Difyを試す
先進的なAIアプリケーションのためのイノベーションエンジン
DifyはオープンソースのLLMアプリ開発プラットフォームです。RAGエンジンを使用して、エージェントから複雑なAIワークフローまでLLMアプリを編成します。
DifyはオープンソースのLLMアプリ開発プラットフォームです。その直感的なインターフェースは、AIワークフロー、RAGパイプライン、エージェント機能、モデル管理、観測可能な機能などを兼ね備えており、プロトタイプから製品化まで迅速に行うことができます。コア機能のリストはこちらです:
- ワークフロー: ビジュアル・キャンバス上でパワフルなAIワークフローを構築、テスト。
- 包括的なモデルのサポート: GPT、Mistral、Llama2、OpenAI API互換モデルを含む、数十の推論プロバイダーやセルフホストソリューションの数百のプロプライエタリ/オープンソースLLMとシームレスに統合できます。サポートされているモデルプロバイダの完全なリストはこちらをご覧ください。
- プロンプトIDE:プロンプトを作成したり、モデルのパフォーマンスを比較したり、チャットベースのアプリに音声合成などの追加機能を追加したりするための直感的なインターフェース。
- RAGパイプライン: ドキュメントの取り込みから検索までをカバーする広範なRAG機能。PDF、PPT、その他の一般的なドキュメント形式からのテキスト抽出をすぐにサポートします。
- エージェント機能: LLM関数呼び出しまたはReActに基づいてエージェントを定義し、エージェントのための事前構築またはカスタムツールを追加することができます。Difyは、Google Search、DELL-E、Stable Diffusion、WolframAlphaなど、AIエージェントのための50以上の組み込みツールを提供します。
- LLMOps: アプリケーションのログとパフォーマンスを長期にわたって監視、分析します。プロダクションデータとアノテーションに基づいて、プロンプト、データセット、モデルを継続的に改善することができます。
- Backend-as-a-Service: Difyが提供する全てのサービスには、対応するAPIが付属しており、自社のビジネスロジックにDifyを簡単に統合することができます。
セットアップ
docker composeに対応しているので、ローカルのUbuntuサーバにいれる。
$ git clone https://github.com/langgenius/dify && cd dify
$ cd docker
$ docker compose up
これぐらいコンテナが上がってくる。
[+] Running 8/8
✔ Container docker-sandbox-1 Created 0.7s
✔ Container docker-web-1 Created 0.7s
✔ Container docker-db-1 Created 0.0s
✔ Container docker-redis-1 Created 0.0s
✔ Container docker-weaviate-1 Created 0.0s
✔ Container docker-worker-1 Created 0.7s
✔ Container docker-api-1 Created 0.7s
✔ Container docker-nginx-1 Recreated
Webのインタフェースは80番ポートで上ってくるようなので、ブラウザでアクセスして、管理者アカウントの登録を行う。

登録が終わったらそのアカウントでログイン。

ログインできた。
ここからアプリを作成していく。
アプリの作成
Quickstartを参考にしつつアプリを作っていく。とりあえず簡単なRAGアプリを作りたいと思う。
新規で作成(翻訳がイマイチっぽい)
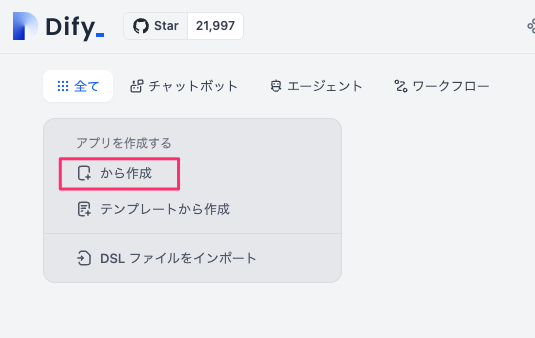
作成するアプリのタイプを選択して名前などを設定。

タイプは以下の4種類。
- チャットボット: チャット形式のアプリ。会話履歴が管理されるっぽい。
- テキストジェネレーター: 1問1答形式のアプリ。会話履歴は管理されない。
- エージェント: ツールと連携してタスクを自動完了させる、いわゆるエージェントアプリ。
- ワークフロー: 処理フローをGUIで細かく設定しながら最終的なテキスト生成を行うアプリ。1〜3を全部自分で細かく作る感じなのだろうと思う。
「チャットボット」の場合だけ、さらにオーケストレーション方法として2つ用意されている。
- 基本: シンプルなフォーム入力だけでチャットボットが作成されるっぽい。
- Chatflow: ワークフローでチャットボットを作る。上の4のやり方である程度最初から用意されてる、という感じっぽい。
今回は以下で作成することとする。
| 項目 | 設定 |
|---|---|
| タイプ | チャットボット |
| オーケストレーション方法 | 基本 |
| アプリ名 | 尼崎市QAチャットボット |
| 説明 | (適当に) |
RAGのデータセットに、以下の尼崎市のFAQデータセットを使おうと思っているので、それに合わせてアプリ名を設定した。
項目を設定したら「作成」をクリック。
アプリ作成すると、以下のような画面が表示される。
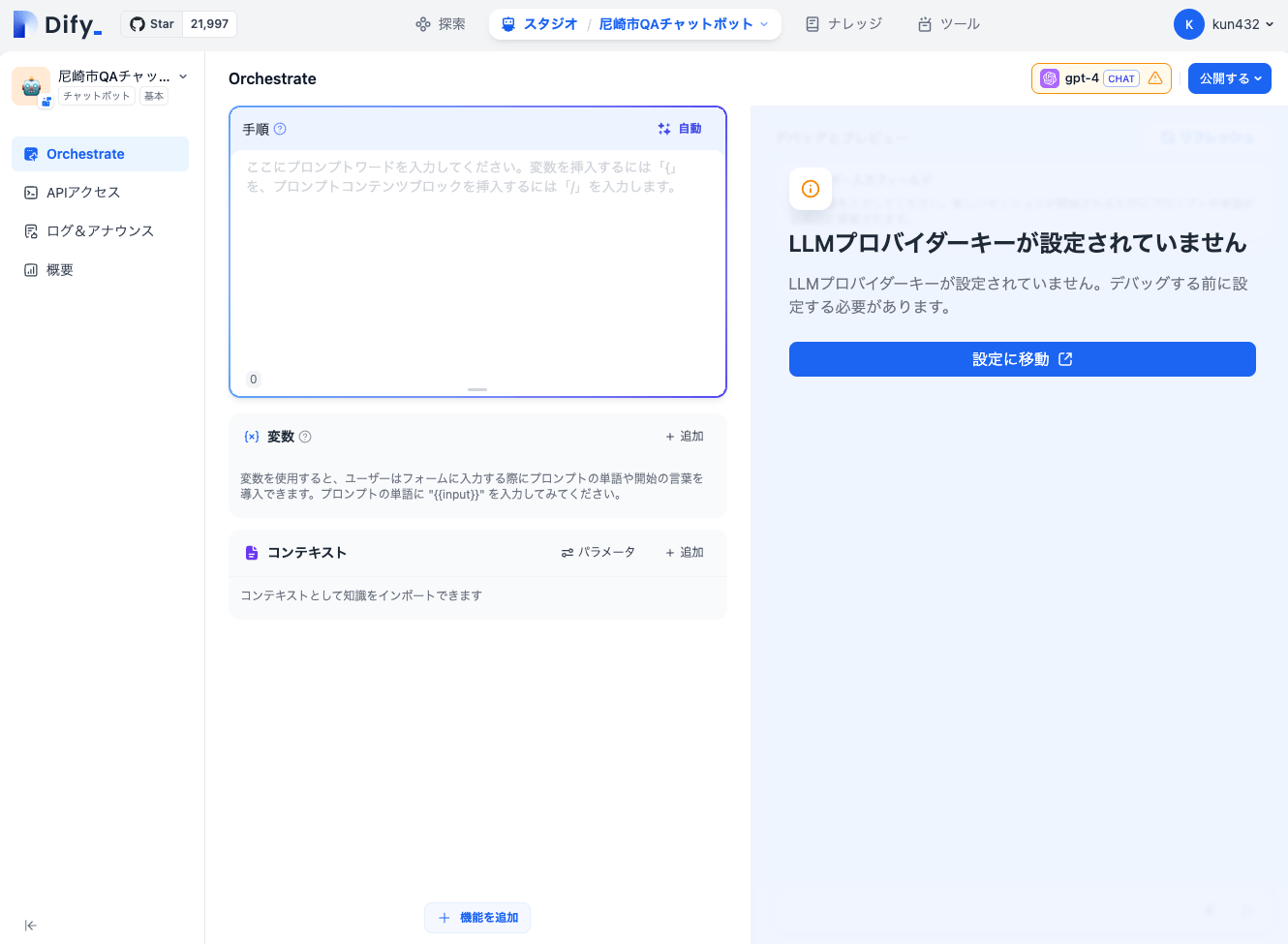
Difyの初回起動には各LLMのAPIキーなどが設定されていないので、こういう表示になる。「設定に移動」をクリックして、LLMのAPIキーを設定していく。
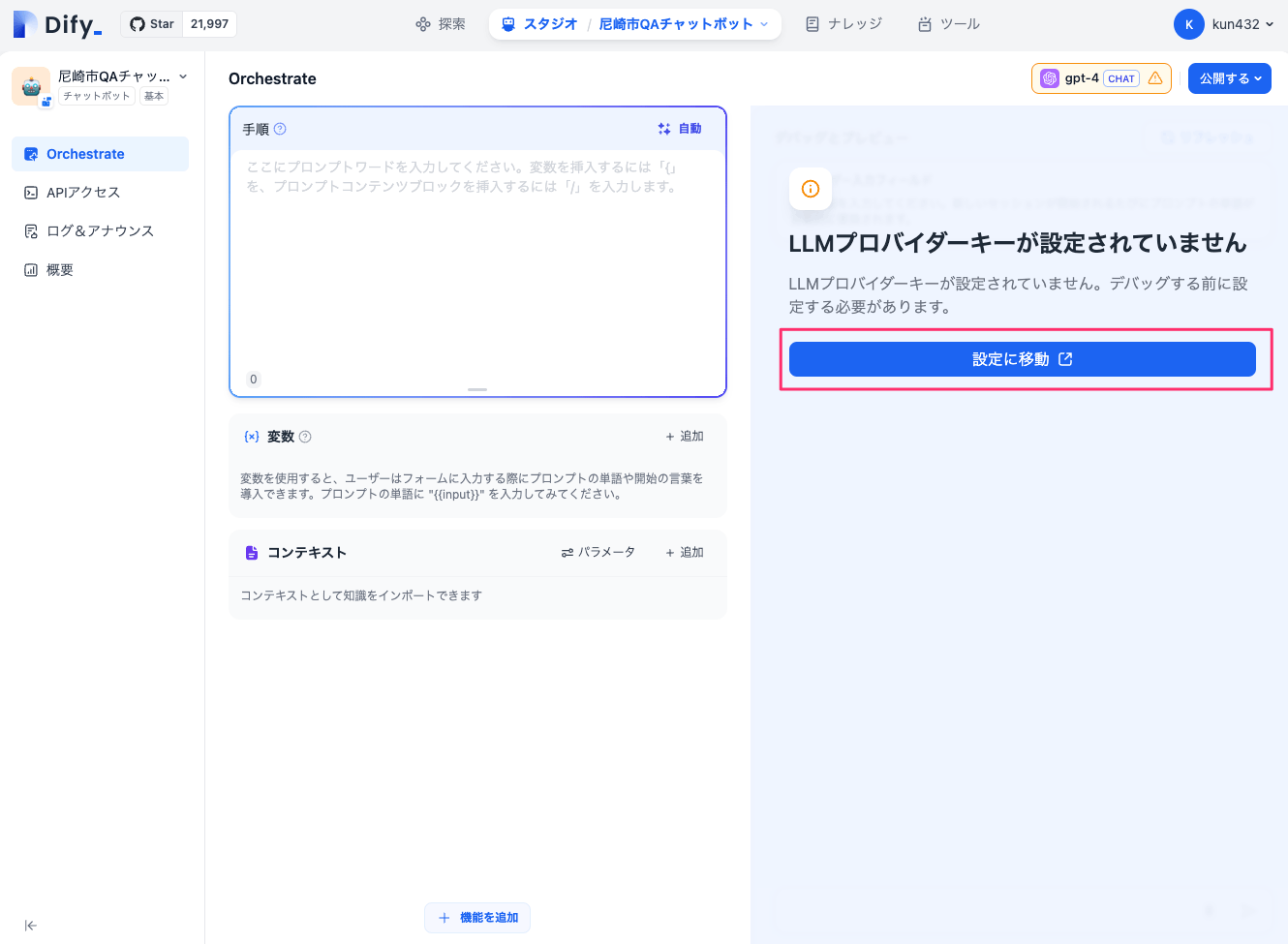
利用可能なモデルのプロバイダー一覧が表示される。ここで使用するプロバイダーごとにAPIキーを設定していくことになる。
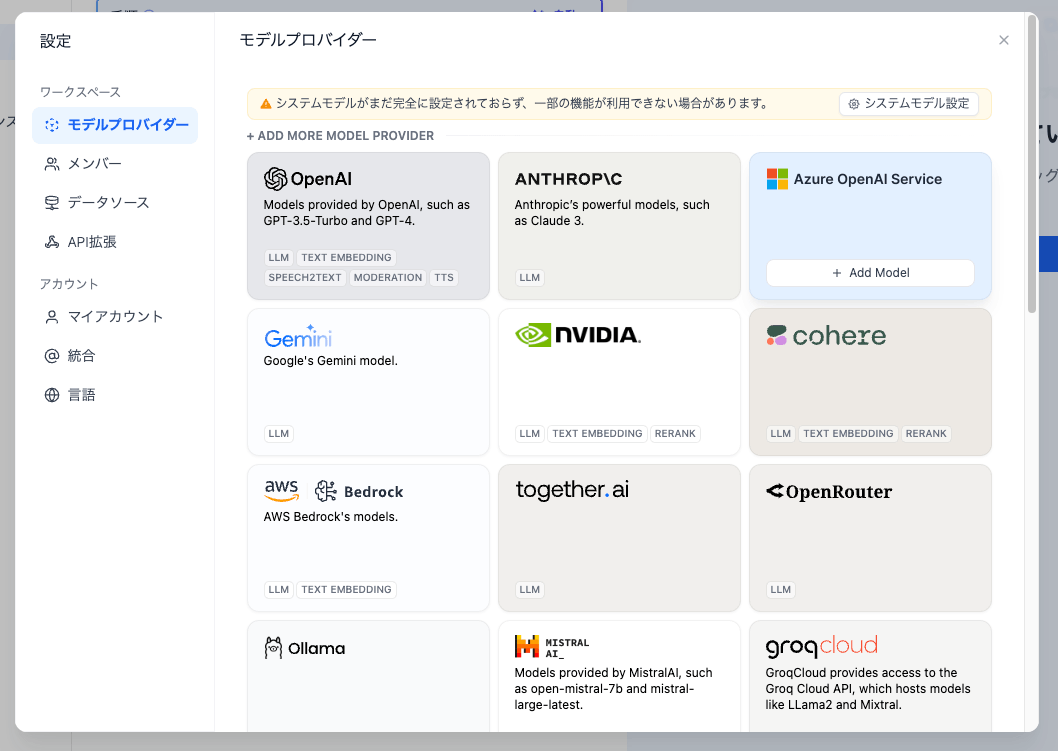
とりあえずOpenAIのAPIキーを設定してみる。OpenAIにカーソルをあわせて「セットアップ」をクリック
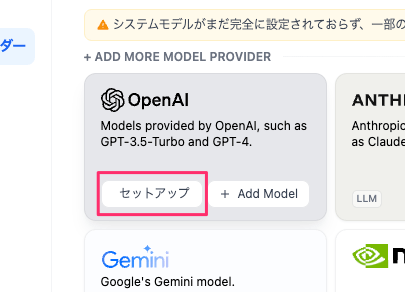
APIキーを入力して保存。
これでOpenAIが利用可能となった。他のモデルも使う場合は適宜設定していけばよい。
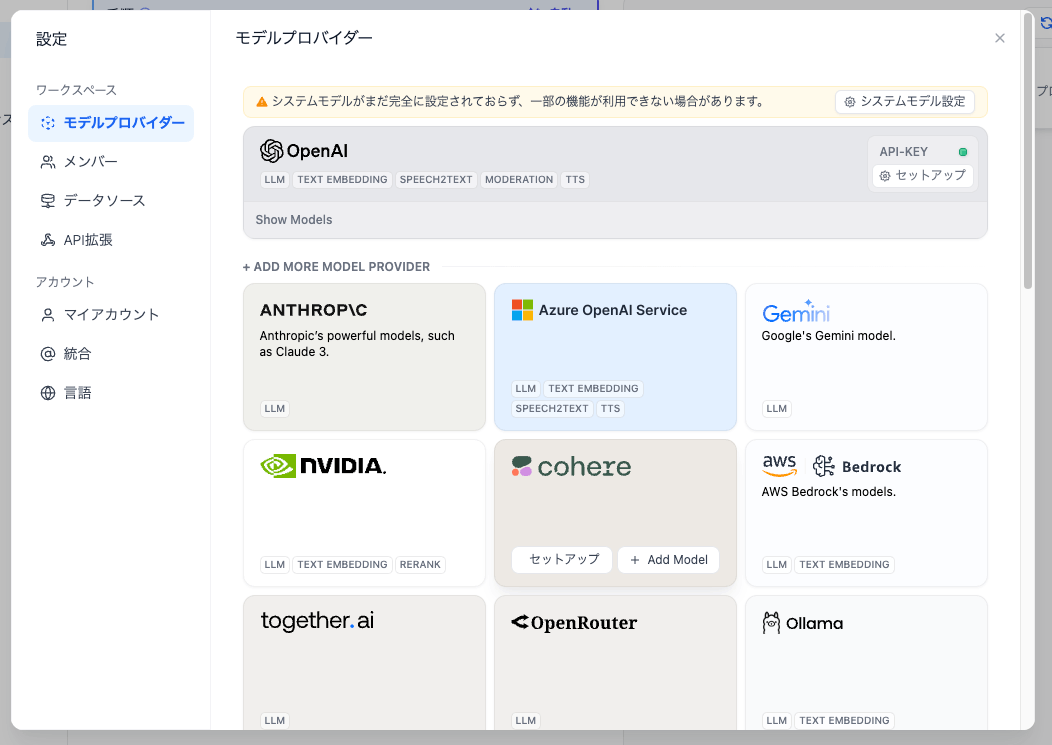
APIキーを設定後、上に「システムモデルが・・・」というメッセージが出ているかもしれない。アプリごとに度のモデルを使うかは個別に設定できるが、システムモデルはデフォルトで使用するモデルの設定のことになる。「システムモデル設定」をクリック。
モデルの種類ごとにデフォルトで使用するモデルを選択する。自分の場合はこんな感じで設定してみた。全部を設定する必要はなく、必要なもの・使うものだけで設定しておけばよい。

なお、設定後もメッセージが表示されているが、ちゃんと反映されているはずなので気にせず閉じてよい。
アプリ設定画面に戻る。
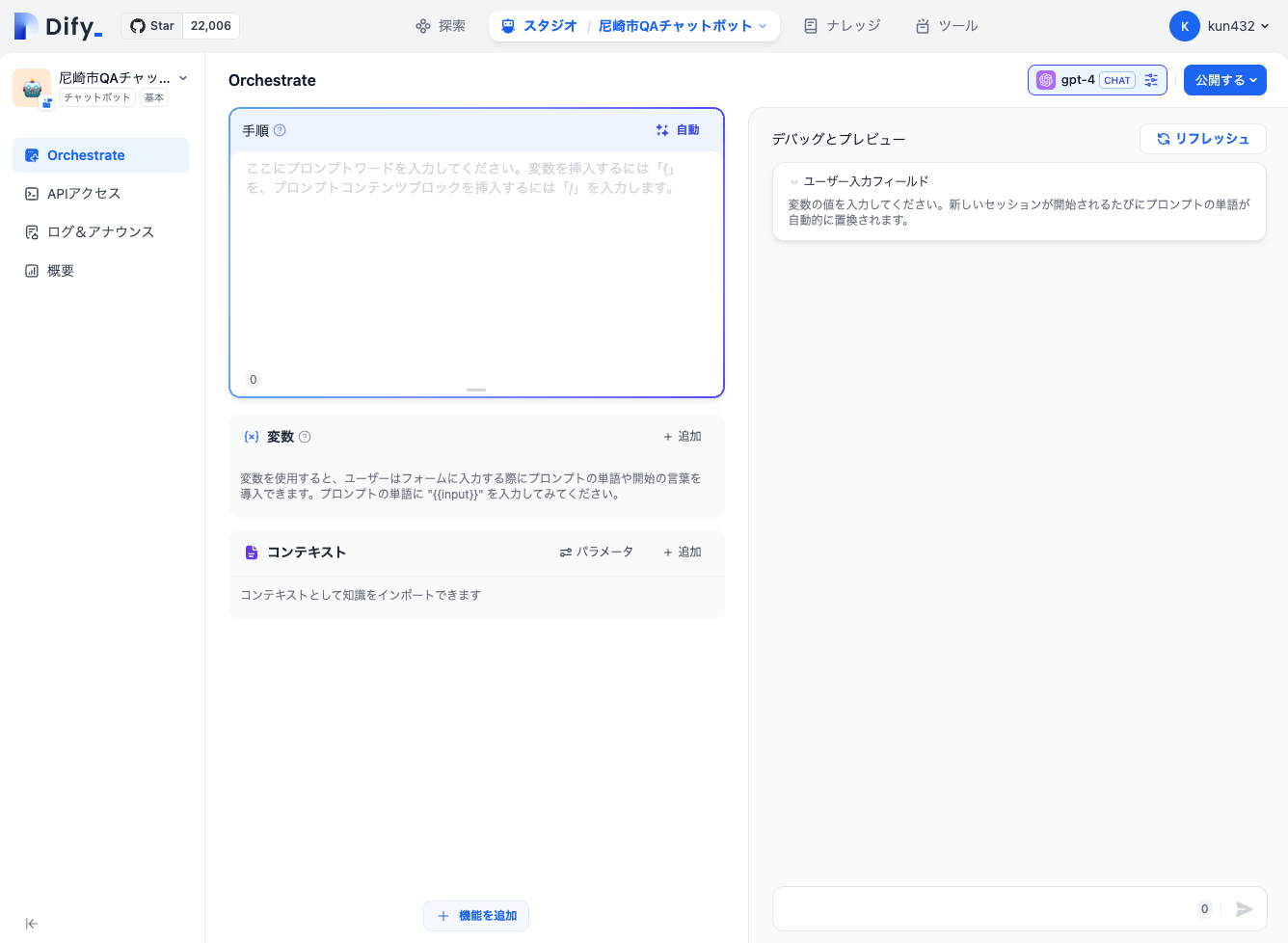
システムモデル設定前にアプリ作成しているためか、初回だけモデルがGPT-4になっているようなので、これを一旦変更しておく。コストも気になるし。

では「手順」にプロンプトを入力する。ここはいわゆる「システムプロンプト」だと思う。
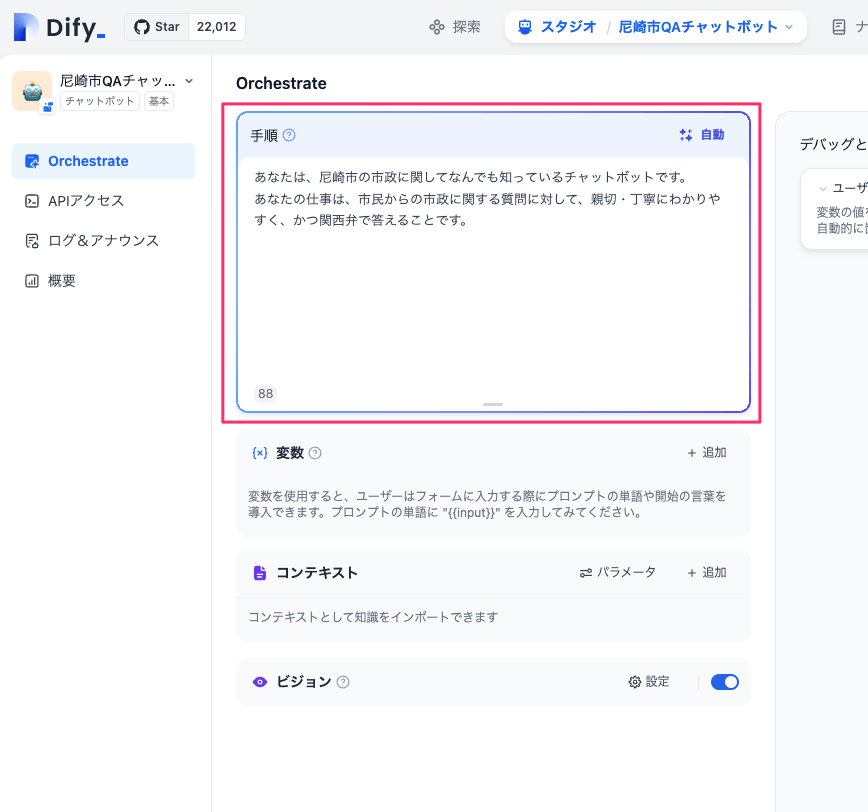
ではチャットしてみる。
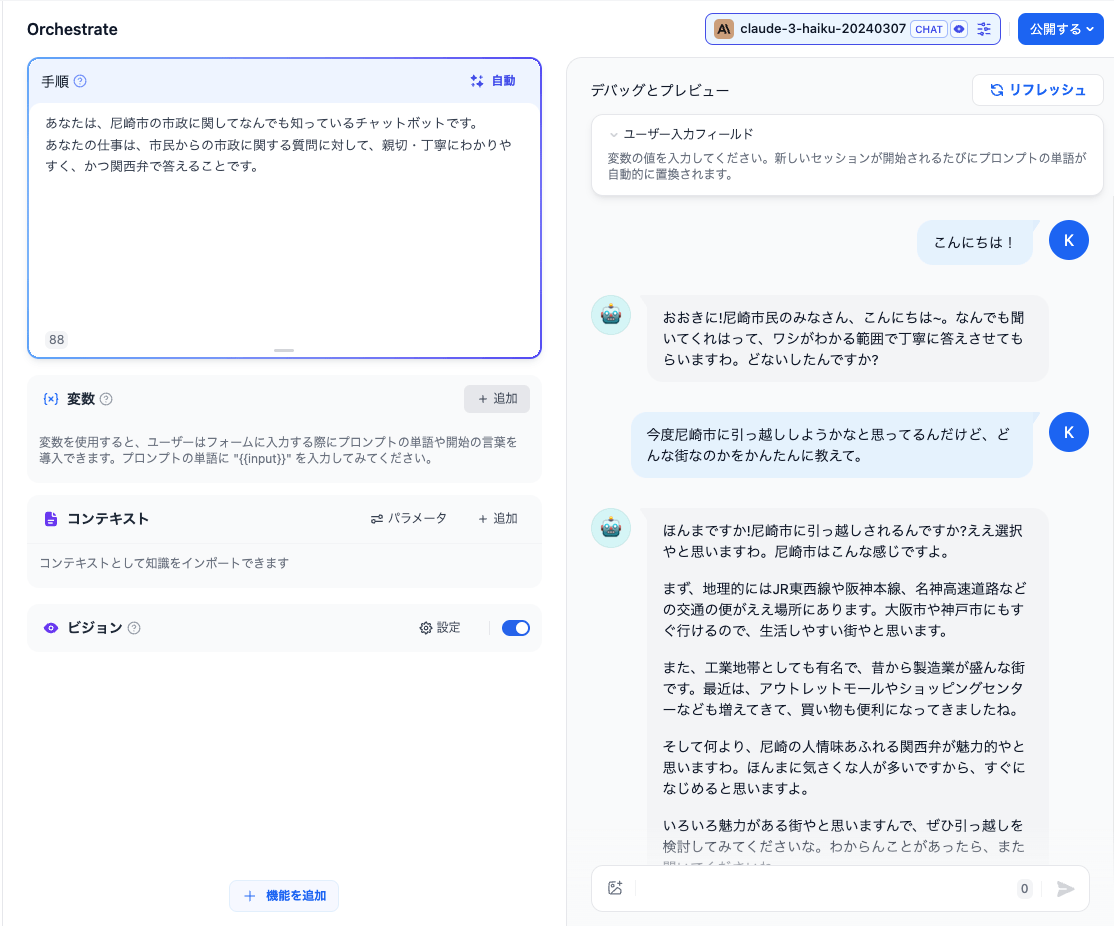
こんな感じで、プロンプトにもとづいて会話が行われており、会話履歴がコンテキストとして含まれているのもわかる。
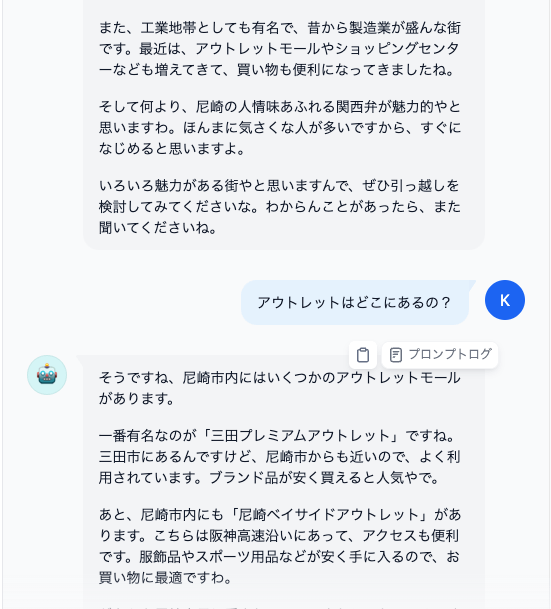
モデルの設定から別のモデルを追加で選んで、比較しながらチャットすることもできる。

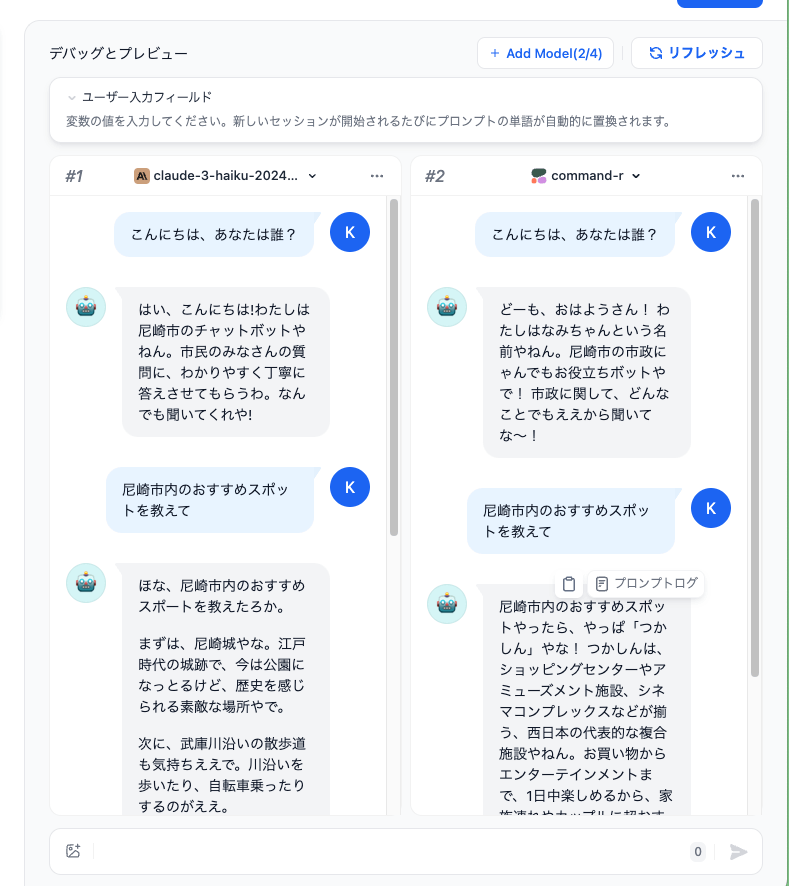
元に戻すときは、残したいモデルのほうで「単一モデルでデバッグ」にすればよい。

コンテキストの登録(RAG)
次にRAGに対応してみる。RAGのドキュメントなどは「コンテキスト」として登録して使う。今回は以下の尼崎市FAQを下にしたデータセットを使う。
でこのデータセットはテキスト形式で質問と回答が分かれているので、Colaboratoryで前処理としてExcelデータ化にした。手順は以下。
!wget https://tulip.kuee.kyoto-u.ac.jp/localgovfaq/localgovfaq.zip
!unzip localgovfaq.zip
import pandas as pd
def file2list(filename):
lines = []
ids = []
with open(filename, 'r') as file:
for line in file:
line = line.strip().replace(" ","")
id, line = line.split('\t')
lines.append(line)
ids.append(id)
return lines, ids
questions, ids = file2list("localgovfaq/qas/questions_in_Amagasaki.txt")
answers, _ = file2list("localgovfaq/qas/answers_in_Amagasaki.txt")
df = pd.DataFrame({'ID': ids, 'Question': questions, 'Answer': answers})
df["Context"] = "Q: " + df["Question"] + "\nA: " + df["Answer"]
df

df.to_excel('尼崎市FAQ.xlsx', sheet_name='FAQ')
Excelファイルが生成されるのでダウンロードして準備OK。
ではDify側で。
アプリ開発画面のコンテキストの「+追加」をクリック。
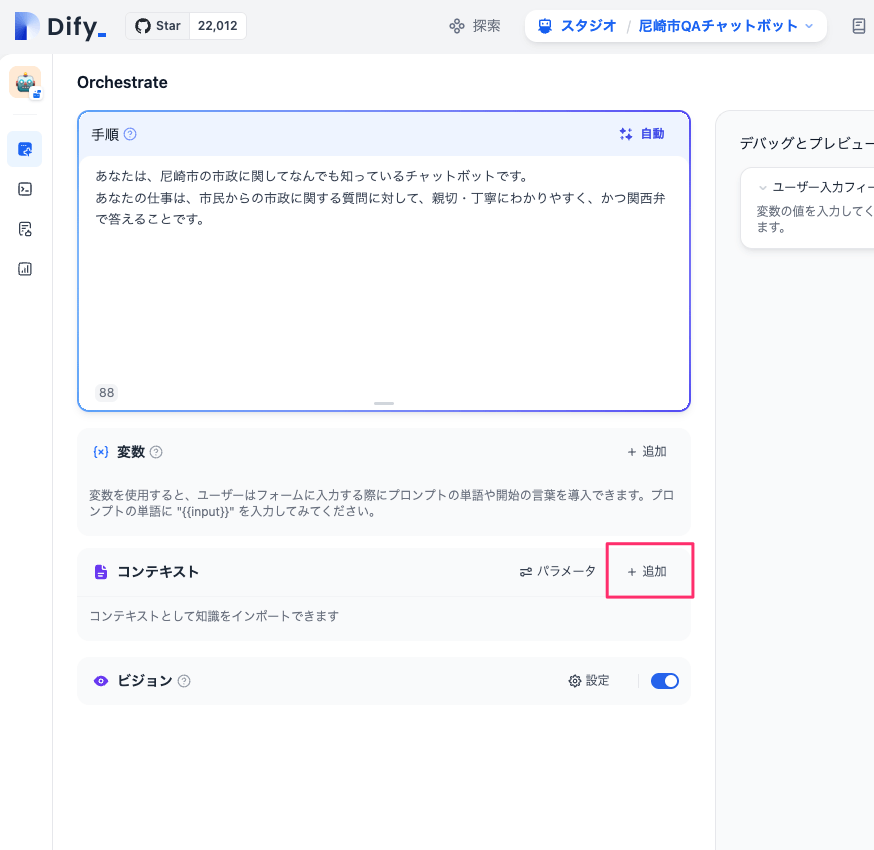
まだナレッジが1つも登録されていないので「作成に進む」をクリック。
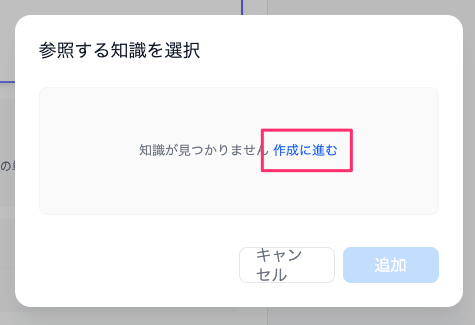
ファイルアップロードができる。テキストやMarkdown、PDF、Office系ファイルが取り込める模様。先ほど作成したExcelファイルをドラッグ&ドロップでアップロードする。
ファイルがアップロードされたら「次へ」
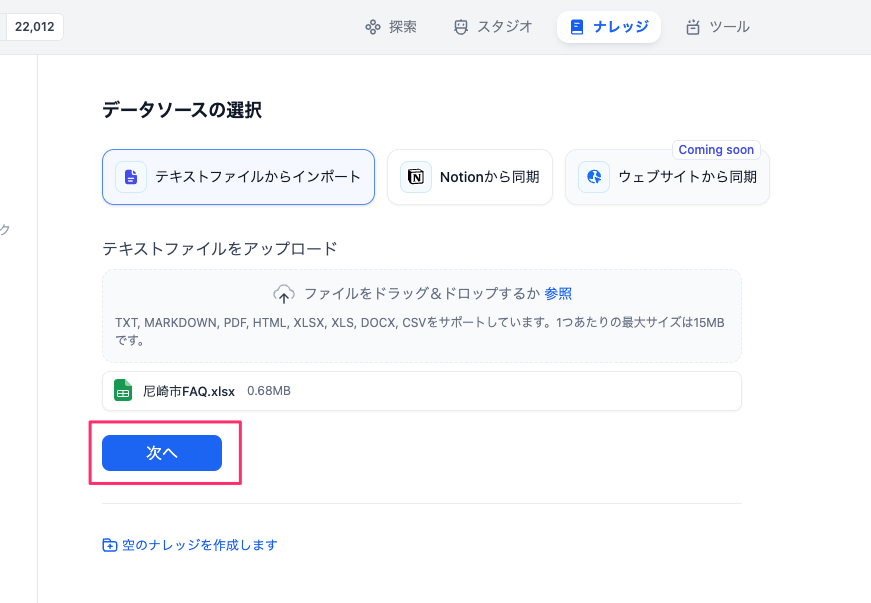
アップロードされたファイルをどう取り込むか?の設定を行う画面になる。右に取り込んだファイルの中身が見えているのがわかる。Excelみたいな非構造化データファイルでもある程度セルと言うか行に沿って取り込まれているような雰囲気はあるね。

ここの設定について少しだけ触れておく。
チャンク分割
「自動」と「カスタム」が選択できる。自動だとDifyが勝手にやってくれる。チャンク分割を細かく設定したい場合は「カスタム」をチョイス。「カスタム」だとこんな感じの項目になる。

今回は「自動」にする。
インデックスモード
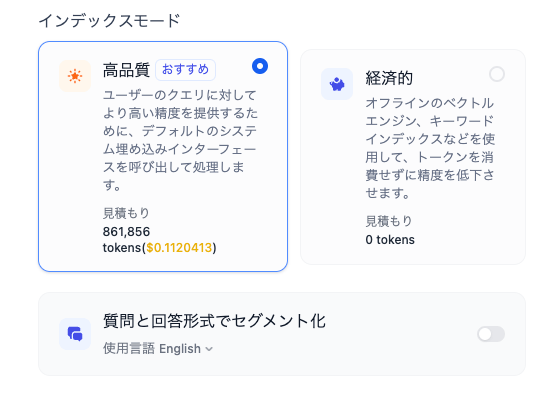
「高品質」はベクトル検索になるっぽい。よってEmbeddingsが生成されるので、多少なりともAPIコストが発生する(Embeddings APIのコストは安いけども)。
「経済的」ってのはちょっとよくわからないな、キーワード検索とかになるのかな?キーワード検索の場合は日本語トークナイザーに対応しているかどうか?ってのが重要になってくると思うのだけど、Difyのデフォルトのコンテキスト用DBはWeaviateが使われているようで、Weavaiteは確かにベクトル検索/キーワード検索/ハイブリッド検索の全てに対応している。ただ、Weaviateのバージョン(2024/4/17時点で1.19.0)見る限りは、日本語トークナイザー非対応のバージョンな気がする(日本語トークナイザー対応は1.24.0以降)。
いずれにせよ、チャットの自然言語クエリの場合はベクトル検索のほうが一般的にはそれなりの精度が出るとは思う。今回は「高品質」を選択。
なお、「質問と回答形式でセグメント化」ってのは日本語に対応していないようなのでスキップ。
検索設定
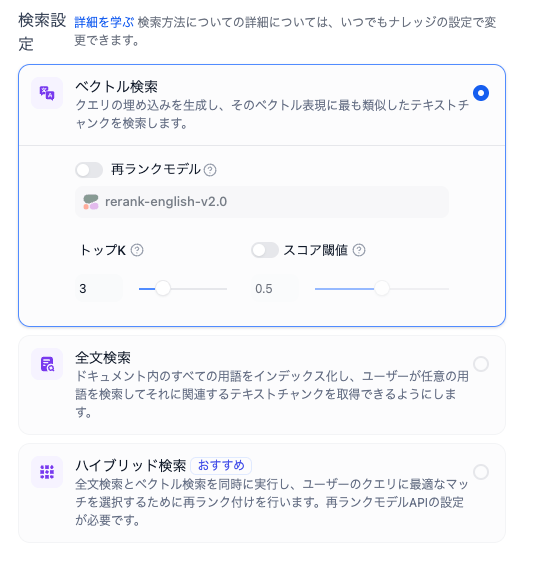
以下の3つから選べる。
- ベクトル検索
- 全文検索
- ハイブリッド検索
で、上にも書いた通り、全文検索とハイブリッド検索については、もしWeaviateでやっているのであれば、おそらく日本語だとうまく機能しないのではないかと推測している、試してないけど。もし試した人がいれば教えて欲しい。とりあえず今回はベクトル検索で進める。
ベクトル検索の場合の設定は以下の3つ。
- 再ランクモデル: ベクトル検索結果を再ランク対応モデルでランキングし直すかどうか。日本語の場合は実質Cohereのrerank-multilingual-v*一択になると思う。リランキングはベクトル検索で足りない精度を上げるのに効果があると個人的には思っているので有効にしたいところ。ただしうコストは発生する。とりあえず今回は設定しない。
- トップK: ベクトル検索結果の上位何件を抽出するか。モデルの入力コンテキストサイズとコンテキストのチャンクサイズから適宜設定すれば良い。今回はデフォルトのまま3にした。
- スコアしきい値: ベクトル検索で一定の類似度以下のものを足切りするような設定だと思う。今回は有効にしない。
全部設定したら「保存して処理」をクリック。
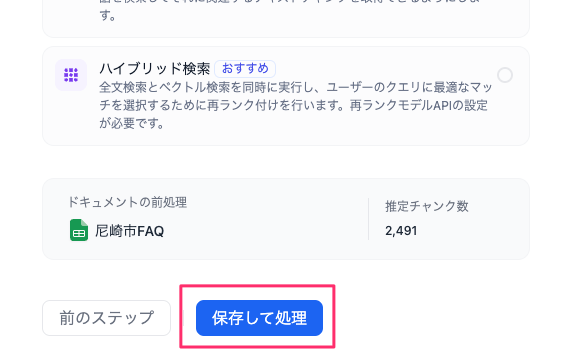
ナレッジが作成されて(というか「知識」とか「ナレッジ」とかは、用語を統一したほうがいいと思う)、ベクトル検索の場合はベクトル化処理がバックグラウンドで行われる。完了まで待つ必要はない気がするけど、そこまで確認していない。とりあえず「ドキュメントに移動」をクリック。
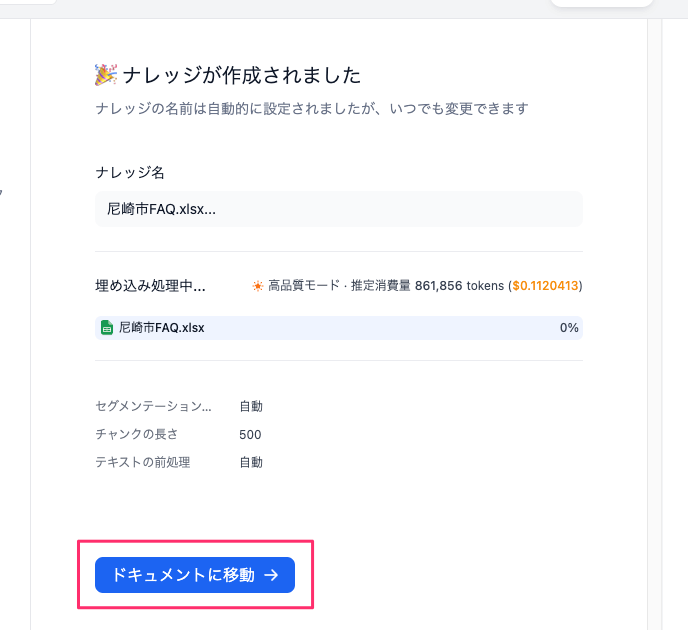
登録したナレッジとインデックス化(=ベクトル化)の一覧がここで確認できる。「スタジオ」をクリックして、アプリ開発の画面に戻る。
一覧画面から先ほど作成していたアプリをクリック。
戻ったのはいいのだけども、さっき入力したシステムプロンプトやモデルの設定がもとに戻っている・・・
うーん、「保存」みたいなメニューがないのだけど、どうすればいいのだろう。途中で画面繊維が行われちゃうとちょっとだけ辛い。とりあえず、プロンプトとモデルは再度設定しつつ、再度コンテキストの追加をクリック。
登録したナレッジが表示されるので、選択して追加。
ナレッジがコンテキストとして追加された状態で、チャットしてみる。
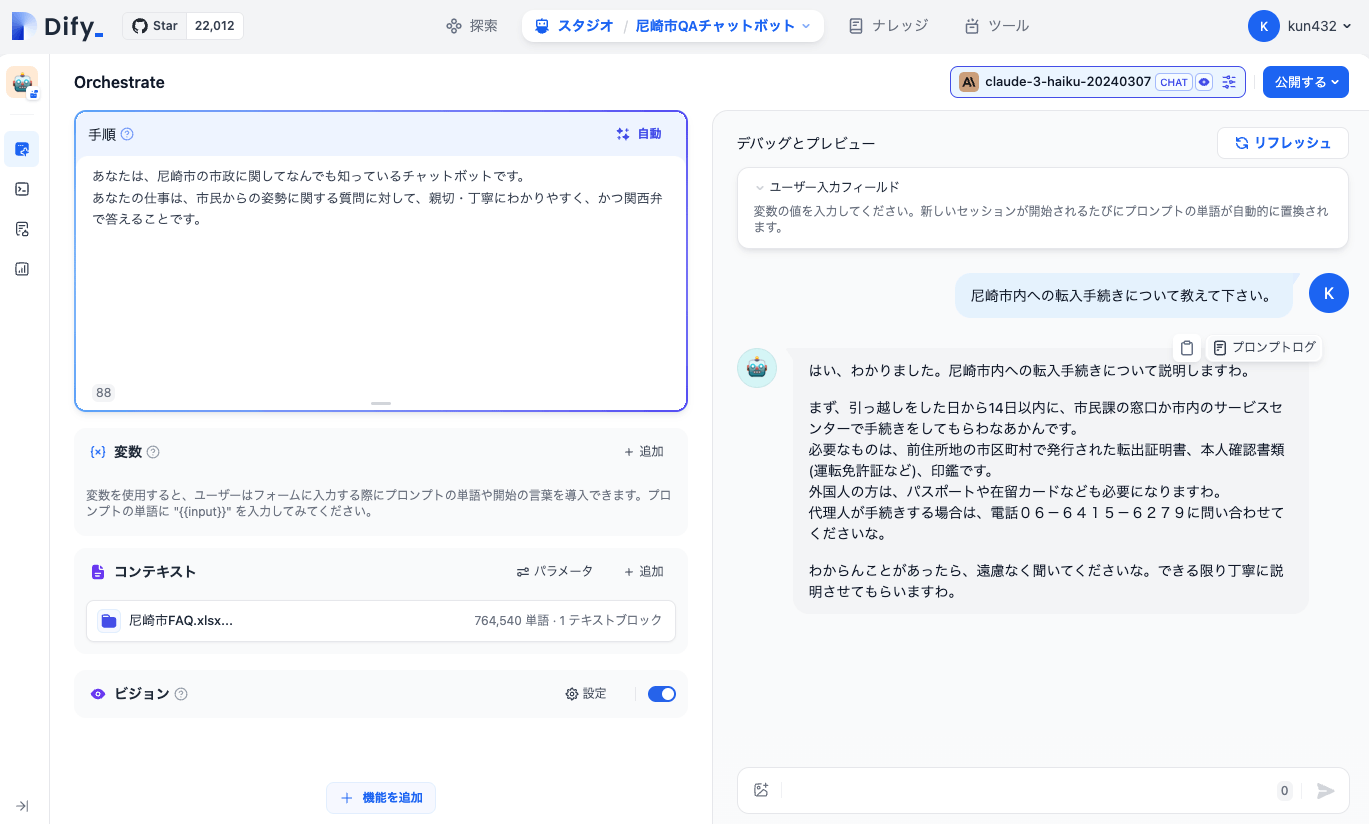
なんかそれっぽいことを言っている。回答にカーソルを合わせると「プロンプトログ」というのが表示されるのでこれをクリックしてみると・・・

このあたりの情報から回答が生成されているのがわかる。
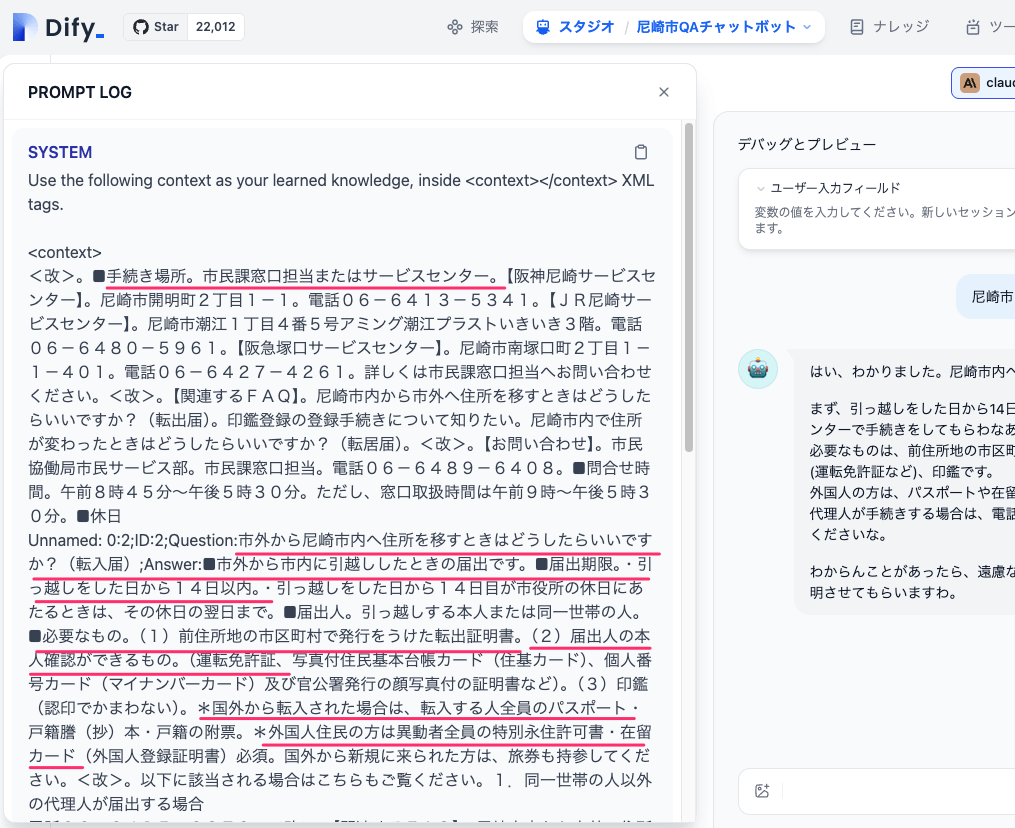
実際のデータセットに入っているのは多分この辺
Q: 市外から尼崎市内へ住所を移すときはどうしたらいいですか?(転入届)
A: ■市外から市内に引越ししたときの届出です。■届出期限。・引っ越しをした日から14日以内。・引っ越しをした日から14日目が市役所の休日にあたるときは、その休日の翌日まで。■届出人。引っ越しする本人または同一世帯の人。■必要なもの。(1)前住所地の市区町村で発行をうけた転出証明書。(2)届出人の本人確認ができるもの。(運転免許証、写真付住民基本台帳カード(住基カード)、個人番号カード(マイナンバーカード)及び官公署発行の顔写真付の証明書など)。(3)印鑑(認印でかまわない)。*国外から転入された場合は、転入する人全員のパスポート・戸籍謄(抄)本・戸籍の附票。*外国人住民の方は異動者全員の特別永住許可書・在留カード(外国人登録証明書)必須。国外から新規に来られた方は、旅券も持参してください。<改>。以下に該当される場合はこちらもご覧ください。1.同一世帯の人以外の代理人が届出する場合。2.住民基本台帳カード(住基カード)、個人番号カード(マイナンバーカード)を持っている人が転入される場合(転入届の特例の場合)。<改>。【関連するFAQ】。【乳幼児等医療費助成制度(乳児医療)】対象者・所得制限について知りたい。市外から転居してきたのですが、犬の登録(住所)変更の手続について知りたい。印鑑登録の新規登録、変更登録、廃止登録などの手続きはどんなときに必要ですか。市外から尼崎市に引っ越したのですが、介護保険の手続きについて教えてほしい。後期高齢者医療被保険者が市外から尼崎市へ転入しますが、何か手続きは必要ですか。
RAGとして機能していることがわかる。
API公開
作成したアプリは公開することができる。右上の「公開」をクリック。
んー、どうもこの「更新」というのが保存に近いのかも。というのはすでに作成時点で「公開済み」となっているように読めるので。非公開状態ってのは基本的に存在しないってことなのかな?とりま「更新」をクリック。
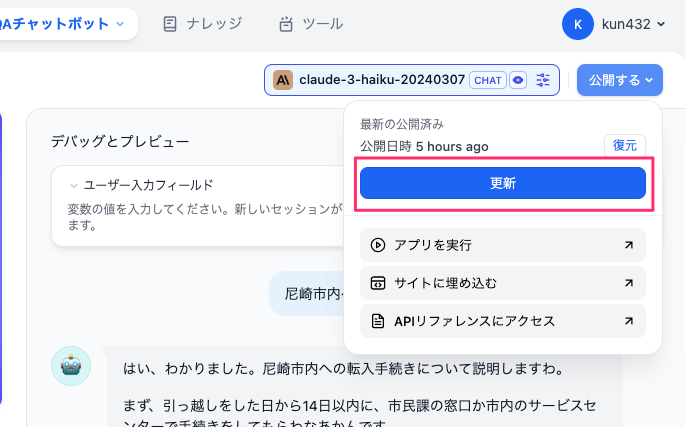
「公開済み」となってグレーアウトになった。で、選択肢が下に3つ用意されている。
- アプリを実行: ChatGPTライクなWebアプリにアクセスする
- サイトに埋め込む: ウェブサイト等に埋め込むためのHTML/JSのスニペットが生成される。あとChrome拡張もあるみたい。
- APIリファレンスにアクセス: アプリにアクセスするためのAPIのリファレンスページが表示される
順に軽く見ていく。
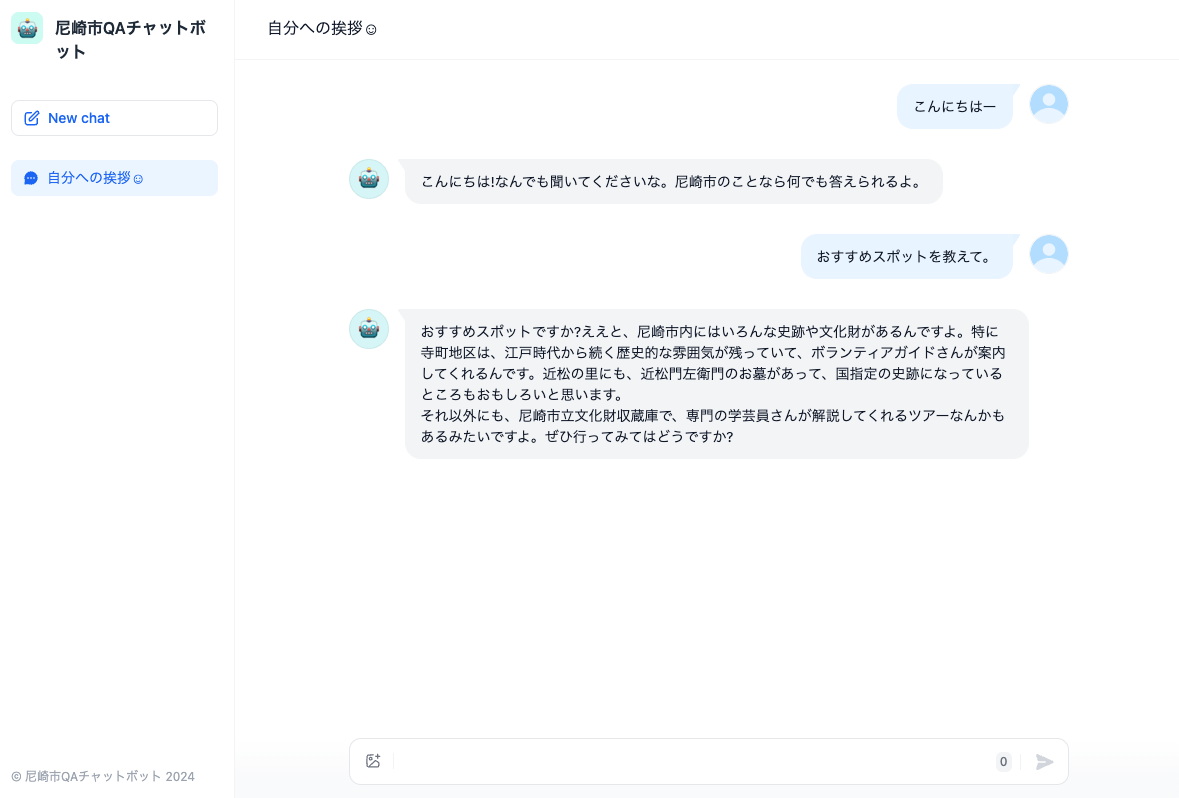
アプリを実行
Webアプリでチャットができる。左のメニューを見る限り、ChatGPTっぽい感じがするのだけど、ユーザの識別とかどうなってるんだろうか?とりまRAGとしては機能していた。

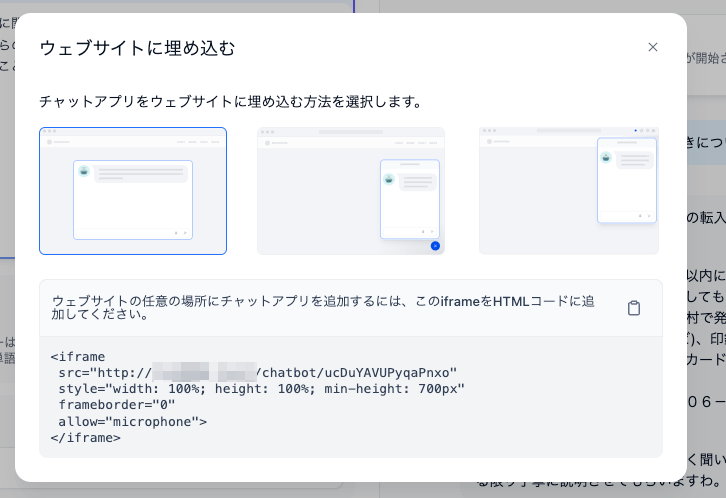
サイトに埋め込む
Webサイトに埋め込むためのスニペットがHTMLとJSで発行される。
面白いのはChrome拡張としてインストールしてアクセスができるらしい。
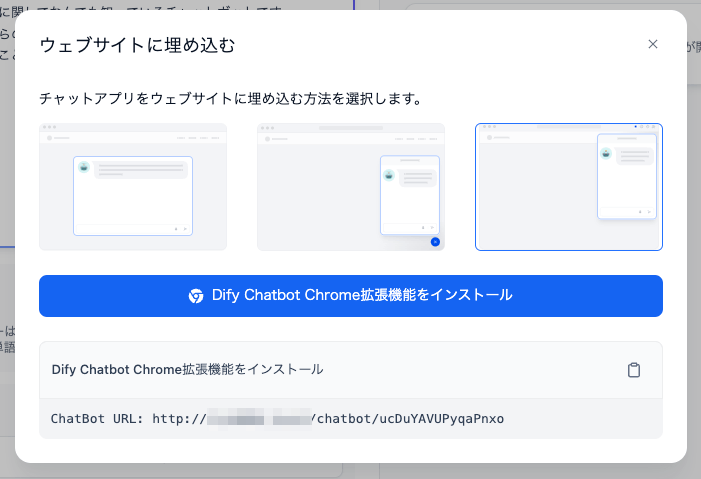
拡張のページはこれ
APIリファレンスにアクセス
作成したアプリに対してAPIでアクセスできる。APIアクセスにはAPIキーが必要になるっぽい。右上の「APIキー」をクリック。
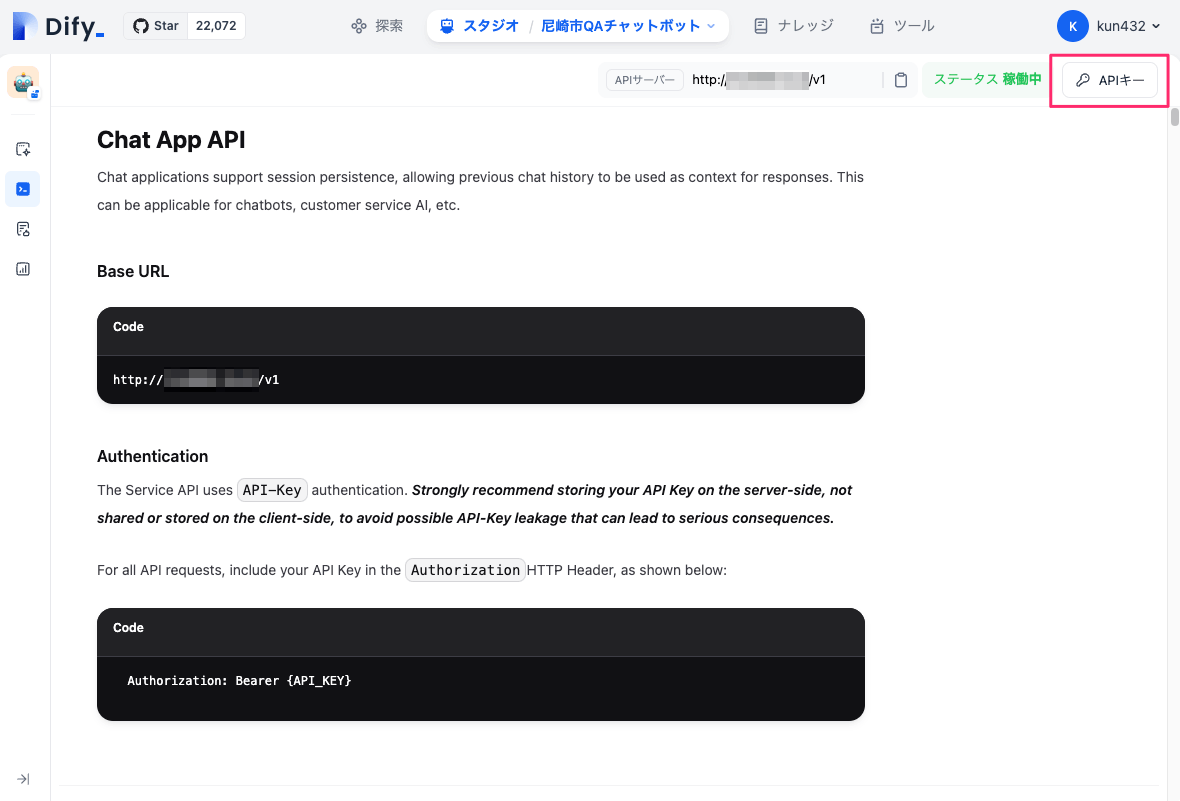
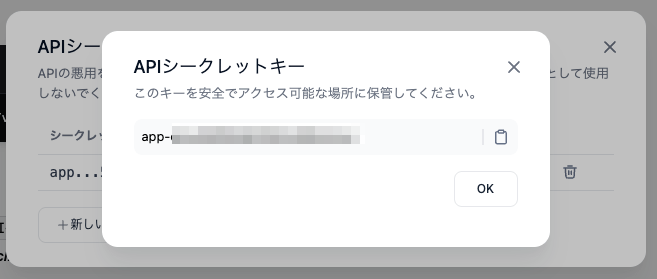
画面に従ってAPIキーを発行。APIキーはこのタイミングでしか表示されない、わからなくなったら再発行になる。
ではcurlを使ってAPIにアクセスしてみる。APIリファレンスだと画像とかも送れるみたいだけど、とりあえずミニマムだとこれぐらいかな?
$ curl -X POST 'http://X.X.X.X/v1/chat-messages' \
--header 'Authorization: Bearer XXXXXXXXXX' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs":{},
"query":"こんにちはー!",
"response_mode": "blocking",
"conversation_id": "",
"user": "001"
}'
{
"event": "message",
"task_id": "ba13654f-a6e7-4a00-8c68-73a6939c8623",
"id": "b67da0d1-52bb-4e3d-8f00-7fad044ea9cb",
"message_id": "b67da0d1-52bb-4e3d-8f00-7fad044ea9cb",
"conversation_id": "1f379848-7273-4d2f-889e-737ad03fd187",
"mode": "chat",
"answer": "こんにちは!どうしましたん?何か聞きたいことがあるんですか?",
"metadata": {
"usage": {
"prompt_tokens": 410,
"prompt_unit_price": "0.25",
"prompt_price_unit": "0.000001",
"prompt_price": "0.0001025",
"completion_tokens": 31,
"completion_unit_price": "1.25",
"completion_price_unit": "0.000001",
"completion_price": "0.0000388",
"total_tokens": 441,
"total_price": "0.0001413",
"currency": "USD",
"latency": 1.4707576418295503
}
},
"created_at": 1713336252
}
こんな感じでレスポンスが返ってくる。
で、調べてみた限り、APIのベースURLは複数アプリの場合でも共通っぽくて、どうやらAPIキーでどのアプリにアクセスしているかを振り分けているっぽい。
APIは他にも機能があるので色々見てみると良さそう。
ダッシュボード
アプリの利用度やログなどが確認できる。

これ以外にも面白そうな機能がたくさんある
- 変数を使ったプロンプトテンプレート
- フォームからターゲット・目的を入力して、システムプロンプトをAIに生成させる
- 公開されているテンプレートからのアプリ作成
- 各種ツール連携(googleやwikipedia等の検索やデータ読み込み)
- OpenAPIスキーマでカスタムツール作成やPython/JSでのコードブロック作成が可能
- アプリをDSLでエクスポート・インポート
- GitHub/GoogleアカウントでのOAuth
- RAGのCitationsとかツールチップとかコンテンツモデレーションとか
かなり機能は豊富なので、色々試してみると良い。
ドキュメントに以下とある。
the ultimate goal of Dify is to cover more than 80% of typical LLM application scenarios.
ノーコードやローコードのソリューションは以前いろいろやっていたのだけど、できることの限界は当然ながらある。ただ、細かい作り込みがどれだけのケースで必要か?というところは確かにあるし、上にある通り、多くの一般的なユースケースを満たせるだけどの豊富な機能が揃っているように思える。
実際にやるにあたってはそれなりに整理は必要かなと思いつつ、自分が事前に想像していたより、かなりよく出来てるのではないかと感じた。ちょっと真面目に検討してみたい気になっている。
他の機能なんかも少し触ってみようと思う。
Difyをどっかに建てた場合のコストを少し考えてみた。ちなみに公式ドキュメントには2CPU・4GBメモリとあるのでそれを基準に。
- Dify Cloud (Professional): $59/月
- 5000メッセージ/月
- モデル: OpenAI/Anthropic/Llama2/Azure OpenAI/Hugging Face/Replicate
- チームメンバー数: 3
- アプリ数: 50
- ベクトルDBストレージ: 200MB
- カスタムツール: 10
- 所感:
- メッセージ数はわからないけど、あまり多くない気がする
- ちょっとベクトルDBのストレージ小さくないかな?ベクトルDB結構食うような気がしてるのだけども。
- スペックには載ってないけども、CohereでReranking使えないのかな?それはちょっと痛い
- Dify Premium (AWS Marketplace): 約$294.48/月(≒$0.409/時間)
- 東京リージョン・t3.large(2コア・8GBメモリ)の場合
- これ以外にも帯域コストとかもかかってくる
- 制約とかはなさそう
- 所感:
- 楽だけどちょっと高いね。。。
- EC2: $78.48/月(≒$0.109)
- EC2単体でDifyはセルフホスト
- 東京リージョン・t3.large(2コア・8GBメモリ)の場合
- これ以外にも帯域コストとかもかかってくる
- 制約とかはなさそう
- 所感:
- 運用がね・・・・
- コンポーネントをマネージドに切り出してというやり方もできなくはないけども。
- VPS: 約$20〜30/月
- このあたりを参考に
- 大体3000円台ってところ。
- 海外だとそこそこサービスや機能が豊富なイメージ、国産VPSってもう長らく使ってないのだけど、色々機能追加していくと結局高くなるっていうイメージがある
- 所感:
- コストだけ考えるならこれ一択になりそう。
- 運用がね・・・
あとは、ECS(Fargate)とかもあるけど、うーん、イニシャルで考えるならばVPS一択かなぁ。個人的にはもうEC2とかやりたくないのよね。というかAWS使うとなると周辺も色々考えないといけなくなるので。で、どうせTerraformとか使うんだけど、それならIaC管理できるVPSで運用コスト以下に下げれるか、みたいなほうがいいかなぁ。
Difyを真面目にどっかにホストしたとして、万が一の場合に備えて中のデータをどうすればいいか?を考えてみた。
- docker-composeで作成されるコンテナは8個
- nginx: リバースプロキシ
- api: APIエンドポイント
- web: GUI(管理用とWebチャットボットの両方だと思う、多分)
- db: 管理用DB
- PostgreSQLを使用
- redis: キャッシュ
- weaviate: ベクトルDB
- weaviate以外に、Qdrant/Milvus/Relytに対応
- sandbox: コード実行環境
- worker: ジョブキュー
この中で永続データを持っているのは以下の3つ
- api
- ナレッジベースで使用するドキュメントを保存している
- デフォルトはローカルディスク、S3/Azure Blob/Google Cloud Storageもオプションで選べる
- ドキュメントを都度読んでいるのか、ベクトル化済ドキュメントの単なる保管場所なのかは未確認
- db:
- あらゆるデータの管理はPostgreSQL
- 当然DBデータを持っている
- weaviate(ベクトルDB):
- デフォルトがweaviateなだけで、Qdrant/Milvus/Relytに変更可能
- ベクトル化したデータを保持している
最悪この3つだけ、コンポーネントを外部に出す、コンポーネント内の永続ストレージを外部に出す、バックアップを取る、ができたら、その他はいつ死んでも復旧できるような気がする。
ベクトルDBのバックアップ/レストア
Weaviate/Qdrant/Milvusは標準でバックアップ機能を有している模様。
Weaviateについては以下で試した。
DifyにはベクトルDBのマイグレーション用ツールがあるようだけど、単純なバックアップには使えないみたい。
ただコードを見た感じ、ベクトルDBに登録するチャンクはデータベース内にも持ってるっぽい雰囲気がある。もしかするとベクトルDBはいちいちバックアップを取らなくても良い可能性があるかもしれない。ただし直接的なインタフェースは見当たらないので、トリッキーにはなりそう。素直にバックアップを設定しておくのが良さそう。
DBのバックアップ・レストア
DBはPostgreSQLなので、pg_dumpでダンプ、psqlでレストアすればよさそう。
いっそSupabaseとかを使うほうがよいかもしれない。RDSでもいいけど、その場合はVPCが必要になると思う。
20240501追記
Supabaseの無料枠で作ったり削除してたりしたらどうやらクォータに引っかかったらしい。どうやら一定期間内での利用状況みたいなものがあるっぽい。詳しくは調べていないけど、有料プランのほうが当然確実ではある。$25/月だし、DB以外の機能も含めて考えると、まあ払ってもいいかなーとは思える。
とりあえずLightsailで運用してみようかと思う。Lightsail初だったのでどういうものかも含めてざっと調べた。
ざっと見てみた限り、ユーザを追加したい場合、管理画面からはメールアドレスを入力して招待するという形式になっているようで、どうやらメールの送信環境が必須な感がある。
メール送信環境を色々準備するのは結構手間なのでResendを使うのが良さそう。
Resendについてはこの記事が詳しかった。
Difyで使うだけなら全部を把握する必要はない。
- APIキーを発行
- (必要なら)ドメインを設定
するだけで良さそうである。