ElevenLabs初のSpeech-to-Textモデル「Scribe」を試す
Scribeの紹介 — 最も正確なSpeech-to-Textモデル
ベンチマークでは最高精度を誇り、Gemini 2.0やOpenAI Whisper v3などのこれまでの最先端モデルを凌駕しています。
現在では、英語、スペイン語、イタリア語など、多くの言語でトップクラスのモデルとなっています。99言語のサポート、話者ダイアライゼーション、文字レベルのタイムスタンプ、笑い声などの非音声イベントにも対応しています。
ほとんどの一般的な言語については、最高精度を実現しています。
また、これまでサポートが十分でなかったセルビア語、広東語、グジャラート語などの言語のパフォーマンスも大幅に改善しています。
ベンチマークと機能の詳細については、次のブログ投稿をご覧ください。
Scribe の低レイテンシー バージョンは近日中にリリースされ、リアルタイムでのユースケースにScribeを拡張します。
Scribeは本日より、UIとAPIの両方でご利用いただけます。
価格は入力音声1時間あたり0.40ドルで、今後6週間は50%の割引が適用されます。
アカウントの登録はこちらから:
公式ブログ
Scribeは、当社初の音声認識モデルであり、世界で最も精度の高い書き起こしモデルです。現実世界の音声の予測不能な性質に対応するように設計されたScribeは、99言語の音声を書き起こし、単語レベルのタイムスタンプ、話者ダイアライゼーション、オーディオイベントタグ付けなどの機能を備えています。これらの機能はすべて、シームレスな統合を可能にする構造化された応答として提供されます。
Scribeは高精度を目指して設計されています。 99言語にわたるFLEURS & Common Voiceベンチマークテストでは、Gemini 2.0 Flash、Whisper Large V3、Deepgram Nova-3のような主要モデルを常に上回っています。 会議の要約であれ、映画の字幕であれ、あるいは歌の歌詞であれ、Scribe はイタリア語 (98.7%)、英語 (96.7%)、その他97の言語において、最も低い自動テープ起こしワードエラー率を実現しています。
Scribeは、ASRを普遍的に利用可能なものとし、競合モデルがしばしば40%を超える単語エラー率を示す、セルビア語、広東語、マラヤーラム語のような伝統的に十分なサービスを受けていない言語におけるエラーを劇的に減少させます。
開発者は、Speech to Text API を介して、今日から Scribe を統合し、話者の日付けや単語レベルのタイムスタンプ、非スピーチイベントマーカー(笑いなど)を含む構造化された JSON トランスクリプトを取得することができます。 リアルタイムアプリケーション用の低遅延バージョンは近日リリース予定です。
ポストにある通り、ElevenLabsはこれまでSpeech−to−Textモデルを提供していなかったので、初のSTTなのだけれども、以前リリースされていた音声エージェント構築サービス「Conversational AI」ではSTTも実装されていた。推測にはなるが、おそらくそこで使われていた可能性がある。
ブログ記事にベンチマークがあるのだけども、画像が小さすぎて見えない・・・

referred from https://elevenlabs.io/blog/meet-scribe
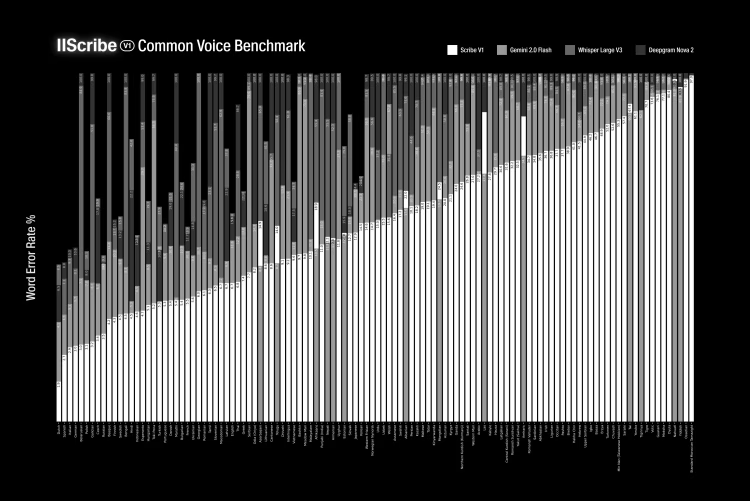
referred from https://elevenlabs.io/blog/meet-scribe
言語ごとでは異なる場合もあるかもしれないが、概ねエラーレートは他社よりも低いというふうには見える。
あとは動画にも対応しているのいうのは、STT専用のサービスとしてはユニークな特徴かもしれない。
Conversatioal AIで試した際はそれほど精度高いというふうには個人的に感じなかったが、同じモデルであるかどうかもわからないので、少し試してみる。
公式ドキュメント
まず日本語にもきちんと対応している。
対応言語
Scribe v1モデルは、以下の99言語に対応しています:
(snip)、 日本語(jpn)、(snip)
あと、言語ごとのベンチマークの大まかな結果があった。エラーレートを4つのグループに分けて、各言語がどのグループに含まれるかという形。
言語サポートの内訳
単語誤り率(WER)は、書き起こしシステムの精度を評価する際に使用される主要な指標です。これは、参照用書き起こしと比較した際の書き起こしに含まれる誤りの数を測定します。以下は、Scribe v1がサポートする各言語のWERの内訳です。
- Excellent (エラーレートが5%以下)
- (snip)、 日本語(jpn)、(snip)
- High Accuracy (エラーレートが5%を超え10%以下)
- Good (エラーレートが10%を超え25%以下)
- Moderate (エラーレートが25%を超え50%以下)
少なくとも日本語についても高い精度を謳っている様子。
Colaboratoryで試す。
パッケージインストール
!pip install elevenlabs
!pip freeze | grep -i elevenlabs
elevenlabs==1.52.0
サンプル音声として、自分が開催した勉強会のYouTube動画から冒頭5分程度の音声を抜き出したオーディオファイルを用意した。
from elevenlabs.client import ElevenLabs
from io import BytesIO
from google.colab import userdata
client = ElevenLabs(
api_key=userdata.get('ELEVENLABS_API_KEY')
)
with open("voice_lunch_jp_5min.wav", "rb") as f:
audio_data = BytesIO(f.read())
transcription = client.speech_to_text.convert(
file=audio_data,
model_id="scribe_v1", # モデルの指定。現時点では "scribe_v1" のみサポート
tag_audio_events=True, # 笑いや拍手などの音声イベントのタグ付けを有効化
language_code="jpn", # 音声の言語。指定がない場合は自動判別
diarize=True, # 話者ダイアライぜーションのアノテーションを有効化
)
print(transcription.text)
だいたい14秒ぐらいで結果が出た。
はい。じゃあ始めます。ちょっとまだ来られてない方もいらっしゃるんですけど、 VOICE LUNCH JP 始めます。皆さん日曜日、はーい。日曜日にお集まりいただきましてありがとうございます。今日久しぶりにですね、オフラインということで、今日はですね、スペシャルなゲストをお二人来ていただいております。ということで、はい。えーと今日ちょっとトピックに参りますけれども、 Voice Flow の CEO であるブレゼンリームさんと、あとセールスフォースのカンバンシステムデザインのディレクターであるグレッグベネットさんに来ていただいてます。ということで、日本に来ていただいてありがとうございます。はい。で、今日はちょっとこの、おふたりにまた後でいろいろと聞こうという、えーとコーナーがありますので、そこでまたいろいろと聞きたいと思います。で、今日のアジェンダなんですけども、えーと、ちょっと時間過ぎちゃいましたが、まず最初に VOICE LUNCH JP についてというところ。あと会場のとこですね、少しご説明させていただいて、一つ目のセッションで、えーと、まず私の方から、えーと Voice Flow の2022年の、新機能とかですね、その辺の話を少しさせていただいて、そのあとえっと、二つ目のセッションで、えーとブレイデンさんとグレッグさんにいろいろ、カンバセーショナル、カンバセーショナルデザインですね、について、何でも聞こうぜ、みたいなところを予定しております。で、その後、15時から、えーと15時で一旦終了という形でさせていただいて、一応VOICELUNCHJP、確か記念撮影は必須ですよね。なのでそれだけさせていただいて、その後ちょっと1時間ぐらい、あの簡単にお菓子と飲み物を用意してますので、懇親会というのをそのままさせていただこうと思っています。で、えーと VOICE LUNCH JP についてなんですけども、えーと VOICE LUNCH はボイス UI とか音声関連ですね、そういった技術にえーと、実際に携わっている人、もしくは興味がある人、そっちのためのグローバルなコミュニティという形になっていて、えーと VOICE LUNCH のえーと、日本リージョンという形が VOICE LUNCH JP になってますと。で、過去もずっとやってますけど、オンラインオフラインでいろんな音声のでないんだったり、技術だったりというところで、情報とかを共有して、みんなで業界を盛り上げていこうぜというようなことでやっております。で、今日の、えーとハッシュタグですね、#voicelunchjpでいろいろと自由にシェアしてください。で、あと会場ですね。今回グラニカ様のご好意で利用させていただいてます。ありがとうございます。で、ぜひこちらもシェアをお願いしたいですと。で、ちょっと配信のところもいろいろとやっていただいてますんで、非常に感謝しております。で、ちょっと今、あの、ごめんなさい、どけた。今あの、えーとコロナで会場に来られる方とかもあまりいないということで、されてないんですけれども、あの通常はなんかここで IoT 機器のとかガジェットとかを展示されているようなので、そういったものがあるとき、今度ですね、また体験してみていただければなと思っています。というところで、あとすいません、トイレがこちらで、あとたばこ吸われる方はこちらのところになってますので、よろしくお願いします。はい。ということで、最初の挨拶はこれで。じゃあまず私のほうのセッションから、させていただきますというところで。 VOICE FLOW UPDATE 2022 というところで、えーと今年の新機能について少しお話をします。えーと自己紹介です。清水と申します。えーと神戸でインフラのエンジニアをやってます。なので普段はKubernetesとか AWS とか Terraform とかをいじってまして、最近ちょっとフリーランスになります。で、えーとちょっと調べてみたら、 VOICE FLOW 一番最初に始めたのが 2019年の頭ぐらいなので、だいたい 4年弱ぐらいですね、いろいろと触ってまして。あと音声関連のコミュニティーのとこでは、えーと VOICE LUNCH JP、 今回のやつですね、以外にえーと、AJUG、 Amazon Alexa Japan User Group とか、あと VOICE FLOW のえーと日本語ユーザーグループということで、 VFGUG というのをやっています。はい。えーと日本コミュニティの方は Facebook の方でえーと、やってますので、もしよろしければ見ていただければなと思います。あと 2年ぐらい前にですね、えーと技術書店の方で、ここに今日スタッフで来ていただいている皆さんとですね、一緒に同人誌作ろうぜということで、えーと作ったんですけれども。もうこれちょっと 2年ぐらい経って、中身がだいぶ古くなってしまっているので、すでにちょっと販売は終了しております。今日はちょっと持ってきたかったんですけど、すいません、忘れてしまいました。はい。なのでこういうこともやっています。
おお、確かに結構精度高いかもしれない。固有名詞などで多少間違ってるぐらいで、そもそも固有名詞は難しいし、あと私の発音、というか今聞くと自分の滑舌悪いな・・・、ってのもある。それを踏まえてもかなりいい感じに思える。
あと、レスポンスのwordsにタイムスタンプごとの発話が含まれている。
for w in transcription.words:
print(w.model_dump())
{'text': 'は', 'start': 0.919, 'end': 1.039, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'い', 'start': 1.039, 'end': 1.379, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '。', 'start': 1.379, 'end': 1.419, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'じ', 'start': 1.419, 'end': 1.439, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ゃ', 'start': 1.439, 'end': 1.559, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'あ', 'start': 1.559, 'end': 1.679, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '始', 'start': 1.679, 'end': 1.939, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'め', 'start': 1.939, 'end': 2.079, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ま', 'start': 2.079, 'end': 2.22, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'す', 'start': 2.22, 'end': 2.319, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '。', 'start': 2.319, 'end': 2.399, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ち', 'start': 2.399, 'end': 2.44, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ょ', 'start': 2.44, 'end': 2.5, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'っ', 'start': 2.5, 'end': 2.579, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'と', 'start': 2.579, 'end': 2.7, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ま', 'start': 2.7, 'end': 2.819, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'だ', 'start': 2.819, 'end': 3.019, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '来', 'start': 3.019, 'end': 3.22, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ら', 'start': 3.22, 'end': 3.359, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'れ', 'start': 3.359, 'end': 3.399, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'て', 'start': 3.399, 'end': 3.539, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'な', 'start': 3.539, 'end': 3.639, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'い', 'start': 3.639, 'end': 3.799, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '方', 'start': 3.799, 'end': 4.179, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'も', 'start': 4.179, 'end': 4.4, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'い', 'start': 4.4, 'end': 4.519, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ら', 'start': 4.519, 'end': 4.679, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'っ', 'start': 4.679, 'end': 4.859, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'し', 'start': 4.859, 'end': 4.94, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ゃ', 'start': 4.94, 'end': 5.079, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'る', 'start': 5.079, 'end': 5.219, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ん', 'start': 5.219, 'end': 5.42, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'で', 'start': 5.42, 'end': 5.559, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'す', 'start': 5.559, 'end': 5.759, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'け', 'start': 5.759, 'end': 5.9, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ど', 'start': 5.9, 'end': 6.92, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '、', 'start': 6.92, 'end': 6.92, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': ' ', 'start': 6.92, 'end': 6.96, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'V', 'start': 6.96, 'end': 6.98, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
(snip)
このtypeってのがオーディオイベントのタグ付けを有効化した際に出力されるものらしく、以下のようなタイプが有る様子
-
word
音声で発話された単語 -
spacing
単語間の区切り。スペースで分割するような言語でのみ使用。日本語などスペース区切りではない言語では使用されない。 -
audio_event
笑いや拍手などの発話ではないサウンド。フィラーのようなものも含まれる。
ざっと見た感じ、今回のサンプルではword以外は検出されていなかった。日本語の「えーと」みたいなのは音声イベントとして認識されないみたい。
でspeaker_idが話者ダイアライぜーションの結果になる様子。今回は一人しか発話していないので、あまり意味がないが。なお、入力可能な音声は最大3600秒なのだが、話者ダイアライぜーションを有効にした場合は最大480秒になる点には注意。
その他、今回はあらかじめ言語指定しているが、自動判別した場合には以下のようなプロパティも役に立つかもしれない。
print(transcription.language_code, transcription.language_probability)
jpn 0.0
以前試した、Kotoba-Whisperのサンプル音声には、複数の話者(3人)が含まれていたので、それを流用させていただいて試してみたところ、きちんと話者ダイアライぜーションが有効になっていた。
(snip)
{'text': 'か', 'start': 12.079, 'end': 12.199, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'え', 'start': 12.199, 'end': 12.3, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'っ', 'start': 12.3, 'end': 12.38, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'て', 'start': 12.38, 'end': 12.439, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '湿', 'start': 12.439, 'end': 12.579, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '度', 'start': 12.579, 'end': 12.739, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'が', 'start': 12.739, 'end': 12.84, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '上', 'start': 12.84, 'end': 12.88, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'が', 'start': 12.88, 'end': 12.979, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'っ', 'start': 12.979, 'end': 13.099, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'て', 'start': 13.099, 'end': 13.219, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'き', 'start': 13.219, 'end': 13.299, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'ま', 'start': 13.299, 'end': 13.439, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': 'す', 'start': 13.439, 'end': 13.559, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': '。', 'start': 13.559, 'end': 13.619, 'type': 'word', 'speaker_id': 'speaker_0', 'characters': None}
{'text': ' ', 'start': 13.619, 'end': 13.599, 'type': 'spacing', 'speaker_id': 'speaker_0', 'characters': [{'text': ' ', 'start': 13.619, 'end': 13.599}]}
{'text': 'や', 'start': 13.599, 'end': 13.739, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'っ', 'start': 13.739, 'end': 13.799, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'ぱ', 'start': 13.799, 'end': 13.84, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'り', 'start': 13.84, 'end': 14.219, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': '愚', 'start': 14.219, 'end': 14.619, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': '直', 'start': 14.619, 'end': 14.639, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'に', 'start': 14.639, 'end': 14.839, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': '、', 'start': 14.839, 'end': 14.859, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'や', 'start': 14.859, 'end': 14.979, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'っ', 'start': 14.979, 'end': 15.039, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'ぱ', 'start': 15.039, 'end': 15.059, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'り', 'start': 15.059, 'end': 15.179, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'そ', 'start': 15.179, 'end': 15.38, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': 'の', 'start': 15.38, 'end': 15.399, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
{'text': '街', 'start': 15.399, 'end': 15.639, 'type': 'word', 'speaker_id': 'speaker_1', 'characters': None}
(snip)
まとめ
上でも書いたけども、
おお、確かに結構精度高いかもしれない。固有名詞などで多少間違ってるぐらいで、そもそも固有名詞は難しいし、あと私の発音、というか今聞くと自分の滑舌悪いな・・・、ってのもある。それを踏まえてもかなりいい感じに思える。
このあたりは公式が謳っている通り精度は非常に高いように思えた。
また、文字起こしを見ていると、いくつかの固有名詞は明らかに「理解」しているように思えるところがあった。
今日の、えーとハッシュタグですね、#voicelunchjpでいろいろと自由にシェアしてください。
あの通常はなんかここで IoT 機器のとかガジェットとかを展示されているようなので、
なので普段はKubernetesとか AWS とか Terraform とかをいじってまして、
このあたり、単純なSTTモデルというよりも、STTに特化したマルチモーダルモデルなのではないだろうか?という気がする。
自分は「Conversational AI」を試した際に、全体的な日本語精度にはあまり良くない印象を持っていて(かなり簡単には作れるのだけども)、おそらくそこで使用していたものだろうと推測していたので、本当に精度高いのかな?と思いながら試したのだが、良い意味で自分の予想は裏切られた。
あらためて「Conversational AI」を試してみたときの会話ログを見直してみたところ、STTは思ったよりは悪くなかったので、日本語TTSの精度の悪さで全体的なイメージが悪くなっていたのかもしれない。決めつけや思い込みは良くない、きちんと試してから判断しないといけないなと少し反省した。
あと、精度が高いのもそうだけど、価格もこれかなり安いんではなかろうか?自分が調べた感じだと、STTはOpenAI Whisperが一番安いのだが、ほぼ同等の価格帯、しかも今は期間限定50%オフでこの精度はかなり競争力高いように思える。精度と価格だけが全てではないにせよ、バッチ処理で使うなら全然良さそうに思える。

kun432個人調べ
個人的には、リアルタイムアプリケーション用の低遅延バージョン、大いに期待したい。
あとは日本語TTSをなんとかしてほしい・・・・ストリーミング入力とかもあってリアルタイムでは使いやすいと思うので是非・・・
やっとでたな
Scribe v2 Realtimeのご紹介 – 最も正確なリアルタイム音声テキスト変換モデル。
ボイスエージェント、ミーティングノートテイカー、ライブアプリケーション向けに構築されており、英語、フランス語、ドイツ語、イタリア語、スペイン語、ポルトガル語、ヒンディー語、日本語を含む90言語以上で150msでの転写を実現します。
本日よりAPIおよびElevenLabs Agentsを通じて利用可能です。
Scribe v2 Realtime は、ライブ精度の新たな標準を設定し、あらゆる低遅延 ASR モデルを上回ります。
Scribe v2 Realtime は、agentic なユースケースのために特別に構築されています。
背景ノイズと複雑な情報が含まれる難しいサンプルでは、他のすべてのモデルを大幅に上回る性能を発揮します。
主な特徴:
- 最先端の精度
- 90以上の言語対応
- SOC 2、ISO27001、PCI DSS L1、HIPAA、GDPR準拠
- EUおよびインドに拠点を置く
- データ保持ゼロモード
APIを使って構築してください。
Scribe v2 Realtimeは本日利用可能です。
ドキュメントを読む: https://elevenlabs.io/docs/capabilities/speech-to-text
ElevenLabs Agents で Scribe v2 Realtime を使用してください。
サポート、営業、製品内エクスペリエンス向けに、自然で人間らしいサウンドのエージェントを展開します。
今日から構築を始めましょう。
Scribe v2 Realtime を API 経由または ElevenLabs Agents 内で直接使用できます。
こちらからサインアップ: https://elevenlabs.io/realtime-speech-to-text
なかなか挑戦的
昨日、ElevenLabsは新しいリアルタイム音声認識モデルをリリースし、「Scribe v2 Realtimeは最も正確な音声認識モデルです」と主張しました。
私たちはそれをテストすることにしました。
あなたも試せます、1分しかかかりません。🎙 http://soniox.com と http://elevenlabs.io/speech-to-text にアクセス
🗣 自分の言語で話す
🔢 いくつかの英数字を試す:ID、メールアドレス、住所
🌍 文の途中で言語を切り替える
👥 複数の話者が話す次に、各システムが正確性、言語検出、話者分離をどのように処理するかを観察してください。
結果は自明です。
🎥 以下のビデオをご覧ください。どのモデルを本物の音声AIエージェントを駆動するために信頼しますか?
デモ見る限りはSonioxの勝ちに見えるが、果たして・・・。Scribe v2 Realtimeは別途試してみようと思う。
なお、Sonioxについては以下で試している。