PostgreSQLでのベクトル管理をシンプルにできる拡張「pgai」を試す
ここで見かけた
ベクターデータベースは誤った抽象概念です。より良い方法をご紹介します:新しいオープンソースのPostgreSQLツール「pgai Vectorizer」です。これにより、埋め込みがデータベースインデックスと同じように、自動的に作成・同期されます。
❌ ベクターデータベースが失敗する理由
ベクターデータベースは、埋め込みをそれを生成した元データと切り離された独立したデータとして扱っていますが、実際には派生データです。この問題により、多くのAIプロジェクトがシンプルなベクター検索の実装から始めたものの、最終的には複雑な監視、同期、修正のオーケストラに進化してしまいます。
😓 埋め込みを同期させ続けるのは難しい
埋め込みの古さを避けるため、エンジニアチームはETLパイプラインの構築と維持、複数のデータベース(ベクターデータベース、メタデータストア、レキシカル検索)を駆使し、更新のための複雑なキューシステムを管理する必要があります。データドリフトの監視、古い結果に対するアラートシステム、システム全体でのバリデーションチェックも追加する必要があり、最終的には壊れやすいインフラが出来上がり、古い埋め込みとエンジニアの労力の浪費を招きます。
Postgresを使うだけで済むとしたらどうでしょう?
✅ Pgai Vectorizer:埋め込みをデータベースインデックスとして扱う
Pgai Vectorizerは埋め込みをデータベースインデックスのように扱い、データが変わるたびに自動で作成、更新、維持します。インデックスと同様に、データベースがすべての複雑さを処理し、同期、バージョン管理、クリーンアップが自動的に行われます。これにより、手動追跡やメンテナンスの負担がなくなり、新しいパイプラインを構築することなく、異なる埋め込みモデルやチャンク戦略を迅速に試す自由が得られます。
🤔 なぜpgai Vectorizerを開発したのか?
私たちのチーム@timescaledbは、PostgreSQLがベクターからテキストデータ、JSONドキュメントまで何でも扱える「万能のデータベース」として、多くの開発者に評価されているため、pgai Vectorizerを開発しました。複数のデータベース管理の悩みを解消し、PostgreSQLのような「何でもできるデータベース」をベクトライザーとAIアプリケーションの基盤とするのが最適と考えています。
⚙️Pgai Vectorizerはどのように機能するのか?
以下のコードスニペットをご覧ください。pgai Vectorizerを使えば、たった6行のSQLで埋め込み作成パイプラインを自動化できます!pgai Vectorizerは、ソーステーブルの変更(挿入、更新、削除)を確認し、外部ワーカーで非同期にベクトル埋め込みを作成・更新します。
🧑💻 興味がありますか?始めるには?
pgai VectorizerはPostgreSQLライセンスの下でオープンソースで提供されており、無料で使用可能です。pgaiのGitHubリポジトリでインストール方法を確認できます(投稿の最後をご覧ください)。また、TimescaleのPostgreSQLクラウドプラットフォームの管理サービスとしても利用可能です。📚 詳細を知る
[1] Pgai GitHubリポジトリ: https://github.com/timescale/pgai
[2] 技術解説ポスト: https://timescale.com/blog/vector-databases-are-the-wrong-abstraction/この投稿をシェアして、pgai Vectorizerについてフォロワーに知らせ、感想や質問をコメントしてください。
GitHubレポジトリ
pgai
pgaiは、PostgreSQL内でRAG(Retrieval Augmented Generation)、セマンティック検索、その他のAIアプリケーションを直接開発できるようにするツールです。
pgaiは、PostgreSQLでの検索やRAG(検索拡張生成)、その他のAIアプリケーションの構築プロセスを簡素化します。pgvectorやpgvectorscaleなど、PostgreSQLのベクトル検索向け拡張機能の能力を活かして機能を提供します。
概要
pgaiの目的は、AIとの連携をより簡単で使いやすくすることです。データはほとんどのAIアプリケーションの基盤であるため、pgaiはAIワークフローでデータを活用しやすくします。特に、pgaiは以下のサポートを提供しています:
データから生成された埋め込み(エンベディング)の活用:
- データのベクトル埋め込みを自動的に作成し、同期します(詳細はこちら)
- ベクトル検索やセマンティック検索を使用してデータを検索します(詳細はこちら)
- 単一のSQLステートメント内でRAGを実装します(詳細はこちら)
- pgvectorを補完するpgvectorscaleを使用して、大規模なベクトルワークロードで高性能かつコスト効率の良いANN(近似最近傍)検索を実行します。
LLM(大規模言語モデル)を用いたデータ処理タスクの活用:
- Claude Sonnet 3.5、OpenAI GPT4o、Cohere Command、Llama 3(Ollama経由)などのモデルからLLMのチャット補完を取得します(詳細はこちら)
- データに基づいて推論を行い、分類や要約、データの強化など、既存のPostgreSQLリレーショナルデータに対するユースケースを支援します(例を参照)
pgaiについて詳しく知る: pgai拡張機能とその開発背景について詳しく知るには、「pgai: PostgreSQL開発者にAIエンジニアリングの力を与える」をお読みください。
コントリビューション: pgaiへの貢献は歓迎されています!詳細はコントリビューションページをご覧ください。
デモ: pgai Vectorizer
PostgreSQL+pgvectorをより使いやすくするためのPostgreSQL拡張って感じかな。
セットアップ
Getting Startedを見ると、pgaiは2つの方法で利用できる様子。
- PostgreSQL+時系列DBのクラウドサービスである「TimescaleDB」上で使う
- セルフホストで使う
- Docker
- ソースからインストール
今回はMac上のDockerで。ビルド済コンテナが用意されているので、それを使ってみる。
docker run --rm -d \
--name timescaledb-test \
-p 5432:5432 \
-e POSTGRES_PASSWORD=password \
timescale/timescaledb-ha:pg16
コンテナに入る
docker exec -ti timescaledb-test bash
psqlで接続
psql -U postgres
psql (16.4 (Ubuntu 16.4-1.pgdg22.04+2))
Type "help" for help.
postgres=#
拡張を確認
\dx
List of installed extensions
Name | Version | Schema | Description
---------------------+---------+------------+---------------------------------------------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
timescaledb | 2.17.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)
timescaledb_toolkit | 1.18.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
(3 rows)
pgai拡張を有効にする
データベースを作成
CREATE DATABASE pgai_test;
作成したデータベースに切り替え
\c pgai_test;
現在有効になっている拡張を確認
\dx
List of installed extensions
Name | Version | Schema | Description
---------------------+---------+------------+---------------------------------------------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
timescaledb | 2.17.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)
timescaledb_toolkit | 1.18.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
(3 rows)
これらはtemplate1で有効になっているもの。
では、pgaiを有効化
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
NOTICE: installing required extension "vector"
NOTICE: installing required extension "plpython3u"
CREATE EXTENSION
再度確認
\dx
List of installed extensions
Name | Version | Schema | Description
---------------------+---------+------------+---------------------------------------------------------------------------------------
ai | 0.4.0 | ai | helper functions for ai workflows
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
plpython3u | 1.0 | pg_catalog | PL/Python3U untrusted procedural language
timescaledb | 2.17.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)
timescaledb_toolkit | 1.18.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
vector | 0.7.4 | public | vector data type and ivfflat and hnsw access methods
(6 rows)
pgvector、plpython3u、そしてpgaiの拡張が有効化された。
LLMとの接続
pgaiはLLMとインテグレーションして使用するため、LLMプロバイダごとの設定が必要になる。
READMEでは、OpenAI、Anthropic、CohereのプロプライエタリLLMプロバイダとOllamaの設定手順がある。今回はOpenAIで進める。
psqlで使う場合
コンテナに入る。
docker exec -ti timescaledb-test bash
pgaiからOpenAI APIに接続するにはAPIキーをpgaiに渡す必要がある。APIキーの渡し方は複数の方法がある。
- セッションパラメータとして暗黙的にセット
- pgaiの関数の引数として明示的にセット
まず、最初の方法。OpenAI APIキーを環境変数にセットする。
export OPENAI_API_KEY="XXXXXXXXXXXX"
PGOPTIONSでai.openai_api_keyにAPIキーをセットして、psqlで接続。
PGOPTIONS="-c ai.openai_api_key=$OPENAI_API_KEY" psql -U postgres pgai_test
以下のようにSELECTすると、モデル一覧が取得できる。
SELECT *
FROM ai.openai_list_models()
ORDER BY created DESC
;
id | created | owned_by
-----------------------------------------+------------------------+-------------------------------
gpt-4o-realtime-preview | 2024-09-30 01:33:18+00 | system
gpt-4o-audio-preview | 2024-09-27 18:07:23+00 | system
gpt-4o-audio-preview-2024-10-01 | 2024-09-26 22:17:22+00 | system
gpt-4o-realtime-preview-2024-10-01 | 2024-09-23 22:49:26+00 | system
o1-mini | 2024-09-06 18:56:48+00 | system
o1-mini-2024-09-12 | 2024-09-06 18:56:19+00 | system
o1-preview | 2024-09-06 18:54:57+00 | system
o1-preview-2024-09-12 | 2024-09-06 18:54:25+00 | system
chatgpt-4o-latest | 2024-08-13 02:12:11+00 | system
gpt-4o-2024-08-06 | 2024-08-04 23:38:39+00 | system
gpt-4o-mini | 2024-07-16 23:32:21+00 | system
gpt-4o-mini-2024-07-18 | 2024-07-16 23:31:57+00 | system
gpt-4o-2024-05-13 | 2024-05-10 19:08:52+00 | system
gpt-4o | 2024-05-10 18:50:49+00 | system
gpt-4-turbo-2024-04-09 | 2024-04-08 18:41:17+00 | system
gpt-4-turbo | 2024-04-05 23:57:21+00 | system
gpt-3.5-turbo-0125 | 2024-01-23 22:19:18+00 | system
gpt-4-turbo-preview | 2024-01-23 19:22:57+00 | system
gpt-4-0125-preview | 2024-01-23 19:20:12+00 | system
text-embedding-3-large | 2024-01-22 19:53:00+00 | system
text-embedding-3-small | 2024-01-22 18:43:17+00 | system
tts-1-hd-1106 | 2023-11-03 23:18:53+00 | system
tts-1-1106 | 2023-11-03 23:14:01+00 | system
tts-1-hd | 2023-11-03 21:13:35+00 | system
gpt-3.5-turbo-1106 | 2023-11-02 21:15:48+00 | system
gpt-4-1106-preview | 2023-11-02 20:33:26+00 | system
dall-e-2 | 2023-11-01 00:22:57+00 | system
dall-e-3 | 2023-10-31 20:46:29+00 | system
gpt-3.5-turbo-instruct-0914 | 2023-09-07 21:34:32+00 | system
gpt-3.5-turbo-instruct | 2023-08-24 18:23:47+00 | system
babbage-002 | 2023-08-21 16:16:55+00 | system
davinci-002 | 2023-08-21 16:11:41+00 | system
gpt-4 | 2023-06-27 16:13:31+00 | openai
gpt-4-0613 | 2023-06-12 16:54:56+00 | openai
gpt-3.5-turbo-0613 | 2023-06-12 16:30:34+00 | openai
gpt-3.5-turbo-16k-0613 | 2023-05-30 19:17:27+00 | openai
gpt-3.5-turbo-16k | 2023-05-10 22:35:02+00 | openai-internal
tts-1 | 2023-04-19 21:49:11+00 | openai-internal
davinci:ft-personal-2023-04-01-02-11-16 | 2023-04-01 02:11:16+00 | user-vb3bg1fna2vp9mvo4z9stiwe
gpt-3.5-turbo-0301 | 2023-03-01 05:52:43+00 | openai
gpt-3.5-turbo | 2023-02-28 18:56:42+00 | openai
whisper-1 | 2023-02-27 21:13:04+00 | openai-internal
text-embedding-ada-002 | 2022-12-16 19:01:39+00 | openai-internal
(43 rows)
もう一つの方法。
こちらもまず環境変数をセット。
export OPENAI_API_KEY="XXXXXXXXXXXX"
psqlの環境変数でAPIキーを渡して、データベースに接続。
psql -U postgres pgai_test -v openai_api_key=$OPENAI_API_KEY
もしくは、psqlで接続したあとに、メタコマンドgetenvでopenai_api_keyをセットすることもできる。
psql -U postgres pgai_test
\getenv openai_api_key XXXXXXXXXXXX
pgaiの関数を使用するSQL文でAPIキーを環境変数からバインドする。つまりクエリ単位でAPIキーをセットすることになる。
SELECT *
FROM ai.openai_list_models(api_key=>$1)
ORDER BY created DESC
\bind :openai_api_key
\g
結果は上と同じなので割愛。
また、こちらの場合でも、暗黙的なAPIキーの設定に切り替えることができる。
SELECT set_config('ai.openai_api_key', $1, false) IS NOT NULL
\bind :openai_api_key
\g
?column?
----------
t
(1 row)
SELECT *
FROM ai.openai_list_models()
ORDER BY created DESC
;
結果は上と同じなので割愛。
pgaiでLLMに接続できて何ができるのか?は後述。
Pythonで使う場合
psqlからLLMにアクセスできることは確認できたので、今度はPythonで。こちらがメインの使い方になるんだろうと思う。
Jupyterのコンテナを別に用意して、そこからpgaiが有効になったPostgreSQLコンテナに繋いで試してみる。
作業ディレクトリ作成
mkdir pgai-test && cd pgai-test
JupyterLabのコンテナを起動
docker run --rm \
-p 8888:8888 \
-u root \
-e GRANT_SUDO=yes \
-v .:/home/jovyan/work \
quay.io/jupyter/minimal-notebook:latest
ブラウザでアクセスして、以降はJupyterLab上の作業。
psycopg2のパッケージインストール
!pip install psycopg2-binary
OpenAI APIキーを変数にセット
import getpass
import os
OPENAI_API_KEY = getpass.getpass('OPENAI_API_KEY')
モデル一覧を取得
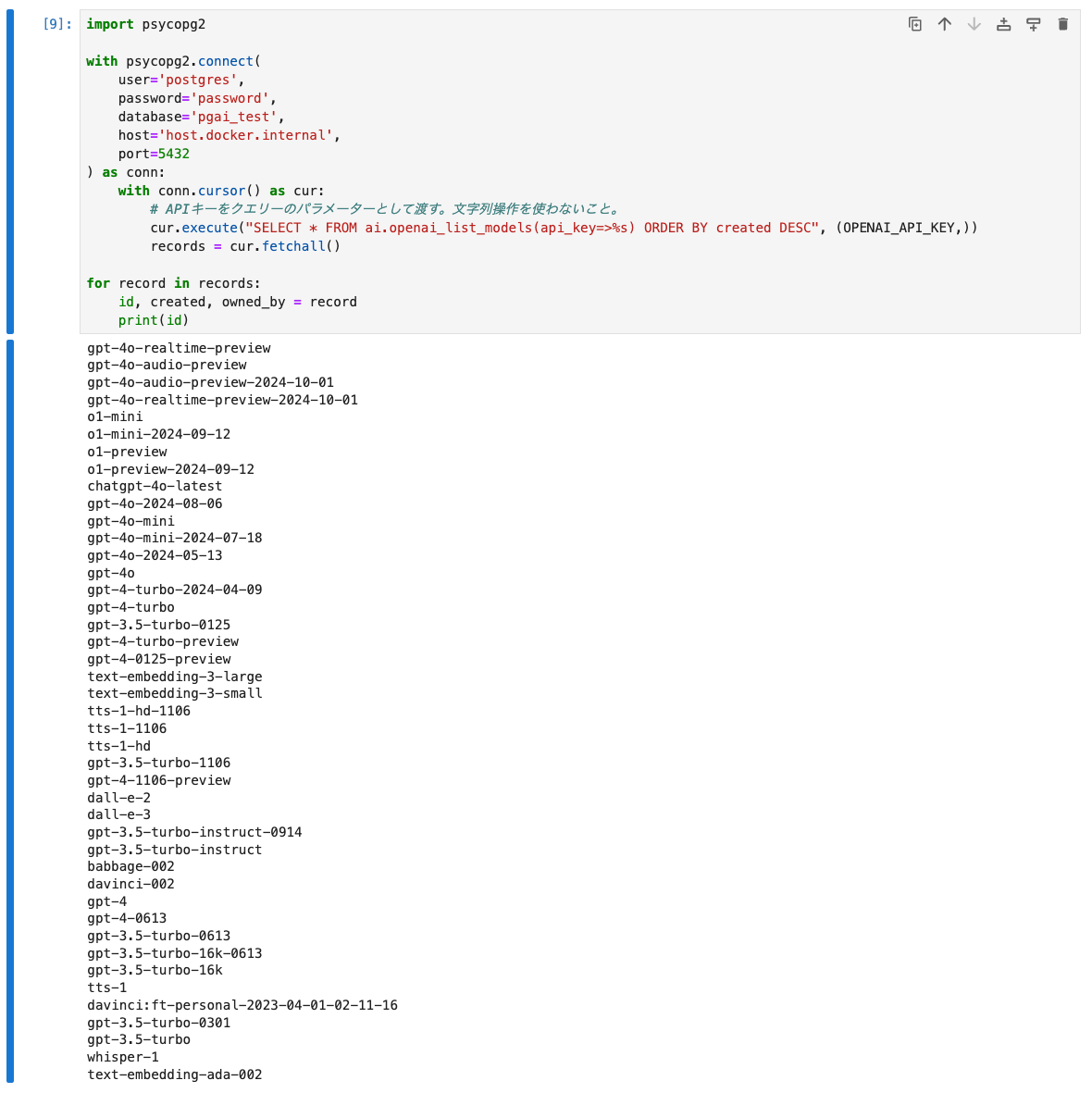
import psycopg2
with psycopg2.connect(
user='postgres',
password='password',
database='pgai_test',
host='host.docker.internal',
port=5432
) as conn:
with conn.cursor() as cur:
# APIキーをクエリーのパラメーターとして渡す。文字列操作を使わないこと。
cur.execute("SELECT * FROM ai.openai_list_models(api_key=>%s) ORDER BY created DESC", (OPENAI_API_KEY,))
records = cur.fetchall()
for record in records:
id, created, owned_by = record
print(id)
LLMを使った機能
pgaiでLLMを使ってできることを確認する。ただし、ここはLLMプロバイダに寄って異なる様子。OpenAIの場合は以下が記載されている。
- モデルの一覧
- テキストをトークンにエンコード・トークンからデコード
- 埋め込み生成
- テキスト生成
- モデレーション
モデルの一覧は上で既に試したので他のものを見てみる。
テキストをトークンにエンコード・トークンからデコード
テキストをトークンにエンコード。
import psycopg2
dsn = "user=postgres password=password dbname=pgai_test host=host.docker.internal port=5432"
sql = """
SELECT ai.openai_tokenize
( 'text-embedding-3-small'
, 'こんにちは。お元気ですか?'
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
result = cur.fetchall()
result
[([90115, 1811, 33334, 24186, 95221, 38641, 32149, 11571],)]
トークン数を確認
sql = """
SELECT array_length
( ai.openai_tokenize
( 'text-embedding-3-small'
, 'こんにちは。お元気ですか?'
)
, 1
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
result = cur.fetchall()
result
[(8,)]
トークンをテキストにデコード
sql = """
SELECT ai.openai_detokenize
('text-embedding-3-small'
, array[90115, 1811, 33334, 24186, 95221, 38641, 32149, 11571]
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
result = cur.fetchall()
result
[('こんにちは。お元気ですか?',)]
デコード・エンコードはapi_keyを指定する必要はない様子(指定するとエラーになる)
埋め込み生成
sql = """
SELECT ai.openai_embed
( 'text-embedding-3-small'
, 'こんにちは。お元気ですか?'
, api_key=>%s
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql, (OPENAI_API_KEY,))
result = cur.fetchall()
result
[('[0.044707533,-0.010570964,-0.0633885,0.044371948,0.07114427, (snip)
バッチで複数まとめて
sql = """
SELECT ai.openai_embed
( 'text-embedding-3-small'
, array['こんにちは。お元気ですか?','おやすみなさい。また明日']
, api_key=>%s
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql, (OPENAI_API_KEY,))
result = cur.fetchall()
result
[('(0,"[0.04468884,-0.010594497,-0.063361995,0.04431612,0.071151786,(snip)
('(1,"[0.045740254,-0.028213786,-0.049460754,-0.026681816,0.0015593269,(snip)
その他次元数の指定やユーザIDの定義なども可能
テキスト生成
import json
sql = """
SELECT jsonb_pretty
(
ai.openai_chat_complete
( 'gpt-4o-mini'
, jsonb_build_array
( jsonb_build_object('role', 'system', 'content', 'あなたは親切な日本語のアシスタントです。')
, jsonb_build_object('role', 'user', 'content', '7月の日本の典型的な気候はどんな感じ?')
)
, api_key=>%s
)
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql, (OPENAI_API_KEY,))
result = cur.fetchall()
print(json.dumps(json.loads(result[0][0]), indent=2, ensure_ascii=False))
{
"id": "chatcmpl-AP4UXmgFc02SjRxZ1lOfsBEzDcBdn",
"model": "gpt-4o-mini-2024-07-18",
"usage": {
"total_tokens": 313,
"prompt_tokens": 41,
"completion_tokens": 272,
"prompt_tokens_details": {
"cached_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0
}
},
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "7月の日本の気候は地域によって異なりますが、一般的には以下のような特徴があります。\n\n1. **高温多湿**: 7月は日本の多くの地域で気温が高く、湿度も高いです。特に関東地方や西日本では、35度以上の猛暑日があることも珍しくありません。\n\n2. **梅雨明け**: 7月の初めにはほとんどの地域で梅雨が明け、晴れの日が増えます。これにより、夏らしい気候になります。\n\n3. **台風の影響**: 7月は台風が発生しやすい時期でもあります。台風が接近すると、強風や大雨が予想されるため注意が必要です。\n\n4. **地域差**: 北海道は比較的涼しく、過ごしやすい気候ですが、南の沖縄地方は非常に高温多湿です。\n\n全体として、7月は日本の夏を体感できる時期であり、海水浴や花火大会などの夏のイベントが楽しめます。ただし、熱中症には十分注意が必要です。",
"refusal": null,
"tool_calls": null,
"function_call": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"created": 1730538829,
"system_fingerprint": "fp_0ba0d124f1"
}
コンテンツ部分だけを指定することもできる。
sql = """
SELECT ai.openai_chat_complete
( 'gpt-4o-mini'
, jsonb_build_array
( jsonb_build_object('role', 'system', 'content', 'あなたは親切な日本語のアシスタントです。')
, jsonb_build_object('role', 'user', 'content', '7月の日本の典型的な気候はどんな感じ?')
)
, api_key=>%s
)->'choices'->0->'message'->>'content';
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql, (OPENAI_API_KEY,))
result = cur.fetchall()
print(result)
[('7月の日本の典型的な気候は、地域によって異なりますが、一般的には以下のような特徴があります。\n\n1. **梅雨明け**: 日本の多くの地域では、7月の初め頃に梅雨が明けます。梅雨期間中の湿気が取れるため、晴れた日が増えます。\n\n2. **高温多湿**: 7月は夏真っ盛りで、気温が高くなる傾向があります。特に都市部では、35度以上の熱波が訪れることもあります。また、湿度が高いため、蒸し暑く感じることが多いです。\n\n3. **降水量の減少**: 梅雨が明けると、降水量は比較的少なくなり、晴れた日が続くことが一般的です。ただし、時折、短いスコールのような雨が降ることもあります。\n\n4. **台風シーズンの始まり**: 7月は台風シーズンの始まりでもありますので、特に沖縄や九州などの南部地域では、台風の影響を受けることがあります。\n\n地域によって具体的な気候は異なるため、例えば北海道は涼しく、沖縄は非常に暑いといった違いがありますが、全体としては夏らしい気候が感じられます。',)]
モデレーション
import psycopg2
import json
dsn = "user=postgres password=password dbname=pgai_test host=host.docker.internal port=5432"
sql = """
select jsonb_pretty
(
ai.openai_moderate
( 'text-moderation-stable'
, '死にたい。'
, api_key=>%s
)
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql, (OPENAI_API_KEY,))
result = cur.fetchall()
print(json.dumps(json.loads(result[0][0]), indent=2, ensure_ascii=False))
{
"id": "modr-AP4juLu8vRnmEogoanaDKd5FbuBso",
"model": "text-moderation-007",
"results": [
{
"flagged": true,
"categories": {
"hate": false,
"sexual": false,
"violence": false,
"self-harm": true,
"self_harm": true,
"harassment": false,
"sexual/minors": false,
"sexual_minors": false,
"hate/threatening": false,
"hate_threatening": false,
"self-harm/intent": true,
"self_harm_intent": true,
"violence/graphic": false,
"violence_graphic": false,
"harassment/threatening": false,
"harassment_threatening": false,
"self-harm/instructions": false,
"self_harm_instructions": false
},
"category_scores": {
"hate": 0.000548333628103137,
"sexual": 4.59224156657001e-06,
"violence": 0.0024716260377317667,
"self-harm": 0.8853654861450195,
"self_harm": 0.8853654861450195,
"harassment": 0.001076185959391296,
"sexual/minors": 1.6591489782058488e-07,
"sexual_minors": 1.6591489782058488e-07,
"hate/threatening": 7.044251105980948e-06,
"hate_threatening": 7.044251105980948e-06,
"self-harm/intent": 0.8645984530448914,
"self_harm_intent": 0.8645984530448914,
"violence/graphic": 2.3819859052309766e-05,
"violence_graphic": 2.3819859052309766e-05,
"harassment/threatening": 0.00010304471652489156,
"harassment_threatening": 0.00010304471652489156,
"self-harm/instructions": 0.00013088244304526597,
"self_harm_instructions": 0.00013088244304526597
}
}
]
}
その他
ドキュメントには実際のデータを使った場合のより複雑な例も載っているので参考に。
Pythonで使う場合に、APIキーをもっとシンプルに渡す方法はないかな、と思って調べてみたら、こんな感じで行けた。
import psycopg2
import os
os.environ['PGOPTIONS'] = f"-c ai.openai_api_key={OPENAI_API_KEY}"
dsn = "user=postgres password=password dbname=pgai_test host=host.docker.internal port=5432"
sql = """
SELECT ai.openai_embed
( 'text-embedding-3-small'
, array['こんにちは。お元気ですか?','おやすみなさい。また明日']
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
result = cur.fetchall()
print(result)
pgai Vectorizerを使った埋め込みの自動化
PostgreSQL+pgvectorを使う場合、ベクトル化の対象となる元のコンテンツと、それをベクトル化したデータの同期はネックになる。pgaiはこのためのよりハイレベルな抽象化インタフェースである pgai Vectorizerを提供している。
ドキュメントは以下。
京都大学大学院情報学研究科知能情報学コース言語メディア研究室 (https://nlp.ist.i.kyoto-u.ac.jp/)様が公開されている尼崎市のFAQデータセットを使用してテーブルを作成してみようと思う。
日本語の論文はおそらくこちらだと思う
データセットをダウンロードして、pandasデータフレームを作成。今回は100件だけ。
!wget https://tulip.kuee.kyoto-u.ac.jp/localgovfaq/localgovfaq.zip
!unzip localgovfaq.zip
!pip install pandas
import pandas as pd
def file2list(filename: str, prefix: str = "") -> tuple:
"""Q/AファイルをIDとコンテンツに分割、それぞれを配列で返す"""
contents = []
ids = []
try:
with open(filename, 'r') as file:
for line in file:
line = line.strip().replace(" ", "")
id, content = line.split('\t')
if prefix:
id = f"{prefix}_{id}"
contents.append(content)
ids.append(id)
except Exception:
raise
return contents, ids
questions, ids = file2list("localgovfaq/qas/questions_in_Amagasaki.txt")
answers, _ = file2list("localgovfaq/qas/answers_in_Amagasaki.txt")
raw_df = pd.DataFrame({'QA_ID': ids, 'QUESTION': questions, 'ANSWER': answers})
df = raw_df.head(100)
df

faqテーブルを作成
import psycopg2
dsn = "user=postgres password=password dbname=pgai_test host=host.docker.internal port=5432"
create_table_query = """
CREATE TABLE IF NOT EXISTS faq (
id bigserial PRIMARY KEY,
qa_id int,
answer text
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(create_table_query)
conn.commit()
作成されたfaqテーブルをpsqlで確認。
\dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | faq | table | postgres
(1 row)
\dt faq
Table "public.faq"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------------------------------
id | bigint | | not null | nextval('faq_id_seq'::regclass)
qa_id | integer | | |
answer | text | | |
Indexes:
"faq_pkey" PRIMARY KEY, btree (id)
ではこのfaqテーブルに対してVectorizerを定義する。Vectorizerを定義するSQLの基本フォーマットは以下となる。
SELECT ai.create_vectorizer(
<テーブル名>::regclass,
destination => <embeddingを保持するテーブル名>,
embedding => ai.embedding_openai(<Embeddingモデル名>, <次元数>),
chunking => ai.chunking_recursive_character_text_splitter(<Embeddingを生成するカラム名>)
);
どうやらチャンク分割もできる様子。
これを今回のfaqテーブルに定義するにはこうなる。
import os
os.environ['PGOPTIONS'] = f"-c ai.openai_api_key={OPENAI_API_KEY}"
sql = """
SELECT ai.create_vectorizer(
'faq'::regclass,
destination => 'answer_embeddings',
embedding => ai.embedding_openai('text-embedding-3-small', 1536),
chunking => ai.chunking_recursive_character_text_splitter('answer', chunk_size => 8192)
);
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
今回のデータだと個々のコンテンツは短いテキストなのでチャンク分割不要なのだが、chunkingの設定は必須となっているようで外せないので、チャンクされないように大きめのチャンクサイズを設定した。またここでは触れないが、ベクトル化するコンテンツのフォーマット化もできるみたい。
psqlでどうなっているかを確認してみる。
\dt faq
Table "public.faq"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------------------------------
id | bigint | | not null | nextval('faq_id_seq'::regclass)
qa_id | integer | | |
answer | text | | |
Indexes:
"faq_pkey" PRIMARY KEY, btree (id)
Referenced by:
TABLE "answer_embeddings_store" CONSTRAINT "answer_embeddings_store_id_fkey" FOREIGN KEY (id) REFERENCES faq(id) ON DELETE CASCADE
Triggers:
_vectorizer_src_trg_1 AFTER INSERT OR UPDATE ON faq FOR EACH ROW EXECUTE FUNCTION ai._vectorizer_src_trg_1()
どうやらanswer_embeddings_storeという別テーブルと紐づけられて、faqテーブルの更新時にベクトル化がトリガーされるようになっている様子。
answer_embeddings_storeテーブルはこうなっている。
\dt answer_embeddings_store
List of relations
Schema | Name | Type | Owner
--------+-------------------------+-------+----------
public | answer_embeddings_store | table | postgres
(1 row)
\d+ answer_embeddings_store
Table "public.answer_embeddings_store"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
----------------+--------------+-----------+----------+-------------------+----------+-------------+--------------+-------------
embedding_uuid | uuid | | not null | gen_random_uuid() | plain | | |
id | bigint | | not null | | plain | | |
chunk_seq | integer | | not null | | plain | | |
chunk | text | | not null | | extended | | |
embedding | vector(1536) | | not null | | external | | |
Indexes:
"answer_embeddings_store_pkey" PRIMARY KEY, btree (embedding_uuid)
"answer_embeddings_store_id_chunk_seq_key" UNIQUE CONSTRAINT, btree (id, chunk_seq)
Foreign-key constraints:
"answer_embeddings_store_id_fkey" FOREIGN KEY (id) REFERENCES faq(id) ON DELETE CASCADE
Access method: heap
現時点ではfaqテーブル・answer_embeddings_storeテーブル、共にデータは0件。
SELECT count(*) FROM faq;
count
-------
0
(1 row)
SELECT count(*) FROM answer_embeddings_store;
count
-------
0
(1 row)
ではfaqテーブルにデータを登録してみる。
from tqdm import tqdm
tqdm.pandas()
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
for _, row in tqdm(df.iterrows(), total=len(df)):
insert_query = "INSERT INTO faq (qa_id, answer) VALUES (%s, %s)"
cur.execute(insert_query, (row['QA_ID'], row['ANSWER']))
conn.commit()
100%|██████████| 100/100 [00:00<00:00, 2354.09it/s]
一瞬で終わってしまったのだけど、動いてるのかな?直接確認してみる。
SELECT count(*) FROM faq;
count
-------
100
(1 row)
SELECT * FROM faq LIMIT 1;
id | qa_id | answer
----+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | 0 | ■市には乳幼児(乳児)とその親が集う場として、次のような取組をしています。以下のいずれについて知りたいですか。1.つどいの広場事業、すこやかプラザ運営事業子育て支援ゾーンPAL。2.保育所子育て支援事業。3.幼稚園すこやか子育て事業。4.子育てサークル活動支援事業。5.子育て学習世代間交流事業。6.双子のための育児教室学級。7.健康教室。
faqテーブルは当然更新されている。
answer_embeddings_storeテーブルも確認してみる。
SELECT count(*) FROM answer_embeddings_store;
count
-------
0
(1 row)
んー、更新されていない?
ということで、ドキュメントを見てみると、以下とあった。
Timescale Cloudでは、Vectorizerは自動的に作成され、5分ごとに実行されるTimescaleDBのバックグラウンドジョブを使ってスケジューリングされる。セルフホスティングの場合は、手動でvectorizer-workerを実行してvectorizerを作成・実行する必要がある。
なるほど、別プロセスで行っているのね。で、これをどうやるのか、というところで、ドキュメントはこちら。
Vectorizerを動かすためのworkerコンテナが必要になるということね。これ最初から書いてほしかったなぁ・・・
name: pgai
services:
db:
image: timescale/timescaledb-ha:cicd-024349a-arm64
environment:
POSTGRES_PASSWORD: postgres
OPENAI_API_KEY: <your-api-key>
ports:
- "5432:5432"
volumes:
- ./data:/var/lib/postgresql/data
vectorizer-worker:
image: timescale/pgai-vectorizer-worker:0.1.0rc4
environment:
PGAI_VECTORIZER_WORKER_DB_URL: postgres://postgres:postgres@db:5432/postgres
OPENAI_API_KEY: <your-api-key>
下の方に、pgaiコマンドをインストールして直接行う方法や、workerのdockerをいろんなポーリング間隔で起動する方法が記載されている。今回はワンショットのDockerを立ち上げてみる。なお、タグは明示的に指定しないとダメ。
docker run --rm \
-e PGAI_VECTORIZER_WORKER_DB_URL="postgres://postgres:password@host.docker.internal:5432/pgai_test" \
- e OPENAI_API_KEY="XXXXXXXXXX" \
timescale/pgai-vectorizer-worker:0.1.0 --once -c 3
2024-11-02 11:14:41 [info ] running vectorizer vectorizer_id=1
2024-11-02 11:14:52 [info ] finished processing vectorizer items=100 vectorizer_id=1
実行された模様。psqlで確認してみる。
SELECT count(*) FROM answer_embeddings_store;
count
-------
100
(1 row)
\x
SELECT * FROM answer_embeddings_store LIMIT 1;
-[ RECORD 1 ]--+----------------------(snip)
embedding_uuid | 15005602-03f9-4e06-9ab2-e6f7639686ee
id | 51
chunk_seq | 0
chunk | ■尼崎市の市営住宅の申込資格(2人以上の世帯)について。次の(1)~(7)のすべての事項に該当していることが必要です。(1)申込み開始日現在、尼崎市内に居住しているか、勤務場所を有しており、引き続き入居時点で居住条件等を満たしている方。(snip)
embedding | [0.03069248,0.047243923,0.007803684,(snip), 0.00017466015,-0.024224563,0.03440852]
Embeddingが生成されているのがわかる。
では検索してみる。
import psycopg2
import os
os.environ['PGOPTIONS'] = f"-c ai.openai_api_key={OPENAI_API_KEY}"
dsn = "user=postgres password=password dbname=pgai_test host=host.docker.internal port=5432"
sql = """
SELECT
chunk,
embedding <=> ai.openai_embed('text-embedding-3-small', '地域総合センター今北へはどう行けばいいですか?') as distance
FROM answer_embeddings
ORDER BY distance
LIMIT 5;
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
results = cur.fetchall()
for result in results:
chunk, distance = result
print(f"Distance: {distance}")
print(chunk)
print("---")
Distance: 0.40668799717712467
■地域総合センター今北には、十分な駐車場がございませんので、市バスをご利用ください。JR沿線からは「立花駅」、阪急沿線からは「塚口駅」「武庫之荘駅」、阪神沿線からは「尼崎駅」「武庫川駅」「出屋敷駅」へお越しいただき、市バスをご利用ください。どちらの駅からいらっしゃいますか?。1.JR立花駅から(位置的には、南西へ徒歩約10分です。)。2.阪急塚口駅(南)から。3.阪急武庫之荘駅(南)から。4.阪神尼崎駅(北)から。5.阪神武庫川駅から。6.阪神出屋敷駅(北)から。<改>。【関連するFAQ】。地域総合センターについて知りたい。<改>。【お問い合わせ】。地域総合センター今北。尼崎市西立花町3丁目14-1。電話06-6416-5729。
---
Distance: 0.4956288788650386
■地域総合センター上ノ島本館及び分館には十分な駐車設備がございませんので、次のとおり阪神バス(尼崎市内線)をご利用ください。以下のいずれの駅からの行き方について知りたいですか。1.阪急塚口駅から。2.JR立花駅から。3.阪神尼崎駅から。<改>。【関連するFAQ】。地域総合センターについて知りたい。<改>。【お問い合わせ】。地域総合センター上ノ島本館。尼崎市南塚口町8丁目7-25。電話06-6429-7640。
---
Distance: 0.5507384806431174
■以下の場所で配布しています。【尾浜庁舎(道路維持担当窓口)】。【尼崎市役所本庁舎】。【尼崎市立魚つり公園】。【支所内地域振興センター】。【尼崎スポーツの森】。【尼崎の森中央緑地】。【尼崎総合庁舎】。【尼崎港管理事務所】。【北堀キャナルベース】。【尼ロック防災展示室】。【尼崎市内警察署】。【尼崎防犯協会】。【尼崎交通安全協会】。【消費生活センター】。【一般社団法人兵庫県自転車防犯登録会】。【JR尼崎駅案内所i+PlusJR尼崎駅構内(改札外)】。【あまらぶアートラボA-lab】。【中央公園内まちなかみどころご案内コーナー】。【阪神沿線レンタサイクル】。【尼崎市記念公園運動施設】。【スポーツクラブWOODY】。【サンシビック尼崎】。【猪名川町スポーツセンター】。【市内の体育館】。各場所の詳細については次のリンクをご覧ください。[URL]。【お問い合わせ】。尼崎市コールセンター。電話06-6375-5639。
---
Distance: 0.5658957205067348
以下のいずれに該当されますか。1.引っ越し先が介護保険に関する施設以外の住宅。2.引っ越し先が介護保険に関する施設。3.受給資格証明書をもらっていない。<改>。■参考。介護保険事業担当でいう「介護保険に関する施設」とは、住所地特例対象施設のことをいい以下のとおりです。・介護保険3施設(特別養護老人ホーム、老人保健施設、介護療養型医療施設)。※ただし、地域密着型介護老人福祉施設(入所定員が30人未満の特別養護老人ホーム)については、住所地特例の対象外となります。(1)特定施設(介護保険法第8条第11項)。・養護老人ホーム(老人福祉法第20条の4)。・軽費老人ホーム(老人福祉法第20条の6)…ケアハウス等。・有料老人ホーム(老人福祉法第29条第1項)。・有料老人ホームに該当するサービスを提供しているサービス付き高齢者向け住宅(高齢者の居住の安定確保に関する法律第5条第1項)。※特定施設は要介護認定の有無に関わらず、住所地特例の対象となります。ただし地域密着型特定施設(介護専用型で入居定員30人未満)については住所地特例の対象外となります。<改>。詳しくは介護保険事業担当にお問い合わせください。■問合せ時間。午前8時45分~午後5時30分。ただし、窓口の取扱時間は午前9時~午後5時30分。■休日。土・日曜日、祝日、年末年始(12月29日~1月3日)。■連絡先。【介護保険事業担当保険料担当】。電話06-6489-6376。【北部保健福祉センター】。尼崎市南塚口町2-1-1。電話06-4950-0562。【南部保健福祉センター】。尼崎市竹谷町2-183。電話06-6415-6279。<改>。【関連するFAQ】。尼崎市内から市外へ住所を移すときはどうしたらいいですか?(転出届)。
---
Distance: 0.5857635336204101
以下のいずれに該当されますか。1.引っ越し先が市内の介護保険に関する施設以外の住宅。2.引っ越し先が市内の介護保険に関する施設。3.受給資格証明書をもらっていない。<改>。■参考。介護保険事業担当でいう「介護保険に関する施設」とは、住所地特例対象施設のことをいいます。・介護保険3施設(特別養護老人ホーム、老人保健施設、介護療養型医療施設)。※ただし、地域密着型介護老人福祉施設(入所定員が30人未満の特別養護老人ホーム)については、住所地特例の対象外となります。・特定施設(介護保険法第8条第11項)。(1)養護老人ホーム(老人福祉法第20条の4)。(2)軽費老人ホーム(老人福祉法第20条の6)…ケアハウス等。(3)有料老人ホーム(老人福祉法第29条第1項)。(4)有料老人ホームに該当するサービスを提供しているサービス付き高齢者向け住宅(高齢者の居住の安定確保に関する法律第5条第1項)。※特定施設は要介護認定の有無に関わらず、住所地特例の対象となります。ただし地域密着型特定施設(介護専用型で入居定員30人未満)については住所地特例の対象外となります。<改>。詳しくは介護保険事業担当へお問い合わせください。■問合せ時間:午前8時45分~午後5時30分。ただし、窓口の取扱時間は、午前9時~午後5時30分。■休日:土・日曜日、祝日、年末年始(12月29日~1月3日)。■連絡先。【介護保険事業担当資格・保険料担当】。電話06-6489-6376。【北部保健福祉センター】。尼崎市南塚口町2-1-1。電話06-4950-0562。【南部保健福祉センター】。尼崎市竹谷町2-183。電話06-6415-6279。【お問い合わせ】。健康福祉局福祉部。介護保険事業担当資格・保険料担当。電話06-6489-6376。<改>。【関連するFAQ】。市外から尼崎市内へ住所を移すときはどうしたらいいですか?(転入届)。
---
データをUPDATEしてみる。対象のデータ
sql = """
SELECT * FROM faq
WHERE qa_id = 1;
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
result = cur.fetchall()
print(result)
[(2, 1, '■地域総合センター今北には、十分な駐車場がございませんので、市バスをご利用ください。JR沿線からは「立花駅」、阪急沿線からは「塚口駅」「武庫之荘駅」、阪神沿線からは「尼崎駅」「武庫川駅」「出屋敷駅」へお越しいただき、市バスをご利用ください。どちらの駅からいらっしゃいますか?。1.JR立花駅から(位置的には、南西へ徒歩約10分です。)。2.阪急塚口駅(南)から。3.阪急武庫之荘駅(南)から。4.阪神尼崎駅(北)から。5.阪神武庫川駅から。6.阪神出屋敷駅(北)から。<改>。【関連するFAQ】。地域総合センターについて知りたい。<改>。【お問い合わせ】。地域総合センター今北。尼崎市西立花町3丁目14-1。電話06-6416-5729。')]
UPDATE
update_query = """
UPDATE faq
SET answer = '地域総合センター今北への行き方は秘密です。'
WHERE qa_id = 1
;
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(update_query)
conn.commit()
UPDATE後にすぐ検索しても結果は変わらない。
sql = """
SELECT
chunk,
embedding <=> ai.openai_embed('text-embedding-3-small', '地域総合センター今北へはどう行けばいいですか?') as distance
FROM answer_embeddings
ORDER BY distance
LIMIT 5;
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
results = cur.fetchall()
for result in results:
chunk, distance = result
print(f"Distance: {distance}")
print(chunk)
print("---")
Distance: 0.40668799717712467
■地域総合センター今北には、十分な駐車場がございませんので、市バスをご利用ください。JR沿線からは「立花駅」、阪急沿線からは「塚口駅」「武庫之荘駅」、阪神沿線からは「尼崎駅」「武庫川駅」「出屋敷駅」へお越しいただき、市バスをご利用ください。どちらの駅からいらっしゃいますか?。1.JR立花駅から(位置的には、南西へ徒歩約10分です。)。2.阪急塚口駅(南)から。3.阪急武庫之荘駅(南)から。4.阪神尼崎駅(北)から。5.阪神武庫川駅から。6.阪神出屋敷駅(北)から。<改>。【関連するFAQ】。地域総合センターについて知りたい。<改>。【お問い合わせ】。地域総合センター今北。尼崎市西立花町3丁目14-1。電話06-6416-5729。
---
Distance: 0.4956288788650386
■地域総合センター上ノ島本館及び分館には十分な駐車設備がございませんので、次のとおり阪神バス(尼崎市内線)をご利用ください。以下のいずれの駅からの行き方について知りたいですか。1.阪急塚口駅から。2.JR立花駅から。3.阪神尼崎駅から。<改>。【関連するFAQ】。地域総合センターについて知りたい。<改>。【お問い合わせ】。地域総合センター上ノ島本館。尼崎市南塚口町8丁目7-25。電話06-6429-7640。
---
(snip)
Vectorizer workerを実行する。
docker run --rm \
-e PGAI_VECTORIZER_WORKER_DB_URL="postgres://postgres:password@host.docker.internal:5432/pgai_test" \
- e OPENAI_API_KEY="XXXXXXXXXX" \
timescale/pgai-vectorizer-worker:0.1.0 --once -c 3
1件だけ処理されている。
2024-11-02 12:38:04 [info ] running vectorizer vectorizer_id=1
2024-11-02 12:38:07 [info ] finished processing vectorizer items=1 vectorizer_id=1
再度検索すると更新が反映されているのがわかる。
sql = """
SELECT
chunk,
embedding <=> ai.openai_embed('text-embedding-3-small', '地域総合センター今北へはどう行けばいいですか?') as distance
FROM answer_embeddings
ORDER BY distance
LIMIT 5;
"""
with psycopg2.connect(dsn) as conn:
with conn.cursor() as cur:
cur.execute(sql)
results = cur.fetchall()
for result in results:
chunk, distance = result
print(f"Distance: {distance}")
print(chunk)
print("---")
Distance: 0.21225871820591824
地域総合センター今北への行き方は秘密です。
---
Distance: 0.4956288788650386
■地域総合センター上ノ島本館及び分館には十分な駐車設備がございませんので、次のとおり阪神バス(尼崎市内線)をご利用ください。以下のいずれの駅からの行き方について知りたいですか。1.阪急塚口駅から。2.JR立花駅から。3.阪神尼崎駅から。<改>。【関連するFAQ】。地域総合センターについて知りたい。<改>。【お問い合わせ】。地域総合センター上ノ島本館。尼崎市南塚口町8丁目7-25。電話06-6429-7640。
---
Distance: 0.5507384806431174
■以下の場所で配布しています。【尾浜庁舎(道路維持担当窓口)】。【尼崎市役所本庁舎】。【尼崎市立魚つり公園】。【支所内地域振興センター】。【尼崎スポーツの森】。【尼崎の森中央緑地】。【尼崎総合庁舎】。【尼崎港管理事務所】。【北堀キャナルベース】。【尼ロック防災展示室】。【尼崎市内警察署】。【尼崎防犯協会】。【尼崎交通安全協会】。【消費生活センター】。【一般社団法人兵庫県自転車防犯登録会】。【JR尼崎駅案内所i+PlusJR尼崎駅構内(改札外)】。【あまらぶアートラボA-lab】。【中央公園内まちなかみどころご案内コーナー】。【阪神沿線レンタサイクル】。【尼崎市記念公園運動施設】。【スポーツクラブWOODY】。【サンシビック尼崎】。【猪名川町スポーツセンター】。【市内の体育館】。各場所の詳細については次のリンクをご覧ください。[URL]。【お問い合わせ】。尼崎市コールセンター。電話06-6375-5639。
---
(snip)
まとめ
RAGといえばベクトルDBというのが最近の流行ではあるが、ベクトル化したデータの管理はそれでもいいとして、ベクトル化する前のコンテンツデータの管理も当然必要になる。そして、元のコンテンツデータが変更されるとベクトルも更新する必要がある。つまり、中身は同じだけど形が異なる2つのデータを「同期」させる必要があるというのが悩ましいところだと思う。
以前に試したWeaviateはこれをモジュール機能とそれに対応したCRUD機能で実現している。
ただ、WeaviateはあくまでもベクトルDBであって、RDBではないので、RDBで求められるような複雑なデータ管理にはさすがに耐えれないのではないかと思う(とはいえ、小さな規模なら十分可能だと思うが)。
PostgreSQL+pgvectorという組み合わせは、本格的なデータ管理が必要・そこにベクトル検索を追加、という感じで採用するケースは多いと思うが、となると最初に書いた課題が出てくる。
自分はRDBの知見があまりないので、このあたりの課題の難易度がわからないが、すくなくともpgaiを使うことで、これらの課題を吸収してくれて、
- ベクトル化・DBアクセスの2つに分かれていたプロセスが、DBアクセスだけで完結する
- データの同期についてもpgaiがやってくれる(完全リアルタイムではないにせよ)
が実現できるので、コードや処理も簡潔になり、運用もPostgreSQLだけを考えればいい点でメリットがあるのではないか、特に商用で使うケースでは有用だと思う。大規模なPostgreSQL運用を行っているTimescaleDBが提供・メンテしているというところも安心感。
なおドキュメントには、pgaiを使ってSQLだけでRAGを実現している例もあるので、興味があれば。GitHubのドキュメントは丁寧に書かれている感があって好印象。
(冒頭のツイート、個人的には、人それぞれでユースケースや状況は異なるので、それを「間違い」といい切ってしまうのはいかがなものかな?とは思う、その点については正直嫌悪感がある)