Ovis2ベースで画像認識・生成・編集が可能なモデル「Ovis-U1-3B」を試す
GitHubレポジトリ
Ovis-U1: 統合的理解、生成、および編集
Ovisシリーズの基盤上に構築されたOvis-U1は、30億パラメータの統合モデルで、<b>マルチモーダル理解</b>、<b>テキストから画像生成</b>、および<b>画像編集</b>を一つの強力なフレームワーク内でシームレスに統合します。
referred from https://github.com/AIDC-AI/Ovis-U1/🏆 ハイライト
- 統合された機能: 単一モデルで3つの主要タスク(複雑なシーンの理解、テキストからの画像生成、指示に基づく精密な編集)を高い精度で実行。
- 先進的アーキテクチャ: 強力な拡散ベースのビジュアルデコーダ(MMDiT)と双方向トークンリファイナーを備え、高忠実度の画像合成とテキスト・ビジョン間の高度な相互作用を実現。
- 相乗的統一トレーニング: 単一タスク訓練モデルとは異なり、理解、生成、編集の多様なデータを同時に用いて学習。実世界のマルチモーダル課題に対して優れた汎化性能を示します。
- 最先端の性能: マルチモーダル理解(OpenCompass:69.6)、生成(DPG-Bench:83.72)、編集(ImgEdit-Bench:4.00)など、複数の学術ベンチマークで強力な contemporaries を上回る成果を達成。
✨ ショーケース
以下はOvis-U1の機能を示す例です。
referred from https://github.com/AIDC-AI/Ovis-U1/ and translated into Japanese by kun432

🚀 ニュース
📄 ライセンス
本プロジェクトは Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0, SPDX-License-Identifier: Apache-2.0) の下で公開されています。
🚨 免責事項
トレーニング過程でコンプライアンスチェックアルゴリズムを使用し、モデルの適切性を最大限確保しています。しかし、データの複雑性や使用シナリオの多様性により、著作権問題や不適切な内容が完全に排除されることを保証できません。権利侵害や不適切な内容がある場合はご連絡ください。迅速に対処いたします。
モデルはこちら
デモはこちら
以前試したOvis2(2B)がベースになっている様子。Ovis2はモデルサイズのバリエーションが豊富で、モデルサイズが小さくても日本語文字の認識精度が非常に高かったモデルとして記憶している。それがベースになっているということで、これは期待したい。
ベンチマークについても記載がある。原文では各ベンチマーク内の比較において、
- 1位: 太文字
- 2位: 下線
となっている様子。ただ、ZennのMarkdownは下線が引けないのでイタリックにしてある(わかりにくい・・・)
GPT-4oとあるのは、画像生成・編集に関して言うならばgpt-image-1ってことかな?さすがにOpenAI強い感じだけども、Ovis-U1もオープンモデルとしてはかなり頑張ってるのではなかろうか。
📊 パフォーマンス
OpenCompass マルチモーダル学術ベンチマーク
モデル 平均 MMB MMS MMMU MathVista Hallusion AI2D OCRBench MMVet GPT-4o 75.4 86 70.2 72.9 71.6 57 86.3 82.2 76.9 InternVL2.5-2B 59.9 70.9 54.3 43.2 51.1 42.3 74.9 80.2 62.6 SAIL-VL-2B 61 73.7 56.5 44.1 62.8 45.9 77.4 83.1 44.2 InternVL3-2B 61.1 78 61.1 48.7 57.6 41.9 78.6 83.1 67 Qwen2.5-VL-3B 64.5 76.8 56.3 51.2 61.2 46.6 81.4 82.8 60 Ovis2-2B 65.2 76.9 56.7 45.6 64.1 50.2 82.7 87.3 58.3 SAIL-VL-1.5-2B 67 78.5 62.6 46.4 67 50 83.7 89.1 58.8 Ristretto-3B 67.7 80.2 62.8 51.3 67.6 50.2 84.2 84.7 60.7 Ovis-U1 69.6 77.8 61.3 51.1 69.4 56.3 85.6 88.3 66.7 GenEval
モデル 全体 単一オブジェクト 二つのオブジェクト カウント 色 位置 属性バインディング GPT-4o 0.84 0.99 0.92 0.85 0.92 0.75 0.61 BAGEL 0.82 0.99 0.94 0.81 0.88 0.64 0.63 BAGEL 📝 0.88 0.98 0.95 0.84 0.95 0.78 0.77 UniWorld-V1 0.80 0.99 0.93 0.79 0.89 0.49 0.70 UniWorld-V1 📝 0.84 0.98 0.93 0.81 0.89 0.74 0.71 OmniGen 0.68 0.98 0.84 0.66 0.74 0.40 0.43 OmniGen2 0.80 1 0.95 0.64 0.88 0.55 0.76 OmniGen2 📝 0.86 0.99 0.96 0.74 0.98 0.71 0.75 Ovis-U1 0.89 0.98 0.98 0.90 0.92 0.79 0.75 DPG-Bench
モデル 全体 グローバル エンティティ 属性 関係 その他 BAGEL 85.07 88.94 90.37 91.29 90.82 88.67 UniWorld-V1 81.38 83.64 88.39 88.44 89.27 87.22 OmniGen 81.16 87.90 88.97 88.47 87.95 83.56 OmniGen2 83.57 88.81 88.83 90.18 89.37 90.27 Ovis-U1 83.72 82.37 90.08 88.68 93.35 85.20 ImgEdit-Bench
モデル 全体 追加 調整 抽出 置換 削除 背景 スタイル ハイブリッド アクション GPT-4o 4.2 4.61 4.33 2.9 4.35 3.66 4.57 4.93 3.96 4.89 MagicBrush 1.90 2.84 1.58 1.51 1.97 1.58 1.75 2.38 1.62 1.22 Instruct-P2P 1.88 2.45 1.83 1.44 2.01 1.50 1.44 3.55 1.20 1.46 AnyEdit 2.45 3.18 2.95 1.88 2.47 2.23 2.24 2.85 1.56 2.65 UltraEdit 2.7 3.44 2.81 2.13 2.96 1.45 2.83 3.76 1.91 2.98 OmniGen 2.96 3.47 3.04 1.71 2.94 2.43 3.21 4.19 2.24 3.38 Step1X-Edit 3.06 3.88 3.14 1.76 3.40 2.41 3.16 4.63 2.64 2.52 ICEdit 3.05 3.58 3.39 1.73 3.15 2.93 3.08 3.84 2.04 3.68 BAGEL 3.2 3.56 3.31 1.70 3.30 2.62 3.24 4.49 2.38 4.17 UniWorld-V1 3.26 3.82 3.64 2.27 3.47 3.24 2.99 4.21 2.96 2.74 OmniGen2 3.44 3.57 3.06 1.77 3.74 3.20 3.57 4.81 2.52 4.68 Ovis-U1 4.00 4.13 3.62 2.98 4.45 4.06 4.22 4.69 3.45 4.61 GEdit-Bench-EN
モデル 平均 背景変更 色変更 素材変更 動作変更 美化(ポートレート) スタイル転送 被写体追加 被写体削除 被写体置換 テキスト変更 トーン変換 GPT-4o 7.534 7.205 6.491 6.607 8.096 7.768 6.961 7.622 8.331 8.067 7.427 8.301 AnyEdit 3.212 4.663 4.260 2.537 2.024 3.479 2.032 3.995 3.089 3.180 0.922 5.151 Instruct-Pix2Pix 3.684 3.825 5.182 3.688 3.509 4.339 4.560 3.461 2.031 4.237 0.955 4.733 MagicBrush 4.518 5.637 5.136 5.078 4.513 4.487 4.439 5.252 3.704 4.941 1.384 5.130 OmniGen 5.062 5.281 6.003 5.308 2.916 3.087 4.903 6.628 6.352 5.616 4.519 5.064 Gemini 6.315 6.781 6.369 6.040 6.938 5.591 4.676 7.501 6.447 7.003 5.765 6.350 Step1X-Edit 6.701 6.547 6.545 6.204 6.483 6.787 7.221 6.975 6.512 7.068 6.921 6.448 Doubao 6.754 7.430 7.095 6.339 6.973 6.972 6.767 7.674 6.748 7.447 3.471 7.383 BAGEL 6.519 7.324 6.909 6.381 4.753 4.573 6.150 7.896 7.164 7.021 7.320 6.218 Ovis-U1 6.420 7.486 6.879 6.208 4.790 5.981 6.463 7.491 7.254 7.266 4.482 6.314
Colaboratory L4で試す。
パッケージインストール。flash-attnが必要な様子だが、最新版(2.8.0-post2)だとうまくいかなかったので、Ovis2を試した時のバージョンに合わせた。
!pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124
!pip install flash-attn==2.7.0.post2 --no-build-isolation
モデルカードやGitHubのREADMEを見ると、どうやらコマンドラインからPythonスクリプトを実行するようになっていて、機能ごとにスクリプトも別々になっている様子。Colaboratoryではちょっと試すにあたって面倒なので、o3でクラス化してもらった。各機能はそれぞれメソッド化されている。
クラス化したOvisU1Pipeline
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
import random
class OvisU1Pipeline:
def __init__(self, model_path="AIDC-AI/Ovis-U1-3B", device="cuda"):
self.model, loading_info = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
output_loading_info=True,
trust_remote_code=True
)
print(f'Loading info of Ovis-U1:\n{loading_info}')
self.model = self.model.eval().to(device)
self.model = self.model.to(torch.bfloat16)
self.device = device
self.text_tokenizer = self.model.get_text_tokenizer()
self.visual_tokenizer = self.model.get_visual_tokenizer()
def _build_inputs(self, prompt, pil_image, multimodal_type="single_image"):
if multimodal_type == "multiple_image":
images = pil_image
else:
images = [pil_image]
result = self.model.preprocess_inputs(
prompt,
images,
generation_preface='',
return_labels=False,
propagate_exception=False,
multimodal_type=multimodal_type,
fix_sample_overall_length_navit=False
)
if len(result) == 5:
prompt, input_ids, pixel_values, grid_thws, vae_pixel_values = result
else:
prompt, input_ids, pixel_values, grid_thws = result
vae_pixel_values = None
attention_mask = torch.ne(input_ids, self.text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=self.model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=self.model.device)
if pixel_values is not None:
pixel_values = torch.cat([
pixel_values.to(device=self.visual_tokenizer.device, dtype=torch.bfloat16) if pixel_values is not None else None
], dim=0)
if grid_thws is not None:
grid_thws = torch.cat([
grid_thws.to(device=self.visual_tokenizer.device) if grid_thws is not None else None
], dim=0)
return input_ids, pixel_values, attention_mask, grid_thws, vae_pixel_values
def image_to_text(self, pil_image, prompt="What is it?"):
gen_kwargs = dict(
max_new_tokens=4096,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=self.text_tokenizer.eos_token_id,
pad_token_id=self.text_tokenizer.pad_token_id,
use_cache=True,
)
prompt = "<image>\n" + prompt
input_ids, pixel_values, attention_mask, grid_thws, _ = self._build_inputs(prompt, pil_image, multimodal_type="single_image")
with torch.inference_mode():
output_ids = self.model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, grid_thws=grid_thws, **gen_kwargs)[0]
gen_text = self.text_tokenizer.decode(output_ids, skip_special_tokens=True)
return gen_text
def multi_image_to_text(self, pil_images, prompt="Describe each image."):
gen_kwargs = dict(
max_new_tokens=4096,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=self.text_tokenizer.eos_token_id,
pad_token_id=self.text_tokenizer.pad_token_id,
use_cache=True,
)
prompt = '\n'.join([f'Image {i+1}: <image>' for i in range(len(pil_images))]) + '\n' + prompt
input_ids, pixel_values, attention_mask, grid_thws, _ = self._build_inputs(prompt, pil_images, multimodal_type="multiple_image")
with torch.inference_mode():
output_ids = self.model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, grid_thws=grid_thws, **gen_kwargs)[0]
gen_text = self.text_tokenizer.decode(output_ids, skip_special_tokens=True)
return gen_text
def text_to_image(self, prompt, height=1024, width=1024, steps=50, txt_cfg=5, seed=None):
# ---- オリジナル test_txt_to_img.py の処理に準拠 ----
def load_blank_image(w, h):
return Image.new("RGB", (w, h), (255, 255, 255)).convert('RGB')
if seed is None:
seed = random.randint(0, 2**32 - 1)
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=self.text_tokenizer.eos_token_id,
pad_token_id=self.text_tokenizer.pad_token_id,
use_cache=True,
height=height,
width=width,
num_steps=steps,
seed=seed,
img_cfg=0,
txt_cfg=txt_cfg,
)
# 1) 無条件(no_both_cond)
uncond_image = load_blank_image(width, height)
uncond_prompt = "<image>\nGenerate an image."
# process_image_aspectratio で VAE 入力を取得
pil_img_proc, vae_pixel_values, cond_img_ids = self.model.visual_generator.process_image_aspectratio(
uncond_image, (width, height)
)
cond_img_ids[..., 0] = 1.0
vae_pixel_values = vae_pixel_values.unsqueeze(0).to(device=self.model.device)
# preprocess_inputs
res = self.model.preprocess_inputs(
uncond_prompt,
[pil_img_proc],
generation_preface=None,
return_labels=False,
propagate_exception=False,
multimodal_type='single_image',
fix_sample_overall_length_navit=False
)
if len(res) == 5:
_, input_ids, pixel_values, grid_thws, _ = res
else:
_, input_ids, pixel_values, grid_thws = res
attention_mask = torch.ne(input_ids, self.text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=self.model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=self.model.device)
if pixel_values is not None:
pixel_values = torch.cat([
pixel_values.to(device=self.visual_tokenizer.device, dtype=torch.bfloat16)
], dim=0)
if grid_thws is not None:
grid_thws = torch.cat([
grid_thws.to(device=self.visual_tokenizer.device)
], dim=0)
with torch.inference_mode():
no_both_cond = self.model.generate_condition(
input_ids,
pixel_values=pixel_values,
attention_mask=attention_mask,
grid_thws=grid_thws,
**gen_kwargs
)
# 2) 条件付き(cond)
prompt_full = "<image>\nDescribe the image by detailing the color, shape, size, texture, quantity, text, and spatial relationships of the objects:" + prompt
# process_image_aspectratio は再利用
pil_img_proc2, vae_pixel_values2, cond_img_ids2 = self.model.visual_generator.process_image_aspectratio(
uncond_image, (width, height)
)
cond_img_ids2[..., 0] = 1.0
vae_pixel_values2 = vae_pixel_values2.unsqueeze(0).to(device=self.model.device)
res2 = self.model.preprocess_inputs(
prompt_full,
[pil_img_proc2],
generation_preface=None,
return_labels=False,
propagate_exception=False,
multimodal_type='single_image',
fix_sample_overall_length_navit=False
)
if len(res2) == 5:
_, input_ids2, pixel_values2, grid_thws2, _ = res2
else:
_, input_ids2, pixel_values2, grid_thws2 = res2
attention_mask2 = torch.ne(input_ids2, self.text_tokenizer.pad_token_id)
input_ids2 = input_ids2.unsqueeze(0).to(device=self.model.device)
attention_mask2 = attention_mask2.unsqueeze(0).to(device=self.model.device)
if pixel_values2 is not None:
pixel_values2 = torch.cat([
pixel_values2.to(device=self.visual_tokenizer.device, dtype=torch.bfloat16)
], dim=0)
if grid_thws2 is not None:
grid_thws2 = torch.cat([
grid_thws2.to(device=self.visual_tokenizer.device)
], dim=0)
with torch.inference_mode():
cond = self.model.generate_condition(
input_ids2,
pixel_values=pixel_values2,
attention_mask=attention_mask2,
grid_thws=grid_thws2,
**gen_kwargs
)
cond["vae_pixel_values"] = vae_pixel_values2
# no_txt_cond は使用しない
images = self.model.generate_img(
cond=cond,
no_both_cond=no_both_cond,
no_txt_cond=None,
**gen_kwargs
)
return images
def edit_image(self, pil_image, prompt, steps=50, txt_cfg=6, img_cfg=1.5, seed=None):
# ---- オリジナル test_img_edit.py 準拠 ----
width_orig, height_orig = pil_image.size
height_proc, width_proc = self.visual_tokenizer.smart_resize(height_orig, width_orig, factor=32)
def load_blank_image(w, h):
return Image.new("RGB", (w, h), (255, 255, 255)).convert('RGB')
if seed is None:
seed = random.randint(0, 2**32 - 1)
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=self.text_tokenizer.eos_token_id,
pad_token_id=self.text_tokenizer.pad_token_id,
use_cache=True,
height=height_proc,
width=width_proc,
num_steps=steps,
seed=seed,
img_cfg=img_cfg,
txt_cfg=txt_cfg,
)
def build_inputs_for_edit(pil_img, prmpt):
# pil_img: PIL.Image or None
if pil_img is not None:
target_size = (int(width_proc), int(height_proc))
pil_img, vae_pixel_values, cond_img_ids = self.model.visual_generator.process_image_aspectratio(
pil_img, target_size
)
cond_img_ids[..., 0] = 1.0
vae_pixel_values = vae_pixel_values.unsqueeze(0).to(device=self.model.device)
w2, h2 = pil_img.width, pil_img.height
resized_h, resized_w = self.visual_tokenizer.smart_resize(h2, w2, max_pixels=self.visual_tokenizer.image_processor.min_pixels)
pil_img = pil_img.resize((resized_w, resized_h))
else:
vae_pixel_values = None
res = self.model.preprocess_inputs(
prmpt,
[pil_img],
generation_preface=None,
return_labels=False,
propagate_exception=False,
multimodal_type='single_image',
fix_sample_overall_length_navit=False
)
if len(res) == 5:
prmpt_ret, input_ids, pixel_values, grid_thws, _ = res
else:
prmpt_ret, input_ids, pixel_values, grid_thws = res
attention_mask = torch.ne(input_ids, self.text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=self.model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=self.model.device)
if pixel_values is not None:
pixel_values = torch.cat([
pixel_values.to(device=self.visual_tokenizer.device, dtype=torch.bfloat16)
], dim=0)
if grid_thws is not None:
grid_thws = torch.cat([
grid_thws.to(device=self.visual_tokenizer.device)
], dim=0)
return input_ids, pixel_values, attention_mask, grid_thws, vae_pixel_values
# 1) no_both_cond(無条件)
uncond_image = load_blank_image(width_proc, height_proc)
uncond_prompt = "<image>\nGenerate an image."
input_ids_nb, pixel_values_nb, attention_mask_nb, grid_thws_nb, _ = build_inputs_for_edit(uncond_image, uncond_prompt)
with torch.inference_mode():
no_both_cond = self.model.generate_condition(
input_ids_nb,
pixel_values=pixel_values_nb,
attention_mask=attention_mask_nb,
grid_thws=grid_thws_nb,
**gen_kwargs
)
# 2) no_txt_cond(画像のみ条件)
pil_resized = pil_image.resize((width_proc, height_proc))
input_ids_nt, pixel_values_nt, attention_mask_nt, grid_thws_nt, _ = build_inputs_for_edit(pil_resized, uncond_prompt)
with torch.inference_mode():
no_txt_cond = self.model.generate_condition(
input_ids_nt,
pixel_values=pixel_values_nt,
attention_mask=attention_mask_nt,
grid_thws=grid_thws_nt,
**gen_kwargs
)
# 3) cond(画像+テキスト条件)
prompt_full = "<image>\n" + prompt.strip()
input_ids_c, pixel_values_c, attention_mask_c, grid_thws_c, vae_pixel_values_c = build_inputs_for_edit(pil_resized, prompt_full)
with torch.inference_mode():
cond = self.model.generate_condition(
input_ids_c,
pixel_values=pixel_values_c,
attention_mask=attention_mask_c,
grid_thws=grid_thws_c,
**gen_kwargs
)
cond["vae_pixel_values"] = vae_pixel_values_c
images = self.model.generate_img(
cond=cond,
no_both_cond=no_both_cond,
no_txt_cond=no_txt_cond,
**gen_kwargs
)
return images
ではパイプラインを初期化。ここでモデル等がロードされる。
ovis_pipeline = OvisU1Pipeline()
VRAM消費は9.6GB程度。
Sat Jul 5 13:27:38 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 45C P0 28W / 72W | 9681MiB / 23034MiB | 34% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
では以降で各機能を見ていく。
画像→テキスト
画像を解析してテキストを出力する。
Ovis2のレポジトリにあるサンプル画像を使用させてもらう。
!wget https://raw.githubusercontent.com/AIDC-AI/Ovis-U1/refs/heads/main/docs/imgs/cat.png
!wget https://raw.githubusercontent.com/AIDC-AI/Ovis-U1/refs/heads/main/docs/imgs/yak.png
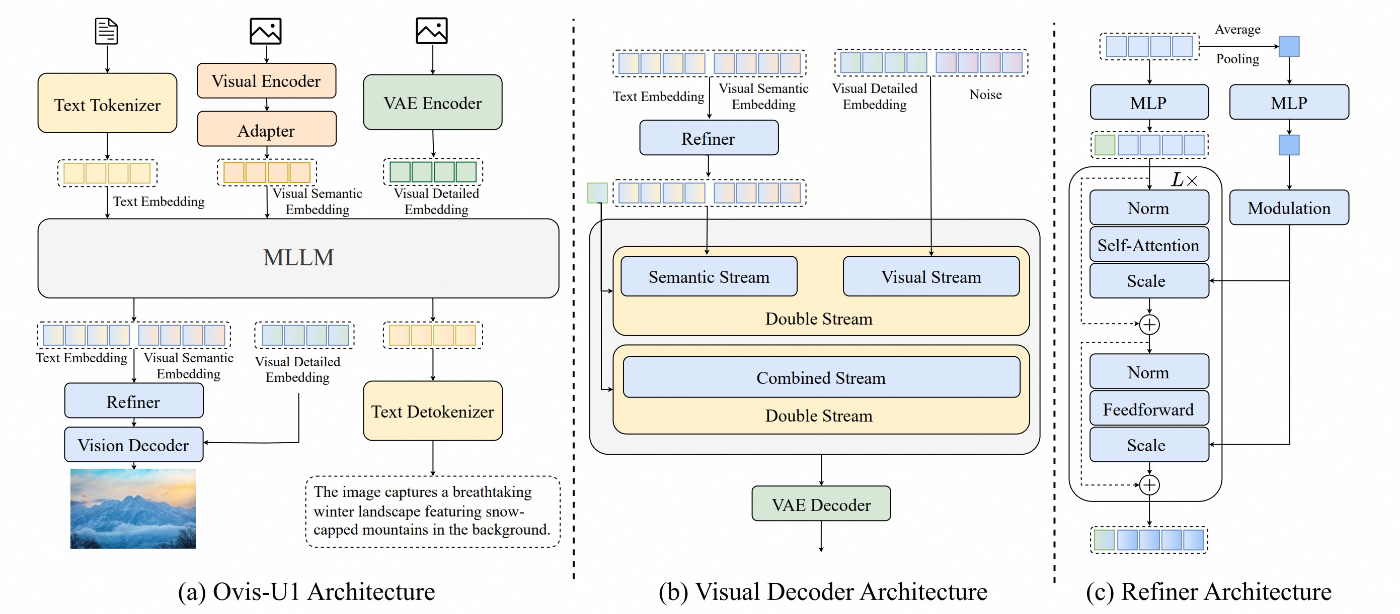
それぞれの画像を見てみる。
from IPython.display import Image as IPY_Image # PIL.Imageと重複するので別名で
display(IPY_Image("cat.png", width=500))
display(IPY_Image("yak.png", width=500))
ファイル名から分かる通り、ネコとヤクの画像になっている。
ではまずネコの画像を説明させてみる。
pil_img = Image.open("cat.png").convert('RGB')
txt = ovis_pipeline.image_to_text(
pil_img,
prompt="この画像について説明して。"
)
print(txt)
結果
この画像は、黒と白の毛並みの猫を捉えたもので、猫の特徴的な特徴である、黒い顔と白い体が際立っています。猫の目は緑色で、これは猫の毛色とよく合っています。猫は竹製の家具の上に座っており、これは猫の自然な好奇心と探検心を示唆している可能性があります。背景の鮮やかな緑色は、猫の毛色と対照的で、画像に視覚的な面白さを加えています。猫の穏やかな表情と、カメラに直接視線を向ける姿勢は、写真家が猫の穏やかな性格と、カメラに注意を払うという、猫の好奇心を捉えようとしたことを示唆しています。この画像は、猫の毛色、表情、そして周囲の環境の美しさを強調することで、猫の魅力を引き立てています。
複数の画像を入力させることもできる。
pil_img2 = Image.open("yak.png").convert('RGB')
txt_multi = ovis_pipeline.multi_image_to_text(
[pil_img, pil_img2],
prompt="それぞれの画像について説明して。"
)
print(txt_multi)
結果
画像1:緑色の背景の前に、黒と白の毛並みの猫が竹製の柵に寄りかかり、こちらを見つめています。猫は白い顔と体をしていますが、頭の上部と耳の部分は黒い毛で覆われています。猫の目は緑色で、鋭い視線をしています。猫の前足は柵に添えられており、リラックスした姿勢でカメラを見つめています。
画像2:淡い茶色の毛並みの高地牛が、青い空の下に立っています。牛の大きな角は両側に伸びており、鼻はピンク色で、目は穏やかに見つめています。背景はぼやけており、牛の存在感が際立っています。
テキスト→画像
テキストから画像を生成する
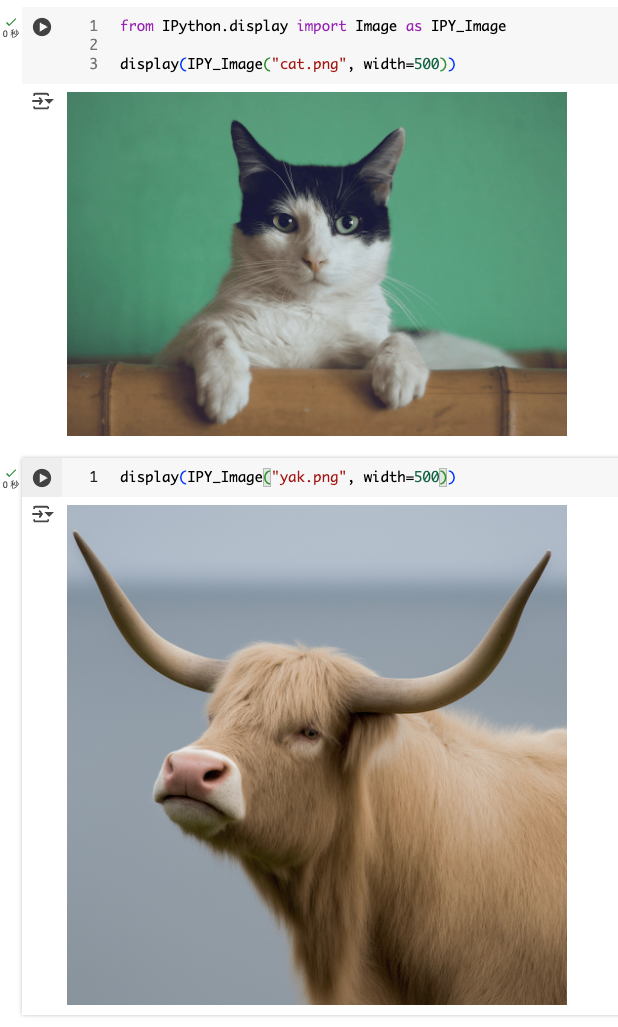
gen_imgs = ovis_pipeline.text_to_image(
"可愛いネコを水彩画タッチで。", height=512, width=512
)
gen_imgs[0].save("sample_t2i.png")
display(IPY_Image("sample_t2i.png"))
画像編集
既存の画像に対して編集を行う。最初に使ったネコとヤクの画像を使ってみる。
pil_img = Image.open("cat.png").convert('RGB')
edit_imgs = ovis_pipeline.edit_image(
pil_img,
"このネコに帽子を被らせて",
)
edit_imgs[0].save("sample_img_edit.png")
display(IPY_Image("sample_img_edit.png", width=500))

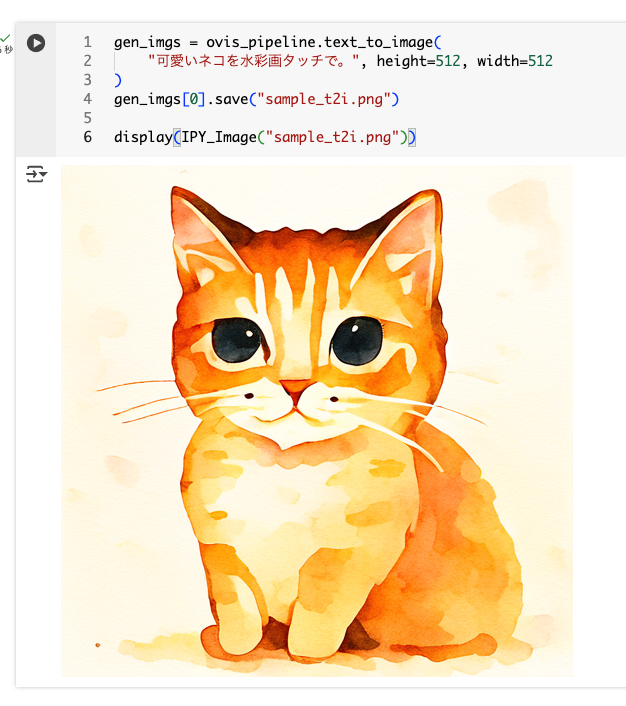
pil_img = Image.open("yak.png").convert('RGB')
edit_imgs = ovis_pipeline.edit_image(
pil_img,
"このヤクの顔を笑顔にして",
)
edit_imgs[0].save("sample_img_edit.png")
display(IPY_Image("sample_img_edit.png", width=500))
一応Ovis2と同じようなことも確認しておく。
神戸の風景

pil_img = Image.open("kobe.jpg").convert('RGB')
txt = ovis_pipeline.image_to_text(
pil_img,
prompt="この画像について説明して。"
)
print(txt)
この画像は、日本の神戸市にあるポートタワーや、その周辺の景観を捉えています。ポートタワーは、神戸のシンボル的な建造物であり、赤い鉄骨構造が特徴的です。この塔は、1994年に開業し、神戸の海を背景に、観光客に人気の観光スポットとなっています。
画像の中央には、赤いポートタワーがそびえ立ち、その背後には高層ビル群が立ち並んでいます。これらのビルは、神戸の近代的な都市景観を象徴しています。また、画像の右側には、白い帆のようなデザインの建物が見えます。これは、神戸ポートタワーパークの一部であり、そのユニークなデザインが特徴です。
画像の左側には、海に浮かぶ船や、埠頭の構造物が見えます。これらの要素は、神戸の港町としての側面を強調しています。背景には、緑豊かな山々が見え、自然と都市が調和した景観が広がっています。
この画像は、神戸の都市景観と、ポートタワーの象徴的な存在を美しく捉えており、神戸の魅力を伝える一枚となっています。
書籍の画像

pil_img = Image.open("book.png").convert('RGB')
txt = ovis_pipeline.image_to_text(
pil_img,
prompt="この画像について説明して。"
)
print(txt)
この画像は、白い背景に置かれた「ドキュメントコミュニケーションの全体観」というタイトルの本の表紙です。表紙は白地に緑色の帯が横に走っており、上部には「ドキュメント、コミュニケーションの全体観」というタイトルが大きく書かれています。その下に「連携、報告書、会議資料の実践と作成スピードを上げるカギを握る」というサブタイトルが書かれています。さらにその下に「上巻 原則と手順 中川邦太著」という著者名が書かれています。
表紙の中央には、コミュニケーションのプロセスを示す図が描かれています。図は「文書の作成・管理」「技術」「手順」の3つの要素で構成されており、それぞれの要素がどのように関連しているかが示されています。
下部には「コミュニケーションはすべて解・動・早で進めよ」というキャッチコピーが書かれています。その下に「解っていたか、動いていたか、ただ遅れるだけ早く」という説明文が書かれています。
この本は、ドキュメントコミュニケーションの理論と実践について解説した書籍であり、特に連携、報告書、会議資料の作成スピードを上げるための方法を紹介しています。著者は中川邦太氏で、この本は上巻と下巻で構成されています。
架空の請求書の画像

pil_img = Image.open("invoice.png").convert('RGB')
txt = ovis_pipeline.image_to_text(
pil_img,
prompt="この画像について説明して。"
)
print(txt)
この画像は、請求書の表紙です。請求書番号はINV-2024-0820で、請求対象は「模範商事株式会社」です。住所は〒100-0001 東京都千代田区見本町1-1で、電話番号は03-1234-5678、FAX番号は03-1234-5679です。
請求対象は「範例工業株式会社 御中」で、下記の通りご請求申し上げます。
項目 数量 単価 金額 特選和紙 (A4サイズ) 1000 ¥50 ¥50,000 高級墨 (松煙) 20 ¥2,000 ¥40,000 筆セット (各種) 50 ¥1,000 ¥50,000 小計は¥140,000で、消費税10%は¥14,000で、合計金額は¥154,000です。
備考として、お支払いは請求書発行日より30日以内にお願いいたします。振込手数料は貴社負担でお願いいたします。本書に関するお問い合わせは下記担当者までご連絡ください。
担当:営業部 見本 太郎
この請求書は、範例工業株式会社が模範商事株式会社に請求するもので、請求対象の商品は和紙、墨、筆セットの3種類です。請求金額は合計¥154,000で、消費税10%が加算されています。
相変わらず素晴らしいね。
画像生成で日本語の文字を生成するのはできなかった。
gen_imgs = ovis_pipeline.text_to_image(
"日本のラーメン屋さんの画像を生成して。店の名前は「ラーメン一直線」。", height=512, width=512
)
gen_imgs[0].save("sample_t2i.png")
display(IPY_Image("sample_t2i.png"))

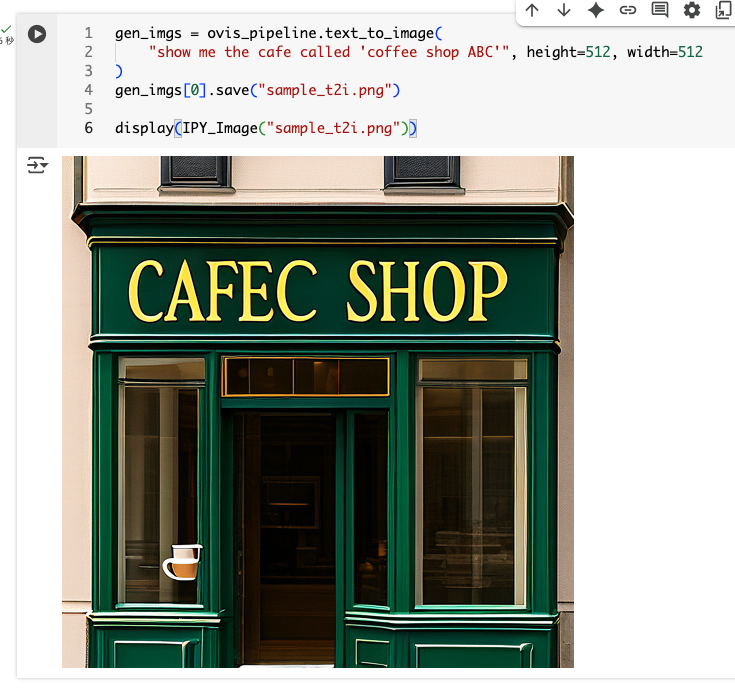
英数字だとある程度はできそう
gen_imgs = ovis_pipeline.text_to_image(
"show me the cafe called 'coffee shop ABC'", height=512, width=512
)
gen_imgs[0].save("sample_t2i.png")
display(IPY_Image("sample_t2i.png"))
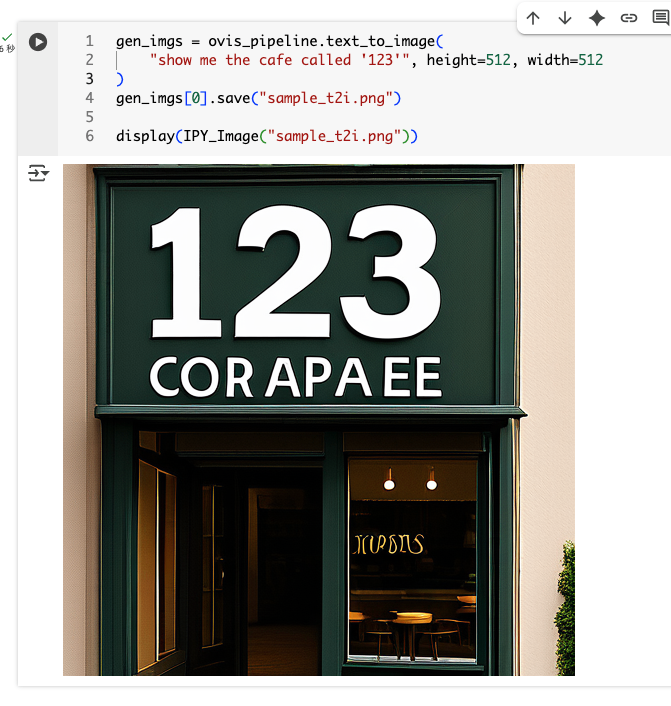
gen_imgs = ovis_pipeline.text_to_image(
"show me the cafe called '123'", height=512, width=512
)
gen_imgs[0].save("sample_t2i.png")
display(IPY_Image("sample_t2i.png"))
VRAM消費量の推移

16GBクラスのGPUがあれば十分いけそう。
まとめ
文字を含んだ画像生成はちょっと残念ではあるが、やっぱりOvisは素晴らしいな。サイズ的にも使いやすいし。
今後もOvisシリーズには注目したい。