Portkey-AIの「AI Gateway」を試す
GitHubレポジトリ
日本語のREADME
英語のREADMEは、日本語READMEとは内容が違うようなので、そちらを翻訳(o4-miniを使用)
AI Gateway
1つの高速かつ親しみやすいAPIで250以上のLLMへルーティング
AI Gateway は、高速、信頼性、安全性を兼ね備えた1600以上の言語、ビジョン、オーディオ、画像モデルへのルーティングを目的としています。軽量でオープンソース、エンタープライズ対応のソリューションで、2分以内にどの言語モデルとも統合可能です。
- 爆速(<1ms レイテンシ)かつ小さなフットプリント(122kb)
- 実戦投入済み、毎日100億トークン以上を処理
- エンタープライズ対応、強化されたセキュリティ、スケール、カスタム展開
AI Gatewayでできること
- 2分以内に任意のLLMと統合 — Quickstart
- 自動リトライ と フォールバック でダウンタイムを回避
- ロードバランシング と 条件付きルーティング でAIアプリをスケール
- ガードレール でAIデプロイを保護
- マルチモーダル機能 でテキストを超えた体験を
- 最後に エージェントワークフロー 統合を探究
コア機能
信頼性の高いルーティング
- フォールバック: 失敗したリクエスト時に別のプロバイダやモデルへフォールバックします。アプリケーションの信頼性を向上。
- 自動リトライ: 最大5回まで失敗リクエストを自動で再試行。指数バックオフ戦略でネットワーク過負荷を防止。
- ロードバランシング: 複数のAPIキーやAIプロバイダ間でウェイトを設定し、リクエストを分散。高可用性と最適パフォーマンスを実現。
- リクエストタイムアウト: 指定時間を超えたリクエストを自動で終了。LLMの遅延や異常動作を制御。
- マルチモーダル LLM ゲートウェイ: 言語だけでなく、ビジョン、オーディオ(音声合成・音声認識)、画像生成モデルも同一のOpenAI互換インターフェースで呼び出し可能。
- リアルタイム API: OpenAIのWebSocketサーバーを統合し、リアルタイムAPIを呼び出し。
セキュリティと正確性
- ガードレール: 入出力を指定チェックに従わせるプリビルト40種以上のルール。独自ルールやパートナールールも利用可。
- セキュアキー管理: 自身のキーを使用、または仮想キーを動的に生成。
- ロールベースアクセス制御: ユーザー、ワークスペース、APIキー単位で細かな権限設定。
- コンプライアンス & データプライバシー: SOC2、HIPAA、GDPR、CCPA対応。
コスト管理
- スマートキャッシング: LLM応答をキャッシュし、コスト削減・レイテンシ改善。シンプルキャッシュとセマンティックキャッシュ*をサポート。
- 使用状況分析: リクエスト数、レイテンシ、コスト、エラー率などをモニタリング。
- プロバイダ最適化*: 利用パターンと価格モデルに応じてコスト効率の高いプロバイダへ自動切り替え。
コラボレーションとワークフロー
- エージェントサポート: Autogen、CrewAI、LangChain、LlamaIndex、Phidata、Control Flow、Custom Agents等のフレームワークとシームレス統合。
- プロンプトテンプレート管理*: ユニバーサルなプロンプト環境でテンプレートの作成・管理・バージョン管理が可能。
対応プロバイダ
プロバイダ 対応 ストリーミング OpenAI ✅ ✅ Azure OpenAI ✅ ✅ Anyscale ✅ ✅ Google Gemini ✅ ✅ Anthropic ✅ ✅ Cohere ✅ ✅ Together AI ✅ ✅ Perplexity ✅ ✅ Mistral ✅ ✅ Nomic ✅ ✅ AI21 ✅ ✅ Stability AI ✅ ✅ DeepInfra ✅ ✅ Ollama ✅ ✅ Novita AI ✅ ✅ エージェント
フレームワーク 200以上のLLM呼び出し 高度ルーティング キャッシュ ロギング・トレース* オブザーバビリティ* プロンプト管理* Autogen ✅ ✅ ✅ ✅ ✅ ✅ CrewAI ✅ ✅ ✅ ✅ ✅ ✅ LangChain ✅ ✅ ✅ ✅ ✅ ✅ Phidata ✅ ✅ ✅ ✅ ✅ ✅ Llama Index ✅ ✅ ✅ ✅ ✅ ✅ Control Flow ✅ ✅ ✅ ✅ ✅ ✅ Build Your Own Agents ✅ ✅ ✅ ✅ ✅ ✅ Gatewayエンタープライズバージョン
✅ セキュアキー管理 — ロールベースアクセス制御とトラッキング
✅ シンプル&セマンティックキャッシュ — 繰返しクエリを高速応答&コスト削減
✅ アクセス制御&インバウンドルール — 接続許可IP/地域の制御
✅ PIIマスキング — リクエストから機微情報を自動除去
✅ SOC2、ISO、HIPAA、GDPR対応 — 最適なセキュリティ基準
✅ プロフェッショナルサポート — 機能優先度対応付き
雰囲気的にはLiteLLMに近いイメージを持っているけど、違いはなんだろうか?
公式ドキュメント
セルフホストもできるけど、クラウド版もある
クラウド版の料金はこちら。制限はあるが無料版もある。とりあえずセルフホストとの違いも見てみたいので、登録しておく。
インストール
インストール方法は色々ある
- マネージド
- portkeyのクラウド
- セルフホスト
- ローカル
- Node(
npx) / Bun(bunx)でシングルコマンドでサーバ起動 - レポジトリクローンして、Node.jsサーバを起動
- Docker/Docker Compose
- Node(
- 他のクラウドサービスでインテグレーション
- Raplit
- Zeabur
- Supabase Functions
- Fastly
- ローカル
今回はQuickstartに従って、npxを使うことにする。別途クラウドも試したい。
作業ディレクトリ作成
mkdir portkey-ai-gateway-work && cd $_
自分はNodeの場合はmiseを使っているので、これで環境を作成。
mise use node@22
npxで起動
npx @portkey-ai/gateway
yで進める
Need to install the following packages:
@portkey-ai/gateway@1.10.0
Ok to proceed? (y)
以下のように表示されればOK
🚀 Your AI Gateway is running at:
http://localhost:8787
📱 UI: http://localhost:8787/public/
✨ Ready for connections!
AI Gatewayを使用したリクエスト
AI Gatewayが起動すると以下のエンドポイントが待ち受け状態になる。
-
http://localhost:8787/v1: OpenAI互換APIエンドポイント -
http://localhost:8787/public: ゲートウェイのコンソール
ゲートウェイコンソールは以下のような感じ。

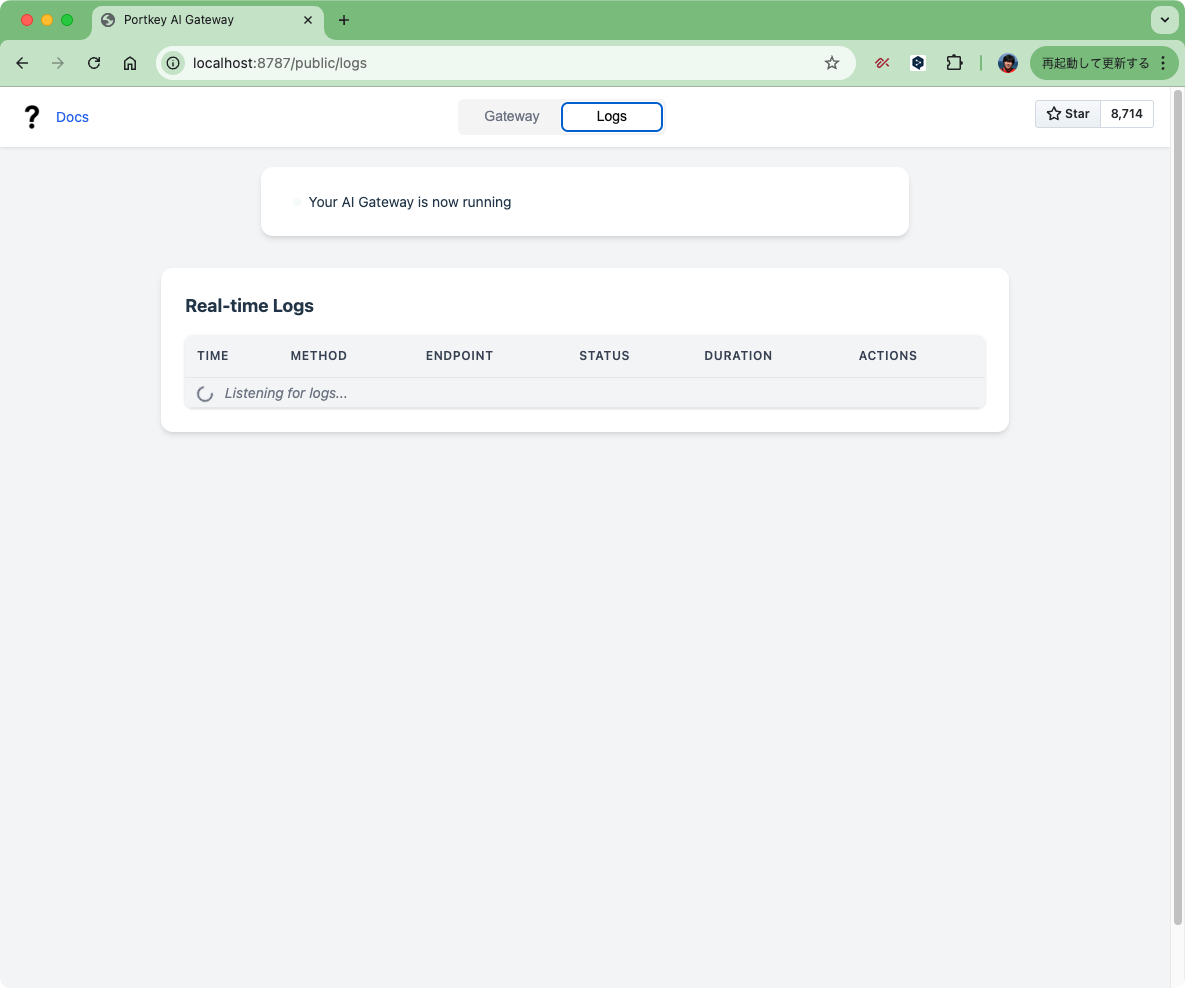
ゲートウェイへのアクセス方法が書いてあるページと、リアルタイムでログが確認できるページ、という感じ。
上記のアクセス方法のページで直接プロバイダとAPIキーを入力してテストもできるのだけど、手元からcurlで叩いてみる。OpenAIとGemini、それぞれで。
OpenAI
export OPENAI_API_KEY=XXXXX
curl -X POST \
http://localhost:8787/v1/chat/completions \
-H "Content-Type: application/json" \
-H "x-portkey-provider: openai" \
-H "Authorization: $OPENAI_API_KEY" \
-d '{
"messages": [
{ "role": "user", "content": "こんにちは!" }
],
"model": "gpt-4o-mini"
}' | jq -r .
{
"id": "chatcmpl-BoWPneYBCEoydQo9wI5hjRzqpMEe9",
"object": "chat.completion",
"created": 1751380703,
"model": "gpt-4o-mini-2024-07-18",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "こんにちは!どういったことをお手伝いできますか?",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 14,
"total_tokens": 23,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default",
"system_fingerprint": "fp_34a54ae93c"
}
Anthropic。こちらはmax_tokensを指定する必要がある。
export ANTHROPIC_API_KEY=XXXXX
curl -X POST \
http://localhost:8787/v1/chat/completions \
-H "Content-Type: application/json" \
-H "x-portkey-provider: anthropic" \
-H "Authorization: $ANTHROPIC_API_KEY" \
-d '{
"messages": [
{ "role": "user", "content": "こんにちは!" }
],
"model": "claude-3-5-sonnet-20240620",
"max_tokens": 1024
}' | jq -r .
{
"id": "msg_01SFh93yH9cTKFMs2e2ChhRL",
"object": "chat.completion",
"created": 1751380726,
"model": "claude-3-5-sonnet-20240620",
"provider": "anthropic",
"choices": [
{
"message": {
"role": "assistant",
"content": "こんにちは!お元気ですか?何かお手伝いできることはありますか?どんな話題でも構いませんので、お気軽にお話しください。"
},
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 13,
"completion_tokens": 53,
"total_tokens": 66
}
}
ログが確認できる。
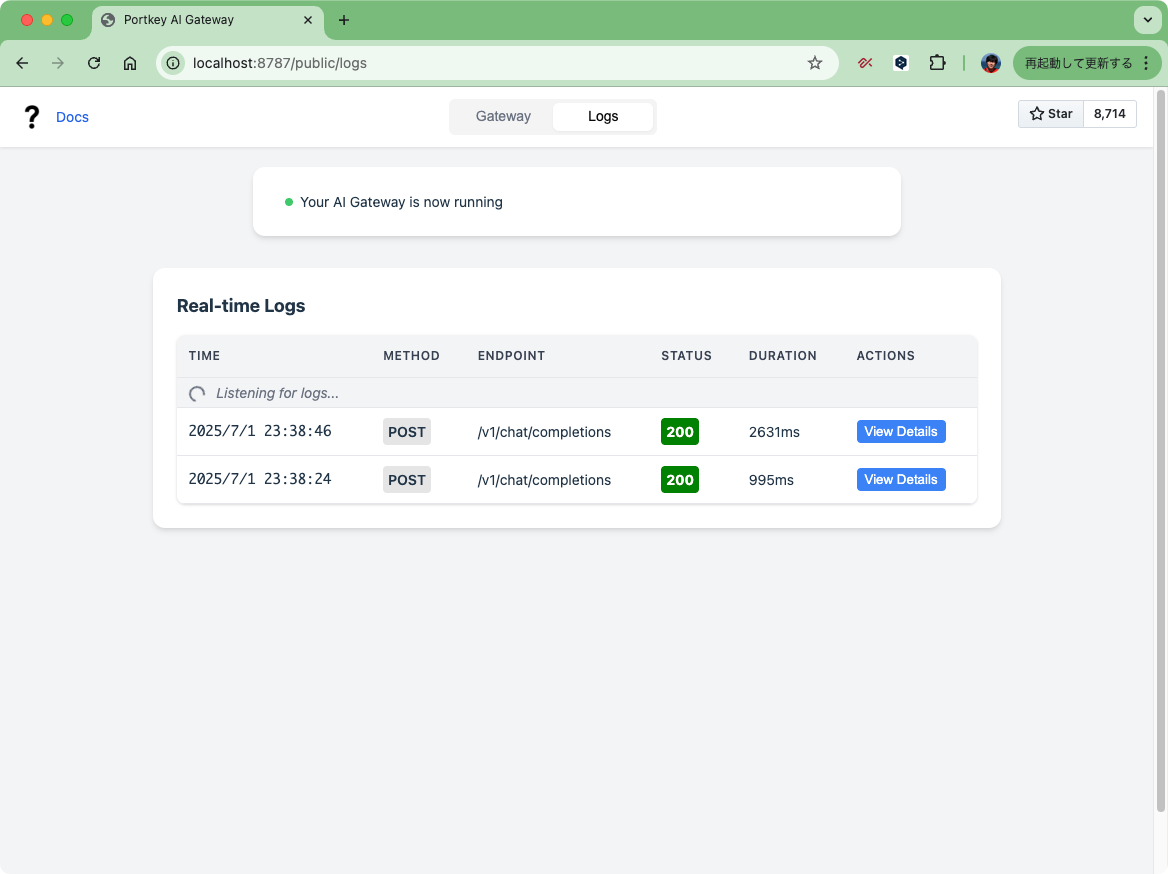
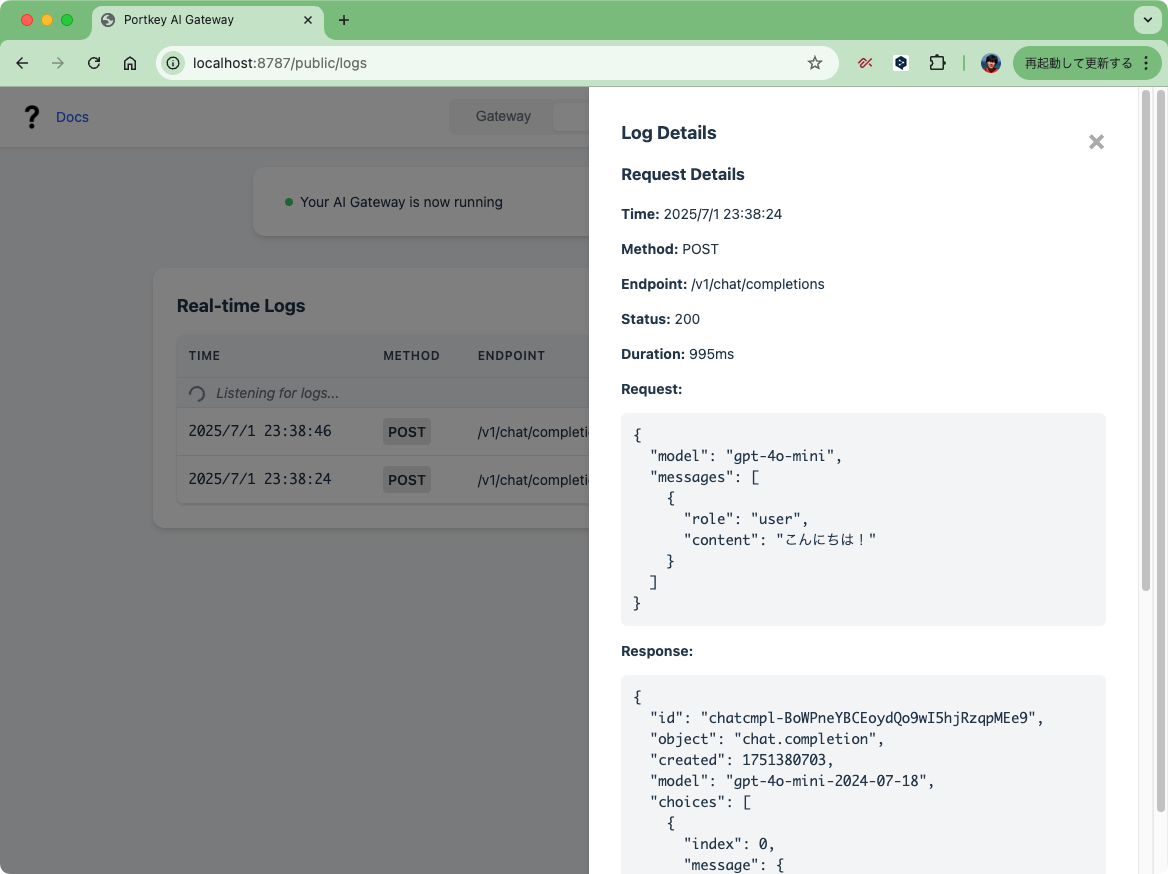
Pythonクライアントもある。
uvで仮想環境を作成
uv init -p 3.12.9 portkey-ai-gateway-python-work && cd $_
パッケージ追加
uv add portkey-ai
+ portkey-ai==1.14.0
こんな感じ。
from portkey_ai import Portkey
import os
client = Portkey(
provider="openai",
Authorization=os.environ["OPENAI_API_KEY"]
)
response = client.chat.completions.create(
messages=[
{"role": "user", "content": "こんにちは!"}
],
model="gpt-4o-mini"
)
print(response.choices[0].message.content)
uv run openai_client.py
こんにちは!何かお手伝いできることがあれば教えてください。
こちらもAnthropicでも。
from portkey_ai import Portkey
import os
client = Portkey(
provider="anthropic",
Authorization=os.environ["ANTHROPIC_API_KEY"]
)
response = client.chat.completions.create(
messages=[
{"role": "user", "content": "こんにちは!"}
],
max_tokens=1024,
model="claude-3-5-sonnet-20240620"
)
print(response.choices[0].message.content)
uv run anthropic_client.py
こんにちは!お元気ですか?何かお手伝いできることはありますか?ご質問やお話したいトピックがあれば、お気軽にお聞かせください。
ルーティングとガードレール
ここはREADMEどおりに書いてもうまく動かなかったので、ドキュメントを漁った。多分こんな感じで書く必要がある。
from portkey_ai import Portkey
import os
config = {
"retry": {
"attempts": 5,
"on_status_codes": [246, 446]
},
"output_guardrails": [{
"default.contains": {
"operator": "none",
"words": ["スーパークリーク", "イナリワン"]
},
"deny": True
}]
}
client = Portkey(
provider="openai",
Authorization=os.environ["OPENAI_API_KEY"],
config=config
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "オグリキャップ、スーパークリーク、イナリワン、のどれかをランダムに答えて。"
}
],
# OpenAI Dashboardで確認するために設定。AI Gatewayで必須ではない。
metadata={"test": "portkey_routing_test"}
)
print(response.choices[0].message.content)
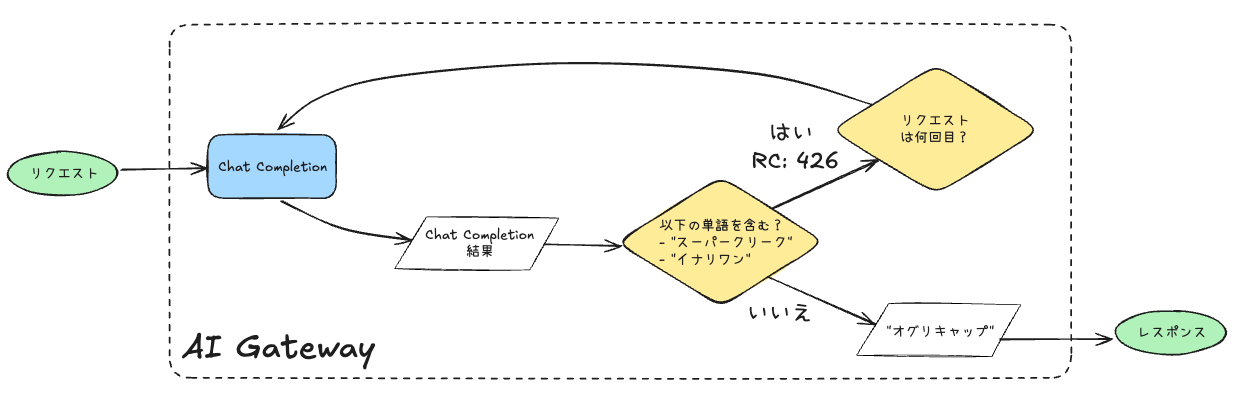
-
output_guardrailsで出力をチェック -
default.contains.wordsで チェックしたい単語をリストアップ。この単語が出力に含まれていれば"deny": Trueでクライアントへのレスポンスを拒否(このときのリターンコードは446) -
retry.on_status_codesでリトライを行うリターンコードを指定、retry.attemptsでリトライの最大回数を指定
という感じになる。図にするとこんな感じ。
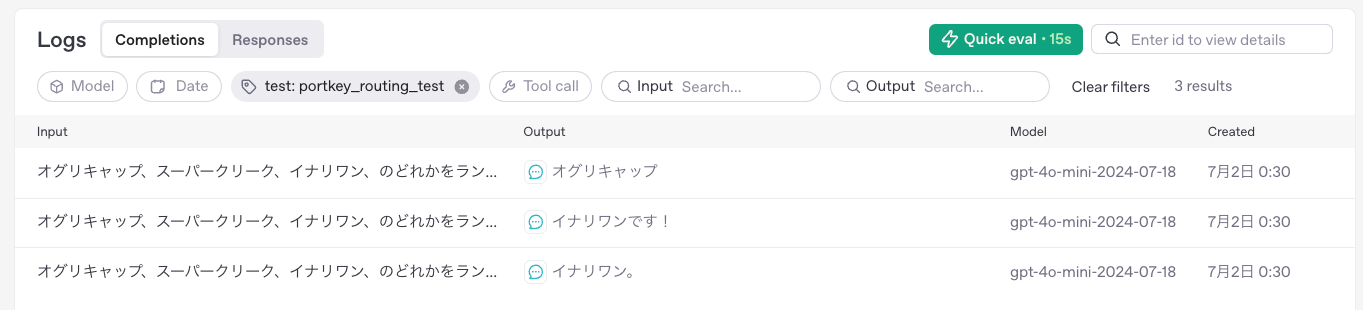
なので、何回実行しても結果は以下となる。
オグリキャップ
が、レスポンスの時間はまちまちで、レスポンスに時間がかかっている場合は裏でリトライされている。

ただ、portkeyのコンソールからその様子は確認できなかったので、使用するOpenAI APIキーのプロジェクトでログ有効にして、メタデータを付与して確認してみたところ、確かにリトライされていた。
Guardrailsについてはもっと詳細を確認する必要はある。以下を参考。
ここまでの所感
とりあえずLiteLLM/LiteLLM Proxyっぽい使い方はそれなりにできるかなというところ。ガードレール周りはもう少し調べてみたいのと、クラウドがどう違うのかは気になる。もう少し触ってみる。
クラウド
Portkeyのクラウドを使ってみる。アカウントを登録。
チーム名を入力、あとアンケート的なものだと思うけどPortkeyの用途なんかをチェックして、開始。

管理画面が表示される。真ん中にあるPortkeyのAPIキーをコピーする。
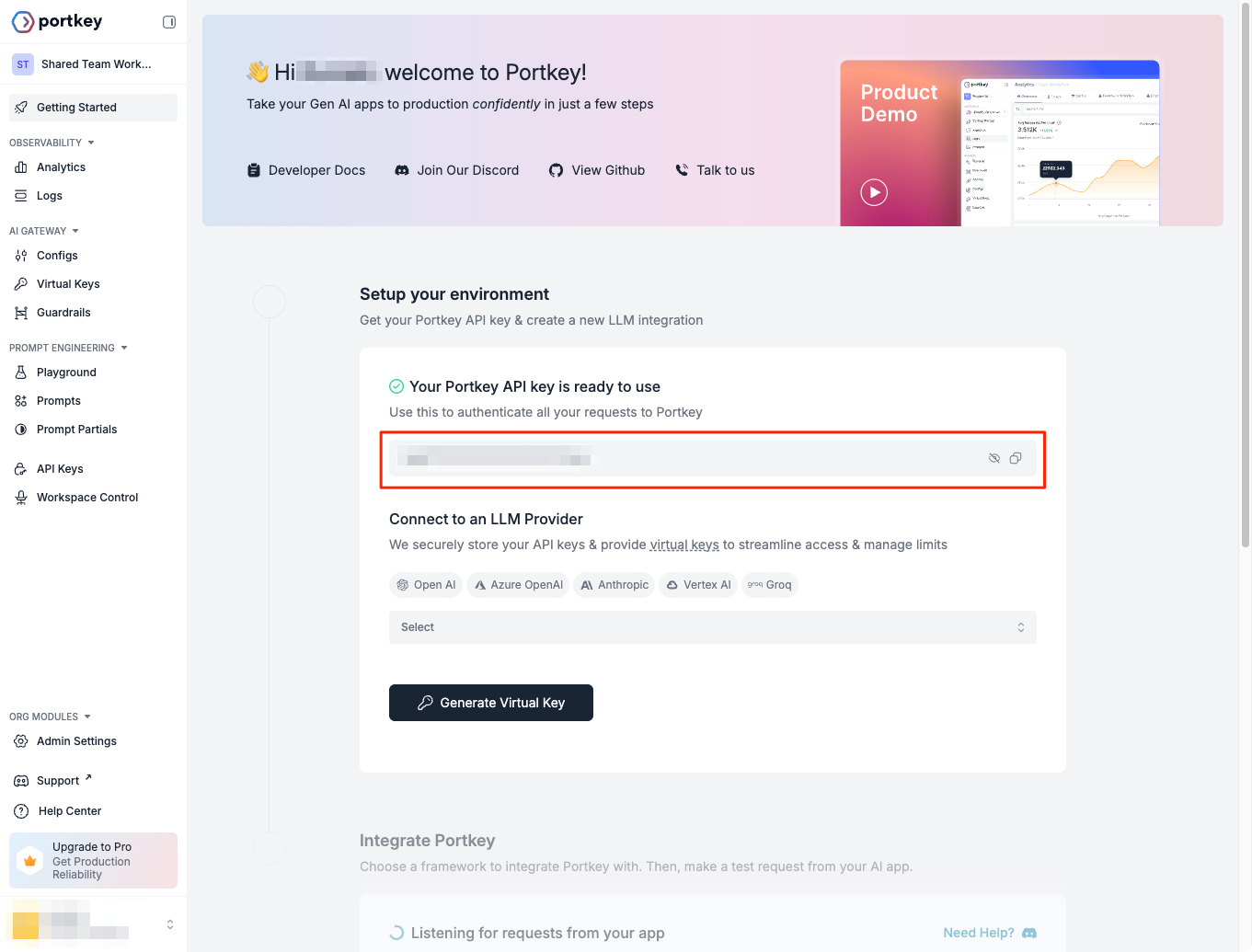
次にPortkeyにLLMプロバイダのAPIキーを登録する。今回はOpenAIを使うのでこんな感じ。入力したら"Generate Virtual Key"をクリック

これでPortkeyのAPIキーと、Portkey上に登録したLLMプロバイダのAPIキーが紐づいた「バーチャルキー」がされるのだと思う。実際にクライアントからアクセスする場合は、PortkeyのAPIキーとバーチャルキーの組み合わせで使うことになるみたい。

下に進むとサンプルコードが生成されている。サンプルコードはNode、Python、curlが用意されている。
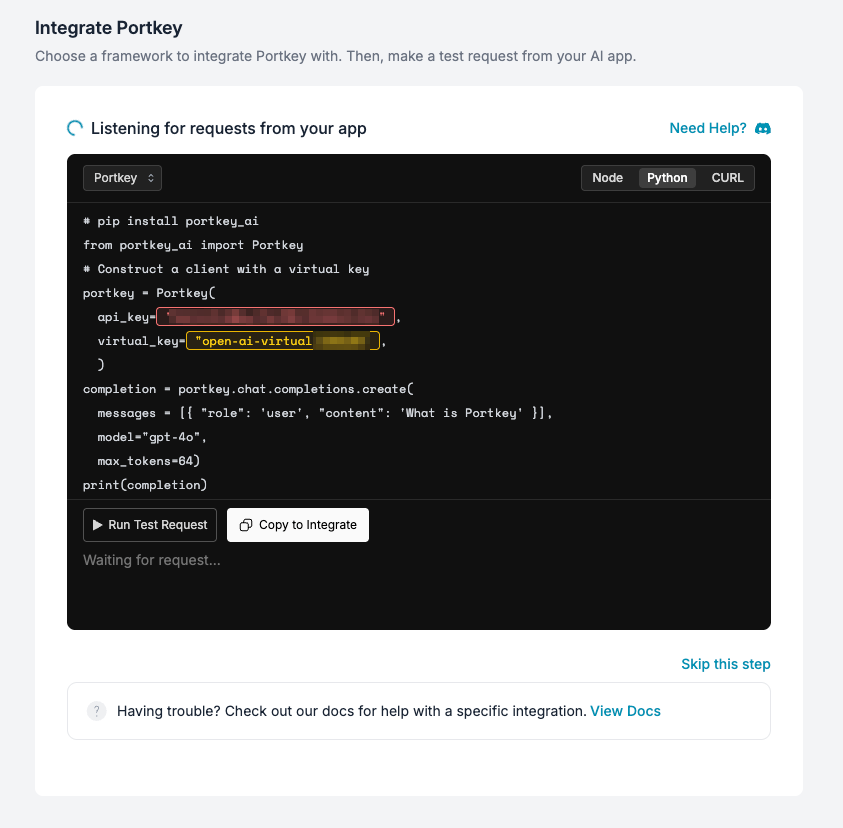
また、主要なSDK,フレームワークごとのサンプルコードも出力してくれる。

今回はOpenAI SDKを使うことにする。テストを実行してみる。

結果が出力された。

ではローカルでもやってみる。管理画面のサンプルコード、ちょっとだけ足りなかった。
pip install openai portkey-ai
+ openai==1.93.0
export PORTKEY_API_KEY=XXXXX
from openai import OpenAI
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
import os
client = OpenAI(
api_key="dummy", # バーチャルキーを使う場合は不要
base_url=PORTKEY_GATEWAY_URL, # 管理画面のサンプルコードではこれが足りない
default_headers=createHeaders(
api_key=os.environ["PORTKEY_API_KEY"],
virtual_key="open-ai-virtual-XXXXXX"
)
)
completion=client.chat.completions.create(
messages=[
{"role": "system", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "こんにちは!"}
],
model="gpt-4o-mini",
)
print(completion.choices[0].message.content)
uv run openai_native_client.py
こんにちは!今日はどんなことをお手伝いしましょうか?
管理画面でログを見てみると2行ログがある。下の方は管理画面上でテストしたもの。上の方がローカルから実行したもの。

ログの中味はこんな感じ。

また、統計的なデータも見れる。

ここからはどういうことができるのかを、気になったものだけ色々見ていく。公式ドキュメントの主にこの辺。
順不同で。全部は試さないかも。
AI Gateway
Portkeyのおそらくキモであろう、AI Gatewayの機能について。ざっくりこんな感じの機能がある様子。
- Universal API: 複数のモダリティ・複数のモデルを1つのOpenAI互換APIで利用可能
- キャッシュ: レスポンスをキャッシュして高速化。シンプルな文字列一致型キャッシュとセマンティックな類似性キャッシュ(こちらはEnterprise/Proプランのみ)がある。
- MCPサポート: リモートMCPサーバをツールとして使える。Responses APIのみ。
- フォールバック: メインのLLMプロバイダーが障害でアクセスできない場合に、別のLLMプロバイダーにアクセスする。
- 条件付きルーティング: メタデータやリクエストパラメータなどで条件判定して、異なるLLMプロバイダーに振り分ける。
- マルチモーダル: 画像認識・画像生成・Function Calling・Speech-to-Text・Text-to-Speechにも1つのAPIで対応。
- 自動リトライ: 任意のエラーコード等で、自動リトライ回数やexponential backoffを設定。
- サーキットブレーカー: 一定の障害率やエラー数などで該当のLLMプロバイダへのルーティングを自動停止。
- ロードバランシング: 複数LLMプロバイダ・モデル間でロードバランシング。
- Canaryテスト: リクエストを一定の割合でテスト用のプロバイダ・モデルなどにルーティング。
- リクエストタイムアウト: プロバイダ・モデルからのレイテンシーが一定の場合にゲートウェイ側でタイムアウトさせる。
- 予算上限: プロバイダやモデルごとに予算上限をセットしてアラートを送信(Enterprise/Proプランのみ)
- レートリミット: リクエスト数やトークン数ベースで、単位時間ごとのレートリミットを設定
とりあえずLLMプロキシとしては一通りの機能はある用に思える。
上記以外にも「バーチャルキー」みたいなLLMプロバイダのAPIキーをPortkey側で管理する機能があるのだけど、どうやらバーチャルキーはDeprecatedになるみたい・・・
その代わりに「モデルカタログ」というのにリプレイスされるみたい。
どうやら、組織の管理者、より小さな単位としてワークスペースの管理者・メンバー、みたいな感じで各ロールごとにAPIリクエスト権限を与える、的な感じになるっぽい。
ただ自分の管理画面を見る限りはモデルカタログは見当たらなくて、バーチャルキーが普通に存在してるので、まさにマイグレ中ってことなのかもね。
インテグレーションも非常に豊富で、数が非常に多いのでパス。
プロンプト管理もできる
- プロンプトテンププレートの作成とPlaygroundでの比較
- プロンプトのバージョン管理とデプロイ
- オブザーバビリティと連携
- プロンプトの共有
- 登録したプロンプトを指定しつつ、Chat Completionをラップした、プロンプトAPI
どうやらツールも同様のライブラリ管理を予定している様子
ガードレール
LLMへの入力と出力を検証して、不正な内容のリクエストを拒否したり、好ましくないレスポンスを返すことなくエラーにする、といったチェックができるのが「ガードレール」。
ガードレールは、すべてのプランで使えるが、プランごとに使えるガードレールに違いがある様子。
| プラン | BASICガードレール | PARTNERガードレール | PROガードレール | カスタムガードレール |
|---|---|---|---|---|
| Developer | ○ | ✘ | ✘ | ✘ |
| Production | ○ | ○ | ○ | ✘ |
| Enterprise | ○ | ○ | ○ | ○ |
管理画面だとこんな感じになっている。



なるほど、BASICは正規表現や文字列で特定の単語が含まれるか、単語数や文字数が一定条件か、JSONスキーマに・・・みたいな感じのテキスト中心のルールベースチェックが多くて、PARTNERはサードパーティのサービスと連携したもの、PROはPortkey独自のもの、って感じに見える。「カスタム」はまあテーラーメイドみたいな感じなんだろう。
ガードレールの一覧は(全部ではないが)以下にある。
一応WebhookみたいなものはBASICでも使えるようなので、ある程度のことはできそう。
基本的にはガードレールはこんな感じで処理される。

referred from https://portkey.ai/docs/product/guardrails and translated into Japanese by kun432
入力・出力のそれぞれのガードレールがかけられるのはまあそうだよね。で、よくわからないのがガードレールのチェックで引っかかった場合に条件判定があるところ。上の図はドキュメントのものを日本語に訳しただけなんだけど、原文では
- 「送信失敗」→"Send Failture"
- 「処理失敗」→"Send Failture"
となっていて、ここで条件分岐してエラーコードが変わったり制御フローが変わったりしている。この単語が何を指しているのか?
とりあえず一旦ガードレールを作成してみる。"Guardrails"メニューから"Create"
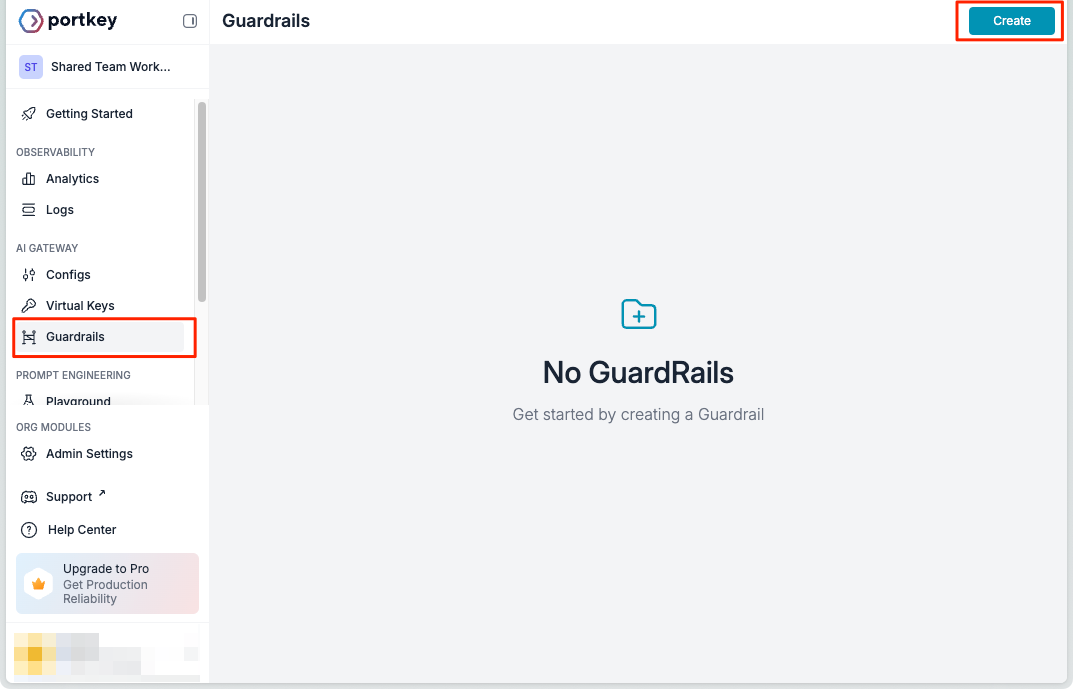
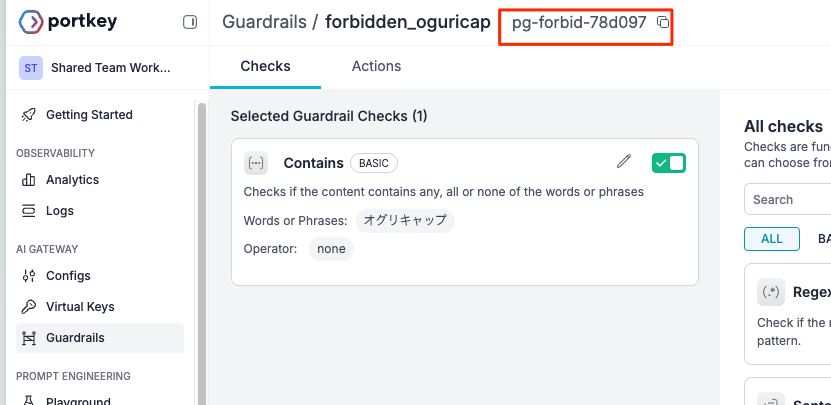
無料プランなので"Basic"で使えるものから。一番シンプルに使えそうな、指定した単語を含んでいるか?をチェックする"Contains"を選択。

ガードレールの設定は
- "Checks": ガードレールとして判定する条件
- "Actions": ガードレールに該当した場合の動作
の2ステップで行う。今回は、ここでは「オグリキャップ」という単語を含んでいる場合は拒否というガードレールを設定してみる。まず、"Checks"。
ここで「オグリキャップ」を単語として登録する。単語は複数登録することもできる。指定の仕方にはAny(どれかを含む)、All(全てを含む)None(すべて含まない)が選べる。ここ少し頭を捻る必要があって、条件は「合致する」→PASS、「合致しない」→FAILED、と判断されるので、今回のように「含んでいれば拒否」みたいな場合はNoneを選択する必要がある。(「含んでいない」→PASS、「含んでいる」→FAILED、になるため)

保存したら"Actions"の設定。
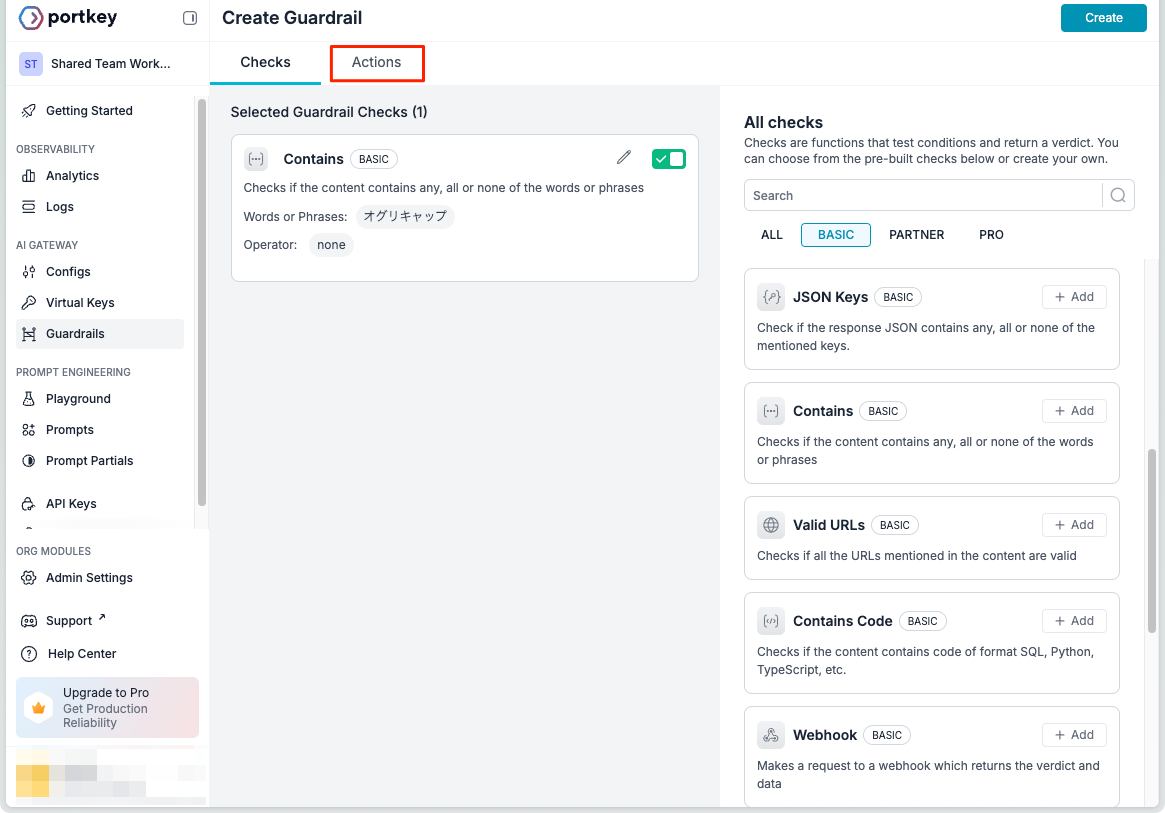
"Actions"では、
- ガードレールをPASS・FAILEDした場合にそれぞれスコアを付与するかどうか、どう加点・減点するか、等
- ガードレールを非同期に実行するか?(
Run this guardrail asynchronously)、ガードレール失敗時に拒否するか?(deny Deny the request if guardrail fails)
を設定できるが、挙動に関係するのは後者。設定では"Settings"内にチェックボックスになっているが、実際には、どちらか1つを選ぶか、どちらも選ばないか、となっている。今回は拒否するようにしてみた。

最後に名前をつけて保存
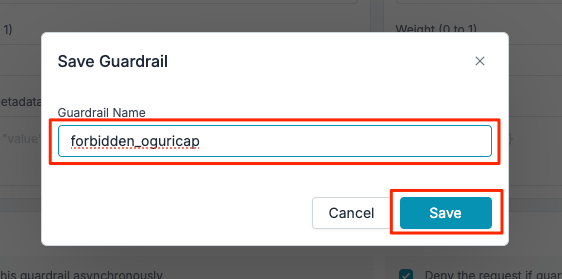
ガードレールが作成された。Portkeyクラウドを使う場合にはこのガードレールIDを指定して使うことになる様子。
では実際のコードから試してみる。
Quickstartでもやったけど、ガードレールの設定はconfigで行う。Portkey SDKを使っている。(OpenAI SDKの場合にはもうひと手間いる模様だが、割愛。)
from portkey_ai import Portkey
import os
config = {
# 入力ガードレール
"input_guardrails": ["pg-forbid-78d097"],
# 出力ガードレール
"output_guardrails": ["pg-forbid-78d097"],
}
client = Portkey(
api_key=os.environ["PORTKEY_API_KEY"],
virtual_key="open-ai-virtual-XXXXXXXX",
config=config,
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "オグリキャップについて教えて。",
}
],
)
print(response.choices[0].message.content)
実行
uv run portkey_cloud_guardrails.py
結果。ちょっと見やすさのため適宜改行を入れている。
openai.APIStatusError: Error code: 446 - {
'error': {
'message': 'The guardrail checks defined in the config failed. You can find more information in the `hook_results` object.',
'type': 'hooks_failed',
'param': None,
'code': None
},
'hook_results': {
'before_request_hooks': [
{
'verdict': False,
'id': 'pg-forbid-78d097',
'transformed': False,
'checks': [
{
'data': {
'explanation': "Check failed for 'none' words. Some words were found.",
'foundWords': ['オグリキャップ'],
'missingWords': [],
'operator': 'none'
},
'verdict': False,
'id': 'default.contains',
'execution_time': 0,
'transformed': False,
'created_at': '2025-07-06T08:35:59.641Z',
'log': None,
'fail_on_error': False
}
],
'feedback': {
'value': -5,
'weight': 1,
'metadata': {
'successfulChecks': '',
'failedChecks': 'default.contains',
'erroredChecks': ''
}
},
'execution_time': 0,
'async': False,
'type': 'guardrail',
'created_at': '2025-07-06T08:35:59.641Z',
'deny': True
}
],
'after_request_hooks': []
}
}
入力チェックに引っかかって446になっているのがわかる。またスコアリングもされている。Portkeyのクラウド側でも確認できる。


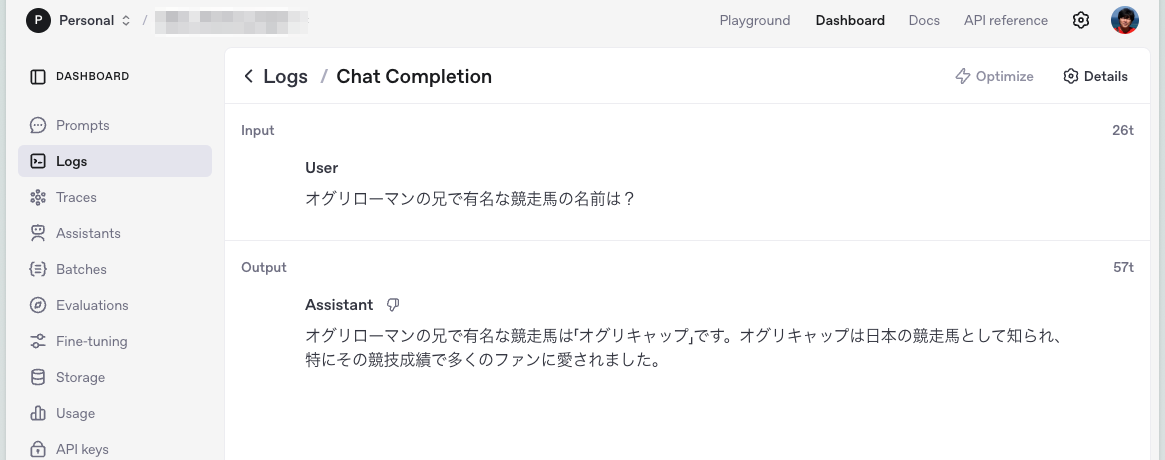
今度は出力チェックにかかるようにしてみる。
(snip)
messages=[
{
"role": "user",
"content": "オグリローマンの兄で有名な競走馬の名前は?",
}
],
(snip)
結果
openai.APIStatusError: Error code: 446 - {
'error': {
'message': 'The guardrail checks defined in the config failed. You can find more information in the `hook_results` object.',
'type': 'hooks_failed',
'param': None, 'code': None
},
'hook_results': {
'before_request_hooks': [
{
'verdict': True,
'id': 'pg-forbid-78d097',
'transformed': False,
'checks': [
{
'data': {
'explanation': "Check passed for 'none' words. No words were found.",
'foundWords': [],
'missingWords': ['オグリキャップ'],
'operator': 'none'
},
'verdict': True,
'id': 'default.contains',
'execution_time': 0,
'transformed': False,
'created_at': '2025-07-06T08:58:41.755Z',
'log': None,
'fail_on_error': False
}
],
'feedback': {
'value': 5,
'weight': 1,
'metadata': {
'successfulChecks': 'default.contains',
'failedChecks': '',
'erroredChecks': ''
}
},
'execution_time': 0,
'async': False,
'type': 'guardrail',
'created_at': '2025-07-06T08:58:41.755Z',
'deny': False
}
],
'after_request_hooks': [
{
'verdict': False,
'id': 'pg-forbid-78d097',
'transformed': False,
'checks': [
{
'data': {
'explanation': "Check failed for 'none' words. Some words were found.",
'foundWords': ['オグリキャップ'],
'missingWords': [],
'operator': 'none'
},
'verdict': False,
'id': 'default.contains',
'execution_time': 0,
'transformed': False,
'created_at': '2025-07-06T08:58:43.294Z',
'log': None,
'fail_on_error': False
}
],
'feedback': {
'value': -5,
'weight': 1,
'metadata': {
'successfulChecks': '',
'failedChecks': 'default.contains',
'erroredChecks': ''
}
},
'execution_time': 0,
'async': False,
'type': 'guardrail',
'created_at': '2025-07-06T08:58:43.294Z',
'deny': True
}
]
}
}
こちらも同じように446で返され、今回は出力側のガードレールでブロックされているのがわかる。
クラウドでも一応確認はできるのだけど、2回チェックが行われてて2回目でFAILEしているので、レスポンスでブロックされてるのはわかるのだが、実際にどういうレスポンスなのか?まではどうも確認ができなさそう。

OpenAI側でログを取るように設定していたので確認してみたらたしかに含まれていた。
そういえばこれ
基本的にはガードレールはこんな感じで処理される。
referred from https://portkey.ai/docs/product/guardrails and translated into Japanese by kun432入力・出力のそれぞれのガードレールがかけられるのはまあそうだよね。で、よくわからないのがガードレールのチェックで引っかかった場合に条件判定があるところ。上の図はドキュメントのものを日本語に訳しただけなんだけど、原文では
- 「送信失敗」→"Send Failture"
- 「処理失敗」→"Send Failture"
となっていて、ここで条件分岐してエラーコードが変わったり制御フローが変わったりしている。この単語が何を指しているのか?
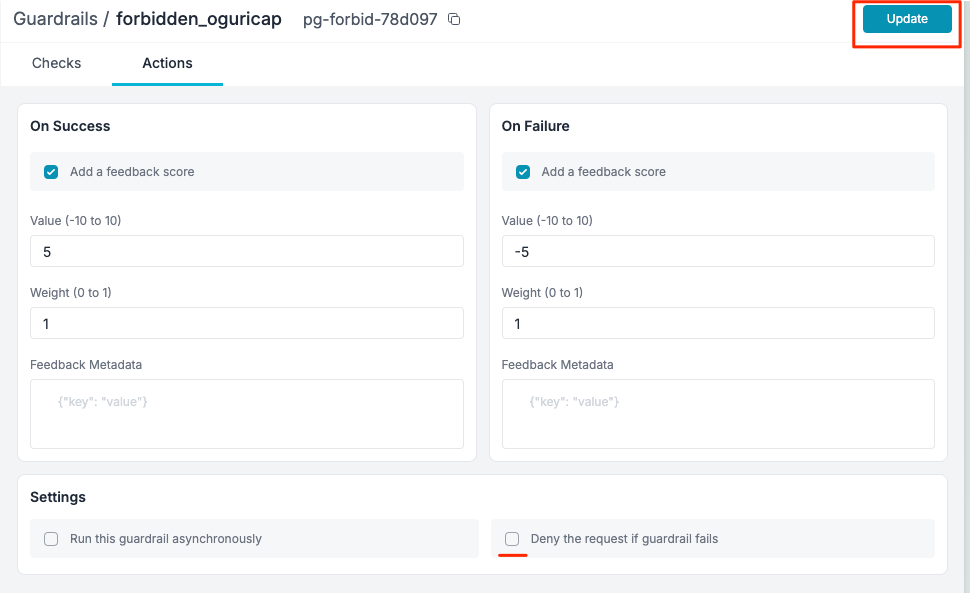
おそらくこれはここ

ここで"Deny"を有効にすると、基本的にはガードレールに引っかかったら446を返してリクエストは失敗する様子。
これを一旦外してみる。
再度リクエストしてみる。レスポンスを全部表示。
from portkey_ai import Portkey
import os
import json
config = {
"input_guardrails": ["pg-forbid-78d097"],
"output_guardrails": ["pg-forbid-78d097"],
}
client = Portkey(
api_key=os.environ["PORTKEY_API_KEY"],
virtual_key="open-ai-virtual-2d0a94",
config=config,
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "オグリキャップについて教えて。",
}
],
)
# レスポンスを全て表示
print(json.dumps(response.model_dump(), indent=2, ensure_ascii=False))
{
"id": "chatcmpl-BqH91nefAPUyAxldR9ZiwqacXq5Ad",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "オグリキャップは、日本の競走馬で、1980年代に活躍した名馬です。彼は1986年にデビューし、その後多くの重要なレースで優勝を果たしました。特に、1988年の有馬記念での勝利は非常に印象的で、多くの競馬ファンに記憶されています。\n\nオグリキャップの特徴としては、優れたスピードとスタミナを兼ね備えていたことが挙げられます。また、彼はその個性的な外見と、ファンとの強い絆でも知られています。オグリキャップは、引退後も競馬界での影響力を持ち続け、多くの人々に愛されました。\n\n彼の血統は、父が「スピリツトスワプス」、母が「オグリヒメ」で、特に父のスピリツトスワプスから受け継いだ能力が彼の成績にも表れています。\n\nオグリキャップの物語やスピリットは、競馬の文化の中で今でも語り継がれており、彼にまつわるエピソードは多くの人に感動を与えています。",
"role": "assistant",
"function_call": null,
"tool_calls": null,
"refusal": null,
"audio": null,
"annotations": []
}
}
],
"created": 1751798659,
"model": "gpt-4o-mini-2024-07-18",
"object": "chat.completion",
"system_fingerprint": "fp_34a54ae93c",
"usage": {
"prompt_tokens": 16,
"completion_tokens": 294,
"total_tokens": 310,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
},
"service_tier": "default",
"hook_results": {
"before_request_hooks": [
{
"verdict": false,
"id": "pg-forbid-78d097",
"transformed": false,
"checks": [
{
"data": {
"explanation": "Check failed for 'none' words. Some words were found.",
"foundWords": [
"オグリキャップ"
],
"missingWords": [],
"operator": "none"
},
"verdict": false,
"id": "default.contains",
"execution_time": 0,
"transformed": false,
"created_at": "2025-07-06T10:44:19.106Z",
"log": null,
"fail_on_error": false
}
],
"feedback": {
"value": -5,
"weight": 1,
"metadata": {
"successfulChecks": "",
"failedChecks": "default.contains",
"erroredChecks": ""
}
},
"execution_time": 0,
"async": false,
"type": "guardrail",
"created_at": "2025-07-06T10:44:19.106Z",
"deny": false
}
],
"after_request_hooks": [
{
"verdict": false,
"id": "pg-forbid-78d097",
"transformed": false,
"checks": [
{
"data": {
"explanation": "Check failed for 'none' words. Some words were found.",
"foundWords": [
"オグリキャップ"
],
"missingWords": [],
"operator": "none"
},
"verdict": false,
"id": "default.contains",
"execution_time": 0,
"transformed": false,
"created_at": "2025-07-06T10:44:23.968Z",
"log": null,
"fail_on_error": false
}
],
"feedback": {
"value": -5,
"weight": 1,
"metadata": {
"successfulChecks": "",
"failedChecks": "default.contains",
"erroredChecks": ""
}
},
"execution_time": 0,
"async": false,
"type": "guardrail",
"created_at": "2025-07-06T10:44:23.968Z",
"deny": false
}
]
}
}
チェック自体は入出力両方FAILしているが、Denyしてないので、そのままLLMに送られて回答が帰ってきているのがわかる。
ただ、このときのステータスコードがわからないな。。。
curlを使ってステータスコードを確認してみる。ただし、configで設定しているガードレールの設定はcurlではそのまま投げれない。この場合はクラウド側でconfigの設定を行って、クライアントからはそれを呼び出すということができる。なお、OpenAI SDKの場合もおそらくこれが必要になる様子。
クラウド側でConfigsメニューからコンフィグを新規作成

コンフィグ名とコンフィグの設定を入力

こんな感じで。デフォルトのものは消して、入出力チェックを追加した。これで保存。

コンフィグのIDが生成された。これでクライアント側にコンフィグを持たなくて済む。

ではcurlで。ヘッダも表示するようにしている。
curl -v https://api.portkey.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "x-portkey-api-key: $PORTKEY_API_KEY" \
-H "x-portkey-virtual-key: open-ai-virtual-2d0a94" \
-H "x-portkey-config: pc-forbid-56ab43" \
-d '{
"model": "gpt-4o-mini",
"messages": [{
"role": "user",
"content": "オグリキャップについて教えて。!"
}]
}'
レスポンスヘッダをみるとたしかに246が返ってきている
< HTTP/2 246
< date: Sun, 06 Jul 2025 10:55:56 GMT
< content-type: application/json
< content-length: 3467
(snip)
結果では入出力ともにFAILEDになっている。
{
"id":"chatcmpl-BqHKBAr4GsonW3eLDwu0aSOoCp7ci",
"object":"chat.completion",
"created":1751799351,
"model":"gpt-4o-mini-2024-07-18",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"content":"オグリキャップ(Oguri Cap)は、日本の競走馬で、特に1980年代後半から1990年代初頭にかけて活躍しました。彼はその独特の外見と走り方、そして数々の名勝負で競馬ファンから愛されました。\n\n### 基本情報\n- **生年**: 1983年\n- **馬主**: 佐々木竹見\n- **調教師**: 矢野照正\n- **主な戦績**: G1レースでの優勝を含む多くの勝ち星\n\n### 特徴\n1. **走り方**: オグリキャップは、時に力強い走りを見せる一方で、繊細な動きも持ち合わせていました。これがファンを魅了しました。\n2. **スタイル**: 毛色は栗毛で、印象的な姿勢と似たような名前を持つ伝説的な競走馬「シンボリルドルフ」ともライバル関係にありました。\n3. **人気**: 彼の競走生活は、多くのファンを魅了し、競馬界におけるアイコン的存在となっています。特に、彼の競走中の姿勢や表情は多くの締切りを記録しました。\n\n### 主な戦績\n- **有馬記念**: 1989年、1990年に優勝\n- **天皇賞(春)**: 1990年に優勝\n- **ジャパンカップ**: 1992年に優勝\n\nオグリキャップは、2000年に引退し、その後は種牡馬としても活動しましたが、2004年に亡くなりました。彼の名は日本競馬史に深く刻まれています。オグリキャップのストーリーは、競馬の魅力や感動を多くの人に伝えるものであり、今でも多くの競馬ファンに親しまれています。",
"refusal":null,
"annotations":[]
},
"logprobs":null,
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":17,
"completion_tokens":468,
"total_tokens":485,
"prompt_tokens_details":{
"cached_tokens":0,
"audio_tokens":0
},
"completion_tokens_details":{
"reasoning_tokens":0,
"audio_tokens":0,
"accepted_prediction_tokens":0,
"rejected_prediction_tokens":0
}
},
"service_tier":"default",
"system_fingerprint":"fp_34a54ae93c",
"hook_results":{
"before_request_hooks":[
{
"verdict":false,
"id":"pg-forbid-78d097",
"transformed":false,
"checks":[
{
"data":{
"explanation":"Check failed for 'none' words. Some words were found.",
"foundWords":["オグリキャップ"],
"missingWords":[],
"operator":"none"
},
"verdict":false,
"id":"default.contains",
"execution_time":0,
"transformed":false,
"created_at":"2025-07-06T10:55:51.363Z",
"log":null,
"fail_on_error":false
}
],
"feedback":{
"value":-5,
"weight":1,
"metadata":{
"successfulChecks":"",
"failedChecks":"default.contains",
"erroredChecks":""
}
},
"execution_time":0,
"async":false,
"type":"guardrail",
"created_at":"2025-07-06T10:55:51.363Z",
"deny":false
}
],
"after_request_hooks":[
{
"verdict":false,
"id":"pg-forbid-78d097",
"transformed":false,
"checks":[
{
"data":{
"explanation":"Check failed for 'none' words. Some words were found.",
"foundWords":["オグリキャップ"],
"missingWords":[],
"operator":"none"
},
"verdict":false,
"id":"default.contains",
"execution_time":0,
"transformed":false,
"created_at":"2025-07-06T10:55:56.316Z",
"log":null,
"fail_on_error":false
}
],
"feedback":{
"value":-5,
"weight":1,
"metadata":{
"successfulChecks":"",
"failedChecks":"default.contains",
"erroredChecks":""
}
},
"execution_time":0,
"async":false,
"type":"guardrail",
"created_at":"2025-07-06T10:55:56.316Z",
"deny":false
}
]
}
}
クラウドのログでも同じようにFAILEDしているが、LLMからの応答は得られている。
じゃあこの246は何に使うの?と思うのだけど、設定の組み合わせと挙動のパターンがある。
ガードレールのアクションには6種類ある
アクション名 状態 説明 インパクト Async TRUE(デフォルト) ガードレールのチェックをリクエストと同時に非同期で実行します。 リクエストの遅延は発生せず、チェック結果を記録するだけの場合に便利です。 Async FALSE リクエスト送信前(入力チェック)やレスポンス返却前(出力チェック)にガードレールを実行します。 リクエストに遅延が発生しますが、重要なチェックを厳密に行いたい場合に適しています。 Deny TRUE 入力または出力のいずれかでガードレールに失敗した場合、リクエストは「446」ステータスで中断されます。すべて成功した場合は「200」ステータスで処理されます。 クリティカルなチェックに失敗した場合、リクエストを完全に止めたいときに使います。まずは一部のリクエストで試すのが推奨されています。 Deny FALSE(デフォルト) ガードレールに失敗してもリクエストは処理されますが、「246」ステータスで「失敗した」ことが通知されます。すべて成功した場合は「200」ステータスです。 結果には影響を与えず、ログとしてチェック結果を残したい場合に便利です。 On Success Send Feedback すべてのガードレールチェックに成功した場合、カスタムフィードバックをリクエストに追加します。 チェックが成功したデータを蓄積し、評価用データセットを作成できます。 On Failure Send Feedback いずれかのガードレールチェックに失敗した場合、カスタムフィードバックをリクエストに追加します。 失敗時のデータも記録できるので、後から分析するのに役立ちます。
ゲートウェイ上でのガードレールの動作
非同期ガードレール(
async= TRUE)の場合、Portkey は LLM プロバイダーからの標準のデフォルトのステータスコードを返します。これは、ガードレールの判定がリクエストのオーケストレーションに影響を与えないためです。Portkey は、ガードレールの結果のみをログに記録します。ただし、同期リクエスト(
async= FALSE)の場合、Portkey はガードレールの判定に基づいてリクエストをオーケストレーションできます。この動作は、以下の条件に依存します:
- ガードレールチェックの判定(
PASSまたはFAIL)および- ガードレールアクション — DENY 設定(
TRUEまたはFALSE)Portkey は、設定されたガードレール動作に応じて異なる
リクエストステータスコードを送信します。
async= FALSEのリクエストの場合:
ガードレール判定 DENY設定 返されるステータスコード 説明 PASS FALSE 200 ガードレールをすべて通過したので、リクエストはそのまま処理される。 PASS TRUE 200 ガードレールをすべて通過したので、リクエストはそのまま処理される。 FAIL FALSE 246 ガードレールに失敗したが、リクエストは処理される。Portkey独自のステータスコードでこの状態を示す。 FAIL TRUE 446 ガードレールに失敗したので、リクエストは処理されない。Portkey独自のステータスコードでこの状態を示す。
ちょっと複雑だけども、246は端的に言うとガードレールのチェックは失敗しているが、ブロックはしない、というモードになる。でこれが嬉しいのはリトライ機構と連動した場合になるかと思う。
例えばこんな感じ
{
"retry": {
"on_status_codes": [246],
"attempts": 5
},
"output_guardrails": ["guardrails-id-xxx"]
}
出力ガードレールのチェックが246で返される場合、これをリトライの対象にすると、ガードレールチェックが通るまではリトライして、チェックが通ればそのままレスポンスを返す、リトライしても通らなければ最終的に446でリクエストを拒否する、というような感じで使えるみたい。
このあたりはうまくつかえると単純なブロッキング設定だけじゃなく、ある程度の柔軟性をもたせることができるのではないかと思う。
まとめ
結構細かいところまで設定はできそうで、他にも色々機能は豊富なので、興味があればいろいろ触ってみると良いと思う。こういうのが必要なユースケースはあると思うし。
直感性にはややかかる気はするけど、この手のものは大体そうかもなー、という気もするので、そこは判断できないかな。凝ったことをやろうと思えばそれなりに複雑にはなると思うし、考えることは多くなると思うので。
あと、PIIマスキングとかプロンプトインジェクション的なものをやっぱりやりたいよね、と思うと、Portkeyクラウドで有償プランを使うか、OSS版なら自分で頑張ってカスタムなガードレールエンドポイント用意するか、になるように思えるので、そらするぐらいなら他にも選択肢があるのではないかなという気もしたり。