データをベクトル化するETLパイプライン用軽量フレームワーク「VectorETL」を試す
VectorETL:ベクトルデータベース用の軽量ETLフレームワーク
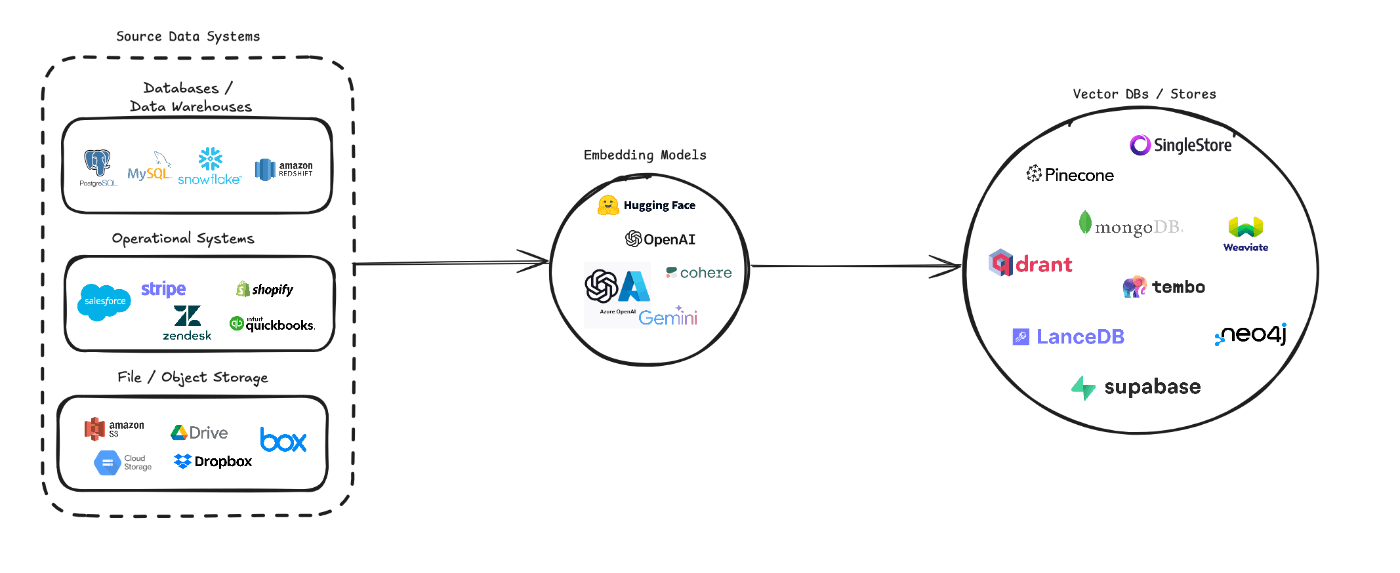
Context DataのVectorETLは、多様なデータソースをベクトル埋め込みに変換し、さまざまなベクトルデータベースに保存するプロセスを合理化するために設計された、柔軟でモジュール式のPythonフレームワークです。 複数のデータソース(データベース、クラウドストレージ、ローカルファイル)、さまざまな埋め込みモデル(OpenAI、Cohere、Google Geminiなど)、複数のベクトルデータベースのターゲット(Pinecone、Qdrant、Weaviateなど)をサポートしています。
このパイプラインは、ベクトル検索システムの作成と管理を簡素化することを目的としており、開発者やデータサイエンティストが、意味検索、レコメンデーションシステム、またはその他のベクトルベースの操作を必要とするアプリケーションを簡単に構築し、拡張できるようにすることを目指しています。
機能
- 複数のデータソース、埋め込みモデル、ベクトルデータベースをサポートするモジュール式のアーキテクチャ
- 大量のデータセットを効率的に処理するためのバッチ処理
- テキストデータのチャンキングとオーバーラップを構成可能
- 新しいデータソース、埋め込みモデル、ベクトルデータベースの統合が容易
referred from https://github.com/ContextData/VectorETL
3. プロジェクトの概要
VectorETL(抽出、変換、ロード)フレームワークは、さまざまなソースからのデータ抽出、ベクトル埋め込みへの変換、そしてこれらの埋め込みをさまざまなベクトルデータベースへのロードというプロセスを合理化するために設計された、強力かつ柔軟なツールです。モジュール性、拡張性、使いやすさを念頭に構築されており、データインフラストラクチャでベクトル検索の力を活用したい組織にとって理想的なソリューションです。
主な特長:
- 多様なデータ抽出: このフレームワークは、従来のデータベース、クラウドストレージソリューション(Amazon S3やGoogle Cloud Storageなど)、人気のSaaSプラットフォーム(StripeやZendeskなど)など、幅広いデータソースをサポートしています。この汎用性により、複数のソースからのデータを統合して単一のベクターデータベースにまとめることができます。
- 高度なテキスト処理: テキストデータについては、このフレームワークは高度なチャンキングとオーバーラッピングの技術を実装しています。これにより、ベクトル埋め込みを作成する際にテキストの意味的なコンテキストが保持され、より正確な検索結果が得られます。
- 最先端のエンベッディングモデル: このシステムは、OpenAI、Cohere、Google Gemini、Azure OpenAI などの主要なエンベッディングモデルと統合されています。これにより、お客様の特定の用途や品質要件に最適なエンベッディングモデルを選択することができます。
- 複数のベクトルデータベースをサポート: Pinecone、Qdrant、Weaviate、SingleStore、Supabase、LanceDBのいずれを使用している場合でも、このフレームワークが対応します。これらの一般的なベクトルデータベースとシームレスにインターフェースするように設計されており、ニーズに最適なものを選ぶことができます。
- 設定および拡張が可能: このフレームワーク全体は、YAMLまたはJSON設定ファイルにより高度な設定が可能です。さらに、モジュール式のアーキテクチャにより、ニーズの進化に合わせて新しいデータソース、埋め込みモデル、ベクターデータベースを追加して拡張することが容易です。
このETLフレームワークは、ベクター検索機能の導入やアップグレードを検討している企業に最適です。
データの抽出、ベクター埋め込みの作成、ベクターデータベースへの保存のプロセスを自動化することで、このフレームワークはベクター検索システムのセットアップにかかる時間と複雑性を大幅に削減します。これにより、データサイエンティストやエンジニアは、データ処理やベクター保存の複雑な作業に悩むことなく、洞察の導出やアプリケーションの構築に集中することができます。
ドキュメント
事前準備
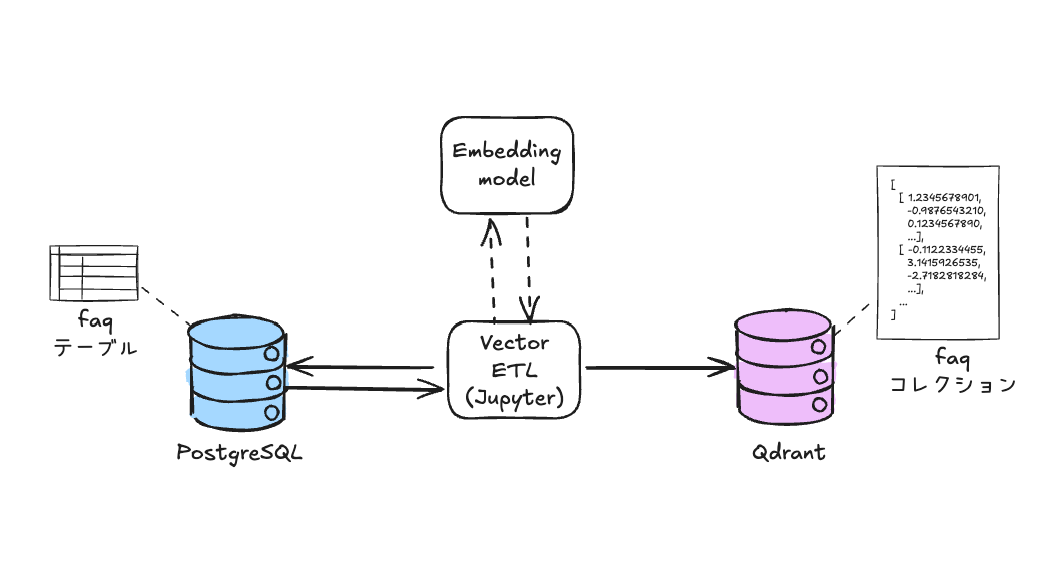
Usageに従って進める。今回はローカルのMac上にdockerで、PostgreSQLをデータソースとして使用し、データベース内のデータをベクトルDBに登録するパイプラインをVectorETLで作ることとする。
docker-compose.yamlを作成
services:
postgres:
image: postgres:latest
environment:
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- ./postgres_data:/var/lib/postgresql/data
jupyterlab:
image: quay.io/jupyter/minimal-notebook:latest
environment:
JUPYTER_TOKEN: "password" # Jupyterlabにアクセスするためのトークン
OPENAI_API_KEY: ${OPENAI_API_KEY}
ports:
- "8888:8888"
volumes:
- ./jupyter_work:/home/jovyan/work
qdrant:
image: qdrant/qdrant:latest
ports:
- "6333:6333"
- "6334:6334"
volumes:
- ./qdrant_storage:/qdrant/storage:z
起動
docker compose up -d
これで
- PostgreSQL
- Qdrant
- VectorETLを動かすためのJupyterLab
が作成される。
ブラウザでhttp://localhost:8888を開いて、JupyterLabにアクセスできればOK。
データソースの設定(PostgreSQL)
PostgreSQLにデータベースを作成する。データは京都大学大学院情報学研究科知能情報学コース言語メディア研究室 (https://nlp.ist.i.kyoto-u.ac.jp/)様が公開されている尼崎市のFAQデータセットを使用する。
パッケージインストール。pandasはデータの整形、psycopg2はPostgreSQLの操作。
!pip install pandas psycopg2-binary
データセットをダウンロードして、pandasデータフレームを作成。今回は100件だけ。
!wget https://tulip.kuee.kyoto-u.ac.jp/localgovfaq/localgovfaq.zip
!unzip localgovfaq.zip
import pandas as pd
def file2list(filename: str, prefix: str = "") -> tuple:
"""Q/AファイルをIDとコンテンツに分割、それぞれを配列で返す"""
contents = []
ids = []
try:
with open(filename, 'r') as file:
for line in file:
line = line.strip().replace(" ", "")
id, content = line.split('\t')
if prefix:
id = f"{prefix}_{id}"
contents.append(content)
ids.append(id)
except Exception:
raise
return contents, ids
questions, ids = file2list("localgovfaq/qas/questions_in_Amagasaki.txt")
answers, _ = file2list("localgovfaq/qas/answers_in_Amagasaki.txt")
raw_df = pd.DataFrame({'qa_id': ids, 'question': questions, 'answer': answers})
df = raw_df.head(100)
df

このデータを使ってデータベースを作成する。
import psycopg2
import pandas as pd
# 接続情報
host = "postgres"
port = "5432"
user = "postgres"
password = "password"
db_name = "faq"
table_name = "faq"
table_columns = ["qa_id", "question", "answer"]
try:
# faqデータベース作成
conn = psycopg2.connect(
dbname="postgres",
user=user,
password=password,
host=host,
port=port
)
conn.autocommit = True
cur = conn.cursor()
cur.execute(f"CREATE DATABASE {db_name}")
print(f"データベース作成: '{db_name}'")
cur.close()
conn.close()
# faqデータベースに接続してテーブルとトリガーを作成
with psycopg2.connect(
dbname=db_name,
user=user,
password=password,
host=host,
port=port
) as conn:
with conn.cursor() as cur:
# テーブル作成
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
id BIGSERIAL PRIMARY KEY,
qa_id INT,
question TEXT,
answer TEXT,
updated_at TIMESTAMP DEFAULT NOW()
)
"""
cur.execute(create_table_query)
# 注意:
# 今回は使用しないが、新規登録・更新時にタイムスタンプを更新して
# VectorETLである時点からの更新データのみを登録する、というような使い方
# を想定してトリガーを設定した。
# トリガー関数作成
create_function_query = """
CREATE OR REPLACE FUNCTION update_timestamp()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated_at = NOW();
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
"""
cur.execute(create_function_query)
# トリガー作成
create_trigger_query = f"""
CREATE TRIGGER set_timestamp
BEFORE UPDATE ON {table_name}
FOR EACH ROW
EXECUTE FUNCTION update_timestamp();
"""
cur.execute(create_trigger_query)
conn.commit()
print(f"テーブルとトリガー作成: '{table_name}'")
# faqテーブルにデータ登録
with psycopg2.connect(
dbname=db_name,
user=user,
password=password,
host=host,
port=port
) as conn:
with conn.cursor() as cur:
insert_query = f"INSERT INTO {table_name} (qa_id, question, answer) VALUES (%s, %s, %s)"
for _, row in df.iterrows():
cur.execute(insert_query, tuple(row))
conn.commit()
print("データ登録完了")
except Exception as e:
print(f"An error occurred: {e}")
finally:
if conn:
conn.close()
以下のように出力されればOK
データベース作成: 'faq'
テーブルとトリガー作成: 'faq'
データ登録完了
参照してみる。
with psycopg2.connect(
dbname=db_name,
user=user,
password=password,
host=host,
port=port
) as conn:
with conn.cursor() as cur:
select_query = f"SELECT * FROM {table_name}"
cur.execute(select_query)
results = cur.fetchall()
for r in results[:5]:
print("\n".join(map(str, r)))
print("----")
データが登録されていることを確認できた

ベクトルDB(Qdrant)
次にQdrantの設定。Qdrantにコレクションを作成する。
パッケージインストール
!pip install qdrant-client
コレクション作成。EmbeddingモデルはOpenAI text-embedding-3-smallを使用するつもりなので、次元数1536で設定する。
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams
client = QdrantClient(url="http://qdrant:6333")
collection_name = "faq"
if client.collection_exists(collection_name):
client.delete_collection(collection_name=collection_name)
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
True
Qdrantのコンソールでも確認してみる。http://localhost:6333/dashboardにアクセスして、コレクションが確認できればOK
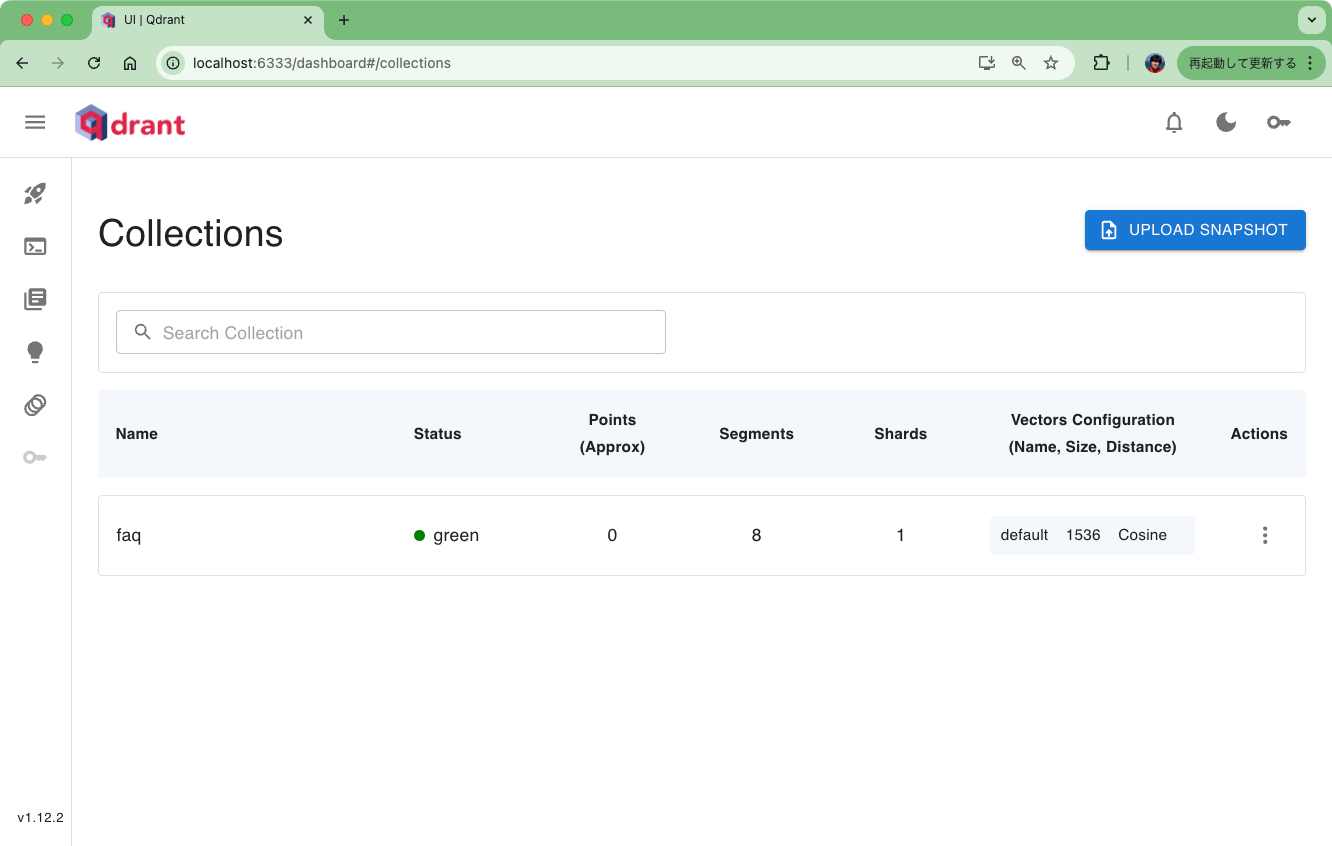
これで事前準備完了
VectorETLによるパイプライン
やっと本題のVectorETL。まずパッケージインストール。結構な量のパッケージがインストールされる。
!pip install --upgrade vector-etl
!pip freeze | grep -i vector-etl
vector-etl==0.1.7.1
パイプラインを定義する。VectorETLでパイプラインの定義して実行する方法は3つ
- YAMLを定義して、Pythonから実行
- YAMLを定義して、コマンドラインから実行
- Pythonで定義して、Pythonで実行
今回は3でやってみる。まずパイプラインの定義
from vector_etl import create_flow
import os
# データソースの定義
source = {
"source_data_type": "database",
"db_type": "postgres",
"host": "postgres",
"port": "5432",
"database_name": "faq",
"username": "postgres",
"password": "password",
"query": "select * from faq",
}
# Embeddingの定義
embedding = {
"embedding_model": "OpenAI",
"api_key": os.environ["OPENAI_API_KEY"],
"model_name": "text-embedding-3-small"
}
# ターゲットの定義
target = {
"target_database": "Qdrant",
"qdrant_url": "http://qdrant:6333",
"qdrant_api_key": "",
"collection_name": "faq"
}
# ベクトル化対象のカラムの定義
embed_columns = ["answer"]
# パイプラインを作成
flow = create_flow()
# 各定義をパイプラインにセット
flow.set_source(source)
flow.set_embedding(embedding)
flow.set_target(target)
flow.set_embed_columns(embed_columns)
パイプラインの定義は
- データソース
- Embedding
- ターゲット(となるベクトルDB)
- ベクトル化対象のカラム
で構成される。データソース、Embedding、ターゲットはそれぞれ複数のオプションがあり、オプションによって設定内容が異なるので、ドキュメントを確認すると良い。
ではパイプラインを実行
flow.execute()
以下のように表示されればOK
INFO:vector_etl.orchestrator:ETL process completed successfully.
Qdrantのコンソールで確認してみるとデータが登録されているのがわかる。


では検索してみる。
from openai import OpenAI
from qdrant_client import QdrantClient
def get_embedding(client, text, model):
response = client.embeddings.create(
input=text,
model=model,
)
return response.data[0].embedding
openai_client = OpenAI()
qdrant_client = QdrantClient(url="http://qdrant:6333")
query = "地域総合センター今北への行き方を教えて。"
query_embed = get_embedding(openai_client, query, "text-embedding-3-small")
results = qdrant_client.query_points(
collection_name="faq",
query=query_embed,
with_payload=True,
limit=3
).points
for r in results:
print(r.score)
print(r.payload["answer"])
print("----")

補足
パイプラインを定義する。VectorETLでパイプラインの定義して実行する方法は3つ
- YAMLを定義して、Pythonから実行
- YAMLを定義して、コマンドラインから実行
- Pythonで定義して、Pythonで実行
今回は3でやってみる。
1と2についてはYAMLを作成するのだが、以下のようにAPIキーを変数でセットしている箇所がある
embedding:
embedding_model: "OpenAI"
api_key: ${OPENAI_API_KEY}
model_name: "text-embedding-ada-002"
READMEには環境変数で渡せるというような記述があるのだが、自分が試した限りは環境変数を設定していても読み込んでくれなかった。環境依存なのかはわからない。
まとめ
テスト用環境を作る手間がかかったので手順としては長くなっているが、実際にやることは、ベクトル化パイプラインをYAML的に定義するだけなので、とても簡単にベクトル化が実現できる。
こういったベクトルインデックス作成用パイプラインは、例えばLlamaIndexなどのフレームワークなどを使うことでも実現できるが、既存のデータソースがすでにあったり、大量のデータを定型的に処理したい場合などは、やはりETLパイプラインを使うのが効率的だと思う。
あと、既存のデータソースがすでにあって、ベクトルDBを別に追加して類似検索を実現する、というようなケースだと、分散したデータの同期などを考える必要が出てくるが、VectorETLのサンプルにもあるように
- データベース側で更新日時などを持たせておく
- パイプライン実行時に、一定のタイミング「以降」のものを処理する
- パイプラインを定期実行する
というような感じで、自動でデータを同期(タイミングは非同期になると思うけども)させるような使い方も良いと思う。