LLMマルチエージェント向けフレームワーク「LANGROID」を試す
ここのところエージェント触り始めて少し気になったので。
Langroidは、元CMUとUW-Madisonの研究者による、LLMを利用したアプリケーションを簡単に構築するための、直感的で軽量、拡張可能で原則的なPythonフレームワークである。エージェントをセットアップし、オプションのコンポーネント(LLM、ベクターストア、ツール/関数)を装備し、タスクを割り当て、メッセージを交換することで共同で問題を解決する。このマルチエージェントパラダイムは、Actorフレームワークにインスパイアされている(しかし、これについて何も知る必要はない!)。Langroidは、LLMアプリ開発の新しい試みであり、開発者の経験を簡素化することにかなりの配慮がなされている;Langchainは使っていない。
Getting Startedにしたがってやってみる。インストールのところを見ると、オプションでQdrant/Redisなりとの連携も書かれているし、レポジトリのサンプルを使うように書かれているけど、一旦そのへんは置いといてColaboratoryで。
インストール
!pip install langroid
!pip freeze | grep langroid
langroid==0.1.252
OpenAIのAPIキーをセット
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
LLM Interaction
使用するモデルの設定と、それにアクセスするためのインスタンスを作成。gpt-4oにしてみた。
import langroid as lr
config = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
)
llm = lr.language_models.OpenAIGPT(config)
こういうwaningが出るけどRedis使ってないので無視。
WARNING:langroid.cachedb.redis_cachedb:REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
2024-05-29 14:24:18 - WARNING - REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
使用するモデルの指定はこのあたり。基本的にはOpenAIを使うっぽい。ollamaとかも使えるようではあるけど、自分はあまりollama使ってないので詳細はわからない。
モデルに送るメッセージはLLMMessageクラスを使う。
from langroid.language_models import Role, LLMMessage
message = LLMMessage(
content="日本の総理大臣は?",
role=Role.USER
)
複数のメッセージを入れる場合。
from langroid.language_models import Role, LLMMessage
messages = [
LLMMessage(content="あなたは親切な日本語のアシスタントです。", role=Role.SYSTEM),
LLMMessage(content="日本の総理大臣は?", role=Role.USER),
]
ではモデルにメッセージを送る。
llm.chat(messages, max_tokens=500)

私の知識は2023年10月までの情報に基づいています。その時点での日本の総理大臣は岸田文雄(きしだ ふみお)です。しかし、最新の情報についてはニュースや公式な発表を確認してください。
LLMResponse(message='私の知識は2023年10月までの情報に基づいています。その時点での日本の総理大臣は岸田文雄(きしだ ふみお)です。しかし、最新の情報についてはニュースや公式な発表を確認してください。', tool_id='', function_call=None, usage=None, cached=False)
同じ内容が2行でているけど、最初の行はどうやらverbose outputっぽくて、ここはストリーミングで出力されていた。
で、レスポンスはLLMResponseオブジェクトで返ってくる。to_LLMMessageメソッドを使えばLLMMessageに変換できるので、これでメッセージ履歴に追加していける。
from pprint import pprint
response = llm.chat(messages, max_tokens=500)
messages.append(response.to_LLMMessage())
pprint(messages)
[LLMMessage(role=<Role.SYSTEM: 'system'>, name=None, tool_id='', content='あなたは親切な日本語のアシスタントです。', function_call=None, timestamp=datetime.datetime(2024, 5, 29, 15, 3, 57, 668491)),
LLMMessage(role=<Role.USER: 'user'>, name=None, tool_id='', content='日本の総理大臣は?', function_call=None, timestamp=datetime.datetime(2024, 5, 29, 15, 3, 57, 668518)),
LLMMessage(role=<Role.ASSISTANT: 'assistant'>, name=None, tool_id='', content='私の知識が2023年10月までのものであるため、その時点での日本の総理大臣は岸田文雄(きしだ ふみお)です。ただし、最新の情報を確認するためには、ニュースや公式な政府のウェブサイトを参照してください。', function_call=None, timestamp=datetime.datetime(2024, 5, 29, 15, 7, 26, 638033))
まとめるとこんな感じ。
from rich import print
from rich.prompt import Prompt
import langroid as lr
from langroid.language_models import Role, LLMMessage
# 出力を抑制
from langroid.utils.configuration import settings
settings.stream = False
messages = [
LLMMessage(role=Role.SYSTEM, content="あなたは親切な日本語のアシスタントです。"),
]
while True:
message = Prompt.ask("[blue]Human")
if message in ["x", "q"]:
print("[magenta]さようなら!")
break
messages.append(LLMMessage(role=Role.USER, content=message))
response = llm.chat(messages=messages)
messages.append(response.to_LLMMessage())
print("[green]Assitant: " + response.message)

Human:
日本の総理大臣は?
Assitant: 2023年10月時点での日本の総理大臣は岸田文雄(きしだ
ふみお)です。彼は2021年10月4日に第100代内閣総理大臣に就任しました。
Human:
そうなんだ
Assitant:
はい、そうです。岸田文雄総理大臣は、外交や経済政策などさまざまな課題に取り組んでいます。もし彼についてもっと知りた
いことがあれば、どうぞお知らせください。
Human:
どこ出身?
Assitant:
岸田文雄総理大臣は広島県広島市の出身です。彼は広島県で生まれ育ち、広島は彼の政治活動の基盤でもあります。広島は第二
次世界大戦中に原子爆弾が投下された都市としても知られており、岸田総理はその歴史的背景を踏まえた平和外交にも力を入れ
ています。
Human:
x
さようなら!
シンプルなチャットエージェント
Agents
ChatAgentクラスは、モデル(tools/function calling対応)・会話履歴・ベクトルDB(オプション)をラップしてくれる。
ChatAgentクラスのコアとなる機能は「メッセージの交換」であり、これをrespondersと呼んでいる。respondersは、メッセージのテキストとメタデータを含むChatDocumentオブジェクトを入力・出力の両方で扱う。
ChatAgentクラスには、レスポンスを扱うエンティティ(LLM / USER / AGENT)に対応した3つのresponderメソッドがある。
-
llm_response- 入力されたメッセージに対するLLMの応答を返す。
- 入力されたメッセージと返されたレスポンスは会話履歴に追加される。
-
agent_response- カスタムエージェントレスポンスを実装するためのメソッド。
- 通常、tool/function callingを含むメッセージで使用される。
- もう1つ、メッセージの検証という用途にも使用される。
-
user_response- ユーザーからの入力をうける。
- 人間が介入したり、終了したりする場合に使う。
エージェントの作成。ChatAgentConfigでモデルなどを設定して、ChatAgentでインスタンスを作成する。
import langroid as lr
config = lr.ChatAgentConfig(
name="MyAgent", # スペースを含めてはいけない
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o
)
)
agent = lr.ChatAgent(config)
responderメソッドの使い方。
response = agent.llm_response(" 2 たす 4は?")
if response is not None:
print(response.content)
response = agent.user_response("それに3を足して")
2たす4は6です。
Stats: N_MSG=4, TOKENS: in=51, out=8, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0006, tot=$0.0006 (gpt-4o)
2たす4は6です。
Human (respond or q, x to exit current level, or hit enter to continue)
:
これちょっとよくわからないのはuser_responsを使うと入力待ちになる。「それに3を足して」という引数を渡していることにどういう意味があるのかわからない。とりあえず手動で入力する。
2たす4は6です。
Stats: N_MSG=4, TOKENS: in=32, out=8, max=1024, ctx=128000, COST: now=$0.0003, cumul=$0.0005, tot=$0.0018 (gpt-4o)
2たす4は6です。
Human (respond or q, x to exit current level, or hit enter to continue)
:
それに3を足して
これだけだと何も起こらないが、一旦このまま進める。
で、ChatAgentはこのやり取りを自動的に会話履歴として管理しているらしい。前回のように自分で会話履歴を組み立てる必要がない。どこで管理しているのかな?というので調べてみると以下で確認できた。
agent.message_history
[LLMMessage(role=<Role.SYSTEM: 'system'>, name=None, tool_id='', content='You are a helpful assistant.', function_call=None, timestamp=datetime.datetime(2024, 5, 30, 18, 23, 56, 834731)),
LLMMessage(role=<Role.USER: 'user'>, name=None, tool_id='', content=' 2 たす 4は?', function_call=None, timestamp=datetime.datetime(2024, 5, 30, 18, 23, 56, 834785)),
LLMMessage(role=<Role.ASSISTANT: 'assistant'>, name='', tool_id='', content='2たす4は6です。', function_call=None, timestamp=datetime.datetime(2024, 5, 30, 18, 23, 57, 622571))]
んー、user_responseのものは含まれていない。というかllm_responseでユーザの入力・LLMからの応答として会話履歴に含まれるようにみえる。
user_responseで入力した場合にresponseがどうなっているか?を見てみる。
response
ChatDocument(content='それに3を足して', metadata=ChatDocMetaData(source='User', is_chunk=False, id='', window_ids=[], parent=None, sender=<Entity.USER: 'User'>, tool_ids=[], parent_responder=None, block=None, sender_name='', recipient='', usage=None, cached=False, displayed=False, has_citation=False, status=None), function_call=None, tool_messages=[], attachment=None)
なるほど、ChatDocumentオブジェクトに変換されている。ということは、これをそのままllm_responseに投げればいいのではないか?
from langroid.utils.constants import USER_QUIT_STRINGS
agent = lr.ChatAgent(config)
while True:
user_response = agent.user_response()
if user_response is None or user_response.content in USER_QUIT_STRINGS:
break
llm_response = agent.llm_response(user_response)
if llm_response is None:
break
print(llm_response.content)
WARNING:langroid.cachedb.redis_cachedb:REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
2024-05-30 19:02:18 - WARNING - REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
Human (respond or q, x to exit current level, or hit enter to continue)
:
2 たす 4は?
2たす4は6です。
Stats: N_MSG=2, TOKENS: in=14, out=8, max=1024, ctx=128000, COST: now=$0.0002, cumul=$0.0002, tot=$0.0092 (gpt-4o)
2たす4は6です。
Human (respond or q, x to exit current level, or hit enter to continue)
:
それに3を足して。
6に3を足すと9になります。
Stats: N_MSG=4, TOKENS: in=29, out=10, max=1024, ctx=128000, COST: now=$0.0003, cumul=$0.0005, tot=$0.0094 (gpt-4o)
6に3を足すと9になります。
Human (respond or q, x to exit current level, or hit enter to continue)
:
x
推測通り。user_responseの引数は相変わらずよくわからないけども、まあ一旦置いておく。
ChatAgentを使えば、会話履歴を自動で管理してくれるが、個々のrespondersの処理は書く必要があった。Taskを使うとこれも書かなくてよくなるので、次項で見ていく。
Task
TaskクラスはChatAgentを更に抽象化して、エージェントのresponderメソッドの繰り返しや複数のタスク間の委譲・ハンドオフなどのオーケストレーションを行う。
Taskは以下のようにして作成する。
- ChatAgentインスタンスやシステムメッセージで初期化
-
Task.run()がエントリーポイントとして実行される。
Task.run()の内部の動きについて色々書かれているけども、一旦動かしてみる。
import langroid as lr
config = lr.ChatAgentConfig(
name="MyAgent",
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
)
)
agent = lr.ChatAgent(config)
task = lr.Task(agent, name="Bot", system_message="あなたは親切な日本語のアシスタントです。")
task.run()
WARNING:langroid.cachedb.redis_cachedb:REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
2024-05-30 19:18:10 - WARNING - REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
(Bot) User
>>> Starting Agent Bot (1) gpt-4o
(Bot) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Bot) Agent
どうも、こんにちは!今日はどんなお手伝いが必要ですか?
Stats: N_MSG=1, TOKENS: in=14, out=17, max=1024, ctx=128000, COST: now=$0.0003, cumul=$0.0003, tot=$0.0098 (gpt-4o)
*(Bot) LLM Entity.LLM( ) (=> ) (X ) ( ) どうも、こんにちは!今日はどんなお手伝いが必要ですか?
Human (respond or q, x to exit current level, or hit enter to continue)
:
2 たす 4 は?
*(Bot) User Entity.USER( ) (=> ) (X ) ( ) 2 たす 4 は?
(Bot) Agent
2 たす 4 は 6 です。何か他にお手伝いできることはありますか?
Stats: N_MSG=3, TOKENS: in=39, out=27, max=1024, ctx=128000, COST: now=$0.0006, cumul=$0.0009, tot=$0.0104 (gpt-4o)
*(Bot) LLM Entity.LLM( ) (=> ) (X ) ( ) 2 たす 4 は 6 です。何か他にお手伝いできることはありますか?
Human (respond or q, x to exit current level, or hit enter to continue)
:
それに3を足したら?
*(Bot) User Entity.USER( ) (=> ) (X ) ( ) それに3を足したら?
(Bot) Agent
6 に 3 を足すと 9 になります。他に質問やお手伝いできることがあれば教えてくださいね。
Stats: N_MSG=5, TOKENS: in=74, out=31, max=1024, ctx=128000, COST: now=$0.0008, cumul=$0.0018, tot=$0.0112 (gpt-4o)
*(Bot) LLM Entity.LLM( ) (=> ) (X ) ( ) 6 に 3 を足すと 9 になります。他に質問やお手伝いできることがあれば教えてくださいね。
Human (respond or q, x to exit current level, or hit enter to continue)
:
q
*(Bot) User Entity.USER( ) (=> ) (X ) ( ) q
Bye, hope this was useful!
<<< Finished Agent Bot (6)
ChatDocument(content='q', metadata=ChatDocMetaData(source='User', is_chunk=False, id='', window_ids=[], parent=None, sender=<Entity.USER: 'User'>, tool_ids=[], parent_responder=None, block=None, sender_name='Bot', recipient='', usage=None, cached=False, displayed=False, has_citation=False, status=<StatusCode.USER_QUIT: 'USER_QUIT'>), function_call=None, tool_messages=[], attachment=None)
なるほど、確かにかなり少ない量でチャットが行われているのがわかる。
Task.run()の内部での動きをまとめる。
-
Task.init()はpending_messageを初期化する。-
pending_messageはレスポンスを返す必要がある最新のメッセージを表す。
-
-
Task.step()がループで呼び出される。- Task.step()はアクションが発生する箇所で、「会話」における「ターン」を表す。
- 単一の
ChatAgentの場合、会話は上記の3つのrespondersのみで行われるが、タスクがサブタスクを保つ場合、他のタスクも絡んでくる。 -
Task.step()はループの中で、ChatAgentのrespondersを実行し、pending_message`に対して正しい回答(たとえばNone以外)を得るまで繰り返す。 -
Task.step()が正しい回答を得たら、その内容でpending_messageを更新して、さらに次のTask.step()を実行する。 -
Task.step()はメッセージが正しく処理されることを保証するメカニズムが組み込まれており、以下のような処理を行う。- 人間が介入しない場合に無限に繰り返されるのを防ぐために、USER以外の応答のあとにUSERが応答する機会を作る
- 応答したばかりのエンティティが応答しないようにする
-
Task.done()がTrueになれば、ループから抜けて、Task.result()でタスクの最終結果を返す。
このあたりはもう少し使い込んでいけばわかるのだろうと思う。
タスク委譲によるマルチエージェントの連携
ここは多分読み物で、この次のTwo/Three Agent Chatへの前知識になるように思う。とりあえずよくわからなければ次に進んで実際の動きを確認すればよいという感じで読む。
なぜマルチエージェントが必要なのか?
例として、以下のようなLLMベースのアプリケーションが紹介されている。
- 法的な契約書を読む
- 構造化された情報を抽出する
- いくつかの分類法と照らし合わせてクロスチェック
- 人間による入力を得る
- 明確な要約を作成する
エージェントを使わなくても、LLMとベクトルDBを使って、モノリシックなアプリケーションとして作成することはできるけど、まあ大変そうというのはわかる。
LangroidのChatAgent/Task抽象化を使うと、自然で直感的な複数のタスクに分割でき、以下のようなメリットが得られる。
- 再利用性: 同じエージェント/タスクを他のコンテキストで再利用できる。
- スケーラビリティ: エージェント/タスクを追加することでソリューションをスケールアップできる。
- 柔軟性: エージェント/タスクを追加/削除することで簡単にソリューションを変更できる。
- 保守性: 個々のエージェント/タスクを更新することでソリューションを保守できる。
- テスト可能性: 個々のエージェント/タスクを独立してテスト/デバッグできる。
- 構成可能性: エージェント/タスクを組み合わせて新しいエージェント/タスクを作成できる。
- 拡張性: 新しいエージェント/タスクを追加することでソリューションを拡張できる。
- 相互運用性: 他のシステムと統合するために新しいエージェント/タスクを追加できる。
- セキュリティ/プライバシー: センシティブなエージェント/タスクを隔離することでソリューションをセキュリティで保護できる。
- パフォーマンス: パフォーマンスクリティカルなエージェント/タスクを隔離することでパフォーマンスを向上させることができる。
サブタスクによるタスク連携
Langroidは階層構造によるタスクの委譲をサポートしている。書かれているサンプルコードは以下のような形。
from langroid import ChatAgent, ChatAgentConfig, Task
main_agent = ChatAgent(ChatAgentConfig(...))
main_task = Task(main_agent, ...)
helper_agent1 = ChatAgent(ChatAgentConfig(...))
helper_agent2 = ChatAgent(ChatAgentConfig(...))
helper_task1 = Task(agent1, ...)
helper_task2 = Task(agent2, ...)
main_task.add_sub_task([helper_task1, helper_task2])
通常のタスク=サブタスクがないタスクの場合、TaskのChatAgent`のネイティブなrespondersは以下の順で正しい応答を得ようとする。
[self.agent_response, self.llm_response, self.user_response]
サブタスクがある場合、上のmain_task.step()だと以下のように後ろに追加される。
[self.agent_response, self.llm_response, self.user_response, helper_task1.run(), helper_task2.run()]
ネイティブなrespondersが現在のpending_messageに応答できない場合は、サブタスクにフェールオーバーするというのが一つの考え方らしい。あと、サブタスクに更にサブタスクがあれば再帰的に実行されるらしい。
Or Elseロジック vs And Thenロジック
上で書いた以下の箇所。
通常のタスク=サブタスクがないタスクの場合、
TaskのChatAgent`のネイティブなrespondersは以下の順で正しい応答を得ようとする。[self.agent_response, self.llm_response, self.user_response]サブタスクがある場合、上の
main_task.step()だと以下のように後ろに追加される。[self.agent_response, self.llm_response, self.user_response, helper_task1.run(), helper_task2.run()]ネイティブなrespondersが現在の
pending_messageに応答できない場合は、サブタスクにフェールオーバーするというのが一つの考え方らしい。
この部分の動きは OR Elseになるらしい。例えば、
[self.agent_response, self.llm_response, self.user_response, helper_task1.run(), helper_task2.run()]
という風に応答を探す場合、
- self.agent_responseから順番に応答を探す。
- なければ次に進む
- 例えば、helper_task1で応答があれば、次のターンでは、また最初、つまりself.agent_responseから応答を探す
- 例外としては、人間以外の応答があれば、次は人間の応答になる
ということになるらしい。
これをAnd Then的にしたい場合は以下のように書くらしい。
helper_task1.add_sub_task(helper_task2)
main_task.add_sub_task(helper_task1)
これにより、main_task→helper_task1→helper_task2と処理されるらしい。
とりあえずざっと見てみたけど、雰囲気だけしかわからないので、次項で実際のコードを書いてみることとする。
2つのエージェントの連携
ということで、複数エージェントの連携を実際に書く。今回は2つのエージェントを用意する。
- Studentエージェント
- 数字のリストを受け取って全ての合計を返すエージェント
- ただし足し算の仕方を知らない
- Adderエージェント
- 2つの数字を受け取って足し算を行う
- 足し算の仕方を知っている
まず、最初にStudentエージェントとタスクだけを作成してやってみる。
import langroid as lr
config = lr.ChatAgentConfig(
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
),
vecdb = None,
)
student_agent = lr.ChatAgent(config)
student_task = lr.Task(
student_agent,
name = "Student",
system_message="""
あなたのゴールは、私(ユーザ)から数字のリストを受け取って、その合計を計算することです。
しかしあなたは数字の足し方を知りません。
私は数字のペアの足し方だけを知っていますので、2つの数字を足すお手伝いができます。
私に足すべき数字のペアを1組づつ送ってくれれば、私はあなたにその合計を返します。
私に聞くときは、単純に数学の表記法で和を聞いて下さい、例えば、"1 + 2"などと聞いて、それ以外には何も言わないでください。
リストにある全ての数字の合計がわかったら、"DONE"と言って、最終的な合計を教えて下さい。
数字のリストをまず聞いてから始めてください。
""",
llm_delegate=True,
single_round=False,
)
タスク実行
student_task.run()
最初にリストを聞いてくるので入力。

1 3 5 6
するとこんな感じで数学の表記法を返してくるので、回答を入力してやる。

4
この回答とリストの次の数字の合計を算出するように求めてくる。
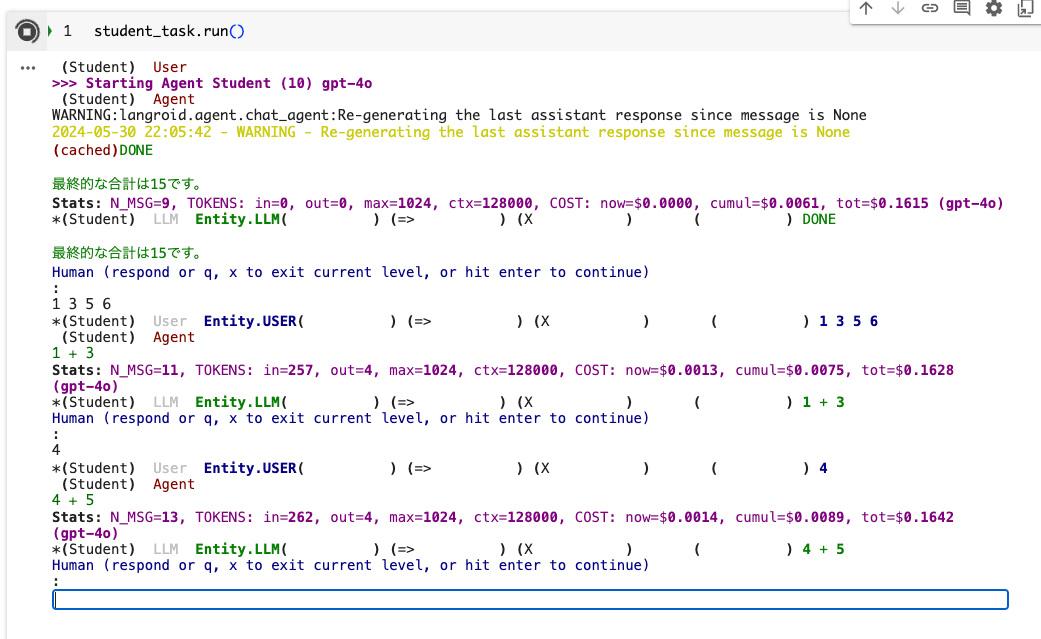
これを繰り返していくと最終的な回答が得られる。

今回は人間とのインタラクションになっているので、ここにAdderエージェントとタスクを追加して自動的に回答を算出させる。
import langroid as lr
config = lr.ChatAgentConfig(
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
),
vecdb = None,
)
student_agent = lr.ChatAgent(config)
student_task = lr.Task(
student_agent,
name = "Student",
system_message="""
あなたのゴールは、私(ユーザ)から数字のリストを受け取って、その合計を計算することです。
しかしあなたは数字の足し方を知りません。
私は数字のペアの足し方だけを知っていますので、2つの数字を足すお手伝いができます。
私に足すべき数字のペアを1組づつ送ってくれれば、私はあなたにその合計を返します。
私に聞くときは、単純に数学の表記法で和を聞いて下さい、例えば、"1 + 2"などと聞いて、それ以外には何も言わないでください。
リストにある全ての数字の合計がわかったら、"DONE"と言って、最終的な合計を教えて下さい。
数字のリストをまず聞いてから始めてください。
""",
llm_delegate=True,
single_round=False,
)
adder_agent = lr.ChatAgent(config)
adder_task = lr.Task(
adder_agent,
name = "Adder",
system_message="""
あなたは足し算のエキスパートです。
足すべき数字が与えられたら、単にその和を返してください。それ以外には他には何も言わないでください。
""",
single_round=True,
)
サブタスクとして追加して実行
student_task.add_sub_task(adder_task)
student_task.run()
こんな感じでまず数字のリストを聞かれるので入力してやる
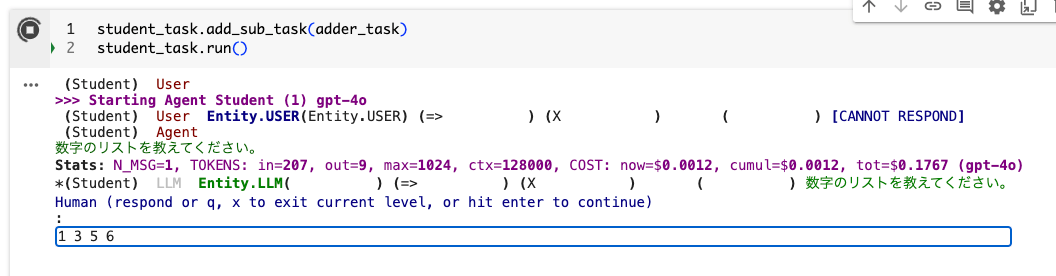
すると、先ほどと変わらない感じで人間の入力を必要とする感じになる。。。。
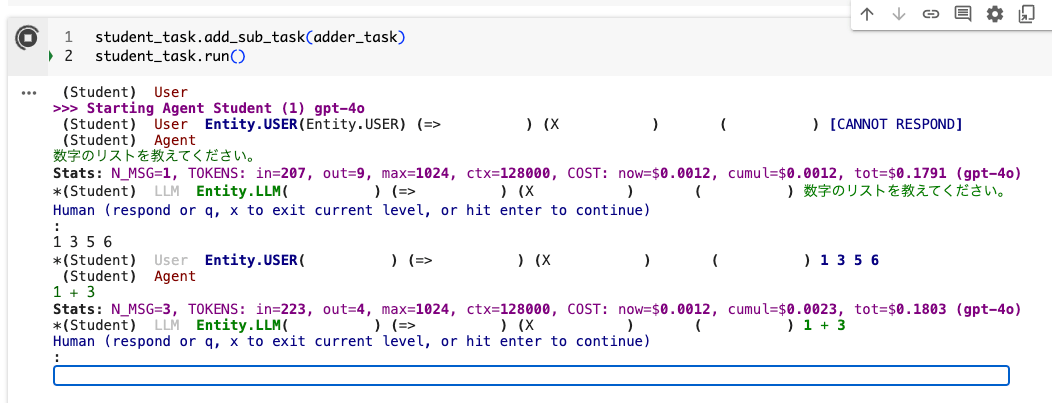
最後まで進めても同じ。Adderエージェントとタスクが呼び出される感じがない。
サンプルのスクリプトを見てみると、どうやらインタラクティブモードというのがデフォルトで有効になっている。
名前 型 説明 デフォルト interactive book trueを指定すると、人間以外が応答するたびに、人間の入力を待つ(人間以外が応答する無限ループを防ぐ)。デフォルトはtrueである。falseの場合、default_human_responseは""に設定される。 True
エージェントだけでやり取りさせる場合には、これをOFFにしてやる必要がある様子。
student_agent = lr.ChatAgent(config)
student_task = lr.Task(
student_agent,
name = "Student",
system_message="""
あなたのゴールは、私(ユーザ)から数字のリストを受け取って、その合計を計算することです。
しかしあなたは数字の足し方を知りません。
私は数字のペアの足し方だけを知っていますので、2つの数字を足すお手伝いができます。
私に足すべき数字のペアを1組づつ送ってくれれば、私はあなたにその合計を返します。
私に聞くときは、単純に数学の表記法で和を聞いて下さい、例えば、"1 + 2"などと聞いて、それ以外には何も言わないでください。
リストにある全ての数字の合計がわかったら、"DONE"と言って、最終的な合計を教えて下さい。
数字のリストをまず聞いてから始めてください。
""",
llm_delegate=True,
single_round=False,
interactive=False, # これ!
)
adder_agent = lr.ChatAgent(config)
adder_task = lr.Task(
adder_agent,
name = "Adder",
system_message="""
あなたは足し算のエキスパートです。
足すべき数字が与えられたら、単にその和を返してください。それ以外には他には何も言わないでください。
""",
single_round=True,
interactive=False, # これ!
)
でインタラクティブモードを無効にすると人間の入力を受け付けなくなるため、最初に与える数字のリストを入力するタイミングもなくなってしまうため、タスク実行時にこれを渡してやる必要がある。
student_task.add_sub_task(adder_task)
student_task.run("1 3 5 6")
すると、2つのエージェントが相互にやり取りしているかのように、完全に自動で処理される。
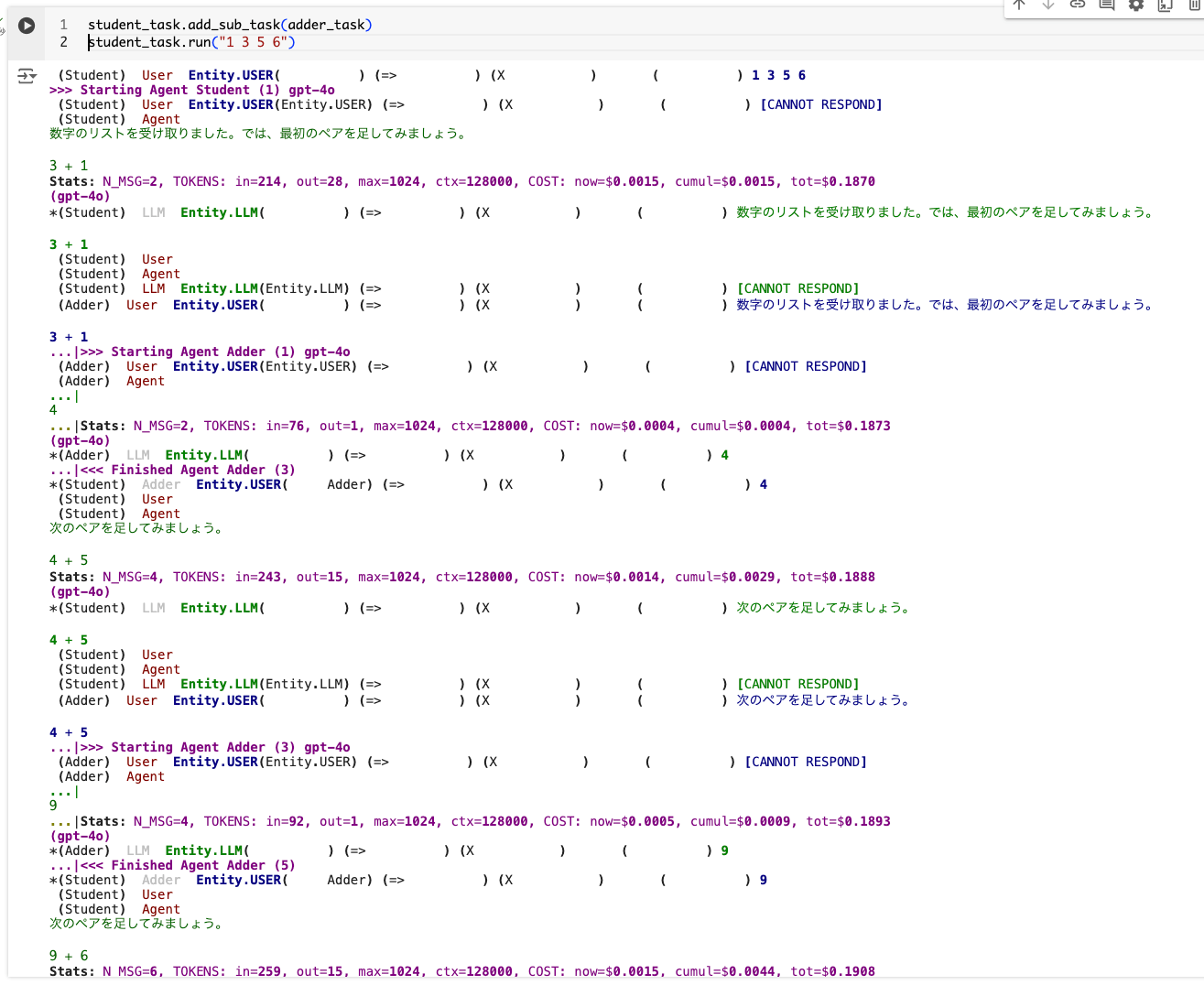

なお、タスクの完了を示す文字列は決まっているようで、完了時に"DONE"という文字列を出力しないとタスクが終了したと判断しないので延々とループするので注意。
複数エージェントのやり取りのログ
複数エージェントでtask.run()を実行すると2つのログが出力される。
logs/<タスク名>.loglogs/<タスク名>.tsv
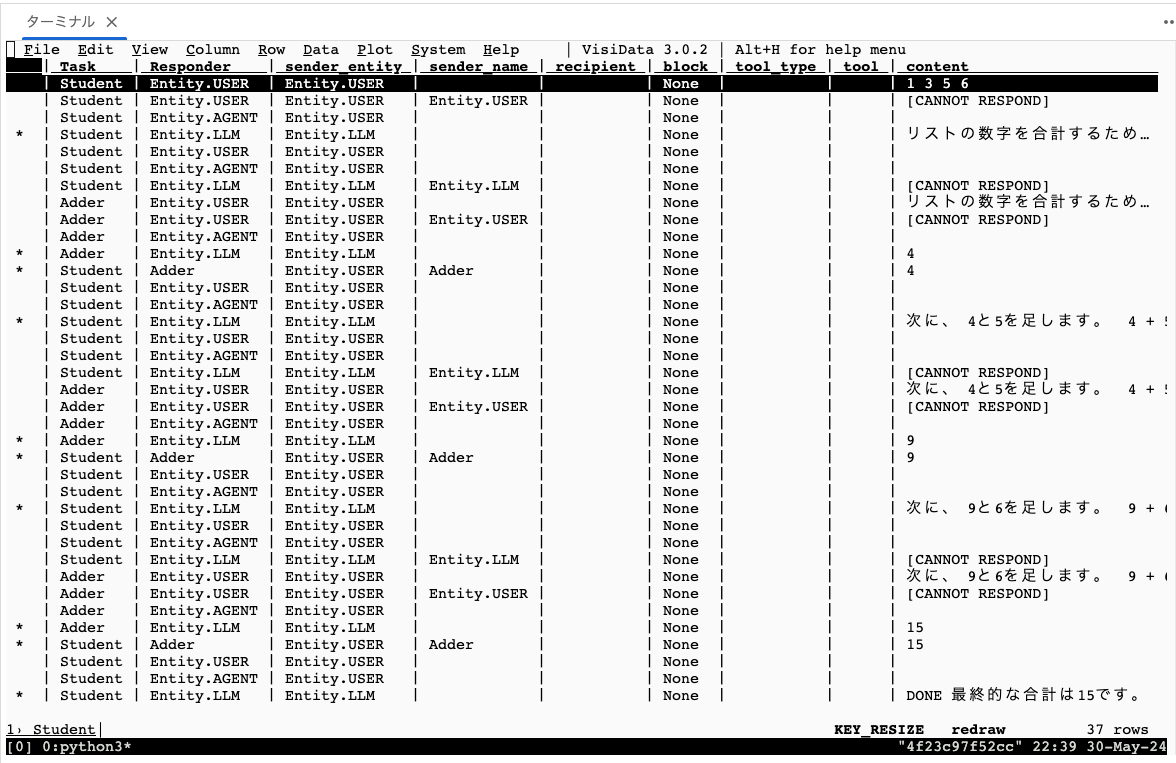
自分が見た限りは*.logには何も出力されておらず、*.tsvの方だけだった。中身はこんな感じ。
Task Responder sender_entity sender_name recipient block tool_type tool content
Student Entity.USER Entity.USER None 1 3 5 6
Student Entity.USER Entity.USER Entity.USER None [CANNOT RESPOND]
Student Entity.AGENT Entity.USER None
* Student Entity.LLM Entity.LLM None リストの数字を合計するために、まずペアを作って足していきます。 1 + 3
Student Entity.USER Entity.USER None
Student Entity.AGENT Entity.USER None
Student Entity.LLM Entity.LLM Entity.LLM None [CANNOT RESPOND]
Adder Entity.USER Entity.USER None リストの数字を合計するために、まずペアを作って足していきます。 1 + 3
Adder Entity.USER Entity.USER Entity.USER None [CANNOT RESPOND]
Adder Entity.AGENT Entity.USER None
* Adder Entity.LLM Entity.LLM None 4
* Student Adder Entity.USER Adder None 4
Student Entity.USER Entity.USER None
Student Entity.AGENT Entity.USER None
* Student Entity.LLM Entity.LLM None 次に、4と5を足します。 4 + 5
Student Entity.USER Entity.USER None
Student Entity.AGENT Entity.USER None
Student Entity.LLM Entity.LLM Entity.LLM None [CANNOT RESPOND]
Adder Entity.USER Entity.USER None 次に、4と5を足します。 4 + 5
Adder Entity.USER Entity.USER Entity.USER None [CANNOT RESPOND]
Adder Entity.AGENT Entity.USER None
* Adder Entity.LLM Entity.LLM None 9
* Student Adder Entity.USER Adder None 9
Student Entity.USER Entity.USER None
Student Entity.AGENT Entity.USER None
* Student Entity.LLM Entity.LLM None 次に、9と6を足します。 9 + 6
Student Entity.USER Entity.USER None
Student Entity.AGENT Entity.USER None
Student Entity.LLM Entity.LLM Entity.LLM None [CANNOT RESPOND]
Adder Entity.USER Entity.USER None 次に、9と6を足します。 9 + 6
Adder Entity.USER Entity.USER Entity.USER None [CANNOT RESPOND]
Adder Entity.AGENT Entity.USER None
* Adder Entity.LLM Entity.LLM None 15
* Student Adder Entity.USER Adder None 15
Student Entity.USER Entity.USER None
Student Entity.AGENT Entity.USER None
* Student Entity.LLM Entity.LLM None DONE 最終的な合計は15です。
ログのフォーマットはドキュメントでは以下とあるが、実際のファイルのヘッダを見ると微妙に違うように見える。
(TaskName) Responder SenderEntity (EntityName) (=> Recipient) TOOL Content
visidataというのを使うと見やすくなるみたい。
$ pip install visidata
$ vd logs/Student.tsv
3つのエージェントの連携
さらに3つのエージェントで連携させてみる。
- Processorエージェント
- 数字のリストを受け取ってここの数値に対して変換を行うエージェント
- ただし変換方法を知らない
- EvenHandlerエージェント
- 与えられた数値
n n / 2 DO-NOT-KNOWを返す
- 与えられた数値
- OddHanlderエージェント
- 与えられた数値
n 3n + 1 DO-NOT-KNOWを返す
- 与えられた数値
import langroid as lr
config = lr.ChatAgentConfig(
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
),
vecdb = None,
)
processor_agent = lr.ChatAgent(config)
processor_task = lr.Task(
student_agent,
name = "Processor",
system_message="""
あなたのゴールは、ユーザから数字のリストを受け取って、それぞれの数字に変換を適用することです。
しかしあなたは変換方法を知らないので、ユーザが助けてくれます。
あなたは単純に「与えられたリストから」それぞれの数字をユーザに送れば、ユーザが結果を返してくれます。
重要: 1度に送る数字は1つだけで、簡潔かつ、それ以外には何も送らないでください。
ゴールを達成したら、"DONE"と言って、結果をリストとして教えて下さい。
数字のリストをまず聞いてから始めてください。
""",
llm_delegate=True,
single_round=False,
interactive=False,
)
NO_ANSWER = lr.utils.constants.NO_ANSWER
even_agent = lr.ChatAgent(config)
even_task = lr.Task(
even_agent,
name = "EvenHandler",
system_message=f"""
あたなには数値が与えられます。
その数値が偶数ならば、2で割ってその結果だけ返して、それ以外には何も返さないでください。
その数値が奇数ならば、{NO_ANSWER} を返してください。
""",
single_round=True, # task done after 1 step() with valid response
interactive=False,
)
odd_agent = lr.ChatAgent(config)
odd_task = lr.Task(
odd_agent,
name = "OddHandler",
system_message=f"""
あたなには数値nが与えられます。
その数値nが奇数ならば、(n*3+1) を返して、それ以外には何も返さないでください。
その数値が偶数ならば、{NO_ANSWER} を返してください。
""",
single_round=True, # task done after 1 step() with valid response
interactive=False,
)
even_taskとodd_taskをprocessorタスクのサブタスクとして追加し、実行する。
processor_task.add_sub_task([even_task, odd_task])
processor_task.run("[1, 3, 6, 9]")
(Processor) User Entity.USER( ) (=> ) (X ) ( ) [1, 3, 6, 9]
>>> Starting Agent Processor (1) gpt-4o
(Processor) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Processor) Agent
(cached)1
Stats: N_MSG=2, TOKENS: in=0, out=0, max=1024, ctx=128000, COST: now=$0.0000, cumul=$0.0352, tot=$0.2520 (gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) 1
(Processor) User
(Processor) Agent
(Processor) LLM Entity.LLM(Entity.LLM) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) User Entity.USER( ) (=> ) (X ) ( ) 1
...|>>> Starting Agent EvenHandler (1) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
DO-NOT-KNOW
...|Stats: N_MSG=2, TOKENS: in=66, out=5, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0004, tot=$0.2524
(gpt-4o)
(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) DO-NOT-KNOW
*(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) DO-NOT-KNOW
...|<<< Finished Agent EvenHandler (3)
(Processor) EvenHandler Entity.USER(EvenHandler) (=> ) (X ) ( ) DO-NOT-KNOW
(OddHandler) User Entity.USER( ) (=> ) (X ) ( ) 1
...|>>> Starting Agent OddHandler (1) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
4
...|Stats: N_MSG=2, TOKENS: in=69, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0004, tot=$0.2528
(gpt-4o)
*(OddHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 4
...|<<< Finished Agent OddHandler (3)
*(Processor) OddHandler Entity.USER(OddHandler) (=> ) (X ) ( ) 4
(Processor) User
(Processor) Agent
(cached)3
Stats: N_MSG=4, TOKENS: in=0, out=0, max=1024, ctx=128000, COST: now=$0.0000, cumul=$0.0352, tot=$0.2528 (gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) 3
(Processor) User
(Processor) Agent
(Processor) LLM Entity.LLM(Entity.LLM) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) User Entity.USER( ) (=> ) (X ) ( ) 3
...|>>> Starting Agent EvenHandler (3) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
DO-NOT-KNOW
...|Stats: N_MSG=4, TOKENS: in=72, out=5, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0008, tot=$0.2532
(gpt-4o)
(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) DO-NOT-KNOW
*(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) DO-NOT-KNOW
...|<<< Finished Agent EvenHandler (5)
(Processor) EvenHandler Entity.USER(EvenHandler) (=> ) (X ) ( ) DO-NOT-KNOW
(OddHandler) User Entity.USER( ) (=> ) (X ) ( ) 3
...|>>> Starting Agent OddHandler (3) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
10
...|Stats: N_MSG=4, TOKENS: in=71, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0007, tot=$0.2536
(gpt-4o)
*(OddHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 10
...|<<< Finished Agent OddHandler (5)
*(Processor) OddHandler Entity.USER(OddHandler) (=> ) (X ) ( ) 10
(Processor) User
(Processor) Agent
(cached)6
Stats: N_MSG=6, TOKENS: in=0, out=0, max=1024, ctx=128000, COST: now=$0.0000, cumul=$0.0352, tot=$0.2536 (gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) 6
(Processor) User
(Processor) Agent
(Processor) LLM Entity.LLM(Entity.LLM) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) User Entity.USER( ) (=> ) (X ) ( ) 6
...|>>> Starting Agent EvenHandler (5) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
3
...|Stats: N_MSG=6, TOKENS: in=78, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0012, tot=$0.2540
(gpt-4o)
*(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 3
...|<<< Finished Agent EvenHandler (7)
*(Processor) EvenHandler Entity.USER(EvenHandler) (=> ) (X ) ( ) 3
(Processor) User
(Processor) Agent
(cached)9
Stats: N_MSG=8, TOKENS: in=0, out=0, max=1024, ctx=128000, COST: now=$0.0000, cumul=$0.0352, tot=$0.2540 (gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) 9
(Processor) User
(Processor) Agent
(Processor) LLM Entity.LLM(Entity.LLM) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) User Entity.USER( ) (=> ) (X ) ( ) 9
...|>>> Starting Agent EvenHandler (7) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
DO-NOT-KNOW
...|Stats: N_MSG=8, TOKENS: in=80, out=5, max=1024, ctx=128000, COST: now=$0.0005, cumul=$0.0017, tot=$0.2545
(gpt-4o)
(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) DO-NOT-KNOW
*(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) DO-NOT-KNOW
...|<<< Finished Agent EvenHandler (9)
(Processor) EvenHandler Entity.USER(EvenHandler) (=> ) (X ) ( ) DO-NOT-KNOW
(OddHandler) User Entity.USER( ) (=> ) (X ) ( ) 9
...|>>> Starting Agent OddHandler (5) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
28
...|Stats: N_MSG=6, TOKENS: in=73, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0011, tot=$0.2549
(gpt-4o)
*(OddHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 28
...|<<< Finished Agent OddHandler (7)
*(Processor) OddHandler Entity.USER(OddHandler) (=> ) (X ) ( ) 28
(Processor) User
(Processor) Agent
(cached)DONE結果のリスト: [4, 10, 3, 28]
Stats: N_MSG=10, TOKENS: in=0, out=0, max=1024, ctx=128000, COST: now=$0.0000, cumul=$0.0352, tot=$0.2549 (gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) DONE結果のリスト: [4, 10, 3, 28]
Bye, hope this was useful!
<<< Finished Agent Processor (11)
ChatDocument(content='結果のリスト: [4, 10, 3, 28]', metadata=ChatDocMetaData(source='User', is_chunk=False, id='', window_ids=[], parent=None, sender=<Entity.USER: 'User'>, tool_ids=[], parent_responder=None, block=None, sender_name='Processor', recipient='', usage=None, cached=False, displayed=False, has_citation=False, status=<StatusCode.DONE: 'DONE'>), function_call=None, tool_messages=[], attachment=None)
1 => 1 * 3 + 1 = 4
3 => 3 * 3 + 1 = 10
6 => 6 / 2 = 3
9 => 9 * 3 + 1 = 28
であっている。
tool/function callに対応したチャットエージェント
エージェントはtool/function callが使える。エージェントでtool/function callを使うと以下のようなユースケースでメリットが得られる。
-
構造化ドキュメントからの情報抽出:
- LLMに契約文書内の主要な用語をJSON構造化フォーマットで表示させることで、その後の処理を容易に行う。
- サンプル
-
特殊な計算
- LLMに単位の変換させたり、(コンテキストに収まらない)大きなファイルをスキャンして特定のパターンを抽出する
-
コードの実行
- サンドボックス環境で実行されるコードを生成させて、実行結果をLLMに返す。
-
APIコール
- APIコール用のパラメータを含むJSONを生成させて、ツールハンドラがそれを使ってAPIコールを行い、結果をLLMに返す。
これらのために、Langroidでは、2つのメカニズムを提供する。
- OpenAIのFunction Calling向けのクリーンで統一されたインタフェース
-
ChatAgentConfigでuse_functions_apiを使う
-
- Langroid独自のネイティブな"tool"メカニズム
-
ChatAgentConfigでuse_toolsを使う - OpenAI以外のLLMで、ネイティブにFunction Callingをサポートしていない場合に有用
-
これらを指定しない場合はLangroidが使用しているLLMに応じて自動的に判定を行う。
そしてこれらはPydanticを使用して実装しているため、
- function callingのために複雑なJSON specを書く必要がない
- LLMが不正なJSONを生成した場合にPydanticのエラーメッセージがLLMに返され、LLMはこれを修正できる
というメリットがある。
例: リストから最小値を見つける
以下のようなサンプルが紹介されている。
- エージェントは、 "秘密"の数字リストを "頭の中 "に持っている。例えば、
[3, 4, 8, 11, 15, 25, 40, 80, 90] - エージェントに与えられたタスクは、この数字リストから最小のものを見つけること。例えば上の例だと
3。 - エージェントにはツールとして
ProbeToolが与えられる。-
ProbeToolのprobeメソッドは以下のような機能を提供する。- エージェントは、
probeメソッドに任意の数字を与える、例えば20。 -
probeメソッドは、与えられた数字と同じ、もしくはそれ以下の数字が、リストの中で何個あるか?を返す。上記の例だと、[3, 4, 8, 11, 15]が該当するので、5となる。
- エージェントは、
- エージェントはこれを繰り返して、数字リストの中の一番小さい数字を回答する。
- 20を与えたら5個
- 10を与えたら3個
- 5を与えたら2個
- 3を与えたら1個
- 2を与えたら0個
- 答えは3
-
ではこのツールを定義していく。ツールの定義は、LangroidのToolMessageクラスを継承してクラスを定義する。今回はProbeToolとする。ToolMessageクラスはPydanticのBaseModelを派生させたものになっている。
そして、このツールクラスの定義に必要なものは以下となる。
- ツールを処理するために必要なエージェントメソッドの名前。今回は
probe。 - ツールのメッセージに指定しないといけないフィールド。今回は
number。 - ツールの「目的」とか「使われ方」などの「説明」。
以下のような感じになる。
import langroid as lr
class ProbeTool(lr.agent.ToolMessage):
request: str = "probe"
purpose: str = """
リストの中で、指定された<数字>に最も近い数字を見つける
"""
number: int
@classmethod
def examples(cls):
# ツールの説明と共に、few shotのサンプルにコンパイルされて送信される
return [
cls(number=10),
(
"20に最も近い数字を見つける",
cls(number=20),
)
]
最初見た時、ここに直接的なメソッドがなくてイマイチピンとこなかったけど、それは後ほど。
面白いなと思ったのは、examplesっていうクラスメソッドを指定することでfew shotの例としてツールの説明に追加されるらしい。
そして、ChatAgentを定義する。
config = lr.ChatAgentConfig(
name="Spy",
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
),
use_tools=True, # `use_tools`が有効なら、Langroid独自のツールメカニズムを使用する
use_functions_api=False, # `use_functions_api`が有効なら、OpenAIのFunction Callingを使用する
vecdb=None,
)
class SpyGameAgent(lr.ChatAgent):
def __init__(self, config: lr.ChatAgentConfig):
super().__init__(config)
self.numbers = [3, 4, 8, 11, 15, 25, 40, 80, 90]
def probe(self, msg: ProbeTool) -> str:
# self.numbersの値のいくつがmsg.number以下であるかを返す
return str(len([n for n in self.numbers if n <= msg.number]))
spy_game_agent = SpyGameAgent(config)
ChatAgentConfigを使って設定を定義するのはこれまでと同じだけども、use_toolsとuse_functions_apiを定義することでツールが使えるようになる。
そしてChatAgentをそのまま使うのではなく、これを継承したクラスを作成して、そこでツールのメソッドを定義する、という流れになるらしい。今回はSpyGameAgentというクラス。
そしてインスタンスを作成して、ツールを登録する。
spy_game_agent = SpyGameAgent(config)
spy_game_agent.enable_message(ProbeTool)
では実行。
task = lr.Task(
spy_game_agent,
system_message="""
私は、1から100までの数字からランダムに選んだ数字のリストを持っています。
あなたの仕事は、その中から最も小さい数字を見つけることです。
ヒントとして、私に数字を言うと、その数字と等しい数字、もしくは、その数字よりも小さい数字が、
私の数字リストの中に「何個あるか?」を教えます。
最小の数字を見つけたら、「DONE」と答えて、その数を報告してください。
""",
interactive=False,
)
task.run()
(Spy) User
>>> Starting Agent Spy (1) gpt-4o
(Spy) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Spy) Agent
まず、50を試してみましょう。{ "request": "probe", "number": 50 }Stats: N_MSG=1, TOKENS: in=365, out=30, max=1024, ctx=128000, COST: now=$0.0023, cumul=$0.1247, tot=$0.4637
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) TOOL( probe) まず、50を試してみましょう。{ "request": "probe", "number": 50 }Agent: 7
*(Spy) Agent Entity.AGENT( Spy) (=> ) (X ) ( ) 7
(Spy) User
(Spy) Agent Entity.AGENT(Entity.AGENT) (=> ) (X ) ( ) [CANNOT RESPOND]
次に、25を試してみましょう。{ "request": "probe", "number": 25 }Stats: N_MSG=3, TOKENS: in=396, out=31, max=1024, ctx=128000, COST: now=$0.0024, cumul=$0.1271, tot=$0.4662
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) TOOL( probe) 次に、25を試してみましょう。{ "request": "probe", "number": 25 }Agent: 6
*(Spy) Agent Entity.AGENT( Spy) (=> ) (X ) ( ) 6
(Spy) User
(Spy) Agent Entity.AGENT(Entity.AGENT) (=> ) (X ) ( ) [CANNOT RESPOND]
次に、12を試してみましょう。{ "request": "probe", "number": 12 }Stats: N_MSG=5, TOKENS: in=428, out=31, max=1024, ctx=128000, COST: now=$0.0026, cumul=$0.1297, tot=$0.4688
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) TOOL( probe) 次に、12を試してみましょう。{ "request": "probe", "number": 12 }Agent: 4
*(Spy) Agent Entity.AGENT( Spy) (=> ) (X ) ( ) 4
(Spy) User
(Spy) Agent Entity.AGENT(Entity.AGENT) (=> ) (X ) ( ) [CANNOT RESPOND]
次に、6を試してみましょう。{ "request": "probe", "number": 6 }Stats: N_MSG=7, TOKENS: in=460, out=31, max=1024, ctx=128000, COST: now=$0.0028, cumul=$0.1325, tot=$0.4716
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) TOOL( probe) 次に、6を試してみましょう。{ "request": "probe", "number": 6 }Agent: 2
*(Spy) Agent Entity.AGENT( Spy) (=> ) (X ) ( ) 2
(Spy) User
(Spy) Agent Entity.AGENT(Entity.AGENT) (=> ) (X ) ( ) [CANNOT RESPOND]
次に、3を試してみましょう。{ "request": "probe", "number": 3 }Stats: N_MSG=9, TOKENS: in=492, out=31, max=1024, ctx=128000, COST: now=$0.0029, cumul=$0.1354, tot=$0.4745
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) TOOL( probe) 次に、3を試してみましょう。{ "request": "probe", "number": 3 }Agent: 1
*(Spy) Agent Entity.AGENT( Spy) (=> ) (X ) ( ) 1
(Spy) User
(Spy) Agent Entity.AGENT(Entity.AGENT) (=> ) (X ) ( ) [CANNOT RESPOND]
次に、2を試してみましょう。{ "request": "probe", "number": 2 }Stats: N_MSG=11, TOKENS: in=524, out=31, max=1024, ctx=128000, COST: now=$0.0031, cumul=$0.1385, tot=$0.4776
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) TOOL( probe) 次に、2を試してみましょう。{ "request": "probe", "number": 2 }Agent: 0
*(Spy) Agent Entity.AGENT( Spy) (=> ) (X ) ( ) 0
(Spy) User
(Spy) Agent Entity.AGENT(Entity.AGENT) (=> ) (X ) ( ) [CANNOT RESPOND]
最小の数字は3であることが確認できました。「DONE」と答えて、最小の数字を報告します。
DONE: 3
Stats: N_MSG=13, TOKENS: in=556, out=33, max=1024, ctx=128000, COST: now=$0.0033, cumul=$0.1418, tot=$0.4808
(gpt-4o)
*(Spy) LLM Entity.LLM( ) (=> ) (X ) ( ) 最小の数字は3であることが確認できました。「DONE」と答えて、最小の数字を報告します。
DONE: 3
Bye, hope this was useful!
<<< Finished Agent Spy (14)
ChatDocument(content='最小の数字は3であることが確認できました。\n\n「」と答えて、最小の数字を報告します。\n\n: 3', metadata=ChatDocMetaData(source='User', is_chunk=False, id='', window_ids=[], parent=None, sender=<Entity.USER: 'User'>, tool_ids=[], parent_responder=None, block=None, sender_name='Spy', recipient='', usage=None, cached=False, displayed=False, has_citation=False, status=<StatusCode.DONE: 'DONE'>), function_call=None, tool_messages=[], attachment=None)
ツールを使って回答にたどり着いている。
3つのエージェントの連携にメッセージのルーティングを追加する
上の方でやった3つのエージェントの連携のログを見てみる。
1つの数値に対して、2つのサブタスク(even_agent, odd_agent)がそれぞれ実行されている。例えば、1の場合。
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) 1
(EvenHandler) User Entity.USER( ) (=> ) (X ) ( ) 1
...|>>> Starting Agent EvenHandler (1) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
DO-NOT-KNOW
(OddHandler) User Entity.USER( ) (=> ) (X ) ( ) 1
...|>>> Starting Agent OddHandler (1) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
4
1は奇数なので、偶数を処理するEvenHandlerではDO-NOT-KNOWという「正しくない」レスポンスが返って、奇数を処理するOddHandlerでは計算結果を返している。
次に、6の場合。
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) 6
...|>>> Starting Agent EvenHandler (5) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
3
6の場合は、偶数を処理するEvenHandlerで「正しい」レスポンスが返せてしまうため、OddHandlerは実行されていない。
これは上でも書いた通り、
サブタスクがある場合、上のmain_task.step()だと以下のように後ろに追加される。
[self.agent_response, self.llm_response, self.user_response, helper_task1.run(), helper_task2.run]ネイティブなrespondersが現在のpending_messageに応答できない場合は、サブタスクにフェールオーバーするというのが一つの考え方らしい。
という動きになっているのだけど、そもそも数値をサブタスクに渡す前に、「どちらのサブタスクで行うべきか?」というルーティングを行えば、無駄な処理をおこなわくて済む上、タスク側で間違った回答をしないように、という考慮も減る。
これを行うにはRecipientToolを使う。まず、エージェントへのシステムプロンプトでRecipientToolの使い方を伝える。
processor_task = lr.Task(
processor_agent,
name = "Processor",
system_message="""
あなたのゴールは、ユーザから数字のリストを受け取って、それぞれの数字に変換を適用することです。
しかしあなたは変換方法を知らないので、以下の2人が助けてくれます。
もし数字が偶数なら、EvenHandlerに送ってください。
もし数字が奇数なら、OddHandlerに送ってください。
重要: 1度に送る数字は1つだけで、簡潔かつ、それ以外には何も送らないでください。
それぞれの数字をこれらのHandlerに送れば結果を返してくれます。
ただし間違った方のHandlerに送ると、負の数が返ってしまいます。あなたは消して負の値を受け取ってはいけません。
そのため、`recipient_message` tool/function-callを使って、数値をどちらに送るのかを明確に指定する必要があります。
`recipient_message` tool/function-callを使う際、 `content`フィールドには送りたい数字を、
`recipient`フィールドには意図する受信者の名前("EvenHandler "または "OddHandler "のいずれか)を指定してください。
ゴールを達成したら、"DONE"と言って、結果をリストとして教えて下さい。
数字のリストをまず聞いてから始めてください。
""",
llm_delegate=True,
single_round=False,
interactive=False,
)
そしてエージェントでRecipientToolを有効にする
processor_agent.enable_message(lr.agent.tools.RecipientTool)
あとは同じようにサブタスクを追加。
processor_task.add_sub_task([even_task, odd_task])
では実行。
processor_task.run("[1, 3, 6, 9]")
(Processor) User Entity.USER( ) (=> ) (X ) ( ) [1, 3, 6, 9]
>>> Starting Agent Processor (1) gpt-4o
(Processor) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Processor) Agent
FUNC: recipient_message: {"intended_recipient":"OddHandler","content":"1"}
Stats: N_MSG=2, TOKENS: in=426, out=45, max=1024, ctx=128000, COST: now=$0.0028, cumul=$0.0028, tot=$0.1141
(gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) FUNC(recipient_message) FUNC: {
"name": "recipient_message",
"arguments": {
"intended_recipient": "OddHandler",
"content": "1"
}
}
RecipientTool: Validated properly addressed message
*(Processor) Agent Entity.LLM( ) (=>OddHandler) (X ) ( ) 1
(Processor) User Entity.USER(Entity.USER) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) Agent Entity.AGENT(Entity.AGENT) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) LLM Entity.LLM(Entity.LLM) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) EvenHandler Entity.USER(EvenHandler) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(OddHandler) User Entity.USER( ) (=>OddHandler) (X ) ( ) 1
...|>>> Starting Agent OddHandler (1) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
4
...|Stats: N_MSG=2, TOKENS: in=69, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0004, tot=$0.1145
(gpt-4o)
*(OddHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 4
...|<<< Finished Agent OddHandler (3)
*(Processor) OddHandler Entity.USER(OddHandler) (=> ) (X ) ( ) 4
(Processor) User
(Processor) Agent
FUNC: recipient_message: {"intended_recipient":"OddHandler","content":"3"}
Stats: N_MSG=4, TOKENS: in=472, out=45, max=1024, ctx=128000, COST: now=$0.0030, cumul=$0.0058, tot=$0.1175
(gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) FUNC(recipient_message) FUNC: {
"name": "recipient_message",
"arguments": {
"intended_recipient": "OddHandler",
"content": "3"
}
}
RecipientTool: Validated properly addressed message
*(Processor) Agent Entity.LLM( ) (=>OddHandler) (X ) ( ) 3
(Processor) User Entity.USER(Entity.USER) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) Agent Entity.AGENT(Entity.AGENT) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) LLM Entity.LLM(Entity.LLM) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) EvenHandler Entity.USER(EvenHandler) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(OddHandler) User Entity.USER( ) (=>OddHandler) (X ) ( ) 3
...|>>> Starting Agent OddHandler (3) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
10
...|Stats: N_MSG=4, TOKENS: in=71, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0007, tot=$0.1179
(gpt-4o)
*(OddHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 10
...|<<< Finished Agent OddHandler (5)
*(Processor) OddHandler Entity.USER(OddHandler) (=> ) (X ) ( ) 10
(Processor) User
(Processor) Agent
FUNC: recipient_message: {"intended_recipient":"EvenHandler","content":"6","request":"recipient_message"}
Stats: N_MSG=6, TOKENS: in=518, out=45, max=1024, ctx=128000, COST: now=$0.0033, cumul=$0.0091, tot=$0.1211
(gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) FUNC(recipient_message) FUNC: {
"name": "recipient_message",
"arguments": {
"intended_recipient": "EvenHandler",
"content": "6"
}
}
RecipientTool: Validated properly addressed message
*(Processor) Agent Entity.LLM( ) (=>EvenHandler) (X ) ( ) 6
(Processor) User Entity.USER(Entity.USER) (=>EvenHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) Agent Entity.AGENT(Entity.AGENT) (=>EvenHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) LLM Entity.LLM(Entity.LLM) (=>EvenHandler) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) User Entity.USER( ) (=>EvenHandler) (X ) ( ) 6
...|>>> Starting Agent EvenHandler (1) gpt-4o
(EvenHandler) User Entity.USER(Entity.USER) (=>EvenHandler) (X ) ( ) [CANNOT RESPOND]
(EvenHandler) Agent
...|
3
...|Stats: N_MSG=2, TOKENS: in=66, out=1, max=1024, ctx=128000, COST: now=$0.0003, cumul=$0.0003, tot=$0.1215
(gpt-4o)
*(EvenHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 3
...|<<< Finished Agent EvenHandler (3)
*(Processor) EvenHandler Entity.USER(EvenHandler) (=> ) (X ) ( ) 3
(Processor) User
(Processor) Agent
FUNC: recipient_message: {"intended_recipient":"OddHandler","content":"9","request":"recipient_message"}
Stats: N_MSG=8, TOKENS: in=564, out=45, max=1024, ctx=128000, COST: now=$0.0035, cumul=$0.0126, tot=$0.1250
(gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) FUNC(recipient_message) FUNC: {
"name": "recipient_message",
"arguments": {
"intended_recipient": "OddHandler",
"content": "9"
}
}
RecipientTool: Validated properly addressed message
*(Processor) Agent Entity.LLM( ) (=>OddHandler) (X ) ( ) 9
(Processor) User Entity.USER(Entity.USER) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) Agent Entity.AGENT(Entity.AGENT) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) LLM Entity.LLM(Entity.LLM) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(Processor) EvenHandler Entity.USER(EvenHandler) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(OddHandler) User Entity.USER( ) (=>OddHandler) (X ) ( ) 9
...|>>> Starting Agent OddHandler (5) gpt-4o
(OddHandler) User Entity.USER(Entity.USER) (=>OddHandler) (X ) ( ) [CANNOT RESPOND]
(OddHandler) Agent
...|
28
...|Stats: N_MSG=6, TOKENS: in=73, out=1, max=1024, ctx=128000, COST: now=$0.0004, cumul=$0.0011, tot=$0.1253
(gpt-4o)
*(OddHandler) LLM Entity.LLM( ) (=> ) (X ) ( ) 28
...|<<< Finished Agent OddHandler (7)
*(Processor) OddHandler Entity.USER(OddHandler) (=> ) (X ) ( ) 28
(Processor) User
(Processor) Agent
DONE結果のリストは: [4, 10, 3, 28]
Stats: N_MSG=10, TOKENS: in=610, out=20, max=1024, ctx=128000, COST: now=$0.0034, cumul=$0.0159, tot=$0.1287
(gpt-4o)
*(Processor) LLM Entity.LLM( ) (=> ) (X ) ( ) DONE結果のリストは: [4, 10, 3, 28]
Bye, hope this was useful!
<<< Finished Agent Processor (11)
ChatDocument(content='結果のリストは: [4, 10, 3, 28]', metadata=ChatDocMetaData(source='User', is_chunk=False, id='', window_ids=[], parent=None, sender=<Entity.USER: 'User'>, tool_ids=[], parent_responder=None, block=None, sender_name='Processor', recipient='', usage=None, cached=False, displayed=False, has_citation=False, status=<StatusCode.DONE: 'DONE'>), function_call=None, tool_messages=[], attachment=None)
Function Callingを使って、どのサブタスクを使うか?を判定してから処理を行っているので、上でやったときよりもスッキリしているのがわかる。
全部のコードは以下。
import langroid as lr
config = lr.ChatAgentConfig(
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
),
vecdb = None,
)
processor_agent = lr.ChatAgent(config)
processor_task = lr.Task(
processor_agent,
name = "Processor",
system_message="""
あなたのゴールは、ユーザから数字のリストを受け取って、それぞれの数字に変換を適用することです。
しかしあなたは変換方法を知らないので、以下の2人が助けてくれます。
もし数字が偶数なら、EvenHandlerに送ってください。
もし数字が奇数なら、OddHandlerに送ってください。
重要: 1度に送る数字は1つだけで、簡潔かつ、それ以外には何も送らないでください。
それぞれの数字をこれらのHandlerに送れば結果を返してくれます。
ただし間違った方のHandlerに送ると、負の数が返ってしまいます。あなたは消して負の値を受け取ってはいけません。
そのため、`recipient_message` tool/function-callを使って、数値をどちらに送るのかを明確に指定する必要があります。
`recipient_message` tool/function-callを使う際、 `content`フィールドには送りたい数字を、
`recipient`フィールドには意図する受信者の名前("EvenHandler "または "OddHandler "のいずれか)を指定してください。
ゴールを達成したら、"DONE"と言って、結果をリストとして教えて下さい。
数字のリストをまず聞いてから始めてください。
""",
llm_delegate=True,
single_round=False,
interactive=False,
)
NO_ANSWER = lr.utils.constants.NO_ANSWER
even_agent = lr.ChatAgent(config)
even_task = lr.Task(
even_agent,
name = "EvenHandler",
system_message=f"""
あたなには数値が与えられます。
その数値が偶数ならば、2で割ってその結果だけ返して、それ以外には何も返さないでください。
その数値が奇数ならば、{NO_ANSWER} を返してください。
""",
single_round=True, # task done after 1 step() with valid response
interactive=False,
)
odd_agent = lr.ChatAgent(config)
odd_task = lr.Task(
odd_agent,
name = "OddHandler",
system_message=f"""
あたなには数値nが与えられます。
その数値nが奇数ならば、(n*3+1) を返して、それ以外には何も返さないでください。
その数値が偶数ならば、{NO_ANSWER} を返してください。
""",
single_round=True, # task done after 1 step() with valid response
interactive=False,
)
processor_agent.enable_message(lr.agent.tools.RecipientTool)
processor_task.add_sub_task([even_task, odd_task])
processor_task.run("[1, 3, 6, 9]")
RAGエージェント
DocChatAgentを使うと、ベクトルストアと連携させたエージェントが作成できる。
ということで以下のドキュメントを元にベクトルデータにいれるためのフォーマットに変換する。ちょっと冗長ではあるのだけども、以前LangChainを使った際のやり方をまるっと流用。
!pip install --upgrade langroid langchain-text-splitters
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
# markdown(.md)ファイルとして出力
with open(data_path / f"{title}.md", "w") as fp:
fp.write(wiki_text)
import glob
import os
from langchain_text_splitters import MarkdownHeaderTextSplitter
from langchain_core.documents import Document
def text_split(text, max_length=400):
"""
"""
chunks = re.split(r'(?<=[。!?\n])', text)
chunks = [s for s in chunks if s.strip()]
temp_chunk = ""
final_chunks = []
for chunk in chunks:
if len(temp_chunk + chunk) <= max_length:
temp_chunk += chunk
else:
final_chunks.append(temp_chunk)
temp_chunk = chunk
if temp_chunk:
final_chunks.append(temp_chunk)
return final_chunks
sections_for_delete = ["競走成績", "外部リンク", "参考文献"]
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
("####", "Header 4"),
("#####", "Header 5"),
("######", "Header 6"),
]
files = glob.glob('data/*.md')
splits = []
for file in files:
with open(file) as f:
md = f.read()
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_split = markdown_splitter.split_text(md)
docs_for_delete = []
for idx, d in enumerate(docs_split):
metadatas = []
header_keys = []
d.metadata["source"] = file
for m in d.metadata:
if m.startswith("Header"):
metadatas.append(d.metadata[m])
header_keys.append(m)
# 削除対象のセクションを含むドキュメントを後で削除するためにそのインデックス登録しておく
if d.metadata[m] in sections_for_delete:
docs_for_delete.append(idx)
# セクションの階層を結合、パンくずリストとしてセクション情報に追加
if len(metadatas) > 0:
d.metadata["section"] = metadata_str = " > ".join(metadatas)
for k in header_keys:
if k.startswith("Header"):
del d.metadata[k]
# 削除対象セクションの削除
docs = [item for i, item in enumerate(docs_split) if i not in docs_for_delete]
# セクション内のテキストが一定量を超えていればさらにチャンク分割
for d in docs:
chunks = text_split(d.page_content, 500)
if len(chunks) == 1:
splits.append(d)
else:
for idx, chunk in enumerate(chunks, start=1):
metadata = d.metadata.copy()
metadata["section"] += f"({idx})"
splits.append(Document(page_content=chunk, metadata=metadata))
こんな感じでドキュメントのチャンクができる。
for s in splits[:5]:
print(s.metadata)
print(s.page_content[:60] + "...")
print("====")
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > 概要'}
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > デビューまで > 誕生に至る経緯'}
オグリキャップの母・ホワイトナルビーは競走馬時代に馬主の小栗孝一が所有し、笠松競馬場の調教師鷲見昌勇が管理した。ホワイト...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > デビューまで > 誕生・生い立ち > 稲葉牧場時代'}
オグリキャップは1985年3月27日の深夜に誕生した。誕生時には右前脚が大きく外向しており、出生直後はなかなか自力で立ち...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > デビューまで > 誕生・生い立ち > 美山育成牧場時代'}
1986年の10月、ハツラツは岐阜県山県郡美山町(現:山県市)にあった美山育成牧場に移り、3か月間馴致を施された。当時の...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > 競走馬時代 > 笠松競馬時代 > 競走内容(1)'}
1987年1月28日に笠松競馬場の鷲見昌勇厩舎に入厩。登録馬名は「オグリキヤツプ」。ダート800mで行われた能力試験を5...
====
でこれをLangroidのDocumentクラスで定義しなおしてリストを作成する。
import langroid as lr
documents = []
for s in splits:
documents.append(
lr.Document(
content=s.page_content,
metadata=lr.DocMetaData(**s.metadata)
)
)
ではエージェントを定義していく。DocChatAgentConfigでLLM、ベクトルDB、とパーサーでのチャンク分割の設定を行う。んー、今回は既にチャンク分割しているので、パーサーの設定はいらないような気がするのだけども、そういう場合にどのように設定すればいいのかがわからないので、一旦サンプルコードのままで。
from langroid.agent.special import DocChatAgent, DocChatAgentConfig
import nest_asyncio
# colaboratoryとかだと必須
nest_asyncio.apply()
config = DocChatAgentConfig(
llm = lr.language_models.OpenAIGPTConfig(
chat_model=lr.language_models.OpenAIChatModel.GPT4o,
),
vecdb=lr.vector_store.QdrantDBConfig(
collection_name="オグリキャップ",
replace_collection=True,
),
parsing=lr.parsing.parser.ParsingConfig(
separators=["\n\n"],
splitter=lr.parsing.parser.Splitter.SIMPLE,
n_similar_docs=2,
)
)
agent = DocChatAgent(config)
エージェントを定義したら、ドキュメントを追加する。
agent.ingest_docs(documents)
89
89件(のチャンク)が処理された。
ではタスクを登録して実行してみる。日本語で出力されるようにシステムメッセージを追加している。
task = lr.Task(
agent,
system_message="""
あなたは親切な日本語のアシスタントです。あなたの仕事は、与えられた文書について、ユーザが理解するのを手伝うことです。
""",
)
task.run()
(LLM-Agent) User
>>> Starting Agent LLM-Agent (2) gpt-4o
(LLM-Agent) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(LLM-Agent) Agent
もちろんです。文書の内容について質問があれば、どうぞお聞かせください。質問に対してできる限り正確でわかりやすい回答を提供いたします。また、要約が必要な場合もお手伝いしますので、具体的な文書の一部を教えてください。
Stats: N_MSG=2, TOKENS: in=78, out=72, max=1024, ctx=128000, COST: now=$0.0015, cumul=$0.0015, tot=$0.0015 (gpt-4o)
*(LLM-Agent) LLM Entity.LLM( ) (=> ) (X ) ( )
もちろんです。文書の内容について質問があれば、どうぞお聞かせください。質問に対してできる限り正確でわかりやすい回答を提供いたします。また、要約が必要な場合もお手伝いしますので、具体的な文書の一部を教え
てください。
Human (respond or q, x to exit current level, or hit enter to continue)
:
オグリキャップの血統について教えて
*(LLM-Agent) User Entity.USER( ) (=> ) (X ) ( ) オグリキャップの血統について教えて
(LLM-Agent) Agent
WARNING:langroid.cachedb.redis_cachedb:REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
2024-06-03 02:41:01 - WARNING - REDIS_PASSWORD, REDIS_HOST, REDIS_PORT not set in .env file,
using fake redis client
INFO:langroid.utils.output.status:[bold green]Running 6 copies of Relevance-Extractor...
2024-06-03 02:41:01 - INFO - [bold green]Running 6 copies of Relevance-Extractor...
(Relevance-Extractor-0) User Entity.USER( ) (=> ) (X ) ( )
お笑い芸人の明石家さんまは雑誌『サラブレッドグランプリ』のインタビューにおいて、オグリキャップについて「マル地馬で血統も良くない。それが中央に来て勝ち続ける。エリートが歩むクラシック路線から外されてね
。ボクらみたいにイナカから出てきて東京で働いているもんにとっては希望の星ですよ」と述べている。須田鷹雄は中央移籍3戦目のNZT4歳Sを7馬身差で圧勝して大きな衝撃を与えたことでオグリキャップは競馬人気の旗手
を担うこととなったとし、その後有馬記念を優勝したことで競馬ブームの代名詞的存在となったと述べている。江面弘也は、5歳初戦のオールカマーでオグリキャップがパドックに姿を現しただけで拍手が沸き起こったこと
を振り返り、「後になって思えば、あれが『オグリキャップ・ブーム』の始まりだった」と回顧している。阿部珠樹は「オグリキャップのように、人の気持ちをグイグイ引っ張り、新しい場所に連れて行ってくれた馬はもう
出ないのではないだろうか」と述べている。
(Relevance-Extractor-0) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Relevance-Extractor-0) Agent
*(Relevance-Extractor-0) LLM Entity.LLM( ) (=> ) (X ) TOOL(extract_segments) {
"request": "extract_segments",
"segment_list": "1"
}
*(Relevance-Extractor-0) Agent Entity.AGENT(Relevance-Extractor-0) (=> ) (X ) ( ) DONE
お笑い芸人の明石家さんまは雑誌『サラブレッドグランプリ』のインタビューにおいて、オグリキャップについて「マル地馬で血統も良くない。それが中央に来て勝ち続ける。エリートが歩むクラシック路線から外されてね
。ボクらみたいにイナカから出てきて東京で働いているもんにとっては希望の星ですよ」と述べている。須田鷹雄は中央移籍3戦目のNZT4歳Sを7馬身差で圧勝して大きな衝撃を与えたことでオグリキャップは競馬人気の旗手
を担うこととなったとし、その後有馬記念を優勝したことで競馬ブームの代名詞的存在となったと述べている。江面弘也は、5歳初戦のオールカマーでオグリキャップがパドックに姿を現しただけで拍手が沸き起こったこと
を振り返り、「後になって思えば、あれが『オグリキャップ・ブーム』の始まりだった」と回顧している。阿部珠樹は「オグリキャップのように、人の気持ちをグイグイ引っ張り、新しい場所に連れて行ってくれた馬はもう
出ないのではないだろうか」と述べている。
(Relevance-Extractor-1) User Entity.USER( ) (=> ) (X ) ( ) オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞
特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に選出。愛称は「オグリ」「芦毛の怪物」など多数。
中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコーに
比肩するとも評される高い人気を得た。
競走馬引退後は北海道新冠町の優駿スタリオンステーションで種牡馬となったが、産駒から中央競馬の重賞優勝馬を出すことができず、2007年に種牡馬を引退。種牡馬引退後は同施設で功労馬として繋養されていたが、2010
年7月3日に右後肢脛骨を骨折し、安楽死の処置が執られた。
(Relevance-Extractor-1) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Relevance-Extractor-1) Agent
*(Relevance-Extractor-1) LLM Entity.LLM( ) (=> ) (X ) FUNC( ) FUNC: {
"name": "",
"arguments": {
"segment_list": "1"
}
}
(Relevance-Extractor-1) User
*(Relevance-Extractor-1) Agent Entity.AGENT( ) (=> ) (X ) ( ) DONE DO-NOT-KNOW
(Relevance-Extractor-2) User Entity.USER( ) (=> ) (X ) ( )
オグリキャップの母・ホワイトナルビーは競走馬時代に馬主の小栗孝一が所有し、笠松競馬場の調教師鷲見昌勇が管理した。ホワイトナルビーが繁殖牝馬となった後はその産駒の競走馬はいずれも小栗が所有し、鷲見が管理
していた。
1984年のホワイトナルビーの交配相手には、小栗によると当初はトウショウボーイが種付けされる予定だったが、種付け予定に空きがなかったため断念した。そこで小栗の意向により、笠松競馬で優れた種牡馬成績を残して
いたダンシングキャップが選ばれた。鷲見はダンシングキャップの産駒に気性の荒い競走馬が多かったことを理由に反対したが、小栗は「ダンシングキャップ産駒は絶対によく走る」という確信と、ホワイトナルビーがこれ
までに出産していた5頭の産駒が大人しい性格だったため大丈夫だろうと感じ、最終的に提案が実現した。
なお、オグリキャップは仔分けの馬で、出生後に小栗が稲葉牧場に対してセリ市に出した場合の想定額を支払うことで産駒の所有権を取得する取り決めがされていた。オグリキャップについて小栗が支払った額は250万円と
も500万円ともされる。
(Relevance-Extractor-2) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Relevance-Extractor-2) Agent
*(Relevance-Extractor-2) LLM Entity.LLM( ) (=> ) (X ) TOOL(extract_segments) {
"request": "extract_segments",
"segment_list": "1"
}
*(Relevance-Extractor-2) Agent Entity.AGENT(Relevance-Extractor-2) (=> ) (X ) ( ) DONE
オグリキャップの母・ホワイトナルビーは競走馬時代に馬主の小栗孝一が所有し、笠松競馬場の調教師鷲見昌勇が管理した。ホワイトナルビーが繁殖牝馬となった後はその産駒の競走馬はいずれも小栗が所有し、鷲見が管理
していた。
1984年のホワイトナルビーの交配相手には、小栗によると当初はトウショウボーイが種付けされる予定だったが、種付け予定に空きがなかったため断念した。そこで小栗の意向により、笠松競馬で優れた種牡馬成績を残して
いたダンシングキャップが選ばれた。鷲見はダンシングキャップの産駒に気性の荒い競走馬が多かったことを理由に反対したが、小栗は「ダンシングキャップ産駒は絶対によく走る」という確信と、ホワイトナルビーがこれ
までに出産していた5頭の産駒が大人しい性格だったため大丈夫だろうと感じ、最終的に提案が実現した。
なお、オグリキャップは仔分けの馬で、出生後に小栗が稲葉牧場に対してセリ市に出した場合の想定額を支払うことで産駒の所有権を取得する取り決めがされていた。オグリキャップについて小栗が支払った額は250万円と
も500万円ともされる。
(Relevance-Extractor-3) User Entity.USER( ) (=> ) (X ) ( )
父・ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、もしくは「(2代父の)ネイティヴダンサーの隔世遺伝で生まれた競走馬である」と主張する者もいた。一
方で血統評論家の山野浩一は、ダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、「オグリキャップに関しても、そういう金の鉱脈を掘り当てたんでしょう」と分析して
いる。
母・ホワイトナルビーは現役時代は笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めている(ただしほとんどの産駒は地方競馬を主戦場としていた)。5代母のクインナルビー(父:クモハタ)は1953年の天皇賞(秋)
を制している。クインナルビーの子孫には他にアンドレアモン、キョウエイマーチなどの重賞勝ち馬がいる。
(Relevance-Extractor-3) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Relevance-Extractor-3) Agent
*(Relevance-Extractor-3) LLM Entity.LLM( ) (=> ) (X ) TOOL(extract_segments) {
"request": "extract_segments",
"segment_list": "1"
}
*(Relevance-Extractor-3) Agent Entity.AGENT(Relevance-Extractor-3) (=> ) (X ) ( ) DONE
父・ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、もしくは「(2代父の)ネイティヴダンサーの隔世遺伝で生まれた競走馬である」と主張する者もいた。一
方で血統評論家の山野浩一は、ダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、「オグリキャップに関しても、そういう金の鉱脈を掘り当てたんでしょう」と分析して
いる。
母・ホワイトナルビーは現役時代は笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めている(ただしほとんどの産駒は地方競馬を主戦場としていた)。5代母のクインナルビー(父:クモハタ)は1953年の天皇賞(秋)
を制している。クインナルビーの子孫には他にアンドレアモン、キョウエイマーチなどの重賞勝ち馬がいる。
(Relevance-Extractor-4) User Entity.USER( ) (=> ) (X ) ( )
オグリキャップの体力面について、競馬関係者からは故障しにくい点や故障から立ち直るタフさを評価する声が挙がっている。輸送時に体重が減りにくい体質でもあり、通常の競走馬が二時間程度の輸送で6キロから8キロ体
重が減少するのに対し、1988年の有馬記念の前に美浦トレーニングセンターと中山競馬場を往復した上に同競馬場で調教を行った際に2キロしか体重が減少しなかった。オグリキャップは心臓や消化器官をはじめとする内臓
も強く、普通の馬であればエンバクが未消化のまま糞として排出されることが多いものの、オグリキャップはエンバクの殻まで隈なく消化されていた。安藤勝己は、オグリキャップのタフさは心臓の強さからくるものだと述
べている。獣医師の吉村秀之は、オグリキャップは中央競馬へ移籍してきた当初からスポーツ心臓を持っていたと証言している。
(Relevance-Extractor-4) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Relevance-Extractor-4) Agent
*(Relevance-Extractor-4) LLM Entity.LLM( ) (=> ) (X ) TOOL(extract_segments) {
"request": "extract_segments",
"segment_list": ""
}
*(Relevance-Extractor-4) Agent Entity.AGENT(Relevance-Extractor-4) (=> ) (X ) ( ) DONE DO-NOT-KNOW
(Relevance-Extractor-5) User Entity.USER( ) (=> ) (X ) ( ) 毎日王冠までは避暑
を行わず、栗東トレーニングセンターで調整を行い、8月下旬から本格的な調教を開始。9月末に東京競馬場に移送された。毎日王冠では終始後方からレースを進め、第3コーナーからまくりをかけて優勝した。この勝利によ
り、当時のJRA重賞連勝記録である6連勝を達成した(メジロラモーヌと並ぶタイ記録)。当時競馬評論家として活動していた大橋巨泉は、オグリキャップのレース内容について「毎日王冠で古馬の一線級を相手に、スローペ
ースを後方から大外廻って、一気に差し切るなどという芸当は、今まで見たことがない」「どうやらオグリキャップは本当のホンモノの怪物らしい」と評した。毎日王冠の後、オグリキャップはそのまま東京競馬場に留まっ
て調整を続けた(レースに関する詳細については第39回毎日王冠を参照)。続く天皇賞(秋)では、前年秋から7連勝中であった古馬のタマモクロスを凌いで1番人気に支持された。
(Relevance-Extractor-5) User Entity.USER(Entity.USER) (=> ) (X ) ( ) [CANNOT RESPOND]
(Relevance-Extractor-5) Agent
*(Relevance-Extractor-5) LLM Entity.LLM( ) (=> ) (X ) TOOL(extract_segments) {
"request": "extract_segments",
"segment_list": ""
}
*(Relevance-Extractor-5) Agent Entity.AGENT(Relevance-Extractor-5) (=> ) (X ) ( ) DONE DO-NOT-KNOW
オグリキャップの父はダンシングキャップであり、母はホワイトナルビーです[1]。ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」もしくは「ネイティヴダンサーの隔世遺伝で生まれた競走馬である」と主張する者もいました[2]。一方で、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、「オグリキャップに関しても、そういう金の鉱脈を掘り当てたんでしょう」と分析しています[2:1]。ホワイトナルビーは現役時代に笠松競馬場で4勝を挙げ、その産駒は全て競馬の競走で勝利を収めています[2:2]。
途中を見てみると、どうやら6件ほどのドキュメントが抽出されている。で、それぞれのドキュメントに対してDONEとDONE DO-NOT-KNOWという風にフラグがついているように思える。もしかすると、抽出したドキュメントごとにクエリとの関連性みたいなものを判断しているのかな???
とりあえず最終的な回答は以下となる。回答とともに引用も含まれている様子。
オグリキャップの父はダンシングキャップであり、母はホワイトナルビーです[1:3]。ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」もしくは「ネイティヴダンサーの隔世遺伝で生まれた競走馬である」と主張する者もいました[2:9]。一方で、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、「オグリキャップに関しても、そういう金の鉱脈を掘り当てたんでしょう」と分析しています[2:10]。ホワイトナルビーは現役時代に笠松競馬場で4勝を挙げ、その産駒は全て競馬の競走で勝利を収めています[2:11]。
SOURCES:
[1:4] data/オグリキャップ.md
オグリキャップの母・ホワイトナルビーは競走馬時代に馬主の小栗孝一が所有し、笠松競馬場の調教師鷲見昌勇が管理した。ホワイトナルビーが繁殖牝馬となった後はその産駒の競走馬はいずれも小栗が所有し、鷲見が管理していた。
1984年のホワイトナルビーの交配相手には、小栗によると当初はトウショウボーイが種付けされる予定だったが、種付け予定に空きがなかったため断念した。そこで小栗の意向により、笠松競馬で優れた種牡馬成績を残していたダンシングキャップが選ばれた。鷲見はダンシングキャップの産駒に気性の荒い競走馬が多かったことを理由に反対したが、小栗は「ダンシングキャップ産駒は絶対によく走る」という確信
と、ホワイトナルビーがこれまでに出産していた5頭の産駒が大人しい性格だったため大丈夫だろうと感じ、最終的に提案が実現した。
なお、オグリキャップは仔分けの馬で、出生後に小栗が稲葉牧場に対してセリ市に出した場合の想定額を支払うことで産駒の所有権を取得する取り決めがされていた。オグリキャップについて小栗が支払った額は250万円とも500万円ともされる。
[2:12] data/オグリキャップ.md
父・ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、もしくは「(2代父の)ネイティヴダンサーの隔世遺伝で生まれた競走馬である」と主張する者もいた。一方で血統評論家の山野浩一は、ダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、「オグリキャップに関しても、そういう金の鉱脈を掘り当てたんでしょう」と分析している。
母・ホワイトナルビーは現役時代は笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めている(ただしほとんどの産駒は地方競馬を主戦場としていた)。5代母のクインナルビー(父:クモハタ)は1953年の天皇賞(秋)を制している。クインナルビーの子孫には他にアンドレアモン、キョウエイマーチなどの重賞勝ち馬がいる。
RAGで使用されているプロンプトはこの辺になると思う。DocChatAgentConfigで設定するのが本来っぽい。
所感
※あくまでも個人的な所感
自分が過去に試した(といっても少ないけど)エージェント系フレームワークの実装はステートマシンによるもので、
- ステートを管理して情報のやり取りを行う
- グラフで処理のフローを決める
というものだった。それらと比較した場合、Langroidだと
- ステート: メッセージ交換
- フロー: エージェントへのタスク割当
という感じになるのかな?と思う。
ステートマシンだとある程度処理の流れは自分で組む、という感じで、ややプログラム的な印象を個人的には持っているのだけども、Langroidの場合、エージェント=人、って感じで、それにタスクやツールを用意するという感じで、この処理の流れみたいなものはあまり意識しなくてよい、という風に感じるし、確かにそのほうがマルチエージェントという意味では「直感的」でわかりやすいのかもな、とは思った。
ただ、現状のモデルの性能で、それで果たしてゴールにたどり着けるのかなぁ?という懸念はある。実際に日本語プロンプトに置き換えてインタラクティブモードOFFでやってみたら、全然最終回答にたどりつけずに無限ループしたりなんかしてたので。やっぱり何かしらステートみたいなものでイテレーションをコントロールとかしたいなぁという感を持ったりはする。人間が介入する・しない、とかをもっと細かく制御できるのかもしれないけど、ちょっとそこまでは追えなかった。
他にいくつか感じたこととしては、
- ドキュメントが足りないように思える。
- サンプルは実は結構あるのだけども、pythonスクリプトになっている物が多いようで、できればドキュメントはnotebookと連動した一連のチュートリアルであるほうがわかりやすくてよいのではないか?という気がする。
- 細かいパラメータの説明がなくて、サンプルスクリプトを見ながら、ドキュメントにはないパラメータを追加したりした。
- インタラクティブモードとか。
- APIリファレンスがなんかこう見にくい&さがしにくい。
- 概念的な説明が多い。
- 自分はMessage Passingというところがいまいちしっくりこなかった。
- responderの順番、とか、わからないのではないのだけども、んー、という感じ。それならいっそ細かく定義したいなぁという感。
- 実際に送っているプロンプトとかリクエストの中身とかトレースしたいのだけども、そのあたりの情報がちょっと見当たらなかった。
- ログは出るのだけど、少し独特な印象。LLMに送っている生のリクエストとかをみたい。
- LangSmithとかTruLensみたいなトレーシング系のプラットフォームとかOSSとシンプルに連動して見れるのが理想。
あたりかなぁ。総じてドキュメントの情報が足りない感はあるのだけど、GitHub見てる限りは非常に活発だし、GitHub Starsの推移も停滞とか見られず右肩上がりなので、そのうち解消されるのではないかという気はする。
て、コード追っかけたり、トレーシングがあまり揃ってないってのは個人的にはちょっと使いにくく感じる。