Ovis1.6-Gemma2-9Bを試す
GitHubレポジトリ
Ovis: マルチモーダル大言語モデルのための構造的埋め込みアライメント
Ovis(Open VISion)は、視覚とテキストの埋め込みを構造的にアラインメントするよう設計された、新しいマルチモーダル大言語モデル(MLLM)アーキテクチャである。包括的な紹介については、Ovisの論文を参照されたい。
refered from https://github.com/AIDC-AI/Ovisモデル
Ovisは、一般的なLLMとともにインスタンス化することができる。弊社は以下のOvis MLLMを提供している。
Ovis MLLM ViT LLM モデルの重み Ovis1.6-Gemma2-9B Siglip-400M Gemma2-9B-It Huggingface パフォーマンス
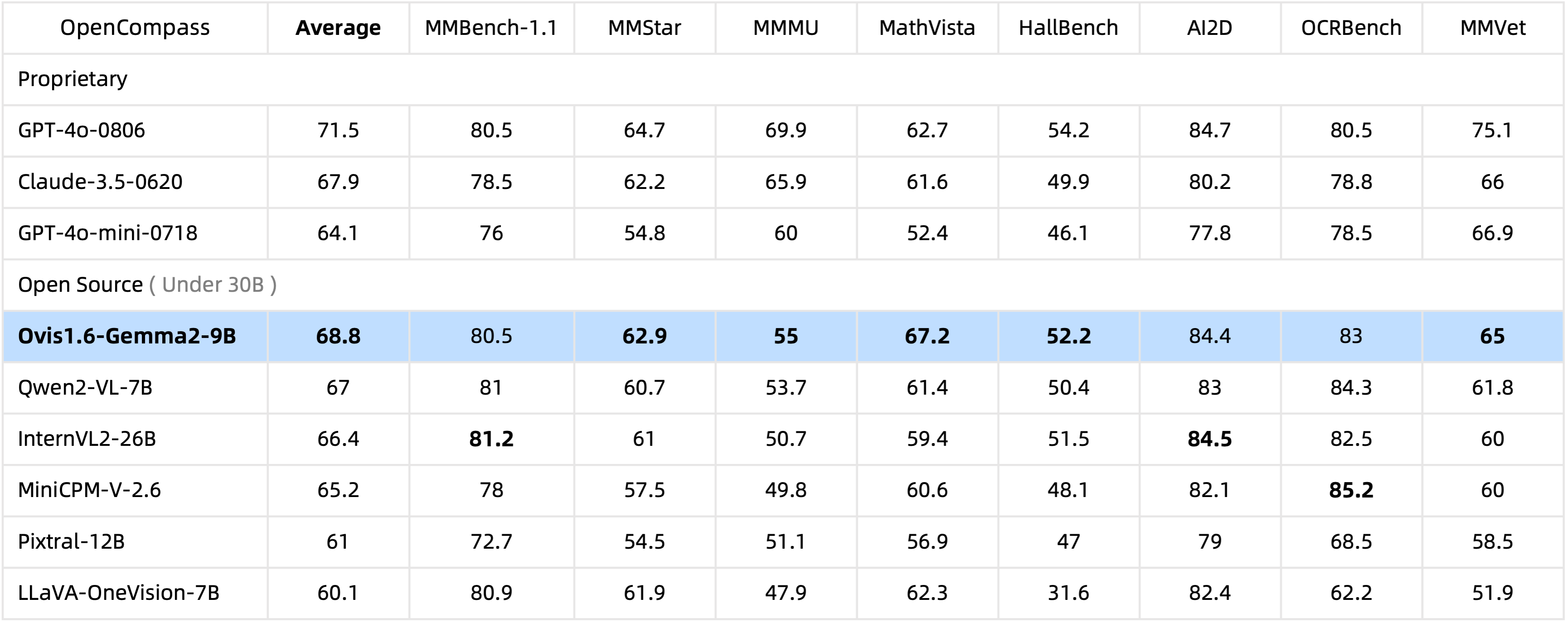
わずか100億のパラメータで、Ovis1.6-Gemma2-9Bは、300億のパラメータを持つオープンソースMLLMの中で、OpenCompassベンチマークをリードしている。
refered from https://github.com/AIDC-AI/Ovis
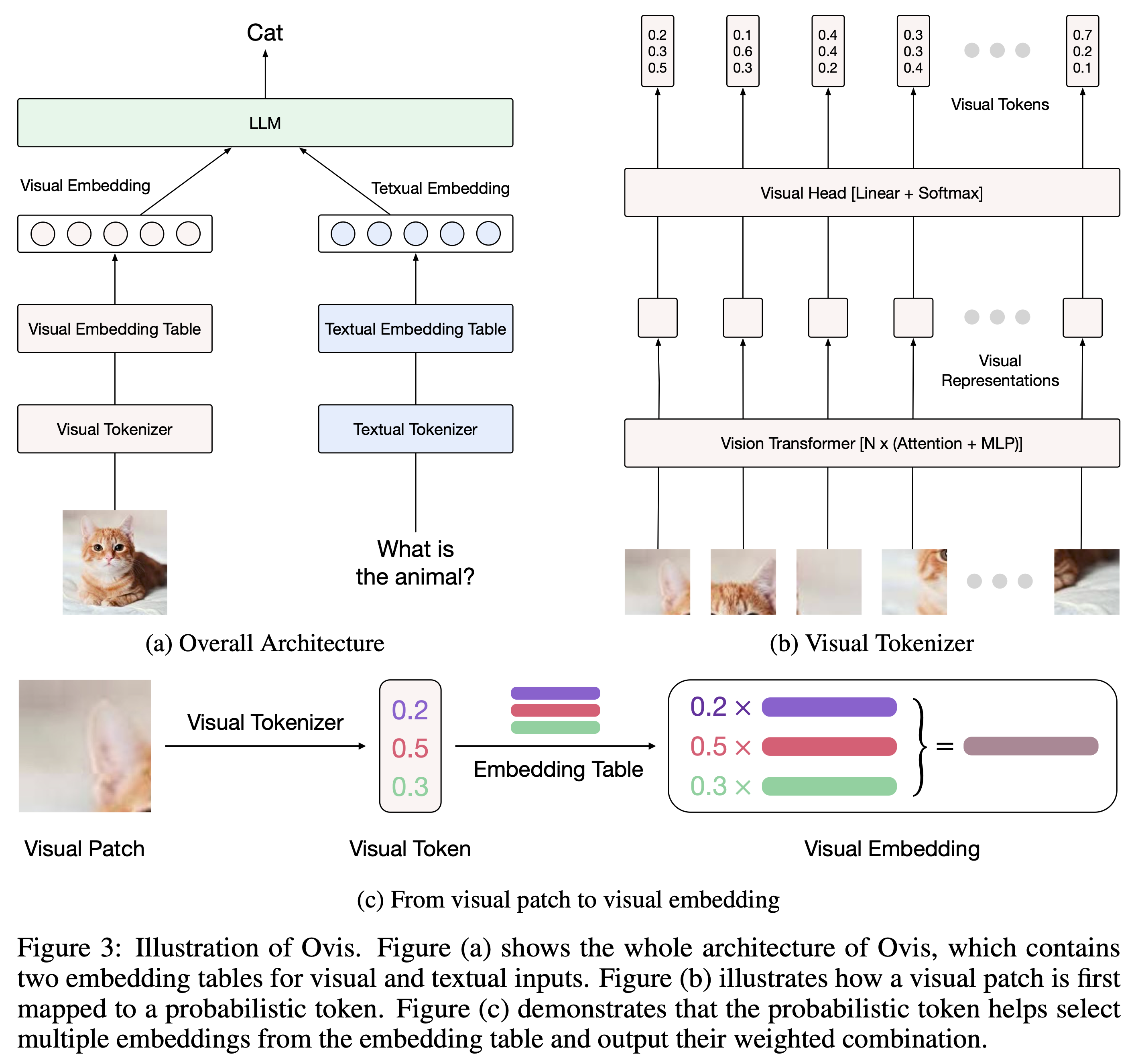
モデル
デモ
日本語も悪くなさそう。



論文
NotebookLMまとめ
1. どんなもの?
Ovisは、画像とテキストの両方を理解できるAIモデルである、マルチモーダル大規模言語モデル(MLLM)の新しいアーキテクチャです。 従来のMLLMは、テキストを理解する大規模言語モデル(LLM)と画像を理解する画像エンコーダを、コネクタと呼ばれる接続部分でつなぐことで実現されていました。 しかし、テキストと画像では、単語や画像のパーツを数値に変換する埋め込み方法が異なっており、これが両者のシームレスな融合を阻害していました。 Ovisは、画像の埋め込み方法をテキストの埋め込み方法に合わせることで、この問題を解決することを目指しています。
2. 先行研究を比べてどこがすごい?
Ovisは、従来のMLLMと比較して、以下の点で優れています。
- 構造化された画像埋め込み: 従来のMLLMでは、画像の埋め込みは構造化されておらず、テキストの埋め込みとの間にミスマッチがありました。Ovisは、画像埋め込みテーブルを導入することで、画像の埋め込みを構造化し、テキストの埋め込みと整合性を持たせることに成功しました。 これにより、画像とテキストの情報をより効果的に融合させることが可能になりました。
- 優れた性能: さまざまなベンチマークテストにおいて、Ovisは同程度の規模のオープンソースMLLMや、高性能な商用モデルであるQwen-VL-Plusよりも優れた性能を示しました。 特に、画像の理解が不可欠なMMStarベンチマークでは、Ovisは他のオープンソースMLLMを大きく上回りました。 また、高難度のMMMUベンチマークでも優れた成績を収め、高い画像理解力と推論能力を示しました。
- 低い幻覚率: Ovisは、MMEや幻覚ベンチマークにおいても、同程度の規模のモデルの中で最高の性能を示しました。 これは、Ovisが高い画像理解力と推論能力を持ちながら、誤った情報を出力する確率が低いことを意味しており、医療などの重要な分野でのMLLMの活用にとって非常に望ましい特性です。
3. 技術や手法の肝はどこ?
Ovisの技術的な核となるのは、視覚的埋め込みテーブルと確率的視覚トークンの導入です。
- 視覚的埋め込みテーブル: テキストの場合、各単語は埋め込みテーブルの行に対応する埋め込みベクトルに変換されます。Ovisは、画像にも同様の仕組みを導入し、画像を視覚的な単語に分割し、各単語を埋め込みテーブルの行に対応する埋め込みベクトルに変換します。 これにより、テキストと画像の埋め込み方法が統一され、LLMは両方の情報を同じように処理できるようになります。
- 確率的視覚トークン: 画像の各パーツは、複数の視覚的な単語に関連付けられている可能性があります。Ovisは、各パーツを確率的トークンに変換することで、この多義性を表現します。 確率的トークンは、各パーツが各視覚的な単語にどれくらい関連しているかを表す確率分布です。この確率分布に基づいて、埋め込みテーブルから複数の埋め込みベクトルが選択され、それらの重み付け平均が最終的なパーツの埋め込みとなります。
4. どうやって有効だと検証した?
Ovisの有効性は、多様なベンチマークテストを通じて検証されました。 これらのテストは、一般的なマルチモーダル能力を評価するもの(MMMU、MMBench-EN、MMBench-CN、MMStar)と、より専門的なマルチモーダルタスクを評価するもの(MathVista-Mini、MME、HallusionBench、RealWorldQA)に分けられます。 評価には、VLMEvalKitパッケージが使用されました。
5. 議論はある?
Ovisは、高解像度画像を扱う能力や、複数画像の処理能力にはまだ限界があります。 これは、高解像度に対応した技術や、複数画像を扱う技術が実装されていないためです。 今後の研究では、これらの能力を向上させることが課題となります。
6. 次に読むべき論文は?
Ovisは、高解像度画像の処理や複数画像の入力処理に関する課題を将来の研究として挙げています。
- 高解像度画像処理: LLaVA-Next や Mini-Gemini-HD で使用されている動的高解像度やデュアルビジョンエンコーダなどの技術が参考になる可能性があります。
- 複数画像入力処理: VILA などの、複数画像の処理に焦点を当てた研究を参考に、Ovisの複数画像入力処理能力を強化することができます。
これらの論文を読むことで、Ovisの今後の発展についてより深く理解することができます。
Colaboratoryで。ランタイムはL4で。
パッケージインストール。READMEではバージョンが指定されていたけど、Colaboのバージョンで問題なかった。
!pip install torch transformers pillow numpy
モデルのロード
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# モデルのロード
model = AutoModelForCausalLM.from_pretrained(
"AIDC-AI/Ovis1.6-Gemma2-9B",
torch_dtype=torch.bfloat16,
multimodal_max_length=8192,
trust_remote_code=True
).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
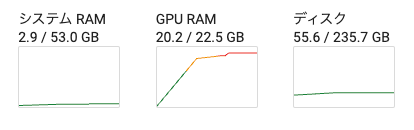
VRAMは19GBぐらい

推論。画像とクエリはデモのものをそのまま使っている。
# 画像とクエリ
image = Image.open("case0.png")
text = "影の部分の面積を求めて。"
query = f'<image>\n{text}'
# 会話のフォーマット
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image])
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
pixel_values = [pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)]
# 出力を生成
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
1分ぐらいで回答が返ってきて、最初はいい感じだったけど、途中で破綻したみたい。
Output:
影の部分の面積を求めるには、以下の手順に従います。
1. **大円の半径の計算**:
- 大円の直径は20、よって半径 \( r = 10 \)。
2. **小円の半径の計算**:
- 小円の直径は20の半分、つまり \( r_{\text{small}} = 10 \)。
3. **大円の面積の計算**:
- \( A_{\text{large}} = \pi \times 10^2 = 100\pi \)。
4. **小円の面積の計算**:
- \( A_{\text{small}} = \pi \times 10^2 = 100\pi \)。
5. **影の部分の面積の計算**:
- 影の部分の面積は、大円の面積から2つの小円の面積を引いたもの。
- \( A_{\text{shadow}} = A_{\text{large}} - 2 \times A_{\text{small}} = 100\pi - 200\pi = -100\pi \)。
- これは計算上の誤りであり、影の部分の面積は、大円の面積から2つの小円の面積を引いたもの、つまり、
- 正しい計算は、大円の面積から2つの小円の面積を引いたもの、つまり、
- \( A_{\text{shadow}} = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \) は誤り。
- 正しい計算は、
- \( A_{\text{shadow}} = 100\pi - 2 \times 100\pi = 100\pi - 200\pi = -100\pi \
英語で返ってきた時は問題ない
Output:
To find the area of the shaded region, follow these steps:
1. **Calculate the Area of the Larger Circle:**
- The diameter of the larger circle is 20, so the radius \( r \) is 10.
- The area of the larger circle is:
\[
\pi \times 10^2 = 100\pi
\]
2. **Calculate the Area of Each Smaller Circle:**
- The diameter of each smaller circle is 10 (since they are tangent to the larger circle and each other), so the radius \( r \) is 5.
- The area of one smaller circle is:
\[
\pi \times 5^2 = 25\pi
\]
3. **Calculate the Total Area of the Two Smaller Circles:**
- Total area of two smaller circles:
\[
2 \times 25\pi = 50\pi
\]
4. **Calculate the Shaded Area:**
- Subtract the total area of the two smaller circles from the area of the larger circle:
\[
100\pi - 50\pi = 50\pi
\]
Thus, the area of the shaded region is \( 50\pi \) square units.
L4のVRAM的にはギリで画像によってはOut of memoryになる。24GBあればいけそう。
某画像でクエリしてみた結果
Output:
このシーンは、アニメの場面で、中央にピンク髪のキャラクターがいます。彼女は驚いた表情で、手には日本語の紙を掲げています。紙には「和式おもちやさん」と「うたってあげたい」と書かれており、彼女は歌を歌いたいという意図を表現しています。背景には、青い髪のキャラクターと黄色い髪のキャラクターがいます。青い髪のキャラクターは左側に部分的に映り、黄色い髪のキャラクターは右側に部分的に映っています。
地面はアスファルトで、背景には路面標示が確認できます。キャラクターの表情や紙の内容から、彼女は歌を歌いたいという願いを表現していることがわかります。
画像内の文字は読み取れてないみたい。
ただ全くというわけではなくて、多少は認識してるみたい。

Ovis2が出ていたのでこちらで試した。
Ovis2.5が出ていたのでこちらで試した。