ETL/RAG/LLMアプリ向けのドキュメント処理エンジン「Sycamore」を試す
GitHubレポジトリ
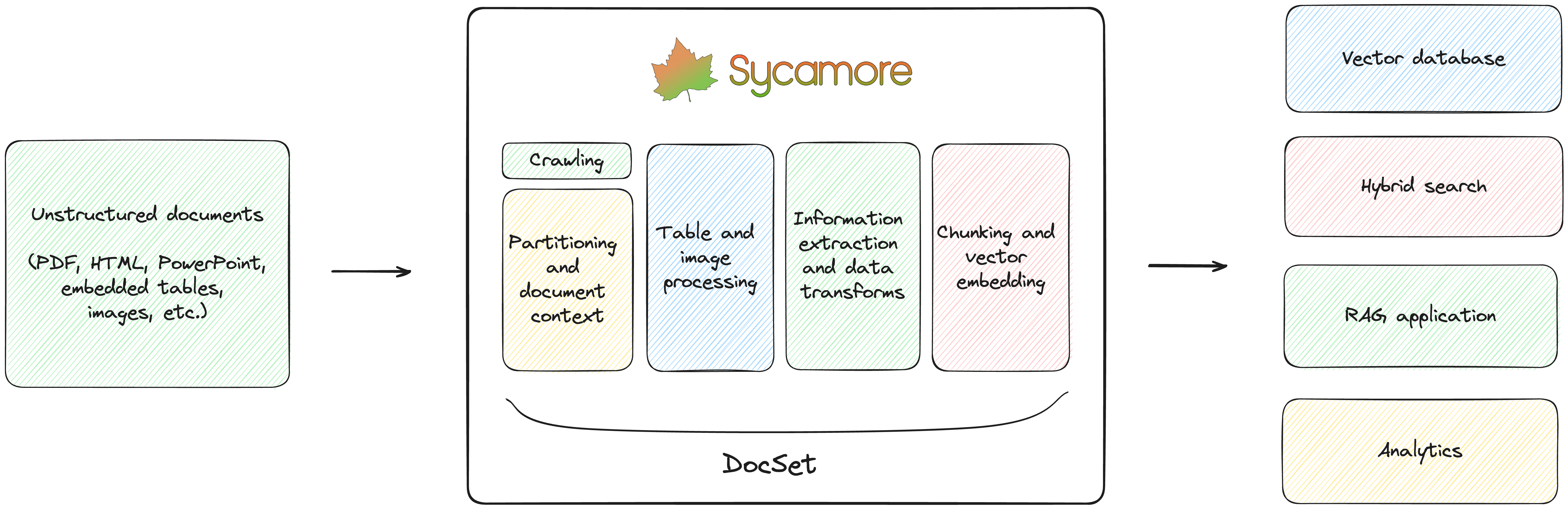
Sycamoreは、ETL、RAG、LLMベースのアプリケーション、および非構造化データの分析のための、AI搭載のオープンソースの文書処理エンジンである。Sycamoreは、レポート、プレゼンテーション、議事録、マニュアルなど、幅広い種類の文書を分割し、内容を充実させることができる。また、表、図、グラフ、その他のインフォグラフィックが埋め込まれたPDFや画像などの複雑な文書を分析し、分割することも可能である。ノートブックの例を参照。
PDFの処理には、サーバーレスでGPUを搭載したAPIであるAryn Partitioning Serviceを活用し、文書のセグメント化とラベル付け、OCR、表や画像の抽出などを行う。これは、80,000件以上の企業文書で訓練されたArynの最先端のオープンソース深層学習AIモデルであるDETRを活用しており、他のシステムと比較すると、ハイブリッド検索またはRAGにおいて、6倍の精度でデータを区分し、2倍の再現率を実現できる。 こちらから無料でサインアップするか、Aryn Partitionerをローカルで実行することも可能だ。
Aryn Partitioning ServiceはPDFを受け取り、パーティショニングされた出力をJSONで返す。追加のデータ抽出、強化、変換、クレンジング、および下流のデータベースへのロードにはSycamoreを使用できる。これらの変換で使用するLLMを選択できる。
Sycamoreは、OpenSearch、ElasticSearch、Pinecone、DuckDB、Weaviateなどのベクターデータベースやハイブリッド検索エンジンを、より高品質なデータで確実にロードする。
Sycamoreフレームワークは、DocSetと呼ばれる拡張性と堅牢性を備えたドキュメント処理の抽象化を中心に構築されており、データ処理、強化、クレンジングのための強力な高レベル変換をPythonで提供している。DocSetは、信頼性の高いチャンクのロードという差別化できない重労働を排除する拡張可能なデータ処理技術もカプセル化している。DocSetの関数型プログラミングのアプローチにより、チャンキングを迅速にカスタマイズし、より質の高いRAG結果を得るための実験を行うことができる。
refered from https://github.com/aryn-ai/sycamore機能
- Aryn Partitioning Serviceと統合され、最先端のビジョンAIモデルを使用してドキュメントのセグメンテーションを行い、意味構造を保持する
- DocSetの抽象化により、非構造化ドキュメントを拡張性と信頼性をもって変換および操作する
- 高品質な表抽出、OCR、視覚的サマライゼーション、LLM搭載のUDF、およびその他の高性能なPythonデータ変換
- 選択したAIモデルを使用してベクトル埋め込みを迅速に作成する
- 自動データクローラ(Amazon S3およびHTTP)、ジョブの作成と反復処理用のJupyterノートブック、テスト用のOpenSearchハイブリッド検索およびRAGエンジンなど、便利な機能
- スケーラブルなRayバックエンド
モデルはこれらしい
トレーニングデータはこれ。
詳細がわからないのだけど、モデルの論文には以下とある
言語に関しては、文書の選択を管理していない。DocLayNetに含まれる文書の大部分(95%近く)は英語で書かれている。しかし、DocLayNetには、ドイツ語(2.5%)、フランス語(1.0%)、日本語(1.0%)など、他の言語で書かれた文書も多数含まれている。文書の言語は、物体検出やセグメンテーションモデルなどのコンピュータビジョン手法のパフォーマンスにはほとんど影響しないが、テキストの特徴を利用するレイアウト分析手法には課題となる可能性がある。
一応マルチリンガルでもいけなくもなさそう?