ドキュメントをMarkdownやJSONに変換してくれる「Docling」を試す
ここで知った。
試しに、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFで一度試していたのだけども:
(出典)
神戸市Webサイトの「観光に関する統計・調査」のページ
上記にある「令和5年度 神戸市観光動向調査結果について」のPDF
- 日本語でも、概ね問題なく、表などもきれいにパースされる
- ただし、表が画像 になってる場合に、うまく解釈されない(表は解釈されるが、中の文字が化ける)
- OCRが正しくできていない可能性
というのがあって、ドキュメント読んだけどわからなくて、それ以上深追いしてなかった。
ただ、X界隈を見る限りは評判は良さそうで、いろいろ記事も出てきたみたいなので、改めて試してみる。
GitHubレポジトリ
ドキュメント
Docling
Doclingは、ドキュメントを解析し、簡単かつ迅速に希望の形式にエクスポートします。
特徴
- 🗂️ 一般的なドキュメント形式(PDF、DOCX、PPTX、画像、HTML、AsciiDoc、Markdown)を読み取り、MarkdownとJSONにエクスポート可能
- 📑 高度なPDFドキュメント理解:ページレイアウト、読み順、表構造を把握
- 🧩 統一された表現力豊かなDoclingDocumentフォーマット
- 📝 メタデータの抽出:タイトル、著者、参考文献、言語など
- 🤖 LlamaIndex 🦙 & LangChain 🦜🔗 とのシームレスな統合による強力なRAG / QAアプリケーション対応
- 🔍 スキャンされたPDFのOCRサポート
- 💻 シンプルで便利なCLI
論文
Claude-3.5-Sonnetによる落合プロンプトの結果
1. どんなもの?
PDFドキュメントを機械処理可能な形式に変換するためのオープンソースパッケージ「Docling」を提案しています。最新のAIモデルとして、レイアウト分析用のDocLayNetと表構造認識用のTableFormerを搭載し、一般的なハードウェアで効率的に動作します。
主な特徴として:
- JSONやMarkdown形式への変換
- ページレイアウトの詳細な理解と読み取り順序の把握
- 図表の検出と構造認識
- メタデータ(タイトル、著者、参考文献、言語など)の抽出
- 必要に応じたOCR処理
MITライセンスで提供され、コード設計は拡張性が高く、新機能やモデルの追加が容易になっています。
2. 先行研究と比べてどこがすごい?
従来のPDF変換ソリューションの多くは商用ソフトウェアやクラウドサービス、最近では多モーダルな視覚-言語モデルが主流でした。これに対してDoclingは、完全にローカルで動作し、オープンソースで提供される点が特徴的です。
特に表構造の認識において、TableFormerモデルは以下のような複雑な表形式に対応できる高度な機能を備えています:
- 部分的な罫線や空のセル
- セルの結合と階層構造
- 列や行の不規則な配置やインデント
3. 技術や手法の肝はどこ?
Doclingは3つの主要コンポーネントによる線形のパイプラインを採用しています。
まず、PDFバックエンドでプログラム的なテキストトークンの取得とページのビットマップ画像のレンダリングを行います。この部分では、既存のパーサーの問題(ライセンス制限、低速、品質の問題など)を解決するため、独自開発のqpdfベースのバックエンドを採用しています。
次に、モデルパイプラインでDocLayNetを用いたレイアウト分析とTableFormerによる表構造認識を各ページに適用します。最後に後処理でメタデータの補強、言語検出、読み取り順序の修正などを行い、JSON/Markdown形式で出力します。
4. どうやって有効だと検証した?
225ページ(arXivからの3論文とIBM Redbooksから2冊)を含む標準テストセットを用いて、処理速度とリソース使用量を検証しています。Apple M3 MaxとIntel Xeon E5-2690の2種類のハードウェアで、デフォルト設定(4スレッド)とフルコア使用(16スレッド)の両方をテストしました。
結果として、ネイティブバックエンドでは1.27〜0.60ページ/秒(メモリ約6.20GB)、pypdfiumバックエンドでは2.18〜0.94ページ/秒(メモリ約2.56GB)の処理速度を達成しています。
5. 議論はある?
主な議論点として、低リソース環境での実行に関して、pypdfiumバックエンドの使用を推奨していますが、表構造認識の品質は低下する可能性があると指摘しています。
また、GPU加速のサポートは現在開発中で、onnxruntimeとtorchランタイムでCUDAが利用可能な場合は暗黙的に動作する可能性があると言及しています。将来の開発計画として、図の分類モデル、数式認識モデル、コード認識モデルなどの追加を予定しています。
6. 次に読むべき論文は?
この論文の主要コンポーネントの詳細を理解するために、以下の論文を読むことを推奨します:
- TableFormerについて:Nassar et al. "TableFormer: Table Structure Understanding with Transformers" (2022)
- DocLayNetデータセットについて:Pfitzmann et al. "DocLayNet: a large human-annotated dataset for document-layout segmentation" (2022)
- RT-DETRアーキテクチャについて:Zhao et al. "Detrs beat yolos on real-time object detection" (2023)
インストール
Colaboratoryで。CPUだとかなり遅いので、T4で。
パッケージインストール
!pip install docling
使い方
神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用させていただく。
PDFの特徴
- サイズ: 1.8MB
- ページ数: 21
- 縦長レイアウト
- 文字は横書き
- 表・グラフ等含む
参考までに一部抜粋。
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
from docling.document_converter import DocumentConverter
source = "r5_doukou.pdf"
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown())
初回はモデルがダウンロードされるので少し時間がかかる。あと、インストールのページにも記載されているが、OCRはEasyOCR、Tesseract、Tesseract CLIが選択でき、デフォルトはEasyOCRになる。
約3分ほどかかったが、初回はモデルのダウンロードの時間も含まれており、それを除くと1分40秒ほどだった。
1ページ目

## 調 査 目 的
本 調査は,来神観光客の特質と神戸市内の観光動向を把握し,今後の観光行政の参考とす ることを目的に実施。
## 調 査 方 法
調 査員が対面にてアンケ-ト項目を聞き取りする形で実施。
## 調査日
- ① 令和5年 5月 13 日(土)·20 日(土)※
- ② 令和5年 9月 9日(土)
- ③ 令和5年 11 月 25 日(土)/12 月2日(土)※
- ④ 令和6年 2月 10 日(土)·17 日(土)·24 日/3月 30 日(土)※
※雨天等により、-部の調査地点については延期して実施。
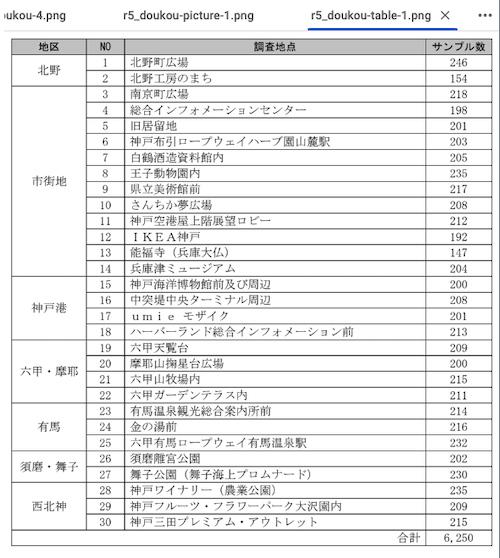
## 調査地点
| NO | 調査地点 | サンプル数 |
|------|-------------------------------------|--------------|
| 1 | 北野町広場 | 246 |
| 2 | 北野工房のまち | 154 |
| 3 | 南京町広場 | 218 |
| 4 | 総合インフォメ-ションセンタ- | 198 |
| 5 | 旧居留地 | 201 |
| 6 | 神戸布引ロ-プウェイハ-ブ園山麓駅 | 203 |
| 7 | 白鶴酒造資料館内 | 205 |
| 8 | 王子動物園内 | 235 |
| 9 | 県立美術館前 | 217 |
| 10 | さんちか夢広場 | 208 |
| 11 | 神戸空港屋上階展望ロビ- | 212 |
| 12 | IKEA神戸 | 192 |
| 13 | 能福寺(兵庫大仏) | 147 |
| 14 | 兵庫津ミュ-ジアム | 204 |
| 15 | 神戸海洋博物館前及び周辺 | 200 |
| 16 | 中突堤中央タ-ミナル周辺 | 208 |
| 17 | umie モザイク | 201 |
| 18 | ハ-バ-ランド総合インフォメ-ション前 | 213 |
| 19 | 六甲天覧台 | 209 |
| 20 | 摩耶山掬星台広場 | 200 |
| 21 | 六甲山牧場内 | 215 |
| 22 | 六甲ガ-デンテラス内 | 211 |
| 23 | 有馬温泉観光総合案内所前 | 214 |
| 24 | 金の湯前 | 216 |
| 25 | 六甲有馬ロ-プウェイ有馬温泉駅 | 232 |
| 26 | 須磨離宮公園 | 202 |
| 27 | 舞子公園(舞子海上プロムナ-ド) | 230 |
| 28 | 神戸ワイナリ-(農業公園) | 235 |
| 29 | 神戸フル-ツ·フラワ-パ-ク大沢園内 | 209 |
| 30 | 神戸三田プレミアム·アウトレット | 215 |
| | | 6,250 |
表もきちんとMarkdownになっているのがわかる。
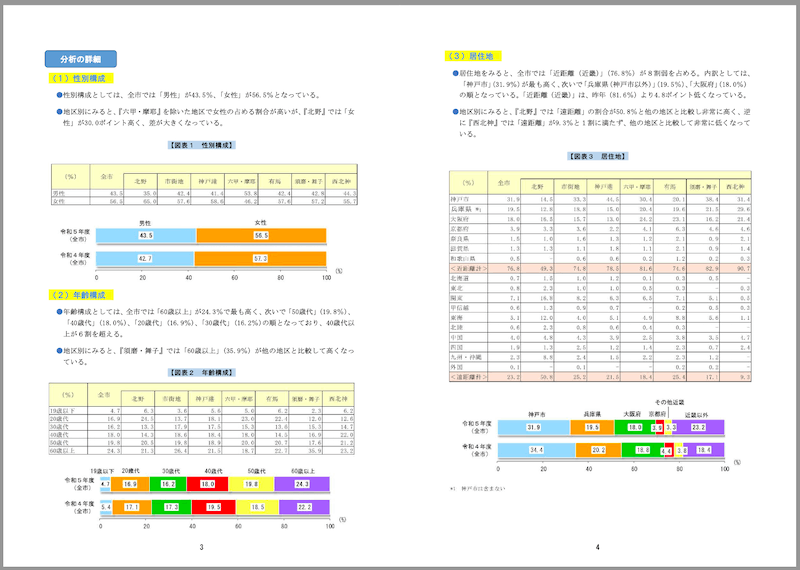
4ページ目
## 分析の詳細
## (1)性別構成
- ●性別構成としては、全市では「男性」が43.5%、 「女性」が56.5%となっている。
- ●地区別にみると、 『六甲·摩耶』を除いた地区で女性の占める割合が高いが、 『北野』では「女 性」が30.0ポイント高く、差が大きくなっている。
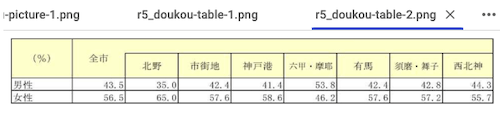
## 【図表1 性別構成】
| (% ) | | | | | | | | |
|--------|-------|-------|--------|-------|-----------|--------|----------|--------|
| | 4mi | Ay | itij t | #Fx# | Fh . PeiT | 4155 | sim . #F | pj 4 # |
| Ua+ | 43.5 | 35. 0 | 42.4 | 41 .4 | 53.8 | 42.4 | 42.8 | 44.3 |
| tN | 56. 5 | 65. 0 | 57.6 | 58 | 46. 2 | 57.6 | 57.2 | 55 . |
<!-- image -->
## (2)年齢構成
- ●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、 「40歳代」(18.0%)、 「20歳代」(16.9%)、 「30歳代」(16.2%)の順となっており、40歳代以 上が6割を超える。
- ●地区別にみると、 『須磨·舞子』では「60歳以上」 (35.9%)が他の地区と比較して高くなっ ている。
## 【図表2 年齢構成】
| | Æihi | | | | | | | |
|---------|--------|--------|---------|-------|----------|-------|-----------|--------|
| | | JL7 | #i fj J | #F## | #H . |es | Ai5 | il# . W < | Vyj 4# |
| 19æ"F | 4 . 7 | 6. 3 | 3. 6 | 5. 6 | 5. 0 | 6. 2 | 2. 3 | 6. 2 |
| 2od/C | 16. 9 | 24. 5 | 13. 7 | 18.1 | 23.0 | 22. | 12. 0 | 12. 6 |
| 3o4 {6 | 16. 2 | 13. 3 | 17. 9 | 17. 5 | 15. 3 | 13. 6 | 15. 3 | 14. 7 |
| Aode {c | 18. 0 | 14 . 3 | 18. 6 | 18 4 | 18. 0 | 14.5 | 16. 9 | 22. 0 |
| 5og {t | 19. 8 | 20. 5 | 19. 8 | 18.9 | 20. 0 | 20. 7 | 17 . 6 | 21 . 2 |
| [6O5VE | 24. 3 | 21.3 | 26 | 21.5 | 18 . | 22 | 35 9 | 23. 2 |
<!-- image -->
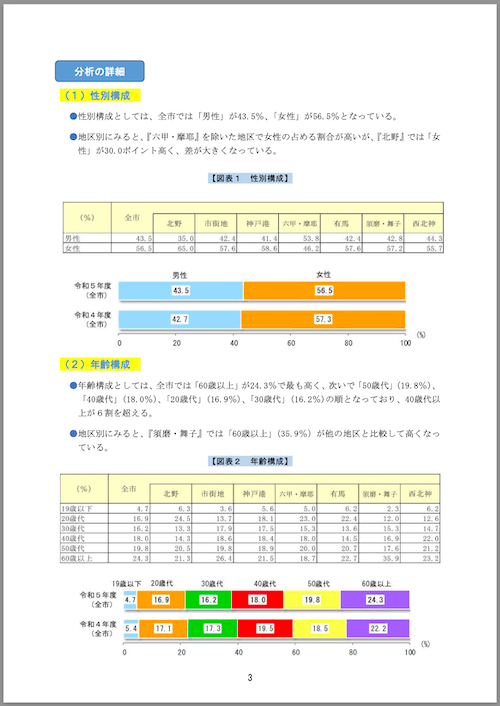
1ページ目で読み取れていた表が4ページ目では読み取れていない、というか表は認識しているのだが中身が文字化けしたようになっている。この違いは、1ページ目の表はテキストになっているのに対し、4ページ目の表+グラフは画像になっているため。つまりここはOCRで正しく言語判定できていないということになる。また、グラフについては画像であるということだけが出力されている。
上記については後で後述する。
DoclingはCLIも提供している。オプション無しのデフォルトだとこんな感じ。
!docling r5_doukou.pdf
カレントディレクトリにr5_doukou.mdが出力される。
!ls -lt
total 1852
-rw-r--r-- 1 root root 52072 Nov 5 06:28 r5_doukou.md
-rw-r--r-- 1 root root 1838405 Sep 13 00:45 r5_doukou.pdf
(snip)
中身については同じだと思うので割愛。
Usageを見ると、入出力フォーマットやOCRエンジン・PDFバックエンド・テーブル構造モデルを指定することができる様子
!docling --help
Usage: docling [OPTIONS] source
╭─ Arguments ──────────────────────────────────────────────────────────────────────────────────────╮
│ * input_sources source PDF files to convert. Can be local file / directory paths or │
│ URL. │
│ [default: None] │
│ [required] │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Options ────────────────────────────────────────────────────────────────────────────────────────╮
│ --from [docx|pptx|html|image|pdf Specify input formats to │
│ |asciidoc|md] convert from. Defaults to │
│ all formats. │
│ [default: None] │
│ --to [md|json|text|doctags] Specify output formats. │
│ Defaults to Markdown. │
│ [default: None] │
│ --ocr --no-ocr If enabled, the bitmap │
│ content will be processed │
│ using OCR. │
│ [default: ocr] │
│ --ocr-engine [easyocr|tesseract_cli|te The OCR engine to use. │
│ sseract] [default: easyocr] │
│ --pdf-backend [pypdfium2|dlparse_v1|dlp The PDF backend to use. │
│ arse_v2] [default: dlparse_v1] │
│ --table-mode [fast|accurate] The mode to use in the │
│ table structure model. │
│ [default: fast] │
│ --artifacts-path PATH If provided, the location │
│ of the model artifacts. │
│ [default: None] │
│ --abort-on-error --no-abort-on-error If enabled, the bitmap │
│ content will be processed │
│ using OCR. │
│ [default: │
│ no-abort-on-error] │
│ --output PATH Output directory where │
│ results are saved. │
│ [default: .] │
│ --version Show version information. │
│ --help Show this message and │
│ exit. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
高度なオプション
より高度なカスタマイズを行うために、パイプラインを設定することができる。パイプラインを使うと以下のようなことが設定できる様子。
- OCR使用の有無(
PdfPipelineOptionsのdo_ocr)- 使用する場合は以下が設定可能
- OCRエンジンの指定
- OCRエンジンに与えるオプションの指定
- 使用する場合は以下が設定可能
- テーブル構造モデル使用の有無(
PdfPipelineOptionsのdo_table_structure)- ここはよくわからなくて、ChatGPTに色々食わせて聞いてみた結果(つまり間違ってる可能性がある)
- 一般的にPDFにおける表は「論理構造を持った表」(表・行・列・セルとしての意味)がなく、「罫線と文字で表現された視覚的な表」になっている場合が多い(PDF作成時にアクセシビリティオプションを有効にしたり、タグ付けを行うことで論理構造をもたせることができるが、有効になっていない場合が多い)らしい。
- つまりPDF内に表があったとしても、パースするだけでは「表」として認識できない可能性が高いということだと思う
- Doclingはこの表を認識するためのテーブル構造モデルを提供してくれる。これを使用するかしないか。
- 使用する場合は以下が設定可能
- セルの構造認識方法(
PdfPipelineOptionsのtable_structure_options.do_cell_matching)-
True- ビジュアル構造に基づく方法
- テーブル構造モデルの予測結果をPDFの視覚的なセル配置(ビジュアル構造)に合わせて整形する。つまり、PDFの見た目どおりの配置を再現しようとする。
- ただし、テーブルの列にまたがるセルがある場合、出力結果が崩れる可能性があり
-
False- テーブル構造モデルによる予測に基づく方法
- テーブル構造モデルが予測したセルをそのまま使い、PDFの視覚的なセルの配置(ビジュアル構造)を無視する。
- テーブル構造モデルがテキストを自動的に分割し、複雑なセル配置に対してより柔軟に対処できる。
- PDFの見た目通りに出力されない場合もある
-
- テーブル構造モデルのモード設定((
PdfPipelineOptionsのtable_structure_options.mode)- Docling 1.16.0以降で、TableFormerというテーブル抽出用モデルに対し、以下の2つのモードを指定できる
-
TableFormerMode.FAST- 高速で一般的なテーブルに対して十分な精度
- 複雑なテーブルは解釈できない可能性がある
-
TableFormerMode.ACCURATE- 複雑なテーブルでもより正確に解釈
- 処理速度は遅い
-
- Docling 1.16.0以降で、TableFormerというテーブル抽出用モデルに対し、以下の2つのモードを指定できる
- セルの構造認識方法(
- ここはよくわからなくて、ChatGPTに色々食わせて聞いてみた結果(つまり間違ってる可能性がある)
上記以外に画像のエクスポートなんかもできるが、一旦置いておく。
ということで、冒頭で試した例に対して、上記のパイプライン設定を行って再度試してみる。あとPDFバックエンドを変えてみた。
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
PdfPipelineOptions,
EasyOcrOptions,
TableFormerMode,
)
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.backend.docling_parse_v2_backend import DoclingParseV2DocumentBackend
# EasyOCRの言語オプションを設定
ocr_options = EasyOcrOptions(lang=["ja"])
pipeline_options = PdfPipelineOptions()
# OCRの使用有無: 使用する
pipeline_options.do_ocr = True
# テーブル構造モデルの使用有無: 使用する
pipeline_options.do_table_structure = True
# セルの認識方法: ビジュアルに基づいてセルを認識させる
pipeline_options.table_structure_options.do_cell_matching = True
# テーブル構造モデルのモード: 正確さを重視
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE
# パイプラインにOCRオプションを設定
pipeline_options.ocr_options = ocr_options
doc_converter = (
DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=pipeline_options,
# PDFバックエンドにDLPARSE_V2を使用
backend=DoclingParseV2DocumentBackend,
),
}
)
)
result = doc_converter.convert("r5_doukou.pdf")
print(result.document.export_to_markdown())
約2分かかった。最初に試した4ページ目がどうなったかを見てみる。
## 分析の詳細
## (1)性別構成
- ●性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
- ●地区別にみると、『六甲·摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女 性」が30.0ポイント高く、差が大きくなっている。
## 【図表1 性別構成】
| (9) | 全市 | 北野 | 市街地 | 神戸港 | 六中 ·摩耶 | 有馬 | 須磨· 舞子 | 西北神 |
|-------|--------|--------|----------|----------|--------------|--------|--------------|----------|
| | 43.5 | 35 | 42.4 | 41 | 53.8 | 42.4 | 42.8 | 44.3 |
| | 56.5 | 65 | 57.6 | 58 | 46.2 | 57.6 | 57.2 | 55 |
<!-- image -->
## (2)年齢構成
- ●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、 「40歳代」(18.0%)、「20歳代」(16.9%)、「30歳代」(16.2%)の順となっており、40歳代以 上が6割を超える。
- ●地区別にみると、『須磨·舞子』では「60歳以上」(35.9%)が他の地区と比較して高くなっ ている。
## 【図表2 年齢構成】
| 全市 | | | | | | | |
|--------|------|--------|--------|-------------|------|-----------|--------|
| | 北野 | 市街地 | 神戸港 | 六甲 · 摩耶 | 有馬 | 須磨·舞子 | 西北神 |
| 4.7 | 6.3 | 3.6 | 5.6 | 5.0 | 6.2 | 2.3 | 6.2 |
| 16.9 | 24,5 | 13.7 | 18.1 | 23,0 | 22. | 12.0 | 12.6 |
| 16.2 | 13.3 | 17.9 | 17.5 | 15,3 | 13.6 | 15.3 | 14.7 |
| 18.0 | 14.3 | 18.6 | 18\_ 4 | 18.0 | 14.5 | 16.9 | 22.0 |
| 19.8 | 20.5 | 19.8 | 18.9 | 20.0 | 20.7 | 17.6 | 21.2 |
| 24.3 | 21.3 | 26 | 21.5 | 18 | 22 | 35 9 | 23.2 |
<!-- image -->
画像で埋め込まれている表が概ね読み取れて日本語で出力されるようになった。
どの組み合わせが一番良いのかは、試行錯誤する必要がありそうだし、あとはPDFによっても変わりそう。ただ自分が今回試してみた感じだと、
- OCRを使用しなければ当然画像部分は読み取れない。表が画像になっていたりする場合は有効にしたほうがよい。
- テーブル構造モデルを使用しなければ、表(テキストであっても画像であっても)は一切パースされなかった。
- セルの認識方法は
Trueにしないと、表画像が表であることは認識できるが、中のセルを認識できなかった(空になった)。 - PDFバックエンドは、DLPARSE_V1(デフォルト) / DLPARSE_V2 / Pypdfium2で、あまり違いがわからなかった。もう少し複雑なレイアウトだと違いが出てくるのかもしれない。
という感じ。
ちなみにTesseractをOCRエンジンに使う場合。
依存パッケージをインストール
%%writefile packages.txt
libmagic-dev
poppler-utils
libpoppler-dev
tesseract-ocr
libtesseract-dev
tesseract-ocr-jpn
tesseract-ocr-jpn-vert
tesseract-ocr-script-jpan
tesseract-ocr-script-jpan-vert
libxml2-dev
libxslt1-dev
libgl1-mesa-dev
libleptonica-dev
pkg-config
!apt update && xargs apt install -y < packages.txt
Tesseractのデータパスを確認
!dpkg -L tesseract-ocr-jpn | egrep tessdata$
/usr/share/tesseract-ocr/4.00/tessdata
!ls -lt /usr/share/tesseract-ocr/4.00/tessdata
total 31768
drwxr-xr-x 2 root root 4096 Nov 1 13:17 configs
drwxr-xr-x 2 root root 4096 Nov 1 13:17 tessconfigs
-rw-r--r-- 1 root root 572 Feb 9 2022 pdf.ttf
-rw-r--r-- 1 root root 5877645 Mar 14 2018 Japanese.traineddata
-rw-r--r-- 1 root root 6445356 Mar 14 2018 Japanese_vert.traineddata
-rw-r--r-- 1 root root 2471260 Feb 21 2018 jpn.traineddata
-rw-r--r-- 1 root root 3037480 Sep 15 2017 jpn_vert.traineddata
-rw-r--r-- 1 root root 10562727 Sep 15 2017 osd.traineddata
-rw-r--r-- 1 root root 4113088 Sep 15 2017 eng.traineddata
オプション指定する場合、.traindataの前の部分で言語は指定することになる。日本語の場合だと、jpn / jpn_vert / Japanese / Japanese_vert のどれかになる。
tesserocrパッケージをビルドしてインストール。
!pip install --no-binary :all: tesserocr
実行
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
PdfPipelineOptions,
TesseractOcrOptions,
TableFormerMode,
)
from docling.document_converter import DocumentConverter, PdfFormatOption
# Tesseractの言語オプションを設定
ocr_options = TesseractOcrOptions(lang=["jpn"])
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE
# OCRオプションをパイプラインに渡す
pipeline_options.ocr_options = ocr_options
doc_converter = (
DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=pipeline_options,
),
}
)
)
result = doc_converter.convert("r5_doukou.pdf")
print(result.document.export_to_markdown())
結果、同じく4ページ目
## 分析の詳細
## (1)性別構成
- ●性別構成としては、全市では「男性」が43.5%、 「女性」が56.5%となっている。
- ●地区別にみると、 『六甲·摩耶』を除いた地区で女性の占める割合が高いが、 『北野』では「女 性」が30.0ポイント高く、差が大きくなっている。
## 【図表1 性別構成】
<!-- image -->
## (2)年齢構成
- ●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、 「40歳代」(18.0%)、 「20歳代」(16.9%)、 「30歳代」(16.2%)の順となっており、40歳代以 上が6割を超える。
- ●地区別にみると、 『須磨·舞子』では「60歳以上」 (35.9%)が他の地区と比較して高くなっ ている。
## 【図表2 年齢構成】
<!-- image -->
67 全市 北野 | 市街地 | 神戸港 |大申·摩耶| 有馬 |逢鹿<舞子| 西北神
31.91 14.5| 44.5| 30. 41 20.11 38. 4| 31. 4
19.5引 9。潤 18.8| 15.0| 20. 4| 19.6| y 6 5 29.6
ちょっと読み取れてない表があったり、読み取れてても微妙な感じ。Tesseractの他のモデルも試してみたけどもあまり変わらず。
結果として、今回のデータの場合はEasyOCRのほうが良かった。TesseractもEasyOCRも以前ちょこっとやった程度なので、他に精度を改善できるオプションがあるのかはわかっていないが、結局のところ、画像が含まれていてそれが表の場合には、OCRエンジンの精度に依存することになる。
TesseractもEasyOCRもどちらもファインチューニングはできるはずなので、デフォルトのモデルの精度が物足りなければファインチューニングするしかないかなぁ。
画像のエクスポート
ここまでの例で、表についてはテキストであっても画像であっても(精度は置いておくとして)読み取れることがわかったが、グラフなどの画像については<!-- image -->となったまま。Doclingではこれらの画像をファイルとしてエクスポートすることができる。
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
PdfPipelineOptions,
EasyOcrOptions,
TableFormerMode,
)
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.backend.docling_parse_v2_backend import DoclingParseV2DocumentBackend
from docling_core.types.doc import ImageRefMode, PictureItem, TableItem
from pathlib import Path
ocr_options = EasyOcrOptions(lang=["ja"])
# 画像解像度のスケール。ここでは2倍にしている。
IMAGE_RESOLUTION_SCALE = 2.0
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE
pipeline_options.ocr_options = ocr_options
# 画像出力オプション
# ---------------
# 解像度スケールの設定
# 注意: ページ画像を操作する場合、画像を保持する必要があり、そうしなければ
# DocumentConverterがメモリを解放するために画像を削除してしまう。
# この画像の保持は、PdfPipelineOptions.images_scaleを設定することで実現され、
# 同時に画像のスケールも定義する。scale=1は標準の72 DPI画像に相当する。
# また、PdfPipelineOptions.generate_*オプションは、画像フィールドで強化される
# ドキュメント要素を選択するためのセレクタになる。
pipeline_options.images_scale = IMAGE_RESOLUTION_SCALE
# ページごとの画像を生成
pipeline_options.generate_page_images = True
# 表ごとの画像を生成
pipeline_options.generate_table_images = True
# 写真や図の画像を生成
pipeline_options.generate_picture_images = True
doc_converter = (
DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=pipeline_options,
),
}
)
)
result = doc_converter.convert("r5_doukou.pdf")
# 出力パス
output_dir = Path("kobe_kanko")
output_dir.mkdir(parents=True, exist_ok=True)
# ページ画像の保存
doc_filename = result.input.file.stem
for page_no, page in result.document.pages.items():
page_no = page.page_no
page_image_filename = output_dir / f"{doc_filename}-{page_no}.png"
with page_image_filename.open("wb") as fp:
page.image.pil_image.save(fp, format="PNG")
# テーブルと図の画像の保存
table_counter = 0
picture_counter = 0
for element, _level in result.document.iterate_items():
if isinstance(element, TableItem):
table_counter += 1
element_image_filename = output_dir / f"{doc_filename}-table-{table_counter}.png"
with element_image_filename.open("wb") as fp:
element.image.pil_image.save(fp, "PNG")
if isinstance(element, PictureItem):
picture_counter += 1
element_image_filename = output_dir / f"{doc_filename}-picture-{picture_counter}.png"
with element_image_filename.open("wb") as fp:
element.image.pil_image.save(fp, "PNG")
# Markdownの保存
content_md = result.document.export_to_markdown(image_mode=ImageRefMode.EMBEDDED)
md_filename = output_dir / f"{doc_filename}-with-images.md"
with md_filename.open("w") as fp:
fp.write(content_md)
以下のように出力される
!tree kobe_kanko
kobe_kanko
├── r5_doukou-10.png
├── r5_doukou-11.png
├── r5_doukou-12.png
├── r5_doukou-13.png
├── r5_doukou-14.png
├── r5_doukou-15.png
├── r5_doukou-16.png
├── r5_doukou-17.png
├── r5_doukou-18.png
├── r5_doukou-19.png
├── r5_doukou-1.png
├── r5_doukou-20.png
├── r5_doukou-21.png
├── r5_doukou-2.png
├── r5_doukou-3.png
├── r5_doukou-4.png
├── r5_doukou-5.png
├── r5_doukou-6.png
├── r5_doukou-7.png
├── r5_doukou-8.png
├── r5_doukou-9.png
├── r5_doukou-picture-10.png
├── r5_doukou-picture-11.png
├── r5_doukou-picture-12.png
├── r5_doukou-picture-13.png
├── r5_doukou-picture-14.png
├── r5_doukou-picture-15.png
├── r5_doukou-picture-16.png
├── r5_doukou-picture-17.png
├── r5_doukou-picture-18.png
├── r5_doukou-picture-19.png
├── r5_doukou-picture-1.png
├── r5_doukou-picture-20.png
├── r5_doukou-picture-21.png
├── r5_doukou-picture-22.png
├── r5_doukou-picture-2.png
├── r5_doukou-picture-3.png
├── r5_doukou-picture-4.png
├── r5_doukou-picture-5.png
├── r5_doukou-picture-6.png
├── r5_doukou-picture-7.png
├── r5_doukou-picture-8.png
├── r5_doukou-picture-9.png
├── r5_doukou-table-10.png
├── r5_doukou-table-11.png
├── r5_doukou-table-12.png
├── r5_doukou-table-13.png
├── r5_doukou-table-14.png
├── r5_doukou-table-15.png
├── r5_doukou-table-16.png
├── r5_doukou-table-17.png
├── r5_doukou-table-18.png
├── r5_doukou-table-19.png
├── r5_doukou-table-1.png
├── r5_doukou-table-20.png
├── r5_doukou-table-21.png
├── r5_doukou-table-22.png
├── r5_doukou-table-2.png
├── r5_doukou-table-3.png
├── r5_doukou-table-4.png
├── r5_doukou-table-5.png
├── r5_doukou-table-6.png
├── r5_doukou-table-7.png
├── r5_doukou-table-8.png
├── r5_doukou-table-9.png
└── r5_doukou-with-images.md
0 directories, 66 files
出力されたファイルを見てみる。まずMarkdown。4ページ目の抜粋。
## 分析の詳細
## (1)性別構成
- ●性別構成としては、全市では「男性」が43.5%、 「女性」が56.5%となっている。
- ●地区別にみると、 『六甲·摩耶』を除いた地区で女性の占める割合が高いが、 『北野』では「女 性」が30.0ポイント高く、差が大きくなっている。
## 【図表1 性別構成】
| (9) | 全市 | 北野 | 市街地 | 神戸港 | 六中 ·摩耶 | 有馬 | 須磨· 舞子 | 西北神 |
|-------|--------|--------|----------|----------|--------------|--------|--------------|----------|
| 弟性 | 43.5 | 35 | 42.4 | 41 | 53.8 | 42.4 | 42.8 | 44.3 |
| 女性 | 56.5 | 65 | 57.6 | 58 | 46.2 | 57.6 | 57.2 | 55 |

## (2)年齢構成
- ●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、 「40歳代」(18.0%)、 「20歳代」(16.9%)、 「30歳代」(16.2%)の順となっており、40歳代以 上が6割を超える。
- ●地区別にみると、 『須磨·舞子』では「60歳以上」 (35.9%)が他の地区と比較して高くなっ ている。
## 【図表2 年齢構成】
| | 全市 | | | | | | | |
|-----------|--------|------|--------|--------|-------------|------|-----------|--------|
| | | 北野 | 市街地 | 神戸港 | 六甲 · 摩耶 | 有馬 | 須磨·舞子 | 西北神 |
| 川9歳以下 | 4.7 | 6.3 | 3.6 | 5.6 | 5.0 | 6.2 | 2.3 | 6.2 |
| 20歳代 | 16.9 | 24,5 | 13.7 | 18.1 | 23,0 | 22. | 12.0 | 12.6 |
| 3歳代 | 16.2 | 13.3 | 17.9 | 17.5 | 15,3 | 13.6 | 15.3 | 14.7 |
| 4歳代 | 18.0 | 14.3 | 18.6 | 18\_ 4 | 18.0 | 14.5 | 16.9 | 22.0 |
| 0歳代 | 19.8 | 20.5 | 19.8 | 18.9 | 20.0 | 20.7 | 17.6 | 21.2 |
| 60歳以上 | 24.3 | 21.3 | 26 | 21.5 | 18 | 22 | 35 9 | 23.2 |

<!-- image -->となっていた箇所に画像がBASE64エンコードされて埋め込まれているのがわかる。
ページ単位の画像。
テーブル単位の画像。ここは表がテキストなのか画像なのかは関係なくすべての表が対象になる模様。
図や写真単位の画像
レイアウトが複雑なPDFで試してみる。
農林水産省が出している「馬産地をめぐる情勢(令和6年6月)」のPDFをパースしてみる。
PDFの特徴
- サイズ: 762KB
- ページ数: 18
- 横長レイアウト
- 文字は横書き
- 表・グラフ・イラスト等含む結構複雑なレイアウト
- 表・グラフについてはテキストで文字が読み取れるものが多い
参考までに一部抜粋。4・5ページ。
上の例はちょっとパースの確認には向いてなさそうなので、以下の17・18ページで確認してみる。
コードは一つ前のものを使用してファイル・ディレクトリパスだけを書き換えたもの。以下のようにファイルが出力された。
basanchi
├── index-24-10.png
├── index-24-11.png
├── index-24-12.png
├── index-24-13.png
├── index-24-14.png
├── index-24-15.png
├── index-24-16.png
├── index-24-17.png
├── index-24-18.png
├── index-24-1.png
├── index-24-2.png
├── index-24-3.png
├── index-24-4.png
├── index-24-5.png
├── index-24-6.png
├── index-24-7.png
├── index-24-8.png
├── index-24-9.png
├── index-24-picture-10.png
├── index-24-picture-11.png
├── index-24-picture-12.png
├── index-24-picture-13.png
├── index-24-picture-14.png
├── index-24-picture-15.png
├── index-24-picture-16.png
├── index-24-picture-17.png
├── index-24-picture-18.png
├── index-24-picture-19.png
├── index-24-picture-1.png
├── index-24-picture-20.png
├── index-24-picture-21.png
├── index-24-picture-22.png
├── index-24-picture-2.png
├── index-24-picture-3.png
├── index-24-picture-4.png
├── index-24-picture-5.png
├── index-24-picture-6.png
├── index-24-picture-7.png
├── index-24-picture-8.png
├── index-24-picture-9.png
├── index-24-table-1.png
├── index-24-table-2.png
├── index-24-table-3.png
├── index-24-table-4.png
├── index-24-table-5.png
├── index-24-table-6.png
└── index-24-with-images.md
0 directories, 47 files
Markdown。表が抜け落ちてしまっているものがある。
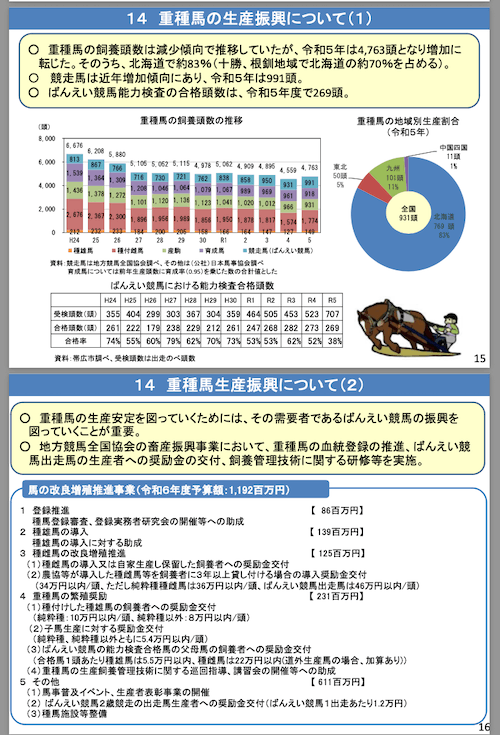
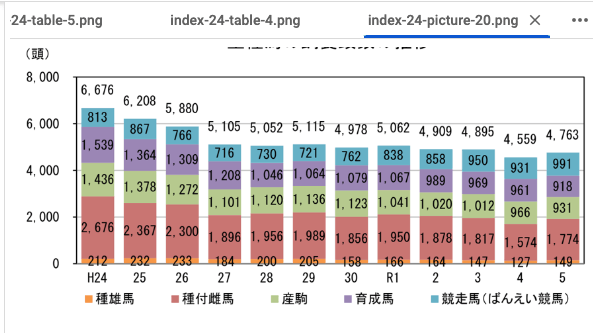
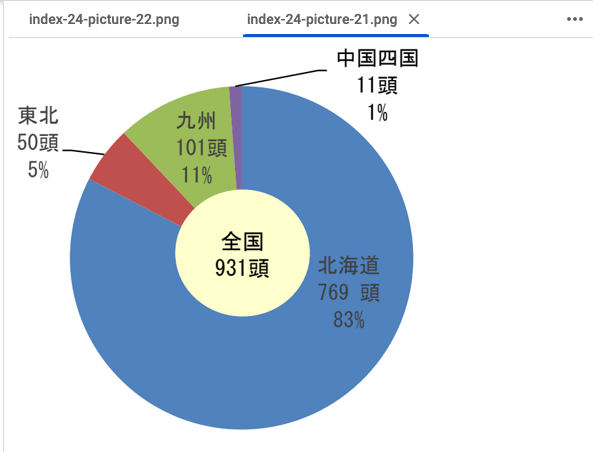
## 14 重種馬の生産振興について(1)
- · 重種馬の飼養頭数は減少傾向で推移していたが、令和5年は 4,763 頭となり増加に 転じた。そのうち、北海道で約 83 %(十勝、根釧地域で北海道の約 70 %を占める)。
- · ばんえい競馬能力検査の合格頭数は、令和5年度で 269 頭。
- 〇 競走馬は近年増加傾向にあり、令和5年は 991 頭。
## 重種馬の飼養頭数の推移

## 14 重種馬生産振興について(2)
- · 重種馬の生産安定を図っていくためには、その需要者であるばんえい競馬の振興を 図っていくことが重要。
- · 地方競馬全国協会の畜産振興事業において、重種馬の血統登録の推進、ばんえい競 馬出走馬の生産者への奨励金の交付、飼養管理技術に関する研修等を実施。
## 馬の改良増殖推進事業(令和6年度予算額: 1,192 百万円)
- 1 登録推進
【 86 百万円】
- 種馬登録審査、登録実務者研究会の開催等への助成
- 2 種雄馬の導入
【 139 百万円】
種雄馬の導入に対する助成
- 3 種雌馬の改良増殖推進
【 125 百万円】
- (1)種雌馬の導入又は自家生産し保留した飼養者への奨励金交付
- (2)農協等が導入した種雌馬等を飼養者に3年以上貸し付ける場合の導入奨励金交付
( 34 万円以内 / 頭、ただし純粋種種雌馬は 36 万円以内 / 頭、ばんえい競馬出走馬は 46 万円以内 / 頭)
- 4 重種馬の繁殖奨励
【 231 百万円】
- (1)種付けした種雄馬の飼養者への奨励金交付
- (純粋種: 10 万円以内 / 頭、純粋種以外:8万円以内 / 頭)
- (2)子馬生産に対する奨励金交付
- (純粋種、純粋種以外ともに 5.4 万円以内 / 頭)
- (3)ばんえい競馬の能力検査合格馬の父母馬の飼養者への奨励金交付
(合格馬1頭あたり種雄馬は 5.5 万円以内、種雌馬は 22 万円以内 ( 道外生産馬の場合、加算あり ) )
- (4)重種馬の生産飼養管理技術に関する巡回指導、講習会の開催等への助成
- 5 その他
【 611 百万円】
- (1)馬事普及イベント、生産者表彰事業の開催
- (2) ばんえい競馬2歳競走の出走馬生産者への奨励金交付(ばんえい競馬1出走あたり 1.2 万円)
- (3)種馬施設等整備
画像や表も、ある程度はうまく切り取れている様子

当然ながら完璧ではないが、想像してたよりは全然マシというのが個人的な印象。
まとめ
最初見たときは、OCRエンジンとかPDFバックエンドに既存のものを使用しているので、単なるラッパーなのかな?と思ったけど、
- レイアウト分析用のDocLayNetと表構造認識用のTableFormerを搭載
- それらをパイプラインとして使えるようにパッケージ化
ってのがDoclingのメリットなんだろうと個人的には認識している。実際にモデルは以下にある。
自分で試してみた限りは悪くない印象。以前とあるLLM(gpt-4oだった記憶)を使って解析するサービスで今回サンプルで使用したPDFを試したことがあるけど、その際の結果と比較しても、こちらのほうがある程度の精度でパースができているように思える。多少ミスってる・抜け落ちてるみたいなのはあるけども、画像として別々に抽出できてたりするので、マルチモーダルRAGなんかの前処理などで使いやすいのではないだろうか。
あとLangChainやLlamaIndexにインテグレーションされているのも使いやすいと思う
ドキュメントは少ない印象でAPIリファレンスみたいなものもないが、サンプルはいくつか用意されているので参考になると思う。
ただ、最近はマルチモーダルなLLMの精度も上がっていると思うし、どちらを使うかは精度・手間などを比較しつつ、結局は実際のデータを使って判断するしかないかなと思う。あとは、段組みとか自由度高めのレイアウトでどうなるかはちょっと興味があるところ。また気が向いたら試してみたい。
結局は実際のデータを使って判断するしかないかなと思う。
今回の例でも、表がテキストなのか?画像なのか?で処理するコンポーネントが違ってきたのだけど、PDFは作り方で結果が変わるんだなというのを別のところでも痛感した機会があった。見た目的には問題ないように思えるが、機械で読ませるということを考える場合にはいろいろ考えて作らないと全然読み取れない場合とか全然あるので。
軽量版、なのかな?
ただ日本語では学習されてなさそうに見える。