AnythingLLMを試す
AnythingLLM: あなたが探していたオールインワンAIアプリ
ドキュメントとチャットし、AIエージェントを使う、設定が自由自在、マルチユーザー、イライラするようなセットアップは必要なし
あらゆる文書、リソース、コンテンツの一部を、LLMがチャット中に参照できるコンテキストに変換できるフルスタックアプリケーション。このアプリケーションは、どのLLMやベクターデータベースを使うか選択することができ、マルチユーザー管理やパーミッションもサポートしている。
製品概要
AnythingLLMは、市販のLLMや一般的なオープンソースのLLMやvectorDBソリューションを使用して、妥協のないプライベートChatGPTを構築できるフルスタックアプリケーションである。
AnythingLLMはドキュメントをワークスペースと呼ばれるオブジェクトに分割する。ワークスペースはスレッドと同じように機能するが、ドキュメントのコンテナ化が追加されている。ワークスペースはドキュメントを共有することができるが、互いに会話することはないので、各ワークスペースのコンテキストをクリーンに保つことができる。
AnythingLLMのクールな特徴
- 🆕 マルチモーダルサポート (クローズドLLMとオープンソースLLMの両方!)
- 👤 マルチユーザーインスタンスのサポートと権限設定 ※Docker版のみ
- 🦾 ワークスペース内のエージェント(ウェブ閲覧、コード実行など)
- 💬 ウェブサイトにカスタム埋め込み可能なチャットウィジェット ※Docker版のみ
- 📖 複数の文書タイプをサポート (PDF、TXT、DOCXなど)
- ドラッグアンドドロップ機能と明確な引用を備えたシンプルなチャットUI。
- 100%クラウドへのデプロイに対応。
- すべての一般的なクローズドおよびオープンソースのLLMプロバイダーで動作する。
- 他のチャットUIと比較して、非常に大きなドキュメントを管理するためのコストと時間の節約策が組み込まれている。
- カスタム統合のための完全な開発者API!
- もっとたくさん...インストールして見つけよう!
自分的には、簡単にチャット+RAGがローカル(Ollama)でできる、ってところで良さそうだなーと前から思っていたが、マルチリンガルなEmbeddingがお手軽に使えなかったのだけがネックだった。
そんなところに、以下の記事にも書いた通り、評判のよいマルチリンガルEmbeddingモデルがOllamaで使えるようになったので、RAGを試してみようと思った次第。
ドキュメント
インストール
上記の記事にある通り、インストール方法には複数あり、機能に違いがある様子。
- デスクトップ版インストール
- 一人で使う、複数ユーザ管理はできない
- ワンクリックでローカルに必要なものがすべて同梱されたアプリケーションとしてインストールされる
- 外部公開するような機能は使えない
- Docker版インストール
- 複数ユーザでの利用に必要な管理機能あり(ワークスペースやドキュメントのアクセス権設定など)
- Dockerを使って簡単にインストール
- チャットウィジェットなどを外部公開できる
- ブラウザでのアクセス
- クラウドへのデプロイも可能
今回は以下の条件でインストールすることにする
- LAN内のUbutuサーバにインストール
- LLMやEmbeddingはすでにインストール済みのOllamaを使う
- Dockerを使う、Dockerはすでにセットアップ済みとする
ollamaは以下のモデルを使わせていただく
事前にpullしておく
$ ollama pull lucas2024/ezo-common-9b-gemma-2-it:q8_0
$ ollama pull ollama pull bge-m3
Dockerでのセルフホストは以下ドキュメントにあるが、
GitHubのドキュメントにdocker composeのサンプルが記載されているため、こちらを使うことにする
では作業ディレクトリを作成
$ mkdir anythingllm-sample && cd anythingllm-sample
GitHubのドキュメントを参考にdocker-compose.yamlを作成
services:
anythingllm:
image: mintplexlabs/anythingllm
container_name: anythingllm
ports:
- "3001:3001"
extra_hosts:
- "host.docker.internal:host-gateway"
cap_add:
- SYS_ADMIN
environment:
- STORAGE_DIR=/app/server/storage
- JWT_SECRET="XXXXXXXXXXXXXXXXXXXX"
- LLM_PROVIDER=ollama
- OLLAMA_BASE_PATH=http://host.docker.internal:11434
- OLLAMA_MODEL_PREF=lucas2024/ezo-common-9b-gemma-2-it:q8_0
- OLLAMA_MODEL_TOKEN_LIMIT=8192
- EMBEDDING_ENGINE=ollama
- EMBEDDING_BASE_PATH=http://host.docker.internal:11434
- EMBEDDING_MODEL_PREF=bge-m3:latest
- EMBEDDING_MODEL_MAX_CHUNK_LENGTH=8192
- VECTOR_DB=lancedb
- WHISPER_PROVIDER=local
- TTS_PROVIDER=native
- PASSWORDMINCHAR=8
volumes:
- anythingllm_storage:/app/server/storage
restart: always
volumes:
anythingllm_storage:
driver: local
driver_opts:
type: none
o: bind
device: ./storage
Linuxの場合は以下を追加しないと、ホストで起動しているOllamaにhost.docker.internalでアクセスできない。
extra_hosts:
- "host.docker.internal:host-gateway"
JWT_SECRETはこんな感じで生成
$ openssl rand -base64 24
データ用のディレクトリを作成
$ mkdir storage
起動
$ docker compose up -d
ブラウザで3001版ポートにアクセスすると以下の画面となる。
まずは左下の設定アイコンをクリック。

ここがシステム全般の設定になる。
全部は見ないけども、起動時に設定したところだけ確認。まず"AI Providers"の"LLM"

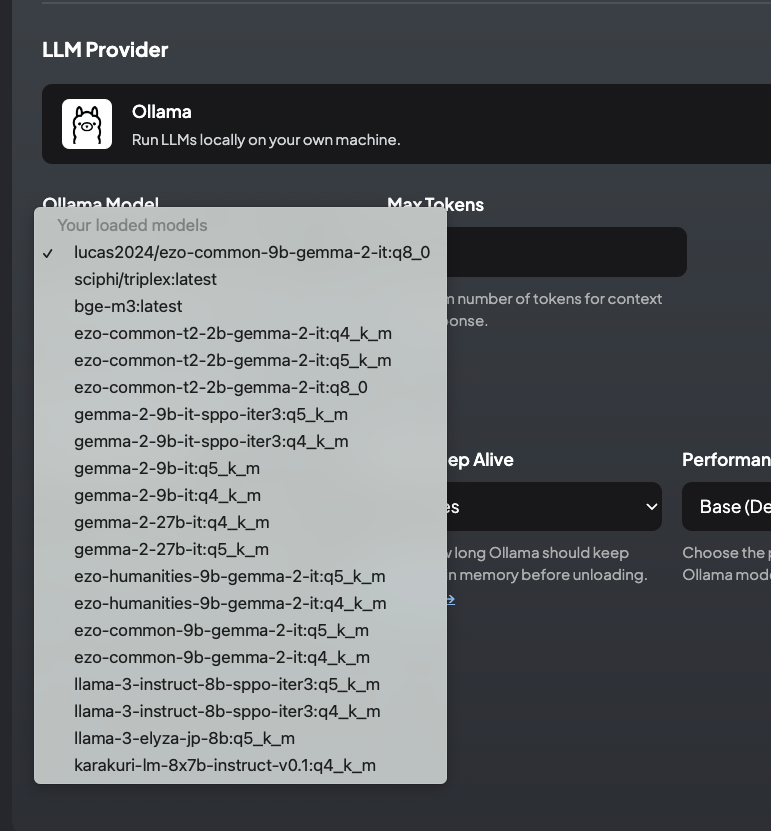
ここはチャットで使うLLMのプロバイダーに関する設定。docker-compose.yamlで指定した通り、Ollamaでpullしたモデルが選択されていることが確認できる。

なお、プロバイダーの設定はここで変更することもできるし、

Ollamaのモデルもすでにダウンロードされたものであれば、ここで変更することもできる。docker-compose.yamlで指定したのはデフォルト値っぽく思える。
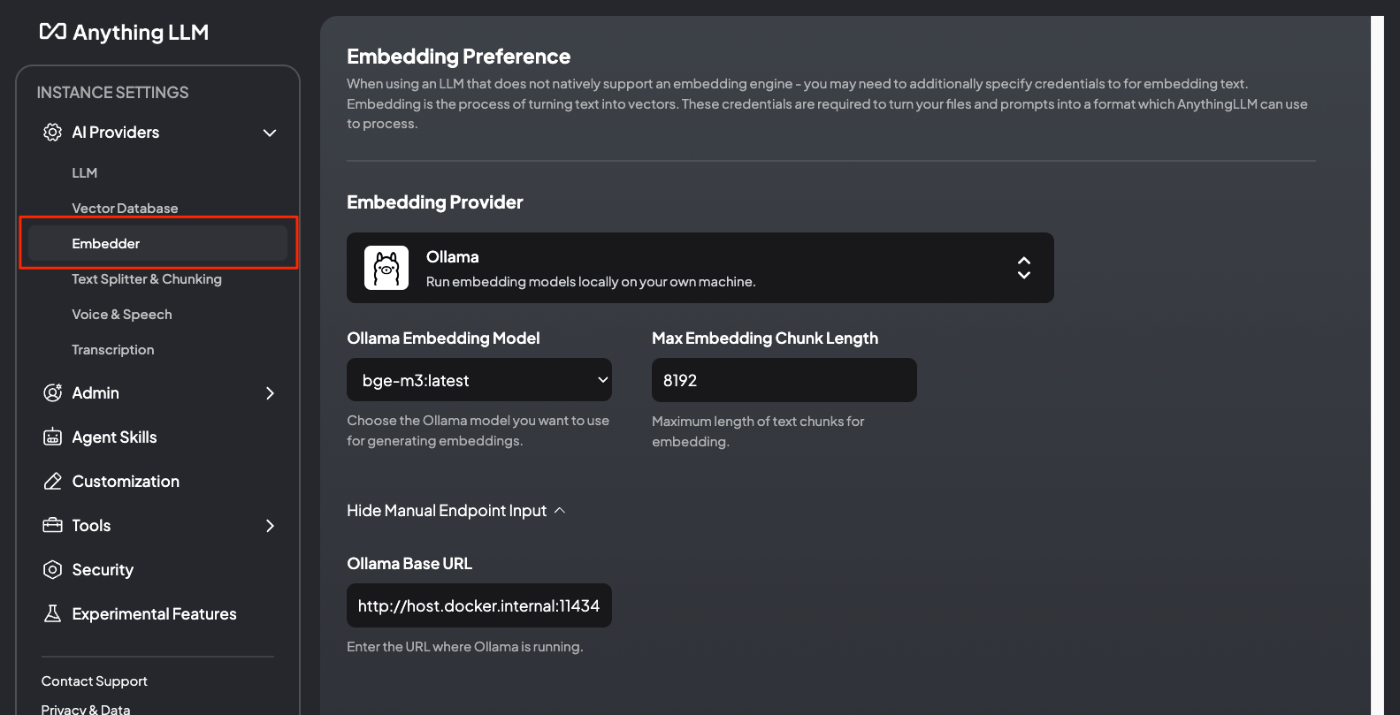
次に、"Vector Database"。AnythingLLMはRAGの機能があり、ドキュメントを登録すればベクトル検索ができるようになっているが、ここではそのためのベクトルデータベースを設定できる。デフォルトはLanceDBになっているが、他のベクトルDBも選択できる。

そして"Embedder"。その名の通りEmbeddingモデルの設定ができる。今回はOllamaでマルチリンガルに対応したモデルを選択している。
"Text Splitter & Chunking"はベクトル化する際のドキュメントのチャンク分割の設定。デフォルトは8192になっているが、今回はチャンクサイズを500、オーバーラップを100にした。
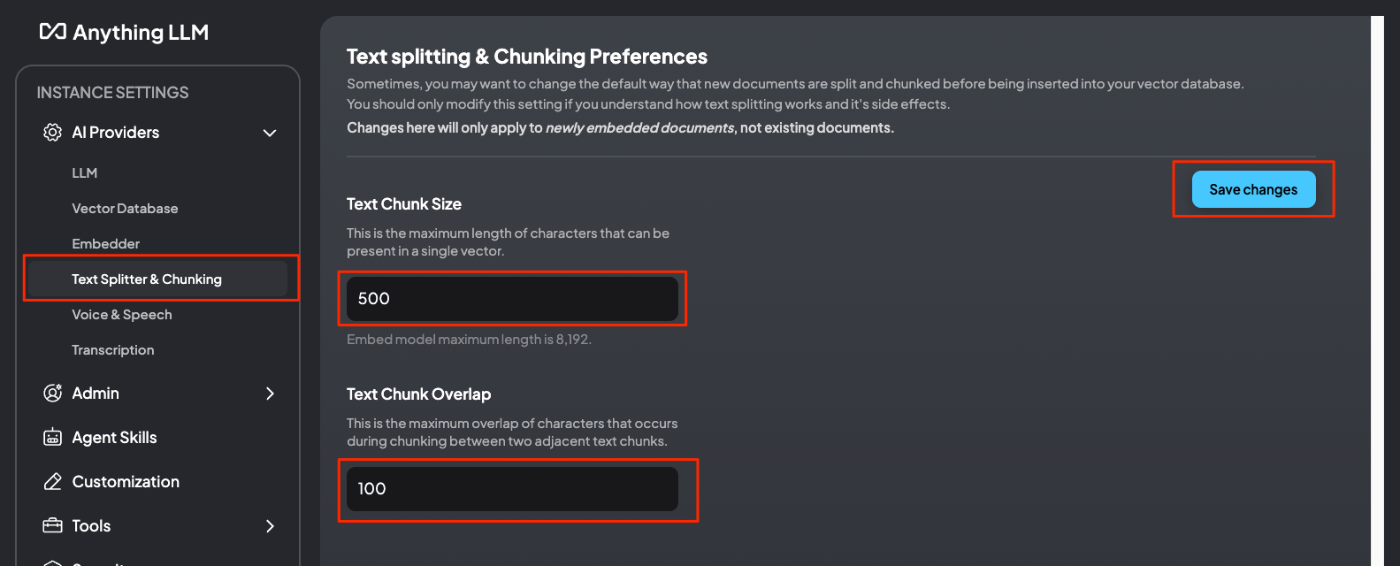
あとはSTT/TTSの設定やら、管理者設定、エージェントの設定などいろいろあるが、とりあえずここまで。
戻るボタンをクリック。

設定が確認できたので、簡単にチャットしてみたい。
まずワークスペースを作成する。ワークスペースの概念についてはドキュメントを探したけど明確に書かれているものはなくて、ざっと見た感じだと、
- マルチユーザの場合に共有する単位。つまり、複数の異なる権限を持ったグループがある場合にはそれぞれのグループごとにワークスペースを分ける。
- システム単位とは別にワークスペース単位で、LLM、ベクトルDB、エージェント設定なんかも設定できる。特にベクトルDBはワークスペース単位で作成されるっぽい。
というような使い方、ということのように思える。ただし初期状態ではマルチユーザ機能は有効にはなっていない。

とりあえず"my workspace"というのを作った。

ワークスペースが作成され、チャット画面らしきものが表示される。
デフォルトでは"default"という名前のスレッドが作成されている。スレッドはChatGPTやAnthropicでいうところの「チャット」と同じだと思う。なお、"default"は消せないようなので、基本は"New Thread"で新しいチャットを作るのだと思う。"New Thread"で新しいスレッドを作成しておく。
では適当にチャットしてみる。

チャットができているのがわかる。スレッドのタイトルも変わっている。
ではRAGをやってみる。サンプルのドキュメントは以下を使用する。
以下のようなコードでとりあえずテキストデータで落としてくる。
from pathlib import Path
import requests
import re
import argparse
import sys
# データ保存先のパスを定義
DATA_PATH = Path("./wiki_data")
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
def scrape_wikipedia(titles):
# データ保存先ディレクトリの作成(存在しない場合)
DATA_PATH.mkdir(exist_ok=True)
for title in titles:
try:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
},
timeout=10 # タイムアウトを10秒に設定
)
response.raise_for_status() # HTTPエラーがあれば例外を発生させる
data = response.json()
page = next(iter(data["query"]["pages"].values()))
if "extract" not in page:
print(f"警告: '{title}' の記事が見つかりませんでした。", file=sys.stderr)
continue
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
# markdown(.md)ファイルとして出力
output_file = DATA_PATH / f"{title}.txt"
with open(output_file, "w", encoding="utf-8") as fp:
fp.write(wiki_text)
print(f"'{title}' の記事を正常に保存しました: {output_file}")
except requests.RequestException as e:
print(f"エラー: '{title}' の取得中にネットワークエラーが発生しました: {e}", file=sys.stderr)
except KeyError as e:
print(f"エラー: '{title}' の解析中に問題が発生しました: {e}", file=sys.stderr)
except IOError as e:
print(f"エラー: '{title}' のファイル書き込み中に問題が発生しました: {e}", file=sys.stderr)
except Exception as e:
print(f"予期せぬエラー: '{title}' の処理中に問題が発生しました: {e}", file=sys.stderr)
def main():
parser = argparse.ArgumentParser(description="Scrape Wikipedia articles and save as markdown files.")
parser.add_argument("titles", nargs="+", help="Wikipedia article titles to scrape")
args = parser.parse_args()
scrape_wikipedia(args.titles)
if __name__ == "__main__":
main()
$ python get_wiki_text.py "オグリキャップ"
ダウンロードしたテキストファイルをアップロードしていく。
ドラッグ&ドロップでファイルをアップロード。
アップロードされたが、この状態は単にサーバ上に置かれただけ。

ファイルを選択して、"Move to Workspace"をクリック。

ファイルがワークスペースに移動する。"Save and Embed"をクリックしてベクトルDBに登録する。
登録が行われるが・・・
エラー・・・
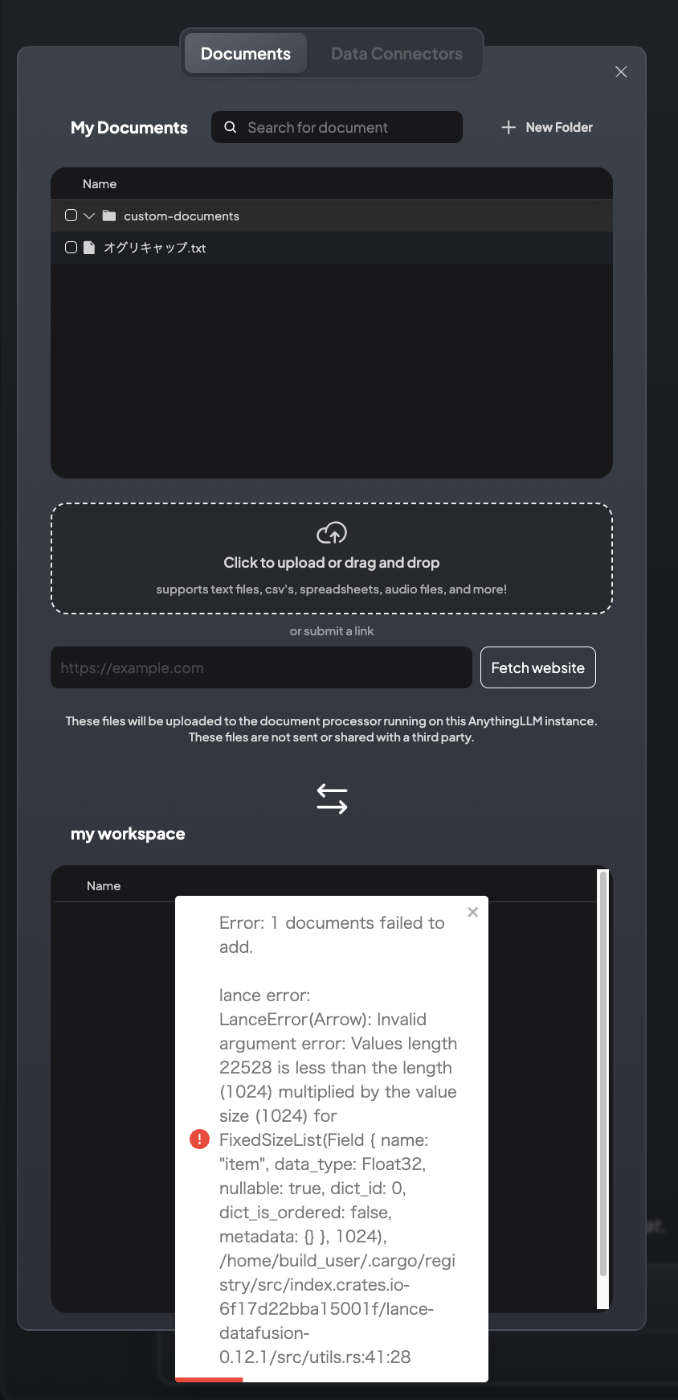
ちょっと原因がわからないのだけども、GitHubのIssueを見ていると似たようなエラーが多い。うーん、どうしたものか。。。
ちなみにやってみた感じだと以下。
- AnythingLLMのビルトインEmbeddingモデルでもダメ。
- OpenAIだといける。
- ベクトルDBはQdrantにも変えてみたけどダメ。
- チャンク設定をデフォルトのままにすればいけた(が、当然1つのチャンクが大きくなる)
- Embeddingモデルは一旦起動したあと途中で変えるとダメっぽい。
Issue見ててもちょっと正直わからないというか、釈然としない感がすごくある。AnythingLLMの問題ではない、設定もしくはEmbeddingプロバイダの問題みたいなことが書いてあったりするけども、設定とかがはっきりしないってのはアプリケーションの問題ではなかろうか?というふうにも思える。
なんとなくこのへんとかは少し気になる。
weaviateにしたほうがいいのかな?
ローカルで完結できて良さげかなーと思ったけど、ちょっと現状はいろいろ不明感のほうが強く感じるので、ペンディングかな。