Orpheus-TTSをOpenAI互換APIサーバで使える「Orpheus-FastAPI」を試す
以前試したOrpheus-TTS
これをFastAPIでラップしてOpenAI互換APIとして使えるらしい
GitHubレポジトリ
Orpheus-FASTAPI
高性能のテキスト読み上げ(Text-to-Speech)サーバー。OpenAI 互換 API、24 種類の声による多言語対応、感情タグ、最新の Web UI を搭載し、RTX GPU に最適化。
モデルコレクション
🚀 新着: 量子化モデルでパフォーマンス向上!
- Q2_K: 2-bit 量子化による超高速推論
- Q4_K_M: 4-bit(混合)量子化で品質と速度のバランス
- Q8_0: 元の高品質 8-bit モデル
Hugging Face で Orpheus-FASTAPI モデルコレクションを見る
音声デモ
- デフォルトテストサンプル — 標準的なニュートラルトーン
- Leah ハッピーサンプル — 陽気で明るいデモ
- Tara サッドサンプル — 感情的で物悲しいデモ
- Zac 思索的サンプル — 思慮深く落ち着いたトーン
ユーザーインターフェース
referred from https://zenn.dev/kun432/scraps/90df52d628f7ab特徴
- OpenAI API 互換: OpenAI の
/v1/audio/speechエンドポイントと置き換え可能- モダンな Web インターフェース: 波形可視化を備えたクリーンでレスポンシブな UI
- 高性能: RTX GPU 向けに並列処理を最適化
- 多言語サポート: 8 言語・24 種類の声
- 感情タグ: 笑い・ため息などの感情表現に対応
- 音声長の制限なし: インテリジェントなバッチ処理で任意の長さを生成
- スムーズな切替: クロスフェードでシームレスなリスニング体験
- Web UI で設定変更: サーバー設定をインターフェースから直接変更
- 動的環境変数: ファイル編集なしで API エンドポイントやタイムアウト、モデルパラメータを更新可能
- サーバー再起動: ワンクリックで設定変更を適用
利用可能な声
英語
tara: 女性、会話調、クリアleah: 女性、温かみ、優しいjess: 女性、エネルギッシュ、若々しいleo: 男性、威厳、低音dan: 男性、フレンドリー、カジュアルmia: 女性、プロフェッショナル、明瞭zac: 男性、熱意、ダイナミックzoe: 女性、落ち着き、癒やしフランス語
pierre: 男性、洗練amelie: 女性、上品marie: 女性、快活ドイツ語
jana: 女性、クリアthomas: 男性、威厳max: 男性、エネルギッシュ韓国語
유나: 女性、メロディック준서: 男性、自信ヒンディー語
ऋतिका: 女性、表情豊か中国語(普通話)
长乐: 女性、穏やか白芷: 女性、クリアスペイン語
javi: 男性、温かみsergio: 男性、プロフェッショナルmaria: 女性、フレンドリーイタリア語
pietro: 男性、情熱的giulia: 女性、表情豊かcarlo: 男性、上品感情タグ
テキストに感情タグを挿入して表現力を追加可能:
<laugh>: 笑い<sigh>: ため息<chuckle>: くすくす笑い<cough>: 咳<sniffle>: 鼻すすり<groan>: うめき<yawn>: あくび<gasp>: 息をのむ例:
"Well, that's interesting <laugh> I hadn't thought of that before."
ライセンス
本プロジェクトは Apache License 2.0 で配布。詳細は LICENSE.txt を参照。
なお、日本語は対応していない
構成は少し変わっている
セットアップ
前提条件
- Python 3.8–3.11(Python 3.12 は
pkgutil.ImpImporterの削除により非対応)- CUDA 対応 GPU(推奨: RTX シリーズ)
- Docker Compose または別途 Orpheus モデルを実行する LLM 推論サーバー(例: LM Studio または llama.cpp サーバー)
🐳 Docker Compose
Docker Compose ファイルは Orpheus-FASTAPI(音声生成)と base モデルのトークン生成用 llama.cpp 推論サーバーを連携させる。GGUF モデルは
model-initサービスで自動ダウンロードされる。 ?
GPU 対応のdocker-compose-gpu.yamlと、CPU 専用のdocker-compose-cpu.yamlの 2 種類を用意。
技術詳細
このサーバーはフロントエンドとして機能し、外部の LLM 推論サーバーに接続する。推論サーバーで生成されたトークンを SNAC モデルで音声へ変換。RTX 4090 GPU 向けに最適化:
- ベクトル化テンソル演算
- CUDA ストリームによる並列処理
- 効率的なメモリ管理
- トークン・音声キャッシュ
- 最適化されたバッチサイズ
外部推論サーバー
本アプリケーションは Orpheus モデルを実行する別途 LLM サーバーが必要。Docker Compose 推奨。または:
- GPUStack — GPU 最適化 LLM サーバー(推奨)
- LM Studio — GGUF モデルをロードしローカルサーバー起動
- llama.cpp server
つまり、上にも書いてあるが、Orpheus-FastAPIは、FastAPIでOpenAI互換APIエンドポイントを提供、フロントエンドで、実際の推論処理は上にあるようなOrpheus TTSでの推論を実行するバックエンドサーバに投げるという仕組みになっている。
でこのあたりはdocker composeでまるっとセットアップできるようになっているので、それを使って試してみる。環境はUbuntu-22.04(RTX4090)。
レポジトリクローン
git clone https://github.com/Lex-au/Orpheus-FastAPI && cd Orpheus-FastAPI
.envを作成する
cp .env.example .env
デフォルトはこうなっている(コメントは日本語化した)
# Orpheus-FastAPI 設定
# このファイルを .env としてコピーして必要なカスタマイズを行ってください
# サーバー接続設定
ORPHEUS_API_URL=http://127.0.0.1:1234/v1/completions
ORPHEUS_API_TIMEOUT=120 # max tokensと推論速度に合わせてこの値を修正してください
# 生成パラメータ
ORPHEUS_MAX_TOKENS=8192 # より長い生成が必要な場合はこの値を増やしてください
ORPHEUS_TEMPERATURE=0.6
ORPHEUS_TOP_P=0.9
# 安定性を確保するため Repetition penalty は 1.1 にハードコードされています(モデルの制約)ー この設定は使用されなくなりました
# ORPHEUS_REPETITION_PENALTY=1.1
ORPHEUS_SAMPLE_RATE=24000
ORPHEUS_MODEL_NAME=Orpheus-3b-FT-Q8_0.gguf # 推論サーバに送信されるモデル名 (Q2_K, Q4_K_M, Q8_0 が選択できます)
# Web UI 設定(Web UI は安全ではないため、インターネットに公開しないでください)
ORPHEUS_PORT=5005
ORPHEUS_HOST=0.0.0.0
外部に公開するわけでもないので、特に変更する必要はなさそう。このまま使うこととする。
docker-compose.ymlはCPU向けとGPU向けが用意されている。今回はGPUを活用したいので、GPU向けのdocker-compose-gpu.ymlを使う。中身を見るとわかるように、FastAPIのフロントエンドとllama.cppのサーバが起動するようになっている。
では起動。初回はモデルがダウンロードされるので少し時間がかかる。
docker compose -f docker-compose-gpu.yml up
ログが以下のように表示されればOK
(snip)
llama-cpp-server-1 | main: server is listening on http://0.0.0.0:5006 - starting the main loop
llama-cpp-server-1 | srv update_slots: all slots are idle
orpheus-fastapi | INFO: Started server process [1]
orpheus-fastapi | INFO: Waiting for application startup.
orpheus-fastapi | INFO: Application startup complete.
orpheus-fastapi | INFO: Uvicorn running on http://0.0.0.0:5005 (Press CTRL+C to quit)
主なエンドポイントは以下。
-
http://[サーバのIP]:5005/: Web UI -
http://[サーバのIP]:5005/docs: APIドキュメント -
http://[サーバのIP]/v1/audio/speech: OpenAI互換APIエンドポイント -
http://[サーバのIP]/v1/speak: シンプルなAPIエンドポイント(レガシー)
APIドキュメント(http://[サーバのIP]:5005/docs)はこんな感じ。音声一覧とか設定の参照・保存、サーバの再起動みたいなエンドポイントもあるみたい。

WebUI(http://[サーバのIP]:5005/)を試してみる。文章はOrpheus公式のデモで使われいたものを拝借
Hey there my name is Tara, <chuckle> and I'm a speech generation model that can sound like a person.
I've also been taught to understand and produce paralinguistic things like sighing, or chuckling, or yawning!
I live in San Francisco, and have, uhm let's see, 3 billion 7 hundred ... well, lets just say a lot of parameters!

生成中

ログを見てるとだいたい12秒ほどで生成された様子。生成結果はその場で再生・ダウンロードできる。
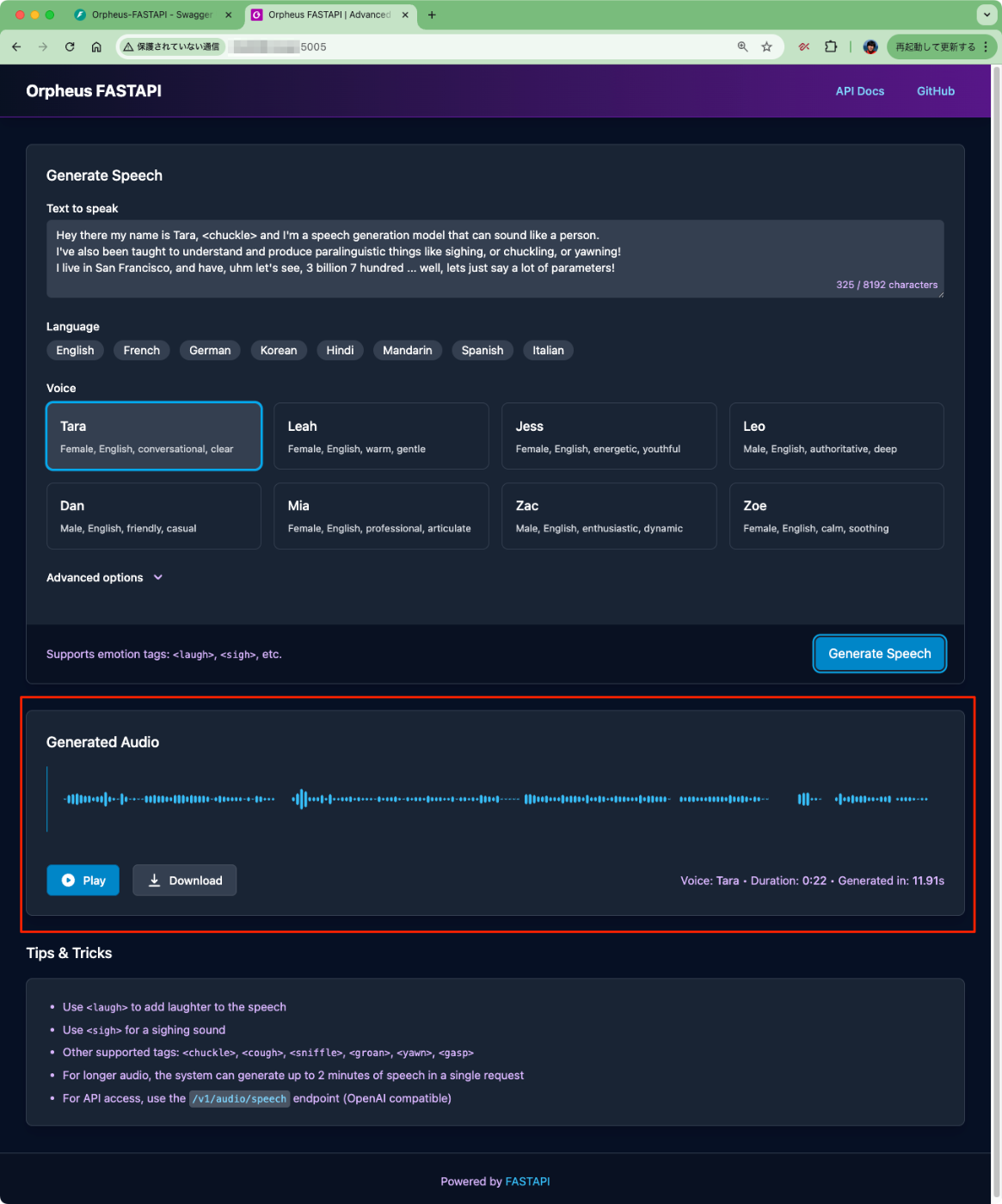
生成されたものはこちら
なお、Advanced optionsでは以下のような設定が可能

次に、OpenAI互換APIにもアクセスしてみる。
curl http://[サーバのIP]:5005/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{
"model": "orpheus",
"input": "Hello world! <laugh> This is a test of the Orpheus TTS system.",
"voice": "Leah",
"response_format": "wav",
"speed": 1.0
}' \
--output speech.wav
2.5秒ぐらいで生成された。生成されたもの。
なお、VRAM消費量は6GBぐらいだった。
Thu May 22 15:07:01 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 49C P8 5W / 450W | 5948MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
デフォルトだとQ8_0で一番大きい量子化バージョンになっている。Q4_K_M、Q2_Kでも試してみて生成速度や生成品質、VRAM消費などを見てみる。生成の仕方は上と同じように実施。
Q4_K_M
- Web UIでは、9秒程度。
- APIでは2.4秒程度
- 発話品質は多少低下したかなー?ぐらいだが、稀に発話の欠けみたいなものがあった。
- VRAM消費は4.6GB
Thu May 22 15:20:34 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 46C P8 4W / 450W | 4592MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
Q2_K
- Web UIでは、8秒程度。
- APIでは2.1秒程度
- 発話品質はかなり低下、非言語タグがうまく発話されない、一部欠けが起きる、あとたまに壊れることもあった。
- VRAM消費は3.9GB
Thu May 22 15:20:34 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 46C P8 4W / 450W | 4592MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
生成速度的には大きな違いが出にくい感じなので、VRAM消費が問題にならないのであれば品質に振ったほうが良さそう。
以下にストリーミングの要望に関するIssueが上がっているが、どうやらストリーミング用のエンドポイントに対応したfork版があるらしい。
これか
ただ、Issueのやり取りを見ていると、
- ストリーミングは最初のトークンの時間を短縮するだけで根本的な解決ではない。Orpheus公式の説明にも低遅延とあるが、単にこのことを指しているだけで、推論時間が高速な訳ではない。
- Orpheusが遅いのはエンコーダとして使用されているSNACが低遅延向けに設計されておらず、速度を犠牲にして品質を優先しているため。
- HiFi-GANのようなモデルのほうが低遅延向けには望ましいが、置き換えることは現状困難に思える
ということで、現状推論時間の高速化には限界があるみたいな話になっている。
ただ実利用を考えた場合、生成された音声を再生している時間のほうが生成時間よりも長いと思うので、ストリーミングには意味があるとは思う。
基本的にほぼ同じ手順で構築できるので試してみたけど、そもそもエラーが出て生成ができない・・・まあ後でちょっと調べてみるか
まとめ
実はOrpheus-TTSを手軽にAPIで動かしたいと思っていろいろ調べてたのだけど、すでにあって簡単に使えるので良き。GGUF化されつつあるとは思ってたけど、すでにGGUF化されてたとは・・・。
ただ生成時間は少し長い感もあるので、実際のアプリケーションに組み込むならば、上のfork版にあるようなストリーミングは欲しいところ。
Unslothが最近TTS向けのファインチューニング用notebookを公開してくれたので、それを使えば音声の追加とかはできそう。
ただ、日本語の場合、事前学習からやらないとおそらく厳しい。Orpheus公式が出しているマルチリンガルの事前学習モデルには日本語含まれていないんだよね・・・