Closed1
tiktokenで文字数・トークンの比率を出してみる
でコスト計算をするに当たり、
- DeepL、Vertex AI text-bisonは文字数
- OpenAIはトークン数
というところで課金の単位が異なる。データによって変わる可能性はあるけども、文字数・トークン数の比率を出してみた。
以下の日本語翻訳品質を図るデータセットを使用した。日・英両方あるので。
!pip install tiktoken datasets
from datasets import load_dataset
import tiktoken
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
dataset = load_dataset('bsd_ja_en')
data = dataset['train']
df = pd.DataFrame(data)
tqdm.pandas()
enc = tiktoken.get_encoding("cl100k_base")
df["en_char_len"] = df["en_sentence"].progress_apply(lambda x: len(x))
df["ja_char_len"] = df["ja_sentence"].progress_apply(lambda x: len(x))
df["en_token_cnt"] = df["en_sentence"].progress_apply(lambda x: len(enc.encode(x)))
df["ja_token_cnt"] = df["ja_sentence"].progress_apply(lambda x: len(enc.encode(x)))
df["ja_token_len_rate"] = df["ja_token_cnt"]/df["ja_char_len"]
df["en_token_len_rate"] = df["en_token_cnt"]/df["en_char_len"]
plt.hist(df['ja_token_len_rate'], bins=20)
plt.xlabel('ja token/len rate')
plt.show()
plt.hist(df['en_token_len_rate'], bins=20)
plt.xlabel('en token/len rate')
plt.show()
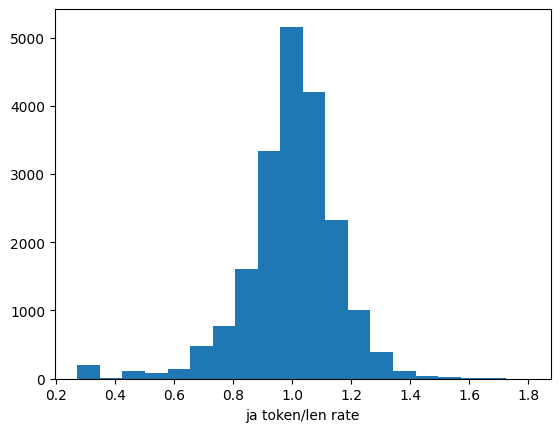
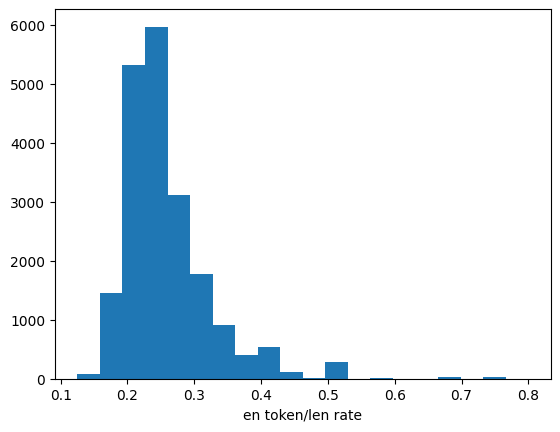
80%タイル、90%タイルな感じでも。
import numpy as np
ja_percentile_05 = np.percentile(df['ja_token_len_rate'], 5)
ja_percentile_10 = np.percentile(df['ja_token_len_rate'], 10)
ja_percentile_90 = np.percentile(df['ja_token_len_rate'], 90)
ja_percentile_95 = np.percentile(df['ja_token_len_rate'], 95)
plt.hist(df['ja_token_len_rate'], color='blue', bins=20, alpha=0.7)
plt.axvline(ja_percentile_10, color='green', linestyle='dashed', linewidth=2)
plt.axvline(ja_percentile_90, color='green', linestyle='dashed', linewidth=2)
plt.axvline(ja_percentile_05, color='red', linestyle='dashed', linewidth=2)
plt.axvline(ja_percentile_95, color='red', linestyle='dashed', linewidth=2)
plt.text(ja_percentile_05, plt.ylim()[1] * 1.05, f' {ja_percentile_05:.2f}', color='red')
plt.text(ja_percentile_10, plt.ylim()[1] * 1.01, f' {ja_percentile_10:.2f}', color='green')
plt.text(ja_percentile_90, plt.ylim()[1] * 1.01, f' {ja_percentile_90:.2f}', color='green')
plt.text(ja_percentile_95, plt.ylim()[1] * 1.05, f' {ja_percentile_95:.2f}', color='red')
plt.xlabel('ja token/len rate')
plt.show()
import numpy as np
en_percentile_05 = np.percentile(df['en_token_len_rate'], 5)
en_percentile_10 = np.percentile(df['en_token_len_rate'], 10)
en_percentile_90 = np.percentile(df['en_token_len_rate'], 90)
en_percentile_95 = np.percentile(df['en_token_len_rate'], 95)
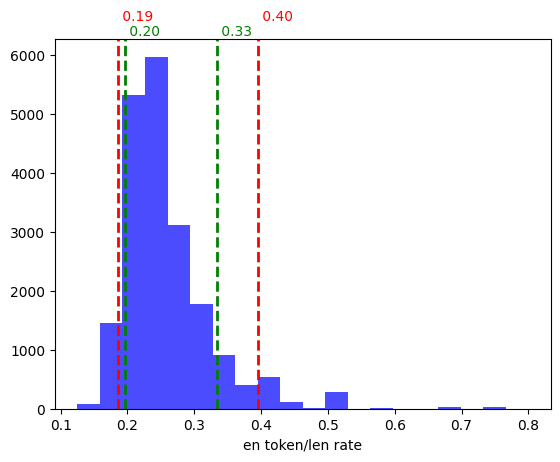
plt.hist(df['en_token_len_rate'], color='blue', bins=20, alpha=0.7)
plt.axvline(en_percentile_10, color='green', linestyle='dashed', linewidth=2)
plt.axvline(en_percentile_90, color='green', linestyle='dashed', linewidth=2)
plt.axvline(en_percentile_05, color='red', linestyle='dashed', linewidth=2)
plt.axvline(en_percentile_95, color='red', linestyle='dashed', linewidth=2)
plt.text(en_percentile_05, plt.ylim()[1] * 1.05, f' {en_percentile_05:.2f}', color='red')
plt.text(en_percentile_10, plt.ylim()[1] * 1.01, f' {en_percentile_10:.2f}', color='green')
plt.text(en_percentile_90, plt.ylim()[1] * 1.01, f' {en_percentile_90:.2f}', color='green')
plt.text(en_percentile_95, plt.ylim()[1] * 1.05, f' {en_percentile_95:.2f}', color='red')
plt.xlabel('en token/len rate')
plt.show()
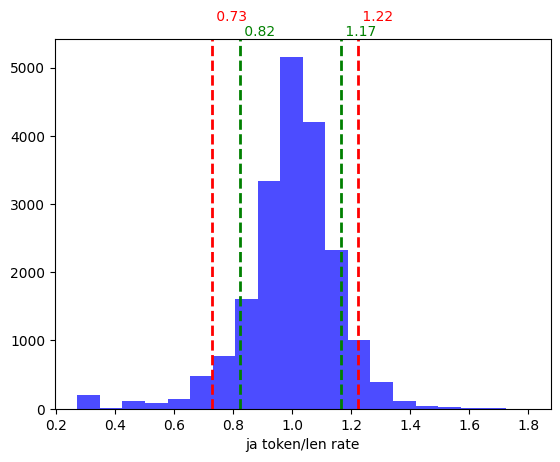
日本語はほぼ文字数≒トークン数で計算しても良さそう。コスト計算なので上振れした場合を考慮しておくならば1.2倍ぐらいに考えておけば良さそう。
英語は逆に、トークン数は文字数の1/3〜1/4ぐらいになると考えておけば良さそう。
このスクラップは2023/12/12にクローズされました