OpenAI gpt-image-1を試す
開発者ガイド
概要
OpenAI API を使用すると、GPT Image または DALL·E モデルを使用して、テキストプロンプトから画像を生成および編集することができます。
現在、画像生成は Image API を通じてのみ利用可能です。現在、Responses API へのサポートの拡大に積極的に取り組んでいます。
Image API は、それぞれ異なる機能を持つ 3 つのエンドポイントを提供しています。
- Generations: テキストプロンプトに基づいて、イチから画像を生成します。
- Edits: 新しいプロンプトを使用して、部分的または完全に既存の画像を編集します
- Variations: 既存の画像のバリエーションを生成します(DALL·E 2のみ対応)
品質、サイズ、形式、圧縮率、背景の透明化を指定して出力をカスタマイズすることも可能です。
モデル比較
当社の最新かつ最先端の画像生成モデルは、ネイティブマルチモーダル言語モデルである
gpt-image-1です。このモデルは、高品質の画像生成と、画像作成に世界知識を活用できる点でお勧めです。ただし、Image API では、DALL·E 2 および DALL·E 3 といった、画像生成に特化したモデルもご利用いただけます。
モデル エンドポイント 使用例 DALL·E 2 Image API: 生成、編集、バリエーション 低コスト、同時リクエスト、インペインティング(マスクを使用した画像編集) DALL·E 3 Image API: 生成のみ DALL·E 2よりも高い画像品質、より高い解像度に対応 GPT Image Image API:生成、編集 – Responses API のサポートは近日中に提供予定 優れた指示遵守、テキストレンダリング、詳細な編集、現実世界の知識 このガイドでは GPT Image に焦点を当てていますが、DALL·E 2 および DALL·E 3 のドキュメントに切り替えることも可能です。
以下Colaboratoryで。
パッケージインストール。Python SDKのリリース見てても特に明記されてないけど、コードを見る限りは多分 v1.76.0〜かなという感。
!pip install -U openai
!pip freeze | grep -i openai
openai==1.76.0
APIキーをセット
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
画像の生成
プロンプトから画像を生成。そこそこ時間はかかる。
from openai import OpenAI
import base64
client = OpenAI()
prompt = """
聴診器を使って赤ちゃんカワウソの心臓の鼓動を聞く獣医を描いた子供向け絵本風に。
"""
result = client.images.generate(
model="gpt-image-1",
prompt=prompt
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
# 画像をファイルに保存
with open("otter.png", "wb") as f:
f.write(image_bytes)
from IPython.display import display, Image
display(Image(filename="otter.png", width=500))

nを指定すると複数の画像を一度に生成できる。
from openai import OpenAI
import base64
client = OpenAI()
prompt = """
聴診器を使って赤ちゃんカワウソの心臓の鼓動を聞く獣医を描いた子供向け絵本風に。
"""
result = client.images.generate(
model="gpt-image-1",
prompt=prompt,
n=2
)
for idx, image in enumerate(result.data, start=1):
image_base64 = image.b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"otter_{idx}.png", "wb") as f:
f.write(image_bytes)
from IPython.display import display, Image
display(Image(filename="otter_1.png", width=300))
display(Image(filename="otter_2.png", width=300))

出力をカスタマイズすることもできるが、後述。
出力のカスタマイズ
先に出力のカスタマイズを見ておく。以下の項目を設定できる。よく見るとサイズの表記がドキュメントは間違ってる気がする・・・APIリファレンスに合わせている。
| パラメータ | 内容 | 設定可能なパラメータ | 備考 |
|---|---|---|---|
size |
サイズ |
1024x1024(正方形)1536x1024(横長)1024x1536(縦長) auto(デフォルト) |
|
quality |
品質 |
lowmediumhighauto(デフォルト) |
|
output_format |
出力形式 |
png(デフォルト)jpegwebp
|
base64エンコードで返される |
output_compression |
圧縮率 |
0〜100(デフォルト) |
出力形式がjpeg / webp の場合のみ |
background |
背景 |
transparent(透明)opaque(不透明)auto(デフォルト) |
出力形式がpng / webp の場合のみ |
from openai import OpenAI
import base64
client = OpenAI()
result = client.images.generate(
model="gpt-image-1",
prompt="2Dピクセルアートスタイルの三毛猫のスプライトシートを作成してください。",
size="1024x1024",
background="transparent",
quality="high",
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
with open("sprite.png", "wb") as f:
f.write(image_bytes)
from IPython.display import display, Image
display(Image(filename="sprite.png", width=500))
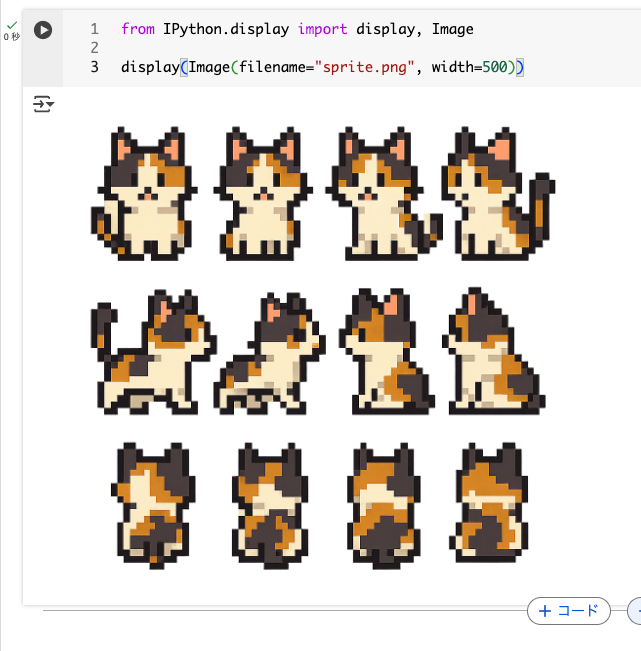
画像の編集
画像の編集では以下のようなことができる。
- 既存の画像を編集
- 既存の画像をリファレンスとして、新しい画像を生成
- 画像と置き換える領域を示すマスク画像をアップロードして、画像の一部を編集。「インペインティング」と呼ばれる。
リファレンスから新しい画像を生成
ドキュメントでは、
- ボディローション
- 石鹸
- バスボール
- お香
の4つの画像から、それらをプレゼント用にバスケットに入れた画像を生成させている。
今回は手元に適当なリファレンス用画像がないので、リファレンス画像も生成させて、それを元に新しい画像を生成することとする。
まず、リファレンスとして4つの画像を生成させる。
import base64
from string import Template
from openai import OpenAI
client = OpenAI()
objects = [
"シャンプー",
"コンディショナー",
"タオル",
"石鹸",
]
prompt_template= "写真のようにリアルな $object の画像を生成してください。"
for o in objects:
prompt = Template(prompt_template).substitute(object=o)
print("プロンプト:", prompt)
result = client.images.generate(
model="gpt-image-1",
prompt=prompt,
size="1024x1024",
quality="low",
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"{o}.png", "wb") as f:
f.write(image_bytes)
from IPython.display import display, Image
for o in objects:
display(Image(filename=f"{o}.png", width=200))

これらをリファレンス画像として入力し、新しい画像を生成する。新しい画像を生成するのだけども、画像を入力として渡す場合は image.edit になるのはちょっとモヤッとした。
import base64
from openai import OpenAI
client = OpenAI()
prompt = """
白い背景にギフトバスケットのフォトリアリスティックな画像を生成してください。
「Relax & Unwind」とリボンと手書き風のフォントでラベルを付け、
参照画像にあるすべてのアイテムを含めてください。
"""
result = client.images.edit(
model="gpt-image-1",
image=[
open("シャンプー.png", "rb"),
open("コンディショナー.png", "rb"),
open("タオル.png", "rb"),
open("石鹸.png", "rb"),
],
prompt=prompt,
size="1024x1024",
quality="low",
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
with open("gift-basket.png", "wb") as f:
f.write(image_bytes)
from IPython.display import display, Image
display(Image(filename="gift-basket.png", width=500))

マスク画像を使って画像を編集
上で作った画像のタオルを書き換える。以下のマスク画像を用意した。

上記をアップロードして実行
import base64
from openai import OpenAI
client = OpenAI()
result = client.images.edit(
model="gpt-image-1",
image=open("gift-basket.png", "rb"),
mask=open("mask.png", "rb"),
prompt="タオルを花柄にして",
size="1024x1024",
quality="low",
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
with open("gift-basket2.png", "wb") as f:
f.write(image_bytes)
from IPython.display import display, Image
display(Image(filename="gift-basket2.png", width=500))
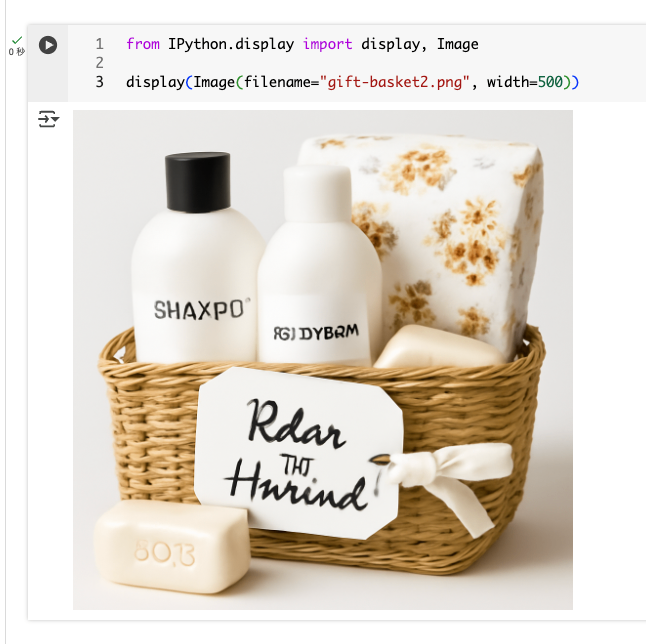
注意すべきこと
制限
GPT-4o Image モデルは、強力で汎用性の高い画像生成モデルですが、以下の制限事項にご注意ください。
- 遅延: 複雑なプロンプトは、処理に最大 2 分かかる場合があります。
- テキストのレンダリング:DALL·E シリーズから大幅に改善されていますが、テキストの正確な配置や明瞭さに関しては、まだ課題が残っています。
- 一貫性: 一貫した画像を生成する能力はありますが、モデルは、複数の生成間で繰り返し登場するキャラクターやブランド要素の視覚的一貫性を維持するのに時々苦労する場合があります。
- 構成制御: 指示の追従性が向上したものの、モデルは構造化またはレイアウトに敏感な構成において要素を正確に配置するのに困難を伴う場合があります。
コンテンツモデレーションコンテンツのモデレーション
すべてのプロンプトと生成された画像は、当社のコンテンツポリシーに従ってフィルタリングされます。
gpt-image-1を使用した画像生成では、モデレーションの厳格さをmoderationパラメーターで制御できます。このパラメーターは、以下の2つの値をサポートしています:
auto(デフォルト): 特定のカテゴリの年齢に不適切なコンテンツの生成を制限する標準的なフィルタリング。low: より制限の緩いフィルタリング。
コストとレイテンシー
レイテンシーは、1枚の画像でも10数秒程度はかかる感じ。で、コスト。
コストとレイテンシー
このモデルは、まず特殊な画像トークンを生成して画像を作成します。遅延と最終的なコストは、画像のレンダリングに必要なトークンの数に比例します。画像サイズが大きくなり、品質設定が高くなると、トークンの数も増えます。
生成されるトークンの数は、画像の寸法と品質によって異なります。
品質 正方形(1024×1024) 縦長 (1024×1536) 横長 (1536×1024) Low 272 トークン 408 トークン 400 トークン Medium 1056 トークン 1584 トークン 1568 トークン High 4160 トークン 6240 トークン 6208 トークン プロンプトで使用される入力テキスト トークンも考慮する必要があります。
テキスト トークンと画像 トークンの単価に関する詳細情報は、価格ページをご参照ください。
価格ページから関連する箇所を引っ張ってくる。まずトークン。
| 種類 | 価格(1M入力トークン) | 価格(1M出力トークン) |
|---|---|---|
| テキストトークン | $5.00 | ー |
| 画像トークン | $10 | $40 |
次に画像生成。1枚あたりとあるが、これはおそらく上記の出力トークンを金額にしたものだと思う。なので、ここに入力トークン分のコストが乗っかると思えば良さそう。
| 品質 | 正方形(1024×1024) | 縦長 (1024×1536) | 横長 (1536×1024) |
|---|---|---|---|
| Low | $0.011 | $0.016 | $0.016 |
| Medium | $0.042 | $0.063 | $0.063 |
| High | $0.167 | $0.25 | $0.25 |
めちゃめちゃざっくりだと、DALL·E 3の倍、ぐらいのイメージかな。
まとめ
やっとAPIが来て嬉しいところだけど、コストはそこそこしそう。
あと、ChatGPTだとチャットの流れで使えてるけども、
現在、画像生成は Image API を通じてのみ利用可能です。現在、Responses API へのサポートの拡大に積極的に取り組んでいます。
というところで、Responses API で使えるようになったらチャットで使いやすくなる。ただChat Completions APIについては明記されてないけど、ここはどうなるのかな?気になる。
さらに一貫性が上がったみたい
この記事では、「Image API」と「Responses」の画像生成ツールで利用可能な「input_fidelity」パラメータを活用して、入力の特徴を保持する方法を説明します。input_fidelity="high" に設定すると、顔やロゴなど、出力に高い忠実度が求められる細部を含む画像を編集する場合に特に便利です。