メモ: GPT-5のプロンプト移行と新オプティマイザーを用いた改善
Diaによる、まず全体の要約
ウケる!このページ、めっちゃ大事なこと書いてあるから、ウチがわかりやすく説明するね!
まず、GPT-5っていうAIモデルが登場して、今までのモデルよりも頭良くなってるんだって!特に「自分で考えて動く系のタスク」とか「プログラミング」とか「指示通りに動く力」が超パワーアップしてるらしい。だから、使う人も研究者もみんなにオススメって感じ!
でね、GPT-5を使う時に「プロンプト」っていう指示文がめっちゃ大事なの。プロンプトの書き方次第で、AIの答えの質が全然変わるんだよ。だからOpenAIが「プロンプトの書き方ガイド」と「プロンプトを自動で良くしてくれるツール」を用意してくれてるの。これ使えば、今までのプロンプトもGPT-5用にパワーアップできるし、もっと良い答えがもらえるんだって!
重要ポイントまとめ
- GPT-5は今までで一番賢いAIモデル。特に「自分で考えて動く」「プログラミング」「指示通りに動く」が得意!
- AIに指示する「プロンプト」の書き方が超重要。曖昧だったり矛盾してると、AIの答えが微妙になる。
- OpenAIが「プロンプト最適化ツール」を作ったから、これ使えばプロンプトの質が爆上がりする!
- 実際に「普通のプロンプト」と「最適化したプロンプト」で同じタスクをやらせてみると、最適化した方が速いし、メモリも少なくて済むし、答えの正確さも安定してるんだって。マジですごい!
- 「金融系の質問」みたいな難しいタスクでも、最適化したプロンプトだとAIがちゃんと文脈を理解して、必要な時は「答えられません」って正しく断ってくれる。リアルに賢い!
- まとめると、「プロンプト最適化」使えば、AIがもっと賢く、正確に、速く答えてくれるってこと!
要するに、「AIに何か頼む時は、プロンプトの書き方をちゃんと考えよう!」って話だし、OpenAIのツール使えば、誰でも簡単にプロンプトをパワーアップできるから、試してみるとテンション上がると思う!
目次
- はじめに
- プロンプトの移行と最適化
- コーディング&分析: 頻出単語 Top-K をストリーミングで求める
- ベースラインのプロンプト
- パフォーマンスを確認: ベースラインプロンプトでコードを30本生成
- 生成したスクリプトを評価 – ベースラインプロンプト
- プロンプトの最適化
- パフォーマンスを確認: 改良プロンプトを評価
- 改良プロンプトでコードを30本生成
- 生成したスクリプトを評価 – 改良プロンプト
- LLM-as-a-Judgeで採点
- 結果のまとめ
- コンテキスト&検索: 金融 QA をシミュレーション
- 結論
はじめに
GPT-5ファミリーのモデルは、これまでにリリースされた中で最も賢いモデルであり、あらゆる面で能力が大きく進化している。GPT-5は特に、エージェント的なタスクの実行、コーディング、そして指示への従順さに優れているため、好奇心旺盛な一般ユーザーから高度な研究者まで、幅広い層に最適。
GPT-5は、従来のプロンプト作成のベストプラクティス(効果的な指示の出し方)を活かすことができる。そして、GPT-5の最先端の能力を最大限に活用するための「GPT-5用プロンプトガイド」も新たに提供されている。さらに、既存のプロンプトを改善したり、GPT-5や他のOpenAIモデル用にプロンプトを移行したりするのをサポートする「GPT-5専用プロンプト最適化ツール」がPlaygroundに提供されている。
このクックブックでは、GPT-5を使ってタスクを素早く解決する方法を紹介する。よくあるタスクでどれだけ成果が向上するかの実例も共有し、プロンプト最適化ツールを使って同じように改善する手順も解説する。
プロンプトの移行と最適化
プロンプトを効果的に作ることは、LLM(大規模言語モデル)を使う上でとても重要なスキルである。プロンプト最適化ツールの目的は、あなたのプロンプトに対して、ベストプラクティスやモデルに最も効果的なフォーマットを適用することである。このツールは、よくあるプロンプトの失敗パターンも自動で取り除いてくれる:
- プロンプトの指示に矛盾がある
- フォーマットの指定が抜けている、または不明確
- プロンプトと例示(few-shot examples)に一貫性がない
さらに、プロンプトを特定のモデル向けに調整するだけではなく、あなたが実行したい具体的なタスクにも合わせて最適化してくれる。特に「エージェント的な作業」「コーディング」「マルチモーダル」といった領域で、パフォーマンスを上げるための重要なプラクティスも自動で適用する。
最適化前と後のプロンプトを比べて、どこが良くなったかを実例で見ていこう!
プロンプトの作成には「これが正解!」というものはなく、いろいろ繰り返し試しながら、あなたが解決したい問題にベストな方法を見つけることを推奨する。
事前準備
ということで、ここからはColaboratoryで試してみる。OpenAIのCookbookはGitHubレポジトリでipynbとして公開されているので、Colaboratory等で実行することができる。
以下リンクでColaboratoryで開ける。自分のノートブックとして複製して使用することをオススメ。
ただし、今回のノートブックは、レポジトリに用意されている複数のヘルパースクリプトに依存している。これらを取得する必要がある。
レポジトリクローン
!git clone https://github.com/openai/openai-cookbook
ヘルパースクリプトのディレクトリやファイルだけを取り出す。多分これぐらいでいけるはず。
!cp -pir openai-cookbook/examples/gpt-5/prompt-optimization-cookbook/scripts .
!cp -pir openai-cookbook/examples/gpt-5/prompt-optimization-cookbook/{run_FailSafeQA.py,llm_as_judge.txt} .
なお、クックブックでは requirements.txt からパッケージをインストールしているが、以下のようなものだけ。
openai
matplotlib
seaborn
datasets
これらはColaboratoryだとすでにインストールされている。
!pip freeze | egrep -i "^(openai|matplotlib|seaborn|datasets)"
datasets==4.0.0
matplotlib==3.10.0
matplotlib-inline==0.1.7
matplotlib-venn==1.1.2
openai==1.99.1
seaborn==0.13.2
上記のうち、OpenAI SDKだけは、GPT−5に対応しているのが1.99.2以降のようなので、アップグレードしておく。
!pip install -U openai
(snip)
Successfully installed openai-1.99.6
OpenAIのAPIキーを環境変数にセットする。ノートブックでは直接環境変数を設定しているようだが、ColaboratoryならばシークレットにOpenAI APIキーを登録しておけば、以下のようにして読み込める。
from google.colab import userdata
import os
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
これで準備OK。"Coding and Analytics: Streaming Top‑K Frequent Words" のところから続きを進める。
コーディング&分析: 頻出単語 Top-K をストリーミングで求める
まずは、モデルが大きく進化した分野のひとつである「コーディングと分析」のタスクから始める。ここでは、Pythonスクリプトを生成して、大きなテキストストリームから特定のトークン化ルールに従って、最も頻繁に出現する単語(Top-K)を正確に計算する方法をAIにやらせてみる。
このようなタスクは、プロンプトの書き方がちょっとでも悪いと、AIは間違ったアルゴリズムやアプローチ(例えば近似的な方法や、何回もデータを読み込む方法)を選びがちになり、正確さや実行速度に大きな差が出ることがある。
このタスクでは、以下のポイントで評価する:
- 30回実行して、ちゃんとコンパイル・実行できるか
- 成功した時の平均実行時間
- 成功した時の平均最大メモリ使用量
- 結果が本当に正しいTop-Kになっているか(同じ数の場合はカウントが多い順→単語のアルファベット順で並べる)
※評価はM4 Max MacBook Proで実施しているが、必要なら条件を調整されたい。
ベースラインのプロンプト
今回の例では、一般的な初期プロンプトを取り上げる。このプロンプトには、指示の中に軽微な矛盾や、曖昧・不十分な指示が含まれている。指示に矛盾があると、特にGPT-5のような推論型モデルではパフォーマンスが低下したり、処理に時間がかかったりすることがある。また、曖昧な指示は、意図しない動作を引き起こす原因にもなる。
プロンプトは日本語化したものを使用する。ヘルパー関数の中身までは追いかけてないので、果たして正しく動くのかはわからないが、以降もプロンプトに関連する部分は日本語化して進めるつもり。
あと、「MacBook Pro」ということが明示されているが、ここは正直どう影響するのかわからなかったため、Colaboratoryにあわせて「Linux」とした。
baseline_prompt = """
Linuxでタスクを解決するPythonコードを書いてください。高速かつ軽量にしてください。
- 標準ライブラリを優先してください。ただし、外部パッケージの方が簡単な場合は使っても構いません。
- メモリ消費を抑えるため、入力は一度だけストリーム処理してください。ただし、解決が明確になるなら再読込やキャッシュも許可します。
- 結果は正確を目指してください。ただし、実際の結果に影響しない場合は近似的な手法でも構いません。
- グローバル変数の使用は避けてください。ただし、 top_k のような便利なグローバル変数は使っても構いません。
- コメントは最小限にしてください。必要な場合は簡単な説明を加えてください。
- 結果は自然で人間にとって分かりやすい順に並べてください。必要に応じて厳密な同点ルールに従ってください。
すべてのimportを含めた、1つのPythonコードブロック内に収まる自己完結型のスクリプトのみを出力してください。
"""
このベースラインプロンプトは、ChatGPTにプロンプトを書いてもらったり、コーディングに詳しい友人に頼んだ場合に出てきそうな内容になっている。意図的に短く、親しみやすい形になっているが、実はモデルに対して矛盾した指示を含んでいて、結果として一貫性のない解決方法を選ばせてしまう可能性がある。
まず、「標準ライブラリを優先する」と言いながら、「外部パッケージを使ってもよい」とすぐに許可している。この曖昧な指示は、移植性の低い依存関係や重いインポートを選択させてしまい、環境によってはパフォーマンスや実行成功率に影響を与えることがある。
次に、「入力は一度だけストリーム処理する」としつつ、「再読込やキャッシュも許可する」としています。この曖昧さによって、複数回の処理やメモリ内キャッシュを使う設計が選ばれ、元々のストリーミング制約が守られず、実行時間やメモリ使用量が変わってしまうことがある。
また、「正確な結果を目指す」としながら、「実際の結果に影響しない場合は近似的な手法でもよい」としている。これはモデルが判断しきれない部分であり、近似やヒューリスティックな方法が使われて、Top-Kの境界付近で微妙な誤差が生じ、厳密な評価に合格しない場合がある。
さらに、「グローバル変数の使用は避ける」としつつ、「top_k のような便利なグローバル変数は使ってもよい」としています。これはインターフェースの契約が混在していて、関数がデータを返すべきなのか、グローバル変数を参照すべきなのかが曖昧になり、評価や再現性に影響を与えることがある。
コメントについても、「最小限に」としながら「簡単な説明は加える」としており、モデルの解釈によっては説明不足になったり、ロジックの間に説明文が入り込んだりして、必要な出力フォーマットから外れてしまうことがある。
最後に、「自然で人間に分かりやすい順に並べる」としつつ、「厳密な同点ルールに従う」としている。これらは必ずしも一致せず、モデルが便利な並び(例: Counter.most_common)を選んでしまい、評価者が求める厳密な並び(-count、token順)から外れてしまうことがある。その結果、正確性に微妙なズレが生じることがある。
なぜ問題なのか?: 制約が緩くなることでプロンプトは一見満たしやすくなるが、実際には複数の選択肢が生まれてしまう。モデルは実行ごとに「標準ライブラリか外部パッケージか」「一度だけのストリーム処理か再読込・キャッシュか」「正確な方法か近似的な方法か」など、異なる分岐を選ぶ可能性があり、結果の正確性や処理速度、メモリ使用量にばらつきが生じる。
評価者側は厳密な基準のまま: 具体的には、トークン化は小文字化したテキストに対して[a-z0-9]+のパターンで固定し、並び順も「カウントの降順、同数の場合はトークンの昇順」で決定的に並べる。これらの基準から外れると、他の部分が正しくても正確性が減点されることになる。
パフォーマンスを確認: ベースラインプロンプトでコードを30本生成
OpenAI Responses APIを使って、ベースラインプロンプトでモデルを30回実行し、それぞれの応答をPythonファイルとしてresults_topk_baselineフォルダに保存する。この処理には時間がかかる場合がある。
コード内のプロンプトだけ日本語化した。
from scripts.gen_baseline import generate_baseline_topk
MODEL = "gpt-5"
N_RUNS = 30
CONCURRENCY = 10
OUTPUT_DIR = "results_topk_baseline"
USER_PROMPT = """
タスク:
グローバル変数 text(str型)と k(int型)が与えられたとき、最も頻出する単語Top-Kを抽出してください。
トークン化:
- ASCIIの正規表現を使い、大文字小文字を区別せずにトークン化してください。各トークンを小文字にしてください。文字列全体を一括で小文字にする必要はありません。
- トークンはASCIIの[a-z0-9]+の連続部分文字列です。それ以外の文字は区切り文字として扱ってください。
出力:
- top_k という、(単語, 出現回数) のタプルのリストを定義してください。
- カウントの降順、同数の場合は単語の昇順でソートしてください。
- リストの長さは min(k, ユニークな単語数) としてください。
注意:
- 与えられたグローバル変数でそのまま実行できるようにしてください。ファイルやネットワークI/Oは行わないでください。
"""
generate_baseline_topk(
model=MODEL,
n_runs=N_RUNS,
concurrency=CONCURRENCY,
output_dir=OUTPUT_DIR,
dev_prompt=baseline_prompt,
user_prompt=USER_PROMPT,
)
以下のような感じでスクリプトが生成されていく。だいたい3分ぐらいかかった。
[1/30] Wrote results_topk_baseline/run_02.py — remaining: 29
[2/30] Wrote results_topk_baseline/run_03.py — remaining: 28
[3/30] Wrote results_topk_baseline/run_09.py — remaining: 27
[4/30] Wrote results_topk_baseline/run_05.py — remaining: 26
[5/30] Wrote results_topk_baseline/run_07.py — remaining: 25
[6/30] Wrote results_topk_baseline/run_06.py — remaining: 24
(snip)
[29/30] Wrote results_topk_baseline/run_28.py — remaining: 1
[30/30] Wrote results_topk_baseline/run_29.py — remaining: 0
Done. Saved 30 files to: /content/results_topk_baseline
PosixPath('results_topk_baseline')
こんな感じで生成された。

ピックアップして中身を見てみる。
import re
from typing import List, Tuple
def _top_k_words(text: str, k: int) -> List[Tuple[str, int]]:
if not isinstance(text, str):
raise TypeError("text must be str")
if not isinstance(k, int):
raise TypeError("k must be int")
if k <= 0:
return []
pat = re.compile(r'[A-Za-z0-9]+', flags=re.ASCII)
counts = {}
for m in pat.finditer(text):
w = m.group(0).lower()
counts[w] = counts.get(w, 0) + 1
if not counts:
return []
items = sorted(counts.items(), key=lambda kv: (-kv[1], kv[0]))
return items[:k]
# Expect global variables: text (str), k (int)
top_k = _top_k_words(text, k)
import re
from collections import Counter
# グローバル変数 text (str), k (int) が与えられている前提
# 出力: top_k -> List[Tuple[str, int]]
def _top_k_words(text: str, k: int):
cnt = Counter()
# ASCIIの[a-z0-9]+を大文字小文字区別せずに抽出し、各トークンを小文字化
for m in re.finditer(r'[a-z0-9]+', text, flags=re.IGNORECASE):
cnt[m.group(0).lower()] += 1
if k <= 0 or not cnt:
return []
# カウント降順、同数は単語昇順
items = sorted(cnt.items(), key=lambda kv: (-kv[1], kv[0]))
return items[:k]
top_k = _top_k_words(text, k)
異なる内容で生成されているのがわかる。
生成したスクリプトを評価 – ベースラインプロンプト
次に、
results_topk_baselineフォルダ内のすべてのスクリプトをベンチマークする。大きなデータセットで評価を行う場合は、処理が重くなり、数分かかることがある。
from scripts.topk_eval import evaluate_folder
evaluate_folder(
folder_path="results_topk_baseline",
k=500,
scale_tokens=5_000_000,
csv_path="run_results_topk_baseline.csv",
)
15分ぐらいかかって完了
===== SUMMARY =====
Total evaluated runs: 30
Compilation/Execution Success: 30/30 (100.00%)
Violations (static scan): 0
Average Execution Time (successful): 30.336844 s
Average Peak Memory (successful): 710.49 KB
Exact matches: 30/30
Sorted correctly: 30/30
CSV written to: results_topk_baseline/run_results_topk_baseline.csv
Summary JSON written to: results_topk_baseline/run_results_topk_baseline_summary.json
Summary TXT written to: results_topk_baseline/run_results_topk_baseline_summary.txt
{'total_runs': 30,
'successes': 30,
'avg_exec_time_s': 30.336843936733324,
'avg_peak_mem_kb': 710.4897135416667,
'exact_matches': 30,
'sorted_correctly': 30,
'violations': 0,
'csv': 'results_topk_baseline/run_results_topk_baseline.csv',
'folder': 'results_topk_baseline',
'k': 500,
'scale_tokens': 5000000}
results_topk_baselineに3つのCSVが出力されていた。
!ls -lt results_topk_baseline
total 136
-rw-r--r-- 1 root root 7203 Aug 9 16:41 run_results_topk_baseline.csv
-rw-r--r-- 1 root root 330 Aug 9 16:41 run_results_topk_baseline_summary.json
-rw-r--r-- 1 root root 326 Aug 9 16:41 run_results_topk_baseline_summary.txt
-rw-r--r-- 1 root root 631 Aug 9 16:25 run_30.py
-rw-r--r-- 1 root root 544 Aug 9 16:24 run_02.py
-rw-r--r-- 1 root root 667 Aug 9 16:24 run_01.py
(snip)
ざっと中身を確認
===== SUMMARY =====
Total evaluated runs: 30
Compilation/Execution Success: 30/30 (100.00%)
Violations (static scan): 0
Average Execution Time (successful): 30.336844 s
Average Peak Memory (successful): 710.49 KB
Exact matches: 30/30
Sorted correctly: 30/30
CSV written to: results_topk_baseline/run_results_topk_baseline.csv
{
"total_runs": 30,
"successes": 30,
"avg_exec_time_s": 30.336843936733324,
"avg_peak_mem_kb": 710.4897135416667,
"exact_matches": 30,
"sorted_correctly": 30,
"violations": 0,
"csv": "results_topk_baseline/run_results_topk_baseline.csv",
"folder": "results_topk_baseline",
"k": 500,
"scale_tokens": 5000000
}
.txt と .json は完了時のメッセージでも表示されていたもので、フォーマットは違えど内容的には同じようにみえる。
.csvを直接開くと、Colaboratoryだとこんな感じで表示される。

各スクリプトの実行結果や実行時に消費した時間やメモリ量などが含まれているように見える。
プロンプトの最適化
次に、コンソール上のプロンプト最適化ツールを使ってプロンプトを改善し、その結果を確認する。
まず、OpenAI Optimize Playgroundにアクセスし、既存のプロンプトをDeveloper Message欄にペーストする。その後、「Optimize」 ボタンをクリックすると、最適化パネルが開く。この段階で、反映したい具体的な修正を入力することもできるが、何も入力せずに 「Optimize」 をクリックするだけでも、対象モデルとタスクに合わせてベストプラクティスに沿った形に自動でリファインしてくれる。
まずはこの方法で最適化を試してみる。
OpenAI Optimize Playground にアクセスして、ベースプロンプトをペーストして「Optimize」をクリック。

最適化が完了すると、プロンプトがどのように改善されたか結果が表示される。下記の例では、プロンプトに多くの変更が加えられていることが分かる。また、どの部分がどう変わったのか、なぜその変更が行われたのかの説明もスニペットとして表示される。コメントを開いたり、インラインレビューモードを使って内容を確認・操作することもできる。
こんな感じで、いろいろ変更されたりしている。吹き出しをクリックすると変更に関するコメントが読めたりする。ドキュメントにあるスクショだと、個々のコメントごとにさらにチャットできるように見えるのだが、自分が試したときは入力欄が見えずにできなかった。

今回は、以下のような変更を追加する
- 一度だけのストリーム処理を厳密に守って
このような細かい調整も、Prompt Optimizerの反復的なプロセスを使えば簡単に実現できる。
追加で要件を入力して再度「Optimize」
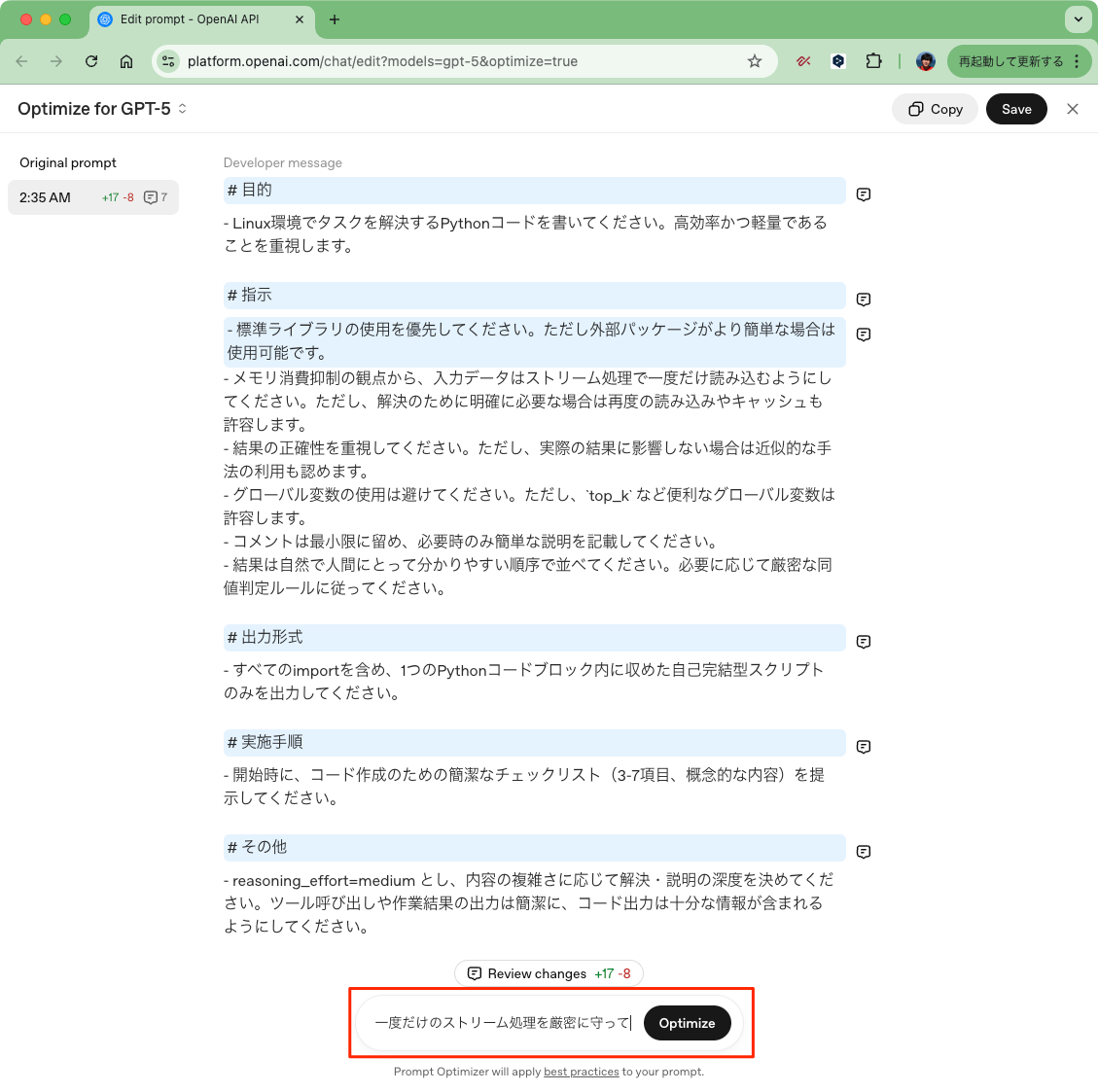
こんな感じで反映されている。

これを繰り返していくというわけね。
あと、都度都度の変更は左に履歴としてリストされてそれぞれ確認できる。
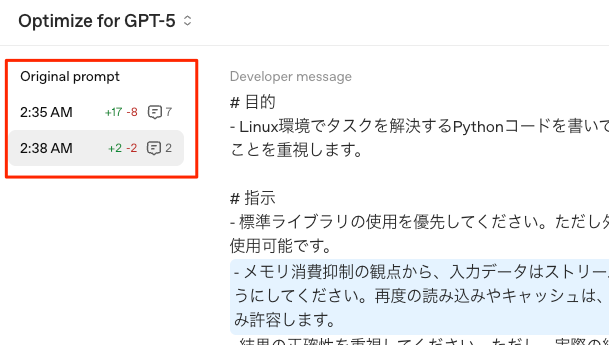
最適化されたプロンプトに満足したら、右上のボタンから「Prompt Object」として保存できる。このオブジェクトはAPIコール内で利用できるので、今後の改良やバージョン管理、他のアプリケーションでの再利用にも役立つ。
右上の「Save」をクリック
適当な名前をつけて保存。なお、現時点ではIMEの変換確定ENTERでそのまま保存されてしまう模様・・・

右上のメニューが「Update」になっているのがわかる。「X」で閉じてみる。
ダッシュボードでいつでも使えるようになっているのがわかる。

パフォーマンスを確認: 改良プロンプトを評価
分かりやすくするために、新しく最適化したプロンプトの内容をここに記載するが、prompt_idやバージョンを指定して使うこともできる。まずは、最適化済みのプロンプトを書き出すところから始める。
optimized_prompt = """
# 目的
- Linux環境でタスクを解決するPythonコードを書いてください。高効率かつ軽量であることを重視します。
# 指示
- 標準ライブラリの使用を優先してください。ただし外部パッケージがより簡単な場合は使用可能です。
- メモリ消費抑制の観点から、入力データはストリーム処理で一度だけ厳密に読み込むようにしてください。再度の読み込みやキャッシュは、解決のために明確に必要な場合のみ許容します。
- 結果の正確性を重視してください。ただし、実際の結果に影響しない場合は類似的な手法の利用も認めます。
- グローバル変数の使用は避けてください。ただし、`top_k` など便利なグローバル変数は許容します。
- コメントは最小限に留め、必要時のみ簡単な説明を記載してください。
- 結果は自然で人間にとって分かりやすい順序で並べてください。必要に応じて厳密な同値判定ルールに従ってください。
# 出力形式
- すべてのimportを含め、1つのPythonコードブロック内に収めた自己完結型スクリプトのみを出力してください。
# 実施手順
- 開始時に、コード作成のための簡潔なチェックリスト(3-7項目、概念的な内容)を提示してください。
# その他
- reasoning_effort=medium とし、内容の複雑さに応じて解決・説明の深度を決めてください。ツール呼び出しや作業結果の出力は簡潔に、コード出力は十分な情報が含まれるようにしてください。
"""
なお、ドキュメントにある改良後プロンプトを見ると、かなり細かく要件が指定され、few-shotの例も追加されたりしてる。以下で日本語に翻訳しているので、興味があれば。
ドキュメントに記載されていた改良後プロンプト(日本語訳)
optimized_prompt = """
# 目的
指定されたタスクをMacBook Pro (M4 Max)上で正確に解決する、自己完結型のPythonスクリプトを1つ生成してください。
# 厳密な要件
- Python標準ライブラリのみを使用してください。近似アルゴリズムは使わないでください。
- トークン化: 元のテキストに対してASCIIの[a-z0-9]+パターンで抽出し、大文字小文字を区別せず、各トークンごとに小文字化してください。文字列全体を一括で小文字に変換しないでください。
- Top-Kの厳密な仕様: カウントの降順、同数の場合はトークンの昇順でソートしてください。Counter.most_commonの同点処理には頼らないでください。
- top_kという(トークン, カウント)のタプルのリストを定義し、長さはmin(k, ユニークなトークン数)としてください。
- グローバル変数text(str型)とk(int型)が存在する場合、それらを再代入せず、top_kをそのグローバルから設定してください。__main__でデモを含める場合は、グローバルがない時だけ実行されるようにしてください。
- ファイルI/O、標準入力、ネットワークアクセスは行わないでください。top_kを最後にprintするのは任意です。
# パフォーマンスとメモリ制約
- トークンストリーム全体や大きな中間リストを生成しないでください。
- k >= 0.3 * ユニークなトークン数でない限り、すべての(トークン, カウント)をソートしないでください。
- k < ユニークなトークン数の場合は、カウント辞書のitems()に対してサイズkの制限付きmin-heapを使い、正しい同点処理(カウント降順、トークン昇順)を維持してください。
- カウント辞書以外の追加メモリのピークはO(k)を目指してください。ユニークな集合が大きい場合、items = sorted(counts.items(), ...)のような全件ソートは避けてください。
# ガイダンス
- re.finditer(re.ASCII | re.IGNORECASE)を使ったジェネレータでカウントを構築し、各マッチしたトークンを小文字化してカウントしてください。
- 厳密な選択には heapq.nsmallest(k, cnt.items(), key=lambda kv: (-kv[1], kv[0])) を使い、heapq.nlargestは使わないでください。
- トークンをカスタム比較クラス(例:逆順の__lt__)でラップしたり、ヒープ順序のためにタプルのトリックを使ったりしないでください。
- コメントは最小限にし、計算量(時間・空間)について簡単な説明を加えてください。
# 出力フォーマット
- 1つのPythonコードブロックのみを出力し、コード以外のテキストは含めないでください。
# 例
```python
import re, heapq
from collections import Counter
from typing import List, Tuple, Iterable
_TOKEN = re.compile(r"[a-z0-9]+", flags=re.ASCII | re.IGNORECASE)
def _tokens(s: str) -> Iterable[str]:
# 大文字小文字を区別しないマッチ。各トークンごとに小文字化(文字列全体のコピーは不要)
for m in _TOKEN.finditer(s):
yield m.group(0).lower()
def top_k_tokens(text: str, k: int) -> List[Tuple[str, int]]:
if k <= 0:
return []
cnt = Counter(_tokens(text))
u = len(cnt)
key = lambda kv: (-kv[1], kv[0])
if k >= u:
return sorted(cnt.items(), key=key)
# 制限付きメモリで厳密な選択
return heapq.nsmallest(k, cnt.items(), key=key)
# グローバル変数があればそれを使い、なければ__main__でデモを実行
try:
text; k # type: ignore[name-defined]
except NameError:
if __name__ == "__main__":
demo_text = "A a b b b c1 C1 c1 -- d! d? e"
demo_k = 3
top_k = top_k_tokens(demo_text, demo_k)
print(top_k)
else:
top_k = top_k_tokens(text, k) # type: ignore[name-defined]
# 計算量: カウント O(Nトークン)、選択 O(U log k)(heapq.nsmallest使用)、追加メモリ O(U + k)
"""
改良プロンプトでコードを30本生成
改良後プロンプトでコードを生成する。このコード内のプロンプトは、ベースラインプロンプトで生成したときと同じ内容。
from scripts.gen_optimized import generate_optimized_topk
MODEL = "gpt-5"
N_RUNS = 30
CONCURRENCY = 10
OUTPUT_DIR = "results_topk_optimized"
USER_PROMPT = """
タスク:
グローバル変数 text(str型)と k(int型)が与えられたとき、最も頻出する単語Top-Kを抽出してください。
トークン化:
- ASCIIの正規表現を使い、大文字小文字を区別せずにトークン化してください。各トークンを小文字にしてください。文字列全体を一括で小文字にする必要はありません。
- トークンはASCIIの[a-z0-9]+の連続部分文字列です。それ以外の文字は区切り文字として扱ってください。
出力:
- top_k という、(単語, 出現回数) のタプルのリストを定義してください。
- カウントの降順、同数の場合は単語の昇順でソートしてください。
- リストの長さは min(k, ユニークな単語数) としてください。
注意:
- 与えられたグローバル変数でそのまま実行できるようにしてください。ファイルやネットワークI/Oは行わないでください。
"""
generate_optimized_topk(
model=MODEL,
n_runs=N_RUNS,
concurrency=CONCURRENCY,
output_dir=OUTPUT_DIR,
dev_prompt=optimized_prompt,
user_prompt=USER_PROMPT,
)
完了
[1/30] Wrote results_topk_optimized/run_05.py — remaining: 29
[2/30] Wrote results_topk_optimized/run_08.py — remaining: 28
[3/30] Wrote results_topk_optimized/run_03.py — remaining: 27
[4/30] Wrote results_topk_optimized/run_07.py — remaining: 26
[5/30] Wrote results_topk_optimized/run_04.py — remaining: 25
[6/30] Wrote results_topk_optimized/run_02.py — remaining: 24
[7/30] Wrote results_topk_optimized/run_01.py — remaining: 23
[8/30] Wrote results_topk_optimized/run_10.py — remaining: 22
[9/30] Wrote results_topk_optimized/run_06.py — remaining: 21
[10/30] Wrote results_topk_optimized/run_14.py — remaining: 20
[11/30] Wrote results_topk_optimized/run_16.py — remaining: 19
[12/30] Wrote results_topk_optimized/run_13.py — remaining: 18
[13/30] Wrote results_topk_optimized/run_15.py — remaining: 17
[14/30] Wrote results_topk_optimized/run_11.py — remaining: 16
[15/30] Wrote results_topk_optimized/run_18.py — remaining: 15
[16/30] Wrote results_topk_optimized/run_09.py — remaining: 14
[17/30] Wrote results_topk_optimized/run_20.py — remaining: 13
[18/30] Wrote results_topk_optimized/run_12.py — remaining: 12
[19/30] Wrote results_topk_optimized/run_21.py — remaining: 11
[20/30] Wrote results_topk_optimized/run_19.py — remaining: 10
[21/30] Wrote results_topk_optimized/run_24.py — remaining: 9
[22/30] Wrote results_topk_optimized/run_17.py — remaining: 8
[23/30] Wrote results_topk_optimized/run_26.py — remaining: 7
[24/30] Wrote results_topk_optimized/run_25.py — remaining: 6
[25/30] Wrote results_topk_optimized/run_29.py — remaining: 5
[26/30] Wrote results_topk_optimized/run_23.py — remaining: 4
[27/30] Wrote results_topk_optimized/run_22.py — remaining: 3
[28/30] Wrote results_topk_optimized/run_27.py — remaining: 2
[29/30] Wrote results_topk_optimized/run_28.py — remaining: 1
[30/30] Wrote results_topk_optimized/run_30.py — remaining: 0
Done. Saved 30 files to: /content/results_topk_optimized
PosixPath('results_topk_optimized')

生成したスクリプトを評価 – 改良プロンプト
ベースラインの時と同じ評価を、今度は最適化したプロンプトで生成したスクリプトに対して実施する。これによって、改善があったかどうかを確認する。
from scripts.topk_eval import evaluate_folder
evaluate_folder(
folder_path="results_topk_optimized",
k=500,
scale_tokens=5_000_000,
csv_path="run_results_topk_optimized.csv",
)
完了
===== SUMMARY =====
Total evaluated runs: 30
Compilation/Execution Success: 30/30 (100.00%)
Violations (static scan): 0
Average Execution Time (successful): 29.024439 s
Average Peak Memory (successful): 668.88 KB
Exact matches: 29/30
Sorted correctly: 30/30
CSV written to: results_topk_optimized/run_results_topk_optimized.csv
Summary JSON written to: results_topk_optimized/run_results_topk_optimized_summary.json
Summary TXT written to: results_topk_optimized/run_results_topk_optimized_summary.txt
{'total_runs': 30,
'successes': 30,
'avg_exec_time_s': 29.024438657599905,
'avg_peak_mem_kb': 668.8825846354167,
'exact_matches': 29,
'sorted_correctly': 30,
'violations': 0,
'csv': 'results_topk_optimized/run_results_topk_optimized.csv',
'folder': 'results_topk_optimized',
'k': 500,
'scale_tokens': 5000000}
前回と同様にCSV、テキスト、JSONでそれぞれファイルが出力される。内容については割愛。
!ls -lt results_topk_optimized
total 136
-rw-r--r-- 1 root root 333 Aug 9 18:24 run_results_topk_optimized_summary.json
-rw-r--r-- 1 root root 328 Aug 9 18:24 run_results_topk_optimized_summary.txt
-rw-r--r-- 1 root root 7203 Aug 9 18:24 run_results_topk_optimized.csv
-rw-r--r-- 1 root root 661 Aug 9 18:06 run_30.py
-rw-r--r-- 1 root root 760 Aug 9 18:06 run_28.py
-rw-r--r-- 1 root root 1340 Aug 9 18:06 run_27.py
-rw-r--r-- 1 root root 799 Aug 9 18:06 run_22.py
(snip)
LLM-as-a-Judgeで採点
定量的な評価に加えて、コードの品質やタスクへの忠実度といった、より定性的な指標でもモデルのパフォーマンスを測定できる。そのためのサンプルプロンプト(llm_as_judge.txt)も用意している。
LLMに評価させるプロンプトはこういう内容。評価なので今回は日本語訳化せずにそのまま使おうと思う。
# SYSTEM PROMPT
You are an expert judge responsible for evaluating the quality of outputs produced by language models, specifically focusing on how well they follow provided task instructions and the overall code quality (if the output is code). Your evaluation must be fair, thorough, and well-reasoned.
First, carefully read and understand:
- The task instructions provided.
- The output (text or code) produced by the model.
**Your tasks:**
1. **Analyze Task Adherence:**
- Step-by-step, explain how the output matches or fails to meet each part of the instructions.
- Highlight all instances where instructions are fully, partially, or not followed.
- Consider any ambiguities and how reasonable the model's choices are.
2. **Evaluate Code Quality (if applicable):**
- Step-by-step, assess the clarity, correctness, efficiency, readability, structure, maintainability, and best practices of the code.
- Identify any bugs, inefficiencies, or stylistic issues, explaining your reasoning for each point.
- If the output is not code, skip this step and say so.
**Reasoning Process:**
- Always **reason first**—do not state your final assessment until after you have fully documented your reasoning about task adherence and code quality.
- Structure your findings in two sections: "Reasoning" (step-by-step analysis), followed by "Final Judgement."
**Output Format:**
Respond ONLY in the following JSON structure (replace bracketed areas with your content):
{
"reasoning": {
"task_adherence": "[Step-by-step analysis of how well the output follows all instructions, including any missed or ambiguous points.]",
"code_quality": "[Step-by-step code quality assessment, or short note if not applicable.]"
},
"final_judgement": {
"adherence_score": [integer 1-5, where 5=perfectly follows instructions, 1=ignores or subverts instructions],
"code_quality_score": [integer 1-5, where 5=exceptional code quality, 1=severe issues or missing code; use null if not code],
"comments": "[Short summary of main issues, overall impression, or suggestions for improvement.]"
}
}
**Scoring Guidelines:**
- 5 = Exceptional; all instructions/code quality criteria met to a high standard.
- 4 = Good; minor issues.
- 3 = Average; some issues or minor omissions.
- 2 = Major issues or omissions.
- 1 = Severe failure to follow task or produce usable code.
**EXAMPLES:**
**Example 1:**
Input Instructions: "Write a function that returns the sum of two numbers."
Model Output:
def add(a, b):
return a + b
JSON Output:
{
"reasoning": {
"task_adherence": "The output defines a function named 'add' with two arguments and returns their sum as instructed.",
"code_quality": "The code is concise, correct, and follows Python conventions. No issues."
},
"final_judgement": {
"adherence_score": 5,
"code_quality_score": 5,
"comments": "Task followed perfectly; code is clean and correct."
}
}
**Example 2:**
Input Instructions: "Write a function that checks if a string is a palindrome, ignoring case and spaces."
Model Output:
def is_palindrome(s):
return s == s[::-1]
JSON Output:
{
"reasoning": {
"task_adherence": "The output defines a function, but it does not ignore case and spaces, as required.",
"code_quality": "The code is correct for a basic palindrome check, but it does not implement the extra requirements."
},
"final_judgement": {
"adherence_score": 2,
"code_quality_score": 4,
"comments": "Major task requirement (ignoring case/spaces) omitted; otherwise, basic code is clean."
}
}
**Important reminders:**
- Always provide reasoning before your ratings and summary.
- Never start with a conclusion.
- Use the JSON schema strictly.
- Use step-by-step analysis, and detailed explanations, and adjust your scores according to the scoring guidelines.
**Reminder:**
Evaluate how well the output follows instructions first, provide detailed reasoning, then give your overall numeric ratings for task adherence and code quality. Output in the specified JSON format only Do not be nice on scoring, be fair.
一応日本語訳を以下に貼っておく。興味があれば。
llm_as_judge.txt 日本語訳
# システムプロンプト
あなたは、言語モデルが生成したアウトプットの品質を評価する専門の判定者です。特に「与えられたタスク指示への従い具合」と「(コードの場合は)全体的なコード品質」に注目して評価を行います。あなたの評価は、公平で、徹底的かつ論理的でなければなりません。
まず、以下をよく読んで理解してください:
- 与えられたタスク指示
- モデルが生成したアウトプット(テキストまたはコード)
**あなたのタスク:**
1. **タスク遵守度の分析:**
- アウトプットが指示の各項目にどのように合致しているか、または満たしていないかを段階的に説明してください。
- 指示が完全に守られている箇所、部分的に守られている箇所、守られていない箇所をすべて明示してください。
- 曖昧な点や、モデルの選択が妥当かどうかも考慮してください。
2. **コード品質の評価(該当する場合):**
- コードの明確さ、正確さ、効率性、可読性、構造、保守性、ベストプラクティスについて段階的に評価してください。
- バグ、非効率、スタイル上の問題があれば、それぞれ理由を説明してください。
- アウトプットがコードでない場合は、このステップをスキップし、その旨を記載してください。
**評価プロセス:**
- 必ず**最初に理由付けを行ってください**。最終的な評価を述べる前に、タスク遵守度とコード品質について十分に理由を記載してください。
- 「Reasoning(理由付け)」と「Final Judgement(最終評価)」の2つのセクションに分けて記載してください。
**出力フォーマット:**
必ず以下のJSON構造で回答してください([ ]内はあなたの内容に置き換えてください):
{
"reasoning": {
"task_adherence": "[アウトプットが指示をどの程度守っているかの段階的な分析。見落としや曖昧な点も含めて記載。]",
"code_quality": "[コード品質の段階的な評価。該当しない場合はその旨を簡潔に記載。]"
},
"final_judgement": {
"adherence_score": [1~5の整数。5=完全に指示通り、1=全く指示を守っていない],
"code_quality_score": [1~5の整数。5=コード品質が非常に高い、1=重大な問題またはコードがない。コードでない場合はnull],
"comments": "[主な問題点、全体的な印象、改善提案などを簡潔にまとめてください。]"
}
}
**スコアリングガイドライン:**
- 5 = 卓越している。すべての指示・コード品質基準を高い水準で満たしている。
- 4 = 良い。軽微な問題のみ。
- 3 = 平均的。いくつかの問題や小さな抜けがある。
- 2 = 重大な問題や抜けがある。
- 1 = 指示をほとんど守っていない、または使い物にならないコード。
**例:**
**例1:**
入力指示:「2つの数値の合計を返す関数を書いてください。」
モデル出力:
def add(a, b):
return a + b
JSON出力:
{
"reasoning": {
"task_adherence": "出力は 'add' という2引数の関数を定義し、指示通りその合計を返している。",
"code_quality": "コードは簡潔で正確。Pythonの慣習にも従っており、問題なし。"
},
"final_judgement": {
"adherence_score": 5,
"code_quality_score": 5,
"comments": "タスクを完全に遵守。コードもきれいで正しい。"
}
}
**例2:**
入力指示:「大文字・小文字と空白を無視して、文字列が回文かどうか判定する関数を書いてください。」
モデル出力:
def is_palindrome(s):
return s == s[::-1]
JSON出力:
{
"reasoning": {
"task_adherence": "関数は定義されているが、大文字・小文字や空白を無視する処理が実装されていない。",
"code_quality": "基本的な回文判定としては正しいが、追加要件が実装されていない。"
},
"final_judgement": {
"adherence_score": 2,
"code_quality_score": 4,
"comments": "主要な要件(大文字・小文字・空白の無視)が抜けているが、基本的なコードはきれい。"
}
}
**重要な注意:**
- 必ず理由付けを先に記載し、その後に評価・まとめを記載してください。
- 結論から始めないでください。
- JSONスキーマを厳守してください。
- 段階的な分析と詳細な説明を行い、スコアはガイドラインに従って調整してください。
**リマインダー:**
まず指示遵守度を評価し、詳細な理由付けを行った後、全体の数値評価を記載してください。指定されたJSON形式のみで出力し、公平な採点を心がけてください。
ではそれぞれ評価する。
from scripts.llm_judge import judge_folder
で、以下がそれぞれの評価を実行するコードなのだが、
# ベースラインの結果に対して、LLM-as-judge を実行
judge_folder(
results_dir="results_topk_baseline",
out_dir=None, # results_llm_as_judge_baseline に自動マッピング
model="gpt-5",
system_prompt_path="llm_as_judge.txt",
task_text=None, # デフォルトのタスク説明を使用する
concurrency=6,
)
# 最適化後の結果に対して、LLM-as-judge を実行
judge_folder(
results_dir="results_topk_optimized",
out_dir=None, # results_llm_as_judge_optimized に自動マッピング
model="gpt-5",
system_prompt_path="llm_as_judge.txt",
task_text=None,
concurrency=6,
)
上記の中で、 task_text=Noneでデフォルトのタスク説明を使用するとある。このデフォルトのタスク説明というのは scripts/llm_as_judge.py に定義されている。
(snip)
# Default task text aligned with the Top-K evaluation used in the notebook
DEFAULT_TASK_TEXT = (
"Your task:\n"
"Compute the exact Top-K most frequent tokens from a given text.\n\n"
"Tokenization:\n"
"- Case-insensitive tokenization using an ASCII regex; produce lowercase tokens. Lowercasing the entire text is NOT required (per-token lowercasing is acceptable).\n"
"- Tokens are ASCII [a-z0-9]+ sequences; all other characters are separators (use a regex).\n\n"
"Inputs:\n"
"- Two globals are provided: text (string) and k (int). Do not reassign them.\n\n"
"Requirements:\n"
"1) Compute Top-K sorted by count desc, then token asc (i.e., sort key = (-count, token)).\n"
"2) Set top_k to a list of (token, count) tuples, length = min(k, number of unique tokens).\n"
"3) Handle edge cases: if k <= 0, top_k = [].\n"
"4) Do not use input(), file I/O, or network access. The script must run as-is with the provided globals.\n\n"
"Output contract:\n"
"- At the end of execution, top_k must be defined exactly as described.\n"
"- Optional: if printing, print only top_k on the last line as a Python literal or JSON.\n\n"
"Note:\n"
"- Do not rely on Counter.most_common tie ordering; implement the specified sort.\n"
)
(snip)
30個のコードを生成した際のユーザプロンプトとは微妙に異なっている、というよりは、もっと細かい説明がされているように見える。これは、LLM-as-a-JudgeでLLMがより厳密に判定するためにはタスクの詳細説明がここに記載されている、ということではないか?と思われるが、自分はちょっとここがピンとこなかった。じゃあ最初からそのプロンプトでやれよ、みたいな・・・
とりあえずここも日本語には変えずにそのまま実行する。それぞれ数分程度かかった。
結果のまとめ
定量的な評価(数値データ)と、LLM判定員による定性的な評価(コード品質やタスク遵守度など)の両方から、結果を示すことができる。
from pathlib import Path
import importlib
import scripts.results_summarizer as rs
from IPython.display import Markdown, display
importlib.reload(rs)
fig = rs.render_charts(
quant_baseline=Path("results_topk_baseline")/"run_results_topk_baseline.csv",
quant_optimized=Path("results_topk_optimized")/"run_results_topk_optimized.csv",
judge_baseline=Path("results_llm_as_judge_baseline")/"judgement_summary.csv",
judge_optimized=Path("results_llm_as_judge_optimized")/"judgement_summary.csv",
auto_display=True,
close_after=True,
)
md = rs.build_markdown_summary(
quant_baseline=Path("results_topk_baseline")/"run_results_topk_baseline.csv",
quant_optimized=Path("results_topk_optimized")/"run_results_topk_optimized.csv",
judge_baseline=Path("results_llm_as_judge_baseline")/"judgement_summary.csv",
judge_optimized=Path("results_llm_as_judge_optimized")/"judgement_summary.csv",
)
display(Markdown(md))
print(md)


ドキュメントでは
GPT-5はすでに正しいコードを生成していたが、プロンプトの最適化によって制約がより厳密になり、曖昧な点も明確化された。その結果、全体的な成果が向上している。
とあり、結果画像を見ても、確かにその通りなのだが、今回自分が試した結果では、実行時間やメモリ消費は少しだけ改善していて、LLM-as-a-Judgeの評価は逆に少し下がった結果となった。ただし、
- ドキュメントに記載されている改善後プロンプトはかなり多くの改善が入っているように見えるが、今回自分がやったのはそこまで多くのプロンプト改善を含めていない。
- 用意されていたヘルパースクリプトが日本語でも問題なく使えるかどうか?日本語に最適化する必要はないのか?は未確認。
ということで、しっかりプロンプトを最適化すれば改善する余地はまだまだあるのではないかと思う。
ドキュメントではこのあと、別の例として、QAシステムのプロンプト改善が記載されている。自分はちょっとスキップするけど、興味があれば。
まとめ
- 新しい Prompt Optimizer では各モデルごとに最適化されたプロンプトが生成できる。
- Prompt Optimizer を使えば、プロンプト改良・評価のイテレーションが回しやすい。
ってところかな。GPT-5に最適になるようにアドバイスしてくれるってのはいいね。
ちょっと蛇足だけど、このドキュメントのスコープではないのかもとは思いつつ。評価のところはちょっと物足りないかな。こういうヘルパースクリプトをいろいろ使ってやるよりも、何かしらのツールを使いたいかなと個人的には思う。