BGE-M3ベースのZero-Shot Classificationモデルを試す
たまたま見つけた
"How to Utilize the BGE-M3 Zero-Shot Classifier"
進化し続ける自然言語処理の世界において、BGE-M3 Zero-Shot Classifierは強力なツールとして際立っています。 事前の学習データがなくてもテキストを分類できるこのモデルは、分類タスクを管理する際の負担を大幅に軽減します。 このガイドでは、このモデルを効率的に実装して利用する方法と、役立つトラブルシューティングのヒントについて説明します。
記事では紹介されているモデルを見ると、どうやらbge-m3をzero-shotの分類にチューニングしたものの様子。-cがついている方が商用利用向けにデータセットなども考慮されたものらしい。
このモデルの作者の方は他にも多数のzero-shot classificationモデルをリリースされているようで、そのなかでマルチリンガルに対応しているものをピックアップした。
少し試してみる。
上記のうち、bge-m3の以下のモデルでまずは試してみようと思う。
一応モデルカードには以下のような記載がある
When to use which model
(snip)
- Multilingual/non-English use-cases: use bge-m3-zeroshot-v2.0 or bge-m3-zeroshot-v2.0-c. Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like EasyNMT and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
日本語訳
- 多言語/非英語ユースケース:bge-m3-zeroshot-v2.0またはbge-m3-zeroshot-v2.0-cを使用してください。多言語モデルは英語のみのモデルよりもパフォーマンスが悪いことに注意してください。そのため、まずEasyNMTのようなライブラリでテキストを英語に機械翻訳し、翻訳されたデータに英語のみのモデルを適用することもできます。 機械翻訳はまた、チームがデータ内のすべての言語を話せない場合の検証を容易にします。
パフォーマンスについて明記されているが、どの程度かも含めて確認したい。
Colaboratoryで。
パッケージインストール
!pip install transformers[sentencepiece]
分類の推論コード。めちゃシンプルに書ける。一旦英語で。
from transformers import pipeline
import json
# 分類したい文章
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# 分類時にモデルに渡すプロンプト。精度が向上する可能性があるらしい。
hypothesis_template = "This text is about {}"
# 分類に使用するラベル
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline(
"zero-shot-classification",
model="MoritzLaurer/bge-m3-zeroshot-v2.0-c"
)
output = zeroshot_classifier(
text,
classes_verbalized,
hypothesis_template=hypothesis_template,
multi_label=False
)
print(json.dumps(output, indent=2, ensure_ascii=False))
結果はこんな感じで返ってくる
{
"sequence": "Angela Merkel is a politician in Germany and leader of the CDU",
"labels": [
"politics",
"economy",
"environment",
"entertainment"
],
"scores": [
0.9909391403198242,
0.0035491036251187325,
0.002897238126024604,
0.0026146159507334232
]
}
上記の例だと「アンゲラ・メルケルはドイツの政治家でCDU党首である」という文章は、「政治」「経済」「環境」「娯楽」の中から「政治」というラベルになっているので、適切。
では日本語でやってみる。
from transformers import pipeline
import json
# 分類したい文章
text = "美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。"
# 分類時にモデルに渡すプロンプト。精度が向上する可能性があるらしい。
hypothesis_template = "このテキストは {} について書かれています。"
# 分類に使用するラベル
classes_verbalized = ["料理", "気象", "自然", "文化"]
zeroshot_classifier = pipeline(
"zero-shot-classification",
model="MoritzLaurer/bge-m3-zeroshot-v2.0-c"
)
output = zeroshot_classifier(
text,
classes_verbalized,
hypothesis_template=hypothesis_template,
multi_label=False
)
print(json.dumps(output, indent=2, ensure_ascii=False))
{
"sequence": "美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。",
"labels": [
"料理",
"自然",
"文化",
"気象"
],
"scores": [
0.8905330300331116,
0.07739073783159256,
0.025312598794698715,
0.006763632874935865
]
}
一応期待した結果にはなっている。
別の例。
from transformers import pipeline
import json
# 分類したい文章
text = "天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。"
# 分類時にモデルに渡すプロンプト。精度が向上する可能性があるらしい。
hypothesis_template = "このテキストは {} について書かれています。"
# 分類に使用するラベル
classes_verbalized = ["料理", "気象", "自然", "文化"]
zeroshot_classifier = pipeline(
"zero-shot-classification",
model="MoritzLaurer/bge-m3-zeroshot-v2.0-c"
)
output = zeroshot_classifier(
text,
classes_verbalized,
hypothesis_template=hypothesis_template,
multi_label=False
)
print(json.dumps(output, indent=2, ensure_ascii=False))
{
"sequence": "天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。",
"labels": [
"気象",
"自然",
"文化",
"料理"
],
"scores": [
0.7071307301521301,
0.2658151388168335,
0.016267459839582443,
0.010786647908389568
]
}
こちらも期待通り。
なお、multi_labelでラベルを一つだけ返すのか全部返すのかを指定できるようなのだけど、自分が試した限り、どちらにしても全部返ってきた。
とりあえずまとまったデータセットで評価してみないとなんともだけども、手軽に使えるし好印象。
学習用のコードはこちらで公開されている模様。
あと論文もあった
Claude-3.5-Sonnet(New)による落合プロンプトの結果。
どんなもの?
この論文は、テキスト分類タスクのための効率的な汎用分類器(Universal Classifier)を構築する手法を提案しています。Natural Language Inference (NLI、文章間の含意関係を認識するタスク)を基盤として、様々な分類タスクを統一的に扱える分類器を作成します。特徴は、大規模言語モデル(LLM)と比べてはるかに少ないリソースで動作すること、ゼロショット学習(事前の学習なしで新しいタスクに対応)とフューショット学習(少数の例で学習)の両方に対応できることです。33のデータセットと389の多様なクラスで訓練された分類器を公開し、従来のNLIのみのモデルと比べて9.4%の性能向上を達成しています。
先行研究と比べてどこがすごい?
従来の手法の多くは、テキスト生成に基づく大規模言語モデル(LLM)を使用していました。これらは柔軟性が高い一方で、多大な計算リソースを必要とします。本研究は、より小規模なBERTベースのモデルでも、NLIタスクを介して汎用的な分類能力を獲得できることを示しています。また、単純なNLIデータだけでなく、28の非NLIデータセットも組み合わせることで、より広範な分類タスクに対応できる点が革新的です。さらに、実装の詳細な手順とコードを公開し、誰でも同様のモデルを構築できるようにしている点も特徴的です。
技術や手法の肝はどこ?
本手法の核心は、あらゆる分類タスクをNLIタスクに変換する方法にあります。NLIは、ある文(前提)から別の文(仮説)が導かれるかを判断するタスクです。例えば、トピック分類であれば、分類したい文を「前提」として、「このテキストは経済に関するものである」といった仮説文を生成し、その含意関係を判定することで分類を行います。また、データの前処理段階で、CleanLabライブラリを使用してノイズの多いデータを除去し、各データセットから最大500のサンプルのみを使用することで、データの質と多様性を重視しています。これにより、より少ないデータでも高い汎用性を実現しています。
どうやって有効だと検証した?
検証は主に3つの方法で行われています。1つ目は、提案手法で訓練したモデル(deberta-v3-zeroshot-v1.1-all-33)の性能評価です。2つ目は、NLIデータのみで訓練したベースラインモデル(deberta-v3-nli-only)との比較です。3つ目は、28の異なるモデルを作成し、それぞれ1つのデータセットを除外して学習させる実験です。これにより、未知のタスクに対する汎化性能を評価しています。結果として、提案モデルはNLIのみのモデルと比べて平均9.4%の性能向上を示し、特に未知のタスクに対しても良好な性能を維持できることが確認されました。
議論はある?
主な議論点として、以下の6つの制限事項が挙げられています:1)学術データセットの多様性が実践的なユースケースを十分にカバーしていない可能性、2)大規模生成モデルとの詳細な比較が行われていない点、3)データのノイズ除去にさらなる改善の余地がある点、4)クラス数が多いタスクでは各クラスごとに予測が必要になる非効率性、5)2021年11月のDeBERTa-v3という比較的古いモデルを使用している点、6)PETやRTDなど、他の普遍的分類アプローチとの比較が行われていない点です。これらの制限は、将来の研究課題として提示されています。
次に読むべき論文は?
論文内で重要な関連研究として以下が挙げられています:
- Schick and Schütze (2021b) "It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners"
- Yin et al. (2019) "Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach"
- Clark et al. (2020) "ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators"
これらの論文は、小規模モデルでのフューショット学習、ゼロショット分類の評価手法、効率的な事前学習手法について、それぞれ重要な知見を提供しています。
とりあえずまとまったデータセットで評価してみないとなんともだけども、手軽に使えるし好印象。
ということで評価してみる。
評価データは感情分類用の以下のデータセットを使った。
!pip install datasets swifter
testのデータ1781件を使う。
from datasets import load_dataset
import pandas as pd
import numpy as np
dataset = load_dataset("llm-book/wrime-sentiment", split="test")
df = pd.DataFrame(dataset)
df['labe_str'] = np.where(df['label'] == 0, "ポジティブ", "ネガティブ")
df

分類。1時間ぐらいかかる。
from transformers import pipeline
import json
import swifter
hypothesis_template = "この文章から読み取れる感情は {}"
classes_verbalized = ["ポジティブ", "ネガティブ"]
zeroshot_classifier = pipeline(
"zero-shot-classification",
model="MoritzLaurer/bge-m3-zeroshot-v2.0-c",
)
def classify(text):
output = zeroshot_classifier(
text,
classes_verbalized,
hypothesis_template=hypothesis_template,
)
return output["labels"][0], output["scores"][0]
df['result'], df['score'] = zip(*df['sentence'].swifter.apply(classify))
df
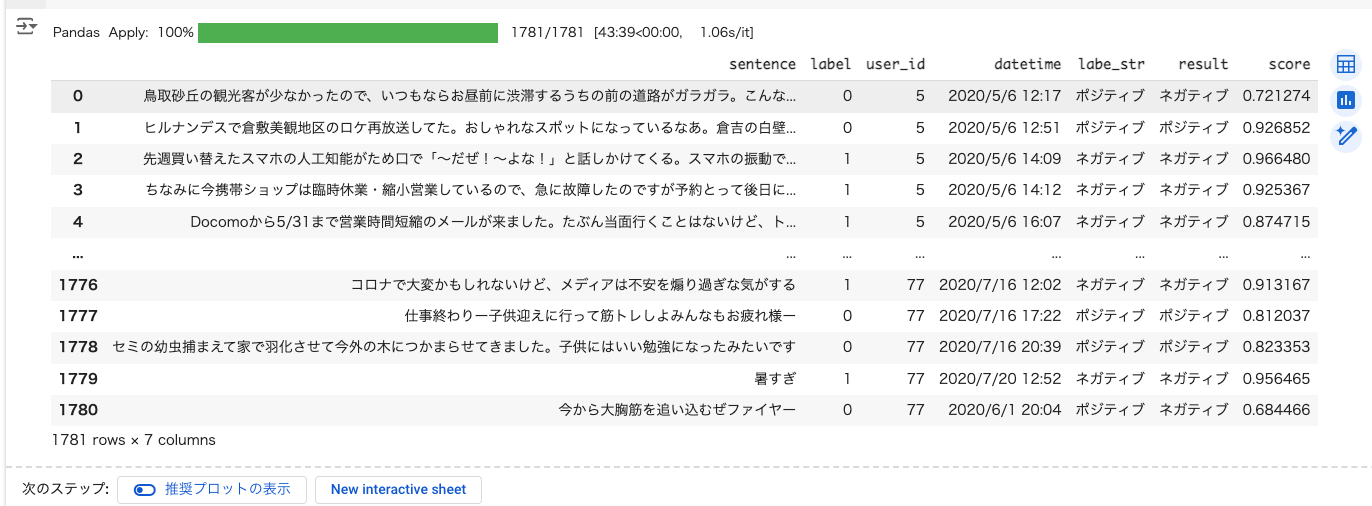
typoしてるのに気づいた・・・
df['is_equal'] = df['labe_str'] == df['result']
df['is_equal'].mean()
0.8674901740595171
特段このデータにあわせた学習はしていないと思うし、まあ悪くないのではなかろうか。
こちらの方でも試してみた。-cなしで恐らくコチラのほうがデータセット自体はバリエーションがあるような雰囲気に思える。
0.8877035373385739
ちょっと-cよりもちょっと上かな
まとめ
分類というユースケースで使うならば、シンプルで使いやすい。自分でも学習にトライしてみようかな。