大規模向けRAG/GraphRAGパイプラインを構築できる「TrustGraph」を試す
GitHubレポジトリ
TrustGraph
データサイロを信頼できるAIで接続する
TrustGraphとは?
TrustGraphは、分断されたデータを繋ぐための信頼性の高いAIエージェントを迅速に導入するためのツール、サービス、グラフストア、VectorDBを提供します。主な特徴:
- 一括ドキュメントインジェスト
- 自動ナレッジグラフ構築
- 自動ベクトル化
- モデル非依存のLLM統合
- ナレッジグラフとVectorDBを組み合わせたRAG(再構成情報検索)
- エンタープライズ級の信頼性、スケーラビリティ、モジュール性
- OllamaやLlamafileによるローカルLLMデプロイでデータプライバシーに対応
機密データを一括で取り込み、一般的なLLMを知識専門家に変えるリユーザブルなナレッジコアを構築します。監視ダッシュボードではLLMのレイテンシ、リソース管理、トークンスループットをリアルタイムで可視化できます。
TrustGraphの操作方法
TrustGraphには以下の2つの操作方法があります:
- TrustGraph CLI
- 開発用Configuration UI
TrustGraph CLIは、TrustGraphと連携するためのコマンドを提供し、Configuration UIはカスタム設定を行ってTrustGraphの展開をサポートします。TrustGraphの主な機能
- PDFデコード:PDFドキュメントを自動的に解析して内容を抽出。
- テキストチャンク化:テキストデータを効果的に処理するために細かいチャンクに分割。
- オンデバイスSLM推論:Ollama や Llamafile と連携し、ローカルデバイスでのSLM推論をサポート。
- クラウドLLM推論:AWS Bedrock、AzureAI、Anthropic、Cohere、OpenAI、および VertexAI といったクラウドプラットフォームでのLLM推論に対応。
- チャンクマップ付きベクトル埋め込み:HuggingFace のモデルを使用して、テキストをチャンクごとにベクトル化。
- RDFナレッジ抽出エージェント:RDFに基づく知識抽出エージェントで、データを高度に整理された知識グラフに変換。
- グラフストア:Apache Cassandra または Neo4j をグラフストアとして使用可能。
- VectorDBとしてのQdrant:Qdrant を使用して、高速な類似性検索を実現するVectorDBを提供。
- ナレッジコアの構築と読み込み:ナレッジコア を構築し、再利用可能な形でデータを管理。
- RAGクエリサービス:グラフストアとVectorDBを組み合わせたRAG(再構成情報検索)クエリサービスを提供。
- Grafanaによるテレメトリダッシュボード:Grafana のダッシュボードでトラフィックやリソース使用状況をリアルタイムで監視。
- モジュール統合:Apache Pulsar を使用したモジュール統合で、データ処理をスムーズに連携。
- コンテナオーケストレーション:Docker、Podman、または Minikube を使ったコンテナの統合管理が可能。
アーキテクチャ
TrustGraphは、できる限り多くの言語モデル(LLM)や環境に対応できるように、モジュラー構造で設計されています。このモジュール式アーキテクチャは、各機能をモジュールとして分割し、Pub/Subバックボーンを通じて連携させる構造です。このPub/SubバックボーンとしてApache Pulsarが利用されています。Pulsarはデータブローカーとして機能し、データ処理のキューを管理し、各処理モジュールに接続します。
Pulsarのワークフロー
- 処理フロー:Pulsarは、処理モジュールからの出力を受け取り、それを次に登録されたモジュールへの入力としてキューに追加します。
- サービスフロー(LLMや埋め込みのようなサービスの場合):Pulsarはクライアント/サーバーモデルを提供します。Pulsarのキューはサービスへの入力として機能し、処理が完了した出力は別のキューに送られます。これにより、クライアント側のサブスクライバーがその出力をリクエストすることが可能になります。
ナレッジエージェント
TrustGraphは、テキストコーパス(PDFやテキストファイル)から知識を抽出し、超高密度のナレッジグラフに変換するために、3つの自律的なナレッジエージェントを使用します。これらのエージェントは、RDFナレッジグラフを構築するために必要な要素ごとに機能を分担しています。エージェントは以下の通りです:
- トピック抽出エージェント:特定のトピックを抽出します。
- エンティティ抽出エージェント:エンティティ(実体)を識別して抽出します。
- ノード接続エージェント:抽出されたエンティティ同士を関連付けます。
これらのエージェントは、テンプレートを用いてカスタマイズ可能で、特定のユースケースに応じた抽出エージェントの設定が可能です。抽出エージェントは、ロードコマンドを使って自動的に起動されます。
RAGクエリ
ナレッジグラフと埋め込みデータの構築が完了するか、ナレッジコアが読み込まれると、RAG(再構成情報検索)クエリを実行できます

公式ドキュメント
結構ガッツリ作り込んであるような印象を受ける。商用向けに良さそうかも。
セットアップ
GetStartedに従って進める
TrustGraphは以下の環境にデプロイ可能。
- Docker(Docker Compose)
- Podman(Podman Machine)
- Minikube(K8S)
- GKE(K8S)
今回はMac上のDockerを使う。
で、GetStartedを見るとCLIのインストールからスタートするのだが、これらはセットアップで使うものではないように思えるのでスキップ。構築用の設定ファイルを生成してくれるGUIがあるのでこれを使ってみる。
以下URLにアクセス
こんな画面

タブが3つあり、"COMPONET SELECTION"で使用するコンポーネントを選択、"CUSTOMIZATION"で各種プロンプトのカスタマイズ、"FINISH DEPLOYMENT"で設定ファイルの生成および手順が出力される。なお、バージョン0.14.17は安定版の様子。

"COMPONET SELECTION"は以下とした。各コンポーネントは過去に自分が触ったことのあるもの、よく触っているものを選択、パラメータはMax Output Tokensがデフォルトだと1000とかなり小さい気がしたのでそれだけ変更、あとはデフォルト、という感じ。

"CUSTOMIZATION"は内部で使用される各種プロンプトのようなのだけど、これがどう影響するのかがわからない。とりあえず最も一般的になりそうな"LLM System Prompt"をクリックすると、タブが増える。中身を見てみる。

システムプロンプトのカスタマイズ画面が表示される。

説明に
「System」プロンプトの目的は、すべてのプロンプトにプライマリ接頭辞を提示することです。
とあるので、ここを修正すれば他のプロンプトにも反映されそう。恐らく何もしなければ全部英語で出力されそうな気がするので、以下のように修正した。
あなたは、親切な日本語のアシスタントです。あなたの仕事は、NLP(自然言語処理)のタスクをこなすことです。

"FINISH DEPLOYMENT"タブを開くと、デプロイの手順が表示される。真ん中の"GENERATE"をクリックすると設定が生成されるので、ダウンロードする。


deploy.zipがダウンロードされるのでこれを適当なパスに展開
unzip deploy.zip -d trustgraph-test
中身はこんな感じ。
tree -a trustgraph-test/
trustgraph-test/
├── docker-compose.yaml
├── grafana
│ ├── dashboards
│ │ └── dashboard.json
│ └── provisioning
│ ├── dashboard.yml
│ └── datasource.yml
└── prometheus
└── prometheus.yml
5 directories, 5 files
あとデプロイ手順に従って起動。
cd trustgraph-test
export OPENAI_KEY=XXXXXXXXXXXX
docker compose -f docker-compose.yaml up
ちょっと気になるけど、ここはおいておく
WARN[0000] The "OPENAI_TOKEN" variable is not set. Defaulting to a blank string.
WARN[0000] The "OPENAI_TOKEN" variable is not set. Defaulting to a blank string.
多数のコンテナが起動する。Docker Desktopの場合、DockerVMにディスク容量も十分に必要になるので注意。
[+] Running 24/26 74.5s
⠼ query-doc-embeddings Pulling 89.5s
⠼ metering-rag Pulling 89.5s
⠼ kg-extract-topics Pulling 89.5s
⠼ metering Pulling 89.5s
⠼ text-completion-rag Pulling 89.5s
⠼ init-pulsar Pulling 89.5s
⠼ grafana [⣿⣿⣿⣿] Pulling 89.5s
⠼ query-graph-embeddings Pulling 89.5s
⠼ graph-rag Pulling 89.5s
⠼ vectorize [⣿⣿⣄⣶⣿] 507MB / 799.6MB Pulling 89.5s
⠼ pdf-decoder Pulling 89.5s
⠼ query-triples Pulling 89.5s
⠼ store-triples Pulling 89.5s
⠼ store-doc-embeddings Pulling 89.5s
✔ neo4j Pulled 32.6s
⠼ pulsar [⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿] Pulling 89.5s
⠼ prometheus Pulling 89.5s
⠼ embeddings Pulling 89.5s
⠼ prompt-rag Pulling 89.5s
⠼ text-completion Pulling 89.5s
⠼ kg-extract-relationships Pulling 89.5s
⠼ kg-extract-definitions Pulling 89.5s
⠼ chunker Pulling 89.5s
⠼ store-graph-embeddings Pulling 89.5s
⠼ qdrant [⣿⣿⣿⣿⣿⣿⣿] Pulling 89.5s
⠼ prompt Pulling 89.5s
で、起動時のログを見ているとこんな感じでずっとエラーが出続けている。。。。
text-completion-rag-1 | Exception ignored in: <function BaseProcessor.__del__ at 0x7ffffb8f6840>
text-completion-rag-1 | Traceback (most recent call last):
text-completion-rag-1 | File "/usr/local/lib/python3.12/site-packages/trustgraph/base/base_processor.py", line 42, in __del__
text-completion-rag-1 | if self.client:
text-completion-rag-1 | <class 'RuntimeError'>
text-completion-rag-1 | Exception: OpenAI API key not specified
text-completion-rag-1 | Will retry...
text-completion-rag-1 | ^^^^^^^^^^^
text-completion-rag-1 | AttributeError: 'Processor' object has no attribute 'client'
text-completion-1 | Exception ignored in: <function BaseProcessor.__del__ at 0x7ffffb8f2840>
text-completion-1 | Traceback (most recent call last):
text-completion-1 | File "/usr/local/lib/python3.12/site-packages/trustgraph/base/base_processor.py", line 42, in __del__
text-completion-1 | if self.client:
text-completion-1 | ^^^^^^^^^^^
text-completion-1 | AttributeError: 'Processor' object has no attribute 'client'
text-completion-1 | <class 'RuntimeError'>
text-completion-1 | Exception: OpenAI API key not specified
text-completion-1 | Will retry...
OPENAI_TOKENもセットしないといけないのかな?と思ってセットしてみたが解決しない。むーん。
とりあえずIssue上げた。
Issueでやり取りしつつ解決。なんか複合的な感じだった。
- OpenAI APIキーは、以前は
OPENAI_KEYで指定することになっていて、現在はOPENAI_TOKENに変わった、はず - だが、コードはまだ変わっていなかった模様
- Config UIで生成される docker-compose.yaml は先んじて
OPENAI_TOKENを渡すようになっていたが、コード側が書き換わっていなかったので意味がなかった
Jsonnetでテンプレートを生成するみたいなのだけど、そこは書き換わっていたが別の箇所で古いコードが残っていた様子。v0.15.5で変更されているようなのでそちらを使う。Stableのv0.14はまだ変更されていない模様。
v0.15のConfig UIはURLがちょっと異なるのだが、こちらはまだ書き換わっていない様子。
https://dev.config-ui.demo.trustgraph.ai/

その場合はGitHubのReleaseからv015.5のものをダウンロードできる。
wget https://github.com/trustgraph-ai/trustgraph/releases/download/v0.15.5/deploy.zip
unzip deploy.zip -d trustgraph-test-0.15.5
cd trustgraph-test-0.15.5
Config UIとは異なり、こちらのdeploy.zipには各コンポーネントの組み合わせごとのdocker-compose.yamlがすべて含まれている。
tree .
.
├── README.md
├── docker-compose
│ ├── grafana
│ │ ├── dashboards
│ │ │ └── dashboard.json
│ │ └── provisioning
│ │ ├── dashboard.yml
│ │ └── datasource.yml
│ ├── prometheus
│ │ └── prometheus.yml
│ ├── tg-azure-cassandra.yaml
│ ├── tg-azure-neo4j.yaml
│ ├── tg-azure-openai-cassandra.yaml
│ ├── tg-azure-openai-neo4j.yaml
│ ├── tg-bedrock-cassandra.yaml
│ ├── tg-bedrock-neo4j.yaml
│ ├── tg-claude-cassandra.yaml
│ ├── tg-claude-neo4j.yaml
│ ├── tg-cohere-cassandra.yaml
│ ├── tg-cohere-neo4j.yaml
│ ├── tg-googleaistudio-cassandra.yaml
│ ├── tg-googleaistudio-neo4j.yaml
│ ├── tg-llamafile-cassandra.yaml
│ ├── tg-llamafile-neo4j.yaml
│ ├── tg-ollama-cassandra.yaml
│ ├── tg-ollama-neo4j.yaml
│ ├── tg-openai-cassandra.yaml
│ ├── tg-openai-neo4j.yaml
│ ├── tg-vertexai-cassandra.yaml
│ ├── tg-vertexai-neo4j.yaml
│ └── vertexai
│ └── private.json
├── gcp-k8s
│ ├── tg-azure-cassandra.yaml
│ ├── tg-azure-neo4j.yaml
│ ├── tg-azure-openai-cassandra.yaml
│ ├── tg-azure-openai-neo4j.yaml
│ ├── tg-bedrock-cassandra.yaml
│ ├── tg-bedrock-neo4j.yaml
│ ├── tg-claude-cassandra.yaml
│ ├── tg-claude-neo4j.yaml
│ ├── tg-cohere-cassandra.yaml
│ ├── tg-cohere-neo4j.yaml
│ ├── tg-googleaistudio-cassandra.yaml
│ ├── tg-googleaistudio-neo4j.yaml
│ ├── tg-llamafile-cassandra.yaml
│ ├── tg-llamafile-neo4j.yaml
│ ├── tg-ollama-cassandra.yaml
│ ├── tg-ollama-neo4j.yaml
│ ├── tg-openai-cassandra.yaml
│ ├── tg-openai-neo4j.yaml
│ ├── tg-vertexai-cassandra.yaml
│ └── tg-vertexai-neo4j.yaml
└── minikube-k8s
├── tg-azure-cassandra.yaml
├── tg-azure-neo4j.yaml
├── tg-azure-openai-cassandra.yaml
├── tg-azure-openai-neo4j.yaml
├── tg-bedrock-cassandra.yaml
├── tg-bedrock-neo4j.yaml
├── tg-claude-cassandra.yaml
├── tg-claude-neo4j.yaml
├── tg-cohere-cassandra.yaml
├── tg-cohere-neo4j.yaml
├── tg-googleaistudio-cassandra.yaml
├── tg-googleaistudio-neo4j.yaml
├── tg-llamafile-cassandra.yaml
├── tg-llamafile-neo4j.yaml
├── tg-ollama-cassandra.yaml
├── tg-ollama-neo4j.yaml
├── tg-openai-cassandra.yaml
├── tg-openai-neo4j.yaml
├── tg-vertexai-cassandra.yaml
└── tg-vertexai-neo4j.yaml
9 directories, 66 files
自分の選んだ
- プラットフォーム: Docker
- モデル: OpenAI
- グラフストア: Neo4j
の場合は、docker-compose/tg-openai-neo4j.yamlになる。残念ながらGitHubのReleasesからダウンロードしたファイルを使う場合には以下の制約がある。
- ConfigUIで設定したようなGUIでの細かいカスタマイズはできず、全部手動でやらざるを得ない。
- v0.15.XのConfigUIは、v0.14.Xのものとはやや異なる、出力も異なるかは未確認
そこで、一旦v0.15.4のConfig UIで生成したものとGitHubのReleases v0.15.5をdiffで見比べつつ手動でマージした(ConfigUIで設定した箇所だけを反映させただけなので、v0.15.5のほうが正としている)。この作業は面倒なので、Config UIが修正されるのを待つのが良いと思う。
参考までに修正したdocker-compose/tg-openai-neo4j.yamlを以下に置いておく。
では起動する。
cd docker-compose
今度はOPENAI_TOKENで!
export OPENAI_TOKEN=XXXXXXXXXXXX
docker compose -f tg-openai-neo4j.yaml up
ログを見ている限りはエラーは起きなくなったし、うまく言ってるように思える。
で、やっとCLIの出番となる。
別ターミナルで、別の作業ディレクトリを作成。
mkdir trustgraph-cli-test && cd trustgraph-cli-test
CLIはPythonパッケージなので仮想環境を作成してインストール。自分はmiseを使うが、やり方は適宜。
mise use python@3.12
cat << 'EOS' >> .mise.toml
[env]
_.python.venv = { path = ".venv", create = true }
EOS
mise trust
CLIのパッケージバージョンは、TrustGraph本体とバージョンをあわせておく。
pip install trustgraph-cli==0.15.5
TrustGraphの各コンポーネントの正常性を確認するにはtg-processor-stateを使う。
tg-processor-state
+--------------------------+---------+
| processor | state |
+--------------------------+---------+
| store-graph-embeddings | running |
| query-graph-embeddings | running |
| embeddings | running |
| chunker | running |
| store-triples | running |
| graph-rag | running |
| pdf-decoder | running |
| metering-rag | running |
| prompt | running |
| query-triples | running |
| metering | running |
| kg-extract-definitions | running |
| vectorize | running |
| kg-extract-relationships | running |
| text-completion | running |
| prompt-rag | running |
| kg-extract-topics | running |
| text-completion-rag | running |
+--------------------------+---------+
どうやらうまく行った様子。
で、CLIの操作についてはコマンドリファレンスはあるものの、手順的なものが見当たらないなと思ったら以下にあった。
ではPDFを読み込ませてみる。今回は、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用させていただく。
mkdir sources
wget -P sources https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
ls sources
total 3592
-rw-r--r--@ 1 kun432 staff 1838405 9 13 09:45 r5_doukou.pdf
PDFを読み込ませるにはtg-load-pdfを使う。ちなみにPDF以外のテキストファイル等の場合はtg-load-textになる
tg-load-pdf sources/r5_doukou.pdf
sources/r5_doukou.pdf: Loaded successfully.
All done.
裏でログを見ているとPDFを処理しているのがわかると思う。
(snip)
store-triples-1 | Create literal 全市で宿泊が2割強であり、地区別では有馬が5割、北野が4割を超える。日帰り客の宿泊なしは西北神が9割弱。
store-triples-1 | Created 1 nodes in 2 ms.
store-triples-1 | Create literal rel http://trustgraph.ai/e/%E6%97%85%E8%A1%8C%E3%81%AE%E6%97%A5%E7%A8%8B%E3%81%8A%E3%82%88%E3%81%B3%E5%AE%BF%E6%B3%8A%E5%9C%B0 http://www.w3.org/2004/02/skos/core#definition 全市で宿泊が2割強であり、地区別では有馬が5割、北野が4割を超える。日帰り客の宿泊なしは西北神が9割弱。
store-triples-1 | Created 0 nodes in 2 ms.
store-triples-1 | Create node http://trustgraph.ai/e/%E6%B6%88%E8%B2%BB%E9%A1%8D%E3%83%BB%E5%89%B2%E5%BC%95%E5%88%B6%E5%BA%A6%E3%81%AE%E5%88%A9%E7%94%A8
store-triples-1 | Created 1 nodes in 1 ms.
store-triples-1 | Create literal 日帰り客の消費額は8722円、宿泊客は46679円で、全体の平均は17267円。割引制度の利用は全市で1割にも満たない。
store-triples-1 | Created 1 nodes in 0 ms.
store-triples-1 | Create literal rel http://trustgraph.ai/e/%E6%B6%88%E8%B2%BB%E9%A1%8D%E3%83%BB%E5%89%B2%E5%BC%95%E5%88%B6%E5%BA%A6%E3%81%AE%E5%88%A9%E7%94%A8 http://www.w3.org/2004/02/skos/core#definition 日帰り客の消費額は8722円、宿泊客は46679円で、全体の平均は17267円。割引制度の利用は全市で1割にも満たない。
store-triples-1 | Created 0 nodes in 1 ms.
store-triples-1 | Create node http://trustgraph.ai/e/%E7%AB%8B%E3%81%A1%E5%AF%84%E3%82%8A%E5%85%88
store-triples-1 | Created 1 nodes in 0 ms.
store-triples-1 | Create literal 神戸市以外も訪問予定の割合は全市で2割弱で、北野が3割を超える。立ち寄り先は新神戸・三宮・元町周辺が最も高い。
store-triples-1 | Created 1 nodes in 1 ms.
(snip)
どうやらグラフが生成されている模様。
PDFが正しく処理されてグラフ生成が完了しているかを見るにはtg-graph-showを使うらしいのだが・・・
tg-graph-show
http://trustgraph.ai/e/%E7%A5%9E%E6%88%B8%E5%B8%82%E8%A6%B3%E5%85%89%E5%8B%95%E5%90%91%E8%AA%BF%E6%9F%BB http://www.w3.org/2004/02/skos/core#definition A survey conducted to understand the characteristics of tourists visiting Kobe and the tourism trends within the city, aimed at informing future tourism administration.
http://trustgraph.ai/e/%E7%A5%9E%E6%88%B8%E5%B8%82%E8%A6%B3%E5%85%89%E5%8B%95%E5%90%91%E8%AA%BF%E6%9F%BB http://www.w3.org/2000/01/rdf-schema#label 神戸市観光動向調査
http://trustgraph.ai/e/%E7%A5%9E%E6%88%B8%E5%B8%82%E8%A6%B3%E5%85%89%E5%8B%95%E5%90%91%E8%AA%BF%E6%9F%BB http://www.w3.org/2004/02/skos/core#definition 来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施された調査。
(snip)
処理されていることはわかるのだが、進捗的なものがわからない。あと、http://trustgraph.aiという風に出力されているのもちょっと気になる。
tg-graph-showの結果をwcコマンドに渡すと、これがエッジの数になるらしい。
tg-graph-show | wc -l
915
ちょっと気になるところではあるが、ログを見ているとだいたい処理が終わったように見えたので、GraphRAGのテストクエリを送信してみる。
tg-query-graph-rag -q "神戸に来る観光客の主な交通手段を教えて"
神戸に来る観光客の主な交通手段は、鉄道利用者が約4割を超えていることが示されています。また、車やバイクの利用も約4割となっています。
tg-query-graph-rag -q "神戸を選んだきっかけは?"
神戸を選んだきっかけは、家族・友人・知人の話や、インターネットの影響が高いことが挙げられます。また、前に来てよかったという理由も観光の動機として重要です。
tg-query-graph-rag -q "報告内容のポイントを要約して"
以下は報告内容のポイントの要約です:
1. **地区の定義と特徴**:
- **有馬**: 神戸の温泉地で、宿泊費や交通費が高い。宿泊者の53.2%が夜間滞在。
- **北野**: 歴史的建築が多く、訪問率が高い。宿泊者の43.0%が夜間滞在。
- **須磨・舞子**: 海岸の景観が魅力で、66.0%の満足度を誇る。
2. **旅行者の傾向**:
- 全市での旅行者の約60%が再来訪意向を持っている。
- 旅行形態はフリープランや団体旅行が多く、予約なしの割合が高い(約70%)。
- 旅行の同行者は友人や家族が多い。
3. **満足度と利用状況**:
- 全市の旅行全体の満足度は「満足」が5割を超えており、特に神戸港や須磨・舞子で高い。
- インターネットが主要な情報収集手段であり、約40%が利用している。
4. **交通手段と宿泊**:
- 鉄道利用者が多く、特に北野地区で63.5%。
- 有馬地区では宿泊施設の充実度が高く、宿泊者の57.6%が予約あり。
5. **年齢構成と性別構成**:
- 60歳以上の割合が全市で24.3%を占め、女性の割合が56.5%と高い。
この報告は、神戸の観光地における旅行者の行動や満足度、利用状況を示しており、特に有馬、北野、須磨・舞子の各地区の特徴が強調されています。
他にできることを色々見てみる。
Grafana
http://localhost:3000にアクセス。ID・PWはadmin/admin。
でこんな感じでメトリクスが可視化される。
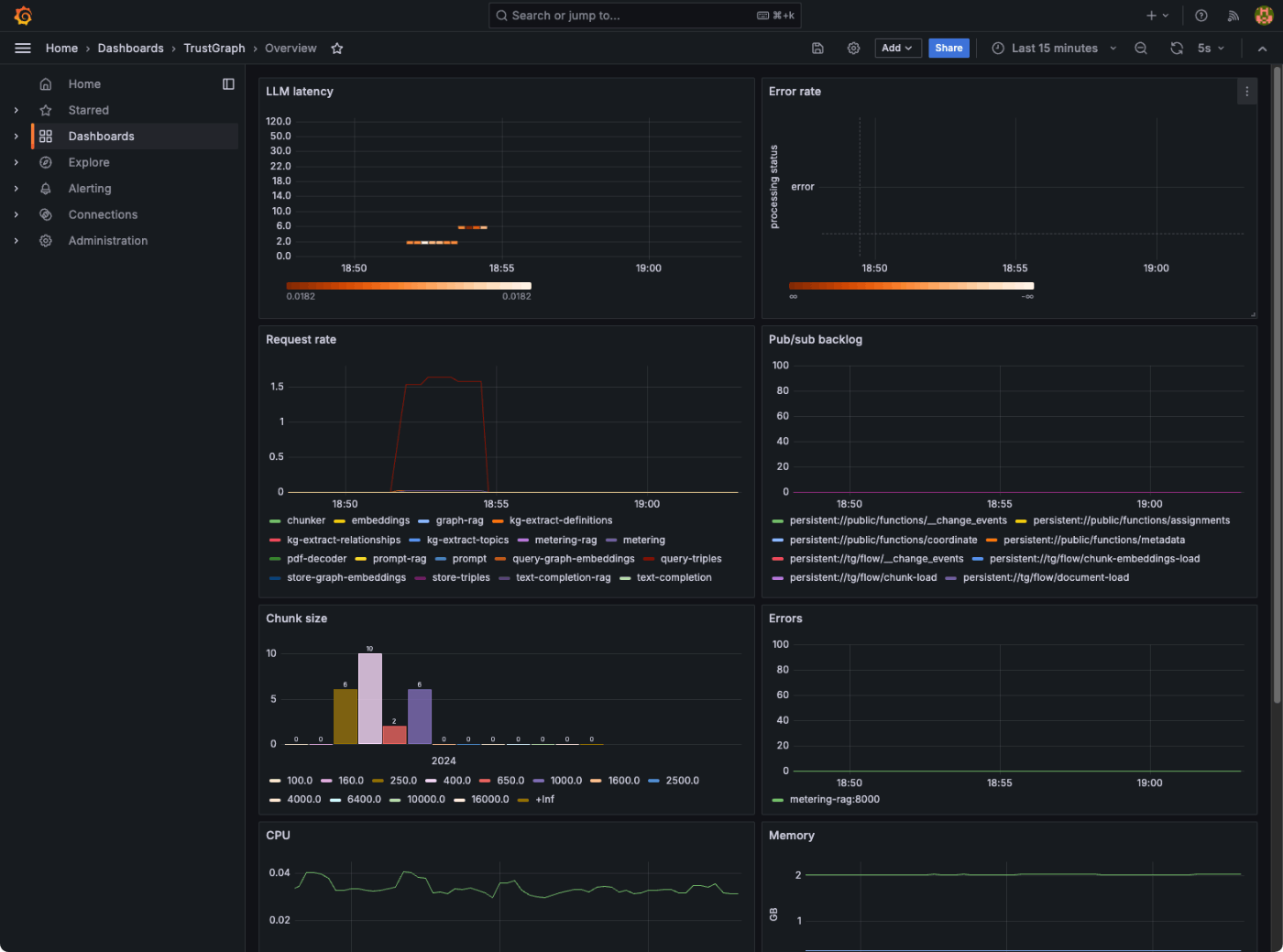
主なメトリクスは以下
- LLMレイテンシー
- エラー率
- サービスリクエスト率
- キューのバックログ
- チャンキングヒストグラム
- サービス別エラーソース
- サービス別CPU使用率
- サービス別メモリ使用量
- 導入されたモデル
- トークンのスループット(トークン/秒)
- コスト・スループット(コスト/秒)
Neo4j
http://localhost:7474にアクセス。ID/PWはneo4j / passwordで。
でこんな感じでグラフが可視化される。

まとめ
実際に動かすまでのほうに時間がかかってしまった。もしかすると開発元はOpenAI以外のものを使用しているのかもしれない。とはいえ、最も主要なモデルプロバイダーといってもいいぐらいなので、そのあたりはきっちり確認して欲しいし、Issueをみてもらうと分かる通り、少し回答も二転三転して、自分の方でコード読んで動かせたのは正直イマイチ感を感じる。
で、TrustGraphそのものとしては、やはり商用なのでGrafanaやPrometheusなど運用に必要なものが用意されているのは良いと思うし、各コンポーネントがそれぞれコンテナ化されているということで、Kubernetesのようなプラットフォームで動かせば耐障害性などは大きく上がると思う。
反面、できることが「ドキュメントを見る限り」はそれほど多くはない印象もあって、個人的にはこれだけのためにこの規模かぁ・・・・と思ってしまったところもある。もしかするとドキュメントになくてできることがあるのかもしれないが、書いてなければこちらとしてはわかりようがない。
まあRAGに関連するプロジェクトを色々みていても、大規模環境を想定しているもの≒Kubernetesとか、にデプロイできるようなものはあまり見当たらないので、こういうアプローチはあってもいいかなとは思う。あとはもう少し目を引くような機能がほしいなと思った。
Getting Startedとかでうまく行かないと、ちょっとダメなのでは?、というバイアスが自分にかかってる気がしたので、ちょっと反省。
改めて考えてみた。
Kubernetesなどの大規模なプラットフォームがすでにあるならば、そこに乗せるのは簡単だと思うし、監視周りなども用意されてるので、かなり手数は減りそう。なので、かけた(作業等の)コストに関しては、他のRAGまたはGraphRAGソリューションをKubernetesで動かせるように準備する場合と比較して・・・っていうのが正しい比較だよね。
あとはv15.4以降では、複数のツールを持ったReActエージェントを作るためのツールなどが提供されているようなので、そのあたり担ってくるとRAGの回答精度も踏まえて、評価すべきではあるな。
ただまあそこまでやって比較するか?と言われると、うーん、というところ。ここはファーストインプレッションに結構起因しているのは否定しない。