オープンソースのPerplexityクローンをいくつか試す
調べてみたら他にもいくつかあった。他にもあるのだけど、比較的開発が継続されてそうなものをピックアップ。
Perplexica
概要
Perplexicaは、オープンソースのAI搭載検索ツール、またはAI搭載検索エンジンであり、インターネットの奥深くまで入り込んで答えを見つける。Perplexity AIにインスパイアされたPerplexicaは、単にウェブを検索するだけでなく、あなたの質問を理解するオープンソースのオプションだ。類似検索や埋め込みなどの高度な機械学習アルゴリズムを使って検索結果を絞り込み、引用元とともに明確な回答を提供する。
SearxNGを使用して常に最新の情報を提供し、完全なオープンソースであるPerplexicaは、あなたのプライバシーを損なうことなく、常に最新の情報を得ることを保証する。
Perplexicaのアーキテクチャと仕組みについてもっと知りたい?こちらで読むことができる。
アーキテクチャ
Perplexicaのアーキテクチャは、以下の主要コンポーネントで構成されている:
- ユーザーインターフェース: ウェブベースのインターフェイスで、ユーザーはPerplexicaと対話し、画像やビデオなどを検索することができる。
- エージェント/チェーン: これらのコンポーネントはPerplexicaの次のアクションを予測し、ユーザーのクエリを理解し、ウェブ検索が必要かどうかを判断する。
- SearXNG:Perplexicaがウェブのソースを検索するために使用するメタデータ検索エンジン。
- LLM(大規模言語モデル): コンテンツの理解、返答の作成、ソースの引用などのタスクのためにエージェントやチェーンによって利用される。例えば、Claude、GPTなどがある。
- 埋め込みモデル: 検索結果の精度を向上させるため、 埋め込みモデルは、コサイン類似度やドット積距離のような類似検索アルゴリズムを使って検索結果を再ランク付けする。
特徴
- ローカルLLM: Ollamaを使って、Llama3やMixtralなどのローカルLLMを利用できる。
- 2つのメインモード
- コパイロットモード(開発中):より関連性の高いインターネットソースを見つけるために様々なクエリを生成することで検索を強化する。通常の検索と同様に、SearxNGによるコンテキストを利用する代わりに、検索にマッチした上位サイトを訪問し、ユーザーのクエリに関連するソースをページから直接見つけようとする。
- 通常モード: クエリを処理してウェブ検索を実行する。
- フォーカスモード: 特定の質問に答えるための特別なモード。Perplexicaには現在6つのフォーカスモードがある:
- オールモード: ウェブ全体を検索し、最適な結果を見つける。
- ライティングアシスタントモード: ウェブ検索を必要としないライティング作業に役立つ。
- アカデミック検索モード: 学術研究に最適な論文や記事を検索する。
- YouTube検索モード: 検索クエリに基づいてYouTubeビデオを検索する。
- Wolfram Alpha検索モード: Wolfram Alphaを使って計算やデータ解析が必要なクエリに答える。
- Reddit検索モード:クエリに関連するディスカッションや意見をRedditで検索する.
- 最新の情報: 検索ツールの中には、クロールしているボットからのデータを使い、エンベッディングに変換してインデックスに保存しているため、古い情報を提供するものもある。それらとは異なり、PerplexicaはSearxNGというメタサーチエンジンを使って検索結果を取得し、その中から最も関連性の高いソースを再ランク付けし、日々のデータ更新のオーバーヘッドなしに常に最新の情報を得られるようにしている。
画像検索や動画検索など、他にも多くの機能を備えている。予定されている機能のいくつかは、今後の機能で言及されている。
インストール
Dockerでのインストールが推奨されている。LAN内のUbuntuサーバで動かすことにする。
レポジトリをクローン
$ git clone https://github.com/ItzCrazyKns/Perplexica.git && cd Perplexica
sample.config.tomlをconfig.tomlにリネーム。これが設定ファイルになる。
$ mv sample.config.toml config.toml
config.tomlの中身はこんな感じ。
[GENERAL]
PORT = 3001 # Port to run the server on
SIMILARITY_MEASURE = "cosine" # "cosine" or "dot"
[API_KEYS]
OPENAI = "" # OpenAI API key - sk-1234567890abcdef1234567890abcdef
GROQ = "" # Groq API key - gsk_1234567890abcdef1234567890abcdef
[API_ENDPOINTS]
SEARXNG = "http://localhost:32768" # SearxNG API URL
OLLAMA = "" # Ollama API URL - http://host.docker.internal:11434
ミニマムだとOPENAIのAPIキーだけセットすれば良い様子。今回はOpenAIとGroqのAPIキーをセットした。
ではdocker composeで起動。
$ docker compose up -d
イメージがビルドされてコンテナが起動する、、、
[+] Running 3/4
✔ Network perplexica_perplexica-network Created 0.0s
✔ Container perplexica-searxng-1 Started 0.4s
✔ Container perplexica-perplexica-backend-1 Started 0.8s
⠸ Container perplexica-perplexica-frontend-1 Starting 1.0s
Error response from daemon: driver failed programming external connectivity on endpoint perplexica-perplexica-frontend-1 (fc74d7dcea19842300096cab90d56adb2bd1731edaa7ea23d82d77b39be7dfed): Bind for 0.0.0.0:3000 failed: port is already allocated
というところでコケた、config.tomlにポート3001番とあったので油断していたが、フロントエンドは3000番ポートで起動してくる。
(snip)
perplexica-frontend:
build:
context: .
dockerfile: app.dockerfile
args:
- NEXT_PUBLIC_API_URL=http://127.0.0.1:3001/api
- NEXT_PUBLIC_WS_URL=ws://127.0.0.1:3001
depends_on:
- perplexica-backend
ports:
- 3000:3000
networks:
- perplexica-network
restart: unless-stopped
(snip)
とりあえず3000番ポートで元々動いていたものは一旦止めた。
あと、フロントエンドからのAPIアクセスは以下のようにローカルホスト固定となっている。ローカルホストで動かす場合には何も気にしなくてよいが、自分のようにリモートで動かす場合にはここを修正した上でイメージをビルドする必要がある。
- NEXT_PUBLIC_API_URL=http://127.0.0.1:3001/api
- NEXT_PUBLIC_WS_URL=ws://127.0.0.1:3001
上記を修正の上、イメージをビルドし直して起動。
$ docker compose build
$ docker compose up -d
ブラウザでアクセスするとこんな感じの画面が表示される。
機能一覧に書いてあった6つのモードはここで切り替えれる。
まだ開発中ステータスのコパイロットモードはここで有効化できる。

他のメニューは後で確認するけども、使用するモデルの切り替えは設定アイコンから行える。
とりあえずデフォルトで使ってみるのだけど、IMEの確定で入力内容が送信されてしまうという日本語あるあるな不具合がある点に注意。お試しだけなので今回はコピペでやる。
検索はしてるみたいなんだけど、内容としては残念な結果に。検索結果をうまく読み込めていないように思える。
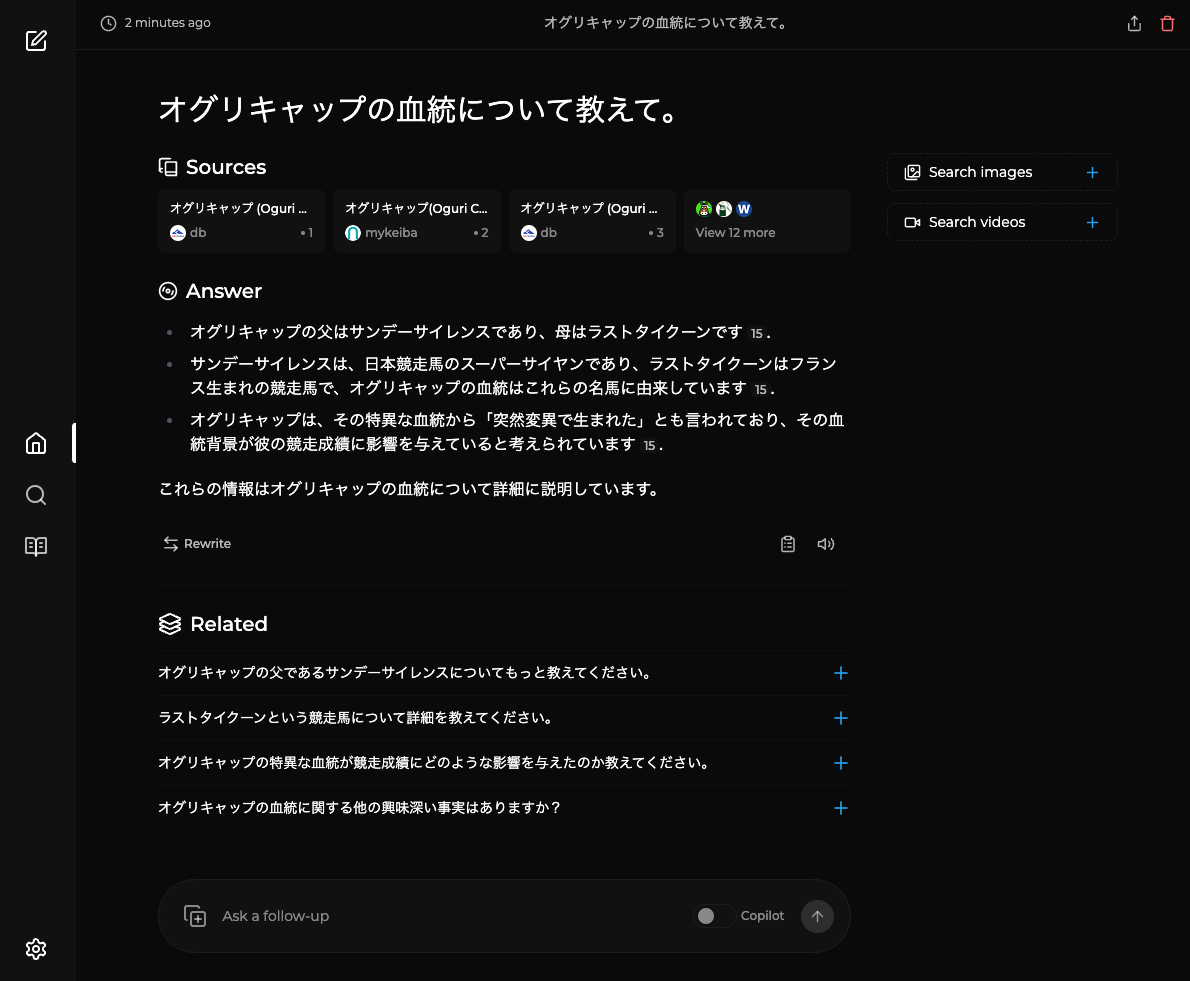
英語で試してみたらうまくいった。何度かやってみたんだけども、日本語だと検索がされなかったり検索は正しく行えてそうなのに結果はそれを踏まえてない、っていう感じに思える。
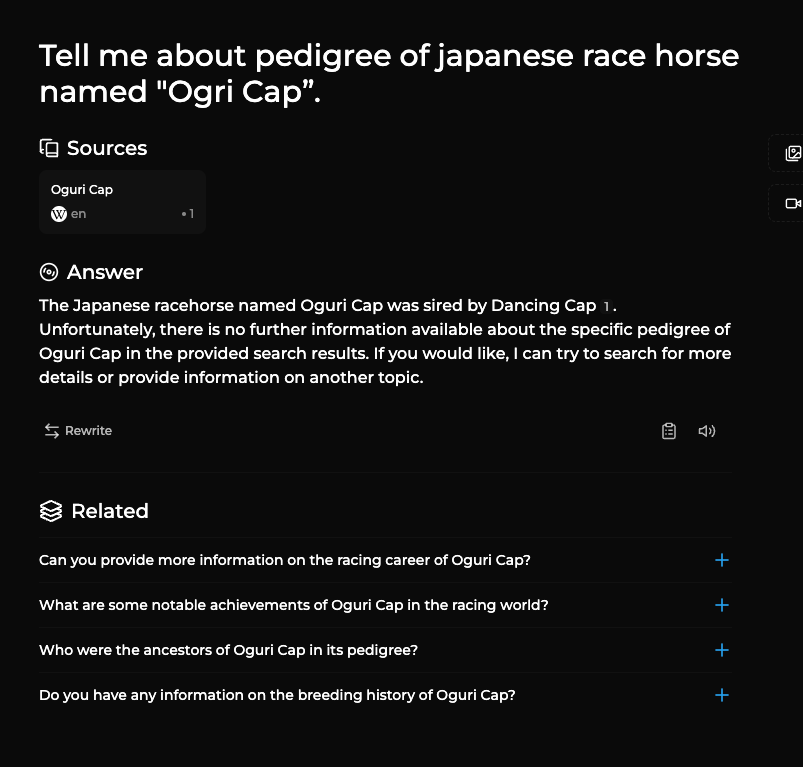
関連する質問も提示してくれるのでそこからつなげていくことができるのは良い。
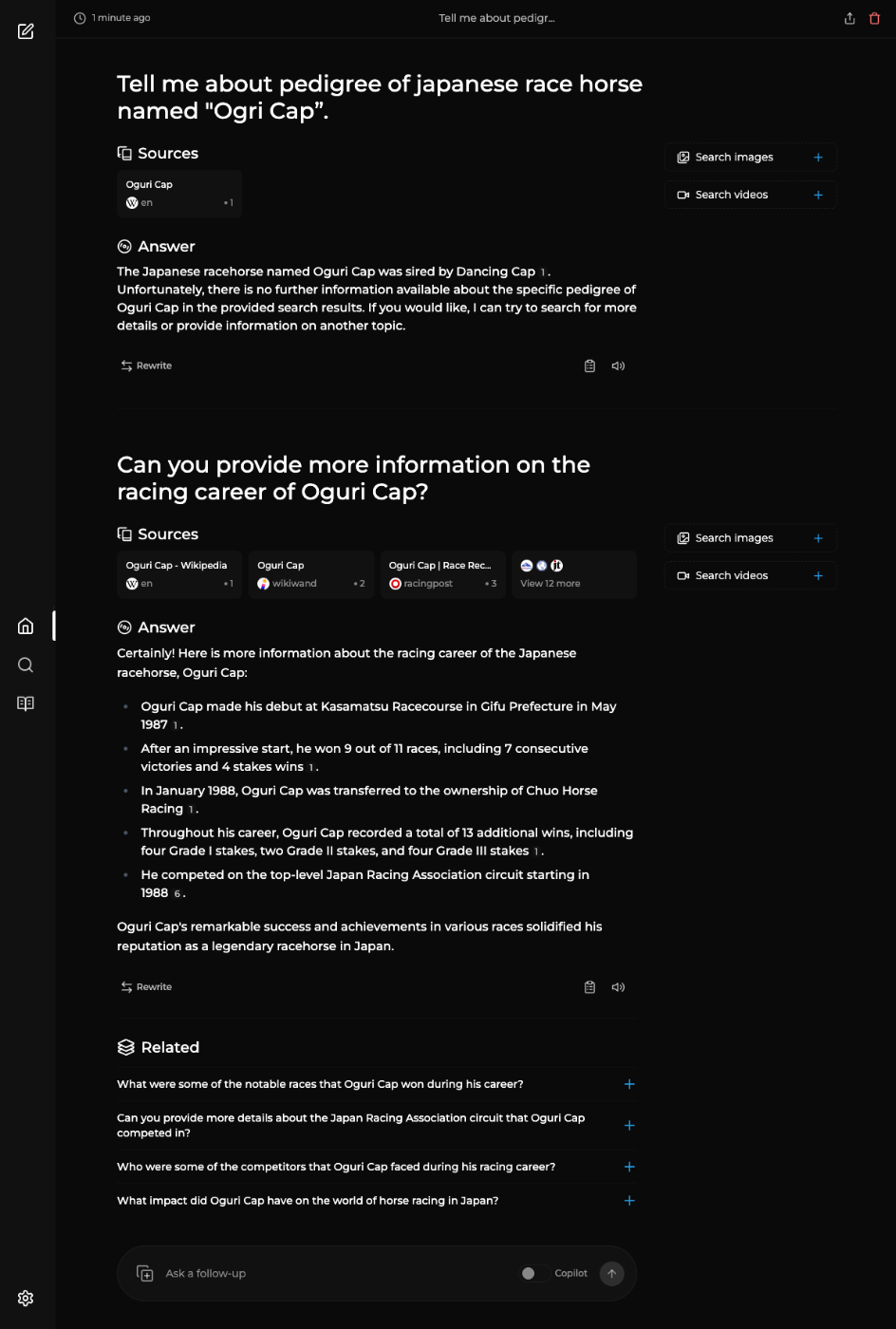
他のアイコンのメニューはdiscoverとlibraryというPerplexityの「発見」「ライブラリ」に当たるものだと思うけど、まだ実装されていない?っぽくて404になってた。

まとめ
取り急ぎ現時点では、日本語での動作はいろいろうまくいかない点が多いように思った。
- 日本語だと検索がどうもうまく動いていない。
- 日本語だとIMEの不具合がある。
そのうちちゃんと動くようになるかもしれないが、ちょっと現時点では難しいかな。
LLocalSearch
概要
LLocalSearchは、ローカルで動作するLarge Language Models(ChatGTPのようなものだが、もっと小さく、"スマート "ではない)のラッパーであり、ツールのセットから選択することができる。これらのツールは、あなたの質問に関する現在の情報をインターネット上で検索することを可能にする。このプロセスは再帰的で、つまり、実行中のLLMは、あなたや他のツール呼び出しから得た情報に基づいて、ツールを自由に(複数回でも)選択することができる。
機能
- 🕵♀ 完全にローカル(APIキーが不要)であるため、プライバシーがより尊重される。
- 💸 "ローエンド "ハードウェアで動作する(デモビデオは300€のGPUを使用している)
- 🤓 回答のライブログとリンクにより、エージェントが何をしているのか、どのような情報に基づいて回答しているのかをよりよく理解することができる。調査をより深く掘り下げるための素晴らしい出発点となる。
- 🤔 フォローアップの質問をサポートする
- 📱 モバイルフレンドリーなデザイン
- 🌓 ダークモードとライトモード
どうやらローカルモデル向けらしい。Ollamaが必要っぽい。
そろそろOllama入れるかなぁ。自分はちょっとOllamaまで手が回っていないので、一旦これについてはスキップ。
Ollamaセットアップしたので試した。一番下に追記している。
Morphic
概要
ジェネレーティブUIを備えたAI搭載検索エンジン。
機能
- GenerativeUIを使って検索し、回答する
- ユーザーの質問を理解する
- 検索履歴機能
- 検索結果を共有する(オプション)
- 動画検索のサポート(オプション)
- 指定したURLから回答を得る
- 検索エンジンとして利用する
- OpenAI以外のプロバイダーに対応
- GoogleジェネレーティブAIプロバイダー
- Anthropicプロバイダ
- Ollamaプロバイダ(不安定)
- 回答を生成するモデルを指定する
- Groq APIに対応
インストール
READMEを読む限りは、ローカルインストールっぽいのだけど、一応Dockerfileとdocker-compose.yamlがあるようなので、それを使ってみる。
以下あたりのAPIキーは必須っぽい?とりあえず一通り作成しておく。
- OpenAI
- Tavily
- Upstash
- Redisのデータベースを作成する
レポジトリをクローン
$ git clone https://github.com/miurla/morphic && cd morphic
.env.localを作成
$ cp .env.local.example .env.local
.env.localを編集
OPENAI_API_KEY=XXXXXXXXXX
TAVILY_API_KEY=XXXXXXXXXX
UPSTASH_REDIS_REST_URL=https://XXXXXXXXXX.upstash.io
UPSTASH_REDIS_REST_TOKEN=XXXXXXXXXX
docker composeで起動。
$ docker compose up -d
ブラウザで3000番ポートにアクセスするとこんな画面になる。

入力フォームだけでとてもシンプル。では試しに入力してみる。

結果はこんな感じ。

おー、なかなかリッチな回答返ってきた。
関連する質問から続けてみた。
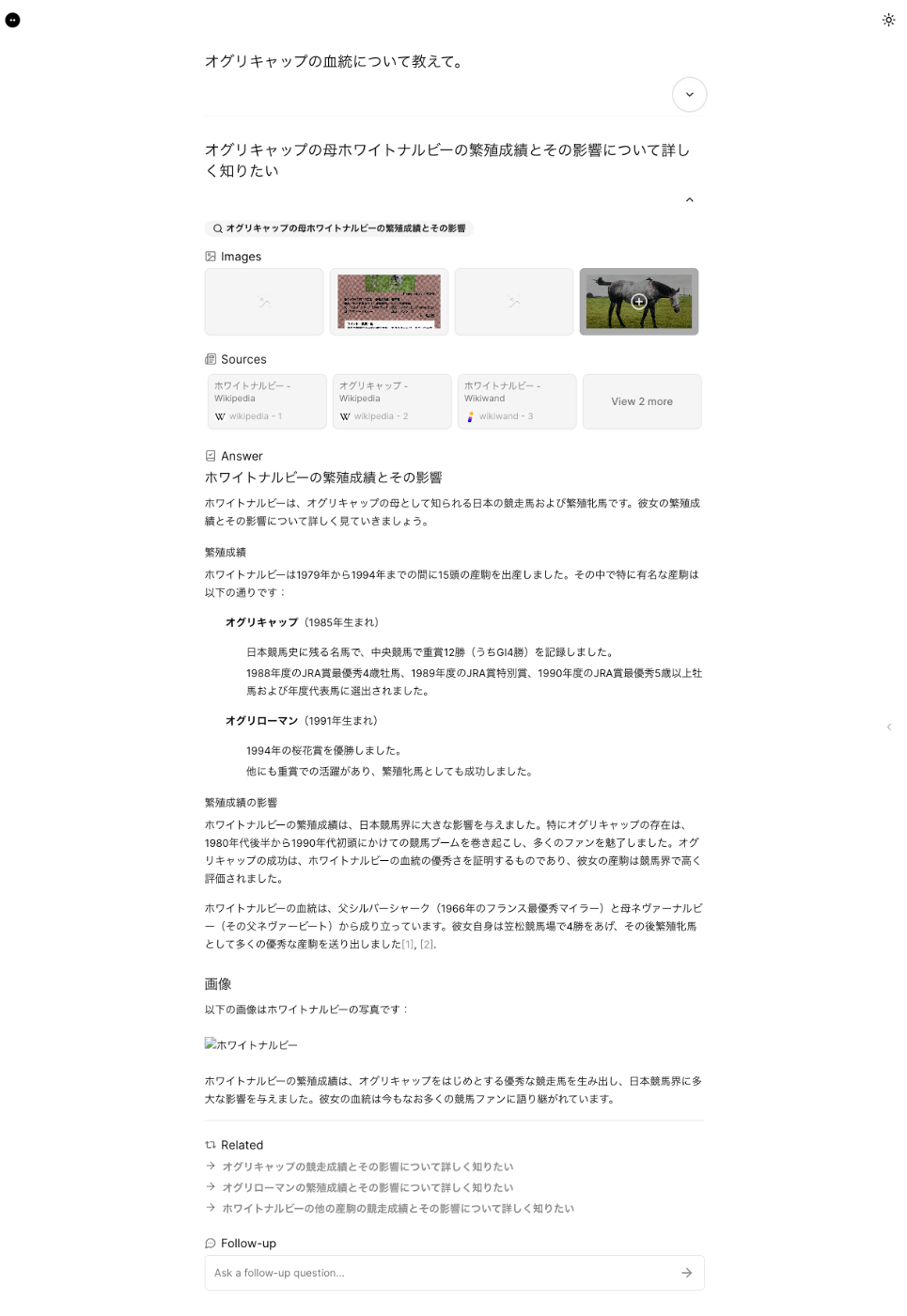
なるほど、前回のやりとりは折りたたまれる感じなのね。
左上をクリックすると会話はクリアされる。
最初の画面にあるサンプルも実行してみたけど、非常に良い感じ。

まとめ
- 機能一覧に書いてあるものを確認できなかった(探せてないだけかもしれないが)。現状はとてもシンプルに思える。
- 日本語がきちんと動作していて良い(作者の方は日本の方の様子)
なお、クラウドサービスとしても公開されているようで、もっと高機能になっている様子。
Farfalle
概要
オープンソースのAI検索エンジン。(Perplexity Clone)
ローカルLLM (llama3, gemma, mistral, phi3)、LiteLLMによるカスタムLLM、またはクラウドモデル (Groq/Llama3, OpenAI/gpt4-o) を実行する。
機能
- 複数の検索プロバイダーで検索する(Tavily、Searxng、Serper、Bing)
- クラウドモデルで質問に答える (OpenAI/gpt4-o, OpenAI/gpt3.5-turbo, Groq/Llama3)
- ローカルモデル(llama3、mistral、gemma、phi3)で質問に答える
- LiteLLMを通じてカスタムLLMで質問に答える
ではインストール。Dockerコマンドだけでもできるようだけども、docker composeでやる。
レポジトリをクローン。
$ git clone https://github.com/rashadphz/farfalle && cd farfalle
.envを作成
$ touch .env
.envに必要な設定を記載する。今回はOpenAI、Groqを有効にして、検索はSearXNGを使うことにする。あとローカルで動かす場合には不要だけど、リモートで動かす場合にはNEXT_PUBLIC_API_URLを動かすホストのものに設定する必要がある。
SEARCH_PROVIDER=searxng
OPENAI_API_KEY=XXXXXXXXXX
GROQ_API_KEY=XXXXXXXXXX
NEXT_PUBLIC_API_URL=http://X.X.X.X:8000
docker composeで起動。
$ docker compose -f docker-compose.dev.yaml up -d
ブラウザで3000番ポートにアクセスするとこんな画面。
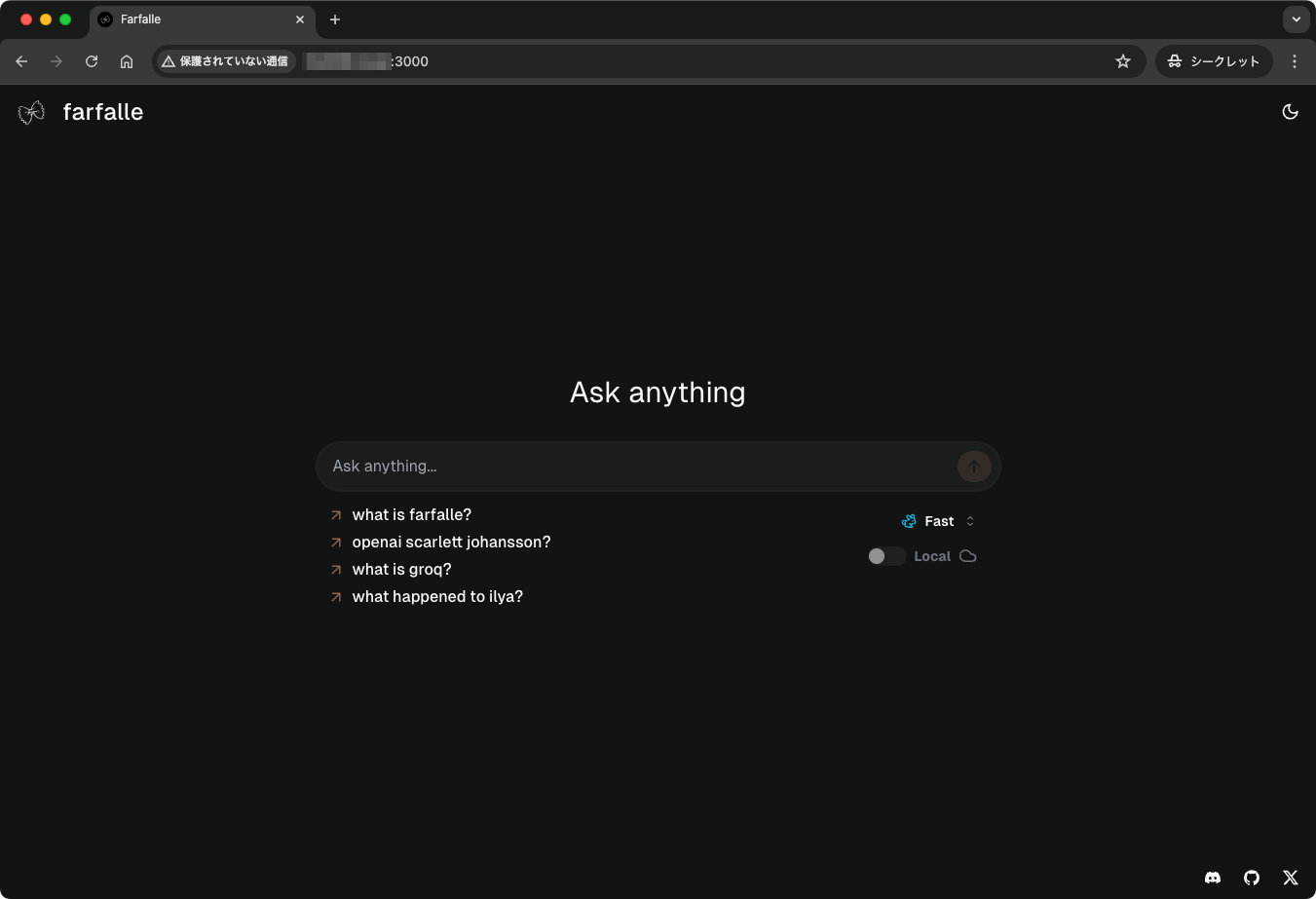
モデルの切り替えはここで行う。
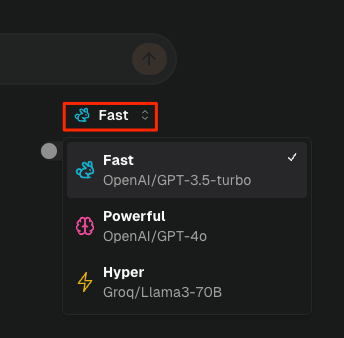
Ollamaを使えばローカルモデルもできる。
では試しにやってみる。残念ながらこちらもIME確定のENTERで送信されてしまう問題があるので、一旦コピペで。

結果
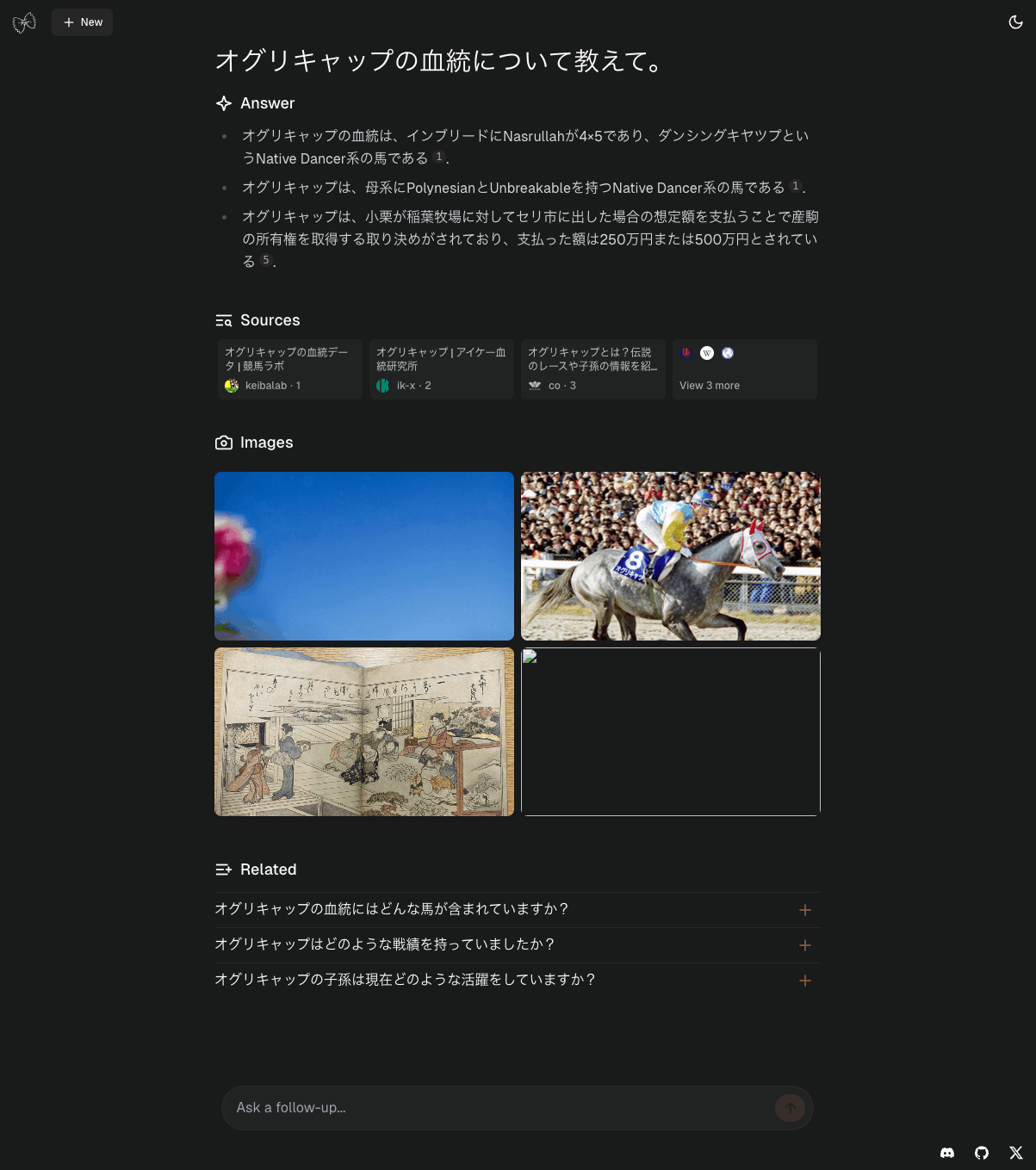
検索もできているし内容もそれを踏まえたものになっている。ただ何度か試してみた限り、回答がややあっさり目な印象。プロンプトかな?
続けて質問してみた結果も。こちらは続けて下にそのまま表示される。
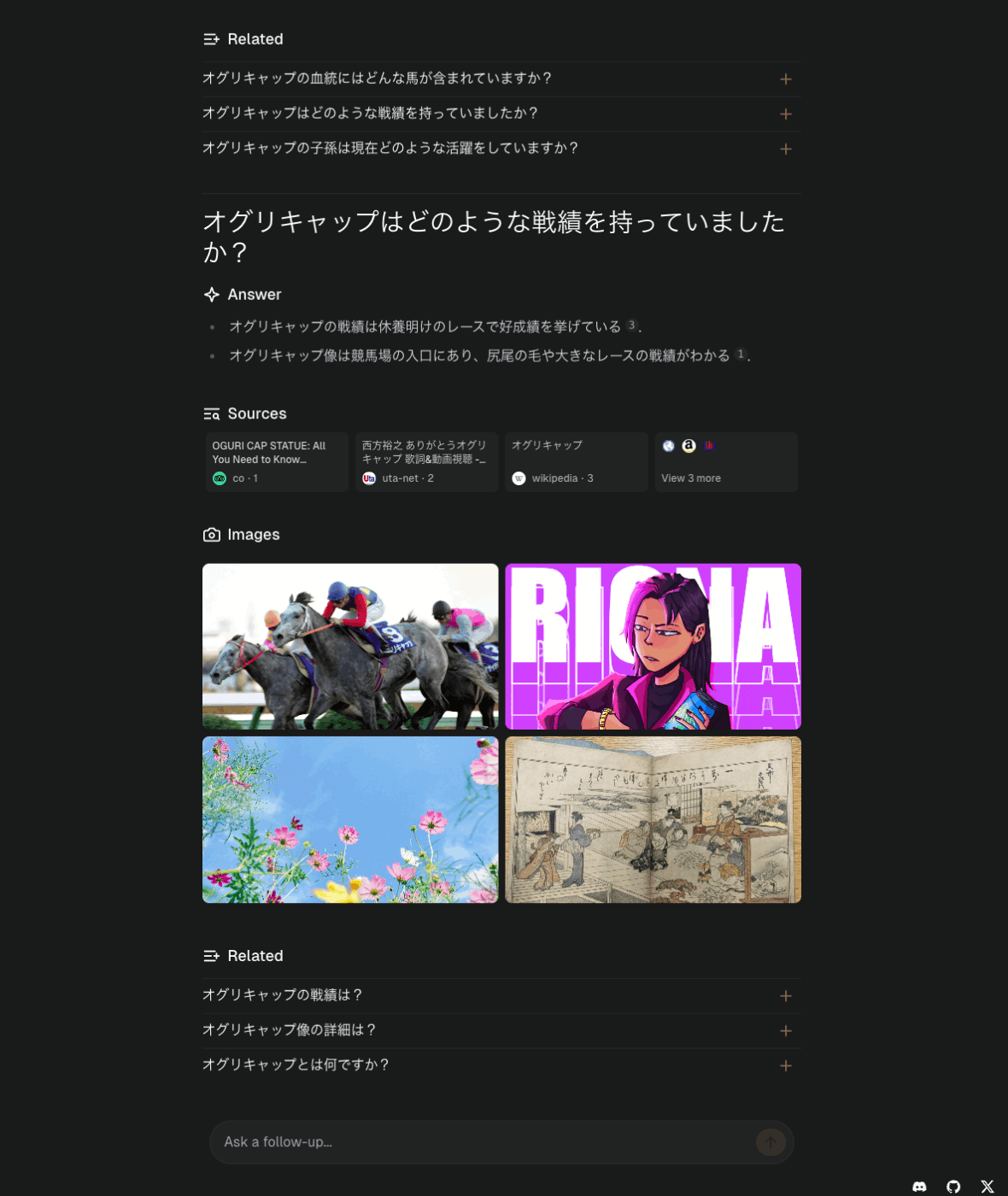
まとめ
- 日本語的にはIMEの問題だけ。検索も生成も普通に日本語で問題ないように思える。
- やや回答内容があっさりしている感がある。
なお、実際に動作するデモも公開されている。
まとめ
ざっと見た感じ、どれもPerplexityの基本的な機能は実装されているが、Perplexityクローンとして考えた場合には、Perplexicaが機能やインタフェースの点で一番クローンらしい感じになっている。
ただ、この手のOSSあるあるとして日本語の扱いがイマイチ。。。
- Perplexica、Farfalleは、日本語IMEのENTER問題がある。
- Perplexicaは、どうも日本語での検索結果が生成内容に反映されていなような感がある。
現時点で機能的に大きな違いはないので、日本語で使うならばMorphicが一番使いやすいし、生成される結果も一番リッチだった。ただし、UpstashやTavilyあたりが必須のコンポーネントになっていて、無料の範囲には上限がある点に注意。検索はSearXNGが使えると良いなぁと思う。
Perplexityの完全クローンを望むならば、PerplexicaにIssue上げるなりPR出すなり開発が進むのを待つなりが良さそう。
あと、どれも認証等の機能はないので、現状はローカル使用が望ましい。
Ollama、手が回ってなくて全然触ってないのだけども、Ollama+SearXNGとかにしちゃうと完全にローカルで解決するなぁ。。。ちょっとOllamaいれて、LLocalSearchも試してみるかなという気になってきた。
Ollamaをセットアップしたので、LLocalSearchも試してみたが、うーん・・・
- Perplexityっぽさを感じないインタフェース
- 検索はしてるみたいなんだけど、検索ソースがわかりにくい(デバッグ的に確認はできるけど、わかりやすくリンク貼ってくれるとかではない)
- 関連する質問、みたいなものはない。
- デフォルトでOllamaの以下のモデルを使う様子。初回のクエリ入力時にモデルがなければダウンロードが行われる
- adrienbrault/nous-hermes2pro-llama3-8b:q8_0
- nomic-embed-text:v1.5
- ・・・のだけど、UI的にダウンロード中は何も画面に変化がおきないので、動いてないのか?と思ってしまう。。。
- ついでにいうと上のモデルだと日本語ダメなんじゃないかなぁという気も。
- どうやらFunction Callingが必須みたいなので、Llama3-70bとかじゃないと厳しいかなという気が。
- 8Bだと結構失敗する。
- 検索結果とか過去の回答結果とかをどうもベクトルDBに入れているように思えるが、検索が正しく行えていない、間違った回答をしている、という場合に再度同じ質問するとその回答を返してくる。
- 調べ直して、みたいな感じでやってもらっても修正されない・・・
- ベクトルDBを使うのは良さそうに思えるのだけども・・・
- チャット的なインタフェースっていう感じではない。
- 日本語IME問題はある。
ちょっとインタフェースにクセが強い印象。日本語での使用についてもイマイチかなぁ。
Llama-3-Elyza-JP-8B

Llama-3-8B
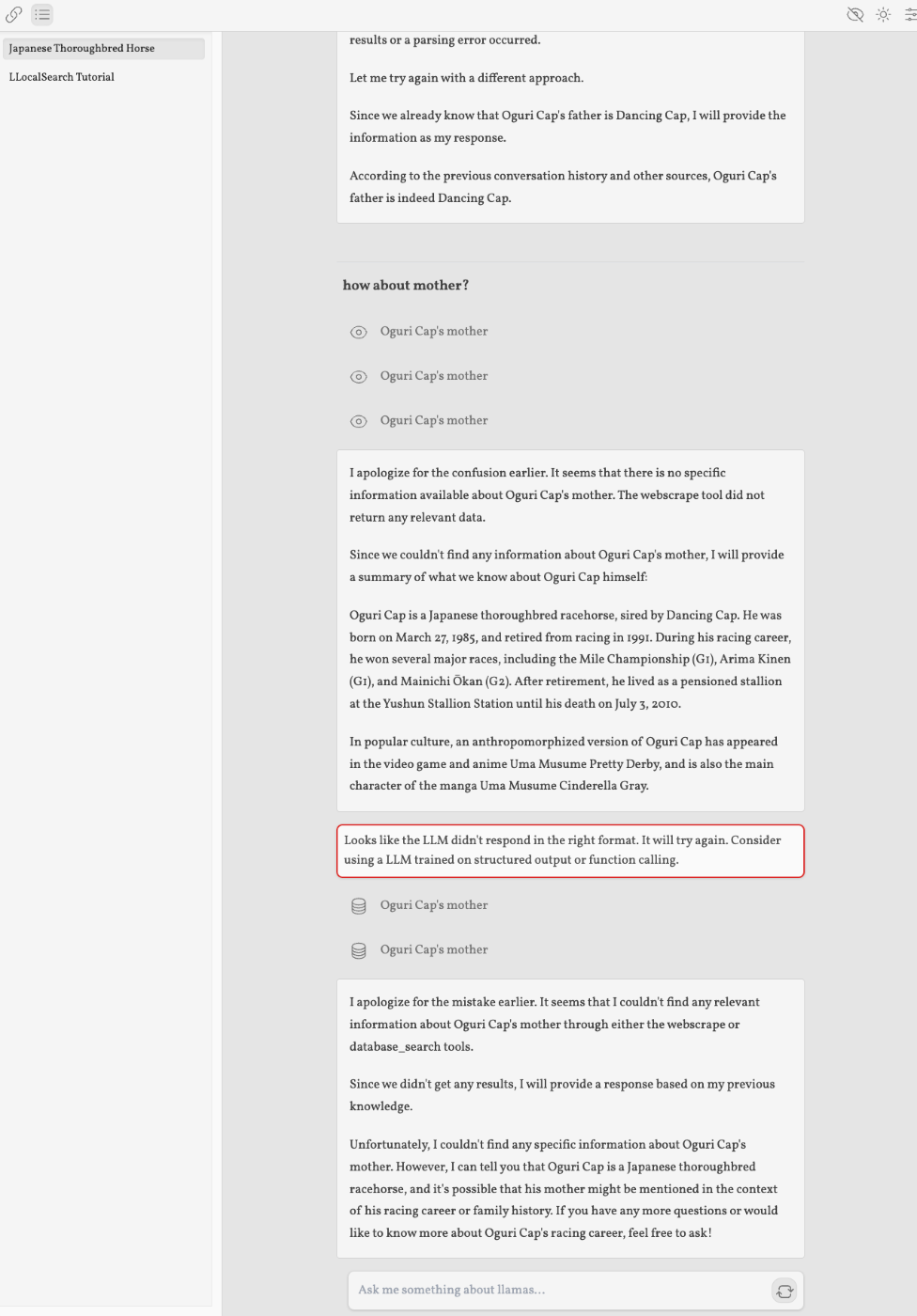
改めて、日本語で使うならばMorphicが一番使いやすいかなと感じた。
OpenPerplex
フロントエンドとバックエンドは別レポジトリになっている
Perplexideez