VoyageAIのEmbeddingモデル「voyage-3」を試す
以前にVoyageAIのEmbeddingモデルはvoyage-multilingual-2を試した
マルチリンガル対応・入力トークン32K、かつ、ベンチマークや自分の評価でもOpenAI Text Embedding-3-largeより上、ということで、非常に精度高いモデルだった。
のだが、いつのまにか「voyage-3」が出ていたのに気づかなかった。
あとマルチモーダルもあったが、今回は触れない。
これはかなり期待できそう。少し試してみる。
公式ドキュメントにモデル一覧がある。今回はマルチリンガル対応したものだけに触れる。
| モデル | コンテキスト長 | 次元数 | ユースケース |
|---|---|---|---|
voyage-3-large |
32000 | 256 512 1024* 2048 |
最も高品質な汎用マルチリンガル検索。量子化にも対応 |
voyage-3 |
32000 | 1024 | 汎用性に優れたマルチリンガル検索 |
voyage-3-lite |
32000 | 512 | レイテンシー・コストに優れたマルチリンガル検索 |
※次元数で*がついているのがデフォルト
上記以外に以下のようなドメイン特化なモデルもあるが、おそらくマルチリンガル非対応と思われる。
-
voyage-code-3: コード検索 -
voyage-finance-2: 財務関連ドキュメントの検索 -
voyage-law-2: 法律関連ドキュメントの検索 -
voyage-code-2: コード検索の前バージョン
あと古いモデルもまだ使える。ただし、多くがマルチリンガル非対応、かつ、すでに新しいモデルへの移行を推奨されているモデルが多いようなので、唯一、以前試したマルチリンガルモデルだけは移行推奨されていない。これは、特定のタスクにおいては現行モデルよりも良いケースがあるためだと思われる。(パフォーマンスについては後述)
voyage-multilingual-2
まずは以下のドキュメントに従って基本的なところをColaboratoryで試す。
パッケージインストール
!pip install -U voyageai
!pip freeze | grep -i voyageai
APIキーをセット
from google.colab import userdata
import os
os.environ['VOYAGE_API_KEY'] = userdata.get('VOYAGE_API_KEY')
クライアントを初期化
import voyageai
vo = voyageai.Client()
テキストをEmbeddingする。ミニマムならembed()にテキストの配列とモデルを渡すだけ。まずはvoyage-3で。
result = vo.embed(
["こんにちは。今日は良いお天気ですね。"],
model="voyage-3"
)
結果
from pprint import pprint
# embeddings
pprint(result.embeddings)
# 次元数
print(len(result.embeddings[0]))
# トークン数
print(result.total_tokens)
[[-0.04379447177052498,
0.023915844038128853,
0.01683219149708748,
-0.01603079028427601,
(snip)
-0.0003698556392919272,
0.00027070759097114205,
0.00874285213649273,
-0.0010872863931581378]]
1024
9
バッチも。今度はvoyage-3-liteを使ってみる。
results = vo.embed(
[
"こんにちは。今日は良いお天気ですね。",
"おはようございます。今日は一段と冷え込みますね。"
],
model="voyage-3-lite"
)
from pprint import pprint
pprint(results.embeddings)
print([len(i)for i in results.embeddings])
print(results.total_tokens)
[[-0.07749442011117935,
-0.0005926524754613638,
-0.007658893242478371,
0.014167065732181072,
(snip)
0.04140864312648773,
-0.011301268823444843,
-0.0754319280385971,
-0.06078696250915527],
[-0.05864318832755089,
0.06015294790267944,
0.04365424066781998,
-0.009788388386368752,
(snip)
0.035325776785612106,
-0.024223702028393745,
-0.049734946340322495,
-0.059645336121320724]]
[512, 512]
23
非同期の場合
import voyageai
# notebook環境では必要
import nest_asyncio
nest_asyncio.apply()
vo = voyageai.AsyncClient()
result = await vo.embed(
["こんにちは。今日は良いお天気ですね。"],
model="voyage-3"
)
pprint(result.embeddings[0][:5])
print(len(result.embeddings[0]))
print(result.total_tokens)
[-0.04379447177052498,
0.023915844038128853,
0.01683219149708748,
-0.01603079028427601,
0.07050428539514542]
1024
9
Quickstart Tutorialでは簡易なRAGの実装例がある。
こんな感じでまずドキュメントのEmbeddingを生成。
import voyageai
documents = [
"地中海式ダイエットは、魚、オリーブオイル、野菜を重視しており、慢性疾患のリスクを軽減すると考えられています。",
"植物の光合成は光エネルギーをブドウ糖に変換し、不可欠な酸素を生成します。",
"20世紀の革新は、ラジオからスマートフォンまで、電子技術の進歩を中心に展開されました。",
"河川は、生態系にとって不可欠な水、灌漑、水生生物の生息地を提供しています。",
"Appleの第4四半期の業績と事業アップデートに関するカンファレンスは、2023年11月2日(木)午後2時(太平洋標準時)/午後5時(東部標準時)に予定されています。",
"「ハムレット」や「真夏の夜の夢」など、シェイクスピアの作品は文学の中で生き続けています。",
]
vo = voyageai.Client()
documents_embeddings = vo.embed(
documents,
model="voyage-3",
input_type="document"
).embeddings
embed()にはinput_typeパラメータがある。用途に合わせて選択すれば良い。
-
None: デフォルト -
query: 検索が目的の場合で、クエリのEmbeddingを生成する。 -
document: 検索が目的の場合で、ドキュメントのEmbeddingを生成する。
次にクエリのEmbeddingsを取得。
query = "アップルのイベントはいつ?"
query_embedding = vo.embed(
[query],
model="voyage-3",
input_type="query"
).embeddings[0]
最も類似度の高いドキュメントを抽出
import numpy as np
# 類似性を計算
# Voyage embeddingsは長さが1になるように正規化されているため
# 内積とコサイン類似度は同じ
similarities = np.dot(documents_embeddings, query_embedding)
retrieved_id = np.argmax(similarities)
score = similarities[retrieved_id]
print(score, ":", documents[retrieved_id])
0.5270807772198853 : Appleの第4四半期の業績と事業アップデートに関するカンファレンスは、2023年11月2日(木)午後2時(太平洋標準時)/午後5時(東部標準時)に予定されています。
ランキングで出力するとこんな感じ。
import numpy as np
similarities = np.dot(documents_embeddings, query_embedding)
docs_scores = list(zip(documents, similarities))
docs_scores_sorted = sorted(docs_scores, key=lambda x: x[1], reverse=True)
for doc, score in docs_scores_sorted:
print(f"ドキュメント: {doc}")
print(f"スコア: {score}\n")
ドキュメント: Appleの第4四半期の業績と事業アップデートに関するカンファレンスは、2023年11月2日(木)午後2時(太平洋標準時)/午後5時(東部標準時)に予定されています。
スコア: 0.5270807772198853
ドキュメント: 植物の光合成は光エネルギーをブドウ糖に変換し、不可欠な酸素を生成します。
スコア: 0.24025862510739765
ドキュメント: 「ハムレット」や「真夏の夜の夢」など、シェイクスピアの作品は文学の中で生き続けています。
スコア: 0.16429711355820178
ドキュメント: 20世紀の革新は、ラジオからスマートフォンまで、電子技術の進歩を中心に展開されました。
スコア: 0.16290744851858913
ドキュメント: 河川は、生態系にとって不可欠な水、灌漑、水生生物の生息地を提供しています。
スコア: 0.14163567767325647
ドキュメント: 地中海式ダイエットは、魚、オリーブオイル、野菜を重視しており、慢性疾患のリスクを軽減すると考えられています。
スコア: 0.07098460515630753
top-
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
from pprint import pprint
def k_nearest_neighbors(query_embedding, documents_embeddings, k=5):
# numpy配列に変換
query_embedding = np.array(query_embedding)
documents_embeddings = np.array(documents_embeddings)
# クエリのベクトルを行数1・列数nの行列に変換し、cosine_similarityの入力形式に合わせる
query_embedding = query_embedding.reshape(1, -1)
# データの各要素のコサイン類似度を計算
cosine_sim = cosine_similarity(query_embedding, documents_embeddings)
# top-kで取得できるように類似度で降順ソート
sorted_indices = np.argsort(cosine_sim[0])[::-1]
# top-kを抽出
top_k_related_indices = sorted_indices[:k]
top_k_related_embeddings = documents_embeddings[sorted_indices[:k]]
top_k_related_embeddings = [
list(row[:]) for row in top_k_related_embeddings
] # リストに変換
return top_k_related_embeddings, top_k_related_indices
#k-NN
retrieved_embds, retrieved_embd_indices = k_nearest_neighbors(
query_embedding, documents_embeddings, k=3
)
retrieved_docs = [documents[index] for index in retrieved_embd_indices]
pprint(retrieved_docs)
結果
['Appleの第4四半期の業績と事業アップデートに関するカンファレンスは、2023年11月2日(木)午後2時(太平洋標準時)/午後5時(東部標準時)に予定されています。',
'植物の光合成は光エネルギーをブドウ糖に変換し、不可欠な酸素を生成します。',
'「ハムレット」や「真夏の夜の夢」など、シェイクスピアの作品は文学の中で生き続けています。']
あとはLLMに渡すだけなので割愛。
ドキュメントではリランクモデルについても記載があるが、そちらも割愛。
さらにvoyage-3-largeでは、
- Matryoshka Embeddings
- Quantized Embeddings
など、Embedding容量の削減が柔軟にできる。
Matryoshka Embeddingsはoutput_dimensionで指定する。
import voyageai
from pprint import pprint
vo = voyageai.Client()
result = vo.embed(
["こんにちは。今日は良いお天気ですね。"],
model="voyage-3-large",
output_dimension=256 # 256/512/1024(デフォルト)/2048 から選択
)
pprint(result.embeddings[0][:5])
print(len(result.embeddings[0]))
[-0.026444874703884125,
0.06570082157850266,
0.12352694571018219,
8.998603880172595e-05,
-0.002086206804960966]
256
Quantized Embeddingsはoutput_以下が選択できる。
int8uint8binaryubinary-
float(デフォルト)
int8の場合
import voyageai
from pprint import pprint
vo = voyageai.Client()
result_int8 = vo.embed(
["こんにちは。今日は良いお天気ですね。"],
model="voyage-3-large",
output_dtype="int8"
)
pprint(result_int8.embeddings[0][:5])
print(len(result_int8.embeddings[0]))
[-8, 20, 38, 0, 0]
1024
ubinaryの場合
import voyageai
from pprint import pprint
vo = voyageai.Client()
result_ubinary = vo.embed(
["こんにちは。今日は良いお天気ですね。"],
model="voyage-3-large",
output_dtype="ubinary"
)
pprint(result_ubinary.embeddings[0][:8])
print(len(result_ubinary.embeddings[0]))
[119, 52, 248, 56, 72, 101, 139, 7]
128
バイナリの場合はビット単位でpackされて返される(つまり128x8=1024)ので、これをunpackしてやる。
import numpy as np
def unpack_binary_embeddings(embeddings: list[int]):
embeddings = np.array(embeddings, dtype=np.uint8)
embeddings = np.unpackbits(embeddings)
return embeddings.astype(bool).tolist()
result_binary = [unpack_binary_embeddings(v) for v in result_ubinary.embeddings]
pprint(result_binary[0][:8])
print(len(result_binary[0]))
[False, True, True, True, False, True, True, True]
1024
上記の「Flexible Dimensions and Quantization」のドキュメント、かなり詳しく書かれているので、もう少し読んでみたい。あと、Colaboratory notebookも用意されているので、これをやるのが良さそう。
トークナイズ用のメソッドもある。
まとめ
とりあえずネイティブのSDKの使い方をざっと押さえただけ。使い方自体はそんなに難しいものでもないのだが、自分が実際に使うときは多分LlamaIndexとかのフレームワーク経由で使うことになると思うし、その場合にどういうオプションがあるのかを知れたので良かった。
で、気になる性能について。
公式のブログ記事に性能評価のスプレッドシートが用意されている。以下記事の中の「All the evaluation results are available in this spreadsheet.」から辿れる。
それぞれのスプレッドシートに記載されている評価対象モデルが微妙に違っていて網羅的に見れなかったので、それらを1つにまとめて、日本語のところだけ抜粋してスコアやランクで色分けしてみたのが以下。
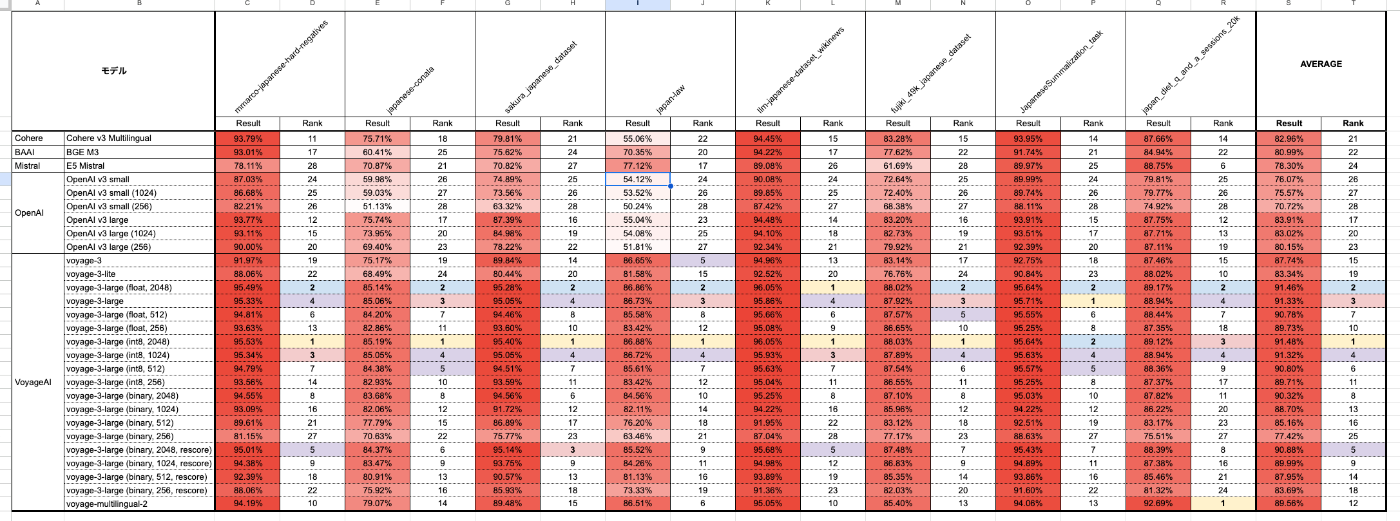
このシートの結果を信頼するならば、voyage-3-largeはダントツの性能である。一部の項目ではvoyage-2-multilingualも未だ上位になっているものもあるし、いずれにせよベンチマーク上はOpenAIやCohere、BAAIよりも優れた結果となっている。過去、自分がvoyage-2-multilingualを以前試した際の結果とも合致するので、VoyageAIはとても優れたEmbeddingモデルベンダーと言える。