LangChainのTruLens Integrationを試してみる
TruLens is an opensource package that provides instrumentation and evaluation tools for large language model (LLM) based applications.
TruLens: scale up and accelerate LLM app evaluation
Create credible and powerful LLM apps, faster. TruLens is a software tool that helps you to objectively measure the quality and effectiveness of your LLM-based applications using feedback functions. Feedback functions help to programmatically evaluate the quality of inputs, outputs, and intermediate results, so that you can expedite and scale up experiment evaluation. Use it for a wide variety of use cases, like chatbot, question answering, and more.
- Build your LLM app
- Connect your LLM app to TruLens and log inputs and responses
- Use feedback functions to evaluate and log the quality of LLM app results
- Explore in dashboard
- Iterate to get to the best chain
なんか面白げー
まずインストール。condaを使っているようだけど、とりまうちはpyenv-virtualenvでやる。Python-3.10.11。
$ pyenv virtualenv 3.10.11 trulens
$ mkdir trulens && cd trulens
$ pyenv local trulens
何はともあれJupyter Notebook。
$ pip install jupyterlab ipywidgets
$ jupyter-lab --ip='0.0.0.0'
ここからはJupyter Notebookで。
!pip install trulens-eval
!git clone https://github.com/truera/trulens.git
%cd trulens/trulens_eval
!pip install -e .
次はQuickstart。
OpenAIとHuggingFaceのAPIキーをセット。
import os
os.environ["OPENAI_API_KEY"] = "..."
os.environ["HUGGINGFACE_API_KEY"] = "..."
サンプルコードに従ってシンプルなLLMChainを実行。
from IPython.display import JSON
from trulens_eval import TruChain, Feedback, Huggingface, Tru
tru = Tru()
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts.chat import ChatPromptTemplate, PromptTemplate
from langchain.prompts.chat import HumanMessagePromptTemplate
full_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template=
"Provide a helpful response with relevant background information for the following, in Japanese: {prompt}",
input_variables=["prompt"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([full_prompt])
llm = OpenAI(temperature=0.9, max_tokens=128)
chain = LLMChain(llm=llm, prompt=chat_prompt_template, verbose=True)
prompt_input = '今何時ですか?'
llm_response = chain(prompt_input)
結果。まあ普通に返ってくる。
> Entering new chain...
Prompt after formatting:
Human: Provide a helpful response with relevant background information for the following, in Japanese: 今何時ですか?
> Finished chain.
{'prompt': '今何時ですか?',
'text': '\n\n今は十二時五十五分です。時間を調べるためには、携帯電話や時計、パソコンのタイマーなどが便利です。'}
ではここからTruLensを組み込んでいく。HuggingFaceを使って入出力の言語が一致しているか?をチェックするフィードバック関数を定義する。
hugs = Huggingface()
f_lang_match = Feedback(hugs.language_match).on_input_output()
結果
✅ In language_match, input text1 will be set to *.__record__.main_input or `Select.RecordInput` .
✅ In language_match, input text2 will be set to *.__record__.main_output or `Select.RecordOutput` .
TruLensでロギングを行うためのChainを実装する。
truchain = TruChain(chain,
app_id='Chain3_ChatApplication',
feedbacks=[f_lang_match])
ここでどうやら内部データベースが作成される様子。恐らくここに記録されていくのではなかろうか。
✅ app Chain3_ChatApplication -> default.sqlite
✅ feedback def. feedback_definition_hash_b6beeeb0fcb5ef1c46ad0b9fadfa669b -> default.sqlite
TruLensで作成したChainを実行する。
llm_response = truchain(prompt_input)
display(llm_response)
なるほど、元のLLMChainをラップしてるような感じになるのか。
> Entering new chain...
> Finished chain.
{'prompt': '今何時ですか?', 'text': '\n\n現在、午後<数字>時<数字>分です。'}
✅ record record_hash_8e9497c3af357fe8c5f0e6a305a2788c from Chain3_ChatApplication -> default.sqlite
✅ feedback feedback_result_hash_0bd97c7bd82314353aaa2864e26cad9a on record_hash_8e9497c3af357fe8c5f0e6a305a2788c -> default.sqlite
TruLensのダッシュボードを立ち上げる
tru.run_dashboard()
結果
Starting dashboard ...
Dashboard log
Dashboard started at http://192.168.XXX.XXX:8501 .
<Popen: returncode: None args: ['streamlit', 'run', '--server.headless=True'...>
アクセスしてみるとこんな感じの画面が表示される。Streamlitですね。

「Leaderboard」は、アプリごとのレイテンシー・コスト・トークン数・平均フィードバック数が表示される。このアプリというのはTruChain()で指定したapp_idになる模様。平均フィードバック数は0〜1の範囲で1が「良い」ということらしい。
右の"Select App"をクリックすると、アプリ実行時に記録されたデータをより詳細に見れる様子。左のメニューだと「Evaluation」がこれっぽい。入力と出力、使用されたプロンプトなど、いろいろ表示される模様。

「Progress」はFeedback Progressとあるけど、ちょっとここは分からなかった。
ドキュメントを見ると、フィードバック関数がいろいろ用意されていて、もう少しなんかいろいろできそうな感がある。続きはまた。
フィードバック関数は予め用意されたものもあるし、自分で作ることもできる。
予め用意されたものをはこんな感じ。
- Relevance
- プロンプトとレスポンスの関連性を判定する
- Sentiment
- プロンプトおよびレスポンスの感情を判定する
- Model Agreement
- プロンプトおよびレスポンスの正しさ?を判定する
- Language Match
- プロンプトとレスポンスに使用されている言語が一致しているかを判定する
- Toxicity
- プロンプトとレスポンスに有害なものが含まれていないかを判定する
- Moderation
- プロンプトとレスポンスにヘイトや暴力的な表現等が含まれていないかを判定する
ToxicityとModerationの違いはちょっとわかりにくいな。Toxicityは以下のモデルを使ってるらしい。
ModerationはAPI Referenceにいくつか記載されてる。
見比べる限りはなんかあんまり違いが見えないのだけど、LangChainにもself-critique chainとmoderation chainがあるし、ネイティブ的にはここは違う間隔なのかもしれない。
Model Agreementってのもよくわからないけど、2回問い合わせて同じような回答が返ってくるかの検証をしてるっぽい。
LLMのレスポンスの正答率評価とかだとこの辺になるのかな。
- Relevance
- Model Agreement
自分でフィードバック関数を作る場合はここ
LangChainのドキュメントにもあるので少し見てみる。
from trulens_eval.feedback import Feedback, Huggingface, OpenAI
hugs = Huggingface()
openai = OpenAI()
lang_match = Feedback(hugs.language_match).on_input_output()
qa_relevance = Feedback(openai.relevance).on_input_output()
toxicity = Feedback(openai.toxicity).on_input()
truchain = TruChain(
chain,
app_id='Chain1_ChatApplication',
feedbacks=[lang_match, qa_relevance, toxicity]
)
truchain("今何時ですか?)
なるほど、複数のフィードバック関数を同時に使うこともできるということ。
ところで これ
from trulens_eval.feedback import Feedback, Huggingface, OpenAI
openai = OpenAI()
LangChain側でこう書いてると名前衝突しちゃうよねぇ。
from langchain.llms import OpenAI
こんな感じで書き換えてみた。
from trulens_eval.feedback import Feedback, Huggingface
from trulens_eval.feedback import OpenAI as TL_OpenAI
(snip)
from langchain.llms import OpenAI
(snip)
hugs = Huggingface()
openai = TL_OpenAI()
f_lang_match = Feedback(hugs.language_match).on_input_output()
f_qa_relevance = Feedback(openai.relevance).on_input_output()
f_toxicity = Feedback(hugs.not_toxic).on_input()
truchain = TruChain(
chain,
app_id='Chain1_ChatApplication',
feedbacks=[f_lang_match, f_qa_relevance, f_toxicity],
tru=tru
)
truchain("今何時ですか?")
Toxicityのフィードバック関数もLangChain側のドキュメントは間違ってるようなのでTruLensのAPIリファレンスを見て修正してる。
これでChainを実行してみると、GUIの方には以下のような感じでロギングされて、各フィードバック関数の結果が出力される。
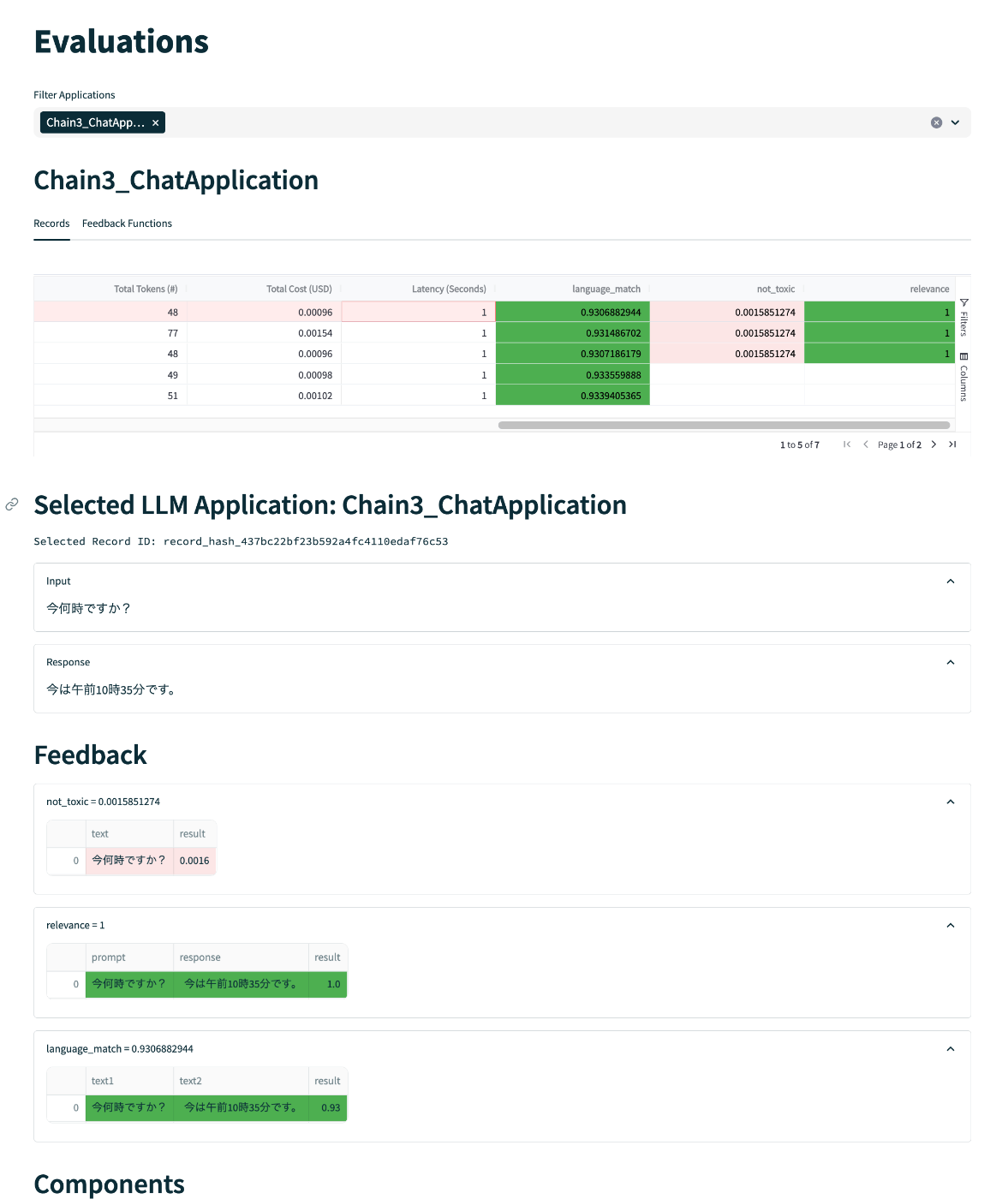
んー、toxicはなんかおかしい?元のモデルでテストしても問題ないんだけどなんでtoxicと判定されてるんだろう?まあその他は想定どおりなので一旦忘れる。
ここまではTruLensを使ったEval(評価)なのだけど、TruLensにはExplainという機能もある様子
TruLens-Explain is a cross-framework library for deep learning explainability. It provides a uniform abstraction over a number of different frameworks. It provides a uniform abstraction layer over TensorFlow, Pytorch, and Keras and allows input and internal explanations.
こちらはちょっとパス
まとめ
いいなと思うのは以下の点
- 記録しつつ評価できるというのは良さそう。
- 複数の評価を同時に行えるというのも良さそう。
ただ作りを見てると、ワンタイムでLLMの評価するぞー、みたいな感じではなくて、いっそ商用でずっと立ち上げておく or 一定期間立ち上げておく、で結果は後でまとめて見る/必要なときに見るみたいな使い方をしたくなる。ロギングもしてくれるわけだし。
それを考えると、SQLiteとかじゃなくてリモートのDB使いたいなと思うし、コード的にもLangChainのchainをラップする感じになってるので、気軽にON/OFFってわけにもいかなさそう。個人的には評価テストはauto-evaluatorみたいなやつのほうが評価に集中できてよいかなという印象。(auto-evaluatorは以前試したけど日本語だといろいろ辛かった。今は改善されてるのかなぁ・・・)。ユースケースに合えば、って感じ。
あと気になったのはここ
Log App Feedback
Capturing app feedback such as user feedback of the responses can be added with one call.
thumb_result = True tru.add_feedback(name="👍 (1) or 👎 (0)", record_id=record.record_id, result=thumb_result)
こういうユーザーフィードバックを受ける仕組み、StreamlitあたりでUI用意すれば比較的簡単に実装できるのかな?
ほほー
TruBricksというのを使ってるらしい。