LlamaIndexのイベント駆動型エージェントアーキテクチャ「Workflows」を試す
今日、私たちは、マルチエージェント・アプリケーションを構築するための新しいイベント駆動型の方法である @llama_index workflowsを紹介できることを嬉しく思う。 各エージェントをイベントをサブスクライブし、イベントをエミットするコンポーネントとしてモデル化することで、複雑なオーケストレーションを、可読性が高く、Pythonicで、バッチ、非同期、ストリーミングを活用できる方法で構築することができる。
グラフ/パイプラインベースのアプローチには限界があった:
私たちは一夜にしてここまでたどり着いたわけではない。 実際、今年の初めにQuery Pipeline抽象化を発表した。これはDAGを使ったLLMオーケストレーションの試みだったが、しかし、より良いものにしようとするうちに、多くの問題に気づいた:
⚠️オーケストレーションがエッジに食い込んでしまい、コードが読めなくなったり、書くのが面倒になったりした。
⚠️ループを追加すると、エッジケースが多すぎて、推論が難しくなった。
⚠️うまくいかなくなったときのデバッグが大変だった。イベント駆動型へ:
イベント駆動アーキテクチャでは、コンポーネントはイベントを購読し、あなたはこれらのイベントを処理するPythonコードを書く責任を負う!これにより、完全な非同期フレームワークが得られる。これでできること:
高度なRAG(クエリー書き換え、リランキング、CRAG)からマルチエージェントシステムまで、あらゆるものをオーケストレーションできる。次のステップ:
Workflowsはまだベータ版だが、LlamaIndexのオーケストレーションのデフォルトになるように頑張っている。
もう一つの次のステップは、llama-agentsとネイティブに統合し、マルチエージェントをサービスに変換することだ!期待していてほしい。
公式ブログやドキュメントなどへのリンクは以下
-
公式ブログ: Introducing workflows beta: a new way to create complex AI applications with LlamaIndex
https://www.llamaindex.ai/blog/introducing-workflows-beta-a-new-way-to-create-complex-ai-applications-with-llamaindex -
公式ドキュメント: Workflows
https://docs.llamaindex.ai/en/latest/module_guides/workflow/ -
公式ドキュメント: RAG Workflow with Reranking
https://docs.llamaindex.ai/en/latest/examples/workflow/rag/ -
公式ドキュメント: Workflow for a Function Calling Agent
https://docs.llamaindex.ai/en/latest/examples/workflow/function_calling_agent/
公式ブログをざっと訳しつつ要約。Claude 3.5 Sonnetで。
workflowsベータの紹介: LlamaIndexで複雑なAIアプリケーションを作成する新しい方法
LlamaIndexは、新しいベータ機能「worflows」を導入しました。これは、複雑化するAIアプリケーションでのアクション連携を可能にする仕組みです。
LLMの登場以来、AIアプリケーションは複数のタスクと異なるコンポーネントで構成されるのが標準になってきました。オープンソースのフレームワークは、データローダー、LLM、ベクトルデータベース、リランカーなどの基本コンポーネントから外部サービスまで、使いやすい抽象化を提供してAIエンジニアの作業を支援していると同時に、複合AIシステムを統合するロジックを実装するために、最も直感的で効率的な方法を模索しています。
チェーンやパイプラインといった有向非巡回グラフ(DAG)の実装が、そのような連携パターンの例であり、。LlamaIndexも年初にQuery Pipelinesをリリースしましたが、より複雑なワークフローをサポートしようとする中で課題が見つかりました。そのため、DAGがエージェントベースの環境に適していない理由を検討し、フレームワークに導入できる代替案を探ることになりました。
グラフベースのUXの限界
DAGの非循環性は、エージェント型のAIアプリケーションにとって制限となります。自己修正や再試行のループが必要な場合があるためです。Query Pipelinesには以下の問題がありました:
- デバッグが困難
- コンポーネントの実行が不透明
- 複雑なパイプラインの可読性が低い
- オーケストレーターが複雑化
Query Pipelinesにサイクルを追加すると、開発者UXの問題がさらに顕著になりました:
- if-else文やwhileループなどの制御ロジックがグラフのエッジに埋め込まれ、定義が煩雑に
- オプション値やデフォルト値の扱いが困難に
- エージェントの自然な表現がグラフUXと合わない場合がある
これらの経験から、「複合AIシステムのオーケストレーションの抽象化はグラフが唯一の方法なのか?」という問いが生まれました。
グラフからEDA(イベント駆動アーキテクチャ)への移行
LlamaIndexの「Workflow」は複合AIシステムの新しい実装方法です。このワークフローは「steps」と呼ばれるPython関数群の間でイベントをやり取りします。各ステップはシステムの一つのコンポーネントとして機能し、クエリ処理、LLMとの対話、ベクトルデータベースからのデータ読み込みなどを担当します。各ステップは1つ以上のイベントを受け取って処理し、必要に応じて他のコンポーネントに転送されるイベントを返すことができます。これにより、柔軟なデータフローと制御が可能になります。
イベント駆動アーキテクチャへの移行は設計に根本的な変化をもたらします。グラフ実装ではtraversalアルゴリズムが次に実行すべきコンポーネントとデータの受け渡しを決定しますが、イベント駆動では各コンポーネントが特定のイベントをサブスクライブし、受け取ったデータに基づいて自律的に動作を決定します。
この方式では、入力のオプション性やデフォルト値の扱いがコンポーネントレベルで解決オーケストレーションのコードが大幅に簡素化されます。
ワークフローの基本
LlamaIndexのワークフローの最小構成例として、OpenAIのLLMを使用して質問に回答するシンプルなワークフローのコードは以下となります。
from llama_index.core.workflow import (
StartEvent,
StopEvent,
Workflow,
step,
)
from llama_index.llms.openai import OpenAI
class OpenAIGenerator(Workflow):
@step()
async def generate(self, ev: StartEvent) -> StopEvent:
query = ev.get("query")
llm = OpenAI()
response = await llm.acomplete(query)
return StopEvent(result=str(response))
w = OpenAIGenerator(timeout=10, verbose=False)
result = await w.run(query="What's LlamaIndex?")
print(result)
ワークフローの主要な特徴は以下の通りです:
-
@step()デコレータを使用して、generate関数をワークフローのステップとして定義します。 - ステップとして定義された関数の引数と戻り値の型アノテーションで、受け取るイベントと送り返すイベントを宣言します。
- ワークフローを実行するには、
OpenAIGeneratorクラスのインスタンスを作成し、runメソッドを呼び出します。 -
runメソッドに渡された引数はStartEventとして関連するステップに転送されます。 -
generateステップはStopEventを返すことでワークフローの実行を終了し、結果を呼び出し元に返します。
このアプローチにより、イベントの流れを通じて複雑なAIタスクを柔軟に組み立てることができます。各ステップが独立して動作しつつ、イベントを介して連携する構造になっています。
ワークフローでのループ処理
イベント駆動アーキテクチャでは、ループは固定的な構造ではなく、動的なイベントのやり取りによって実現されます。任意のステップが適切なイベントを作成・送信することで、他のステップを複数回呼び出すことができます。
以下の例では、自己修正ループを実装しています:
class ExtractionDone(Event):
output: str
passage: str
class ValidationErrorEvent(Event):
error: str
wrong_output: str
passage: str
class ReflectionWorkflow(Workflow):
@step()
async def extract(
self, ev: StartEvent | ValidationErrorEvent
) -> StopEvent | ExtractionDone:
if isinstance(ev, StartEvent):
passage = ev.get("passage")
if not passage:
return StopEvent(result="Please provide some text in input")
reflection_prompt = ""
elif isinstance(ev, ValidationErrorEvent):
passage = ev.passage
reflection_prompt = REFLECTION_PROMPT.format(
wrong_answer=ev.wrong_output, error=ev.error
)
llm = Ollama(model="llama3", request_timeout=30)
prompt = EXTRACTION_PROMPT.format(
passage=passage, schema=CarCollection.schema_json()
)
if reflection_prompt:
prompt += reflection_prompt
output = await llm.acomplete(prompt)
return ExtractionDone(output=str(output), passage=passage)
@step()
async def validate(
self, ev: ExtractionDone
) -> StopEvent | ValidationErrorEvent:
try:
json.loads(ev.output)
except Exception as e:
print("Validation failed, retrying...")
return ValidationErrorEvent(
error=str(e), wrong_output=ev.output, passage=ev.passage
)
return StopEvent(result=ev.output)
w = ReflectionWorkflow(timeout=60, verbose=True)
result = await w.run(
passage="There are two cars available: a Fiat Panda with 45Hp and a Honda Civic with 330Hp."
)
print(result)
-
ReflectionWorkflowクラスには2つのステップがあります:extractとvalidate。 -
extractステップは、初回実行時はStartEventを、修正が必要な場合はValidationErrorEventを受け取ります。 -
validateステップは、extractの結果を検証し、問題がある場合はValidationErrorEventを返します。 -
ValidationErrorEventが発生すると、extractステップが再度呼び出され、前回の誤りを反映した新しいプロンプトで再試行します。 - このループは、正しい結果が得られるか、タイムアウトするまで続きます。
この方法により、結果の品質を確保しつつ、柔軟な再試行メカニズムを実装できます。タイムアウトの代わりに、固定回数の試行後に諦める戦略など、様々なアプローチが可能です。このアプローチは、複雑なAIタスクにおける自己修正や品質管理のプロセスを効果的に実装できる点で優れています。
ワークフローの状態保持
ワークフローは実行中にグローバルな状態を保持し、この状態は必要に応じて各ステップで共有・伝播されます。この共有状態はContextオブジェクトとして実装され、以下のような用途があります:
- イテレーション間でのデータ保存
- 異なるステップ間の代替的な通信手段
RAGの例を用いて、グローバルコンテキストの使用方法を見てみましょう:
class RAGWorkflow(Workflow):
@step(pass_context=True)
async def ingest(self, ctx: Context, ev: StartEvent) -> Optional[StopEvent]:
dataset_name = ev.get("dataset")
_, documents = download_llama_dataset(dsname, "./data")
ctx.data["INDEX"] = VectorStoreIndex.from_documents(documents=documents)
return StopEvent(result=f"Indexed {len(documents)} documents.")
...
-
@step(pass_context=True)デコレータを使用して、ステップがContextオブジェクトを必要とすることを宣言します。 -
ingestステップでは、ドキュメントのインデックスを作成し、それをコンテキストに保存します。 - コンテキストに保存されたデータは、
ctx.data["INDEX"]のように、事前に定義されたキーを使ってアクセスできます。 - 他のステップも同様にコンテキストにアクセスでき、
ingestステップで作成されたインデックスを利用できます。
この方法により、
- ステップ間で大きなデータ構造を効率的に共有できます。
- ワークフローの実行全体を通じて持続する状態を管理できます。
- 直接的なイベントのやり取り以外の方法で、ステップ間の連携が可能になります。
これは特に、RAGシステムのような複雑なAIアプリケーションで、異なるコンポーネント間でデータや状態を共有する必要がある場合に有用です。
ワークフローのカスタマイズ
LlamaIndexは、一般的なユースケースに対応する事前定義されたワークフローセットを提供する予定です。これにより、多くの場合、1行のコードで実装が可能になります。さらに、ユーザーは既存のワークフローを少し変更して、カスタム動作を導入することもできます。
例えば、RAGワークフローをカスタマイズしてカスタムの再ランキングステップを使用したい場合、次のように実装できます:
class MyWorkflow(RAGWorkflow):
@step(pass_context=True)
def rerank(
self, ctx: Context, ev: Union[RetrieverEvent, StartEvent]
) -> Optional[QueryResult]:
# my custom reranking logic here
w = MyWorkflow(timeout=60, verbose=True)
result = await w.run(query="Who is Paul Graham?")
- 組み込みの
RAGWorkflowクラスを継承した新しいクラスMyWorkflowを作成します。 -
rerankステップをオーバーライドして、カスタムロジックを実装します。 -
@step(pass_context=True)デコレータを使用して、コンテキストへのアクセスを確保します。 - 新しい
MyWorkflowクラスのインスタンスを作成し、runメソッドを呼び出して実行します。
このアプローチの利点は以下となります。
- 既存のワークフローの大部分を再利用しつつ、特定の部分だけをカスタマイズできます。
- ワークフロー全体を一から書き直す必要がありません。
- カスタマイズの範囲を必要な部分に限定できるため、開発効率が向上します。
これにより、ユーザーは自身の特定のニーズに合わせてAIアプリケーションを柔軟にカスタマイズできる一方で、既存のワークフローの堅牢性と効率性を活用することができます。
ワークフローのデバッグ
アプリケーションロジックの複雑化に伴い、ワークフローも複雑になります。そのため、LlamaIndexは以下の機能を提供し、複雑なワークフローの理解とデバッグをサポートします:
-
draw_all_possible_flows関数は、ワークフロー内のすべてのステップと可能なイベントフローを視覚化します。全体的な構造と潜在的な実行パスを把握するのに役立ちます。 -
draw_most_recent_execution関数は、直近の実行で実際に発生したイベントフローのみを視覚化します。特定の入力に対する実際の動作を理解するのに有用です。

referred from https://www.llamaindex.ai/blog/introducing-workflows-beta-a-new-way-to-create-complex-ai-applications-with-llamaindex
これらの視覚化ツールに加えて、ワークフローは手動で実行することもできます。run_step()メソッドを複数回呼び出すことで、すべてのステップが完了するまでワークフローを段階的に実行できます。各run_step呼び出しの後、ワークフローを検査し、中間結果やデバッグログを確認することができます。
この手動実行アプローチにより、開発者はワークフローの各段階を詳細に追跡し、問題を特定したり、予期しない動作を調査したりすることができます。特に複雑なAIアプリケーションの開発において、この機能は非常に有用で、効率的なデバッグと問題解決を可能にします。
ワークフローを今すぐ使うべき理由
LlamaIndexのWorkflowは開発初期段階ですが、Query Pipelinesと比較して、拡張性・柔軟性が高く、大きな進歩を遂げています。さらに、通常はより成熟したソフトウェアに期待される機能セットも備えています:
- 完全な非同期処理とストリーミングサポート
- デフォルトでの計測機能、サポートされているインテグレーションにより、ワンクリックで観測可能性を提供
- ステップバイステップの実行によるより簡単なデバッグ
- イベント駆動型依存関係の検証と可視化
- Pydanticモデルとして実装されたイベントによるカスタマイズの容易さと新機能開発の促進
ということで、モジュールガイドに従って、実際に動かしてみる。Colaboratoryで。
パッケージインストール。workflowsではデフォルトでトレーシングに対応しているため、Arize Phonenixのインテグレーションパッケージも追加。
!pip install llama-index llama-index-callbacks-arize-phoenix
!pip freeze | egrep -i "llama-|arize|open-"
arize-phoenix==4.19.0
arize-phoenix-evals==0.14.1
llama-cloud==0.0.11
llama-index==0.10.59
llama-index-agent-openai==0.2.9
llama-index-callbacks-arize-phoenix==0.1.6
llama-index-cli==0.1.13
llama-index-core==0.10.59
llama-index-embeddings-openai==0.1.11
llama-index-indices-managed-llama-cloud==0.2.7
llama-index-legacy==0.9.48
llama-index-llms-openai==0.1.27
llama-index-multi-modal-llms-openai==0.1.8
llama-index-program-openai==0.1.7
llama-index-question-gen-openai==0.1.3
llama-index-readers-file==0.1.32
llama-index-readers-llama-parse==0.1.6
llama-parse==0.4.9
openinference-instrumentation-llama-index==2.2.1
トレーシング先はLLamaTraceを使う。
import llama_index.core
import os
from google.colab import userdata
PHOENIX_API_KEY = userdata.get('PHOENIX_API_KEY')
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)
LLMはOpenAIを使う。APIキーを環境変数にセット。
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
イベントループのネストを有効化。なお、Workflowsにおいてはasyncが前提になる。
import nest_asyncio
nest_asyncio.apply()
ワークフローの実装
ではGettiing Startedのサンプルコードを実行してみる。
from llama_index.core.workflow import (
Event,
StartEvent,
StopEvent,
Workflow,
step,
)
from llama_index.llms.openai import OpenAI
class JokeEvent(Event):
joke: str
class JokeFlow(Workflow):
llm = OpenAI(model="gpt-4o-mini")
@step()
async def generate_joke(self, ev: StartEvent) -> JokeEvent:
topic = ev.get("topic")
prompt = f"{topic}についてのジョークを生成して。"
response = await self.llm.acomplete(prompt)
return JokeEvent(joke=str(response))
@step()
async def critique_joke(self, ev: JokeEvent) -> StopEvent:
joke = ev.joke
prompt = f"次のジョークを徹底的に分析し、批評して: {joke}"
response = await self.llm.acomplete(prompt)
return StopEvent(result=str(response))
w = JokeFlow(timeout=60, verbose=False)
result = await w.run(topic="パイレーツ")
print(str(result))
このジョークは、言葉遊びを基にしたユーモアの一例です。以下に、ジョークの構造や要素を分析し、批評します。
### 構造分析
1. **設定**: 海賊というキャラクターが登場します。海賊は一般的に冒険や航海を象徴する存在であり、コンパスは航海において重要な道具です。この設定は、聴衆にとって親しみやすく、期待感を持たせます。
2. **質問形式**: 「なぜ海賊はいつもコンパスを持っているの?」という質問は、聴衆の興味を引き、答えを期待させます。この形式は、ジョークの効果を高めるためによく使われます。
3. **ダブルミーニング**: ジョークの核心は「北を見失いたくない」という部分です。「失う」という言葉が二重の意味を持っています。一つは物理的な方向を失うこと、もう一つは「北」を「失う」という言葉遊びです。この言葉のかけ方が、ジョークのユーモアの源泉です。
### 批評
- **ユーモアの質**: このジョークは、シンプルでわかりやすい言葉遊びを用いており、聴衆にすぐに理解されやすいです。しかし、言葉遊びのレベルは比較的低いため、特に高度なユーモアを求める人には物足りないかもしれません。
- **文化的背景**: 海賊やコンパスというテーマは、特に西洋文化において広く知られているため、国や文化によっては共感を得やすいです。ただし、海賊文化に馴染みのない人には、ジョークの面白さが伝わりにくい可能性があります。
- **オリジナリティ**: 言葉遊び自体は一般的な手法であり、特に新しいアイデアや視点を提供しているわけではありません。そのため、オリジナリティに欠けると感じる人もいるでしょう。
- **感情的な反応**: 聴衆がこのジョークを聞いたとき、軽い笑いや微笑みを引き起こすことが期待されますが、深い感情的な反応を引き起こすことは難しいでしょう。
### 結論
このジョークは、シンプルで親しみやすい言葉遊びを用いたものであり、特に子供やカジュアルな場面での笑いを狙ったものと言えます。ユーモアの質やオリジナリティには限界がありますが、軽い気持ちで楽しむには適した内容です。
部分ごとに見ていく。
ワークフローイベントの定義
ワークフローの各ステップ間でやり取りされるイベントを定義する。この定義はPydanticで行える。
以下の例ではJokeEventというイベントでjokeという属性を持たせている。
class JokeEvent(Event):
joke: str
ワークフロークラスの作成
Workflowクラスをサブクラス化して、ワークフローを定義する。
以下ではJokeFlowというワークフローを定義して、クラス内でモデルの定義を行っている。
class JokeFlow(Workflow):
llm = OpenAI(model="gpt-4o-mini")
(snip)
ワークフローのエントリーポイント
ワークフローが実行されるとStartEventイベントが発火され、これがエントリーポイントとなる。イベントを処理するステップは@step()デコレータ関数を定義する。
以下ではStartEventに紐づくステップとしてgenerate_jokeステップを定義、generate_jokeはStartEventから入力を取り出して、処理を行い、その結果をJokeEventとして返す。これによりJokeEventが発火され、値が受け渡される。
class JokeFlow(Workflow):
llm = OpenAI(model="gpt-4o-mini")
@step()
async def generate_joke(self, ev: StartEvent) -> JokeEvent:
topic = ev.get("topic")
prompt = f"{topic}についてのジョークを生成して。"
response = await self.llm.acomplete(prompt)
return JokeEvent(joke=str(response))
(snip)
ワークフローのイグジットポイント
StopEventが発火されると、ワークフローの処理は終了し結果が返される。
以下の例ではJokeEventイベントからcritique_jokeステップが実行され、処理を行った後、StopEventイベントを発火して、ワークフローの処理が終了する。
class JokeFlow(Workflow):
(snip)
@step()
async def critique_joke(self, ev: JokeEvent) -> StopEvent:
joke = ev.joke
prompt = f"次のジョークを徹底的に分析し、批評して: {joke}"
response = await self.llm.acomplete(prompt)
return StopEvent(result=str(response))
ワークフローの実行
ワークフローの実行は.run()メソッドで行う。.run()メソッドは非同期なのでawaitする。
w = JokeFlow(timeout=60, verbose=False)
result = await w.run(topic="パイレーツ")
print(str(result))
なおverboseオプションを有効化すると以下のようなデバッグ出力が行われ、イベントの遷移が確認できる。
Running step generate_joke
Step generate_joke produced event JokeEvent
Running step critique_joke
Step critique_joke produced event StopEvent
ワークフローの可視化
ワークフローは可視化できる。pyvisが必要になるのでインストール。
!pip install pyvis
可視化は、ワークフロークラスそのものに対しても生成できるし、最後に実行したワークフローに対しても生成できる。前者の場合はワークフローが取りうるパスを全てまとめたものとなり、後者は実行時にたどったパスということになる様子。
from llama_index.core.workflow import (
# 注: ドキュメントには`draw_all_possible_paths`とあるが、おそらく間違い。
draw_all_possible_flows,
draw_most_recent_execution,
)
# 定義したワークフロークラスに対して可視化する場合は`draw_all_possible_flows`を使う
draw_all_possible_flows(JokeFlow, filename="joke_flow_all.html")
# 実行したワークフローに対して可視化する場合は`draw_most_recent_execution`を使う
w = JokeFlow(timeout=60, verbose=True)
result = await w.run(topic="パイレーツ")
draw_most_recent_execution(w, filename="joke_flow_recent.html")
今回の例では一本道のパスなので、どちらの場合も同じ内容になった。

グローバルなコンテキスト/ステート
Contextを使うと、ステップ間で共有できるコンテキスト/ステートを作成することもできる。ステップのデコレータにpass_context=Trueを渡してやると、共有オブジェクト的なContextにアクセスできるらしい。
from llama_index.core.workflow import Context
@step(pass_context=True)
async def query(self, ctx: Context, ev: QueryEvent) -> StopEvent:
# コンテキストからデータを取り出す
query = ctx.data.get("query")
# コンテキストにデータを保存する
ctx["key"] = "val"
result = run_query(query)
return StopEvent(result=result)
複数のイベントを待つ
コンテキストには、単にデータを保持して共有するだけではなく、複数のイベントをバッファリングして待機するユーティリティとしての使い方もできる。
@step(pass_context=True)
async def query(
self, ctx: Context, ev: QueryEvent | RetrieveEvent
) -> StopEvent | None:
data = ctx.collect_events(evm[QueryEvent, RetrieveEvent])
# 実行してよいかをチェックする
if data is None:
return None
# バッファリングされたイベントを使う
print(data[0]) # QueryEvent
print(data[1]) # RetrieveEvent
ctx.collect_events()を使うと、すべてのイベントが到着するまでバッファリングして、全て到着したら(要求された順序で)データを返す、というようなステップを定義することができる。
ステップ実行
run_stepを使えば、ワークフローのステップ実行が行える。
import time
import asyncio
w = JokeFlow(timeout=60, verbose=True)
# ワークフローを開始
print("開始")
await w.run_step(topic="パイレーツ")
# 完了するまで繰り返す
while not w.is_done():
print("ステップ継続")
await w.run_step()
await asyncio.sleep(10)
print("完了")
# 最終結果を取得
result = w.get_result()
print("===== 出力 =====")
print(result[:50] + "...")
開始
Running step generate_joke
ステップ継続
Step generate_joke produced event JokeEvent
Running step critique_joke
ステップ継続
Step critique_joke produced event StopEvent
ステップ継続
完了
===== 出力 =====
このジョークは、言葉遊びとダブルミーニングを利用したユーモアの一例です。以下に、ジョークの構造や要素...
ちょっと今回の例ではあまり良い例ではないけども、各イベントごとに一時停止されるような感じ。
クラスを使わないワークフローの定義
ワークフローをサブクラス化せずに、関数デコレータだけで定義することもできる。
from llama_index.core.workflow import (
Event,
StartEvent,
StopEvent,
Workflow,
step,
)
from llama_index.llms.openai import OpenAI
class JokeEvent(Event):
joke: str
llm = OpenAI(model="gpt-4o-mini")
joke_flow = Workflow(timeout=60, verbose=True)
@step(workflow=joke_flow)
async def generate_joke(ev: StartEvent) -> JokeEvent:
# ドキュメントだと`ev.topic`になっているが、そんなattirbuteはないと言われる
topic = ev.get("topic")
prompt = f"{topic}についてのジョークを生成して。"
response = await llm.acomplete(prompt)
return JokeEvent(joke=str(response))
@step(workflow=joke_flow)
async def critique_joke(ev: JokeEvent) -> StopEvent:
# こちらはイベント定義があるので、`ev.joke`で取り出せる
joke = ev.joke
prompt = f"次のジョークを徹底的に分析し、批評して: {joke}"
response = await llm.acomplete(prompt)
return StopEvent(result=str(response))
result = await joke_flow.run(topic="パイレーツ")
print(result)
このジョークは、海賊の特徴や文化に基づいた言葉遊びを利用しています。以下に、ジョークの構造や要素を分析し、批評します。
### 構造分析
1. **質問形式**: ジョークは「なぜ海賊はいつも『アーrrr!』と言うの?」という質問から始まります。この形式は、聞き手の興味を引き、期待感を高める効果があります。
2. **答え**: 「だって、彼らは『海の男』だからさ!」という答えは、海賊のイメージを強調しています。「アーrrr!」という言葉は、海賊の典型的なセリフとして知られており、海賊文化の象徴的な表現です。
### 言葉遊び
- **言葉の響き**: 「アーrrr!」という表現は、海賊の粗野で無骨なイメージを想起させます。この音の響きが、海賊のキャラクターを強調し、ユーモアを生み出しています。
- **「海の男」**: このフレーズは、海賊が海で生活し、冒険をする男たちであることを示しています。ここでの「男」という言葉は、海賊の勇敢さや自由さを象徴しています。
### 批評
1. **ユーモアの質**: このジョークはシンプルで、子供から大人まで楽しめるタイプのユーモアです。特に、海賊のキャラクターが好きな人や、海賊映画や物語に親しんでいる人には受け入れられやすいでしょう。
2. **文化的背景**: 海賊というテーマは、映画や文学で広く知られているため、聞き手が共通の理解を持っていることが前提となっています。このため、特定の文化や背景を持つ人々には特に響くでしょう。
3. **深みの欠如**: 一方で、このジョークは非常にシンプルであり、深い意味や複雑な構造を持っていないため、あまりに直球すぎて物足りなさを感じる人もいるかもしれません。特に、より洗練されたユーモアを求める人には物足りないかもしれません。
### 結論
このジョークは、海賊のイメージを利用したシンプルで親しみやすいユーモアです。聞き手の文化的背景や興味によって受け取り方が変わるため、特定の状況や聴衆においては非常に効果的です。しかし、深みや複雑さを求める人には物足りないと感じられる可能性もあります。全体として、軽い気持ちで楽しむには良いジョークと言えるでしょう。
ここまでの所感
一言で言ってしまうと、LangChainでいうところのLangGraphに相当するものだと思う。
LangChainにおけるフローエンジニアリングでは、ループが必要ないDAGはLCEL、ループが必要なステートマシンはLangGraph、という風にユースケースごとにフレームワークが分かれている。
それに対して、LlamaIndexでは、DAGについてはQuery Pipelineがあるが、LangGraphに相当するものがなかった。ループ的なことをやろうと思うとエージェントモジュールを組み合わせるしかないのかなと思うし、またそのやり方もわかりやすいものではない印象がある(単体で使う分にはそれほど複雑ではないと思うけど、Query Pipelineと組み合わせると一気に複雑化する感じ)。このあたりは公式のブログにも書いてある通り。
今回のWorkflowsはそれを埋めるものになるかなと思う。
個人的にはLangGraphよりもこちらの書き方のほうが好みかな、個々の処理がカプセル化されていて、見やすいし、テストも機能追加とかもやりやすそうに思える。ちょっとタイプ数は増えそうだけど、
まだベータではあるけども、ちょっと期待できそうな印象。
個人的にはこれ、Alexa Skills Kitを思い出した。Alexaスキル開発したことある人なら雰囲気がわかるのではなかろうか。
ひととおりWorkflowsの仕組み的なところを抑えたので、実際の使用例を少し試してみる。ということで、RAG+リランキングのサンプルをやってみる。
まず、全体像をざっと図にしてみた。今回のサンプルはグローバルコンテキストの使い方がよく分かるものになっていると思う。

RAGのドキュメントを用意する。以下を使う。
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
# markdown(.md)ファイルとして出力
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
data/オグリキャップ.txtが作成される。
今回のワークフローで必要なカスタムのイベントは、RetrieverEventとRerankEventの2つ。これを定義する。
from llama_index.core.workflow import Event
from llama_index.core.schema import NodeWithScore
class RetrieverEvent(Event):
"""検索実行の結果"""
nodes: list[NodeWithScore]
class RerankEvent(Event):
"""検索されたノードのりランキング結果"""
nodes: list[NodeWithScore]
ワークフローを定義する。
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.core.postprocessor.llm_rerank import LLMRerank
from llama_index.core.workflow import (
Context,
Workflow,
StartEvent,
StopEvent,
step,
)
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
class RAGWorkflow(Workflow):
@step(pass_context=True)
async def ingest(self, ctx: Context, ev: StartEvent) -> StopEvent | None:
"""StartEventに`dir_name`が渡されるとトリガーされる、RAGのIndexing Stage用のエントリーポイント"""
dirname = ev.get("dirname")
if not dirname:
return None
documents = SimpleDirectoryReader(dirname).load_data()
# ドキュメントからインデックスを作成して、グローバルコンテキストに保存
ctx.data["index"] = VectorStoreIndex.from_documents(
documents=documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
)
return StopEvent(result=f"{len(documents)}件のドキュメントをインデックス化しました。")
@step(pass_context=True)
async def retrieve(
self, ctx: Context, ev: StartEvent
) -> RetrieverEvent | None:
"""StartEventに`query`が渡されるとトリガーされる、RAGのQuerying Stage用のエントリーポイント"""
query = ev.get("query")
if not query:
return None
print(f"データベース検索クエリ: {query}")
# グローバルコンテキストにクエリを保存
ctx.data["query"] = query
# グローバルコンテキストからインデックスを取得
index = ctx.data.get("index")
if index is None:
print("インデックスは空です。クエリを行う前に、ドキュメントのインデックスを作成してください!")
return None
retriever = index.as_retriever(similarity_top_k=2)
nodes = retriever.retrieve(query)
print(f"{len(nodes)}件のノードを取得しました。")
return RetrieverEvent(nodes=nodes)
@step(pass_context=True)
async def rerank(self, ctx: Context, ev: RetrieverEvent) -> RerankEvent:
# ノードをリランキング
ranker = LLMRerank(
choice_batch_size=5, top_n=3, llm=OpenAI(model="gpt-4o-mini")
)
print(ctx.data.get("query"), flush=True)
new_nodes = ranker.postprocess_nodes(
ev.nodes, query_str=ctx.data.get("query") # グローバルコンテキストからクエリを取得
)
print(f"{len(new_nodes)}件のノードをリランキングしました。")
return RerankEvent(nodes=new_nodes)
@step(pass_context=True)
async def synthesize(self, ctx: Context, ev: RerankEvent) -> StopEvent:
"""リランキングされたノードを使って、ストリーミングレスポンスを返す"""
llm = OpenAI(model="gpt-4o-mini")
summarizer = CompactAndRefine(llm=llm, streaming=True, verbose=True)
# グローバルコンテキストからクエリを取得
query = ctx.data.get("query")
response = await summarizer.asynthesize(query, nodes=ev.nodes)
return StopEvent(result=response)
同じイベントでも入力データによって別のステップに振り分けていたり、都度都度コンテキストに出し入れしたり、というところは参考になる。
ではワークフローを実行する。まずはインデックスの作成。
# ワークフローインスタンスを生成
w = RAGWorkflow()
# ワークフローを実行して、インデックスを作成
await w.run(dirname="data")
1件のドキュメントをインデックス化しました。
次に、クエリを投げる。
# ワークフローを実行して、クエリを投げる
result = await w.run(query="オグリキャップの血統について教えて。")
結果を出力。今回はストリーミングで出力する。
async for chunk in result.async_response_gen():
print(chunk, end="", flush=True)
データベース検索クエリ: オグリキャップの血統について教えて。
2件のノードを取得しました。
オグリキャップの血統について教えて。
2件のノードをリランキングしました。
オグリキャップの血統は、父がダンシングキャップで、母がホワイトナルビーです。ダンシングキャップの種牡馬成績はあまり優れていなかったため、オグリキャップは「突然変異で生まれた」とか「ネイティヴダンサーの隔世遺伝で生まれた競走馬」とも言われています。しかし、血統評論家はダンシングキャップを「一発ある血統」と評価し、ネイティヴダンサー系の種牡馬が時折大物を出すことから、オグリキャップもそのような可能性を秘めていたと分析しています。
母のホワイトナルビーは現役時代に笠松で4勝を挙げ、産駒は全て競馬で勝利を収めています。5代母のクインナルビーは1953年の天皇賞(秋)を制した実績があります。オグリキャップには兄弟もおり、オグリローマンは1994年の桜花賞優勝馬、オグリイチバンはシンジケートを組まれて種牡馬となりました。また、オグリトウショウもオグリキャップの活躍を受けて誕生し、競走馬引退後に種牡馬となっています。
可視化。
from llama_index.core.workflow import (
draw_all_possible_flows,
draw_most_recent_execution,
)
draw_all_possible_flows(RAGWorkflow, filename="rag_workflow_all.html")
draw_most_recent_execution(w, filename="jrag_workflow_recent.html")
rag_workflow_all.html

rag_workflow_recent.html

一応トレースも。まずinject

retrieve

rerank

synthesize

ところでトレース結果、最終的にはエラーになってるのだよな、、、どうもワークフロー完了が全部Exception扱いになってるっぽい。この辺はベータだからしょうがないのかも。
次はFunction Callingを使ったエージェントのサンプル。
こちらも全体像から。
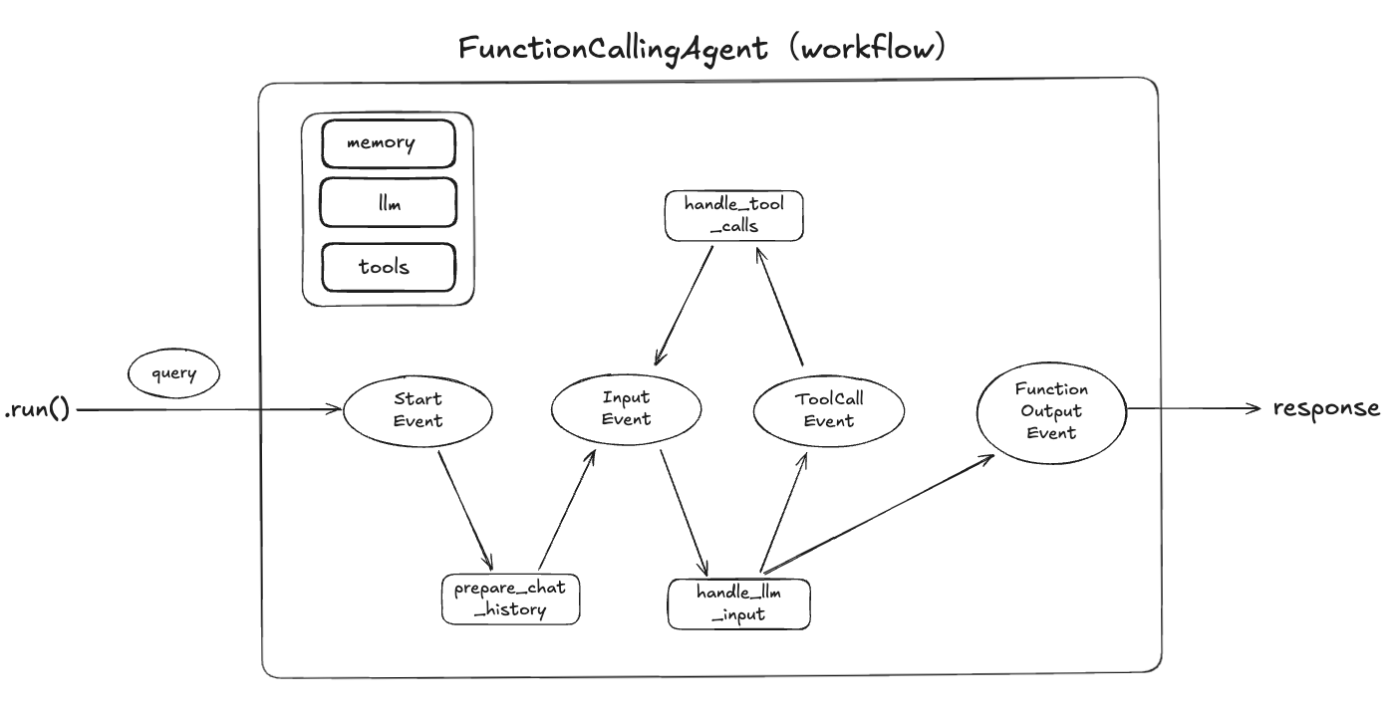
RAG+リランキングの例では、各ステップで共有するインデックスやクエリはContextを使用していたがが、今回の例では、会話履歴・LLM・ツールなどをコンストラクタで定義して、各ステップからアクセスできるようになっている。
あとエージェントということでFunction Callingを使う箇所でループしている部分がある。
上記を踏まえて、イベントの定義。以下のイベントを定義している。
-
InputEvnet- (クエリやツール実行結果を含む)会話履歴を受け取ったら発火する
- 上記をLLMに投げる
handle_llm_inputを呼び出す
-
ToolCallEvent- ToolCallが必要な場合にツールのリストを受け取ったら発火する
- ツールを実行する
handle_tool_callsを呼び出す
ドキュメントではもう一つ。FunctionOutputEventというイベントが定義されているのだけど、ワークフローを見ても使用されていないので、不要だと思う。
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import ToolSelection, ToolOutput
from llama_index.core.workflow import Event
class InputEvent(Event):
input: list[ChatMessage]
class ToolCallEvent(Event):
tool_calls: list[ToolSelection]
# ドキュメントでは定義されているが、実際には使用されていない
#class FunctionOutputEvent(Event):
# output: ToolOutput
ではワークフローを定義。
from typing import Any, List
from llama_index.core.llms.function_calling import FunctionCallingLLM
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.tools.types import BaseTool
from llama_index.core.workflow import Workflow, StartEvent, StopEvent, step
class FuncationCallingAgent(Workflow):
def __init__(
self,
*args: Any,
llm: FunctionCallingLLM | None = None,
tools: List[BaseTool] | None = None,
**kwargs: Any,
) -> None:
super().__init__(*args, **kwargs)
self.tools = tools or []
self.llm = llm or OpenAI()
assert self.llm.metadata.is_function_calling_model
self.memory = ChatMemoryBuffer.from_defaults(llm=llm)
# toolの実行結果をソースとして保持する
self.sources = []
@step()
async def prepare_chat_history(self, ev: StartEvent) -> InputEvent:
# ソースを削除
self.sources = []
# ユーザの入力を取得
# ドキュメントではev.inputだけど、
# `'StartEvent' object has no attribute 'input'`
# となってしまう。
user_input = ev.get("input")
user_msg = ChatMessage(role="user", content=user_input)
self.memory.put(user_msg)
# 会話履歴を取得
chat_history = self.memory.get()
return InputEvent(input=chat_history)
@step()
async def handle_llm_input(
self, ev: InputEvent
) -> ToolCallEvent | StopEvent:
chat_history = ev.input
# (クエリとツール実行結果を含む)会話履歴をLLMに投げる
response = await self.llm.achat_with_tools(
self.tools, chat_history=chat_history
)
self.memory.put(response.message)
# LLMからのレスポンスからtool callを取り出す
tool_calls = self.llm.get_tool_calls_from_response(
response, error_on_no_tool_call=False
)
if not tool_calls:
# tool callがなければ、StopEvnetを呼び出して最終解答を出力へ
return StopEvent(
result={"response": response, "sources": [*self.sources]}
)
else:
# tool callがあれば、ToolCallEventを呼び出してツール実行へ
return ToolCallEvent(tool_calls=tool_calls)
@step()
async def handle_tool_calls(self, ev: ToolCallEvent) -> InputEvent:
tool_calls = ev.tool_calls
tools_by_name = {tool.metadata.get_name(): tool for tool in self.tools}
tool_msgs = []
# ツールの呼び出し
for tool_call in tool_calls:
tool = tools_by_name.get(tool_call.tool_name)
additional_kwargs = {
"tool_call_id": tool_call.tool_id,
"name": tool.metadata.get_name(),
}
if not tool:
tool_msgs.append(
ChatMessage(
role="tool",
content=f"ツール「{tool_call.tool_name}」は存在しません。",
additional_kwargs=additional_kwargs,
)
)
continue
# ツールの実行
try:
tool_output = tool(**tool_call.tool_kwargs)
self.sources.append(tool_output)
tool_msgs.append(
ChatMessage(
role="tool",
content=tool_output.content,
additional_kwargs=additional_kwargs,
)
)
except Exception as e:
tool_msgs.append(
ChatMessage(
role="tool",
content=f"ツール呼び出しでエラーが発生しました: {e}",
additional_kwargs=additional_kwargs,
)
)
# ツール実行結果を会話履歴に追加
for msg in tool_msgs:
self.memory.put(msg)
chat_history = self.memory.get()
# 会話履歴をInputEventに渡す
return InputEvent(input=chat_history)
先にワークフローを可視化してみる。
from llama_index.core.workflow import (
draw_all_possible_flows,
draw_most_recent_execution,
)
draw_all_possible_flows(FuncationCallingAgent, filename="function_calling_agent_workflow_all.html")
ループ構造になっているのがわかる。

ではツールを渡して、ワークフローを実行。
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
def add(x: int, y: int) -> int:
"""2つの数値を加算する便利な関数"""
return x + y
def multiply(x: int, y: int) -> int:
"""2つの数値を乗算する便利な関数"""
return x * y
tools = [
FunctionTool.from_defaults(add),
FunctionTool.from_defaults(multiply),
]
agent = FuncationCallingAgent(
llm=OpenAI(model="gpt-4o-mini"), tools=tools, timeout=120, verbose=True
)
ret = await agent.run(input="こんにちは!")
print(ret["response"])
ツールの実行が不要な場合はToolCallEventは発生しない。
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event StopEvent
assistant: こんにちは!今日はどんなことをお手伝いできますか?
draw_most_recent_execution(agent, filename="function_calling_agent_workflow_recent.html")

計算が必要なクエリを投げてみる。
ret = await agent.run(input="(2123 + 2321) * 312 は?")
print(ret["response"])
ToolCallEventが複数回発生して最終回答が生成されているのがわかる。
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event ToolCallEvent
Running step handle_tool_calls
Step handle_tool_calls produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event ToolCallEvent
Running step handle_tool_calls
Step handle_tool_calls produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event StopEvent
assistant: 計算の結果、(2123 + 2321) * 312 は 1,386,528 です。何か他にお手伝いできることはありますか?
draw_most_recent_execution(agent, filename="function_calling_agent_workflow_recent.html")

会話履歴についても確認
ret = await agent.run(input="それを2で割って。")
print(ret["response"])
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event ToolCallEvent
Running step handle_tool_calls
Step handle_tool_calls produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event ToolCallEvent
Running step handle_tool_calls
Step handle_tool_calls produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event StopEvent
assistant: 1,386,528 を 2 で割ると 693,264 になります。他に何かお手伝いできることはありますか?
会話が引き継がれているのがわかる。
なお、StopEventに渡しているレスポンスは、LLMからの回答であるresponseと、ツール実行結果をソース/根拠として使うためのsourcesという辞書を生成して渡していた。以下のように参照できる。
print(ret["sources"])
[ToolOutput(content='2773056', tool_name='multiply', raw_input={'args': (), 'kwargs': {'x': 1386528, 'y': 2}}, raw_output=2773056, is_error=False), ToolOutput(content='693264.0', tool_name='multiply', raw_input={'args': (), 'kwargs': {'x': 1386528, 'y': 0.5}}, raw_output=693264.0, is_error=False)]
もう1つ。ReAct Agentのサンプル。これは結構複雑。
図にしてみた。

以下のステップで構成される。
-
new_user_msg-
StartEventから発火される - ユーザからの入力クエリを受け取って会話履歴を初期化する
- ReActの推論ステップの状態を初期化
-
PrepEventを発火する
-
-
prepare_chat_history-
PrepEventから発火される - 会話履歴と、ReActの推論ステップの状態、ツールを取得して、ReActプロンプトを作成する
-
InputEventを発火する
-
-
handle_llm_input-
InputEventから発火される - 上記で作成されたReActプロンプトをLLMに投げる
- LLMからの応答で分岐して、それぞれのイベントを発火する
- ReActの推論プロセスが完了している場合
-
StopEventを発火して最終回答を返す
-
- ReActの推論ステップが完了していない、かつ、推論ステップが"Action"の場合
-
ToolCallEventを発火(してツールを実行させる)
-
- どちらにも該当しない
-
PrepEventを発火して再度推論ループを回す
-
- ReActの推論プロセスが完了している場合
-
-
handle_tool_calls-
ToolCallEventから発火される - tool callのレスポンスを受けてツールを実行
-
PrepEventを発火して再度推論ループを回す
-
ポイントは、ReActの推論プロセス(Thought/Action/Observation)ごとに処理が分岐するところだと思う。その部分はhandle_llm_inputステップの中で実装されていて、そのためのReActプロンプト生成がprepare_chat_historyで行われ、推論プロセスの状態管理はContextで管理されている。ここはイベントドリブンちょっとわかりにくく感じるかもしれない。
ということでコードを書いていく。まずイベント定義。
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import ToolSelection, ToolOutput
from llama_index.core.workflow import Event
class PrepEvent(Event):
pass
class InputEvent(Event):
input: list[ChatMessage]
class ToolCallEvent(Event):
tool_calls: list[ToolSelection]
# ドキュメントのコードでは定義されているが、実際には使用されていない
#class FunctionOutputEvent(Event):
# output: ToolOutput
ここは各ステップをつなぐことになるのだけど、いろいろコンストラクタで持たせているものや、コンテキストで持たせているものもあって、それほど受け渡しているものはない。この辺の棲み分けをどうするかは慣れが必要な感がある。
ちょっとややこしいなと思うのはPrepEventで、これは複数のステップからの処理を受けてprepare_chat_historyに流すだけのものになっている、なるほど。
ではワークフローを定義。
from typing import Any, List
from llama_index.core.agent.react import ReActChatFormatter, ReActOutputParser
from llama_index.core.agent.react.types import (
ActionReasoningStep,
ObservationReasoningStep,
)
from llama_index.core.llms.llm import LLM
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.tools.types import BaseTool
from llama_index.core.workflow import (
Context,
Workflow,
StartEvent,
StopEvent,
step,
)
from llama_index.llms.openai import OpenAI
class ReActAgent(Workflow):
def __init__(
self,
*args: Any,
llm: LLM | None = None,
tools: list[BaseTool] | None = None,
extra_context: str | None = None,
**kwargs: Any,
) -> None:
super().__init__(*args, **kwargs)
self.tools = tools or []
self.llm = llm or OpenAI()
self.memory = ChatMemoryBuffer.from_defaults(llm=llm)
self.formatter = ReActChatFormatter(context=extra_context or "")
self.output_parser = ReActOutputParser()
self.sources = []
@step(pass_context=True)
async def new_user_msg(self, ctx: Context, ev: StartEvent) -> PrepEvent:
# ソースをクリア
self.sources = []
# ユーザの入力を取得
# ドキュメントではev.inputだけど、
# `'StartEvent' object has no attribute 'input'`
# となってしまう。
user_input = ev.get("input")
user_msg = ChatMessage(role="user", content=user_input)
self.memory.put(user_msg)
# 現在の推論状態をクリア
ctx.data["current_reasoning"] = []
return PrepEvent()
@step(pass_context=True)
async def prepare_chat_history(
self, ctx: Context, ev: PrepEvent
) -> InputEvent:
# 会話履歴を取得
chat_history = self.memory.get()
current_reasoning = ctx.data.get("current_reasoning", [])
# ReActの推論プロセスの状態を踏まえて、ReActプロンプトを生成
llm_input = self.formatter.format(
self.tools, chat_history, current_reasoning=current_reasoning
)
return InputEvent(input=llm_input)
@step(pass_context=True)
async def handle_llm_input(
self, ctx: Context, ev: InputEvent
) -> ToolCallEvent | StopEvent:
chat_history = ev.input
response = await self.llm.achat(chat_history)
# ReActの推論プロセスの状態により分岐
try:
reasoning_step = self.output_parser.parse(response.message.content)
ctx.data.get("current_reasoning", []).append(reasoning_step)
if reasoning_step.is_done:
# 推論プロセスが完了している場合
self.memory.put(
ChatMessage(
role="assistant", content=reasoning_step.response
)
)
# StopEventを発火(して最終回答を出力)
return StopEvent(
result={
"response": reasoning_step.response,
"sources": [*self.sources],
"reasoning": ctx.data.get("current_reasoning", []),
}
)
elif isinstance(reasoning_step, ActionReasoningStep):
# 推論プロセスが"Action"の場合はToolEventを発火(してツール実行)
tool_name = reasoning_step.action
tool_args = reasoning_step.action_input
return ToolCallEvent(
tool_calls=[
ToolSelection(
tool_id="fake",
tool_name=tool_name,
tool_kwargs=tool_args,
)
]
)
except Exception as e:
ctx.data.get("current_reasoning", []).append(
ObservationReasoningStep(
observation=f"推論結果のパースに失敗しました: {e}"
)
)
# tool callがレスポンスに含まれない、もしくはReAct推論プロセスが最終回答ではないなら、PrepEventでループさせる
return PrepEvent()
@step(pass_context=True)
async def handle_tool_calls(
self, ctx: Context, ev: ToolCallEvent
) -> PrepEvent:
tool_calls = ev.tool_calls
tools_by_name = {tool.metadata.get_name(): tool for tool in self.tools}
# ツールの実行
for tool_call in tool_calls:
tool = tools_by_name.get(tool_call.tool_name)
if not tool:
ctx.data.get("current_reasoning", []).append(
ObservationReasoningStep(
observation=f"ツール「{tool_call.tool_name}」は存在しません。"
)
)
continue
try:
tool_output = tool(**tool_call.tool_kwargs)
self.sources.append(tool_output)
ctx.data.get("current_reasoning", []).append(
ObservationReasoningStep(observation=tool_output.content)
)
except Exception as e:
ctx.data.get("current_reasoning", []).append(
ObservationReasoningStep(
observation=f"Error calling tool {tool.metadata.get_name()}: {e}"
)
)
# 次の繰り返しへ
return PrepEvent()
自分の場合、ReActAgentモジュールしか使ったことがなくて、ReActがやってることは理解しつつも、スクラッチで実装したことがなかった。で、ReActChatFormatter、ReActOutputParserとか何するものぞ?と思って改めて調べてみたらここにあった。
ReActChatFormatterは ReAct向けにプロンプトを作ってくれるもので、ReActOutputParserはそのプロンプトに対するLLMの出力をパースしてReActの推論プロセスの状態を取得するためのものらしい。つまり、これらを使ってReActの推論プロセスを踏まえた分岐を行っているということね。
で、一旦可視化してみる。
from llama_index.core.workflow import (
draw_all_possible_flows,
draw_most_recent_execution,
)
draw_all_possible_flows(ReActAgent, filename="react_agent_workflow_all.html")
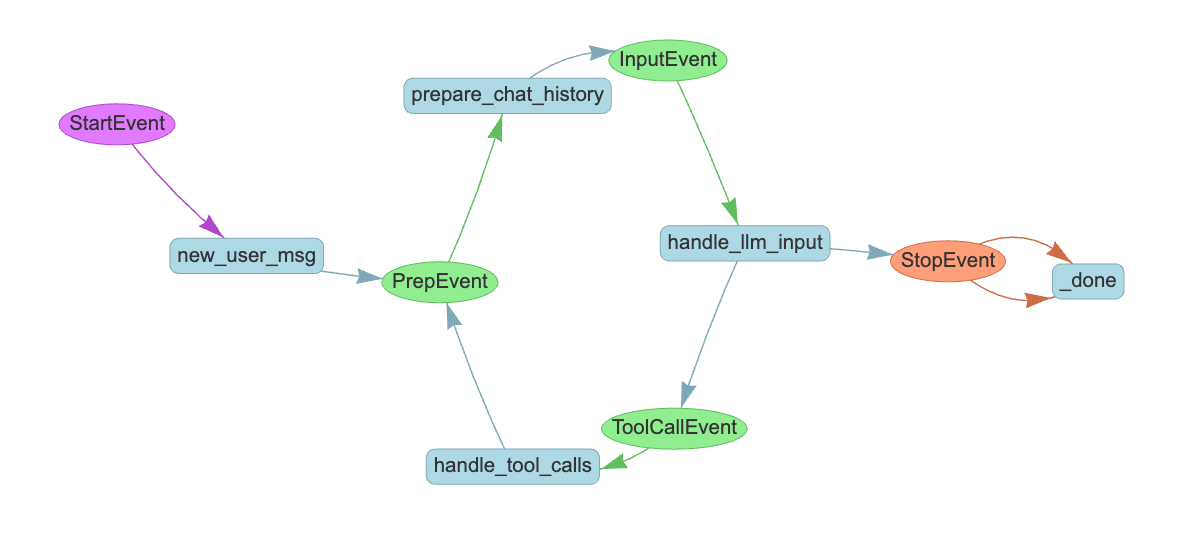
自分がコードを読みながらまとめた図とやや違っているけど、どうやらこの可視化は各ステップの型ヒントから作成されているみたい。コードを読む限りはhandle_llm_inputはPrepEventを返す場合があるけど、戻り値の型にPrepEventが含まれていないため、この可視化に含まれていないのだと思う。修正して再度出力してみるとこうなった。

ではワークフローを実行してみる。
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
def add(x: int, y: int) -> int:
"""2つの数値を加算する便利な関数"""
return x + y
def multiply(x: int, y: int) -> int:
"""2つの数値を乗算する便利な関数"""
return x * y
tools = [
FunctionTool.from_defaults(add),
FunctionTool.from_defaults(multiply),
]
agent = ReActAgent(
llm=OpenAI(model="gpt-4o-mini"), tools=tools, timeout=120, verbose=True
)
ret = await agent.run(input="こんにちは!")
print(ret["response"])
Running step new_user_msg
Step new_user_msg produced event PrepEvent
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event StopEvent
こんにちは!どのようにお手伝いできますか?
ツールを使うクエリを続けて投げてみる。
ret = await agent.run(input="(2123 + 2321) * 312 は?")
print(ret["response"])
Running step new_user_msg
Step new_user_msg produced event PrepEvent
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event ToolCallEvent
Running step handle_tool_calls
Step handle_tool_calls produced event PrepEvent
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event ToolCallEvent
Running step handle_tool_calls
Step handle_tool_calls produced event PrepEvent
Running step prepare_chat_history
Step prepare_chat_history produced event InputEvent
Running step handle_llm_input
Step handle_llm_input produced event StopEvent
(2123 + 2321) * 312 の結果は1386528です。
トレースを見てみるとReActの推論ステップが確認できた。

サンプルはもう一つあって、出力パーサーで構造化して、出力バリデーションに失敗したらリトライするというようなもの。気が向いたらやってみたいと思う。
まとめ
個人的にはとても良い印象を持った。上の方にも書いたけど、
一言で言ってしまうと、LangChainでいうところのLangGraphに相当するものだと思う。
それに対して、LlamaIndexでは、DAGについてはQuery Pipelineがあるが、LangGraphに相当するものがなかった。
今回のWorkflowsはそれを埋めるものになるかなと思う。
というところで、やっとピースが埋まった感じがしている。
以前にLangChainのLCELでRAGを実装したとき、これまでブラックボックスだったモジュールがLCELでコンポーネントを分解しながら書けるあの感じ、それと同じものを今回、WorkflowsでReActエージェントを書きながら感じた。フレームワークが、高レベルなモジュールを使って楽に書く、低レベルなモジュールで細かく書く、の両方を用意してくれるのは、開発者側のいろんなユースケースに合うと思うので良いと思う。
あとは、
- ステップ間のデータの共有に、コンテキストを使うか、コンストラクタで渡すか、みたいなのはどう考えればいいのだろうか?
- シンプルなエージェントならば、普通にReAct Agentとか使ったほうがぜんぜんスッキリ書けるので、ユースケースを踏まえて選ぶ必要がありそう。
- トレーシングできるのはいいんだけど、もうちょっとシンプルにverboseできないかな?
- マルチエージェントと謳っているが、具体的にどう書けばいいのかがわからない。
- Human-in-the-loopはどう書けばいいんだろうか?
- マルチエージェントの場合はLlama Agentもあるが、どう棲み分けるのか?
- Llama Agentはややインフラも含めた感じのオーケストレーションだと思っている。
- (まだ書き方はわからないけど、Workflowsのほうがよりコード的な解決には近い印象)
あたりは調べてつつ引き続きウォッチしていく感じかな、まだベータだし情報も足りないので。
とりあえずQuery Pipelineはもう使わない、というか慣れれなかったので、同じことならばWorkflowsで書いてみて慣れていきたいなという感じ。
設計力がより必要な感はある・・・・
とりあえずQuery Pipelineはもう使わない、というか慣れれなかったので、同じことならばWorkflowsで書いてみて慣れていきたいなという感じ。
と思っていたのだけど、Workflowの今の感じだと並列とかはできないんじゃないかなぁ・・・・
シンプルなコードで試してみるか
と思ったけど、
コンテキストには、単にデータを保持して共有するだけではなく、複数のイベントをバッファリングして待機するユーティリティとしての使い方もできる。
これを使えばステップを並列で実行するようなフローができるはず・・・ちょっと試してみる
あるトピックについて、メリットとデメリットをそれぞれ並列で推論させて、その結果を両方あわせて評価を推論させるフロー
from llama_index.core.workflow import (
Event,
StartEvent,
StopEvent,
Workflow,
step,
Context
)
from llama_index.llms.openai import OpenAI
class TopicEvent(Event):
pass
class AdvantageEvent(Event):
advantage: str
class DisadvantageEvent(Event):
disadvantage: str
class EvaluationFlow(Workflow):
llm = OpenAI(model="gpt-4o-mini")
@step(pass_context=True)
async def query(self, ctx: Context, ev: StartEvent) -> TopicEvent:
topic = ev.get("topic")
ctx.data["topic"] = topic
return TopicEvent()
@step(pass_context=True)
async def generate_advantage(self, ctx: Context, ev: TopicEvent) -> AdvantageEvent:
topic = ctx.data["topic"]
prompt = f"{topic}についてのメリットをリストアップして"
response = await self.llm.acomplete(prompt)
return AdvantageEvent(advantage=str(response))
@step(pass_context=True)
async def generate_disadvantage(self, ctx: Context, ev: TopicEvent) -> DisadvantageEvent:
topic = ctx.data["topic"]
prompt = f"{topic}についてのデメリットをリストアップして"
response = await self.llm.acomplete(prompt)
return DisadvantageEvent(disadvantage=str(response))
@step(pass_context=True)
async def evaluate(self, ctx: Context, ev: AdvantageEvent | DisadvantageEvent ) -> StopEvent:
data = ctx.collect_events(ev, [AdvantageEvent, DisadvantageEvent])
if data is None:
return None
topic = ctx.data["topic"]
advantage_event, disadvantage_event = data
advantage = advantage_event.advantage
disadvantage = disadvantage_event.disadvantage
prompt = f"""\
{topic}についてメリット・デメリットを比較してどちらのほうが有利か判断して。
メリット:
{advantage}
デメリット:
{disadvantage}
判定:
"""
response = await self.llm.acomplete(prompt)
return StopEvent(result=str(response))
w = EvaluationFlow(timeout=60, verbose=True)
result = await w.run(topic="円高")
print(str(result))
verboseを見ると、メリット生成・デメリット生成が同時に行われて、evaluateステップがメリット・デメリット揃うまでは実行されていないように見える。
Running step query
Step query produced event TopicEvent
Running step generate_advantage
Running step generate_disadvantage
Step generate_disadvantage produced event DisadvantageEvent
Running step evaluate
Step evaluate produced no event
Step generate_advantage produced event AdvantageEvent
Running step evaluate
Step evaluate produced event StopEvent
円高のメリットとデメリットを比較すると、どちらが有利かは状況や視点によって異なりますが、以下のように考えることができます。
メリットの要点
- 輸入コストの低下: 消費者にとっては安価な商品が手に入るため、生活コストが下がる。
- 海外旅行のコスト削減: 海外旅行がしやすくなるため、観光業や旅行業界にとってはプラス。
- 海外資産の価値向上: 海外投資を行っている企業や個人にとっては資産が増える。
- インフレ抑制: 物価上昇を抑えることで、経済の安定に寄与する。
- 企業の海外展開支援: 海外投資がしやすくなり、国際競争力が向上する可能性がある。
デメリットの要点
- 輸出企業の利益減少: 輸出依存度の高い日本経済にとっては大きな打撃。
- 雇用への影響: 輸出企業の利益減少が雇用に悪影響を及ぼす可能性がある。
- 国内産業の競争力低下: 国内産業が外国製品に圧迫されることで、経済全体に悪影響。
- 観光業への影響: 外国人観光客が減少することで、観光業が打撃を受ける。
- 金融市場への影響: 株式市場が不安定になる可能性がある。
判定
円高の影響は、特に日本の経済構造や産業の特性に依存します。輸出が経済の重要な部分を占める日本においては、円高は輸出企業にとって大きなデメリットとなり、雇用や国内産業に悪影響を及ぼす可能性が高いです。
一方で、消費者や海外資産を持つ企業にとってはメリットも多く、特に生活コストの低下や海外旅行のしやすさは大きな利点です。
結論
全体的に見ると、円高は輸出依存度の高い日本経済にとってはデメリットが大きいと考えられます。特に、雇用や国内産業への影響が深刻であるため、経済全体の健全性を考慮すると、円高の進行は必ずしも有利とは言えません。したがって、状況によっては円安の方が経済にとって有利である場合が多いと判断できます。
フローを見てみる。
from llama_index.core.workflow import (
draw_all_possible_flows,
draw_most_recent_execution,
)
draw_all_possible_flows(EvaluationFlow, filename="evaluate_flow_all.html")
draw_most_recent_execution(w, filename="evaluate_flow_recent.html")
ワークフローの図、想定通り
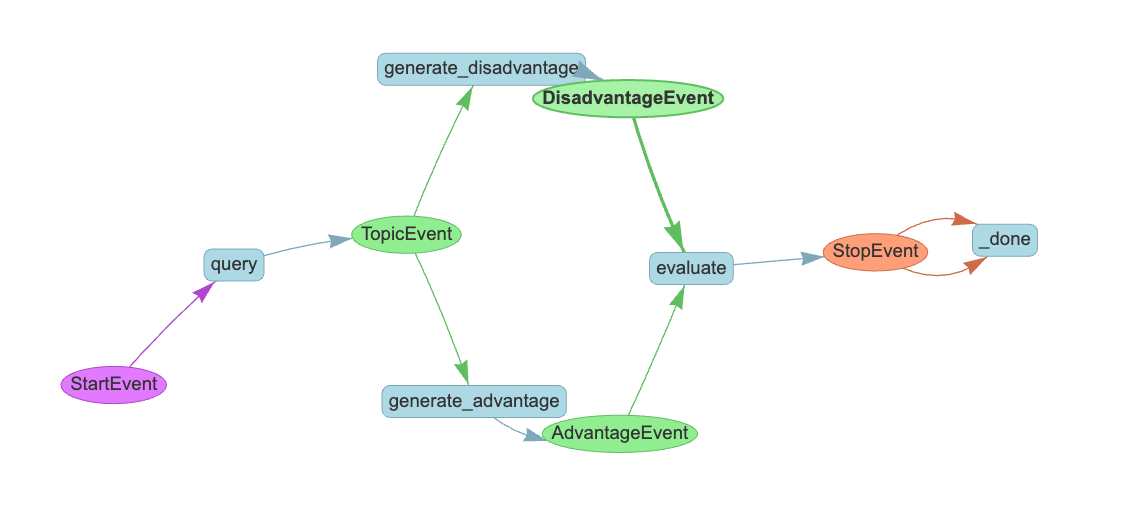
実行時の図はうまく表現されていない・・・

トレースを見てもちゃんとそれぞれの結果を渡して回答を生成しているようには見える。

これができるなら、本当にQuery Pipelineはもう使わなくていい気がする。もうちょっとコントロールしたいみたいなところができるかどうかを確認したい。
手動でイベントをトリガーできるようになってた。send_event(event)を使う。
from llama_index.core.workflow import step, Context, Event, Workflow
class MyEvent(Event):
pass
class MyEventResult(Event):
result: str
class GatherEvent(Event):
pass
class MyWorkflow(Workflow):
@step()
async def dispatch_step(self, ev: StartEvent) -> MyEvent | GatherEvent:
self.send_event(MyEvent())
self.send_event(MyEvent())
return GatherEvent()
@step()
async def handle_my_event(self, ev: MyEvent) -> MyEventResult:
return MyEventResult(result="result")
@step(pass_context=True)
async def gather(
self, ctx: Context, ev: GatherEvent | MyEventResult
) -> StopEvent | None:
# wait for events to finish
events = ctx.collect_events([MyEventResult, MyEventResult])
if not events:
return None
return StopEvent(result=events)
フローを可視化してみる。
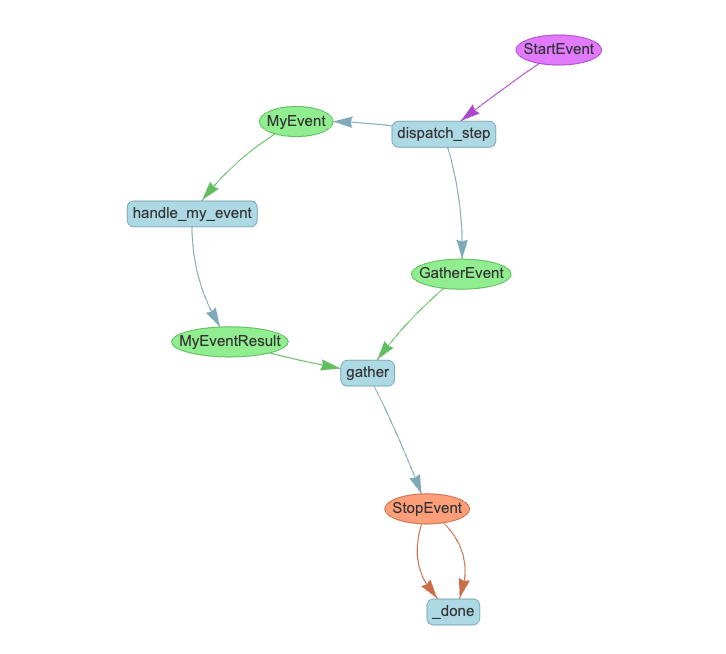
MyEventResultイベントは実際は2回起きてるはずなんだけどね、でもフロー的にはsend_eventから個別にイベントを発火して、GatherEventで集約されているのがわかる。
1つ前でやった複数イベントを受け取るサンプルでも書いてみた。前回実装したときに、ステップから複数イベントをreturnできるようには思えなかったので、複数のステップ側で同一のイベントを受け取るように設定していたけど、send_eventを使うとこんな感じになる(プロンプトは英語に変えている)
from llama_index.core.workflow import (
Event,
StartEvent,
StopEvent,
Workflow,
step,
Context
)
from llama_index.llms.openai import OpenAI
class AdvantageEvent(Event):
topic: str
class DisadvantageEvent(Event):
topic: str
class AdvantageResultEvent(Event):
result: str
class DisadvantageResultEvent(Event):
result: str
class GatherEvent(Event):
topic: str
class DecisionFlow(Workflow):
llm = OpenAI(model="gpt-4o-mini")
@step()
async def dispatch_step(self, ev: StartEvent) -> AdvantageEvent | DisadvantageEvent | GatherEvent:
topic = ev.get("topic")
self.send_event(AdvantageEvent(topic=topic))
self.send_event(DisadvantageEvent(topic=topic))
return GatherEvent(topic=topic)
@step()
async def generate_advantage(self, ev: AdvantageEvent) -> AdvantageResultEvent:
topic = ev.topic
prompt = f"List the benefits about {topic}."
response = await self.llm.acomplete(prompt)
return AdvantageResultEvent(result=str(response))
@step()
async def generate_disadvantage(self, ev: DisadvantageEvent) -> DisadvantageResultEvent:
topic = ev.topic
prompt = f"List the disadvantages about {topic}"
response = await self.llm.acomplete(prompt)
return DisadvantageResultEvent(result=str(response))
@step(pass_context=True)
async def evaluate(self, ctx: Context, ev: GatherEvent | AdvantageResultEvent | DisadvantageResultEvent) -> StopEvent | None:
events = ctx.collect_events(ev, [GatherEvent, AdvantageResultEvent, DisadvantageResultEvent])
if not events:
return None
gather_event, advantage_event, disadvantage_event = events
topic = gather_event.topic
advantages = advantage_event.result
disadvantages = disadvantage_event.result
prompt = f"""\
Based on the advantages and disadvantages about {topic}, decide which is better.
Advantages:
{advantages}
Disadvantages:
{disadvantages}
Decision:
"""
response = await self.llm.acomplete(prompt)
return StopEvent(result=str(response))
w = DecisionFlow(timeout=60, verbose=True)
result = await w.run(topic="investing in NVIDIA")
Running step dispatch_step
Step dispatch_step produced event GatherEvent
Running step evaluate
Step evaluate produced no event
Running step generate_advantage
Running step generate_disadvantage
Step generate_disadvantage produced event DisadvantageResultEvent
Running step evaluate
Step evaluate produced no event
Step generate_advantage produced event AdvantageResultEvent
Running step evaluate
Step evaluate produced event StopEvent
Based on the advantages and disadvantages of investing in NVIDIA, the decision ultimately depends on your investment goals, risk tolerance, and market outlook.
Summary of Considerations:
Advantages:
- NVIDIA is a leader in GPU technology with strong growth potential in gaming, AI, data centers, and automotive sectors.
- The company has a solid financial track record and a robust product pipeline, which can drive future growth.
- Positive industry trends align well with NVIDIA's core competencies, and the company has a history of returning value to shareholders.
Disadvantages:
- The stock is subject to high volatility and competitive pressures, which can impact its market position and pricing power.
- Dependence on cyclical markets and key customers poses risks, as does the potential for regulatory scrutiny and supply chain issues.
- High valuation and limited diversification could lead to significant losses if market conditions change.
Decision:
If you are an investor with a high risk tolerance and a long-term investment horizon, the advantages of investing in NVIDIA may outweigh the disadvantages. The company's leadership in high-growth sectors, strong financial performance, and innovative product pipeline present compelling reasons to consider it as a valuable addition to your portfolio.
However, if you are risk-averse or prefer more stable investments, the potential for market volatility, competition, and regulatory risks may lead you to reconsider or limit your investment in NVIDIA.
Conclusion:
In conclusion, if you believe in the long-term growth potential of AI, gaming, and data centers, and are willing to navigate the associated risks, investing in NVIDIA could be a strong choice. Conversely, if you prioritize stability and lower risk, you might want to explore other investment opportunities or maintain a cautious approach to NVIDIA. Always consider diversifying your investments to mitigate risks.
可視化

この例だとここまでやる必要はないと思うけど、一応こういうのが制御できるようになったのは良い。
Workflowsの情報色々増えてきた
WorkflowsでArize Phoenixを使ったトレーシング
Sub Question Query Engine as a workflowのnotebook
あといろいろnotebookのサンプル関連のPRあがってる
workflows cookbook
LongRAG, Corrective RAG, Self-Discover
Mixture Of Agents Packの中身がWorkflowに書き換わっている
もうちょっとしたらドキュメントに反映されると思う。
この辺の動きや、自分で試した限りの印象から、今後LlamaIndexを使っていく上でWorkflowsはかなりkiller featureになりそうな気がする。
Workflowsの全機能がリストアップされてるCookbook
同じステップが複数回同時に呼ばれる場合はどうやら並列でない場合があったらしく、@step(num_workers=n)で非同期並列実行されるようになったらしい。
最初触ったときに気になったこともいろいろ情報が揃ってきた感がある
- マルチエージェントと謳っているが、具体的にどう書けばいいのかがわからない。
以前公開されたmutli-agent-conciergeがworkflowsで書き直された
あとはhuman-in-the-loopだけかなー。Llama Agentsでは実装されてるみたいなんだけども。
と思ったらFeature Requestが挙がってた、楽しみ。
RAGに引用つけるworkflow
Human-in-the-loopが実装された!