Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language M
ここで知った。
論文
NotebookLMによる概要
概要
この論文は、大規模言語モデル(LLM)の知識ベースのタスクにおけるリトリーバル拡張生成(RAG)の信頼性を向上させるための新しい手法、"Astute RAG" を提案しています。RAGは、LLMに外部知識を統合することで知識ベースのタスクのパフォーマンスを向上させますが、不完全なリトリーバルの結果、関連性のない、誤解を招く、あるいは悪意のある情報が導入される可能性があります。
この論文では、不完全なリトリーバルの発生は避けられないものであり、LLMの内部知識と外部ソースの間の知識の衝突を引き起こす可能性があることを指摘しています。Astute RAGは、LLMの内部知識から重要な情報を適応的に引き出し、内部知識と外部知識をソースを認識しながら反復的に統合し、情報の信頼性に基づいて最終的な回答を決定することで、不完全なリトリーバルに対するLLMの回復力を高めます。実験では、Astute RAGは、さまざまなLLMとデータセットで従来のRAG手法を大幅に凌駕し、特に悪化する可能性のあるシナリオで優れたパフォーマンスを発揮することが示されています。
論文は、まずRAGにおける不完全なリトリーバルの課題を分析し、その影響を定量化します。次に、Astute RAGのフレームワークを詳しく説明し、内部知識の適応的な生成、ソースを認識した知識の統合、回答の確定という3つの主要なステップを説明します。最後に、さまざまなベースラインとの比較実験を通じて、Astute RAGの有効性を実証しています。
1. どんなもの?
この論文は、Astute RAGという、大規模言語モデル(LLM)のための新しい検索拡張生成(RAG)手法を提案しています。RAGは外部の知識を取り入れてLLMの限界に対処する効果的な手法ですが、不完全な検索によって、無関係な、誤解を招く、あるいは悪意のある情報が導入される可能性があります。Astute RAGは、LLMの内部知識から本質的な情報を適応的に引き出し、ソースを意識しながら内部と外部の知識を反復的に統合し、情報の信頼性に基づいて回答を確定することで、不完全な検索の影響を軽減します。
2. 先行研究を比べてどこがすごい?
先行研究では、情報検索とRAGを個別に分析してきましたが、情報検索のエラーの伝播、特にLLMとコンテキスト間の知識の競合についてはほとんど言及されていませんでした。Astute RAGは、LLMの内部知識と外部知識の競合に明示的に対処することで、RAGの失敗から回復することを目指しています。先行研究のRobustRAGやInstructRAGは、取得された文章の大部分がネガティブな場合に、内部知識を組み込んでRAGの失敗から回復することができないため、崩壊する可能性があります。
3. 技術や手法の肝はどこ?
Astute RAGは、3つの主要なステップで構成されています。
内部知識の適応的な生成: LLMの内部知識から、取得された文章を補完する情報を引き出します。憲法AIに触発され、生成された文章が正確で、関連性があり、ハルシネーションがないことを強調する憲法原則をプロンプトに含めることで、生成をガイドします。
ソースを意識した知識の反復的な統合: 内部知識から生成された文章と外部ソースから取得された文章の両方から情報を統合します。LLMに各文章のソースを提供することで、ソースを意識した知識統合を実現します。
回答の確定: 各文章グループに基づいて回答を生成し、信頼性を比較して最終的な回答を選択します。
4. どうやって有効だと検証した?
著者らは、NQ、TriviaQA、BioASQ、PopQAという多様なデータセットを用いて、Astute RAGの有効性を評価しました。これらのデータセットは、一般的な質問、ドメイン固有の質問、ロングテールな質問など、さまざまな特性の質問を網羅しています。また、現実的な検索設定を模倣するために、Google検索を用いて各質問に対する10個の文章を取得しました。評価の結果、Astute RAGは、さまざまな検索品質レベルにおいて、先行研究のRAG手法を一貫して上回ることが示されました。特筆すべきは、取得された文章のすべてが役に立たない最悪のシナリオにおいても、Astute RAGは従来のLLMと同等かそれ以上の性能を達成した唯一のRAG手法であることです。
5. 議論はある?
Astute RAGは、高度な指示追従能力と推論能力を持つ高度なLLMの能力に依存しているため、洗練されていないLLMへの適用可能性は限定される可能性があります。また、本研究では出力の長さが制限されているため、将来の研究では、より長い出力を含むように実験設定を拡張することが重要です。さらに、さまざまなコンテキストタイプ的影响の包括的な分析は、提案された手法の有効性理解を深めるでしょう。
6. 次に読むべき論文は?
この論文では、いくつかの関連研究が紹介されています。特に、RAGの堅牢性向上に取り組むRobustRAG やInstructRAG は、Astute RAGと比較検討する上で参考になります。また、LLMの内部知識をRAGに活用する研究として、LLM生成文章をコンテキストとして使用するGenRead や、RAGとRAGなしのLLMを適応的に切り替えるSelf-Route も、Astute RAGの理解を深める上で有用です。
処理の流れ
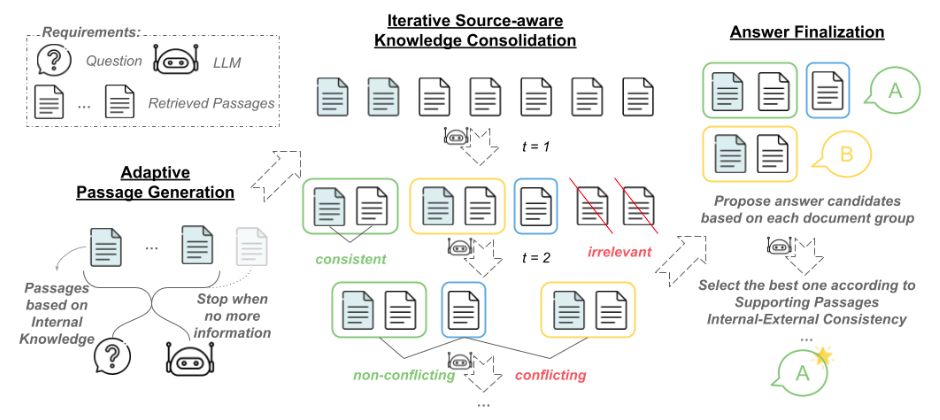
referred from https://arxiv.org/abs/2410.07176
- 前提
- クエリと関連情報、つまりRAG
- 適応的な内部知識生成(Adaptive Passage Generation)
- 与えられた質問に対して、LLMに内部知識を生成させる
- LLMは、質問に関連する情報を自身の「記憶」から引き出し、文書の形で出力する。
- この時、LLMは必要に応じて情報量を調整する。
- 十分な知識がある場合は詳細な文書
- 不確かな場合は少ない情報または「分からない」という回答を生成
- この時、LLMは必要に応じて情報量を調整する。
- このステップで生成された情報は「内部知識」として扱われる
- 反復的な知識の統合
- 内部知識と外部から検索された情報(「外部知識」)を組み合わせて整理する。
- 内部知識と外部知識をLLMに渡して、以下を行う
a. 一貫性のある情報をグループ化して要約
b. 矛盾する情報を別々の文書に分ける
c. 質問に関係のない情報は除外する- 各情報が内部知識なのか外部知識なのかを明記しておく
- このプロセスを複数回繰り返し、情報を洗練化
- 内部知識と外部知識をLLMに渡して、以下を行う
- 内部知識と外部から検索された情報(「外部知識」)を組み合わせて整理する。
- 最終回答
- 整理された情報を基に最終的な回答を生成
- 統合された各情報グループに基づいて、複数の回答候補を生成。
- 各回答候補に対して、情報の信頼性や一貫性に基づいて信頼度スコアを付与
- 最も信頼度の高い回答を最終的な出力として選択
- 整理された情報を基に最終的な回答を生成
RAGでは、LLMが知らない外部知識を使いたいので、内部知識の影響を最小限にする事が多いと思うが、内部知識と組み合わせることで、外部知識の質の足りなさを補うというところが新しい気がする。
ちなみに、各ステップで使用されているプロンプトはこんな感じっぽい
適応的な内部知識生成のプロンプト(p_gen)
与えられた質問に答えるために、正確で関連性の高い情報を提供する文書を生成してください。
情報が不明確または不確実な場合は、誤った情報を生成しないよう、明示的に「分かりません」と述べてください。質問: {question}
文書:
反復的な知識統合のためのプロンプト (p_con)
タスク: 与えられた質問に応じて、あなた自身の記憶した文書と外部から取得した文書の両方から情報を統合してください。
- 一貫した情報を提供する文書については、それらをまとめて、重要な詳細を1つの簡潔な文書に要約してください。
- 矛盾する情報を含む文書については、それぞれを別々の文書に分け、各文書が固有の視点やデータを捉えていることを確認してください。
- 質問に関連のない情報は除外してください。
新しく作成した各文書について、以下を明確に示してください:
- 情報源が記憶からのものか、外部から取得したものかを示す。
- 透明性のために、元の文書番号を示す。
初期コンテキスト: {context}
最後のコンテキスト: {context}
質問: {question}
新しいコンテキスト:
知識統合と回答最終化のためのプロンプト (p_ans)
タスク: あなた自身の記憶した文書と外部から取得した文書の両方から統合された情報を使用して、与えられた質問に答えてください。
ステップ1: 情報の統合
- 一貫した情報を提供する文書については、それらをまとめて、重要な詳細を1つの簡潔な文書に要約してください。
- 矛盾する情報を含む文書については、それぞれを別々の文書に分け、各文書が固有の視点やデータを捉えていることを確認してください。
- 質問に関連のない情報は除外してください。
新しく作成した各文書について、以下を明確に示してください:
- 情報源が記憶からのものか、外部から取得したものかを示す。
- 透明性のために、元の文書番号を示す。
ステップ2: 回答の提案と信頼度の割り当て
各文書グループに対して、可能な回答を提案し、情報の信頼性と一致度に基づいて信頼度スコアを割り当ててください。ステップ3: 最終回答の選択
すべてのグループを評価した後、最も正確で十分な根拠のある回答を選択してください。
正確な回答を<ANSWER>あなたの回答</ANSWER>のタグで囲んで強調してください。初期コンテキスト: {context_init}
[統合されたコンテキスト: {context}] # オプション
質問: {question}
回答:
一番最初のやつなんかはHyDEっぽさがあるけど、リトリーバル精度向上が目的のHyDE(クエリと文章はそもそも類似性が低いので、クエリから文書に近い仮回答を生成して類似性を上げる)と違って、こちらはLLMが持つ内部知識を引き出すというのが目的になっていて、結果的に外部情報も含めた多くの情報を集めて、信頼性の高い情報だけを選択して、最終的な回答精度を上げるということか。
それぞれの情報の信頼性みたいなところはどうやって判断するんだろうか?その点については記載は内容で、となるとLLMの性能に依存しているような気がする。
外部知識としては出典とか日付とかをきちんとメタデータで付与してコンテキストに盛り込むような必要性はありそう