Amazon Kendraを試す
概要
機械学習を活用したインテリジェントなエンタープライズ検索で回答を迅速に見つける
- 複数の構造化および非構造化コンテンツリポジトリに対して、統一された検索エクスペリエンスを迅速に実装します。
- 自然言語処理 (NLP) を使用することで、機械学習 (ML) の専門知識がなくても、非常に正確な回答を得ることができます。
- コンテンツの属性、鮮度、ユーザーの行動などに基づいて検索結果を微調整します。
- ML を活用したインスタント回答、FAQ、ドキュメントのランク付けを、フルマネージド型サービスとして提供します。
料金
エンタープライズ検索というだけあって料金はちょっと高め
Amazon Kendra サービスは、実際に使用した分に対してのみ料金が発生します。前払いコストの義務はありません。インデックスを作成して、Amazon Kendra をプロビジョニングすると、インデックスの作成から削除までの時間に応じて Amazon Kendra の時間が課金されます。部分インデックスのインスタンス時間は、1 秒単位で課金されます。
Amazon Kendra には 2 つのエディションがあります。Kendra Enterprise Edition (KEE) では、本番ワークロード用に高可用性のサービス (1K USD/月) を提供します。Kendra Developer Edition (KDE) では、デベロッパーに PoC (概念実証) を構築する低コストのオプション (810 USD/月) を提供します。このエディションは本番ワークロードには推奨されません。
無料枠がある
最初の 30 日間で最大 750 時間の無料利用枠が提供される Amazon Kendra Developer Edition を無料で始めることができます。コネクタの使用は無料利用には含まれず、通常の使用時間とスキャンの料金が適用されます。無料利用枠の制限を超過した場合、使用した追加のリソースに対して Amazon Kendra Developer Edition の料金が発生します。
コネクターとはなんぞや?
コネクタを使用すると、複数のコンテンツリポジトリのデータを Amazon Kendra インデックスと簡単に同期できます。コネクタはインデックスとデータソースを自動で同期させるようにスケジュールすることができるため、ユーザーは常に最新のデータコンテンツを安全に検索できます。
なるほど、同期を取るためのものらしい。ざっと見た感じ、ウェブクローラー、S3、Dropbox、Googleドライブ等がある。新しいドキュメントなどが増えると自動でインデックス貼り直してくれるみたいなイメージかな。イメージとしてはLlamaIndexのLlamaHubとか、LangChainのDocumentLoadersと同じような感じがする。
あとインテリジェントリランキングは別料金に見える。
こちらは1000クエリ単位での課金の様子。
あとコチラも無料枠がある。
You can get started for free with Amazon Kendra Intelligent Ranking. The AWS Free Tier provides free usage of up to 750 hours for the first 30 days for base capacity customers (1 capacity unit). If you exceed the free tier usage limits, you’ll be charged the Amazon Kendra Intelligent Ranking rates for the additional resources you use.
ハンズオン
オンデマンドセミナーがあるので、これに沿って試してみるか・・・
と思ったけど、builders.flashにもあるな、こっちの方が自分のペースでできるので良さそう。
まずこちらから
以下メモ
Kendra概要
- AWSのドキュメント検索でも使われている
- 以下の質問・検索に対応
-
Factoid 型
- 誰が、何を、いつ、どこで、など。1単語・1語句で事実を回答するような質問
- 「Kendra が一般利用可能になったのはいつ?」
- Haystackでやったこういうやつ
-
Non-Factoid 型
- 1 文/1 節/ドキュメント全体が回答となる、理由や説明を問うもの。
- 「Kendra はどのようなサービス?」
-
キーワードまたは自然言語による検索
- 検索キー、もしくは自然言語で検索する
- 「Kendra 構築 手順」
- 「Kendraの構築手順」
- 自然言語ではセマンティックサーチも可能
-
Factoid 型
検索できるデータフォーマット
- 構造化テキスト
- 非構造化テキスト
- HTML
- Word/Excel等のOffice系ファイル
- 一覧はここ
検索できるデータソース
- RDBやストレージなどなど
- サードパーティも
- 一覧はこの辺
- 多分コネクタってこれのことだと思った
リージョン
今は東京リージョンでも使える
主な機能
以下はハンズオン資料にあった2023年1月の情報。今はどうなってるのかわからない。
- 日本語で使えるもの
- セマンティックサーチ
- FAQ
- メタデータ検索
- チューニング
- 日本語未対応
- 増分学習
- クエリ自動補完(インクリメンタルサーチ)
- 類義語検索
- ただし日本語でもDynamoDBを使ってカスタムシノニム辞書を作れば実現可能
ChangeLogはここ。見た感じ面白いそうなのがあるが、日本語の対応状況は知らない。
RAG向けを謳っているものもある
インデックス作成
「4. Amazon Kendra での検索を実際に試してみる」に沿って作成していく。
- マネージメントコンソールからKendraを開く
- "Create Index"をクリック
- インデックス設定は以下
- Index name:
sample-index - IAM Role:
Create a new role (Recommended)を選択- Role name:
AmazonKendra-ap-northeast-1-sample-index-role-
AmazonKendra-ap-northeast-1-までは勝手に設定される
-
- その他はデフォルトで
- Role name:
- Index name:
- アクセスコントロール設定
- 両方ともデフォルト(「No」「None」)で
- エディション設定
- 今回は無料枠でやるので「Developer edition」で。
- 確認画面が表示されたら「Create」
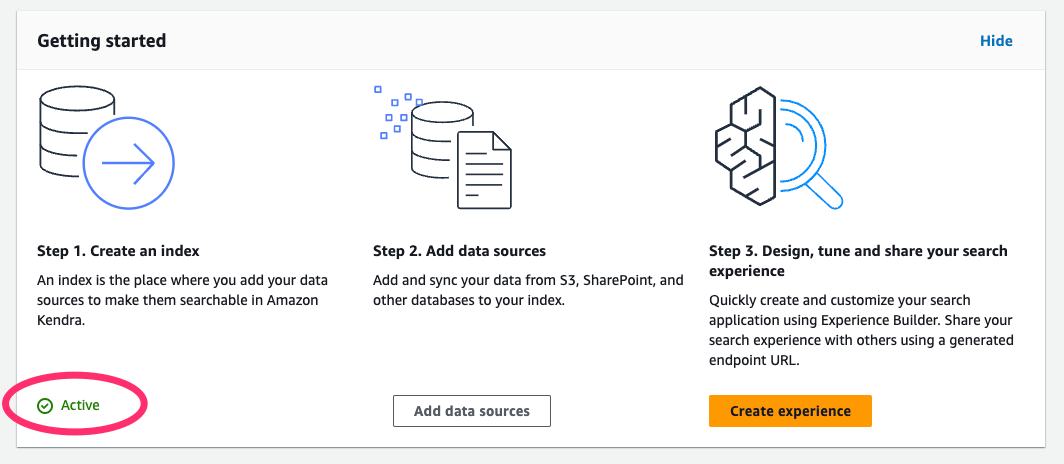
インデックス作成までには30分ぐらいかかるらしい。

ここがActiveになればOK
データソースの作成
インデックス化するドキュメントをおいておくためのデータソースとして、S3バケットを作成。記載の通りCloud Shellで作成してS3バケットにサンプルのPDFを配置する。
以下のようになった。
$ aws s3 ls s3://kendra-sample-data-source-XXXXX --recursive
2023-11-17 10:33:19 35286005 awsdoc/DynamoDB.pdf
2023-11-17 10:33:19 7459182 awsdoc/Kendra.pdf
2023-11-17 10:33:20 20797389 awsdoc/Lambda.pdf
2023-11-17 10:33:19 8699426 awsdoc/Route53.pdf
2023-11-17 10:33:19 4270533 awsdoc/VPC.pdf
データソース追加
「Add data sources」から「Amazon S3 Connector」を探して「Add connector』をクリック。
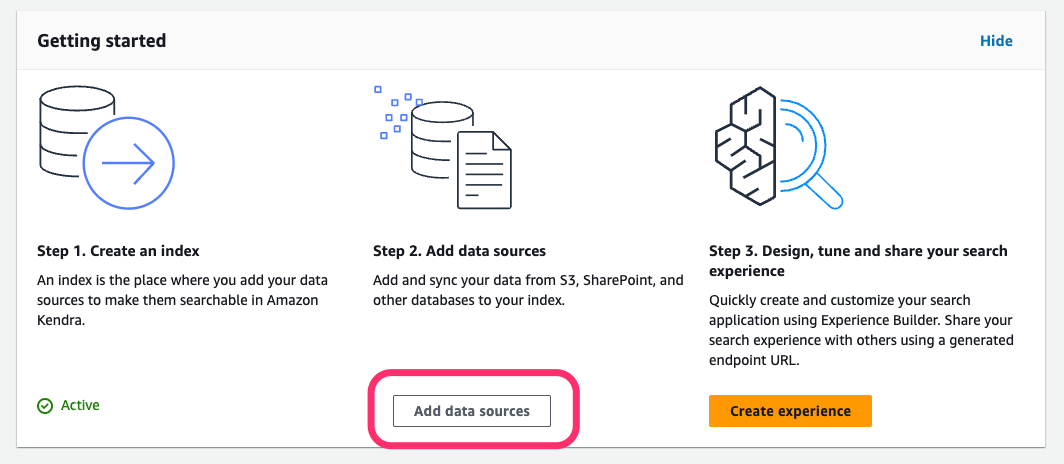
ちなみにサンプルも用意されているっぽいので、チュートリアルとしてはコチラを選んでも良さそうだけど、まあ一連の流れを抑える意味でS3を自分で作ったほうが良さそう。

「Specify data source details」の画面でデータソースの設定を行う。なるほど、言語の指定はデータソースレベルで行うのか。
- Data source name:
sample-data-source - Ddefault Language:
Japanese (ja)
「Define access and security」でアクセス・セキュリティ設定を行う。最初に作ったIAMロールはインデックス/FAQ作成用になるらしく、ここでは使えない。データソース側のIAMロールを別に作るっぽい。
- IAM role:
Create a new role (Recommended)を選択- Role name:
AmazonKendra-sample-data-source-role
- Role name:
- VPC:
No VPCを選択。
「Configure sync settings」でデータ同期の設定
- Enter the data source location: 上で作成したS3バケットを指定、例えば
s3://kendra-sample-data-source-XXXXX- メタデータやACLを別のバケットにおいておくこともできるらしい。
- S3バケットのフォルダを指定する。Additional configuration - optional Add patterns to include or exclude documents from your index をクリックして以下を設定
- Include patternsタブを選択
- Type:
Prefix - Prefix:
awsdoc - 「Add」をクリック
- Sync mode:
Full sync-
Full syncで前回の同記事の変更に関係なくすべて同期、New, modified, or delete contetnt syncで新規作成・変更・削除を同期する様子。rsyncでいうところの-u --deleteな感じかな
-
- Sync run scheduleで同期のトリガーを設定
- Frequency:
Run on demand(手動) -
Run on demandで手動。その他は、毎時/毎日/毎週/毎月、あとcron形式で設定すれば、自動にもできる様子
- Frequency:
「Set field mappings」でフィールドマッピングができる。なんだろう、メタデータの一部っぽいんだけど、S3の場合はS3のドキュメントIDをインデックスに紐付けることができるみたい。
今回はデフォルトのまま。
確認画面が出たら「Add data source」
ページ遷移せずに待ってるとデータソースの作成が始まる。以下のように"Status"が"Active"になればOK。

で、"Last sync status"等をみるとまだ同期が行われていないのがわかる。「Sync now」をクリックしてデータの同期を行う。
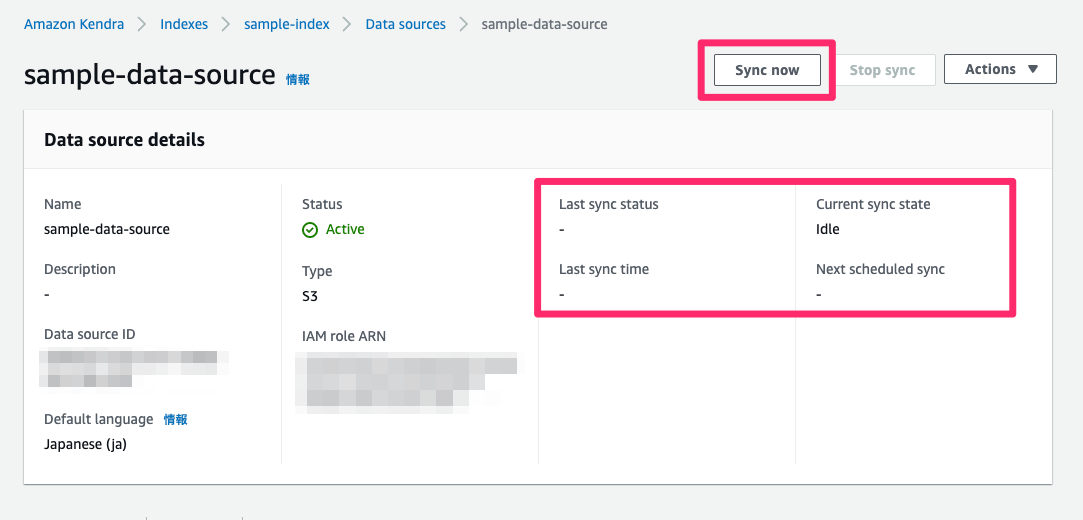
データの同期が開始されているのがわかる。約30分ほどかかるらしい。
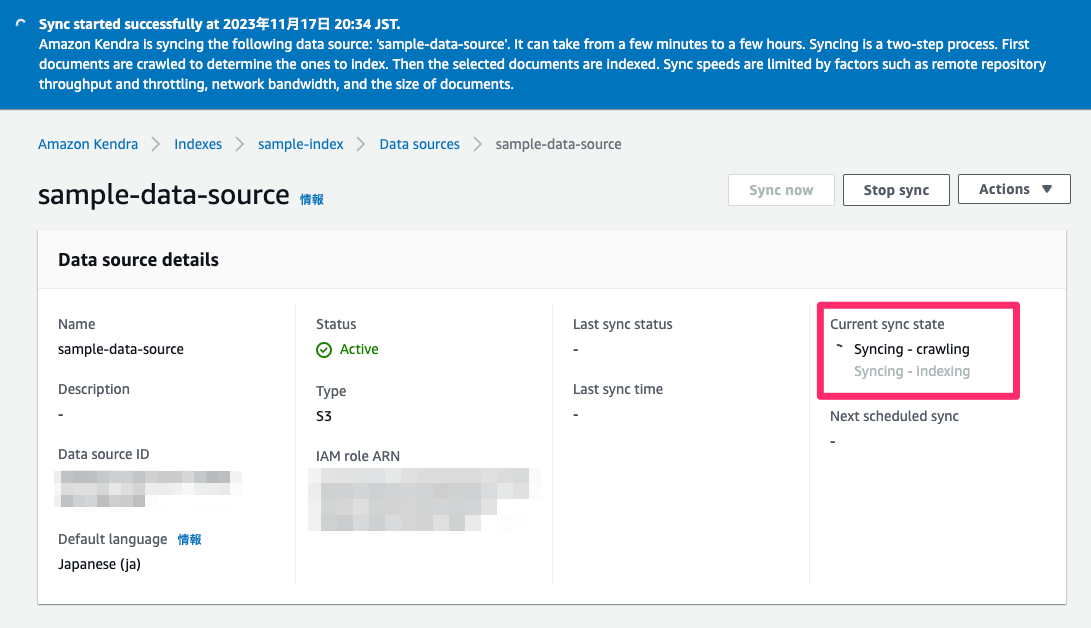
たまたまかもしれないが、3時間経っても終わらないwww
ちなみに、見てた感じ同期はクローリング→インデックス化の流れになっていて、クローリングは5分ぐらいで終わってるようだけど、インデックス化が終わらない。たまたまだったとしても、以下を見ればわかるようにめちゃめちゃ時間かかる のは間違いない。
EKSクラスタ何回も作ったことあるけど、こんな時間かかったことないな。
Syncにめっちゃ時間がかかる
サンプルのPDFを見てみると、AWSの各サービスのディベロッパーガイド(DynamoDB/Lambda/VPC/Kendra/Route53)で合計5000ページ以上あるのでそこそこボリュームはありそう。とはいえ、ちょっとこれはいただけない・・・・(毎晩とか怖くて回せない)
一晩寝かせることにした
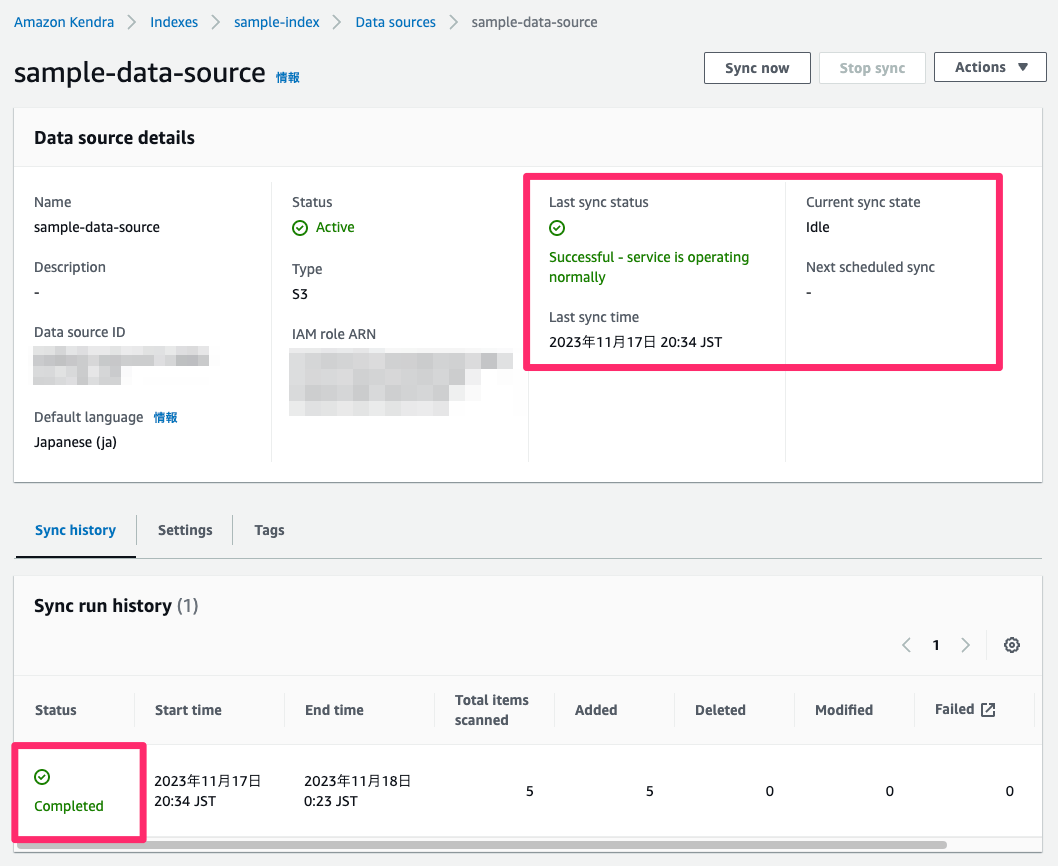
4時間ぐらいでやっと終わった・・・・
以下のようにLast sync statusが更新され、Sync run historyもcompletedになっている。
検索
ここで検索はできる状態になっているはず。手順ではFAQを先に登録するみたいだけど、一旦検索してみる。
左のメニューから「Search Indexed Conent」を開くと以下のような画面になる。
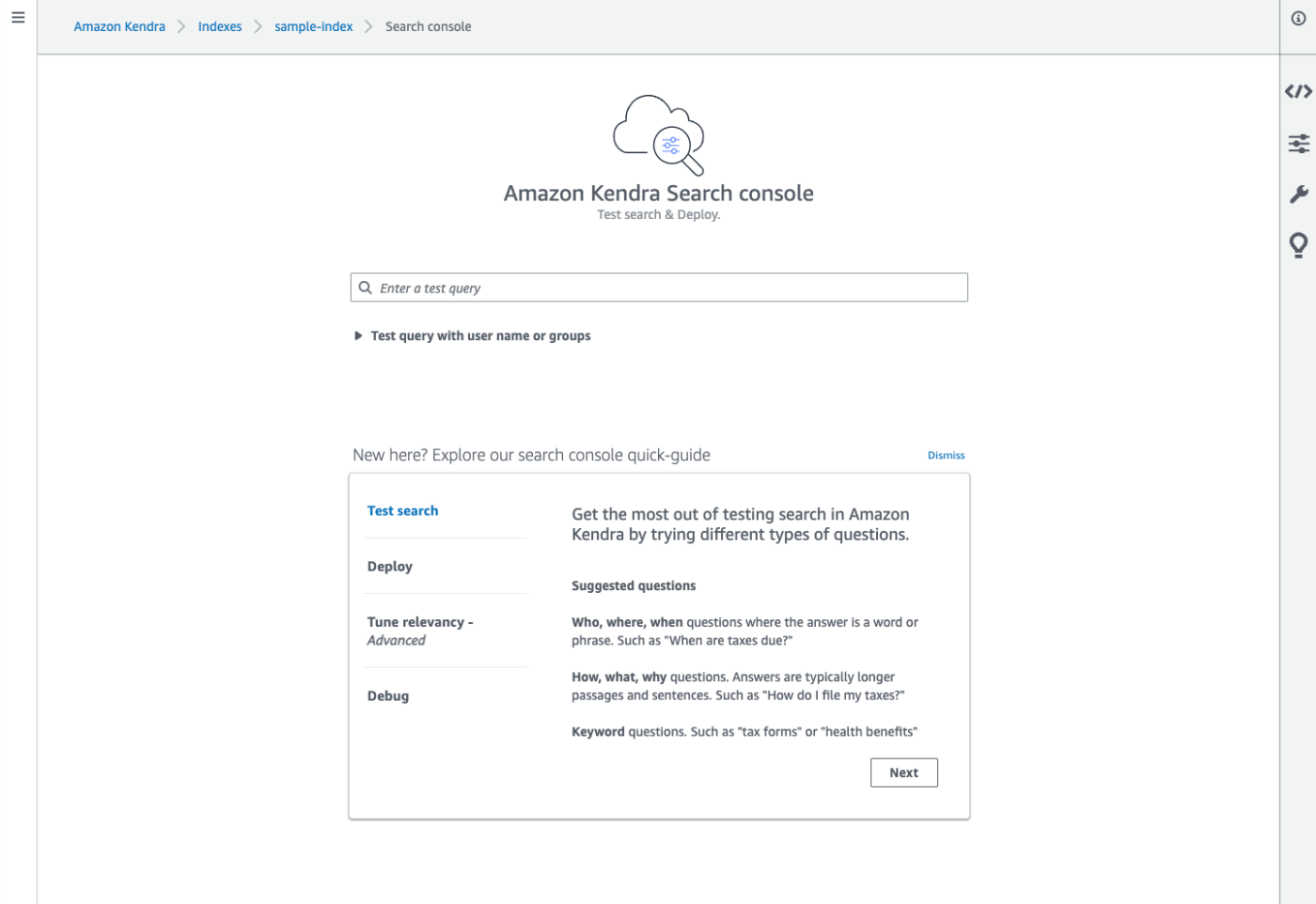
適当に検索する前に、右の設定画面で言語を日本語にする。ログインしなおしたらもとに戻るので毎回びに設定する必要がある模様。まあコンソールということで。
では検索していく。
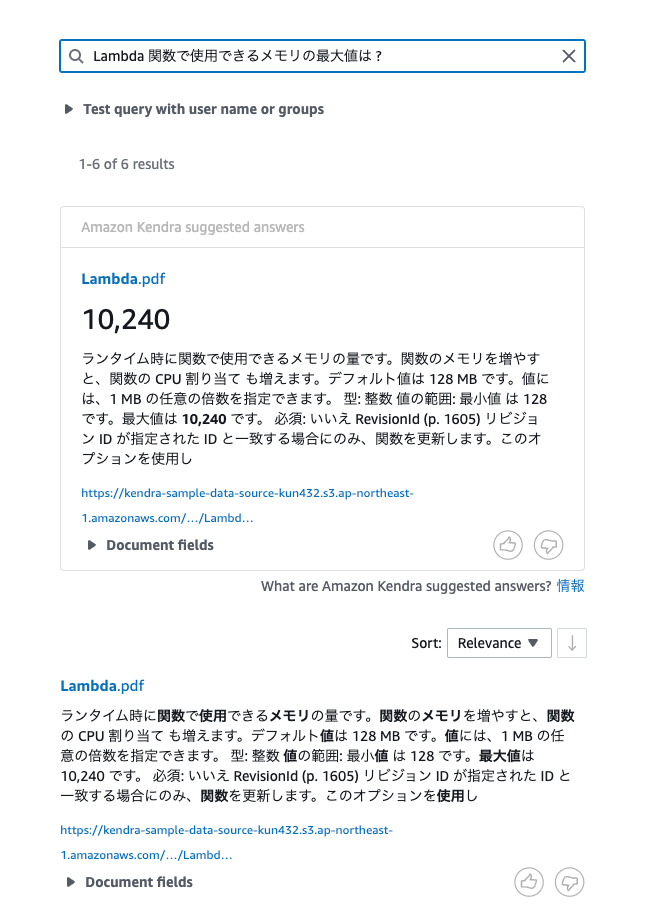
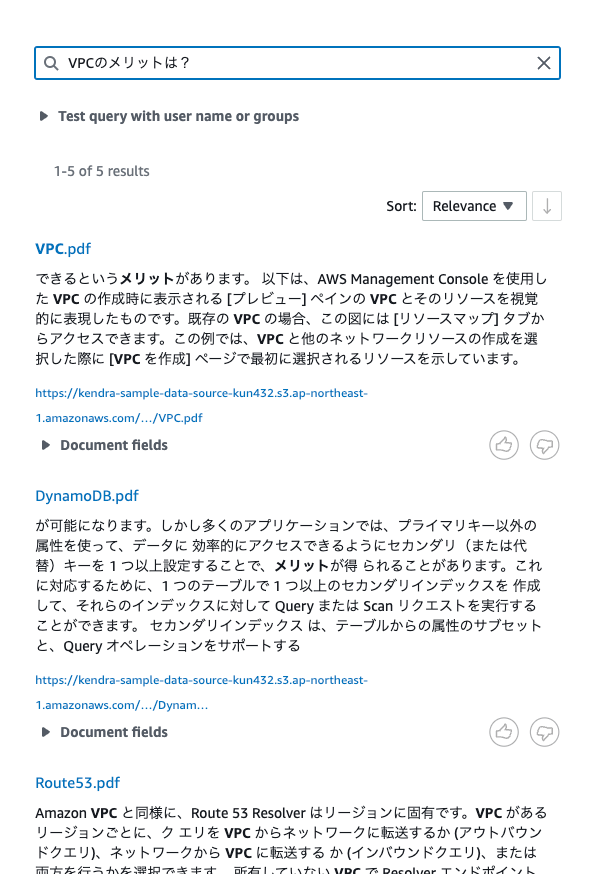
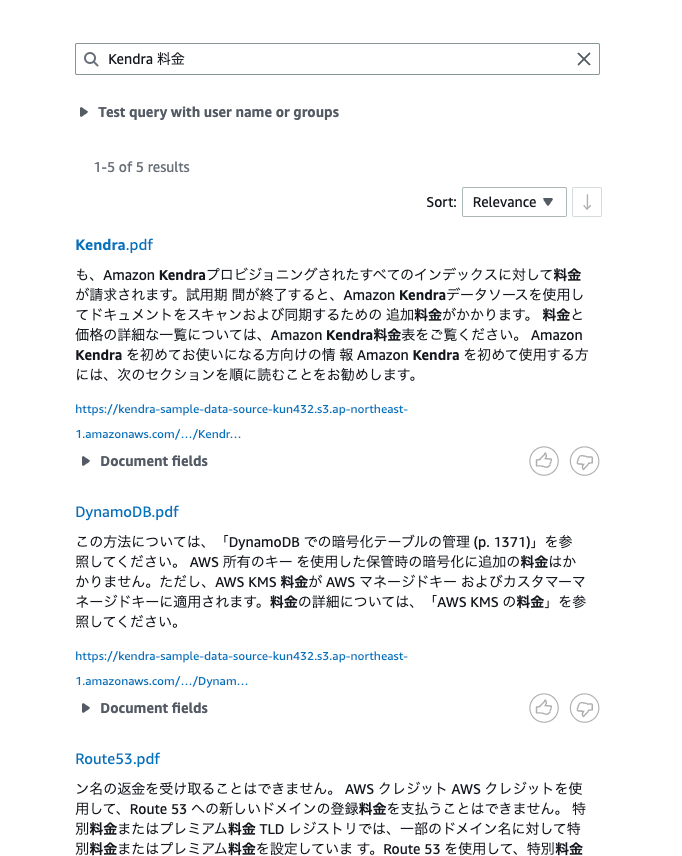
んー、こんなものなのかな?思ったより微妙な感じ。
FAQ
頻出な質問に対して確実に回答させるための設定。作成したインデックスよりも優先されるっぽく見える。
「4-4. よくある質問の追加」に従って実施。
- FAQのフォーマットはCSVで。質問、回答、参照先URL、という感じで作ればいいみたい。
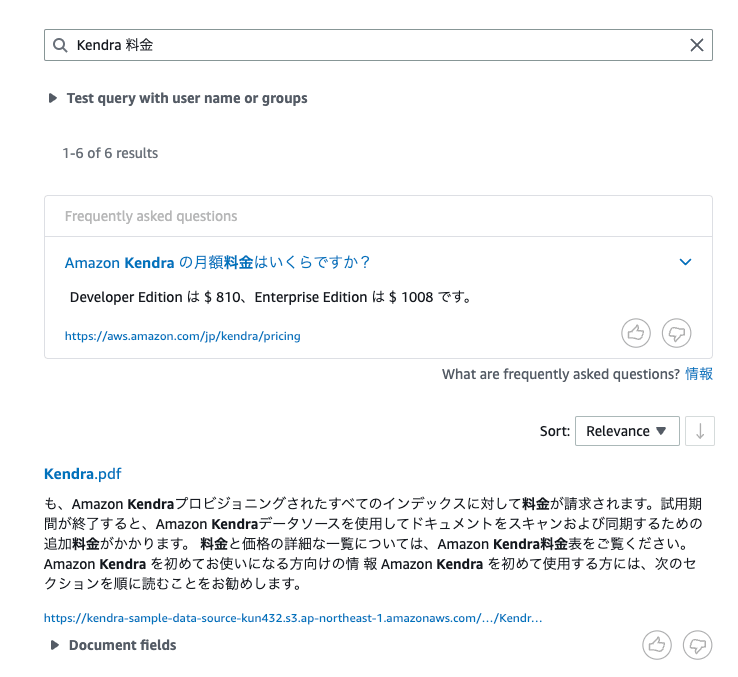
Amazon Kendra の月額料金はいくらですか?,Developer Edition は $ 810、Enterprise Edition は $ 1008 です。,https://aws.amazon.com/jp/kendra/pricing/
- 最初に作ったS3バケットに別フォルダを作成してそこにCSVをアップロードして、アップロードしたファイルのS3 URIを取得
- 例ではこんな感じ:
s3://kendra-sample-data-source-XXXXX/faqs/sample-faq.csv
- 例ではこんな感じ:
- Kendraの左のメニューからFAQsをクリックして「Add FAQ」をクリック
- 以下を設定
- FAQ name:
sample-faq - Default language:
Japanese (ja) - FAQ file format:
.csv file - Basic - S3: 先ほどのファイルのURIを入力
- 例だと
s3://kendra-sample-data-source-XXXXX/faqs/sample-faq.csv
- 例だと
- IAM Role:
-
Create a new role (Recommended)を選択 - Role name:
AmazonKendra-sample-faq-role
-
- FAQ name:
- 「Add」をクリック
IAMロールとFAQが作成される。
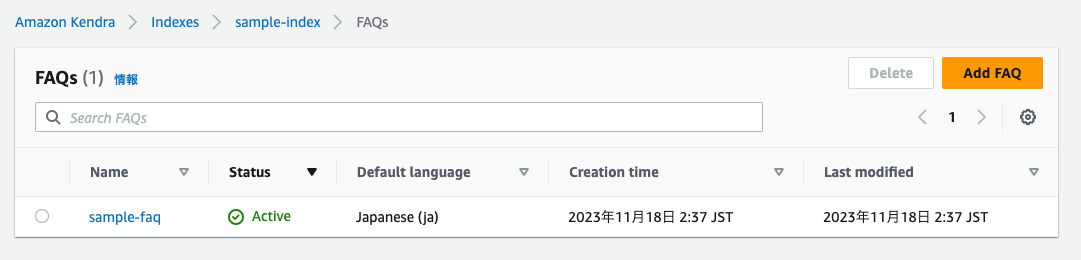
適当に検索してみると以下のように質問候補が表示される。
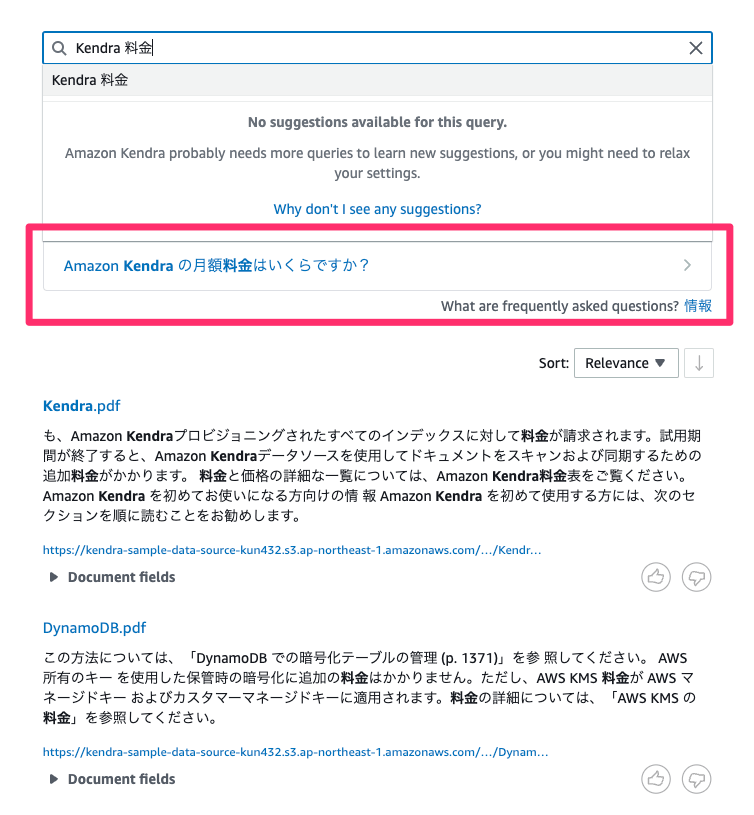
クリックすると先ほど登録したFAQが表示される。
このハンズオンはここで終わりで、後はリソース削除になるのだけど、もう少し色々触ってみたい。
ということで、冒頭のオンデマンドセミナーを見てみる。
こちらは6章立てのハンズオンになっているが、ここまでやってきた内容は1〜2賞とほぼ同じ。ということで、3章以降を進めていけばいいかと思う。
個人的な所感
精度は思ってたよりもそんなによくない感を感じた。ただ、これはハンズオンのデータにもよりそう。ちょっと自前のデータでやり直してみたい。ただ基本的なところで精度あげようと思うと、工夫の余地あまりなさそうな気が・・・(そもそも工夫する必要ないというのがウリなのかもだけど)
まあ確かにコネクター用意すれば検索したいデータの登録・更新自体は簡単かも。そこは大きなメリット。
ただ反映にめちゃめちゃ時間かかるってのとコストそこそこする、ってので、簡単さがそれを凌駕するぐらいの重要度を持つかどうか、というのが正直な印象。
自前データでやろうと思うのだけど、またウン時間かかるかと思うと、心も体も前に進まない・・・
コードからアクセスしてみる。
ちょっと調べてみた感じだと、Kendraの検索APIに外部からアクセスできるようにするのはめんどくさそう。ということで、sagemaker notebookインスタンスを立ち上げてboto3で接続してみる。
- インスタンスタイプ:
ml.t3.medium - IAMロールにAmazonKendraReadOnlyAccessポリシーを追加
pythonのコードはこの辺を参考に。日本語をちゃんと指定しないと回答は返ってこない。
sagemaker notebookJupyterLabを立ち上げて以下を実行
import boto3
import pprint
kendra = boto3.client("kendra")
# KendraのインデックスIDを指定
index_id = "XXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
# Provide the query text
query = "Lambdaの料金を教えて"
response = kendra.query(
QueryText = query,
IndexId = index_id,
AttributeFilter = {
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "ja"
}
}
}
)
print("\nSearch results for query: " + query + "\n")
for query_result in response["ResultItems"]:
print("-------------------")
print("Type: " + str(query_result["Type"]))
if query_result["Type"]=="ANSWER" or query_result["Type"]=="QUESTION_ANSWER":
answer_text = query_result["DocumentExcerpt"]["Text"]
print(answer_text)
if query_result["Type"]=="DOCUMENT":
if "DocumentTitle" in query_result:
document_title = query_result["DocumentTitle"]["Text"]
print("Title: " + document_title)
document_text = query_result["DocumentExcerpt"]["Text"]
print(document_text)
print("------------------\n\n")
結果
Search results for query: Lambdaの料金を教えて
-------------------
Type: QUESTION_ANSWER
Developer Edition は $ 810、Enterprise Edition は $ 1008 です。
------------------
-------------------
Type: DOCUMENT
Title: Lambda.pdf
NAT ゲートウェイにはパブリック IP アドレスが
あるため、VPC のインターネットゲートウェイを介してインターネットに接続できます。アイドル状態の
NAT ゲートウェイ接続は、350 秒後にタイムアウトします。詳細については、「VPC 内にある Lambda
関数に、インターネットへのアクセス許可を付与する方法を教えてください」を参照してください。
VPC チュートリアル
次のチュートリアルでは、VPC 内のリソースに Lambda 関数を接続します。
• チュートリアル: Lambda 関数を使用して Amazon VPC 内の Amazon RDS にアクセスする
------------------
-------------------
Type: DOCUMENT
Title: VPC.pdf
Amazon Athena を使用したフローログのクエリを参照してください。
料金
クエリの実行には、標準の Amazon Athena 料金が発生します 。(パーティションのロード頻度を指定
するが、開始日と終了日を指定しない場合)定期的なスケジュールで新しいパーティションをロードする
Lambda 関数には、標準の AWS Lambda 料金が発生します。
定義済みクエリを使用するには
• コンソールを使用した CloudFormation テンプレートの生成 (p. 246)
• AWS CLI を使用した CloudFormation テンプレートの生成 (p. 247)
------------------
-------------------
Type: DOCUMENT
Title: Kendra.pdf
ます。たとえば、Amazon KendraAnalytics を使用して上位のクエリを調べて、「kendra は結果をセマン
ティックにランク付けする方法を教えてください」など、特定のクエリが見つかったとします。また、
「kendra セマンティック検索」が頻繁に使用される場合、これらのクエリは「search 101」というタイト
ルのドキュメントを特集する場合に便利です。Amazon Kendra
------------------
-------------------
Type: DOCUMENT
Title: SageMaker オートパイロット - アマゾン SageMaker
オートパイロットが提供するデータ探索および候補について独自の変更を行うことで、よりパフォーマンスの高いモデルについてさらに実験を行うこともできます。
アマゾンで SageMaker、使用した分のみをお支払いいただきます。その中の基盤となるコンピューティングリソースとストレージリソースの料金を支払う SageMaker またはその他AWS使用状況に基づくサービス。使用コストについての詳細について SageMaker、参照アマゾン SageMaker価格設定。
トピック
アマゾンを作成 SageMaker 表形式データの自動操縦実験
------------------
-------------------
Type: DOCUMENT
Title: DynamoDB.pdf
ページ分割
• DynamoDB にページネーションを実装するにはどうすればよいですか?
トランザクション
• DynamoDB で TransactWriteItems API コールが失敗するのはなぜですか?
[Troubleshooting] (トラブルシューティング)
• DynamoDB 自動スケーリングの問題を解決する方法を教えてください。
• DynamoDB の HTTP 4XX エラーをトラブルシューティングする方法を教えてください。
DynamoDB に関するその他の記事や動画については、ナレッジセンターの記事を参照してください。
ブログ投稿、リポジトリ、ガイド
------------------
-------------------
Type: DOCUMENT
Title: Amazon S3 とは - Amazon Simple Storage Service
Amazon S3 では、実際に使用した分だけが請求されます。隠れた料金や超過料金はありません。このモデルでは、AWS インフラストラクチャのコスト面のメリットを得ながら、ビジネスの成長に応じた可変コストのサービスを利用することができます。詳細については、Amazon S3 の料金 を参照してください。
AWS にサインアップすると、Amazon S3 を含む AWS のすべてのサービスに対して AWS アカウント が自動的にサインアップされます。ただし、料金が発生するのは、実際に使用したサービスの分のみです。
------------------
-------------------
Type: DOCUMENT
Title: Amazon SageMaker とは - アマゾン SageMaker
アマゾンSageMaker特徴
SageMakerアマゾン価格
SageMakerアマゾンを初めてご利用になる方ですか?
SageMakerアマゾン価格
AWS他の商品と同様、SageMaker Amazonを利用するための契約や最低契約はありません。トレーニングとホスティングは、分ごとの使用量で課金されます。最低料金や前払いの義務はありません。SageMaker の使用料金に関しては、「SageMaker の料金」を参照してください。
------------------
RAGで使うならこれをコンテキストに含めれば良さそう。
クエリを自然言語でそのまま渡せるのはよいポイントかな。