Mistralの音声認識モデル「Voxtral」を試す
世界最高の(そしてオープンな)音声認識モデルをご紹介します!
Voxtralは、現在の主要なオープンソース音声認識モデルであるWhisper large-v3を音声認識性能において総合的に上回っています。GPT-4o mini TranscribeとGemini 2.5 Flashをすべてのタスクで凌駕し、英語の短文音声認識とMozilla Common Voiceにおいて最先端の性能を達成し、ElevenLabs Scribeを凌駕し、強力な多言語対応能力を示しています。
Voxtral 3B および Voxtral 24B モデルは、文字起こしを超える機能を備えています。
- 長文のコンテキスト: 32k トークンのコンテキスト長により、Voxtral は最大 30 分間の音声の文字起こし、または 40 分間の音声の理解に対応しています
- 組み込みのQ&Aと要約機能: 音声コンテンツに関する質問を直接行ったり、構造化された要約を生成したりできます。ASRと言語モデルを別々にチェーンする必要はありません_
- ネイティブ多言語対応: 自動言語検出と、世界で最も広く使用されている言語(英語、スペイン語、フランス語、ポルトガル語、ヒンディー語、ドイツ語、オランダ語、イタリア語など)における最先端の性能を提供し、単一のシステムでグローバルなユーザーに対応できます
- 音声から直接関数呼び出し: ユーザーの音声意図に基づいてバックエンド機能、ワークフロー、またはAPI呼び出しを直接トリガーし、中間解析ステップなしで音声インタラクションを実行可能なシステムコマンドに変換します。
・テキスト処理能力が非常に高い: 言語モデル基盤であるMistral Small 3.1のテキスト理解機能を維持しています。
API 呼び出しで Voxtral を試してみてください: https://console.mistral.ai
Le Chat で試してみてください: http://chat.mistral.ai
または Hugging Face からダウンロードしてください: https://huggingface.co/mistralai。
詳細については、当社のブログをご覧ください。
モデル。3Bと24Bがある。モデルカードの前に実行環境だけ確認。
注: GPU で Voxtral-Mini-3B-2507 を実行するには、bf16 または fp16 で約 9.5 GB の GPU RAM が必要です。
注: GPU で Voxtral-Small-24B-2507 を実行するには、bf16 または fp16 で約 55 GB の GPU RAM が必要です。
ということで、24Bは動かせなさそうなので、Voxtral-Mini-3B-2507を試そうと思う。
改めてモデルカードの翻訳(DeepL使用)
Voxtral Mini 1.0 (3B) - 2507
Voxtral Mini は、Ministral 3B を強化し、最先端の音声入力機能を搭載しながら、クラス最高のテキスト性能を維持しています。音声の文字起こし、翻訳、音声理解に優れています。
Voxtral の詳細については、こちらのブログ記事をご覧ください。
主な機能
Voxtral は、Ministral-3B を基盤に、強力な音声理解機能を搭載しています。
- 専用の文字起こしモード: Voxtral は、パフォーマンスを最大化するための純粋な音声文字起こしモードで動作可能です。デフォルトでは、Voxtral はソース音声の言語を自動的に予測し、それに応じてテキストを文字起こしします。
- 長文のコンテキスト: 32k トークンのコンテキスト長により、Voxtral は文字起こしで最大 30 分、理解で最大 40 分の音声に対応可能です。
- 組み込みのQ&Aと要約: 音声から直接質問を投げかけることができます。音声分析と構造化された要約を生成し、ASRや言語モデルを別途用意する必要はありません
- ネイティブ多言語対応: 世界中で最も広く使用されている言語(英語、スペイン語、フランス語、ポルトガル語、ヒンディー語、ドイツ語、オランダ語、イタリア語)で自動言語検出と最先端の性能を実現
- 音声から直接関数呼び出し: ユーザーの音声意図に基づいて、バックエンド機能、ワークフロー、またはAPI呼び出しを直接トリガーできます
- テキスト処理能力が非常に高い: 言語モデル基盤のMinistral-3Bのテキスト理解機能を維持しています
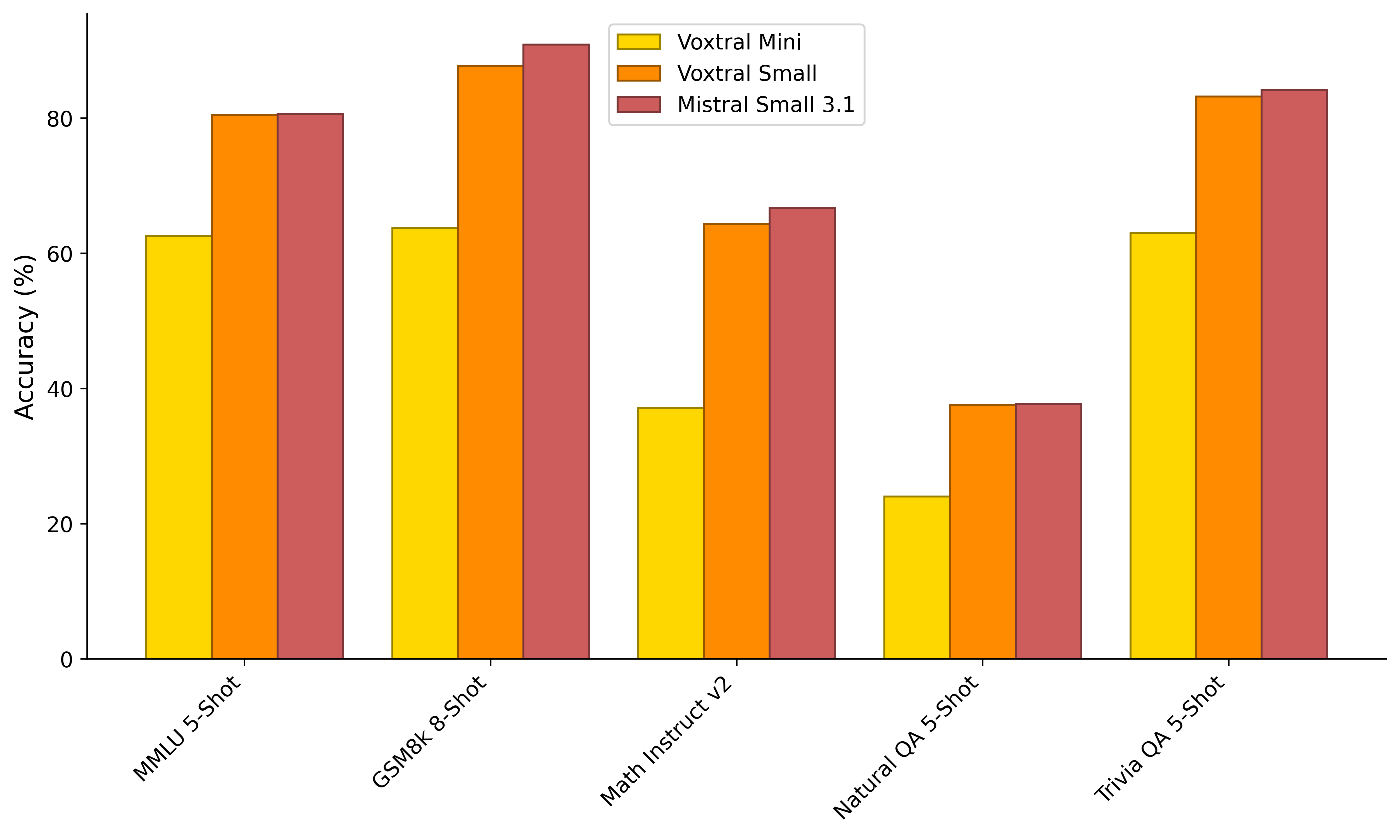
ベンチマーク結果
音声
FLEURS、Mozilla Common Voice、および Multilingual LibriSpeech ベンチマークにおける平均単語誤認識率 (WER):
referred from https://huggingface.co/mistralai/Voxtral-Mini-3B-2507テキスト
referred from https://huggingface.co/mistralai/Voxtral-Mini-3B-2507

vLLMサーバのセットアップ
今回はUbuntu-22.04+RTX4090で。
リリースされた当初は、vLLMのインストールコマンドがころころ修正されていたり、vLLM側がまだ追いついてなかったせいか起動すらしなかったのだが、やっと動くようになったみたい。
uvで作業ディレクトリ作成。
uv init -p 3.12 voxtral-work && cd $_
仮想環境作成
uv venv
vLLMインストール
uv pip install -U "vllm[audio]" \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
vLLMでサーバ起動
uv run vllm serve mistralai/Voxtral-Mini-3B-2507 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral
以下のように表示されればOK
(snip)
INFO 07-16 08:09:07 [api_server.py:1700] Starting vLLM API server 0 on http://0.0.0.0:8000
(snip)
INFO: Started server process [3992102]
INFO: Waiting for application startup.
INFO: Application startup complete.
クライアントのセットアップ
ではクライアント。こちらは同じLAN内のM2 Macで。
uvでプロジェクト作成
uv init -p 3.12 voxtral-client && cd $_
クライアント側は mistral_common[audio]パッケージが必要らしい。その他サンプルコードで使用されている他のパッケージも追加。
uv add mistral_common[audio] openai huggingface_hub
文字起こし
モデルカードの順番とは異なるが、まずは日本語が使えるかどうかを確認したいので、文字起こしから試してみる。
まずはモデルカード通りに英語の文字起こし。3分23秒ほどの音声が使用されている。
from mistral_common.protocol.transcription.request import TranscriptionRequest
from mistral_common.protocol.instruct.messages import RawAudio
from mistral_common.audio import Audio
from huggingface_hub import hf_hub_download
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://[vLLMサーバのIPアドレス]:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
obama_file = hf_hub_download(
"patrickvonplaten/audio_samples",
"obama.mp3",
repo_type="dataset"
)
audio = Audio.from_file(obama_file, strict=False)
audio = RawAudio.from_audio(audio)
req = TranscriptionRequest(
model=model,
audio=audio,
language="en",
temperature=0.0
).to_openai(exclude=("top_p", "seed"))
response = client.audio.transcriptions.create(**req)
print(response)
実行。処理時間も計測。
time uv run transcribe_en.py
obama.mp3: 100%|██████████████████████████████████| 4.88M/4.88M [00:00<00:00, 10.3MB/s]
Transcription(text="This week, I traveled to Chicago to deliver my final farewell address to the nation, following in the tradition of presidents before me. It was an opportunity to say thank you. Whether we've seen eye-to-eye or rarely agreed at all, my conversations with you, the American people, in living rooms and schools, at farms and on factory floors, at diners and on distant military outposts, All these conversations are what have kept me honest, kept me inspired, and kept me going. Every day, I learned from you. You made me a better president, and you made me a better man. Over the course of these eight years, I've seen the goodness, the resilience, and the hope of the American people. I've seen neighbors looking out for each other as we rescued our economy from the worst crisis of our lifetimes. I've hugged cancer survivors who finally know the security of affordable health care. I've seen communities like Joplin rebuild from disaster, and cities like Boston show the world that no terrorist will ever break the American spirit. I've seen the hopeful faces of young graduates and our newest military officers. I've mourned with grieving families searching for answers, and I found grace in a Charleston church. I've seen our scientists help a paralyzed man regain his sense of touch, and our wounded warriors walk again. I've seen our doctors and volunteers rebuild after earthquakes and stop pandemics in their tracks. I've learned from students who are building robots and curing diseases and who will change the world in ways we can't even imagine. I've seen the youngest of children remind us of our obligations to care for our refugees, to work in peace, and above all, to look out for each other. That's what's possible when we come together in the slow, hard, sometimes frustrating, but always vital work of self-government. But we can't take our democracy for granted. All of us, regardless of party, should throw ourselves into the work of citizenship. Not just when there's an election. Not just when our own narrow interest is at stake. But over the full span of a lifetime. If you're tired of arguing with strangers on the Internet, try to talk with one in real life. If something needs fixing, lace up your shoes and do some organizing. If you're disappointed by your elected officials, then grab a clipboard, get some signatures, and run for office yourself. Our success depends on our participation, regardless of which way the pendulum of power swings. It falls on each of us to be guardians of our democracy, to embrace the joyous task we've been given to continually try to improve this great nation of ours. Because for all our outward differences, we all share the same proud title. Citizen. It has been the honor of my life to serve you as president. Eight years later, I am even more optimistic about our country's promise. And I look forward to working along your side as a citizen for all my days that remain. Thanks, everybody. God bless you. And God bless the United States of America.", logprobs=None, usage=None)
real 0m10.657s
user 0m1.812s
sys 0m0.216s
文字起こし部分だけ抜粋
This week, I traveled to Chicago to deliver my final farewell address to the nation, following in the tradition of presidents before me. It was an opportunity to say thank you. Whether we've seen eye-to-eye or rarely agreed at all, my conversations with you, the American people, in living rooms and schools, at farms and on factory floors, at diners and on distant military outposts, All these conversations are what have kept me honest, kept me inspired, and kept me going. Every day, I learned from you. You made me a better president, and you made me a better man. Over the course of these eight years, I've seen the goodness, the resilience, and the hope of the American people. I've seen neighbors looking out for each other as we rescued our economy from the worst crisis of our lifetimes. I've hugged cancer survivors who finally know the security of affordable health care. I've seen communities like Joplin rebuild from disaster, and cities like Boston show the world that no terrorist will ever break the American spirit. I've seen the hopeful faces of young graduates and our newest military officers. I've mourned with grieving families searching for answers, and I found grace in a Charleston church. I've seen our scientists help a paralyzed man regain his sense of touch, and our wounded warriors walk again. I've seen our doctors and volunteers rebuild after earthquakes and stop pandemics in their tracks. I've learned from students who are building robots and curing diseases and who will change the world in ways we can't even imagine. I've seen the youngest of children remind us of our obligations to care for our refugees, to work in peace, and above all, to look out for each other. That's what's possible when we come together in the slow, hard, sometimes frustrating, but always vital work of self-government. But we can't take our democracy for granted. All of us, regardless of party, should throw ourselves into the work of citizenship. Not just when there's an election. Not just when our own narrow interest is at stake. But over the full span of a lifetime. If you're tired of arguing with strangers on the Internet, try to talk with one in real life. If something needs fixing, lace up your shoes and do some organizing. If you're disappointed by your elected officials, then grab a clipboard, get some signatures, and run for office yourself. Our success depends on our participation, regardless of which way the pendulum of power swings. It falls on each of us to be guardians of our democracy, to embrace the joyous task we've been given to continually try to improve this great nation of ours. Because for all our outward differences, we all share the same proud title. Citizen. It has been the honor of my life to serve you as president. Eight years later, I am even more optimistic about our country's promise. And I look forward to working along your side as a citizen for all my days that remain. Thanks, everybody. God bless you. And God bless the United States of America.
では、次に日本語。オーディオファイルは、自分が過去に開催した勉強会のYouTube動画から冒頭1分程度の音声を抜き出したをサンプルとして使う。
from mistral_common.protocol.transcription.request import TranscriptionRequest
from mistral_common.protocol.instruct.messages import RawAudio
from mistral_common.audio import Audio
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://[vLLMサーバのIPアドレス]:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
audio = Audio.from_file(
"voice_lunch_jp_1min.wav", # WAVファイルを指定
strict=False
)
audio = RawAudio.from_audio(audio)
req = TranscriptionRequest(
model=model,
audio=audio,
language="ja", # 日本語を指定
temperature=0.0,
).to_openai(exclude=("top_p", "seed"))
response = client.audio.transcriptions.create(**req)
print(response)
実行
time uv run transcribe_ja.py
Transcription(text='はい、じゃあ始めます。ちょっとまだこられていない方もいらっしゃるんでしょうが、ボイスランチJ-P始めます。皆さん、日曜日、はい、日曜日にお集まりいただきました。ありがとうございます。今日は久しぶりにオフラインということで、今日は特別なゲストを2人来ていただいています。ということで、今日はちょっとトピックに回りますけど、ボイスロのシオであるブレディンリムさんと、それからセールスフォースのカモセデザインのディレクターであるグレッグベネズさんに来ていただいています。ということで、日本に来ていただいてありがとうございます。', logprobs=None, usage=None)
real 0m2.139s
user 0m0.416s
sys 0m0.082s
はい、じゃあ始めます。ちょっとまだこられていない方もいらっしゃるんでしょうが、ボイスランチJ-P始めます。皆さん、日曜日、はい、日曜日にお集まりいただきました。ありがとうございます。今日は久しぶりにオフラインということで、今日は特別なゲストを2人来ていただいています。ということで、今日はちょっとトピックに回りますけど、ボイスロのシオであるブレディンリムさんと、それからセールスフォースのカモセデザインのディレクターであるグレッグベネズさんに来ていただいています。ということで、日本に来ていただいてありがとうございます。
一応日本語もいけるみたい。
ただし、音声ファイルをさらに5分の長さに伸ばしてみたところ、めちゃめちゃ時間がかかった挙げ句、どうやら途中で繰り返しになってしまった様子。
Transcription(text='はい、じゃあ始めます。ちょっとまだ来れていない方もいらっしゃるんでしょうが、ボイスランチJ.P.始めます。皆さん、日曜日、はい、日曜日にお集まりいただきました。ありがとうございます。今日は久しぶりにオフラインということで、今日は特別なゲストを2人来ていただいています。ということで、はい、今日はちょっとトピックに回りますけど、ボイスロのシオダル、ブレデンリムさんと、それからセールスフォースのカモセジョナルデザインのディレクターダル、グレックベネズさんに来ていただいています。ということで、日本に来ていただけてありがとうございます。はい、今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いていただきたいと思います。今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いていただきたいと思います。今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いていただきたいと思います。今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いていただきたいと思います。今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いていただきたいと思います。今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いていただきたいと思います。今日は(...snip...)でまたいろいろと聞いていただきたいと思います。今日はちょっとこの2人にまた後でいろい', logprobs=None, usage=None)
real 5m47.476s
user 0m0.461s
sys 0m0.126s
mistral_commonパッケージの中味を見てみたけど、指定できるパラメータに repetition_penalty とか frequency_penalty とかはなさそう、というか temperature / top_p / random_seed / max_tokens だけのように思える。公式の推奨は temperature=0 だけども 0.1 に変えたらいけた。
Transcription(text='はい、じゃあ始めます。ちょっとまだ来られていない方もいらっしゃるんでしょうが、ボイスランチJ.P.始めます。皆さん、日曜日、はい、日曜日にお集まりいただきました。ありがとうございます。今日は久しぶりにオフラインということで、今日は特別なゲストを2人来ていただいています。ということで、はい、今日はちょっとトピックに回りますけど、ボイスロのシオダル、ブレデンリームさんと、それからセールスフォースのカモセジョナルデザインのディレクターダル、グレックベネズさんに来ていただいています。ということで、日本に来ていただけてありがとうございます。はい、今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いてみたいと思います。今日はちょっとこのアジェンダなんですけど、ちょっと時間すぎちゃいましたけど、まず最初にボイスランチJ.P.についてということで、それから概要の部分です。少し説明させていただきます。1つ目のセッションで、まず私の方から、ボイスロの2022年の新機能とかですね、その辺の話を少しさせていただきます。それから2つ目のセッションで、グレデンさんとグルさんにいろいろカムバセーションデザインについて、何でも聞いてみたいというところを予定しています。それから15時から15時で一旦終了という形でさせていただきます。ちょっと一旦ボイスランチJ.P.だけ記念撮影は必須ですので、それだけさせていただきます。それからちょっと1時間ぐらい簡単にお菓子と飲み物を用意していますので、この新会というものをそのようにさせていただこうと思います。ボイスランチJ.P.についてですが、ボイスランチはボイスUIとか音声関連ですね、そんないった技術に実際に取り組んでいる人、もしくは興味がある人、この方のためのグローバルなコミュニティという形になっています。ボイスランチの日本リーダーという形でボイスランチJ.P.になっています。過去もずっとやっていますけど、オンラインオフラインでいろいろ音声のデザインだったり、技術だったりというところで情報とかを共有してみんなで業界を盛り上げていくぜというようなことをしています。今日はハッシュタグですね、#ボイスランチJ.P.でいろいろ自由にシェアしてください。それから会場ですね、今日のグラニカ様のご協力で利用させていただいています。ありがとうございます。ぜひこちらもシェアお願いします。それから、はい、新しい部分もいろいろとやっていただいています。とても感謝しています。ちょっと今、すみません、今コロナで会場に来られる方とかもあまりいなくてさせていないんですが、通常はここでIoT機能とかガジェットとかを展示していますので、そんないったものがあれば今度また体験してみていただければと思いますというところです。それから、すみません、トイレはこっちです。それからタバコ吸う人はいいところになっていますので、よろしくお願いします。はい、ということで、最初の挨拶はこれです。じゃあまず私の方のセッションからさせていただきますというところです。ボイスロアップデート2022というところです。今年の新機能について少しお話しします。自己紹介です。しまづと申します。こうべでインフラのエンジニアをやっていますので、普段はクバネテスとか、EDWASとか、テレホンとかいじってました。最近ちょっとフリーランスになりました。ちょっと調べてみたら、ボイスフロー一番最初に始めたのは2019年の秋の頃なんですね、大体4年弱ぐらいです。いろいろと触ってました。それから音声関連のコミュニティの部分では、ボイスランチJ.P.、今日のやつですね、以外に、EJAG、Amazon、Alexa、Japanユーザーグループとか、それからボイスフローの日本語ユーザーグループということで、VFJUGというものを選んでいます。日本語コミュニティの方はFacebookの方でやっていますので、もしよろしければ見ていただければと思います。それから2年ぐらい前ですね、技術書店の方で、ここには今スタッフで聞いていただいている皆さんと一緒に同人誌を作ろうということで作りました。もうこれちょっと2年ぐらいたって、内容がだいぶ古くなってしまっていますので、既にちょっと販売は終了しています。今日はちょっと持ってきたかったんですが、すみません、忘れてしまいました。はい、だからこんなこともやっています。', logprobs=None, usage=None)
real 0m12.516s
user 0m0.468s
sys 0m0.092s
文字起こし部分だけ抜粋
はい、じゃあ始めます。ちょっとまだ来られていない方もいらっしゃるんでしょうが、ボイスランチJ.P.始めます。皆さん、日曜日、はい、日曜日にお集まりいただきました。ありがとうございます。今日は久しぶりにオフラインということで、今日は特別なゲストを2人来ていただいています。ということで、はい、今日はちょっとトピックに回りますけど、ボイスロのシオダル、ブレデンリームさんと、それからセールスフォースのカモセジョナルデザインのディレクターダル、グレックベネズさんに来ていただいています。ということで、日本に来ていただけてありがとうございます。はい、今日はちょっとこの2人にまた後でいろいろと聞こうというコーナーがあって、そこでまたいろいろと聞いてみたいと思います。今日はちょっとこのアジェンダなんですけど、ちょっと時間すぎちゃいましたけど、まず最初にボイスランチJ.P.についてということで、それから概要の部分です。少し説明させていただきます。1つ目のセッションで、まず私の方から、ボイスロの2022年の新機能とかですね、その辺の話を少しさせていただきます。それから2つ目のセッションで、グレデンさんとグルさんにいろいろカムバセーションデザインについて、何でも聞いてみたいというところを予定しています。それから15時から15時で一旦終了という形でさせていただきます。ちょっと一旦ボイスランチJ.P.だけ記念撮影は必須ですので、それだけさせていただきます。それからちょっと1時間ぐらい簡単にお菓子と飲み物を用意していますので、この新会というものをそのようにさせていただこうと思います。ボイスランチJ.P.についてですが、ボイスランチはボイスUIとか音声関連ですね、そんないった技術に実際に取り組んでいる人、もしくは興味がある人、この方のためのグローバルなコミュニティという形になっています。ボイスランチの日本リーダーという形でボイスランチJ.P.になっています。過去もずっとやっていますけど、オンラインオフラインでいろいろ音声のデザインだったり、技術だったりというところで情報とかを共有してみんなで業界を盛り上げていくぜというようなことをしています。今日はハッシュタグですね、#ボイスランチJ.P.でいろいろ自由にシェアしてください。それから会場ですね、今日のグラニカ様のご協力で利用させていただいています。ありがとうございます。ぜひこちらもシェアお願いします。それから、はい、新しい部分もいろいろとやっていただいています。とても感謝しています。ちょっと今、すみません、今コロナで会場に来られる方とかもあまりいなくてさせていないんですが、通常はここでIoT機能とかガジェットとかを展示していますので、そんないったものがあれば今度また体験してみていただければと思いますというところです。それから、すみません、トイレはこっちです。それからタバコ吸う人はいいところになっていますので、よろしくお願いします。はい、ということで、最初の挨拶はこれです。じゃあまず私の方のセッションからさせていただきますというところです。ボイスロアップデート2022というところです。今年の新機能について少しお話しします。自己紹介です。しまづと申します。こうべでインフラのエンジニアをやっていますので、普段はクバネテスとか、EDWASとか、テレホンとかいじってました。最近ちょっとフリーランスになりました。ちょっと調べてみたら、ボイスフロー一番最初に始めたのは2019年の秋の頃なんですね、大体4年弱ぐらいです。いろいろと触ってました。それから音声関連のコミュニティの部分では、ボイスランチJ.P.、今日のやつですね、以外に、EJAG、Amazon、Alexa、Japanユーザーグループとか、それからボイスフローの日本語ユーザーグループということで、VFJUGというものを選んでいます。日本語コミュニティの方はFacebookの方でやっていますので、もしよろしければ見ていただければと思います。それから2年ぐらい前ですね、技術書店の方で、ここには今スタッフで聞いていただいている皆さんと一緒に同人誌を作ろうということで作りました。もうこれちょっと2年ぐらいたって、内容がだいぶ古くなってしまっていますので、既にちょっと販売は終了しています。今日はちょっと持ってきたかったんですが、すみません、忘れてしまいました。はい、だからこんなこともやっています。
ただ、temperatureに関係なく、結構語尾とか書き換わってしまっているかなぁ・・・意味は通ってるんだけど正しい発話ではない(固有名詞とかそういうのは除く)、っていうのがちらほらある感じ。
音声指示
詳細がわからないけども、入力は音声・テキスト、出力はテキスト、って感じかな?
モデルカードのサンプルはこんな流れっぽい
- 音声ファイルとテキストを入力して推論
- 音声
- オバマ大統領の演説の発話
- 天気について話した発話
- テキスト
- 「どちらのスピーカーがよりインスピレーションを与えますか?その理由は?彼らは互いにどのように異なりますか?」
- 音声
- 続けて、さらにテキストで以下を入力
- 「では、最初の音声の内容を要約してください。」
テキスト部分を日本語に置き換えてやってみる。
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage, AssistantMessage, RawAudio
from mistral_common.audio import Audio
from huggingface_hub import hf_hub_download
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://[vLLMサーバのIPアドレス]:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
obama_file = hf_hub_download(
"patrickvonplaten/audio_samples",
"obama.mp3",
repo_type="dataset"
)
bcn_file = hf_hub_download(
"patrickvonplaten/audio_samples",
"bcn_weather.mp3",
repo_type="dataset"
)
def file_to_chunk(file: str) -> AudioChunk:
audio = Audio.from_file(file, strict=False)
return AudioChunk.from_audio(audio)
text_chunk = TextChunk(text="どちらのスピーカーがよりインスピレーションを与えますか?その理由は?彼らは互いにどのように異なりますか?")
user_msg = UserMessage(
content=[
file_to_chunk(obama_file),
file_to_chunk(bcn_file),
text_chunk
]
).to_openai()
print(30 * "=" + "ユーザ1" + 30 * "=")
print(text_chunk.text)
print("\n\n")
response = client.chat.completions.create(
model=model,
messages=[user_msg],
temperature=0.2,
top_p=0.95,
)
content = response.choices[0].message.content
print(30 * "=" + "ボット1" + 30 * "=")
print(content)
print("\n\n")
messages = [
user_msg,
AssistantMessage(content=content).to_openai(),
UserMessage(content="では、最初の音声の内容を要約してください。").to_openai()
]
print(30 * "=" + "ユーザ2" + 30 * "=")
print(messages[-1]["content"])
print("\n\n")
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.2,
top_p=0.95,
)
content = response.choices[0].message.content
print(30 * "=" + "ボット2" + 30 * "=")
print(content)
実行
uv run audio_instruct.py
結果
==============================ユーザ1==============================
どちらのスピーカーがよりインスピレーションを与えますか?その理由は?彼らは互いにどのように異なりますか?==============================ボット1==============================
どちらのスピーカーもインスピレーションを与えますが、どちらがよりインスピレーションを与えるかは個人の感受によって異なります。以下にその理由と違いを示します:
- アメリカ大統領のスピーチ:彼はアメリカの人々との対話を通じて、自分自身をより良い人、より良い大統領にすることができたと述べています。彼は民主主義の重要性と、市民としての責任を強調しています。彼は自分たちの成功は市民の参加に依存すると述べています。
- バルセロナの天気予報:このスピーチは天気予報に関するものであり、インスピレーションを与えるような内容ではありません。天気予報は事実を伝えるためのものであり、感情や行動を引き起こすものではありません。
したがって、どちらのスピーチがよりインスピレーションを与えるかは、聴取者の個人的な感受や、その場の状況によって異なります。
==============================ユーザ2==============================
では、最初の音声の内容を要約してください。==============================ボット2==============================
最初の音声の内容は、アメリカ大統領がシカゴで行われた最後の辞令の内容を述べたものです。彼は、8年間の大統領任期中にアメリカの人々との対話を通じて、自分自身をより良い人、より良い大統領にすることができたと述べています。彼は、アメリカの人々の善良さ、回復力、希望を見てきたと強調し、市民としての責任を果たすことの重要性を説明しました。彼は、民主主義を守るために、自分たちの成功は市民の参加に依存すると述べています。最後に、彼は自分たちの成功は市民の参加に依存すると述べています。
なるほど。入力に使った音声はあくまでもコンテキストという感じで、実際の指示はテキストで与えているけど、おそらくそれも音声でできるのではないか?と思われる。
レスポンスは結構速いかな。
まとめ
あくまでも個人の印象。
日本語の音声文字起こしについては、過去自分が試した他のものと比較しても、ベンチマークで謳われているほどの精度は感じなかった。ここはベンチマークからすると正直期待外れだったが、これは日本語だから、というのもあるかもしれない。
音声指示についてはレスポンスが良いように感じたし、Function Callingにも対応しているのであれば、少なくとも使い勝手は良さそうに思える。まあこれは実際にそういうものを作って体験してみないと判断できないとは思う。
ASR→LLM→TTSみたいなパイプラインで、LLMが音声を直接扱えると、手間が1つ減るしレイテンシーを減らせる可能性もあるので、今後も同様のものが増えると嬉しい。
3Bは語尾や単語の書き換えが多い印象で(意味は通るけども)、個人的には精度それほど高くないと感じたけども、24Bだと良いのかな?
動かせる環境・・・