GPTCacheを試してみる
🚀 What is GPTCache?
ChatGPT and various large language models (LLMs) boast incredible versatility, enabling the development of a wide range of applications. However, as your application grows in popularity and encounters higher traffic levels, the expenses related to LLM API calls can become substantial. Additionally, LLM services might exhibit slow response times, especially when dealing with a significant number of requests.
To tackle this challenge, we have created GPTCache, a project dedicated to building a semantic cache for storing LLM responses.
これが気になったのは、
- ベクトルデータベース"zilliz"、"Milvus"の開発元であるzilliztechのレポジトリ
- 以下PRでDynamoDBに対応していた
ドキュメントにQuick Startがあるけど
Colaboratyのnotebookが公開されているのでこちらを試していく
!pip install -q gptcache
OpenAI APIキーを環境変数に読み込み。Colaboratoryで環境変数を指定できるようになったのでそれを使ってみた。
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
まず普通にOpenAI APIを使った場合
import time
import openai
def response_text(openai_resp):
return openai_resp['choices'][0]['message']['content']
question = 'what‘s github?'
# OpenAI API original usage
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
'role': 'user',
'content': question
}
],
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')
約3.11秒
Question: what‘s github?
Time consuming: 3.11s
Answer: GitHub is a web-based platform that allows developers to collaborate on and share code. It provides a version control system called Git, which allows multiple people to work on a project simultaneously and track changes made to the code. GitHub also offers features like issue tracking, project management, and code review, making it a popular platform for software development. It is widely used in the open-source community and by many companies for collaborative software development.
次にGPTCacheを使った場合。2回続けて実行している。
import time
def response_text(openai_resp):
return openai_resp['choices'][0]['message']['content']
print("Cache loading.....")
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache.adapter import openai
cache.init()
cache.set_openai_key()
# -------------------------------------------------
question = "what's github"
for _ in range(2):
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
'role': 'user',
'content': question
}
],
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')
Cache loading.....
start to install package: redis
successfully installed package: redis
start to install package: redis-om
successfully installed package: redis-om
Question: what's github
Time consuming: 2.72s
Answer: GitHub is a web-based platform for version control and collaboration that allows developers to work together on projects, record changes made to code, and share their work with others. It uses the Git version control system, which allows multiple developers to make changes to a project simultaneously, while keeping track of those changes and allowing for easy collaboration and merging of code. GitHub provides a graphical interface and various features for managing repositories, tracking issues, and facilitating project collaboration. It is widely used in the software development community for managing and hosting source code.
start to install package: tiktoken
successfully installed package: tiktoken
Question: what's github
Time consuming: 7.84s
Answer: GitHub is a web-based platform for version control and collaboration that allows developers to work together on projects, record changes made to code, and share their work with others. It uses the Git version control system, which allows multiple developers to make changes to a project simultaneously, while keeping track of those changes and allowing for easy collaboration and merging of code. GitHub provides a graphical interface and various features for managing repositories, tracking issues, and facilitating project collaboration. It is widely used in the software development community for managing and hosting source code.
むしろ遅くなっとるやないかい、というか、多分ライブラリのインストールとかが行われたせいだと思う。
質問を変えてもう一度実行してみる。
question = "what's Google Colaboratory"
2回目の結果が速くなっていること、回答がおなじになっていることがわかる。
Cache loading.....
Question: what's Google Colaboratory
Time consuming: 2.45s
Answer: Google Colaboratory, also known as Colab, is a free cloud-based Jupyter notebook environment offered by Google. It allows users to write and execute Python code in a web browser without the need for any setup or installation. Colab provides access to powerful computing resources, including GPUs and TPUs, and allows collaborative editing, sharing, and commenting on notebooks. Users can import data, install packages, and run code cells to perform data analysis, deep learning, machine learning, and other data-related tasks conveniently.
Question: what's Google Colaboratory
Time consuming: 0.00s
Answer: Google Colaboratory, also known as Colab, is a free cloud-based Jupyter notebook environment offered by Google. It allows users to write and execute Python code in a web browser without the need for any setup or installation. Colab provides access to powerful computing resources, including GPUs and TPUs, and allows collaborative editing, sharing, and commenting on notebooks. Users can import data, install packages, and run code cells to perform data analysis, deep learning, machine learning, and other data-related tasks conveniently.
コードを見てみる。
from gptcache import cache
from gptcache.adapter import openai
cache.init()
cache.set_openai_key()
gptcache.adapterがopenaiをオーバーライドしている。デフォルトだと"exact match"、つまり入力と完全マッチした場合にキャッシュが使用されるということらしい。このキャッシュの振る舞いを決めているのがdata_managerらしい。
より進んだ形のキャッシュとして、
- 入力内容のembeddingsを取得して、キャッシュ化
- 入力ごとにembeddingsと類似検索して一定の類似度以上ならばキャッシュを使う
というのがある様子。cache.init()でキャッシュ設定を行う際に、embeddingsを生成する関数をembedding_funcで指定、similarity_evaluationに類似度を求める関数をセットするとdata_managerは上記のような挙動になるらしい。
import time
def response_text(openai_resp):
return openai_resp['choices'][0]['message']['content']
from gptcache import cache
from gptcache.adapter import openai
from gptcache.embedding import Onnx
from gptcache.manager import CacheBase, VectorBase, get_data_manager
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
print("Cache loading.....")
onnx = Onnx()
data_manager = get_data_manager(CacheBase("sqlite"), VectorBase("faiss", dimension=onnx.dimension))
cache.init(
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key()
questions = [
"what's github",
"can you explain what GitHub is",
"can you tell me more about GitHub",
"what is the purpose of GitHub"
]
for question in questions:
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
'role': 'user',
'content': question
}
],
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')
入力内容が毎回異なるのに、1回目と比べると2回目以降は、レスポンスが速く、かつ、すべて同じ回答担っているのがわかる。
Cache loading.....
start to install package: transformers
successfully installed package: transformers
start to install package: onnxruntime==1.14.1
successfully installed package: onnxruntime==1.14.1
Downloading (…)okenizer_config.json: 100%
465/465 [00:00<00:00, 13.9kB/s]
Downloading (…)lve/main/config.json: 100%
827/827 [00:00<00:00, 26.8kB/s]
Downloading spiece.model: 100%
760k/760k [00:00<00:00, 5.22MB/s]
Downloading (…)/main/tokenizer.json: 100%
1.31M/1.31M [00:00<00:00, 9.53MB/s]
Downloading (…)cial_tokens_map.json: 100%
245/245 [00:00<00:00, 10.9kB/s]
Downloading model.onnx: 100%
46.9M/46.9M [00:00<00:00, 54.6MB/s]
start to install package: faiss-cpu
successfully installed package: faiss-cpu
Question: what's github
Time consuming: 4.07s
Answer: GitHub is a development platform that allows developers to store and manage their code repositories in a centralized and distributed version control system called Git. It provides a web-based interface for collaborating with other developers, managing projects, tracking issues, and organizing code contributions. GitHub also allows users to showcase their work by creating and hosting websites directly from their repositories. It is widely used in the software development industry for open-source projects, as well as for private code repositories and team collaborations.
Question: can you explain what GitHub is
Time consuming: 1.33s
Answer: GitHub is a development platform that allows developers to store and manage their code repositories in a centralized and distributed version control system called Git. It provides a web-based interface for collaborating with other developers, managing projects, tracking issues, and organizing code contributions. GitHub also allows users to showcase their work by creating and hosting websites directly from their repositories. It is widely used in the software development industry for open-source projects, as well as for private code repositories and team collaborations.
Question: can you tell me more about GitHub
Time consuming: 1.07s
Answer: GitHub is a development platform that allows developers to store and manage their code repositories in a centralized and distributed version control system called Git. It provides a web-based interface for collaborating with other developers, managing projects, tracking issues, and organizing code contributions. GitHub also allows users to showcase their work by creating and hosting websites directly from their repositories. It is widely used in the software development industry for open-source projects, as well as for private code repositories and team collaborations.
Question: what is the purpose of GitHub
Time consuming: 0.80s
Answer: GitHub is a development platform that allows developers to store and manage their code repositories in a centralized and distributed version control system called Git. It provides a web-based interface for collaborating with other developers, managing projects, tracking issues, and organizing code contributions. GitHub also allows users to showcase their work by creating and hosting websites directly from their repositories. It is widely used in the software development industry for open-source projects, as well as for private code repositories and team collaborations.
GPTCacheのキャッシュの仕組みについては以下にある
GPTCacheのキャッシュは2つのプロセスで行われる
- キャッシュのビルド
- LLMの選択
気になったところを雑にメモる。どうもドキュメントが追いついていなくてコードには実装済みのものもあるのでその辺も含めて(ただし実際に試したわけではないので正しく動作するかはわからない)
1. キャッシュのビルド
キャッシュの設定に必要なパラメータを確認してみる。
embedding_func
入力内容の類似検索を行うためにベクトルを作成する関数を設定する。指定できるのは以下。
- OpenAI
- Cohere
- HuggingFace
- ONNX
- data2vec
- SentenceTransformers
- FastText
- PaddleNLP
- RWKV
- Timm
- UForm
- ViT
参考)https://github.com/zilliztech/GPTCache/tree/main/gptcache/embedding
例えばOpenAIのEmbedding APIを使う場合だとこんな感じ?
from gptcache.core import cache, Config
from gptcache.manager import get_data_manager, CacheBase, VectorBase
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
from gptcache.embedding import OpenAI
openai_embedding = OpenAI()
data_manager = get_data_manager(CacheBase("sqlite"), VectorBase("faiss", dimension=openai_embedding.dimension))
cache.init(embedding_func=openai_embedding.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key()
参考)https://github.com/zilliztech/GPTCache/tree/main/gptcache/embedding
data_manager
data_managerは、キャッシュデータとベクトルデータのストレージを指定する。
まず、キャッシュの対象となるのは以下。
- 元の入力内容
- プロンプト
- 回答
- アクセス時刻
キャッシュストレージとして選択できるのは以下。
- SQLite
- MySQL
- PostgreSQL
- MariaDB
- SQL Server
- Oracle
- DuckDB
- DynamoDB
- MongoDB
- Redis
参考)https://github.com/zilliztech/GPTCache/tree/main/gptcache/manager/scalar_data
次に、類似検索を行うためのベクトル化したキャッシュデータのストレージで選択できるのは以下。
- Milvus/Zilliz Cloud
- FAISS
- ChromaDB
- docarray
- Redis Vectorstore
- weaviate
- hnswlib
- Qdrant
- PGVector
- usearch
参考)https://github.com/zilliztech/GPTCache/tree/main/gptcache/manager/vector_data
あとドキュメントにはないけどobjectストレージの設定もある様子。マルチモーダル用途とか?
- ローカルディスク
- S3
参考)https://github.com/zilliztech/GPTCache/tree/main/gptcache/manager/object_data
data_managerはのような形で設定する。
from gptcache.manager import get_data_manager, CacheBase, VectorBase
from gptcache.embedding import OpenAI
openai_embedding = OpenAI()
data_manager = get_data_manager(CacheBase("mysql"), VectorBase("milvus", dimension=openai_embedding.dimension), max_size=100, eviction='LRU')
キャッシュのEviction
キャッシュが保持できる最大容量(max_size)を超えた場合に度のデータを消すか?は以下から選択できる様子
-
LRU(Least Recently Used) ・・・ 最も長い間使われていないものから消される -
LFU(Least Frequency Used) ・・・ 最も使用回数が少ないものから消される -
FIFO(First in First out) ・・・ 古いものから消される -
RR(Random Replacment) ・・・ ランダムに消される
evaluation_func
キャッシュに該当するかどうかを判定する関数を指定する。3つのパラメータを受ける。
- user request data
- cached data
- user-defined parameters
指定できる関数は以下。
- exact match evaluation ・・・ 完全一致
- embedding distance evaluation ・・・ Embeddingsの距離≒類似度
- ONNX model evaluation ・・・ ONNXを使ってモデルによる判定を行う。 PytorchやTensorRTがサポートされている。
- Numpy norm ・・・ Numpyによるベクトルの大きさ≒距離?を使う
その他
以下のようなオプションもある
-
log_time_func・・・ embeddingやsearchなどの時間をロギングする。 -
similarity_threshold・・・類似度のしきい値を設定する。
2. LLMの選択
LLMとのやりとりadapterが行う。以下に対応している模様。
- OpenAI
- LangChain
- Diffuser
- Dolly
- llama.cpp
- MiniGPT-4
- Replicate
- Stability SDK
これ以外に、API adapterというのがあり、これをつかうと対応していないものでも対応可能っぽい?多分自分で定義することになる?しらんけど。
あとはLangChainが対応しているLLMならLangChainを介すというやり方もある様子
サポートしている各種モジュールはコードを直接見るよりもREADMEのここをみるのが良さそう
コンポーネントの構成図もここにあった
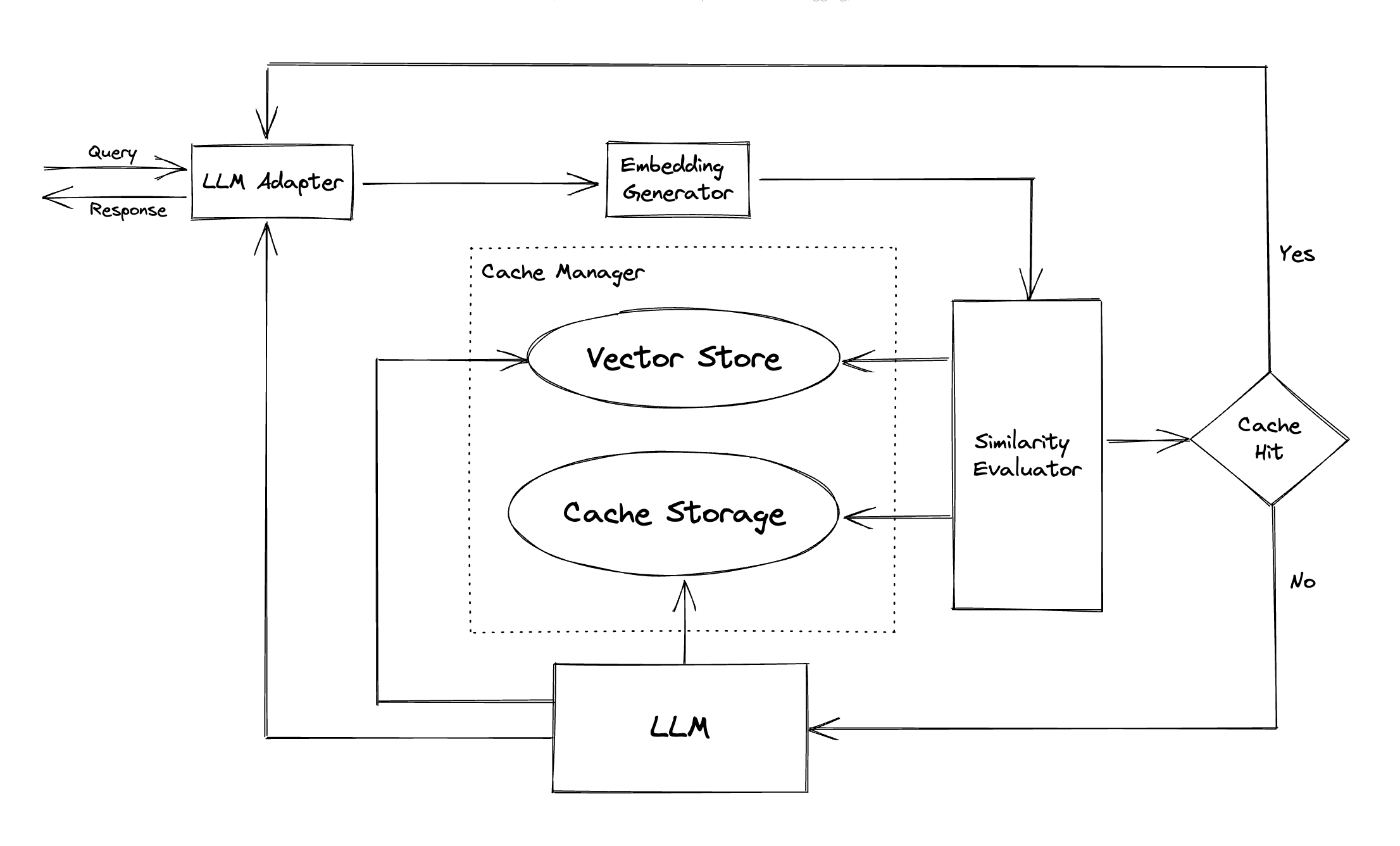
なんかこのスクラップと似たようなものがすでにあるな・・・
とりあえずOpenAIで。キャッシュストレージはsqlite、ベクトルストレージはChromaで。
!pip install -q gptcache redis redis-om openai faiss-cpu tiktoken
!apt update && apt install sqlite3
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
import time
from gptcache import cache
from gptcache.adapter import openai
from gptcache.manager import CacheBase, VectorBase, get_data_manager
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
from gptcache.embedding import OpenAI
def response_text(openai_resp):
return openai_resp['choices'][0]['message']['content']
print("Cache loading.....")
openai_embedding = OpenAI()
data_manager = get_data_manager(CacheBase("sqlite"), VectorBase("chromadb", dimension=openai_embedding.dimension))
cache.init(
embedding_func=openai_embedding.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key()
questions = [
"what's github",
"can you explain what GitHub is",
"can you tell me more about GitHub",
"what is the purpose of GitHub"
]
for question in questions:
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
'role': 'user',
'content': question
}
],
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')
んー、1回目はともかく、2回目も少し時間がかかるのはなんか処理が行われているのかな?
Question: what's github
Time consuming: 2.62s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
Question: can you explain what GitHub is
Time consuming: 1.44s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
Question: can you tell me more about GitHub
Time consuming: 0.15s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
Question: what is the purpose of GitHub
Time consuming: 0.14s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
もっかい実行すると明らかにキャッシュの回答になってる。
Question: what's github
Time consuming: 0.14s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
Question: can you explain what GitHub is
Time consuming: 0.13s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
Question: can you tell me more about GitHub
Time consuming: 0.14s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
Question: what is the purpose of GitHub
Time consuming: 0.14s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It provides features like code repository hosting, issue tracking, pull requests, and code review. GitHub allows developers to work together on projects, share and contribute to open-source projects, and keep track of changes made to the codebase. It is widely used in the software development community and has a vast collection of public repositories covering various programming languages and frameworks.
cache.init()直後のキャッシュデータを見てみる
$ sqlite3 sqlite.db
SQLite version 3.37.2 2022-01-06 13:25:41
Enter ".help" for usage hints.
sqlite> .tables
gptcache_answer gptcache_question_dep gptcache_session
gptcache_question gptcache_report
sqlite> .schema gptcache_question
CREATE TABLE gptcache_question (
id INTEGER NOT NULL,
question VARCHAR(3000) NOT NULL,
create_on DATETIME,
last_access DATETIME,
embedding_data BLOB,
deleted INTEGER,
PRIMARY KEY (id)
);
sqlite> .schema gptcache_answer
CREATE TABLE gptcache_answer (
id INTEGER NOT NULL,
question_id INTEGER NOT NULL,
answer VARCHAR(3000) NOT NULL,
answer_type INTEGER NOT NULL,
PRIMARY KEY (id)
);
sqlite> .schema gptcache_question_dep
CREATE TABLE gptcache_question_dep (
id INTEGER NOT NULL,
question_id INTEGER NOT NULL,
dep_name VARCHAR(1000) NOT NULL,
dep_data VARCHAR(3000) NOT NULL,
dep_type INTEGER NOT NULL,
PRIMARY KEY (id)
);
sqlite> .schema gptcache_session
CREATE TABLE gptcache_session (
id INTEGER NOT NULL,
question_id INTEGER NOT NULL,
session_id VARCHAR(1000) NOT NULL,
session_question VARCHAR(3000) NOT NULL,
PRIMARY KEY (id)
);
sqlite> .schema gptcache_report
CREATE TABLE gptcache_report (
id INTEGER NOT NULL,
user_question VARCHAR(3000) NOT NULL,
cache_question_id INTEGER NOT NULL,
cache_question VARCHAR(3000) NOT NULL,
cache_answer VARCHAR(3000) NOT NULL,
similarity FLOAT NOT NULL,
cache_delta_time FLOAT NOT NULL,
cache_time DATETIME,
extra VARCHAR(3000),
PRIMARY KEY (id)
);
ちなみにエントリは1件もない。
Chromaも。
import chromadb
chroma_client = chromadb.Client()
print(chroma_client.list_collections())
[Collection(name=gptcache)]
collection = chroma_client.get_collection("gptcache")
print(collection.get())
{'ids': [], 'embeddings': None, 'metadatas': [], 'documents': []}
こちらも空。
では推論を行ってみる。
questions = [
"what's github",
"can you explain what GitHub is",
"can you tell me more about GitHub",
"what is the purpose of GitHub"
]
question = questions[0]
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
'role': 'user',
'content': question
}
],
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')
Question: what's github
Time consuming: 2.84s
Answer: GitHub is a web-based platform used for version control and collaboration. It allows software developers to track changes to their code, manage and share their code repositories, and collaborate on projects with other developers. GitHub provides features such as code hosting, pull requests, issue tracking, and project management tools. It is a widely used platform for open-source projects and a popular choice among developers for sharing and contributing to code repositories.
ではこの状態でsqliteとChromaの状態を見てみる。
sqlite> .mode line
sqlite> select * from gptcache_question;
id = 1
question = what's github
create_on = 2023-11-05 11:57:46.577177
last_access = 2023-11-05 11:57:46.577183
embedding_data = 8kF|v<Ms7<C;&<:41,%=Cͼ[fna@=='w;}<s%g?ؼu<w:jZPC(y:h<i˼;WPCoe;5V<A<1<ӕGnI<_źPX+z<<])ݺ݇S<Il< <) <};NvǼСeD<u9fq<;0p<<&Q<@<%ݮÔ%<6k[<ל'/5;&<̼
ӼU<
Tf<<#h<|<$5;A<<;[<aM;#;:>P<1b<jZ<Tf.M;A(
-(C=>мx<Tf.1='<"<
deleted = 0
sqlite> select * from gptcache_answer;
id = 1
question_id = 1
answer = GitHub is a web-based platform used for version control and collaboration. It allows software developers to track changes to their code, manage and share their code repositories, and collaborate on projects with other developers. GitHub provides features such as code hosting, pull requests, issue tracking, and project management tools. It is a widely used platform for open-source projects and a popular choice among developers for sharing and contributing to code repositories.
answer_type = 0
questionとanswerにキャッシュされているのがわかる。その他のテーブルには特に変更はない。
sqlite> select * from gptcache_question_dep;;
sqlite> select * from gptcache_session;
sqlite> select * from gptcache_report;
Chromaの方にも(おそらく)questionのEmbeddingsが登録されている。
from pprint import pprint
collection = chroma_client.get_collection("gptcache")
pprint(collection.get(include=["embeddings", "metadatas", "documents"]))
{'documents': [None],
'embeddings': [[-0.012110523879528046,
0.008817311376333237,
-0.011196923442184925,
(snip)
-0.006296055857092142,
-0.004369704052805901,
-0.005417866166681051]],
'ids': ['1'],
'metadatas': [None]}
メタデータはないのでおそらくベクトル検索結果からIDを拾ってDB側のanswerを引っ張ってきているのだと思う。
セッション
何かしら一意のIDでキャッシュを分けたいような場合はカスタムセッションを使えば良さそう。
DynamoDBを使いたいところだけども、ちょっとスキーマが複雑なのだよね。それはそのうち試すことにする。
ちょっと気になるのは2023/9/28が最終コミットになってて、まあそれほど手を入れるものでもないのかもしれないけど、インテグレーションを広げたりを考えるとメンテが停滞気味なのかなーというところ。ただissueやPRのコメントのやりとりは多少あるようにみえるので完全には止まってないとは思う。
あとLangChainを使う場合は、LangChain側のキャッシュモジュールでGPTCacheを使うのか、GPTCacheのLangChain adapterを使うのか、の違いがある
どっちがいいんだろうねぇ・・・
- なんとなくLangChainのほうがいろいろ変化が激しそうなので、 GPTCacheのLangChain adapter使うとつらくなりそうな気がする
- ただLangChainのドキュメントを斜め読みした限り、キャッシュモジュールはあまり細かい設定ができるようには見えないので、細かい制御がしたければGPTCacheなのかな
- 個人的には最近はLangChainで書くことがほとんどなくて素のOpenAI API使ってるので、GPTCacheを使うメリットはあるかな、自分で書きたくないし。もしLangChainで書くなら、GPTCacheでキャッシュの抽象化レイヤーをさらに増やすよりかは直接Momento Cacheとかを使う方がいいかな~という気はする。
しらんけど。