BM25Sを試す
BM25-Sparse⚡
BM25Sは、PythonによるBM25アルゴリズムの高速で効率的な実装であり、NumpyとScipyの上に構築されている。
動機
BM25Sは、PythonでBM25アルゴリズムの高速、低依存、低メモリ実装を提供するように設計されている。BM25SはNumpyとScipyのみで構築されており、ステミングとセレクションのためのオプションの依存関係や、Huggingface Hubとの統合により、他のBM25インデックスを簡単に共有し使用することができる。
最小限の依存関係を持つことで、
bm25sはPython内部で数行ですべてを実現できる。しかしながら、新しいスパース・イーガー計算ストラテジーのおかげで、bm25sはElasticSearchに匹敵するか、それを超えるスピードを達成することができる。さらに、トークナイザー(
bm25s.tokenize()で呼び出される)も同梱されており、純粋にPythonベースの実装のおかげで高速でありながら、拡張も非常に簡単である(ただし、ElasticSearchの高度なアナライザーと比較すると、データセットによっては若干のパフォーマンス低下が見られるかもしれない)。Pythonで最も人気のあるBM25実装であるrank-bm25(シングルスレッド設定)に対する
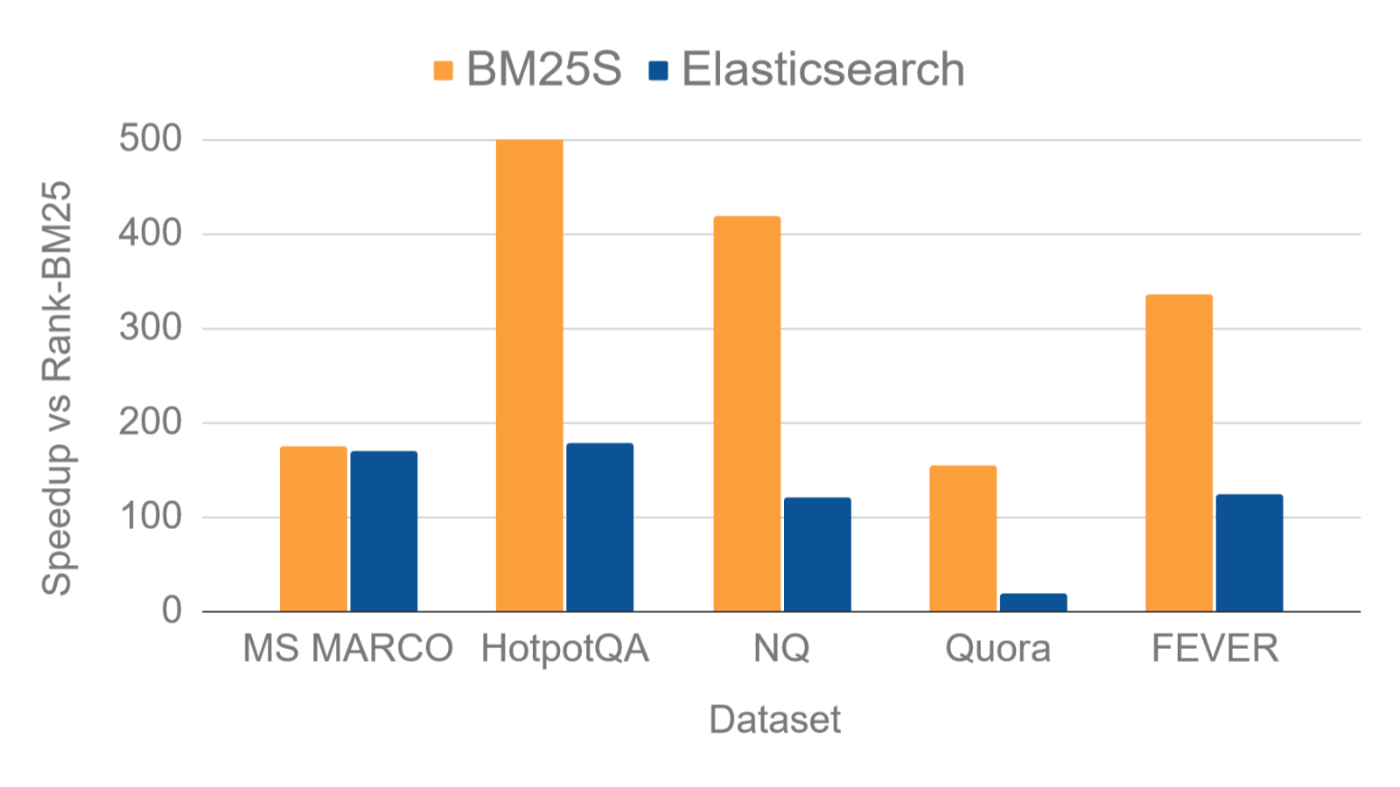
BM25SとElasticの相対的なスピードアップを以下に示す。スピードアップは、BEIRからの5つの人気のあるデータセットで、rank-bm25に対する1秒あたりのクエリの比率として計算されている。
referred from https://bm25s.github.io/
BM25の亜種なんだけど、他の亜種としてはBM42もある。
この違いをChatGPTに聞いてみた。
BM42とBM25Sの比較
BM42
具体的な使用例
BM42は、Qdrant社が開発したハイブリッド検索アルゴリズムで、ベクトル検索とスパース検索を組み合わせて利用します。特に短いテキストやリアルタイムアプリケーションに効果的で、以下のような分野で使われます:
- 医療:診療記録の検索や症例照会
- 保険:請求書やポリシーの検索
- 金融:取引記録の検索や顧客問い合わせ対応
検索精度と速度
BM42は、トランスフォーマーモデルを使用しているため、高精度な検索結果を提供します。また、リアルタイムアプリケーション向けに最適化されており、低メモリ使用で高速な検索が可能です。
アーキテクチャ
- ハイブリッド検索:ベクトル検索とスパース検索を組み合わせ、密な埋め込みと疎な埋め込みを利用
- トランスフォーマーモデル:検索クエリとドキュメントの関連性を高次元データで評価
技術的な利点
- 高精度な検索結果
- リアルタイム処理能力
- 低メモリ使用
限界
- トランスフォーマーモデルの調整が必要な場合がある
- 高度な実装が必要
BM25S
具体的な使用例
BM25Sは、高速で効率的なBM25アルゴリズムのPython実装で、特に大規模なドキュメント検索に使用されます:
- ウェブ検索:ウェブページのインデックスと検索
- ドキュメント管理システム:社内文書の検索
検索精度と速度
BM25Sは、特にスパースマトリックスを利用することで高速な検索を実現し、シングルスレッドの設定でElasticSearchよりも平均2倍の速度を持ちます (GitHub) (PyPI)。
アーキテクチャ
- スパースマトリックス:メモリ効率の良いデータ構造
- シンプルなPython実装:依存関係が少なく、使いやすい
技術的な利点
- 高速な検索速度
- メモリ効率が高い
- Hugging Faceとの統合が可能
限界
- ベクトル検索に対応していない
- 非常に大規模なデータセットではメモリ使用量が増加する可能性がある
比較まとめ
BM42は、ハイブリッド検索アルゴリズムとして高精度でリアルタイム性に優れ、特定の分野での適用に向いています。一方、BM25Sはスパース検索に特化し、高速でメモリ効率の良いテキスト検索を提供します。それぞれのアルゴリズムは異なる用途や要件に応じて選択することが重要です
んー、あってるのかな?ちょっと違う気がするけども、自分の雑な認識としては、BM42はモデルを使った推論(FastEmbed)による精度向上、BM25Sはアルゴリズムによる高速化・効率化、というイメージなので、ちょっと方向性が違うかなと勝手に思っている。
QuickStartに従って進めてみる。サンプルは英語での例なので、まずはそれにあわせて。
インストール
pip install bm25s[full]
オプションだがbm25sではステミング用のライブラリを組み合わせることもできて、上記のようにextrasを指定すればあわせてPyStemmerがインストールされる。ただPyStemmerは日本語には対応していないというか、そもそも日本語においてはステミングのようなシンプルな処理ではなく正規化を使うのではないかと思うので、とりあえずあまり気にしない。
ドキュメント、ここではコーパスとよんでいるが、これをトークン化する。
import bm25s
import Stemmer
# コーパスの定義
corpus = [
"cat is a feline and likes to purr",
"a dog is the human's best friend and loves to play",
"a bird is a beautiful animal that can fly",
"a fish is a creature that lives in water and swims",
]
# ステマーの定義
stemmer = Stemmer.Stemmer("english")
# コーパスをトークン化してIDだけを残す(高速化、メモリ節約)
corpus_tokens = bm25s.tokenize(corpus, stopwords="en", stemmer=stemmer)
トークンはこうなっていた。
corpus_tokens
Tokenized(ids=[[2, 19, 9, 5], [12, 1, 16, 18, 8, 11], [4, 13, 14, 0, 3], [6, 7, 10, 17, 15]], vocab={'can': 0, 'human': 1, 'cat': 2, 'fli': 3, 'bird': 4, 'purr': 5, 'fish': 6, 'creatur': 7, 'love': 8, 'like': 9, 'live': 10, 'play': 11, 'dog': 12, 'beauti': 13, 'anim': 14, 'swim': 15, 'best': 16, 'water': 17, 'friend': 18, 'felin': 19})
なるほど、単語とIDの辞書と、トークンはIDに置き換えたリストからなる、Tokenizedオブジェクトが作成される様子。
このトークンを使ってインデックスおよびretrieverを作成する。
retriever = bm25s.BM25()
retriever.index(corpus_tokens)
次に検索するためのクエリをトークン化。
query = "does the fish purr like a cat?"
query_tokens = bm25s.tokenize(query, stemmer=stemmer)
query_tokens
Tokenized(ids=[[0, 1, 4, 3, 2]], vocab={'doe': 0, 'fish': 1, 'cat': 2, 'like': 3, 'purr': 4})
ではretrieverにクエリトークンを渡して検索する。
# (doc id, score)のタプルとして、top-kの結果を得る。どちらも (n_queries, k) 形式の配列である。
results, scores = retriever.retrieve(query_tokens, corpus=corpus, k=2)
results、scoresはそれぞれ以下が返る。
results
array([['cat is a feline and likes to purr',
'a fish is a creature that lives in water and swims']],
dtype='<U50')
scores
array([[1.5876564 , 0.48158914]], dtype=float32)
これをあわせて表示するとこうなる。
for i in range(results.shape[1]):
doc, score = results[0, i], scores[0, i]
print(f"Rank {i+1} (score: {score:.2f}): {doc}")
Rank 1 (score: 1.59): cat is a feline and likes to purr
Rank 2 (score: 0.48): a fish is a creature that lives in water and swims
作成したretrieverは以下のように保存できる。
retriever.save("animal_index_bm25", corpus=corpus)
$ tree animal_index_bm25
animal_index_bm25
├── corpus.jsonl
├── corpus.mmindex.json
├── data.csc.index.npy
├── indices.csc.index.npy
├── indptr.csc.index.npy
├── params.index.json
└── vocab.index.json
0 directories, 7 files
これを読み出す場合は以下。
import bm25s
reloaded_retriever = bm25s.BM25.load("animal_index_bm25", load_corpus=True)
次はこれを日本語で・・・ということでコードを見てみたのだけども、少なくともbm25s.tokenizeは、英語のようなスペース区切りの言語のみ想定しており、分かち書きが必要な日本語のような言語を想定していない。よって日本語のトークナイザーを別途実装する必要がある。
とりあえず日本語テキストをトークン化して、bm25sのTokenizedオブジェクトとして返すトークナイザーを実装する。sudachiを使う。Claude-3.5-Sonnetに相談しながら書いてみた。
!pip install sudachipy sudachidict-core sudachidict-core sudachidict-small sudachidict-full
from typing import List, Union, Literal, Optional
from sudachipy import tokenizer, dictionary
from bm25s.tokenization import Tokenized
from tqdm.auto import tqdm
def sudachi_tokenize(
texts: Union[str, List[str]],
sudachi_mode: Literal['A', 'B', 'C'] = 'C',
sudachi_dict: Literal['small', 'core', 'full'] = 'core',
stopwords: Optional[List[str]] = None,
pos_filter: Optional[List[str]] = None,
return_ids: bool = True,
show_progress: bool = True,
leave: bool = False,
) -> Union[List[List[str]], Tokenized]:
"""
SudachiPyを使用して日本語テキストをトークン化する関数。
Parameters:
-----------
texts : Union[str, List[str]]
トークン化するテキストまたはテキストのリスト。
sudachi_mode : Literal['A', 'B', 'C'], optional
Sudachiの分割モード。'A'(短い), 'B'(中間), 'C'(長い)から選択。デフォルトは'C'。
sudachi_dict : Literal['small', 'core', 'full'], optional
使用するSudachi辞書。'small', 'core', 'full'から選択。デフォルトは'core'。
stopwords : Optional[List[str]], optional
除去するストップワードのリスト。Noneの場合、ストップワードは使用されません。
pos_filter : Optional[List[str]], optional
抽出する品詞のリスト。Noneの場合、全ての品詞を抽出します。
return_ids : bool, optional
トークンIDと語彙辞書を返すかどうか。Falseの場合、トークン化された文字列のリストを返します。
show_progress : bool, optional
進捗バーを表示するかどうか。
leave : bool, optional
完了後に進捗バーを残すかどうか。
Returns:
--------
Union[List[List[str]], Tokenized]
return_idsがTrueの場合、Tokenizedオブジェクトを返します。
Falseの場合、トークン化された文字列のリストのリストを返します。
"""
if isinstance(texts, str):
texts = [texts]
if sudachi_mode not in ['A', 'B', 'C']:
raise ValueError("sudachi_mode must be 'A', 'B', or 'C'")
mode = getattr(tokenizer.Tokenizer.SplitMode, sudachi_mode)
if sudachi_dict not in ['small', 'core', 'full']:
raise ValueError("sudachi_mode must be 'core', 'small', or 'full'")
tokenizer_obj = dictionary.Dictionary(dict=sudachi_dict).create()
# ストップワードの設定
stopwords_set = set(stopwords) if stopwords else set()
corpus_ids = []
token_to_index = {}
for text in tqdm(texts, desc="Tokenizing", disable=not show_progress, leave=leave):
morphemes = tokenizer_obj.tokenize(text, mode)
tokens = []
for m in morphemes:
# 品詞とストップワードでフィルタ
if pos_filter is None or any(m.part_of_speech()[0].startswith(pos) for pos in pos_filter):
token = m.normalized_form()
if token not in stopwords_set:
tokens.append(token)
doc_ids = []
for token in tokens:
if token not in token_to_index:
token_to_index[token] = len(token_to_index)
token_id = token_to_index[token]
doc_ids.append(token_id)
corpus_ids.append(doc_ids)
if return_ids:
return Tokenized(ids=corpus_ids, vocab=token_to_index)
else:
reverse_dict = {v: k for k, v in token_to_index.items()}
return [[reverse_dict[token_id] for token_id in doc_ids] for doc_ids in corpus_ids]
インデックス作成と検索。
import requests
import bm25s
# stopwordsはSlothLibのものを使用する
url = "http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt"
stopwords_ja = []
for line in requests.get(url).text.split("\r\n"):
if len(line) > 1:
stopwords_ja.append(line)
# 品詞フィルタの設定
pos_list = ["名詞","動詞","形容詞"]
corpus = [
"猫は哺乳類で、ゴロゴロするのが好きです。",
"犬は人間の最良の友で、遊ぶのが大好きです。",
"鳥は美しい動物で、飛ぶことができます。",
"魚は水中に生息し、泳ぐ生物です。",
]
corpus_tokens = sudachi_tokenize(corpus, stopwords=stopwords_ja, pos_filter=["名詞","動詞","形容詞"])
print("コーパスのトークン: ", corpus_tokens)
retriever = bm25s.BM25()
retriever.index(corpus_tokens)
query = "犬も猫は両方哺乳類?"
query_tokens = sudachi_tokenize(query, stopwords=stopwords_ja, pos_filter=["名詞","動詞","形容詞"])
print("クエリのトークン: ", query_tokens)
results, scores = retriever.retrieve(query_tokens, corpus=corpus, k=2)
print("検索結果: ")
for i in range(results.shape[1]):
doc, score = results[0, i], scores[0, i]
print(f"Rank {i+1} (score: {score:.2f}): {doc}")
DEBUG:bm25s:Building index from IDs objects
コーパスのトークン: Tokenized(ids=[[0, 1, 2], [3, 4, 5, 6, 7], [8, 9, 10, 11, 12], [13, 14, 15, 2, 16, 17]], vocab={'猫': 0, '哺乳類': 1, '為る': 2, '犬': 3, '人間': 4, '最良': 5, '友': 6, '遊ぶ': 7, '鳥': 8, '美しい': 9, '動物': 10, '飛ぶ': 11, '出来る': 12, '魚': 13, '水中': 14, '生息': 15, '泳ぐ': 16, '生物': 17})
クエリのトークン: Tokenized(ids=[[0, 1, 2, 3]], vocab={'犬': 0, '猫': 1, '両方': 2, '哺乳類': 3})
検索結果:
Rank 1 (score: 1.15): 猫は哺乳類で、ゴロゴロするのが好きです。
Rank 2 (score: 0.47): 犬は人間の最良の友で、遊ぶのが大好きです。
できるにはできたんだけども、bm25s.tokenizeがガッツリ英語向けに書かれていて日本語とはかなり違うのと、bm25s側が持ってるインタフェースで日本語対応する方法はなさそう(トークナイザーをbm25sの外でやる or bm25sのサブクラスを作ってtokenizeをオーバーライドする等になる)なので、どういう風に組み込むかはちょっと悩ましいところ。。。