LLMアプリのためのAIネイティブなデータベース「Infinity」を試す
GitHubレポジトリ
Infinity
AIネイティブのデータベースで、LLMアプリケーション向けに構築され、密ベクトル、疎ベクトル、テンソル、フルテキスト検索のハイブリッド検索を超高速で提供します。
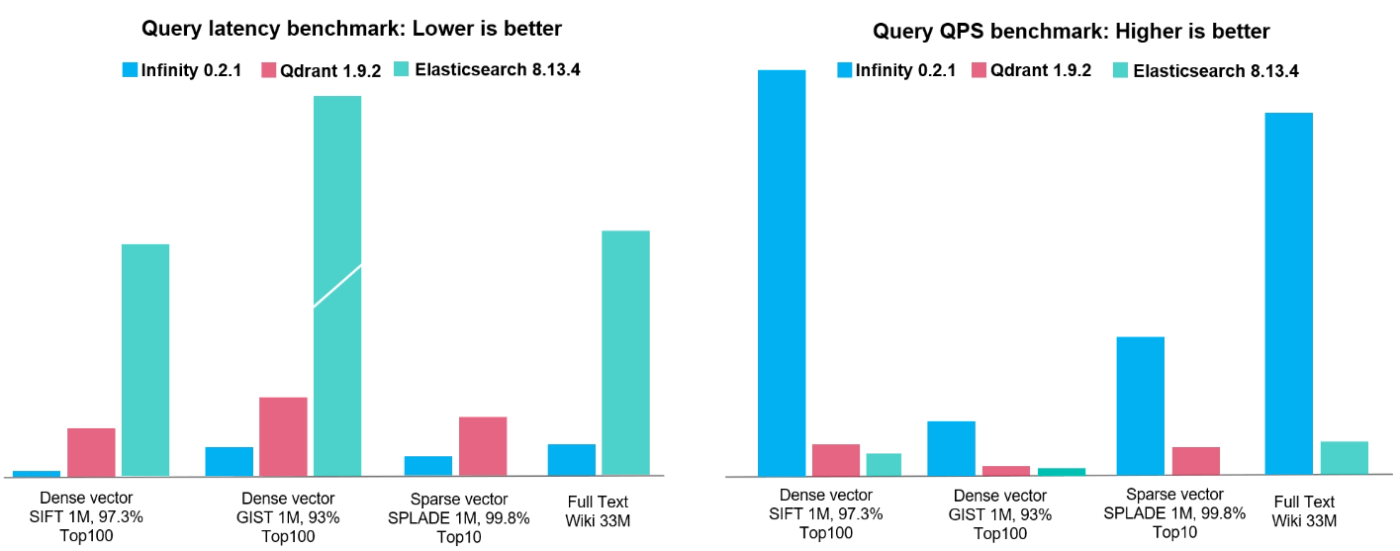
⚡️ パフォーマンス
referred from https://github.com/infiniflow/infinity?tab=readme-ov-file#️-performance🌟 主な特徴
Infinityは、高性能で柔軟、使いやすさに優れ、次世代AIアプリケーションが直面する課題に対応する多くの機能を備えています:
🚀 超高速
- 100万スケールのベクトルデータセットで、クエリ遅延0.1ミリ秒、QPS15,000以上を実現。
- 3,300万件のドキュメントで、フルテキスト検索において遅延1ミリ秒、QPS12,000以上を達成。
詳細はベンチマークレポートをご覧ください。
🔮 強力な検索機能
- 密ベクトル、疎ベクトル、テンソル、フルテキストのハイブリッド検索とフィルタリングをサポート。
- RRF、加重和、ColBERTを含むさまざまなリランカーをサポートします。
🍔 豊富なデータタイプ
- 文字列、数値、ベクトルなどの幅広いデータタイプをサポート。
🎁 使いやすさ
- 直感的なPython API。Python APIをご覧ください。
- 依存関係がない単一バイナリアーキテクチャで、簡単にデプロイ可能。
- Pythonのモジュールとして埋め込まれ、AI開発者にとって使いやすい設計です。
なお、開発者とInfiniFlowは「RAGFlow」というRAGプラットフォームも開発している。恐らくRAGFlowの裏ではInfinityが動いているのだろうと推測。
公式ドキュメントのQuickstartに従って進める
要件
- CPU: x86_64 with AVX2 support.
- OS:
- Linux with glibc 2.17+
- Windows 10+ with WSL/WSL2.
- Python: Python 3.10+
インストール
Infinityは2つの方式で利用できる。
- 組み込みモード
- クライアント・サーバモード
今回はColaboratoryで、組み込みモードを試してみる。
パッケージインストール。Embeddingの生成にはOpenAIを使おうと思うのであわせて。ランタイム再起動が必要になると思う。
!pip install infinity-embedded-sdk==0.5.0.dev1 openai
OpenAI APIキーをセット
from google.colab import userdata
import os
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
サンプルの文字列からEmbeddingsを生成
from openai import OpenAI
client = OpenAI()
def get_embedding(text: str)->list[float]:
response = client.embeddings.create(
model = "text-embedding-3-small",
input = [text]
)
return response.data[0].embedding
queries = [
"和食の特徴について教えて",
"気象観測にはどのようなデータが使用されますか?",
]
contexts = [
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用して行われます。",
]
queries_embeddings = [get_embedding(s) for s in queries]
contexts_embeddings = [get_embedding(s) for s in contexts]
ではInfinityのインスタンスを作成する。
import infinity_embedded
# データディレクトリを指定して、infinityに接続。データディレクトリはフルパスで指定すること。
infinity_object = infinity_embedded.connect("/content/infinity_data")
# default_dbという名前のデータベースを取得
db_object = infinity_object.get_database("default_db")
# my_tableという名前のテーブルを作成。カラムは以下
# - num(integer): 多分IDっぽいものを入れる
# - body(varchar): ベクトル化前の文字列を入れる
# - vec(float): 文字列をベクトル化したものを入れる。次元数も指定。
table_object = db_object.create_table(
"my_table",
{
"num": {"type": "integer"},
"body": {"type": "varchar"},
"vec": {"type": "vector, 1536, float"}
}
)
WARNING:root:Directory /content/infinity_data not found, try to create it
/content/infinity_dataにデータが作成される。中身はこんな感じ。
!tree /content/infinity_data
infinity_data/
├── data
│ └── catalog
│ └── FULL.8.json
├── log
│ └── infinity.log
├── tmp
└── wal
├── wal.log
└── wal.log.8
5 directories, 4 files
データを登録して検索してみる。
# テーブルにデータをINSERT
table_object.insert(
[
{"num": 1, "body": contexts[0], "vec": contexts_embeddings[0]},
{"num": 2, "body": contexts[1], "vec": contexts_embeddings[1]}
]
)
# クエリごとに検索
for qe in queries_embeddings:
res = table_object.output(["*"]).match_dense("vec", qe, "float", "ip", 2).to_pl()
print(res)
shape: (2, 3)
┌─────┬─────────────────────────────────┬─────────────────────────────────┐
│ num ┆ body ┆ vec │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ list[f64] │
╞═════╪═════════════════════════════════╪═════════════════════════════════╡
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ [-0.02593, -0.034317, … -0.023… │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
│ 2 ┆ 気象観測には、気温、湿度、気圧 ┆ [0.013447, 0.01278, … 0.021535… │
│ ┆ 、風向風速、雨や雪の分布、雲の… ┆ │
└─────┴─────────────────────────────────┴─────────────────────────────────┘
shape: (2, 3)
┌─────┬─────────────────────────────────┬─────────────────────────────────┐
│ num ┆ body ┆ vec │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ list[f64] │
╞═════╪═════════════════════════════════╪═════════════════════════════════╡
│ 2 ┆ 気象観測には、気温、湿度、気圧 ┆ [0.013447, 0.01278, … 0.021535… │
│ ┆ 、風向風速、雨や雪の分布、雲の… ┆ │
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ [-0.02593, -0.034317, … -0.023… │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
└─────┴─────────────────────────────────┴─────────────────────────────────┘
Pythonのサンプルコードが用意されている
Quickstartでやったこと以外をざざっとまとめ
テーブルの参照
res = table_object.output(["*"]).to_pl()
print(res)
shape: (2, 3)
┌─────┬─────────────────────────────────┬─────────────────────────────────┐
│ num ┆ body ┆ vec │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ list[f64] │
╞═════╪═════════════════════════════════╪═════════════════════════════════╡
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ [-0.02593, -0.034317, … -0.023… │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
│ 2 ┆ 気象観測には、気温、湿度、気圧 ┆ [0.013447, 0.01278, … 0.021535… │
│ ┆ 、風向風速、雨や雪の分布、雲の… ┆ │
└─────┴─────────────────────────────────┴─────────────────────────────────┘
カラムを限定
res = table_object.output(["num", "body"]).to_pl()
print(res)
shape: (2, 2)
┌─────┬─────────────────────────────────┐
│ num ┆ body │
│ --- ┆ --- │
│ i32 ┆ str │
╞═════╪═════════════════════════════════╡
│ 1 ┆ 日本の伝統的な和食は、「一汁三 │
│ ┆ 菜」を基本とし、主食、汁物、主… │
│ 2 ┆ 気象観測には、気温、湿度、気圧 │
│ ┆ 、風向風速、雨や雪の分布、雲の… │
└─────┴─────────────────────────────────┘
ファイルからのインポート
TSVファイルを生成して、ファイルからインポートしてみる
import pandas as pd
data = {
"index": [3, 4],
"context": [
"選挙は民主主義の基本であり、有権者は自らの意思を表明するために投票を行います。また、候補者は政策やビジョンを掲げて支持を得るためのキャンペーンを展開します。",
"サッカーは、チームスポーツの一つであり、攻撃と守備のバランスが重要です。選手たちは戦術に従い、パスやドリブルで相手ゴールを目指します。"
]
}
df = pd.DataFrame(data)
df["embedding"] = df["context"].apply(get_embedding)
df.to_csv('/content/import_data.tsv', sep='\t', index=False)
こういうTSVができる
index context embedding
3 選挙は民主主義の基本であり、有権者は自らの意思を表明するために投票を行います。また、候補者は政策やビジョンを掲げて支持を得るためのキャンペーンを展開します。 [0.029333697631955147, -0.01584487222135067, 0.030736535787582397, (snip), 0.023524509742856026, -0.05413515120744705, -0.050933804363012314]
4 サッカーは、チームスポーツの一つであり、攻撃と守備のバランスが重要です。選手たちは戦術に従い、パスやドリブルで相手ゴールを目指します。 [0.00018516274576541036, 0.00953442882746458, 0.043175410479307175, (snip), 0.018798377364873886, 0.010700874961912632, 0.006652123294770718]
table_object.import_data(
"/content/import_data.tsv",
{"header": True, "file_type": "csv", "delimiter": "\t"}
)
確認
res = table_object.output(["*"]).to_pl()
print(res)
shape: (4, 3)
┌─────┬─────────────────────────────────┬─────────────────────────────────┐
│ num ┆ body ┆ vec │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ list[f64] │
╞═════╪═════════════════════════════════╪═════════════════════════════════╡
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ [-0.02593, -0.034317, … -0.023… │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
│ 2 ┆ 気象観測には、気温、湿度、気圧 ┆ [0.013447, 0.01278, … 0.021535… │
│ ┆ 、風向風速、雨や雪の分布、雲の… ┆ │
│ 3 ┆ 選挙は民主主義の基本であり、有 ┆ [0.029334, -0.015845, … -0.050… │
│ ┆ 権者は自らの意思を表明するため… ┆ │
│ 4 ┆ サッカーは、チームスポーツの一 ┆ [0.000185, 0.009534, … 0.00665… │
│ ┆ つであり、攻撃と守備のバランス… ┆ │
└─────┴─────────────────────────────────┴─────────────────────────────────┘
データの削除
table_object.delete("num = 2")
res = table_object.output(["*"]).to_pl()
print(res)
shape: (3, 3)
┌─────┬─────────────────────────────────┬─────────────────────────────────┐
│ num ┆ body ┆ vec │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ list[f64] │
╞═════╪═════════════════════════════════╪═════════════════════════════════╡
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ [-0.02593, -0.034317, … -0.023… │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
│ 3 ┆ 選挙は民主主義の基本であり、有 ┆ [0.029334, -0.015845, … -0.050… │
│ ┆ 権者は自らの意思を表明するため… ┆ │
│ 4 ┆ サッカーは、チームスポーツの一 ┆ [0.000185, 0.009534, … 0.00665… │
│ ┆ つであり、攻撃と守備のバランス… ┆ │
└─────┴─────────────────────────────────┴─────────────────────────────────┘
データの更新
update_str = "バスケットボールは、チームスポーツの一つであり、攻撃と守備のバランスが重要です。選手たちは戦術に従い、パスやドリブルで相手ゴールを目指します。"
table_object.update(
"num = 4",
{
"body": update_str, "vec": get_embedding(update_str)
}
)
res = table_object.output(["*"]).to_pl()
print(res)
shape: (3, 3)
┌─────┬─────────────────────────────────┬─────────────────────────────────┐
│ num ┆ body ┆ vec │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ list[f64] │
╞═════╪═════════════════════════════════╪═════════════════════════════════╡
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ [-0.02593, -0.034317, … -0.023… │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
│ 4 ┆ バスケットボールは、チームスポ ┆ [0.014494, -0.003029, … 0.0162… │
│ ┆ ーツの一つであり、攻撃と守備の… ┆ │
│ 3 ┆ 選挙は民主主義の基本であり、有 ┆ [0.029334, -0.015845, … -0.050… │
│ ┆ 権者は自らの意思を表明するため… ┆ │
└─────┴─────────────────────────────────┴─────────────────────────────────┘
(密)ベクトル検索
Quickstartでも少し試しているけど、少し違う例
qe = get_embedding("バスケットボールはどんなスポーツですか?")
res = table_object.output(["num", "body", "_similarity"]).match_dense("vec", qe, "float", "cosine", 3).to_pl()
print(res)
shape: (3, 3)
┌─────┬─────────────────────────────────┬────────────┐
│ num ┆ body ┆ SIMILARITY │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ f32 │
╞═════╪═════════════════════════════════╪════════════╡
│ 4 ┆ バスケットボールは、チームスポ ┆ 0.654721 │
│ ┆ ーツの一つであり、攻撃と守備の… ┆ │
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ 0.109094 │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
│ 3 ┆ 選挙は民主主義の基本であり、有 ┆ 0.105264 │
│ ┆ 権者は自らの意思を表明するため… ┆ │
└─────┴─────────────────────────────────┴────────────┘
-
_similarityを出力に指定すると類似度スコアが出力される。 -
match_dense()メソッドで、類似度手法とtop-kが指定できる-
ip: 内積 -
l2: ユークリッド距離 -
cosine: コサイン類似度
-
全文検索
多分キーワード検索だと思う。日本語の場合トークナイザーがどうなるのかなと思うのだけど、どうやらMecabが組み込まれているっぽい。
で、その場合は以下のほうが参考になる
from infinity_embedded.index import IndexInfo, IndexType
from infinity_embedded.common import ConflictType
# 全文検索インデックスを作成
res = table_object.create_index(
"japanese_fulltext_index",
IndexInfo(
"body",
IndexType.FullText,
{"ANALYZER": "japanese"}
),
ConflictType.Error
)
なのだが・・・
InfinityException: (<ErrorCode.INVALID_ANALYZER_NAME: 3079>, 'Invalid analyzer file path: Failed to load JMA analyzer@src/storage/definition/index_full_text.cpp:63')
Issueを見てみるとこういうのがあった
Checkout https://github.com/infiniflow/resource.git under /var/infinity (defined by 'resource_dir' of config file). The jieba dict is
/var/infinity/resource/jieba/dict/jieba.dict.utf8
どうやら辞書をダウンロードしないといけないっぽい。ということでクローン。クローン先は一番最初にconnectで指定したディレクトリになる。
!git clone https://github.com/infiniflow/resource /content/infinity_data/resource
再度実行、今度はエラーなし。
from infinity_embedded.index import IndexInfo, IndexType
from infinity_embedded.common import ConflictType
# 全文検索インデックスを作成
res = table_object.create_index(
"japanese_fulltext_index",
IndexInfo(
"body",
IndexType.FullText,
{"ANALYZER": "japanese"}
),
ConflictType.Error
)
では検索
query = "バスケットボールの特徴は?"
result = (
table_object.output(["num", "body", "_score"]).highlight(["body"]).match_text("body", query, 3).to_pl()
print(result)
shape: (3, 3)
┌─────┬─────────────────────────────────┬──────────┐
│ num ┆ body ┆ SCORE │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ f32 │
╞═════╪═════════════════════════════════╪══════════╡
│ 4 ┆ <em>バスケットボール</em><em>は ┆ 1.680543 │
│ ┆ </em>、チー… ┆ │
│ 3 ┆ 選挙<em>は</em>民主主義<em>の</ ┆ 0.262001 │
│ ┆ em>基本であ… ┆ │
│ 1 ┆ 日本<em>の</em>伝統的な和食<em> ┆ 0.178222 │
│ ┆ は</em>、「… ┆ │
└─────┴─────────────────────────────────┴──────────┘
できてるっぽい。検索で合致した部分がハイライトされるみたい。
ハイブリッド
(密)ベクトルとキーワード検索を両方設定しておいて、ハイブリッドで検索。
query = "バスケットボールの特徴は?"
result = (
table_object.output(["num", "body", "_score"])
.match_dense("vec", get_embedding(query), "float", "cosine", 3)
.match_text("body", query, 3)
.fusion("rrf", 3)
.to_pl()
)
print(result)
shape: (3, 3)
┌─────┬─────────────────────────────────┬──────────┐
│ num ┆ body ┆ SCORE │
│ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ f32 │
╞═════╪═════════════════════════════════╪══════════╡
│ 4 ┆ バスケットボールは、チームスポ ┆ 0.032787 │
│ ┆ ーツの一つであり、攻撃と守備の… ┆ │
│ 3 ┆ 選挙は民主主義の基本であり、有 ┆ 0.032258 │
│ ┆ 権者は自らの意思を表明するため… ┆ │
│ 1 ┆ 日本の伝統的な和食は、「一汁三 ┆ 0.031746 │
│ ┆ 菜」を基本とし、主食、汁物、主… ┆ │
└─────┴─────────────────────────────────┴──────────┘
fusion()は、RRFの他にweighted_sumやmatch_tensorが使える。細かいパラメータの設定なんかもできるみたい。
なお、sparse vectorも扱えるようだが、明示的にsparseであることを記述する必要がある様子。
まとめ
C++で書かれているみたいだけども、Python SDKで使う分には意識する必要はなくて、とてもシンプルに扱える印象。
ドキュメントで丁寧に説明してくれてるわけではないが、以下にサンプルが多数用意されていて、これを見ながらリファレンスを見れば、概ねの操作はわかるのではないかと思う。
実際にどれだけ高速なのか?は確認していないけど、ベンチマークを見る限りは高速、ただしリソース的にはややメモリを食うのかなぁという印象。とはいえElasticSearchほどではない。検索速度が重要なケースで有用なのだろうと思うし、日本語も使えてハイブリッドもできるなら、悪くないのでは?と思う。
ところで、LangChainを見てみるとインテグレーションされてるのかなと思いきや、
Infinity違いだった。これはこれで気になるのだけど。
あと、出力はto_pl()でPolarsのデータフレーム形式になるけど、他にも
-
to_df(): pandasのデータフレームで出力 -
to_arrow(): Apache Arrowのテーブル形式で出力 -
to_result(): タプルで出力
がある。