「Amazon Bedrock AgentCore」を試す ③Built-in Tools: Code Interpreter
前回の続き。次はBuilt-in Tools。
Bedrock AgentCore Built-in Tools
Dia によるまとめ。
Amazon Bedrock AgentCoreっていうのは、今プレビュー中のサービスで、アプリ開発とかテストをめっちゃ便利にしてくれるツールが最初から入ってるんだよ。これ使うと、自分で面倒な準備とかしなくても、いろんな機能をすぐ使えるのがウケる!
どんなツールがあるの?
- コードインタープリター
これはPythonとかTypeScript、JavaScriptみたいなプログラミング言語を使って、データの分析とか計算ができる安全な場所だよ。自分のコードを実行できるから、めっちゃ便利!- ブラウザーツール
これはネットのページを安全に見たり、ウェブアプリをテストしたりできるやつ。自分のパソコンに変な影響が出ないように、ちゃんと隔離されてるから安心だし、リア充な開発ができる!セキュリティもバッチリ!
- それぞれのツールは完全に分けて動いてるから、他のツールに悪影響が出ないようになってる。
- セッション(使う時間)も決まってて、使いすぎ防止できる。
- アクセス権限(IAM)で誰が何できるか管理できるし、ネットワークの制限もできるから、外部からの変なアクセスも防げる!
使い方の流れ
- まず使いたいツール(コードインタープリターかブラウザーツール)を作る。
- そのツールでセッション(作業する時間・場所)を作る。
- ツールのAPIを使って、いろいろ操作する。
- 終わったらセッションを終了!
まとめ
AgentCoreのツールは、セキュリティもちゃんとしてて、しかも自分でサーバーとか準備しなくていいから、マジで楽だし、開発のテンション上がる!新しいこと試したい人には超おすすめだよ!
対象としては
- CodeInterpreter
- Browser
がある。
こちらも参考になりそう
ということで、こちらもまずはCode Interpreterから。
Bedrock AgentCore Code Interpreter
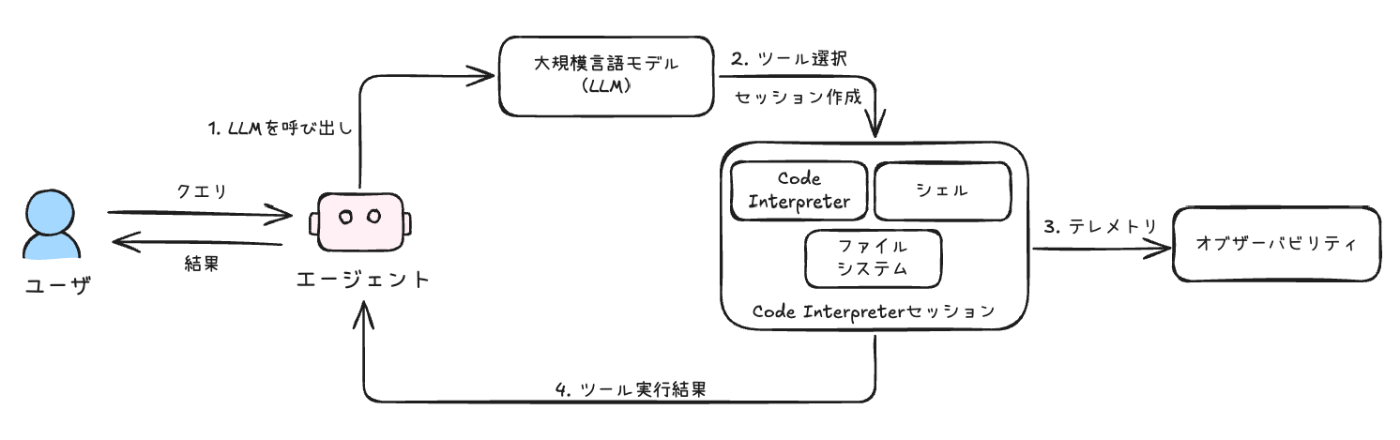
referred from https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/code-interpreter-tool.html and rewritten and translatesd into Japapnese by kun432
Amazon Bedrock AgentCoreの「コードインタープリター」ってやつは、AIエージェントが安全なサンドボックス環境でコードを書いたり実行したりできるツールなんだ。これがあると、AIが複雑なタスクもこなせるし、セキュリティ面もバッチリで、データ漏洩とかのリスクも減らせるのが超ポイント高い!
主な特徴をまとめると…
- 安全にコード実行できる!
サンドボックスっていう隔離された環境で動くから、他のシステムに悪影響を与えないし、内部データも守れるんだよ。- いろんな言語に対応!
Python、JavaScript、TypeScriptとか、人気の言語が使えるから、用途に合わせて選べるのがウケる。- 大きいファイルもOK!
直接アップロードなら100MBまで、Amazon S3経由なら5GBまで扱えるから、データ分析とかも余裕。- ネットアクセスやログもバッチリ!
インターネットにアクセスできるし、CloudTrailで操作ログも残せるから、監査とかトラブルシュートも安心。- 環境カスタマイズもできる!
セッションの設定やネットワークモードも自分で調整できるから、企業のセキュリティ要件にも対応できる!- 長時間の処理もOK!
デフォルトで15分、最長8時間まで実行できるから、重い処理も任せられる。- データ処理が得意!
CSV、Excel、JSONとかのデータを読み込んで、クリーニングや分析もできる。マジで便利!- 複雑なワークフローも対応!
推論だけじゃ難しい計算やデータ処理も、コードでガンガン解決できるし、何回も試行錯誤できるから、開発が超はかどる!まとめ
この「コードインタープリター」があれば、AIエージェントがもっと賢く、いろんなタスクを安全にこなせるようになるって感じ!開発者にとっても、セキュリティやパフォーマンスを気にせずに高度なAI開発ができるから、テンション上がるでしょ!
Getting Started
Python環境作成
uv init -p 3.12 agentcore-codeinterpreter-work && cd $_
uv add boto3 bedrock-agentcore
(snip)
+ bedrock-agentcore==0.1.1
+ boto3==1.40.1
(snip)
Code Interpreterは、AgentCore SDKだけでなくboto3でも使える。まず、AgentCore の場合。
from bedrock_agentcore.tools.code_interpreter_client import CodeInterpreter
import json
# CodeInterpreterセッションを開始
code_client = CodeInterpreter('us-east-1')
code_client.start()
# ハローワールドのコードを実行
response = code_client.invoke("executeCode", {
"language": "python",
"code": 'print("Hello World!!!")'
})
# レスポンスを処理して出力
for event in response["stream"]:
print(json.dumps(event["result"], indent=2))
# CodeInterpreterセッションを停止
code_client.stop()
実行
uv run ci_sample_with_ac_sdk.py
結果
{
"content": [
{
"type": "text",
"text": "Hello World!!!"
}
],
"structuredContent": {
"stdout": "Hello World!!!",
"stderr": "",
"exitCode": 0,
"executionTime": 0.014670848846435547
},
"isError": false
}
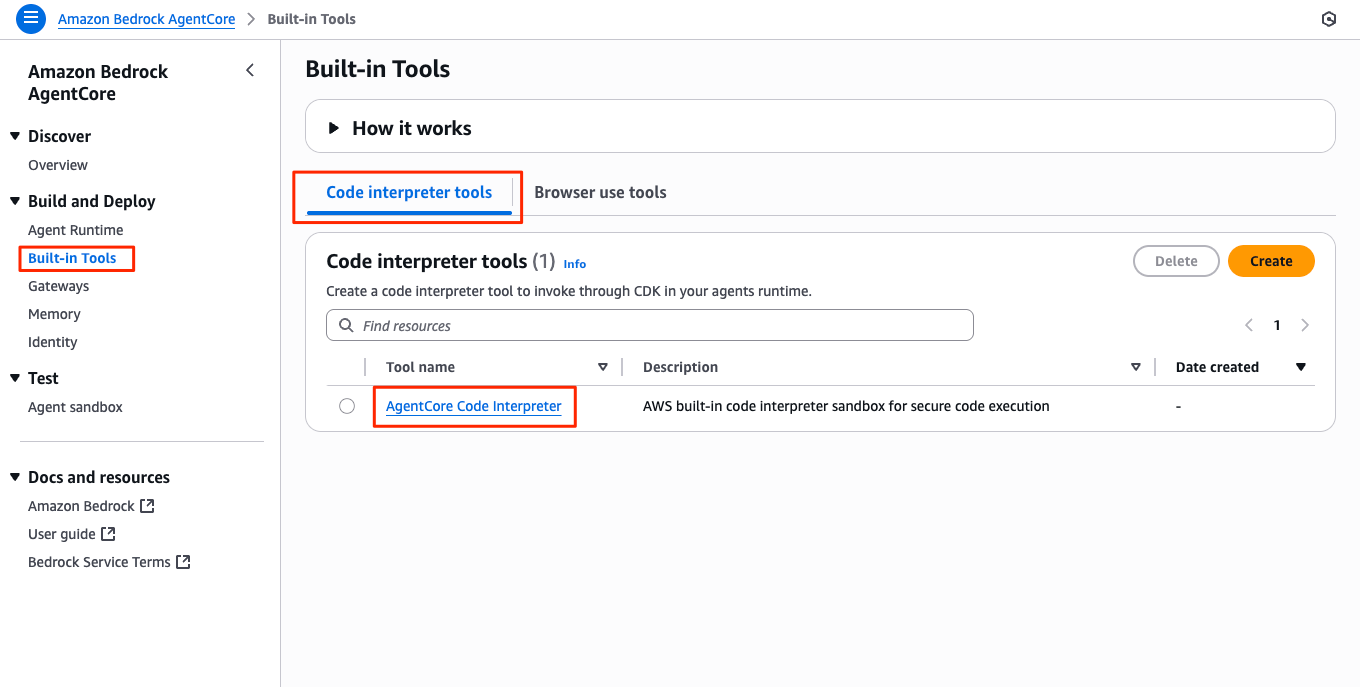
マネジメントコンソールで見ると、どうやらCode Interpreterのリソースはあらかじめデフォルトで用意されていて、これを使って一時的なセッションの中で実行されているのではないか?と思われる。

boto3の場合
import boto3
import json
code_to_execute = """
print("Hello World!!!")
"""
client = boto3.client(
"bedrock-agentcore",
region_name="us-east-1",
endpoint_url="https://bedrock-agentcore.us-east-1.amazonaws.com"
)
session_id = client.start_code_interpreter_session(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
name="my-code-session",
sessionTimeoutSeconds=900
)["sessionId"]
execute_response = client.invoke_code_interpreter(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
sessionId=session_id,
name="executeCode",
arguments={
"language": "python",
"code": code_to_execute
}
)
# ストリームからテキスト出力を抽出して出力
for event in execute_response['stream']:
if 'result' in event:
result = event['result']
if 'content' in result:
for content_item in result['content']:
if content_item['type'] == 'text':
print(content_item['text'])
# 処理完了後はセッションを停止するのを忘れないように
client.stop_code_interpreter_session(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
sessionId=session_id
)
uv run ci_sample_with_boto3.py
Hello World!!!
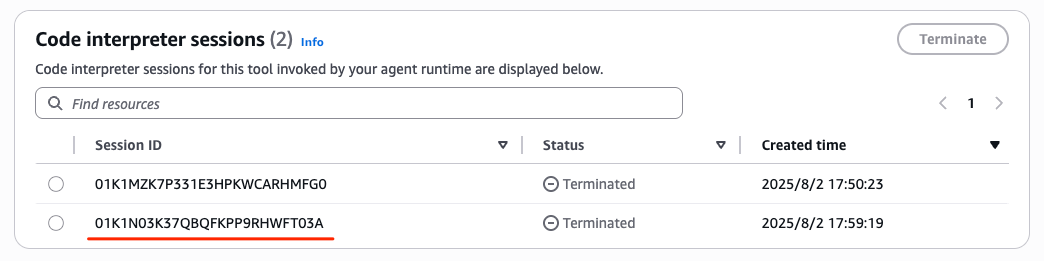
マネージメントコンソールでもセッションが増えていた。
エージェントからCode Interpreterでコードを実行する
実際にエージェントからCode Interpreterでコードを実行させてみる。サンプルはStrands AgentsとLangChainが用意されているが、今回はStrands Agentsで。
パッケージ追加
uv add strands-agents
(snip)
strands-agents==1.2.0
(snip)
Pythonコードを実行するエージェント
import json
from strands import Agent, tool
from strands.models import BedrockModel
from bedrock_agentcore.tools.code_interpreter_client import code_session
import asyncio
#システムプロンプトを定義
SYSTEM_PROMPT = """\
あなたは、すべての回答をコードの実行を通じて検証する役立つAIアシスタントです。
検証の原則:
1. コード、アルゴリズム、または計算に関する主張を行う場合 - それらを検証するためのコードを記述してください
2. 数学的計算、アルゴリズム、論理のテストには execute_python を使用してください
3. 回答を提供する前に、理解を確認するためのテストスクリプトを作成してください
4. 実際のコードの実行結果を常に示してください
5. 不確実な場合は、制限事項を明示し、検証可能な部分のみを検証してください
アプローチ:
- プログラミング概念について尋ねられた場合、コードで実装して示してください
- 計算を求められた場合、プログラムで計算し、コードを表示してください
- アルゴリズムを実装する場合、正しさを証明するためのテストケースを含めてください
- 検証プロセスを文書化して透明性を確保してください
- 実行間での状態は保持されるため、以前の結果を参照できます
利用可能なツール:
- execute_python: Python コードを実行し、出力を表示
レスポンス形式: execute_pythonツールは、以下のJSONレスポンスを返します:
- sessionId: サンドボックスセッションID
- id: リクエストID
- isError: エラーが発生したかどうかを示すブール値
- content: タイプとテキスト/データを含むコンテンツオブジェクトの配列
- structuredContent: コード実行時、stdout、stderr、exitCode、executionTime を含む
コード実行が成功した場合、出力は content[0].textおよびstructuredContent.stdout に格納されます。
isError フィールドを確認してエラーの有無を確認してください。
徹底的に、正確に、可能な限り回答を検証してください。"""
# Code Interpreterツールを定義
@tool
def execute_python(code: str, description: str = "") -> str:
"""Pythonコードを実行する"""
if description:
code = f"# {description}\n{code}"
# 実行するコードを出力
print(f"\n コード: {code}")
# Invokeメソッドを呼び出し、生成されたコードを実行し、
# 初期化されたCode Interpreterセッション内で実行
with code_session("us-east-1") as code_client:
response = code_client.invoke("executeCode", {
"code": code,
"language": "python",
"clearContext": False
})
for event in response["stream"]:
return json.dumps(event["result"])
# モデルの定義
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0",
region_name="us-east-1",
temperature=0.3
)
# Strandsエージェントを設定して、ツールを追加
agent=Agent(
model=bedrock_model,
tools=[execute_python],
system_prompt=SYSTEM_PROMPT,
callback_handler=None
)
query="地球と月の間に太陽系のすべての惑星を収めることができますか?"
# エージェントを非同期で呼び出し、レスポンスをストリーム
async def main():
response_text = ""
async for event in agent.stream_async(query):
if "data" in event:
# テキストレスポンスをストリーム
chunk = event["data"]
response_text += chunk
print(chunk, end="")
asyncio.run(main())
実行
uv run strands_ci_agent.py
結果
この興味深い質問を検証するために、地球と月の距離と太陽系の全惑星の直径を計算して比較してみましょう。
コード: # 地球と月の距離、および太陽系の惑星の直径データ
# 距離と直径は全てキロメートル単位
# 地球と月の平均距離
earth_moon_distance = 384400 # km
print(f"地球と月の平均距離: {earth_moon_distance:,} km")
# 太陽系の惑星の直径(km)
planets = {
'水星': 4879,
'金星': 12104,
'地球': 12756,
'火星': 6792,
'木星': 142984,
'土星': 120536,
'天王星': 51118,
'海王星': 49528
}
print("\n太陽系の惑星の直径:")
total_diameter = 0
for planet, diameter in planets.items():
print(f"{planet}: {diameter:,} km")
total_diameter += diameter
print(f"\n全惑星の直径の合計: {total_diameter:,} km")
コード: # 比較と結果の分析
difference = earth_moon_distance - total_diameter
percentage = (total_diameter / earth_moon_distance) * 100
print("=== 結果の比較 ===")
print(f"地球と月の距離: {earth_moon_distance:,} km")
print(f"全惑星の直径合計: {total_diameter:,} km")
print(f"差: {difference:,} km")
print(f"惑星の直径合計は地球-月距離の {percentage:.1f}% を占める")
if total_diameter <= earth_moon_distance:
print("\n✅ 結論: はい、地球と月の間に太陽系のすべての惑星を収めることができます!")
print(f" 余裕のスペース: {difference:,} km")
else:
print("\n❌ 結論: いいえ、地球と月の間に太陽系のすべての惑星を収めることはできません。")
print(f" 不足分: {abs(difference):,} km")
# 各惑星の寄与度を可視化
print("\n=== 各惑星の寄与度 ===")
for planet, diameter in sorted(planets.items(), key=lambda x: x[1], reverse=True):
contribution = (diameter / total_diameter) * 100
print(f"{planet}: {diameter:,} km ({contribution:.1f}%)")
コード: # 変数を再定義して計算を実行
earth_moon_distance = 384400 # km
planets = {
'水星': 4879,
'金星': 12104,
'地球': 12756,
'火星': 6792,
'木星': 142984,
'土星': 120536,
'天王星': 51118,
'海王星': 49528
}
total_diameter = sum(planets.values())
# 比較と結果の分析
difference = earth_moon_distance - total_diameter
percentage = (total_diameter / earth_moon_distance) * 100
print("=== 結果の比較 ===")
print(f"地球と月の距離: {earth_moon_distance:,} km")
print(f"全惑星の直径合計: {total_diameter:,} km")
print(f"差: {difference:,} km")
print(f"惑星の直径合計は地球-月距離の {percentage:.1f}% を占める")
if total_diameter <= earth_moon_distance:
print("\n✅ 結論: はい、地球と月の間に太陽系のすべての惑星を収めることができます!")
print(f" 余裕のスペース: {difference:,} km")
else:
print("\n❌ 結論: いいえ、地球と月の間に太陽系のすべての惑星を収めることはできません。")
print(f" 不足分: {abs(difference):,} km")
# 各惑星の寄与度を可視化
print("\n=== 各惑星の寄与度 ===")
for planet, diameter in sorted(planets.items(), key=lambda x: x[1], reverse=True):
contribution = (diameter / total_diameter) * 100
print(f"{planet}: {diameter:,} km ({contribution:.1f}%)")
コード: # 追加の検証:もし木星を除いた場合はどうなるか?
planets_without_jupiter = {k: v for k, v in planets.items() if k != '木星'}
total_without_jupiter = sum(planets_without_jupiter.values())
print("=== 木星を除いた場合の検証 ===")
print(f"木星を除いた惑星の直径合計: {total_without_jupiter:,} km")
print(f"地球と月の距離: {earth_moon_distance:,} km")
if total_without_jupiter <= earth_moon_distance:
remaining_space = earth_moon_distance - total_without_jupiter
print(f"✅ 木星を除けば収まります!余裕: {remaining_space:,} km")
else:
shortage = total_without_jupiter - earth_moon_distance
print(f"❌ 木星を除いても収まりません。不足分: {shortage:,} km")
# 視覚的な比較のためのスケール表示
print("\n=== スケール比較 ===")
print("地球-月距離を100とした場合:")
print(f"全惑星の直径: {(total_diameter/earth_moon_distance)*100:.1f}")
print(f"木星のみ: {(planets['木星']/earth_moon_distance)*100:.1f}")
print(f"土星のみ: {(planets['土星']/earth_moon_distance)*100:.1f}")
print(f"木星+土星: {((planets['木星']+planets['土星'])/earth_moon_distance)*100:.1f}")
コード: # 完全な検証を一つのセルで実行
earth_moon_distance = 384400 # km
planets = {
'水星': 4879,
'金星': 12104,
'地球': 12756,
'火星': 6792,
'木星': 142984,
'土星': 120536,
'天王星': 51118,
'海王星': 49528
}
total_diameter = sum(planets.values())
print("=== 最終結果 ===")
print(f"地球と月の平均距離: {earth_moon_distance:,} km")
print(f"太陽系全惑星の直径合計: {total_diameter:,} km")
print(f"差: {earth_moon_distance - total_diameter:,} km")
if total_diameter <= earth_moon_distance:
print("\n✅ 答え: はい、収まります!")
else:
print("\n❌ 答え: いいえ、収まりません!")
print(f" 約 {total_diameter - earth_moon_distance:,} km 不足します")
# 追加の検証:木星を除いた場合
planets_without_jupiter = {k: v for k, v in planets.items() if k != '木星'}
total_without_jupiter = sum(planets_without_jupiter.values())
print(f"\n=== 参考:木星を除いた場合 ===")
print(f"木星以外の惑星の直径合計: {total_without_jupiter:,} km")
if total_without_jupiter <= earth_moon_distance:
print(f"✅ 木星を除けば収まります!余裕: {earth_moon_distance - total_without_jupiter:,} km")
print(f"\n=== 主要な惑星の寄与 ===")
print(f"木星: {planets['木星']:,} km ({planets['木星']/total_diameter*100:.1f}%)")
print(f"土星: {planets['土星']:,} km ({planets['土星']/total_diameter*100:.1f}%)")
print(f"木星+土星で全体の {(planets['木星']+planets['土星'])/total_diameter*100:.1f}% を占める")
## 検証結果
コードによる計算で検証した結果、**いいえ、地球と月の間に太陽系のすべての惑星を収めることはできません。**
### 詳細な数値:
- **地球と月の平均距離**: 384,400 km
- **太陽系全惑星の直径合計**: 400,697 km
- **不足分**: 約16,297 km(約4.2%不足)
### 主要な要因:
1. **木星**が最大の要因で、直径142,984 km(全体の35.7%)
2. **土星**が2番目で、直径120,536 km(全体の30.1%)
3. この2つの巨大惑星だけで全体の65.8%を占める
### 興味深い事実:
- もし**木星を除けば**、残りの7惑星は余裕で収まります(126,687 kmの余裕)
- 地球と月の距離は思っているより近く、太陽系の巨大惑星の大きさは想像以上に大きい
この計算は、宇宙のスケールの感覚を掴むのに非常に有用な例ですね!
出力で コード: と出ている箇所がコードを生成した箇所で、それぞれのコードをCode Interpreterを使って実行しているので、マネジメントコンソール上ではセッションが複数記録されている。

Code Interpreterセッションで、ファイルの読み書き
Code Interpreterで指定したファイルの読み書きを行う場合は、Code Interpreterセッションにファイルをアップロードする。
サンプルのファイルが用意されているのでそれを使用する。
wget https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/samples/read_write_files.zip
unzip read_write_files.zip
Archive: read_write_files.zip
inflating: data.csv
inflating: stats.py
中身はこんな感じで、Pandasを使ってCSVを解析するというものになっている。(一部抜粋)
Name,Place,Animal,Thing
Betty Ramirez,Dallas,Elephant,Sofa
Jennifer Green,Naples,Bee,Shirt
John Lopez,Helsinki,Zebra,Wallet
Susan Gonzalez,Beijing,Chicken,Phone
(snip)
Andrew Clark,Brussels,Hamster,Ring
Donna Wilson,Seoul,Panda,Earrings
Thomas Wright,Moscow,Eagle,Toy
Mary Torres,Barcelona,Goose,Necklace
Richard Torres,London,Sheep,Pants
import pandas as pd
df = pd.read_csv('data.csv')
print(df.describe())
for column in df.columns:
print(f"\n--- Analyzing Column: {column} ---")
# データ型を確認
if pd.api.types.is_numeric_dtype(df[column]):
# 数値列の分析
print("Data Type: Numeric")
print(df[column].describe()) # 基本的な記述統計
# IQR(四分位範囲)を使用して外れ値を検出
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)][column]
if not outliers.empty:
print(f"Potential Outliers (IQR Method):\n{outliers}")
else:
print("No obvious outliers detected by IQR method.")
elif pd.api.types.is_string_dtype(df[column]) or pd.api.types.is_categorical_dtype(df[column]):
# カテゴリカル/テキスト列の分析
print("Data Type: Categorical/Text")
print(df[column].value_counts()) # 一意の値の頻度分布
else:
print("Data Type: Other (e.g., Datetime, Boolean)")
print(df[column].head()) # 最初の数値を表示して確認
これらをアップロードしてCode Interpreterで実行するスクリプト。ファイル名にagentとあるけど、シンプルにCode Interpreterで実行してるだけに見える。
from bedrock_agentcore.tools.code_interpreter_client import CodeInterpreter
import json
from typing import Dict, Any, List
#Code Interpreterセッションを開始
code_client = CodeInterpreter('us-east-1')
code_client.start()
#サンプルデータファイルの内容を読み込む
data_file = "data.csv"
try:
with open(data_file, 'r', encoding='utf-8') as data_file_content:
data_file_content = data_file_content.read()
#print(data_file_content)
except FileNotFoundError:
print(f"エラー: ファイル '{data_file}' が見つかりませんでした。")
except Exception as e:
print(f"エラーが発生しました: {e}")
#サンプルデータファイルを分析するPythonスクリプトの内容を読み込む
code_file = "stats.py"
try:
with open(code_file, 'r', encoding='utf-8') as code_file_content:
code_file_content = code_file_content.read()
#print(code_file_content)
except FileNotFoundError:
print(f"エラー: ファイル '{code_file}' が見つかりませんでした。")
except Exception as e:
print(f"エラーが発生しました: {e}")
files_to_create = [
{
"path": "data.csv",
"text": data_file_content
},
{
"path": "stats.py",
"text": code_file_content
}]
#invoke APIを呼び出すメソッドを定義
def call_tool(tool_name: str, arguments: Dict[str, Any]) -> Dict[str, Any]:
response = code_client.invoke(tool_name, arguments)
for event in response["stream"]:
return json.dumps(event["result"], indent=2)
#サンプルデータと分析スクリプトの内容をCode Interpreterセッションに書き込む
writing_files = call_tool("writeFiles", {"content": files_to_create})
print(f"書き込むファイル: {writing_files}")
#ファイルが正常に書き込まれたことをリストで確認
listing_files = call_tool("listFiles", {"path": ""})
print(f"ファイル一覧: {listing_files}")
#Pythonスクリプトを実行してサンプルデータファイルを分析
execute_code = call_tool(
"executeCode", {
"code": files_to_create[1]['text'],
"language": "python",
"clearContext": True
}
)
print(f"コード実行結果: {execute_code}")
#Code Interpreterセッションを停止
code_client.stop()
実行
uv run file_mgmt_ci_agent.py
結果
書き込むファイル: {
"content": [
{
"type": "text",
"text": "Successfully wrote all 2 files"
}
],
"isError": false
}
ファイル一覧: {
"content": [
{
"type": "resource_link",
"uri": "file:///log",
"name": "log",
"description": "Directory"
},
{
"type": "resource_link",
"mimeType": "text/csv",
"uri": "file:///data.csv",
"name": "data.csv",
"description": "File"
},
{
"type": "resource_link",
"mimeType": "text/x-python",
"uri": "file:///stats.py",
"name": "stats.py",
"description": "File"
},
{
"type": "resource_link",
"uri": "file:///.ipython",
"name": ".ipython",
"description": "Directory"
}
],
"isError": false
}
コード実行結果: {
"content": [
{
"type": "text",
"text": "Name Place Animal Thing\ncount 299130 299130 299130 299130\nunique 1722 55 50 51\ntop Lisa White Prague Goat Pencil\nfreq 222 5587 6141 6058\n\n--- Analyzing Column: Name ---\nData Type: Categorical/Text\nLisa White 222\nSarah Perez 212\nSusan Green 211\nLisa Flores 211\nChristopher Ramirez 210\n ... \nKimberly Moore 140\nJames Flores 137\nJoshua Martinez 132\nLinda Allen 132\nDonald Jackson 120\nName: Name, Length: 1722, dtype: int64\n\n--- Analyzing Column: Place ---\nData Type: Categorical/Text\nPrague 5587\nSeoul 5580\nMumbai 5577\nAmsterdam 5570\nIstanbul 5547\nAtlanta 5546\nLima 5545\nNew York 5542\nMiami 5539\nTokyo 5517\nRome 5511\nSingapore 5511\nNaples 5509\nCairo 5499\nSydney 5493\nLos Angeles 5493\nBerlin 5492\nBrussels 5487\nGeneva 5482\nCopenhagen 5478\nNashville 5473\nDublin 5473\nLas Vegas 5472\nLondon 5466\nBeijing 5464\nMadrid 5460\nStockholm 5457\nSan Francisco 5453\nBangkok 5452\nZurich 5451\nMilan 5429\nVienna 5426\nAthens 5420\nAustin 5416\nVenice 5415\nFlorence 5412\nPortland 5409\nDallas 5408\nBuenos Aires 5407\nBoston 5383\nMexico City 5374\nHelsinki 5374\nBarcelona 5372\nDenver 5369\nChicago 5350\nMoscow 5349\nDubai 5342\nOslo 5332\nSeattle 5331\nParis 5317\nHouston 5304\nCape Town 5291\nRio de Janeiro 5284\nToronto 5254\nPhoenix 5236\nName: Place, dtype: int64\n\n--- Analyzing Column: Animal ---\nData Type: Categorical/Text\nGoat 6141\nPig 6109\nHamster 6107\nWolf 6103\nPanda 6103\nPenguin 6088\nSheep 6086\nOwl 6083\nWhale 6082\nTurtle 6075\nRabbit 6057\nCow 6045\nKoala 6039\nTiger 6035\nTurkey 6030\nButterfly 6029\nGiraffe 6028\nGoose 6027\nKangaroo 6021\nCat 6019\nBear 6006\nElephant 6004\nDeer 6001\nOctopus 5997\nSquirrel 5989\nParrot 5986\nBee 5980\nGuinea Pig 5980\nChicken 5980\nGoldfish 5964\nLizard 5962\nCrocodile 5953\nAnt 5950\nDolphin 5948\nFox 5947\nLion 5942\nDuck 5939\nZebra 5933\nSpider 5912\nSnake 5912\nDog 5891\nMonkey 5891\nMouse 5882\nFrog 5878\nHawk 5877\nRaccoon 5868\nEagle 5847\nHorse 5833\nRat 5810\nShark 5761\nName: Animal, dtype: int64\n\n--- Analyzing Column: Thing ---\nData Type: Categorical/Text\nPencil 6058\nDress 6044\nBowl 5988\nPen 5978\nBall 5970\nGame 5958\nBasket 5952\nPhone 5929\nEarrings 5926\nKnife 5922\nVase 5920\nShirt 5919\nKeys 5917\nBook 5917\nCan 5912\nTable 5910\nBottle 5909\nCoat 5905\nJacket 5901\nRing 5894\nNotebook 5892\nBlanket 5883\nWallet 5883\nComputer 5879\nCup 5869\nPants 5865\nClock 5857\nPicture 5855\nSofa 5851\nGlasses 5850\nBracelet 5844\nBackpack 5834\nPillow 5821\nSpoon 5817\nBed 5814\nNecklace 5811\nBox 5808\nToy 5801\nShoes 5800\nChair 5794\nFork 5789\nMirror 5787\nLamp 5784\nSculpture 5784\nHat 5780\nBag 5779\nWatch 5776\nPlate 5764\nPainting 5757\nUmbrella 5753\nCandle 5720\nName: Thing, dtype: int64"
}
],
"structuredContent": {
"stdout": "Name Place Animal Thing\ncount 299130 299130 299130 299130\nunique 1722 55 50 51\ntop Lisa White Prague Goat Pencil\nfreq 222 5587 6141 6058\n\n--- Analyzing Column: Name ---\nData Type: Categorical/Text\nLisa White 222\nSarah Perez 212\nSusan Green 211\nLisa Flores 211\nChristopher Ramirez 210\n ... \nKimberly Moore 140\nJames Flores 137\nJoshua Martinez 132\nLinda Allen 132\nDonald Jackson 120\nName: Name, Length: 1722, dtype: int64\n\n--- Analyzing Column: Place ---\nData Type: Categorical/Text\nPrague 5587\nSeoul 5580\nMumbai 5577\nAmsterdam 5570\nIstanbul 5547\nAtlanta 5546\nLima 5545\nNew York 5542\nMiami 5539\nTokyo 5517\nRome 5511\nSingapore 5511\nNaples 5509\nCairo 5499\nSydney 5493\nLos Angeles 5493\nBerlin 5492\nBrussels 5487\nGeneva 5482\nCopenhagen 5478\nNashville 5473\nDublin 5473\nLas Vegas 5472\nLondon 5466\nBeijing 5464\nMadrid 5460\nStockholm 5457\nSan Francisco 5453\nBangkok 5452\nZurich 5451\nMilan 5429\nVienna 5426\nAthens 5420\nAustin 5416\nVenice 5415\nFlorence 5412\nPortland 5409\nDallas 5408\nBuenos Aires 5407\nBoston 5383\nMexico City 5374\nHelsinki 5374\nBarcelona 5372\nDenver 5369\nChicago 5350\nMoscow 5349\nDubai 5342\nOslo 5332\nSeattle 5331\nParis 5317\nHouston 5304\nCape Town 5291\nRio de Janeiro 5284\nToronto 5254\nPhoenix 5236\nName: Place, dtype: int64\n\n--- Analyzing Column: Animal ---\nData Type: Categorical/Text\nGoat 6141\nPig 6109\nHamster 6107\nWolf 6103\nPanda 6103\nPenguin 6088\nSheep 6086\nOwl 6083\nWhale 6082\nTurtle 6075\nRabbit 6057\nCow 6045\nKoala 6039\nTiger 6035\nTurkey 6030\nButterfly 6029\nGiraffe 6028\nGoose 6027\nKangaroo 6021\nCat 6019\nBear 6006\nElephant 6004\nDeer 6001\nOctopus 5997\nSquirrel 5989\nParrot 5986\nBee 5980\nGuinea Pig 5980\nChicken 5980\nGoldfish 5964\nLizard 5962\nCrocodile 5953\nAnt 5950\nDolphin 5948\nFox 5947\nLion 5942\nDuck 5939\nZebra 5933\nSpider 5912\nSnake 5912\nDog 5891\nMonkey 5891\nMouse 5882\nFrog 5878\nHawk 5877\nRaccoon 5868\nEagle 5847\nHorse 5833\nRat 5810\nShark 5761\nName: Animal, dtype: int64\n\n--- Analyzing Column: Thing ---\nData Type: Categorical/Text\nPencil 6058\nDress 6044\nBowl 5988\nPen 5978\nBall 5970\nGame 5958\nBasket 5952\nPhone 5929\nEarrings 5926\nKnife 5922\nVase 5920\nShirt 5919\nKeys 5917\nBook 5917\nCan 5912\nTable 5910\nBottle 5909\nCoat 5905\nJacket 5901\nRing 5894\nNotebook 5892\nBlanket 5883\nWallet 5883\nComputer 5879\nCup 5869\nPants 5865\nClock 5857\nPicture 5855\nSofa 5851\nGlasses 5850\nBracelet 5844\nBackpack 5834\nPillow 5821\nSpoon 5817\nBed 5814\nNecklace 5811\nBox 5808\nToy 5801\nShoes 5800\nChair 5794\nFork 5789\nMirror 5787\nLamp 5784\nSculpture 5784\nHat 5780\nBag 5779\nWatch 5776\nPlate 5764\nPainting 5757\nUmbrella 5753\nCandle 5720\nName: Thing, dtype: int64",
"stderr": "",
"exitCode": 0,
"executionTime": 0.7842898368835449
},
"isError": false
}
ちょっと見にくいけど、Pandasのデータフレームっぽい出力になっているのがわかる。あと、内部的にはJupyter notebook的な環境になっているのかもね。
ターミナルコマンドを実行
カスタムなCode Interpreterツールを作成して、S3との間でファイルアップロード・ダウンロードを行えるようにする。
ドキュメントでは以下のような想定になっている。
- カスタムなCode Interpreterで、S3から
generate_csv.pyというPythonスクリプトをダウンロード。 - コマンドラインで上記のPythonスクリプトに引数を与えて実行
python generate_csv.py 5 10 - 実行結果は
generated_data.csvというファイルに出力される。 - この結果ファイルを S3にアップロードする。
ドキュメントには上記のスクリプトは用意されていなかったので、Dia にドキュメントを読ませつつ、作ってもらった。
import csv
import sys
# コマンドライン引数で行数と列数を指定
rows = int(sys.argv[1]) if len(sys.argv) > 1 else 5
cols = int(sys.argv[2]) if len(sys.argv) > 2 else 3
with open('generated_data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# ヘッダー
writer.writerow([f'col{i+1}' for i in range(cols)])
# データ
for r in range(rows):
writer.writerow([f'data{r+1}_{c+1}' for c in range(cols)])
ローカルでお試し実行してみる。
uv run generate_csv.py 5 10
generated_data.csvというファイルがこんな感じに作成される。
col1,col2,col3,col4,col5,col6,col7,col8,col9,col10
data1_1,data1_2,data1_3,data1_4,data1_5,data1_6,data1_7,data1_8,data1_9,data1_10
data2_1,data2_2,data2_3,data2_4,data2_5,data2_6,data2_7,data2_8,data2_9,data2_10
data3_1,data3_2,data3_3,data3_4,data3_5,data3_6,data3_7,data3_8,data3_9,data3_10
data4_1,data4_2,data4_3,data4_4,data4_5,data4_6,data4_7,data4_8,data4_9,data4_10
data5_1,data5_2,data5_3,data5_4,data5_5,data5_6,data5_7,data5_8,data5_9,data5_10
では、このスクリプトおよび結果を保持するためのS3バケットを作成する。今回はcodeinterpreterartifacts-kun432-20250802という名前にした。
# us-east-1以外の場合には以下を指定
# `--create-bucket-configuration LocationConstraint=<リージョン名>`
aws s3api create-bucket \
--bucket codeinterpreterartifacts-kun432-20250802 \
--region us-east-1
PythonスクリプトをS3にアップロードしておく。
aws s3 cp generate_csv.py s3://codeinterpreterartifacts-kun432-20250802/
Code Interpreter から S3アクセスを許可させるための IAMロールを作成。
cat <<EOF > trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock-agentcore.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
cat <<EOF > permissions-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::codeinterpreterartifacts-kun432-20250802/*"
}
]
}
EOF
aws iam create-policy \
--policy-name BedrockAgentCore-CodeInterpreter-S3Policy \
--policy-document file://permissions-policy.json
aws iam create-role \
--role-name BedrockAgentCore-CodeInterpreter-S3Role \
--assume-role-policy-document file://trust-policy.json
AWS_ACCOUNT_ID=XXXXXXXXXXXX
aws iam attach-role-policy \
--role-name BedrockAgentCore-CodeInterpreter-S3Role \
--policy-arn "arn:aws:iam::${AWS_ACCOUNT_ID}:policy/BedrockAgentCore-CodeInterpreter-S3Policy"
ロールのARNを確認
aws iam get-role --role-name BedrockAgentCore-CodeInterpreter-S3Role \
--query 'Role.Arn' --output text
arn:aws:iam::XXXXXXXXXXXX:role/BedrockAgentCore-CodeInterpreter-S3Role
ではコード。
import boto3
import json
import time
REGION = "us-east-1"
CP_ENDPOINT_URL = f"https://bedrock-agentcore-control.{REGION}.amazonaws.com"
DP_ENDPOINT_URL = f"https://bedrock-agentcore.{REGION}.amazonaws.com"
# S3バケット名
S3_BUCKET_NAME = "codeinterpreterartifacts-kun432-20250802"
# IAMロールARN
IAM_ROLE_ARN = "arn:aws:iam::XXXXXXXXXXXX:role/BedrockAgentCore-CodeInterpreter-S3Role"
bedrock_agentcore_control_client = boto3.client(
'bedrock-agentcore-control',
region_name=REGION,
endpoint_url=CP_ENDPOINT_URL
)
bedrock_agentcore_client = boto3.client(
'bedrock-agentcore',
region_name=REGION,
endpoint_url=DP_ENDPOINT_URL
)
# カスタムなCode Interpreterを作成
unique_name = f"s3InteractionEnv_{int(time.time())}"
create_response = bedrock_agentcore_control_client.create_code_interpreter(
name=unique_name,
description="Combined test code sandbox",
executionRoleArn=IAM_ROLE_ARN,
# Code Interpreterがパブリックなインターネットにアクセスする必要がある場合は"PUBLIC"を指定
# パブリックなインターネットにアクセスする必要がない場合は"SANDBOX"を指定
networkConfiguration={
"networkMode": "SANDBOX"
}
)
code_interpreter_id = create_response['codeInterpreterId']
print(f"作成したカスタムCode Interpreter ID: {code_interpreter_id}")
# Code Interpreterセッションを開始
session_response = bedrock_agentcore_client.start_code_interpreter_session(
codeInterpreterIdentifier=code_interpreter_id,
name="combined-test-session",
sessionTimeoutSeconds=1800
)
session_id = session_response['sessionId']
print(f"作成したセッションID: {session_id}")
print(f"S3からCSV生成スクリプトをダウンロード")
command_to_execute = f"aws s3 cp s3://{S3_BUCKET_NAME}/generate_csv.py ."
response = bedrock_agentcore_client.invoke_code_interpreter(
codeInterpreterIdentifier=code_interpreter_id,
sessionId=session_id,
name="executeCommand",
arguments={
"command": command_to_execute
}
)
for event in response["stream"]:
print(json.dumps(event["result"], default=str, indent=2))
print(f"CSV生成スクリプトを実行")
response = bedrock_agentcore_client.invoke_code_interpreter(
codeInterpreterIdentifier=code_interpreter_id,
sessionId=session_id,
name="executeCommand",
arguments={
"command": "python generate_csv.py 5 10"
}
)
for event in response["stream"]:
print(json.dumps(event["result"], default=str, indent=2))
print(f"生成されたアーティファクトをS3にアップロード")
command_to_execute = f"aws s3 cp generated_data.csv s3://{S3_BUCKET_NAME}/output_artifacts/"
response = bedrock_agentcore_client.invoke_code_interpreter(
codeInterpreterIdentifier=code_interpreter_id,
sessionId=session_id,
name="executeCommand",
arguments={
"command": command_to_execute
}
)
for event in response["stream"]:
print(json.dumps(event["result"], default=str, indent=2))
print(f"Code Interpreterセッションを停止")
stop_response = bedrock_agentcore_client.stop_code_interpreter_session(
codeInterpreterIdentifier=code_interpreter_id,
sessionId=session_id
)
print(f"Code Interpreterを削除")
delete_response = bedrock_agentcore_control_client.delete_code_interpreter(
codeInterpreterId=code_interpreter_id
)
print(f"Code Interpreterの応答ステータス: {delete_response['status']}")
print(f"クリーンアップが完了しました、スクリプトの実行が成功しました")
実行
uv run custom_ci_s3.py
結果
作成したカスタムCode Interpreter ID: s3InteractionEnv_1754141337-mmujaBgRvr
作成したセッションID: 01K1NFHC06K3G7G6E74RANV92M
S3からCSV生成スクリプトをダウンロード
{
"content": [
{
"type": "text",
"text": "Completed 462 Bytes/462 Bytes (9.0 KiB/s) with 1 file(s) remaining\rdownload: s3://codeinterpreterartifacts-kun432-20250802/generate_csv.py to ./generate_csv.py\r\n"
}
],
"structuredContent": {
"stdout": "Completed 462 Bytes/462 Bytes (9.0 KiB/s) with 1 file(s) remaining\rdownload: s3://codeinterpreterartifacts-kun432-20250802/generate_csv.py to ./generate_csv.py\r\n",
"stderr": "",
"exitCode": 0,
"executionTime": 1.0490565299987793
},
"isError": false
}
CSV生成スクリプトを実行
{
"content": [],
"structuredContent": {
"stdout": "",
"stderr": "",
"exitCode": 0,
"executionTime": 0.06273937225341797
},
"isError": false
}
生成されたアーティファクトをS3にアップロード
{
"content": [
{
"type": "text",
"text": "Completed 462 Bytes/462 Bytes (6.3 KiB/s) with 1 file(s) remaining\rupload: ./generated_data.csv to s3://codeinterpreterartifacts-kun432-20250802/output_artifacts/generated_data.csv\r\n"
}
],
"structuredContent": {
"stdout": "Completed 462 Bytes/462 Bytes (6.3 KiB/s) with 1 file(s) remaining\rupload: ./generated_data.csv to s3://codeinterpreterartifacts-kun432-20250802/output_artifacts/generated_data.csv\r\n",
"stderr": "",
"exitCode": 0,
"executionTime": 0.5230810642242432
},
"isError": false
}
Code Interpreterセッションを停止
Code Interpreterを削除
Code Interpreterの応答ステータス: DELETED
クリーンアップが完了しました、スクリプトの実行が成功しました
確認
aws s3 ls s3://codeinterpreterartifacts-kun432-20250802 --recursive
2025-08-02 22:22:11 462 generate_csv.py
2025-08-02 22:29:05 462 output_artifacts/generated_data.csv
aws s3 cp s3://codeinterpreterartifacts-kun432-20250802/output_artifacts/generated_data.csv -
col1,col2,col3,col4,col5,col6,col7,col8,col9,col10
data1_1,data1_2,data1_3,data1_4,data1_5,data1_6,data1_7,data1_8,data1_9,data1_10
data2_1,data2_2,data2_3,data2_4,data2_5,data2_6,data2_7,data2_8,data2_9,data2_10
data3_1,data3_2,data3_3,data3_4,data3_5,data3_6,data3_7,data3_8,data3_9,data3_10
data4_1,data4_2,data4_3,data4_4,data4_5,data4_6,data4_7,data4_8,data4_9,data4_10
data5_1,data5_2,data5_3,data5_4,data5_5,data5_6,data5_7,data5_8,data5_9,data5_10
リソースとセッションの管理
Code Interpreterでは、リソースとセッションを管理して、使うことになる。ここでいう「リソース」と「セッション」はざっくり以下となる
- リソース: Code Interpreterそのものを管理
- セッション: 1回のCode Interpreter実行を管理
リソース管理
Code Interpreterは2種類のリソースが用意されている。
| 種類 | システムARN(デフォルト) | カスタムARN(カスタム作成) |
|---|---|---|
| 作成者 | AWSがあらかじめ用意 | ユーザー自身で作成 |
| 設定 | 一番厳しい(デフォルト) | ネットワークや実行ロールを自由に設定可 |
| ネットワーク | 固定(サンドボックス、外部アクセス不可) | サンドボックス or パブリックから選択 |
| 利用可能リージョン | 全リージョン | 作成したリージョン |
| ARN | 固定 | ユーザーがリソース作成時に生成される |
| 主な用途 | すぐ使いたい・安全重視 | 独自の要件や外部連携が必要な場合 |
※システムARNのARNは arn:aws:bedrock-agentcore:<リージョン>:aws:code-interpreter/aws.codeinterpreter.v1
また、ネットワーク設定については以下の2つがある
| 条件 | サンドボックスモード | パブリックネットワークモード |
|---|---|---|
| 外部アクセス | できない(完全隔離) | できる(インターネットOK) |
| セキュリティ | 超安全 | リスク高め(外部とつながるため注意) |
| 主な用途 | 内部データ処理・セキュリティ重視 | 外部APIやサービスと連携したいとき |
| デメリット | 外部サービスに一切アクセス不可 | セキュリティ対策が必要 |
これらを踏まえて、Code Interpreterを使用する場合の一連の流れは、ビルトインを使う場合とカスタムの場合で以下のようになる。
-
ビルトインの場合
- エージェントにシステムARNのIDを組み込む
- すでに用意されているCode Interpreterをそのまま使うだけ
- エージェントがリアルタイムでコード実行できるようになる
- セッションを開始する
⁃ デフォルトで15分間(設定で変更可能)
⁃ 複数のセッションを同時に動かすこともできる - セッション内でコードを実行する
⁃ Python、JavaScript、TypeScriptが使える
⁃ ファイルのアップロード・ダウンロード、シェルコマンド、AWS CLIコマンドも利用可能 - セッション終了後、リソースを解放する
⁃ 使い終わったらセッションを停止
⁃ システムARNの場合はリソース自体の削除は不要
- エージェントにシステムARNのIDを組み込む
-
カスタムの場合
- Code Interpreterリソースを作成
⁃ ネットワーク設定(サンドボックス or パブリック)を選ぶ
⁃ 実行ロール(どのAWSリソースにアクセスできるか)を設定 - エージェントにCode InterpreterのIDを組み込む
⁃ エージェントがリアルタイムでコード実行できるようになる - セッションを開始する
⁃ デフォルトで15分間(設定で変更可能)
⁃ 複数のセッションを同時に動かすこともできる - セッション内でコードを実行する
⁃ Python、JavaScript、TypeScriptが使える- ファイルのアップロード・ダウンロード、シェルコマンド、AWS CLIコマンドも利用可能
- セッション終了後、リソースを解放する
⁃ 使い終わったらセッションを停止 - Code Interpreterリソースを削除
⁃ 不要ならばCode Interpreter自体を削除できる
- Code Interpreterリソースを作成
よって、Code Interpreterの実行、およびカスタムの場合は作成・削除などの権限がエージェントには必要になる。ドキュメントのIAM権限のサンプルは以下となっていた。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock-agentcore:CreateCodeInterpreter",
"bedrock-agentcore:StartCodeInterpreterSession",
"bedrock-agentcore:InvokeCodeInterpreter",
"bedrock-agentcore:StopCodeInterpreterSession",
"bedrock-agentcore:DeleteCodeInterpreter",
"bedrock-agentcore:ListCodeInterpreters",
"bedrock-agentcore:GetCodeInterpreter",
"bedrock-agentcore:GetCodeInterpreterSession",
"bedrock-agentcore:ListCodeInterpreterSessions"
],
"Resource": "arn:aws:bedrock-agentcore:*"
}
]
}
セッション管理
セッションの特徴
- セッションタイムアウト
- デフォルトは15分(900秒)
- セッション作成時に最長8時間まで延長可能
- セッションの持続性
- セッション中に作ったファイルやデータは、そのセッションが続いてる間はずっと使える。
- セッションが終わると全部消える
- 自動終了
- 設定した時間が過ぎたら、セッションは自動で終了する。
- 複数セッション
- 1つのCode Interpreterで、複数のセッションを同時に動かせる。
- それぞれのセッションは独立しており、状態やデータも別々になる
- データ保持ポリシー
- セッションデータの保持期間(TTL)は30日間。
セッションの隔離(アイソレーション)
- 各セッションは専用の「マイクロVM」といういう小さな仮想マシンで動いてる。
- CPU、メモリ、ファイルシステムも全部分かれており、他のユーザーのデータにはアクセスできない。
- セッションが終わったら、そのマイクロVMは完全に消去されて、データも全部消える。
- 他のセッションとデータが混ざったり漏れたりする心配はない
その他、ドキュメントには、リソース・セッションの細かい操作について AWS CLI / Boto3 / API それぞれでの例や、APIリファレンスがある。
次は Browser。