MiniMaxのTTS「Speech-02」を試す
Artificial AnalysisのTTSでクオリティがトップになっていた。
テクニカルペーパー。
o3による冒頭部分の翻訳。
私たちは MiniMax-Speech を紹介します。これは自己回帰型の Transformer アーキテクチャを採用した Text-to-Speech(TTS)モデルで、高品質な音声を生成します。主な革新点は学習可能な 話者エンコーダ にあり、参照音声の転写(文字起こし)を必要とせずに音色(ティンバー)特徴を抽出できます。これにより MiniMax-Speech は、ゼロショット で参照音声と一貫した音色を保ちながら非常に表情豊かな音声を合成できるうえ、ワンショット音声クローン でも参照音声ときわめて高い類似度を達成します。さらに提案する Flow-VAE により合成音声の全体的な品質が向上します。
本モデルは 32 言語 をサポートし、複数の客観評価・主観評価指標で優れた性能を示しました。特に音声クローンの客観指標(Word Error Rate と Speaker Similarity)で SOTA(最先端) の結果を達成し、公開リーダーボード TTS Arena で首位を獲得しています。
もう一つの大きな強みは、話者エンコーダが生成する ロバストで分離された表現 により、ベースモデルを改変せずに拡張できる ことです。これにより次のような多彩な応用が可能になります。
- 任意音声の感情制御:LoRA を用いて感情を付与
- Text to Voice (T2V):テキスト記述から直接音色特徴を合成
- プロフェッショナル音声クローン (PVC):追加データで音色特徴を微調整
これらにより MiniMax-Speech は、幅広い場面で高品質で柔軟な TTS ソリューションを提供します。
論文についてはalphaXivのまとめを参照。
MiniMaxのモデル・サービス
APIサービスとして提供されている。
ざっと見た感じ「マルチモーダル」をウリにしたAIプラットフォームという感じ。提供しているものはこんな感じ。
- モデル
- テキストチャット
- MiniMax-Text-01
- 言語モデル
- MoEモデル: 総パラメータ数 456B、アクティブパラメータ数 45.9B
- 入力トークン: 4M
- MiniMax-VL-01
- ビジュアルマルチモーダル言語モデル
- 上記に加え、ViTの総パラメータ数 303M
- MiniMax-Text-01
- 音声合成
- MiniMax Speech-02-HD / Speech-02-Turbo
- ゼロショット音声合成も可能なTTS
- 多言語対応(日本語含む)
- おそらくTurboが高速性、HDが精度を謳ったものだと思われる
- MiniMax Speech-01-HD / Speech-01-Turbo
- おそらくSpeech-02の前のバージョン
- MiniMax Speech-02-HD / Speech-02-Turbo
- 音楽生成
- Minimax Music-01
- 楽曲とボーカルの両方が生成可能
- Minimax Music-01
- 動画生成
- T2V-01-Director / I2V-01-Director
- テキスト・画像から動画を生成しつつ、カメラワークなどを制御できる
- S2V-01
- 主題となる被写体の一貫性に優れた動画を生成。
- I2V-01-live
- 画像から動画を生成、特に2D表現に優れる(ライブドローイング的なものとか)
- T2V-01
- テキストから動画を生成
- I2V-01
- 画像から動画を生成
- T2V-01-Director / I2V-01-Director
- 画像生成
- Image-01
- テキストから画像を生成
- Image-01
- テキストチャット
- サービス・製品
- Hailuo AI
- 動画・画像を生成するためのプラットフォーム
- MiniMax Audio
- 音声を生成するためのプラットフォーム
- MiniMax Chat
- ChatGPTライクなテキストチャットサービス
- MiniMax MCP Server
- MCPでMiniMaxのサービスを利用できる
- talkey
- キャラクターを作成して、キャラクターとのチャットが楽しめるサービス
- APIプラットフォーム
- 上記モデルにAPIアクセスするためのプラットフォーム
- Hailuo AI
マルチモーダルがウリなだけあって幅広くやってんだな、というかtalkieは前から知ってたけどMiniMaxだったのね。
MiniMax-Text-01 と MiniMax-VL-01 はオープンモデルとしてHuggingFaceに公開されている。
コードやベンチマークはGitHubレポジトリにある
コードのライセンスはMITだけど、モデルは独自ライセンス(MiniMax Model License)っぽい。元のライセンスの条項に従う限りは商用利用可能に読めるけどどうなんだろう?
(でもこれを動かせる環境を用意するのが難しそう・・・)
料金
APIプラットフォームの料金はこちら
あと、各プラットフォーム毎に料金は異なるみたい。ここのプラットフォームでサインアップが必要だったように思うのだが、プラットフォーム間のアカウント連携はどうなっているんだろう?
とりあえずMiniMax Audioでアカウントを作成してみた。

右上にクレジットが表示されている。少し試してみたので減っているけど、無料アカウントを作成すると初回は10000クレジット(約12分の生成、ただし言語によって異なる)が付与される様子。プランは左の「Subscribe」をクリックすると表示されて、以下のようになっている。

上記の下にFAQがあって以下のように記載されていた(内容は今後変わるかもしれないので適宜確認のこと)。ChatGPTによる翻訳。
Q. テキストとクレジットの換算関係は?
テキストとクレジットの換算率は使用する言語によって異なります。一般的には 英字1文字=1クレジット、中国語・日本語の文字1文字=2クレジット です。具体的な換算率は入力ボックス左下隅でご確認ください。
Q. 生成した音声をプロジェクトで使ったり、SNSに投稿したりしてもいいですか?
個人利用(SNS投稿や非営利プレゼンなど)の場合は自由にご利用いただけますが、当社のロゴを表示するか、出典として当社をクレジットしてください。
商用利用(収益化コンテンツやビジネス目的など)の場合は、スタータープラン以上へのご加入をお願いいたします。
Q. 一度にどれくらいのテキストを音声に変換できますか?
変換できる文字数は 保有クレジット残高に基づき、モデルの料金表に従って文字数へ換算されます。換算後の文字数がモデルの上限(HD: 5,000文字、Turbo: 10,000文字)を超える場合、上限値が表示されます。
Q. なぜ1回の音声生成あたりのテキスト長に制限があるのですか?
最高のモデル性能を維持するために、HDで5,000文字、Turboで10,000文字という制限を設けています。より長いテキストを変換したい場合は、テキストを複数のセクションに分割して順に処理してください。現在、一度に長文を扱える機能も検討中です。
APIで利用するケースは多分別だと思うけど、少なくともこのプラットフォームで生成した音声について、商用用途なら有償プランにする必要がある点に注意。
ではトップに戻って、メニューを見ながら、MiniMax Audioプラットフォームで何ができるのか?を少し見てみる。
まず「Home」。ここには「Create Lifelike Speech」というメニューがあり、テキストを入力できるフォームが用意されている。ここにテキストを入力すれば、おそらく音声が生成されるのだろうと予測される。

が、「Text to Speech」は左のメニューにもある。何が違うのか?
ということで、デモが3つほど用意されているので、それを試してみる(ちなみに用意されたデモはクレジットが減らない。もしかすると実際に生成されているわけではなく、あらかじめ用意されているものなのかもしれない)。まずは「Tell a Story」。

テキストが入力されて、どうやらファイルもアップロードされているように見える。これはファイルから読み込んでくれるということなのかな?あと、それを元に音声が生成されているようで、一番下で再生コントローラが見える。

入力されている文章はこんな感じ
The thunderous hooves of twenty thousand cavalry shook the frozen ground at Austerlitz, as Napoleon stood atop the Pratzen Heights, his heart pounding with fierce determination.The bitter December wind carried the acrid smell of gunpowder across the battlefield, while the morning fog slowly lifted to reveal the vast armies before him. The fate of Europe hung in the balance.
(日本語訳)
アウステルリッツの凍てついた大地を、2万の騎兵の轟く蹄が震わせた。ナポレオンはプラッツェン高地の上に立ち、激しい決意で胸を鼓動させていた。厳しい12月の風が、戦場に火薬の刺激的な臭いを運び、朝の霧がゆっくりと晴れて、彼の前に広がる広大な軍勢が姿を現した。ヨーロッパの運命は、まさにこの瞬間に懸かっていた。
生成された音声はこちら
感情豊かな音声が生成されているのがわかる。そして背景にBGM的なものも流れている!こんな機能使えるの?これはちょっと後で確認してみる。
他のでもはこんな感じ。

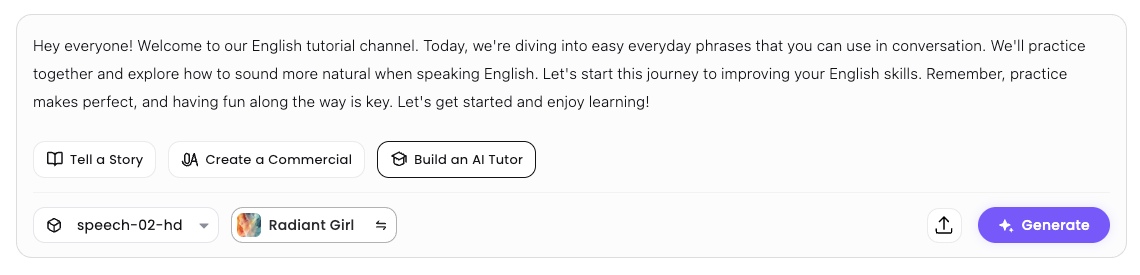
自分でも試してみた。上の日本語訳を入力。で、音声の箇所を選択。

音声はこんな感じ、言語・アクセント・性別・年齢でフィルタできる。アイコンをクリックするとプレビューが聞ける。適当な音声の「Use」をクリック。

なお、モデルも選択できるが、ここは最新の"speech-02-hd"を選択。

では「Generate」をクリック

Text to Speechの画面に移動した。なるほど、Homeにあるのは単にショートカットとデモを体験できるだけのもの、って感じなのね。右にパラメータを設定できる箇所があるけども、一旦そのままで「Generate」

こんな感じで生成される

実際に生成されたもの。
声や表現はとても自然なのだけど、ちょいちょい読み間違えがあるな、この辺はLLMベースのTTSだとしょうがないかな。あとBGMがついてないけど、もしかするとあれはあくまでもデモ用途っていう可能性があるかも。
とりあえず右側の生成時の設定で何ができるかを見てみる。
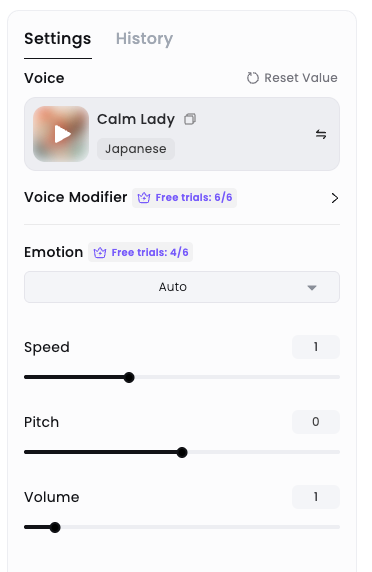
- 音声
- 発話速度
- 発話ピッチ(声の高さ)
- 発話ボリューム
あたりは普通に設定ができる。あと、料金プランによって、利用に制限がかかるものがある。まず、感情。

デフォルトは"Audo"(自動)になっているが、これを
- "Happy" (喜び)
- "Sad"(悲しみ)
- "Angry"(怒り)
- "Fearful"(恐怖)
- "Disgusted"(嫌悪)
- "Surprised"(驚き)
- "Neutral"(ニュートラル)
から選択できる。無料プランだとトライアルということで利用回数に制限がある様子。"Happy"を選択して生成させてみた結果は以下。
んー、あんまり変わった気はしないね。まあこの辺は選択する音声や文章にもよりそう。
で、もう一つの"Voice Modifier"。

こちらでは
- 声の深さ・軽さ
- 声の強さ・柔らかさ
- 声の籠もり具合
- エコー
- 電話っぽい環境
- ロボット的な音声
みたいな設定ができるみたい。
あと、生成前にクレジット消費がわかるのはいいね。

上記は"speech-02-hd"の場合だけど、"speech-02-turbo"だとちょっとクレジット消費が減る。
"speech-02-turbo"でも生成してみた結果。
他のメニューについても。
「Voices」では、用意されている音声をブラウズしたり、あと、音声クローンができる。音声クローンは後で少し試してみる。

「Voice Isolator」では、音声ファイルから背景ノイズなどを除去して、音声だけを抽出することができる。まあユーティリティだね。

では音声クローンを試す。
無料プランでも3つの音声クローンが作成できる様子。


使用する音声のインポート方法は以下の2つ
- 音声ファイルをアップロード(1ファイルあたり20MB)
- その場でマイクで録音(10〜60秒程度)
今回はマイクで録音してみる。「Record audio」をクリックするとこんな感じで録音が介される。最低10秒は発話する必要がある。

こんな感じでファイルが作成された。最大で10ファイルまでインポートできるみたい。また、ここで背景ノイズの削除なんかもできるみたい。

どれぐらい登録すればいいのかわからないが、今回は20秒ほど録音してみたので、このまま進める。
名前と言語を設定して、規約に同意して「Convert」。完了するまで少し待つ。

完了するとこんな感じ。プレビューが再生されるのだが、再現率はかなり高いのではないだろうか?

作成した音声はもちろんTTSで使用できる。

作成した音声クローンは基本的には自分だけしか使えない、と考えてよいのかな?ElevenLabsみたいな音声をシェアする機能はなさそう。
APIプラットフォームはこちら
ちょっと試してみようと思ったのだけど、こちらは無料では使えないみたい。ただし、Developer Programがあって、色々入力して申請すると最大$100のクレジットがもらえるかもしれない。
APIドキュメントはこちら
TTSのAPIについては
- 通常の推論
- HTTP REST API(非ストリーミング・ストリーミング生成)
- WebSocket
- 長文用推論
- 最大 100万文字の入力
- タスク登録して非同期で結果を取得
- 音声クローン
- 音声ファイルアップロード
- 音声ファイルから音声クローン実行
という感じで、SDKはなく、全部APIで実行できるような感じ。ただ、例えば、利用可能な音声とか作成した音声クローンの一覧を取得するとか、みたいなエンドポイントは見当たらないな。
MiniMax Audioで作成した音声クローンがAPIでも使えるのか?みたいなのはちょっと気になる(アカウント的にはどう連携しているのかがよくわからない)
まとめ
あくまでも個人の所感
- 用意されている日本語音声の質は結構高そう、というか声優っぽい感じがする。
- 生成された発話も自然な感じで良い。
- ただ、LLMベースのTTSらしく、テキストの読み間違いは結構多い。もうこのあたりは宿命かも。
- 感情などを設定できるのは良いのだけど、自分が試した限りではあまり効果的ではなかった。このあたりは選択する音声やテキストにもよりそうなので、各自で試して判断をオススメ。
- 音声クローンの再現度は高かった。
- APIは現状最低限という感じ。
自分はTTSを確認するのが目的だったのでここまでだけど、動画・音楽・画像と他にもいろいろあるので、ユースケースに合えば試してみると良さそう。個人的には、テキストモデルを手元で動かしてみたいところだけど、流石にあのサイズをローカルで動かすのは難しそう。
後継らしき「Speech 2.5」が出ている
軽くPlaygroundで試してみた限り、自然さは以前よりも増していると思うけど、やっぱり読み間違いはちょいちょいある、Speech-02よりも多少はマシになったかなぁ???ぐらいの印象。