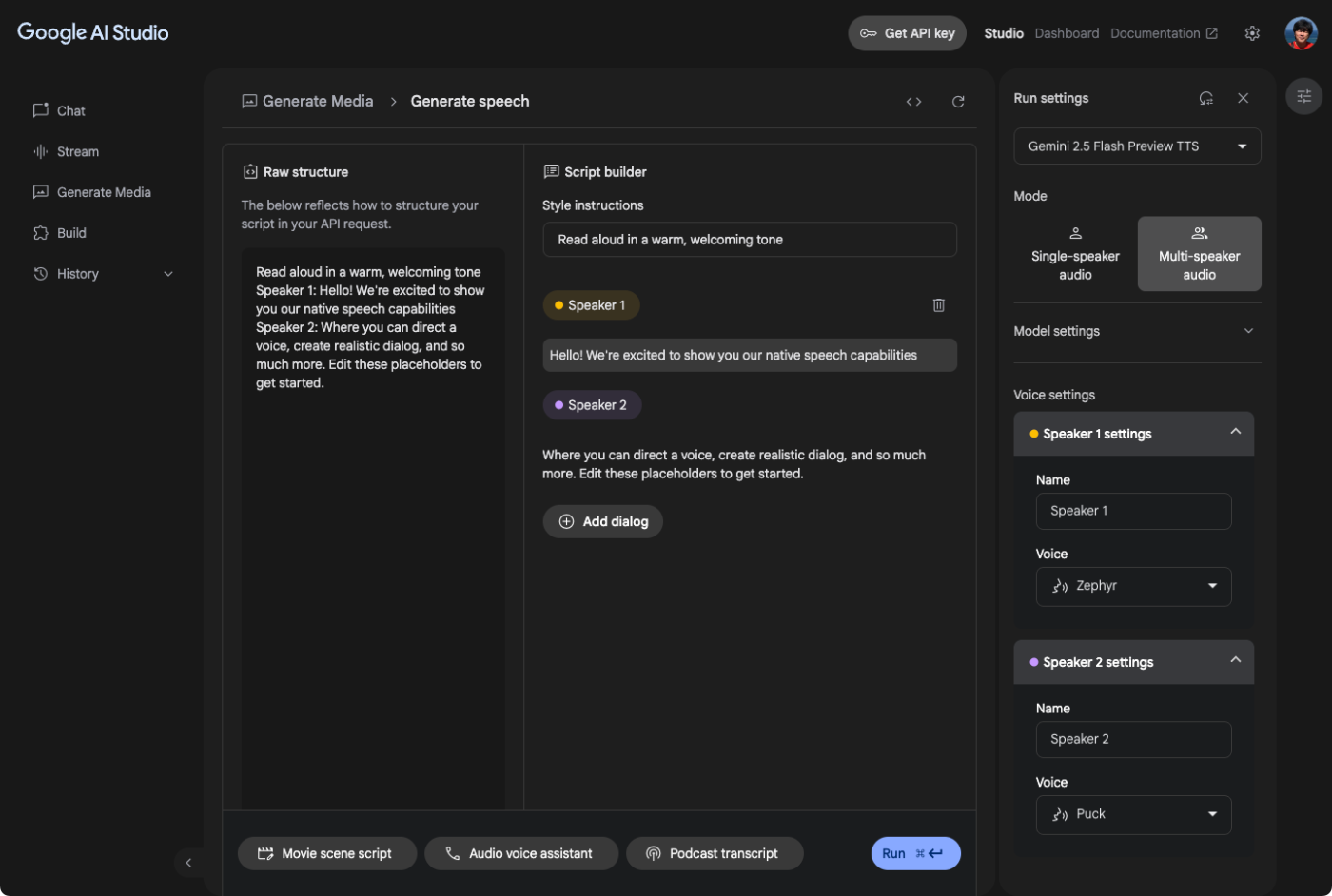
この画面は複数話者の音声生成。単一話者・複数話者の切り替えは右のモードで切り替える。
複数話者の場合
- 右のメニューでTTSのモデルや話者の名前・音声などを指定
- 左のRaw structure または 真ん中のScript builder で対話の台本を設定
- Script Builder
- Style Instructions で全体の発話に対する指示を設定
- あとはSpeaker1・Speaker2の発話を交互に入力していく
- Raw structure
- 上記の設定をテキストで行う
- 1行目にStyule Instructionsを書く
-
Speaker 1:/Speaker 2:で始まる行はそれぞれの発話となる - 右のメニューで話者名を設定している場合はそれになる
- 例:
太郎:/花子:
- 例:
-
- Script Builder
という感じ。とりあえずやってみた。

スクリプトはこんな感じ。話者名を設定しているのでそれに合わせる必要がある。
ポッドキャスト風、軽快でリズミカルに楽しく。
太郎: こんにちは、太郎です。今日は花子さんと、2025年春の競馬、G1レースの展望について語りたいと思います。まずは、各レースの見どころについて教えてください。
花子: こんにちは、花子です。春のG1レースは例年通り熱い展開が期待されますね。たとえば、フェブラリーステークスで見せたコスタノヴァの走りは印象的でしたし、今後のレースにも大きな影響を与えそうです。
太郎: 確かに。さらに、皐月賞ではファウストラーゼンやピコチャンブラックといった有力馬が注目されています。若手の勢いがこのレースの鍵になりそうですね。
花子: その通りです。そして、NHKマイルカップからはアドマイヤズームの動きにも期待が高まっています。各レースで個性豊かな馬たちが戦うので、騎手や調教師の戦略も見逃せません。
太郎: また、春の締めくくりとして注目される天皇賞(春)も、昨シーズンの歴史を踏まえて、今年はより一層白熱した争いが予想されますね。
花子: まさにその通りです。伝統と革新が融合する春のG1レース、ファンにとっては見逃せないシーズンになりそうです。
太郎: 今日は、花子さんが各レースの見どころや有力馬について熱く語ってくれました。来たる春のレース、私たちもワクワクしながら応援していきましょう!
花子: はい、最新情報をしっかりチェックしながら、競馬ファンとして楽しみたいですね。ご清聴ありがとうございました。
太郎: ありがとうございました。次回もお楽しみに!
生成されたもの
少し読み間違えてるところがあったけど、思ったよりは読めてる気がするなぁ。あとは人名・地名などの漢字の固有名詞とかでどれぐらい読めるかな?というのは気になる。
単位話者の生成はこういう画面。あらかじめ用意されているサンプルを使ってみた。
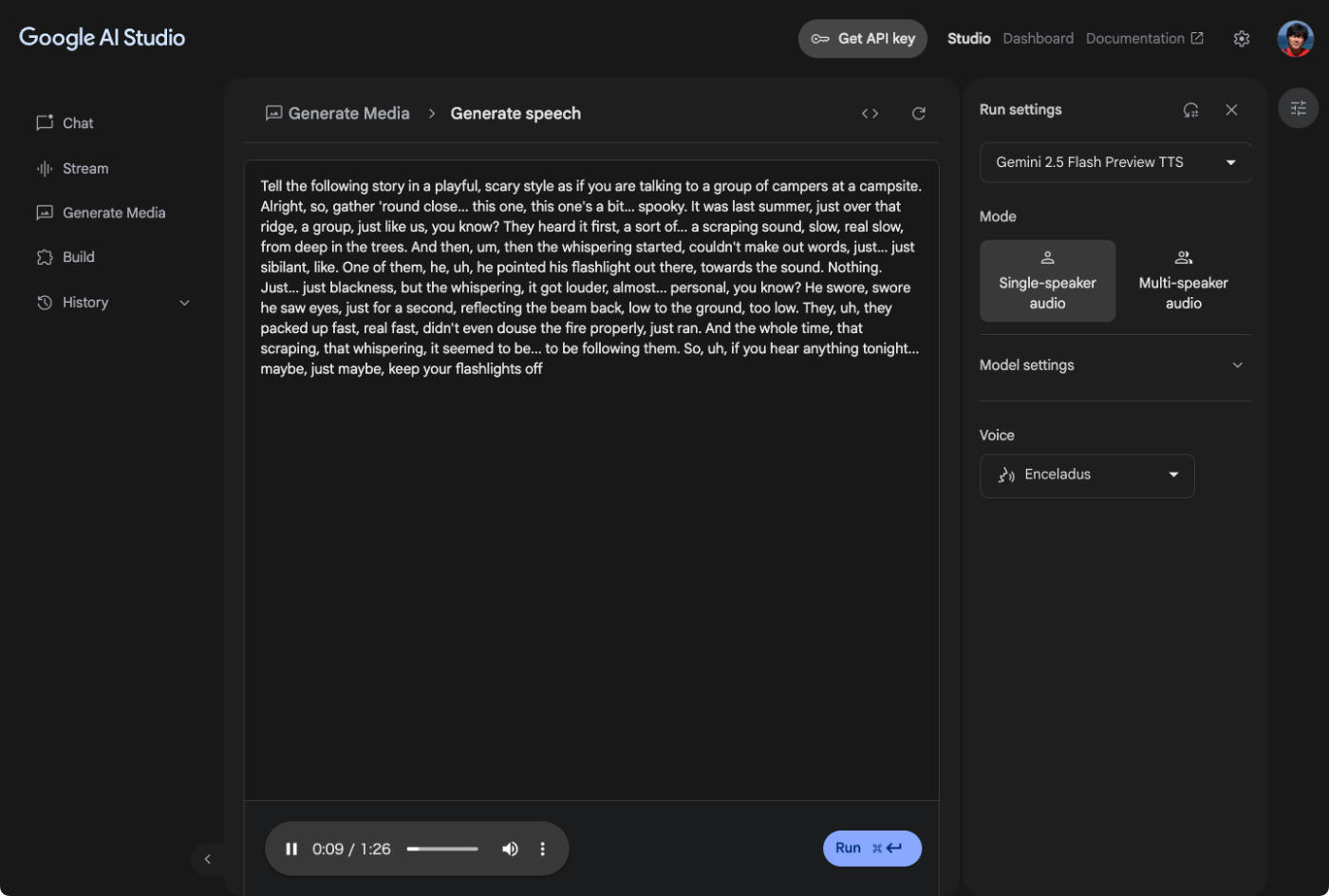
プロンプトは1行目に設定すればいいみたい。生成すると2行目の"Alright, so ..." からの音声が生成された。
ドキュメントに従って、サンプルコードを試してみる。Colaboratoryで。
パッケージインストール
!pip install -q -U google-genai
!pip freeze | grep -i google-genai
APIキーをセット
import os
from google.colab import userdata
os.environ["GOOGLE_API_KEY"] = userdata.get("GOOGLE_API_KEY")
まず単一話者の音声生成。プロンプト:発話するテキストという形で設定するみたい。
from google import genai
from google.genai import types
import wave
# 生成結果をWAVファイルに保存
def wave_file(filename, pcm, channels=1, rate=24000, sample_width=2):
with wave.open(filename, "wb") as wf:
wf.setnchannels(channels)
wf.setsampwidth(sample_width)
wf.setframerate(rate)
wf.writeframes(pcm)
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-preview-tts",
contents="明るく言ってください: 素晴らしい一日をお過ごしください!",
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Kore',
)
)
),
)
)
data = response.candidates[0].content.parts[0].inline_data.data
file_name='out.wav'
wave_file(file_name, data)
Colaboratory上で再生して確認
from IPython.display import Audio
Audio(file_name, autoplay=True)
実際に生成されたもの
少しプロンプトを変えてみる。
素晴らしい一日をお過ごしください!(プロンプトなし)
悲しみと絶望を込めて言ってください:素晴らしい一日をお過ごしください!
怒りと皮肉を込めて言ってください:素晴らしい一日をお過ごしください!
関西弁のなまりで言ってください:ほなぼちぼちがんばってやー。
感情に関する指示は行けそう。方言とかは何度か試してみたけどちょっと厳しいかな。でも使用する音声やプロンプトによってはいろいろできそう。
少し生成時間もみてみたけど、上の例だと概ね2.5〜3.0秒って感じかな。文章量にもよるだろうけど。ストリーミングを使ったらどれぐらい変わるかな?
複数話者の音声生成
from google import genai
from google.genai import types
import wave
def wave_file(filename, pcm, channels=1, rate=24000, sample_width=2):
with wave.open(filename, "wb") as wf:
wf.setnchannels(channels)
wf.setsampwidth(sample_width)
wf.setframerate(rate)
wf.writeframes(pcm)
client = genai.Client()
prompt = """ポッドキャスト風、軽快でリズミカルに楽しく。:
太郎: こんにちは、太郎です。今日は花子さんと、2025年春の競馬、G1レースの展望について語りたいと思います。まずは、各レースの見どころについて教えてください。
花子: こんにちは、花子です。春のG1レースは例年通り熱い展開が期待されますね。たとえば、フェブラリーステークスで見せたコスタノヴァの走りは印象的でしたし、今後のレースにも大きな影響を与えそうです。
"""
response = client.models.generate_content(
model="gemini-2.5-flash-preview-tts",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
multi_speaker_voice_config=types.MultiSpeakerVoiceConfig(
speaker_voice_configs=[
types.SpeakerVoiceConfig(
speaker='太郎',
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Umbriel',
)
)
),
types.SpeakerVoiceConfig(
speaker='花子',
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Gacrux',
)
)
),
]
)
)
)
)
data = response.candidates[0].content.parts[0].inline_data.data
file_name='out.wav'
wave_file(file_name, data)
from IPython.display import Audio
Audio(file_name, autoplay=True)
生成されたもの
その他ドキュメントには
- ストリーミング
- LLMで台本・TTSでその音声を生成
のサンプルコードもあるので、興味があれば。
いろいろ試していた中で、雑なプロンプトだとイントネーションがおかしくなって、少し明示的に指定すると治ったりもしたので、プロンプトはいろいろ工夫して試してみたほうが良さそう。
プロンプトで話し方を制御する
自然言語プロンプトを使って、単一話者 TTS でも複数話者 TTS でも スタイル、トーン、アクセント、速度 を制御できます。たとえば単一話者の場合、次のように指示できます。
不気味なささやき声で読み上げてください: 「私の親指の疼きが告げている… 何か邪悪なものがこちらに来る」複数話者の場合は、各話者の名前とスクリプトをプロンプトに記載し、それぞれに個別のガイダンスを与えることも可能です。
Speaker1 は疲れて退屈そうに、Speaker2 は興奮して幸福そうに聞こえるようにしてください: Speaker1: それで…今日の予定は何かな? Speaker2: きっと当てられないよ!伝えたいスタイルや感情に合った voice option を選択すると、より効果的に強調できます。前述の例では、Enceladus の息遣いの多い声は「疲れ」や「退屈」を際立たせ、Puck の陽気なトーンは「興奮」や「幸福」を際立たせることができます。
あとは台本も重要だね。NotebookLMの感じを出そうと思うと、まず台本を生成するプロンプトが必要になる。
ちなみにStreamのほうでもNative Audio Outputが使えるけど、こっちがLive APIってことだよね。

なお、ドキュメントの下の方にcookbookへのリンクがあるが、まだできてないらしく404になる。
Xほ色々お試しポスト見てる限り、プロンプトや入力文でいじれそう。上の方で方言試してるけど、実際に方言喋らせてる例があった。すごいな。
ストリーミングできないな、と思って調べてみたけど、うーん・・・
多分こんな感じになるはずなのだけど、確かにまるっと1つのチャンクで返ってくるので、ストリーミングの意味がない。以下のような短いものでもだいたい3秒ぐらいかかる。
from google import genai
from google.genai import types
import wave
import time
import pyaudio
client = genai.Client(api_key="XXXXXXXXXX")
pya = pyaudio.PyAudio()
stream = pya.open(
format=pyaudio.paInt16,
channels=1,
rate=24_000,
output=True)
def play_audio(chunks):
chunk: Blob
for chunk in chunks:
stream.write(chunk.candidates[0].content.parts[0].inline_data.data)
response = client.models.generate_content_stream(
model="gemini-2.5-flash-preview-tts",
contents="明るく言ってください: 素晴らしい一日をお過ごしください!",
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Kore',
)
)
),
)
)
play_audio(response)