OpenAIのオープンウェイトモデル「gpt-oss」を試す
Transformersでやってみたのだが、MXFP4は自分の環境(RTX4090)だと動かなかった(ValueError: MXFP4 quantized models is only supported on GPUs with compute capability >= 9.0 (e.g H100, or B100) と表示される)ので、Ollamaの最新版で。
環境はUbuntu-22.04+RTX4090。なお、自分はMacにもOllamaは入っているが、Homebrew経由だとまだ最新版が来ていなかった(確認した時点では0.10.1で、このバージョンだとgpt-ossは動かない。)
ollama --version
ollama version is 0.11.0
ollama run gpt-oss:20b
ダウンロード後にエラー・・・
Error: template: :3: function "currentDate" not defined
Issueが上がってる。んー、原因がよくわからんが、インストール済みのものを消して、入れ直せ、という感じなのかな?
自分は /opt/ollama にマニュアルインストールしてるので、一旦 /opt/ollama 以下を全部消して、バイナリもGitHubのReleasesからダウンロードし直して再度起動してみたらいけた。
統計情報を有効にしてやってみる
>>> /set verbose
>>> 競馬の魅力を5つリストアップして。
Thinking...
The user asks the same question again: "競馬の魅力を5つリストアップして。" So need to list 5 attractions. The
previous answer listed 5. Maybe respond with a new list or refine. Just answer in Japanese. Provide 5 bullet
points. Possibly different perspective. Ensure each point distinct. Provide short but clear explanation.
...done thinking.
競馬の魅力を5つ挙げると、以下のようになります。
1. **究極のスピードと迫力**
最高速度で走る馬たちの姿は、まるで時間が止まったかのようなスリルと感動を提供します。
2. **戦術と知性の融合**
騎手は馬の特性やレース展開を読み、最適なペース配分や追い込みを決断。競馬は肉体だけでなく頭脳も試されるスポーツで
す。
3. **予想のエンターテインメント**
人気馬・穴馬・人気投手の相性など、数えきれない予測要素があるため、ファンはレース前からワクワクします。
4. **ファン同士のコミュニティ**
競馬場では、同じレースを観戦する仲間が自然とつながり、情報交換や盛り上がりが生まれます。さらに、レース場での飲食
やイベントも魅力です。
5. **文化・経済への貢献**
競馬は日本の歴史と文化に根ざしており、馬主・騎手・調教師の仕事を通じて地方経済や観光業の発展にも寄与しています。
これらが、競馬が多くの人に愛され続ける理由です。
total duration: 1m40.737371088s
load duration: 42.48845ms
prompt eval count: 484 token(s)
prompt eval duration: 38.518041004s
prompt eval rate: 12.57 tokens/s
eval count: 419 token(s)
eval duration: 1m2.124580786s
eval rate: 6.74 tokens/s
んー、もっとGPU使ってほしいなぁ・・・
ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
gpt-oss:20b 05afbac4bad6 36 GB 34%/66% CPU/GPU 8192 Forever
nvidia-smi
Wed Aug 6 04:04:56 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 51C P0 49W / 450W | 12671MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
llama.cppの方もマージされたみたいだが、なんかチャットテンプレート周りでまだうまく行かないみたいなコメントも見える。
とりあえず現状でllama.cppで試してみる。
git clone https://github.com/ggml-org/llama.cpp && cd llma.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j 16
モデルカードに従ってロード。GPUにはフルオフロードしている。
./build/bin/llama-server \
-hf ggml-org/gpt-oss-20b-GGUF \
--ctx-size 0 \
--flash-attn on \
--jinja \
--reasoning-format none \
-ngl 99 \
--host 0.0.0.0
MXFP4版がダウンロードされている。
(snip)
common_download_file_single: no previous model file found /home/kun432/.cache/llama.cpp/ggml-org_gpt-oss-20b-GGUF_gpt-oss-20b-mxfp4.gguf
(snip)
起動したらブラウザでアクセスしてこんな感じ。

コンソールのログでは200tps近く出ている。
prompt eval time = 82.44 ms / 95 tokens ( 0.87 ms per token, 1152.34 tokens per second)
eval time = 2835.65 ms / 549 tokens ( 5.17 ms per token, 193.61 tokens per second)
total time = 2918.09 ms / 644 tokens
フルオフロードでこれぐらい。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 54C P8 17W / 450W | 15117MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
あと、起動時にチャットテンプレートが表示されるが、システムプロンプトを含めた例が出力されていた。
(snip)
, example_format: '<|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-08-06
reasoning: medium
# Valid channels: analysis, commentary, final. Channel must be included for every message.
Calls to these tools must go to the commentary channel: 'functions'.<|end|><|start|>developer<|message|># Instructions
You are a helpful assistant<|end|><|start|>user<|message|>Hello<|end|><|start|>assistant<|message|>Hi there<|end|><|start|>user<|message|>How are you?<|end|><|start|>assistant'
(snip)
システムプロンプトでreasoning: 〜 でReasoningレベルを設定できるみたい(low / medium / high)。llama-serverの設定で変更するならこうかな?
You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-08-06
reasoning: high
# Valid channels: analysis, commentary, final. Channel must be included for every message.
Calls to these tools must go to the commentary channel: 'functions'.
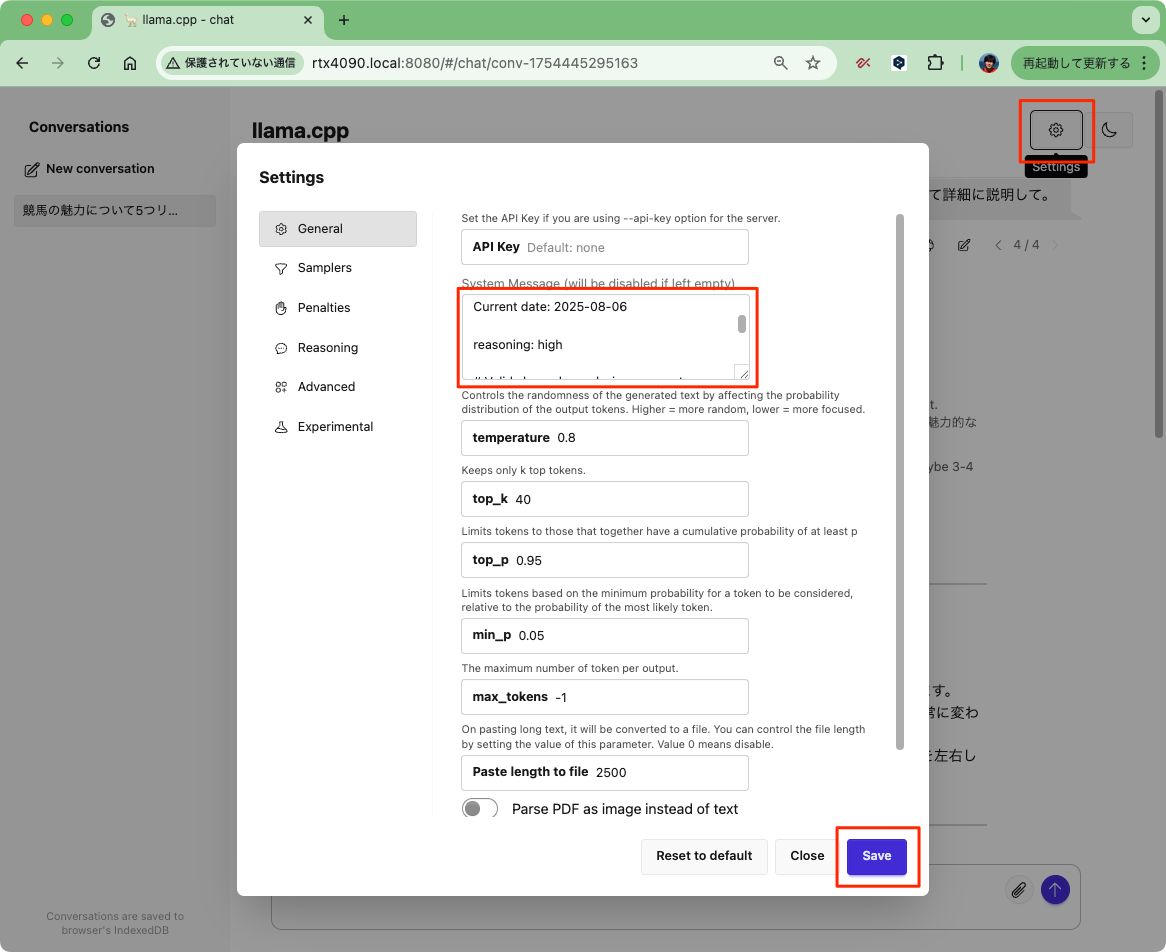
設定後の推論はこんな感じ。ちょっとプロンプトも変えてるけど。

Unslothからも出ている。
モデル。こちらもDiscussionsを見ると、チャットテンプレート周りで修正が入ってGGUFが一度更新されたりしているみたい。
ドキュメントはこちら
Unslothによると推奨設定は以下らしい。
temperature=0.6top_p=1.0top_k=0- 最小コンテキストサイズの推奨は 16,384
- 最大コンテキストサイズは 131,072
あと、多少チャットテンプレートに違いはある。
では起動。こちらはCLIで。
./build/bin/llama-cli \
-hf unsloth/gpt-oss-20b-GGUF:F16 \
--jinja \
-ngl 99 \
--threads -1 \
--ctx-size 16384 \
--temp 0.6 \
--top-p 1.0 \
--top-k 0 \
-sys "You are ChatGPT, a large language model trained by OpenAI.\nKnowledge cutoff: 2024-06\nCurrent date: 2025-08-05\n\nReasoning: medium\n\n# Valid channels: analysis, commentary, final. Channel must be included for every message."
> 競馬の魅力について5つ、詳細にリストアップして。
<|channel|>analysis<|message|>The user wants "競馬の魅力について5つ、詳細にリストアップして。". They want 5 items, each with details, about the appeal of horse racing (in Japanese). So we need to respond in Japanese, with a list of 5 points, each detailed. We need to ensure the answer is detailed. We should cover aspects like excitement, betting, culture, horse training, etc. We'll produce a numbered list with headings and explanation. Let's do it.<|start|>assistant<|channel|>final<|message|>## 競馬の魅力を5つ、詳細にご紹介
| # | 魅力 | 詳細 |
|---|------|------|
| 1 | **スピードとドラマの「瞬間決定」** | 競馬はスタートからゴールまで約1〜2分で完結するため、観客はほぼリアルタイムで結果を味わえます。レース途中での追い抜き、逆転、レース終盤のスプリントなど、予測不可能な展開が連続し、まるで映画のクライマックスのような緊迫感があります。さらに、競走馬は時速30〜35kmで走るため、目に見える速度感が観客を圧倒します。 |
| 2 | **多様な戦略と“知識”の深さ** | 単に速さだけでなく、レースコースの形状(ダート・芝・メイツ)、天候・馬場状態、馬の性格・体調、騎手の戦術など、数百の要因がレース結果に影響します。これらを分析し、的確に予想するためには統計学、遺伝学、動物学、心理学などの知識が必要です。競馬ファンはこうした複合情報を組み合わせて予想を立てる楽しみを味わいます。 |
| 3 | **“賭け”というエンターテインメント性** | 競馬は賭けが主要な収益源です。単勝・複勝・枠連・三連単など、多彩なベッティングオプションが用意され、リスクとリターンを自分で調整できます。ギャンブルとしてのスリルはもちろん、的中したときの達成感や、相場との戦いで勝ったときの喜びは他のスポーツでは味わえない独自の感情を生み出します。 |
| 4 | **馬と人の“絆”と“情熱”** | 競馬は馬と騎手、トレーナー、調教師、馬主など多くの人々が協力して作り上げる産業です。馬の成長やトレーニング過程、騎手の技術向上、馬主の投資判断など、背後にあるドラマがファンを引き込みます。特に、馬の誕生からレースまでのストーリーを追うことで、単なる競技以上の感動を得られます。 |
| 5 | **文化・歴史・社会的価値** | 日本の競馬は大正時代から続く長い歴史があり、年金や地方自治体の財源に大きく貢献しています。また、競馬場は「レース場」としての祭典空間だけでなく、ファッションショー、食文化、音楽イベントなど多様な文化イベントを開催。競馬は国民のリフレッシュタイムとして、季節ごとの祭り感覚を提供します。 |
---
### まとめ
競馬は「速さ」「戦略」「賭け」「絆」「文化」という五つの要素が組み合わさって、観客に多層的な体験を提供します。これらの魅力が、競馬が長年にわたって多くの人々に愛され続ける理由です。ぜひ、レース観戦や予想を通じて、これらの要素を実感してみてください。
llama_perf_sampler_print: sampling time = 224.34 ms / 962 runs ( 0.23 ms per token, 4288.13 tokens per second)
llama_perf_context_print: load time = 7998.03 ms
llama_perf_context_print: prompt eval time = 343.34 ms / 150 tokens ( 2.29 ms per token, 436.89 tokens per second)
llama_perf_context_print: eval time = 5944.69 ms / 939 runs ( 6.33 ms per token, 157.96 tokens per second)
llama_perf_context_print: total time = 169093.48 ms / 1089 tokens
llama_perf_context_print: graphs reused = 908
公式のドキュメントもざっと見ておく。
OpenAI のオープンモデル
あらゆるユースケースに合わせてカスタマイズでき、どこでも実行可能な高度なオープンウェイト推論モデル。
-
gpt-oss-120b
- データセンターやハイエンドのデスクトップ/ノート PC で動作するよう設計された大規模オープンモデル
-
gpt-oss-20b
- ほとんどのデスクトップやノート PC で動作可能な中規模オープンモデル。
以下より利用可能
特徴
-
寛容なライセンス
- Apache 2.0 ライセンスで提供。
- 実験・カスタマイズ・商用展開、いずれの場合でもコピーレフトの制約や特許リスクを気にせず自由に構築可能
-
エージェント的なタスク向けに設計
- Web検索や Python 実行を含む、chain-of-thoght内での強力な指示追従とツール使用を活用可能
-
高度なカスタマイズ性
- Reasoningの負荷を低・中・高に調整可能。
- 全パラメータのファインチューニングによりユースケースへ適応可能。
-
フル chain-of-thought
- 完全なchain-of-thoughtにアクセス可能
- デバッグが容易で、モデル出力への信頼性を高める
モデル性能
Reasoning & knowledge
ベンチマーク gpt-oss-120b gpt-oss-20b OpenAI o3 OpenAI o4-mini MMLU 90.0 85.3 93.4 93.0 GPQA Diamond 80.1 71.5 83.3 81.4 Humanity’s Last Exam 19.0 17.3 24.9 17.7 Competition math
ベンチマーク gpt-oss-120b gpt-oss-20b OpenAI o3 OpenAI o4-mini AIME 2024 96.6 96.0 95.2 98.7 AIME 2025 97.9 98.7 98.4 99.5
詳細は https://openai.com/index/introducing-gpt-oss/
その他リソース
まとめ
Xを見ていると、英語の性能は高いが、日本語だと知識がちょっと足りなかったりするみたい。でも上のような感じであれば、普通に使えるかな。
Cookbookもいろいろ用意されていて、ファインチューニングの手順なども公開されているも良い。
個人的にはHarmonyちょっと気になるので、後で調べる。
120Bも動かせなくはないのか
うみゆきさんのgpt-ossに関する記事で、llama.cppのMoE固有のパラメータをいろいろ詰めて120Bを動かしている例がある。今後MoEを動かす場合にもとても参考になる。
精度についてはこちらも参考になる
このPRは、チャットテンプレートを修正するのではなくて、コード側で修正するのが良い、ということでマージされずにクローズされてる。
で、これがそのPRかな?上のPRに関してメンションされてないのでわからないけども。
某所で、最初のPRで試してみたらベンチマーク上がった、というのを見かけたので、これがマージされればまた使いやすくなるのでは。
そういえば、リリース直後にColabでやってみたのだけど、ライブラリ間の依存関係を上手く解決できなくて諦めたんだけど、Colabでも動くノートブックが公開されたみたい。
vLLMでもやってみた
mkdir gpt-oss-vllm && cd $_
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
で、普通に起動すると
vllm serve openai/gpt-oss-20b
こういうエラーが出る。
(snip)
(EngineCore_0 pid=1436464) ERROR 09-09 10:34:25 [core.py:718] AssertionError: Sinks are only supported in FlashAttention 3
(snip)
FlashAttention 3 は NVIDIA Hopper以降のGPUじゃないと使えないらしい。RTX4090は非対応。
ペパボさんの記事によると、
さらに、A100およびL4環境では前世代のアーキテクチャでの起動をサポートするためTRITON_ATTN_VLLM_V1をattention backendとして指定しました。
をつければ良いらしい。あと以下のオプションも付与されていた。
起動オプションについては、公式レシピに従い --async-schedulingを付与しました。
vLLM公式のgpt-oss向けガイドがあるのね
ちなみにA100のようなAmepereデバイスだと TRITON_ATTN がもうデフォルトで設定されるとあるんだけど、指定しないと起動しなかった。
起動
VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 vllm serve openai/gpt-oss-20b --async-scheduling
(snip)
(APIServer pid=1453355) INFO 09-09 11:21:46 [api_server.py:1857] Starting vLLM API server 0 on http://0.0.0.0:8000
(snip)
(APIServer pid=1453355) INFO: Started server process [1453355]
(APIServer pid=1453355) INFO: Waiting for application startup.
(APIServer pid=1453355) INFO: Application startup complete.
curl http://<サーバのIPアドレス>:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-20b",
"messages": [
{
"role": "developer",
"content": "あなたは親切な日本語のアシスタントです。"
},
{
"role": "user",
"content": "競馬の魅力について5つリストアップして"
}
]
}' | jq -r .choices[0].message.content
競馬の魅力を5つにまとめました。
1. **スピードとパワーの迫力**
里馬が30‑40マイル/時間(約48‑64km/h)で走る姿は、観客を圧倒します。スタート直後のエネルギッシュな踏み出しから、終盤のギリギリまでの一瞬一瞬が目が離せません。
2. **予想の楽しみと知識の深化**
コース形態・天候・馬の健康・騎手など多角的に情報を集め、独自の予想を立てる作業は頭脳ゲーム。正解に近づくたびに“知識が増えた”という満足感が得られます。
3. **騎手と馬のヒューマンドラマ**
騎手は体重や姿勢で馬に影響を与え、長いキャリアと友情を育む仲間です。勝利の喜びや敗北の悔しさ、トレーニングの裏側を知ることで、競馬は単なるギャンブルを超える物語になります。
4. **社交と文化の場**
競馬はファッション・食事・酒席など付き合いの場としても定着。テレビで情報を共有し、スタンドでは“競馬語”が飛び交う中、仲間の輪が広がります。
5. **大きな報酬と夢の実現**
大レースでは大きな賞金が頭を切りますが、夢を追い続ける小さな馬主や走者にとっては「1頭で生まれ変わるチャンス」でもあります。成功すれば人生そのものが変わるほどの強烈な魅力です。
これらが競馬が多くの人々に愛され続ける理由です。
んー、Reasoningは出力されない?OpenAI SDKでやってみた。
from openai import OpenAI
import json
client = OpenAI(
base_url="http://<サーバのIPアドレス>:8000/v1",
api_key="EMPTY"
)
def main():
result = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[
{"role": "system", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "競馬の魅力について5つリストアップして。"}
]
)
print(json.dumps(result.model_dump(), indent=2, ensure_ascii=False))
if __name__ == "__main__":
main()
{
"id": "chatcmpl-c593cd677f31427c81ebd56435d0f747",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "1. **スピードとドラマの追体験** \n 速さとタイムの競い合いはまるで映画のようなサスペンスを生み出し、衝撃と興奮が瞬間的に広がります。 \n\n2. **多彩なレース形態と戦略** \n 競走距離、馬場状態、騎手の戦術など、同じ馬でも条件が変わると結果も変動。予想の幅が広く、戦略性が楽しめます。 \n\n3. **馬の個性と美しさ** \n 各馬には独自の走り方や個性があり、迫力のある走りや優雅な姿を間近で見ることで、動物としての魅力を再発見。 \n\n4. **歴史と伝統の重み** \n 古代ギリシャから続く競走文化は、日本ではフジテレビや各地の競馬場での長い歴史があります。祭りのような雰囲気を味わえます。 \n\n5. **仲間との共有とコミュニティ体験** \n 観客席やパルクラ、ネットでの情報交換で同じレースを応援する仲間ができ、友情や連帯感が生まれます。 \n\nこれらの要素が重なり合うことで、競馬は多くの人に忘れられないエンターテインメントとして愛されています。",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning_content": "The user wants \"競馬の魅力について5つリストアップして\". They want 5 points. Must be in Japanese. So give 5 items. Provide concise list, maybe bullet points or numbered. Probably numbered 1-5. Should be Japanese. Let's craft."
},
"stop_reason": null
}
],
"created": 1757386911,
"model": "openai/gpt-oss-20b",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 409,
"prompt_tokens": 102,
"total_tokens": 511,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"kv_transfer_params": null
}
なるほど、別々に出力されるのね。
llama.cppでもOpenAI SDKでやってみた。
{
"id": "chatcmpl-4rc7mZz3ohh6oMdXVxBITTiTZBYu4srL",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "<|channel|>analysis<|message|>The user wants: \"競馬の魅力について5つリストアップして。\" i.e., \"List 5 attractions/appeal of horse racing\" in Japanese. They want a list. So respond in Japanese, list 5 points. Should be brief but informative. Provide 5 bullets. Let's produce.<|end|>競馬の魅力を5つ挙げると、以下のようになります。\n\n1. **スピードと迫力** \n 1,600メートルの短距離から3,200メートル以上の長距離まで、走るたびに全力で駆け抜ける馬たちの速度と力強さは観客を圧倒します。\n\n2. **戦略性と知識の奥深さ** \n 馬の血統・調子・コース適性・騎手のテクニックなど、数多くの要素が勝敗に直結します。予想やレース展開を読む楽しみが大きいです。\n\n3. **社会的イベントとしての一体感** \n 競馬場やテレビ・オンラインでの観戦は、ファン同士が盛り上がる社交的空間。ファッションやグルメ、イベントも充実しています。\n\n4. **経済的側面と投資感覚** \n 賭け金が小さくても大きなリターンが期待でき、また馬券以外にもオッズやレース結果を活かした投資・ビジネスチャンスがあります。\n\n5. **文化・歴史の継承** \n 競馬は古くから日本の文化に根付いており、レースの名前や馬の歴史、スタジアムの伝統といった要素がファンの情熱を呼び覚まします。",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1757387144,
"model": "openai/gpt-oss-20b",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": "b6396-fd621880",
"usage": {
"completion_tokens": 420,
"prompt_tokens": 101,
"total_tokens": 521,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"timings": {
"prompt_n": 101,
"prompt_ms": 87.84,
"prompt_per_token_ms": 0.8697029702970297,
"prompt_per_second": 1149.8178506375227,
"predicted_n": 420,
"predicted_ms": 2234.528,
"predicted_per_token_ms": 5.320304761904762,
"predicted_per_second": 187.9591573701471
}
}
llama.cppだと出力が同じになるのか。チャットテンプレートで解決するものなのかな?