テキスト・動画から音声・音楽を生成する「AudioX」を試す
GitHubレポジトリ
🎧 AudioX: Anything-to-Audio 生成のためのDiffusion Transformer
これは "AudioX: Diffusion Transformer for Anything-to-Audio Generation" の公式リポジトリです。
📺 デモ動画
(訳注: GitHubのREADMEを参照)
✨ 概要
オーディオおよび音楽生成は多くのアプリケーションにおいて重要な課題として浮上していますが、既存の手法には重大な制約があります。それらはモダリティ間で統一的な能力を持たずに個別に機能し、高品質なマルチモーダル学習データが不足しており、多様な入力を効果的に統合するのが困難です。本研究では、Anything-to-Audioおよび音楽生成のための統一的なDiffusion TransformerモデルであるAudioXを提案します。従来のドメイン特化型モデルとは異なり、AudioXは高品質な一般オーディオおよび音楽の生成が可能であり、柔軟な自然言語制御やテキスト、動画、画像、音楽、音声といった様々なモダリティのシームレスな処理が可能です。本モデルの主要な革新点は、モダリティを超えて入力をマスクし、マスクされた入力から学習を行うマルチモーダルマスキング訓練戦略にあります。これにより、頑健で統一されたクロスモーダル表現の獲得が可能になります。データ不足への対応として、VGGSoundデータセットに基づく19万件のオーディオキャプションを含むvggsound-capsと、V2Mデータセット由来の600万件の音楽キャプションを含むV2M-capsという2つの包括的なデータセットを整備しました。広範な実験の結果、AudioXは最先端の専門モデルに匹敵またはそれを上回る性能を示し、多様な入力モダリティおよび生成タスクへの高い汎用性を統一的なアーキテクチャで実現することが確認されました。
✨ ティーザー
referred from https://github.com/ZeyueT/AudioX
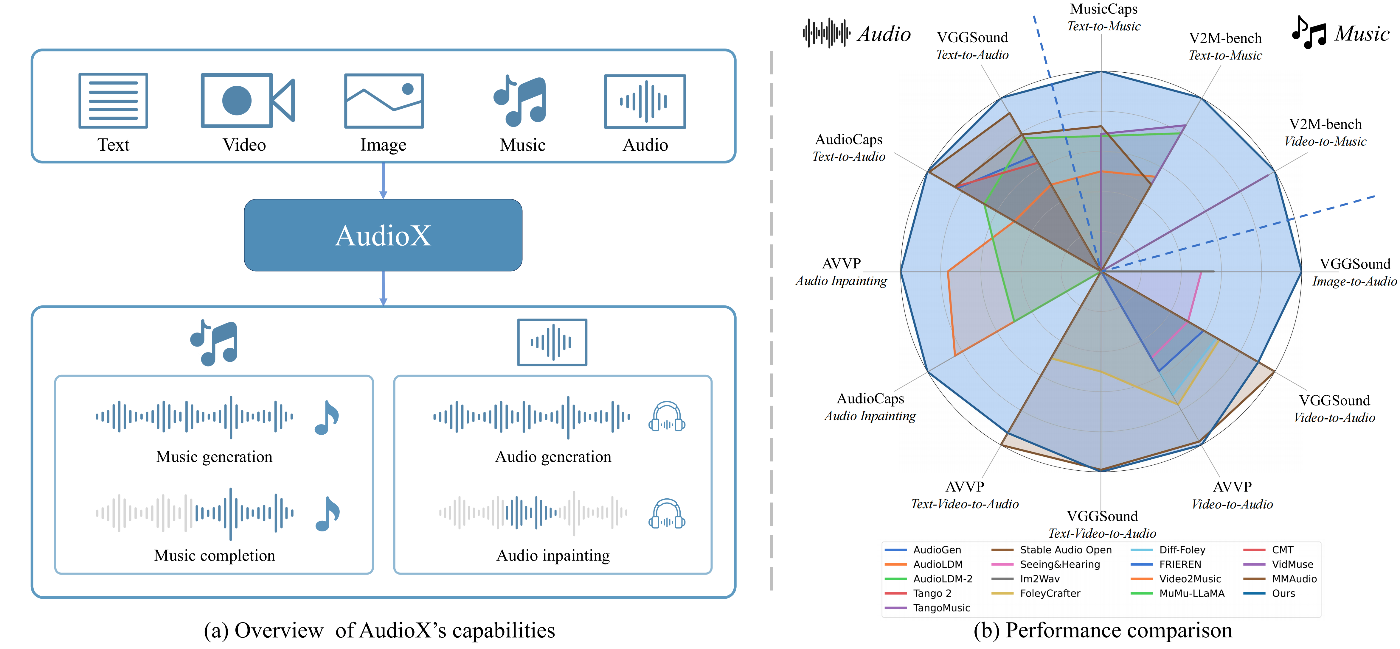
(a) AudioXの概要図。様々なタスクにおける能力を示しています。(b) 複数のベンチマークにおける各手法の性能比較レーダーチャート。AudioXは多様なオーディオおよび音楽生成タスクにおいて、優れたInception Score(IS)を示しています。✨ 手法
referred from https://github.com/ZeyueT/AudioX
AudioXフレームワークの概要

ライセンス
CC-BY-NC に従ってください。
論文はalphaXivのまとめを参照
手軽に試すなら、HuggingFace Spaceのデモがオススメ
Ubuntu-22.04(RTX4090・CUDA-12.4)で試す。
レポジトリクローン
git clone https://github.com/ZeyueT/AudioX AudioX-work && cd AudioX-work
uvでPython仮想環境を作成。なお、試してみた限りだと、Python-3.11 / 3.12では動かず。READMEで記載のあるPython-3.8で実施。
uv venv -p 3.8
uv pip install pop
source .venv/bin/activate
パッケージインストール
pip install git+https://github.com/ZeyueT/AudioX.git
あと自分はインストール済みだったのだけど、以下も必要みたい。
sudo apt install ffmpeg libsndfile
モデルを modelディレクトリにダウンロード
mkdir -p model
wget https://huggingface.co/HKUSTAudio/AudioX/resolve/main/model.ckpt -O model/model.ckpt
wget https://huggingface.co/HKUSTAudio/AudioX/resolve/main/config.json -O model/config.json
GradioのWebUIが用意されているので起動。デフォルトだと127.0.0.1でしかLISTENせず、自分の場合はLAN内のリモートサーバになるので、GRADIO_SERVER_NAME=0.0.0.0を付与している。あと初回起動時はおそらくstable-audio-toolsのモデルもダウンロードされていると思われるので少し時間がかかる。
GRADIO_SERVER_NAME=0.0.0.0 python run_gradio.py --model-config model/config.json
なお、このまま使うと、推論時にコンソールに以下の出力が出るので、
No module named 'flash_attn'
flash_attn not installed, disabling Flash Attention
FlashAttentionはインストールしておいてもいいかも(以前はsetup.pyに記載されてたみたいだけど今は削除されてる、多分インストール時に時間がかかるせいだと思う)
pip install flash-attn --no-build-isolation
起動してブラウザで7860番ポートにアクセスするとこんな感じ。

基本的にHuggingFace Spaceのデモと同じ(なので試すだけならそっちのほうがお手軽)で、できることはREADMEにある以下
🎯 プロンプト構成例
タスク video_pathtext_promptaudio_pathText-to-Audio (T2A) None"Typing on a keyboard"NoneText-to-Music (T2M) None"A music with piano and violin"NoneVideo-to-Audio (V2A) "video_path.mp4""Generate general audio for the video"NoneVideo-to-Music (V2M) "video_path.mp4""Generate music for the video"NoneTV-to-Audio (TV2A) "video_path.mp4""Ocean waves crashing with people laughing"NoneTV-to-Music (TV2M) "video_path.mp4""Generate music with piano instrument"None
それぞれのサンプルがGradio内に用意されているのでそれを試すと良い

HuggingFace上のデモで試せるのであまり意味がないかもだが、一応一通り試してみる。
Text-to-Audio
テキストから環境音や効果音を生成
Typing on a keyboard

生成されたもの
rain and thunder
Text-to-Music
テキストから楽曲を作成
new york style punk rock
8bit game music
Video-to-Audio / Video-to-Music
(無音の)動画から、環境音や効果音(Audio)、または 音楽(Music)を生成する。出力は音声データ単体とその音声データをミックスした動画になる。
入力する動画を用意するのがちょっと面倒なので、サンプルの動画を1つ使って、V2A/V2Mをそれぞれ試してみる。使用するのは以下。

参考: 上記をGIFアニメ化したもの
サンプルで用意されているプロンプトは以下のようなシンプルなものだったが、ここを工夫するとTV-to-Audio (TV2A) / TV-to-Music (TV2M) ということになるのだろうと思う。
Video-to-Audio
Generate general audio for the video
Video-to-Music
Generate music for the video
推論時のVRAMは7.6GBぐらいだった
Sat May 24 11:54:16 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 51C P8 5W / 450W | 7581MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
サンプルは概ね10秒程度の生成になるけども、推論は概ね3秒程度。結構速いのではないだろうか?と感じた。