今更ながら「OpenCV」を試す
これ見て俄然興味が出たので、今更感あるけどちゃんと触ったことないので試してみる。
あとこういうのも気になっている
公式はこちら
なのだけど、なんかオンラインコースに誘導される。とりあえず試してはみたものの、動画が中心になっていて、個人的にはドキュメントスタイルで自分のペースで進めるほうが好み。
一応ここにあるみたいなのだけども、なんかとても使いづらい・・・
書籍のほうがいいのかしら、と思ったけども、それだとZennにメモるのは若干憚られるなぁ、と思っていたら、どうやらこちらが良さそう。(タイトルは違う)
とりあえずここのGetting Startedを眺めてみる。
learnopencv.comのGetting Startedをいろいろ見てみたが、まず環境構築が面倒そう。ソースからインストールってのがOpenCVの標準なのかな?
手元で環境作ろうと思ったけど、とりあえずまずはPythonで画像処理の基本的なやり方とかを試したいので、Colaboratoryでやることにする。GPUも使えるだろうし。
以下のOpenCV For Beginnersに従って進める
なお、Colaboratoryだとあらかじめインストールされている様子。
import cv2
cv2.__version__
'4.12.0'
画像の読み込み・表示・書き込み
画像の基本
-
imread(): 画像を読み込む -
imshow(): 画像をウィンドウに表示する関数です。 -
imwrite(): 画像をファイルに保存
サンプル画像をダウンロード
!wget https://learnopencv.com/wp-content/uploads/2021/04/input-image-for-demo-throughout-1024x682.jpg -O test.jpg
上記の基本的な関数を一通りまとめたもの。
# cv2ライブラリをインポート
import cv2
# cv2.imread() で画像を読み込む
img_grayscale = cv2.imread('test.jpg',0)
# cv2.imshow() で画像をウィンドウに表示
cv2.imshow('grayscale画像',img_grayscale)
# waitKey() でウィンドウを閉じるためのキー入力を待つ。0を指定すると無限ループ。
cv2.waitKey(0)
# cv2.destroyAllWindows() で、作成したすべてのウィンドウを単純に破棄。
cv2.destroyAllWindows()
# cv2.imwrite() で画像をファイルに保存
cv2.imwrite('grayscale.jpg',img_grayscale)
エラー。なるほど、imshow()はウインドウを開いて表示するが、ノートブック環境だとそれができないってことね。表示はColaboratory用の代替が用意されている。
DisabledFunctionError: cv2.imshow() is disabled in Colab, because it causes Jupyter sessions
to crash; see https://github.com/jupyter/notebook/issues/3935.
As a substitution, consider using
from google.colab.patches import cv2_imshow
上記に置き換え、ウインドウの制御用の関数も使えないと思うので、削除。再実行。
import cv2
from google.colab.patches import cv2_imshow
img_grayscale = cv2.imread('test.jpg',0)
cv2_imshow(img_grayscale) # 引数は1つだけ
cv2.imwrite('grayscale.jpg',img_grayscale)

画像の読み込み
imread(ファイル名, フラグ)
フラグはオプションで、画像の表示形式を指定できる。複数のオプションがあるが、一般的なのは以下。
-
cv2.IMREAD_UNCHANGED/-1: 画像をそのまま読み込む。 -
cv2.IMREAD_GRAYSCALE/0: シングルチャネルのグレイスケール画像に変換して読み込む。 -
cv2.IMREAD_COLOR/1: カラー画像として読み込む。デフォルト。
注意点として、一般的にカラー画像はRGBのチャネル順で表現されるが、OpenCVでBGRの順序になる。他のライブラリなどと併用する場合にはチャネルを入れ替える必要がある。
それぞれの形式を指定して読み込んで表示する例
img_grayscale = cv2.imread('test.jpg',cv2.IMREAD_COLOR)
cv2_imshow(img_color)

img_grayscale = cv2.imread('test.jpg',cv2.IMREAD_GRAYSCALE)
cv2_imshow(img_grayscale)

img_unchanged = cv2.imread('test.jpg',cv2.IMREAD_UNCHANGED)
cv2_imshow(img_unchanged)

画像の表示
ここはちょっとノートブックだと試せないので、まとめだけ。
imshow(ウィンドウ名, 画像)
ウインドウ名は画像のウインドウに表示される名前で、複数の場合にはそれぞれ別の名前をつける。
また、ウインドウを制御するため、以下の関数と組み合わせることが前提となっている。
-
waitKey()- キーボード操作を制御する。
- 引数でウインドウが表示される時間(ms)を指定。ユーザがキーを入力すると継続。0を指定すると無限ループで待機。
- 入力されたキーを返すので、特定のキー(QやESCなど)に対する操作を制御することもできる。
-
destroyAllWindows()- 作成した全てのウインドウを破棄
-
destroyWindow()- 特定のウインドウのみを破棄。ウインドウ名を引数で指定できる。
注意として、waitKey()の操作は直感的ではないため、十分に確認すること、とある。
画像の書き込み(保存)
cv2.imwrite(ファイル名, 画像データ)
動画の読み込み・書き込み
動画の読み込みや書き込み。
-
cv2.VideoCapture(): 動画キャプチャオブジェクトを作成。これにより動画のストリーミングや表示が可能になる。 -
cv2.VideoWriter)0: 動画を指定したディレクトリに出力・保存。 - その他、
VideoCapture.get()で動画のメタデータ(総フレーム数やフレームレートなど)を取得したり、VideoCapture.get()で該当のフレームデータを取得したり、など。
で、サンプルの動画が用意されているのだが、ダウンロードにはメアドの登録が必要・・・ちょっとOpenCVはこういうのが目立つなぁ・・・
Pixabayのものを使用させてもらう。
import cv2
from google.colab.patches import cv2_imshow
# 動画キャプチャオブジェクトを作成。この例ではファイルから動画を読み込む。
vid_capture = cv2.VideoCapture('7969-205946421_small.mp4')
if (vid_capture.isOpened() == False):
print("動画ファイルのオープンに失敗しました")
# フレームレートと総フレーム数を取得
else:
# フレームレート情報を取得
# 5の代わりにCAP_PROP_FPSを使用してもOK。
fps = vid_capture.get(5)
print('フレームレート : ', fps,'FPS')
# フレーム数を取得
# 7の代わりにCAP_PROP_FRAME_COUNTを使用してもOK。
frame_count = vid_capture.get(7)
print('フレーム数 : ', frame_count)
cnt=1
while(vid_capture.isOpened()):
# vid_capture.read() はタプルを返す。最初の要素はbool、2番目の要素は実際のフレームデータ。
ret, frame = vid_capture.read()
if ret == True:
if cnt % 10 == 0: # フレーム数が多いので一部のみ表示
print(f"フレーム {cnt}:")
cv2_imshow(frame)
else:
break
cnt += 1
# ビデオキャプチャオブジェクトを解放
vid_capture.release()


ファイルからの動画読み込み
動画はVideoCapture()クラスを使って、ファイルなどからVideoCaptureオブジェクトを作成し、それに対して操作を行う。
VideoCapture(ファイルパス, API設定)
ファイルからの読み込みはシンプルに動画パスを指定する。
vid_capture = cv2.VideoCapture('7969-205946421_small.mp4')
ファイルが正常に開かれたかどうかは isOpened()でチェックできる。
vid_capture.isOpened()
True
開かれない場合はFalseが返る。ドキュメントにはエラーメッセージが表示されるとあるが、そういうものはないし、cv2.VideoCaptureも特にエラーは返さないってことなのかな?
failed_vid_capture = cv2.VideoCapture('not_exists.mp4')
failed_vid_capture.isOpened()
False
動画ファイルを開くとVideoCaptureオブジェクトが作成される。このオブジェクトに対してget()メソッドを使うと、動画のメタデータが取得できる。引数でどのメタデータにアクセスするかを指定する。設定できるENUMのリストは以下にある。
fps = int(vid_capture.get(5))
print("フレームレート : ",fps,"フレーム/秒")
frame_count = vid_capture.get(7)
print("フレーム数 : ", frame_count)
フレームレート : 29 フレーム/秒
フレーム数 : 586.0
VideoCaptureオブジェクトから個々のフレームの画像を読み出すにはVideoCapture.read()を使う。これはタプルを返し、
- 読み込むフレームが存在するか(bool)
- 実際のフレーム
となるため、ループで取得すれば全部読み込める。
while True:
ret, frame = vid_capture.read()
if not ret:
break
cv2_imshow(frame)
画像シーケンスの読み込み
動画ファイルは複数のフレーム画像を1つにしたものと同じだが、逆に複数の画像を一連のシーケンスとして読み込んで、VideoCaptureオブジェクトを作成することもできる。
ちょっと逆説的だけれど、動画から各フレームを画像として切り出す。
import cv2
from google.colab.patches import cv2_imshow
vid_capture = cv2.VideoCapture('7969-205946421_small.mp4')
if (vid_capture.isOpened() == False):
print("動画ファイルのオープンに失敗しました")
else:
cnt = 1
while True:
ret, frame = vid_capture.read()
if not ret:
break
cv2.imwrite(f'sample{cnt:04d}.jpg', frame)
cnt += 1
vid_capture.release()
ls *jpg | head
sample0001.jpg
sample0002.jpg
sample0003.jpg
sample0004.jpg
sample0005.jpg
sample0006.jpg
sample0007.jpg
sample0008.jpg
sample0009.jpg
sample0010.jpg
これを読み出してみる。
vid_capture = cv2.VideoCapture('sample%04d.jpg')
if (vid_capture.isOpened() == False):
print("画像シーケンスファイルのオープンに失敗しました")
else:
fps = int(vid_capture.get(5))
print("フレームレート : ",fps,"フレーム/秒")
frame_count = vid_capture.get(7)
print("フレーム数 : ", frame_count)
フレームレート : 25 フレーム/秒
フレーム数 : 586.0
Webカメラからの読み込み
Webカメラなどの呼び出す場合はビデオキャプチャデバイスのインテックスを指定するだけ。
vid_capture = cv2.VideoCapture(0, cv2.CAP_DSHOW) # cv2.CAP_DSHOWはオプション、なくてもよい。
動画の書き込み
動画・画像シーケンス・ウェブカメラなどから作成したVideoCaptureオブジェクトをファイルに保存する。
ファイルに保存するにはVideoWriter()を使う。
VideoWriter(filename, apiPreference, fourcc, fps, frameSize[, isColor])
-
filename: 出力する動画ファイルのパス名 -
apiPreference: APIバックエンドの識別子 -
fourcc: フレーム圧縮に使用するコーデックの4文字コード(fourcc) -
fps: 生成する動画ストリームのフレームレート -
frame_size: 動画フレームのサイズ(幅・高さ) -
isColor: カラーで処理するか- 0の場合はグレースケールフレームで処理、0以外はカラーフレームで処理
- このフラグは現在Windows環境でのみサポート。
この fourcc というやつは以下で確認できるのだが、種類が沢山あってよくわからん・・・
とりあえず
- AVI:
cv2.VideoWriter_fourcc('M', 'J', 'P', 'G') - MP4:
cv2.VideoWriter_fourcc('X', 'V', 'I', 'D')
みたいな感じで設定すれば良いみたい。
で実際に保存する場合は、
-
VideoCaptureを開く - フレームの高さ・幅を取得
- 上記+コーデックなどを指定して
VideoWriterオブジェクトを作成 - ストリームを書き出し
という感じ。1つ上で画像シーケンスからの読み込みを試したが、それを使って動画ファイル(mp4)に出力してみる。
vid_capture = cv2.VideoCapture('sample%04d.jpg')
if (vid_capture.isOpened() == False):
print("画像シーケンスファイルのオープンに失敗しました")
else:
# フレームの高さ、幅を取得
frame_width = int(vid_capture.get(3)) # CAP_PROP_FRAME_WIDTH
frame_height = int(vid_capture.get(4)) # CAP_PROP_FRAME_HEIGHT
frame_size = (frame_width,frame_height)
fps = 20
output = cv2.VideoWriter(
'output_video_from_file.mp4',
cv2.VideoWriter_fourcc('X','V','I','D'),
fps,
frame_size
)
while True:
ret, frame = vid_capture.read()
if ret == True:
# フレームを出力ファイルに書き込み
output.write(frame)
else:
print('Stream disconnected')
break
vid_capture.release()
こんな感じで手元では再生できた。

その他よくあるエラーについても書いてあるので参考に。
画像のリサイズ
画像のリサイズ。画像のリサイズは以下が重要になる。
- 画像のアスペクト比(高さ・幅の比率)を維持する場合は、リサイズ後もこの比率を維持する必要がある
- 画像のサイズを縮小する場合は、ピクセルの再サンプリングが必要
- 画像のサイズを拡大する場合は、新しいピクセルを保管して、画像の再構築が必要
これらの操作を行うには様々な補間手法があり、OpenCVでは複数の補間手法に対応している。
ドキュメントのサンプル画像を取得。
!wget https://learnopencv.com/wp-content/uploads/2021/04/image-e1619470839641.jpg -O image.jpg
import IPython.display
IPython.display.Image("image.jpg", width=800)
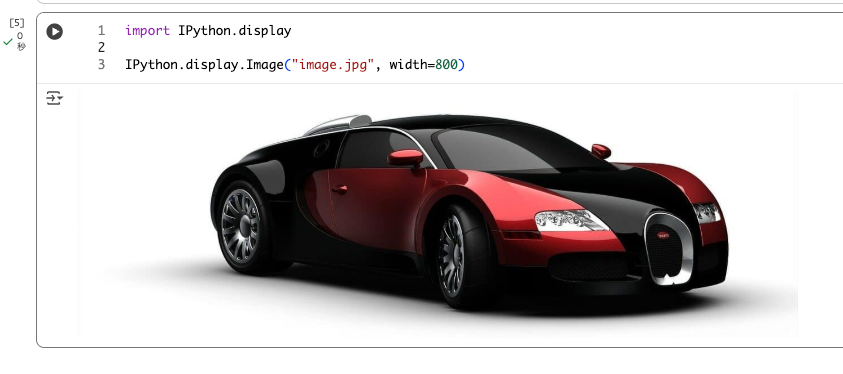
リサイズは cv2.resize()を使う。比率で高さ・幅を調整する方法と、個別にサイズを指定する方法があるが、以下は個別にサイズを指定した場合。
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
image = cv2.imread('image.jpg')
print('元の画像')
cv2_imshow(image)
# 新しい幅と高さを使用して画像を縮小
down_width = 300
down_height = 200
down_points = (down_width, down_height)
resized_down = cv2.resize(image, down_points, interpolation= cv2.INTER_LINEAR)
# 新しい幅と高さを使用して画像をアップスケール
up_width = 600
up_height = 400
up_points = (up_width, up_height)
resized_up = cv2.resize(image, up_points, interpolation= cv2.INTER_LINEAR)
print('高さと幅を指定して縮小した画像')
cv2_imshow(resized_down)
print('高さと幅を指定して拡大した画像')
cv2_imshow(resized_up)

画像の読み込み
画像の読み込みは上でやっているが、リサイズにおいては読み込んだ画像の高さ・幅を取得しておくことが重要になる。shape()で取得できる。
image = cv2.imread('image.jpg')
# shape()で取得
# - h: 高さ
# - w: 幅
# - c: チャネル
h,w,c = image.shape
print("元のサイズ:", h,"×", w)
元のサイズ: 441 × 1280
このとき、順番としては高さ→幅→チャネルとなる。OpenCVでは画像をNumPy配列として読み込むが、この配列は rows(高さ) * columns(幅) となっているためらしい。他の画像処理ライブラリでは幅→高さになっている場合もあるので注意。
resize()
リサイズはresize()を使う。
resize(src, dsize[, dst[, fx[, fy[, interpolation]]]])
- src: 入力する画像を指定。必須。
- dsize: 出力画像のサイズを指定。高さと幅を設定。
- fx: 水平軸方向(幅)の拡大縮小係数。
- fy: 垂直軸方向(高さ)の拡大縮小係数。
- interpolation: 画像のリサイズに使用する手法。
幅と高さを指定してリサイズ
上でも書いた通り、リサイズは比率を指定する方法と、直接幅・高さを指定する方法があり、こちらは直接幅・高さを指定する方法。
幅300x高さ200にリサイズする。
image = cv2.imread('image.jpg')
down_width = 300
down_height = 200
down_points = (down_width, down_height)
resized_down = cv2.resize(image, down_points, interpolation=cv2.INTER_LINEAR)
cv2_imshow(resized_down)

幅、高さを指定することになるので、元の画像の比率は(自分で比率を維持した設定値にしない限り)維持されない。
スケーリング係数を指定してリサイズ
もう一つの比率で指定する方法。こちらは、サイズを気にせずに、元の画像のアスペクト比を維持しつつリサイズできる。比率は縦横それぞれに行うこともできるし、単一の比率でも指定できる。縦横それぞれに比率を指定する場合、比率が同じであればアスペクト比は維持される。
image = cv2.imread('image.jpg')
# 拡大率を x 方向と y 方向の両方で 1.2 倍に設定して画像を拡大
scale_up_x = 1.2
scale_up_y = 1.2
# 単一の拡大縮小係数を指定して画像を0.6倍に縮小。
scale_down = 0.6
scaled_f_down = cv2.resize(image, None, fx= scale_down, fy= scale_down, interpolation=cv2.INTER_LINEAR)
scaled_f_up = cv2.resize(image, None, fx= scale_up_x, fy= scale_up_y, interpolation=cv2.INTER_LINEAR)
print('スケーリング係数を指定して縮小した画像')
cv2_imshow(scaled_f_down)
print('スケーリング係数を指定して拡大した画像')
cv2_imshow(scaled_f_up)

縦横の比率を個別に指定する場合、異なる比率を設定すると当然アスペクト比は維持されない。
image = cv2.imread('image.jpg')
x = 0.3
y = 0.6
resized = cv2.resize(image, None, fx= x, fy= y, interpolation=cv2.INTER_LINEAR)
cv2_imshow(resized)

画像リサイズの補間手法
画像のリサイズ時に使用する補完手法には以下のようなものがある。
-
INTER_AREA- ピクセル面積比に基いてリサンプリングする手法。
- 画像サイズの縮小に最適。
- 画像を拡大する場合(ズーム処理)には、
INTER_NEARESTが使用される
-
INTER_CUBIC- バイキュービック補間を使用して画像のリサイズを行う。
- リサイズ時に新規ピクセルを生成する際、画像の4×4近傍ピクセルを対象とし、これら16ピクセルの重み付き平均値を計算して新しい補間ピクセルを生成する。
-
INTER_LINEAR-
INTER_CUBICと似ているが、2×2の近傍ピクセルを使用して重み付き平均値を計算し、補間ピクセルを生成する点が異なる。
-
-
INTER_NEAREST- 近傍補間方式。
- 最もシンプルな方法の一つで、画像から1つの近傍ピクセルのみを使用して補間を行う。
比較のために並べてみる。
image = cv2.imread('image.jpg')
scale_down = 0.5
res_inter_nearest = cv2.resize(image, None, fx= scale_down, fy= scale_down, interpolation= cv2.INTER_NEAREST)
res_inter_linear = cv2.resize(image, None, fx= scale_down, fy= scale_down, interpolation= cv2.INTER_LINEAR)
res_inter_area = cv2.resize(image, None, fx= scale_down, fy= scale_down, interpolation= cv2.INTER_AREA)
# 比較用に画像を水平軸方向に連結して表示
vertical= np.concatenate((res_inter_nearest, res_inter_linear, res_inter_area), axis = 1)
print('Inter Nearest :: Inter Linear :: Inter Area')
cv2_imshow(vertical)

小さすぎてあんまり違いがわからんな・・・
画像の切り抜き
画像から、不要なオブジェクト・領域を除去したり、特定の特徴を強調するために、特定部分を切り抜く。
OpenCVで切り抜き専用の関数が用意されているわけではないが、NumPy配列のスライシングを利用することで実現できる。
- 画像を読み込むと、各カラーチャネルごとに2次元配列として格納される
- 切り抜きたい領域の高さと幅を指定してスライシングする
サンプルの画像
!wget https://learnopencv.com/wp-content/uploads/2021/04/test.png -O test.png
import IPython.display
IPython.display.Image(filename='test.png')

import cv2
import numpy as np
from google.colab.patches import cv2_imshow
img = cv2.imread('test.png')
print("元の画像")
print("形状:", img.shape) # 画像の形状(高さ・幅・チャネル数)を返す
cv2_imshow(img)
# 画像の切り取り処理
cropped_image = img[80:280, 150:330]
# 切り取った画像を表示
print("切り取り後の画像")
print("形状:", cropped_image.shape)
cv2_imshow(cropped_image)
# 切り取った画像を保存する
cv2.imwrite("Cropped Image.jpg", cropped_image)

画像の切り取り
上にも書いた通り、NumPy配列のスライシングを使う。
cropped = img[start_row:end_row, start_col:end_col]
rowは高さ、colは幅となるので、上の例だとこういう感じかな。

クロッピングによる画像の小領域分割
この応用として画像を複数に分割する。
元の画像
img = cv2.imread("test.png")
image_copy = img.copy()
imgheight = img.shape[0]
imgwidth = img.shape[1]
print(f"形状: h{imgheight}, w{imgwidth}")
cv2_imshow(img)

3x3で分割
import os
import shutil
if os.path.exists('saved_patches'):
shutil.rmtree('saved_patches')
os.makedirs('saved_patches')
M = imgheight // 3
N = imgwidth // 3
x1 = 0
y1 = 0
for y in range(0, imgheight, M):
for x in range(0, imgwidth, N):
if (imgheight - y) < M or (imgwidth - x) < N:
break
y1 = y + M
x1 = x + N
# パッチの幅または高さが画像の幅または高さを超えているかどうかを確認
if x1 >= imgwidth and y1 >= imgheight:
x1 = imgwidth - 1
y1 = imgheight - 1
# M×N サイズのパッチに分割して切り取り
tiles = image_copy[y:y+M, x:x+N]
#各パッチをファイルディレクトリに保存
cv2.imwrite('saved_patches/'+'tile'+str(x)+'_'+str(y)+'.jpg', tiles)
cv2.rectangle(img, (x, y), (x1, y1), (0, 255, 0), 1)
elif y1 >= imgheight: # パッチの高さが画像の高さを超えた場合
y1 = imgheight - 1
# MxN サイズのパッチに分割して切り取り
tiles = image_copy[y:y+M, x:x+N]
#各パッチをファイルディレクトリに保存
cv2.imwrite('saved_patches/'+'tile'+str(x)+'_'+str(y)+'.jpg', tiles)
cv2.rectangle(img, (x, y), (x1, y1), (0, 255, 0), 1)
elif x1 >= imgwidth: # パッチの幅が画像の幅を超えた場合
x1 = imgwidth - 1
# M×N サイズのパッチに分割して切り取り
tiles = image_copy[y:y+M, x:x+N]
#各パッチをファイルディレクトリに保存
cv2.imwrite('saved_patches/'+'tile'+str(x)+'_'+str(y)+'.jpg', tiles)
cv2.rectangle(img, (x, y), (x1, y1), (0, 255, 0), 1)
else:
# MxN サイズのパッチに分割して切り取り
tiles = image_copy[y:y+M, x:x+N]
#各パッチをファイルディレクトリに保存
cv2.imwrite('saved_patches/'+'tile'+str(x)+'_'+str(y)+'.jpg', tiles)
cv2.rectangle(img, (x, y), (x1, y1), (0, 255, 0), 1)
画像をタイルで分割する。元の画像に矩形を描画しているのはわかりやすさのためだね。
こんな感じのイメージ。
cv2_imshow(img)

分割された画像はこうなっている。
directory = 'saved_patches'
for filename in os.listdir(directory):
if filename.endswith(".jpg") or filename.endswith(".png"): # 画像ファイルのみを対象とする
img_path = os.path.join(directory, filename)
img = cv2.imread(img_path)
print(f"{filename}:")
cv2_imshow(img)

画像の平行移動と回転
サンプル画像を取得。
!wget https://learnopencv.com/wp-content/uploads/2021/04/image-15.png -O image.png
import IPython.display
IPython.display.Image("image.png")

画像の回転
もろもろ数式など書いてあるが、画像の回転処理は以下の3つのステップで行われる。
- 画像の中心位置を特定する
- 上記の中心位置を使用して
getRotationMatrix2D()で2次元回転行列を作成 - 上記の回転行列を使用して、
warpAffine()で 画像にアフィン変換を適用
getRotationMatrix2D(center, angle, scale)
-
center- 入力画像の回転中心位置
-
angle- 回転角度(度単位)
- 正の値なら反時計回り、負の値なら時計回りに回転
-
scale- 画像を拡大・縮小するための等方性スケール係数。
- 指定された値に応じて画像サイズを変更する
warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]])
-
src- 入力画像
-
M- 変換行列
-
dsize- 出力画像のサイズ
-
dst- 出力画像
-
flags- INTER_LINEAR や INTER_NEAREST などの補間方法の組み合わせ
-
borderMode- ピクセル補外方法
-
borderValue- 定数境界を使用する場合の値。デフォルト値は 0。
import cv2
from google.colab.patches import cv2_imshow
image = cv2.imread('image.png')
# 画像の高さと幅を取得、2で割って中心座標を取得
height, width = image.shape[:2]
center = (width/2, height/2)
# cv2.getRotationMatrix2D() を使用して、反時計回りに45度回転する場合の回転行列を取得
rotate_matrix = cv2.getRotationMatrix2D(center=center, angle=45, scale=1)
# cv2.warpAffine() を使用して画像を回転
rotated_image = cv2.warpAffine(src=image, M=rotate_matrix, dsize=(width, height))
print('元の画像')
cv2_imshow(image)
print('回転後の画像')
cv2_imshow(rotated_image)
cv2.imwrite('rotated_image.png', rotated_image)

画像の平行移動
画像の平行移動は以下の3つのステップで行われる。
- 画像の幅と高さを特定する
- x軸・y軸方向へ移動させるピクセル数から変換行列を作成
- 上記の変換行列を使用して、
warpAffine()で 画像にアフィン変換を適用
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
image = cv2.imread('image.png')
# 画像の高さと幅を取得
height, width = image.shape[:2]
# 平行移動させる tx と ty の値を取得
# - txに正の値を指定すると右方向、負の値を指定すると左方向に移動
# - tyに正の値を指定すると下方向、負の値を指定すると上方向に移動
# ここでは幅と高さの1/4だけ右・下に移動する
tx, ty = width / 4, height / 4
# tx と ty を使用して変換行列を作成(NumPy 配列)
translation_matrix = np.array([
[1, 0, tx],
[0, 1, ty]
], dtype=np.float32)
# cv2.warpAffine を使用して画像を移動
rotated_image = cv2.warpAffine(src=image, M=translation_matrix, dsize=(width, height))
print('元の画像')
cv2_imshow(image)
print('移動後の画像')
cv2_imshow(rotated_image)
cv2.imwrite('translated_image.png', rotated_image)

数式なども出てきて、回転のところで理解できなくて躓いたのだけど、以下の記事が参考になった。
画像の回転処理にアフィン変換がよく用いられますが、アフィン変換≠回転です。アフィン変換はもっと広く処理ができますし、回転処理はその一部です。最初に回転を考えると理解しにくくなります。
とても長くなってしまいましたが、アフィン変換はとても強力な手法です。ポイントだけかいつまむと、
- アフィン変換は三角形の変形を定義することで決まる変換
- アフィン変換は行列の積を取ることで合成して1つの変換と考えることができる
- 合成して1つの変換にしたほうが、計算量やアノテーションの変換という点では都合がいい。Numpyでかけるような処理でも、多態性をもたせるケースでは、1つのアフィン変換に書いたほうが見通しが効きやすいことがある。
ということでした。回転だけでなくぜひ使いこなしてみてください。
完全な理解には全く程遠いのだが、理解したい・・・
画像へのアノテーション
以下の様の用途において、画像・動画へのアノテーションは有用
- デモに情報を追加する
- 物体検出時に対象物の周囲にバウンディングボックスを描画する
- 画像セグメンテーションのために、異なる色でピクセルを強調表示する
サンプル画像をダウンロード
!wget https://learnopencv.com/wp-content/uploads/2021/06/sample.jpg
import IPython.display
IPython.display.Image("sample.jpg")

線の描画
線の描画にはline()を使う
line(image, start_point, end_point, color, thickness)
-
image- 画像
-
start_point/end_point- 線の始点(
(x1, y1))と終点((x2, y2))を指定。 - x軸は画像の水平方向・列方向
- y軸は画像の垂直方向・行方向
- 線の始点(
-
color- 線の色
-
thickness- 線の太さ
画像を読み込む
import cv2
from google.colab.patches import cv2_imshow
img = cv2.imread('sample.jpg')
height, width = img.shape[:2]
print(f"元の画像: h{height}, w{width}")
cv2_imshow(img)

画像をコピーして、線を描画する
# 画像のコピーを作成
imageLine = img.copy()
# 点Aから点Bまでの線を描画
pointA = (200,80)
pointB = (450,80)
cv2.line(imageLine, pointA, pointB, (255, 255, 0), thickness=3)
cv2_imshow(imageLine)

線の位置や色・太さを変えてみる
pointA = (100,80)
pointB = (500,300)
cv2.line(imageLine, pointA, pointB, (0, 0, 255), thickness=10)
cv2_imshow(imageLine)

円の描画
円の描画はcircle()を使う
circle(image, center_coordinates, radius, color, thickness)
-
image- 画像
-
center_coordinates- 円の中心座標
-
radius- 円の半径
-
color- 線の色
-
thickness- 線の太さ
# 画像のコピーを作成
imageCircle = img.copy()
# 円の中心位置と半径
circle_center = (415,190)
radius =100
# circle() 関数を使用して円を描画
cv2.circle(imageCircle, circle_center, radius, (0, 0, 255), thickness=3, lineType=cv2.LINE_AA)
cv2_imshow(imageCircle)

lineTypeってのは以下。どうやら線の滑らかさらしい。cv2.LINE_AAだとアンチエイリアスになるみたい。
塗りつぶし円の描画
thicknessを-1にして円を描画すれば塗りつぶされる。
cv2.circle(imageCircle, circle_center, radius, (0, 0, 255), thickness=-1, lineType=cv2.LINE_AA)
cv2_imshow(imageCircle)

長方形の描画
長方形の場合は rectangle() を使う。
rectangle(image, start_point, end_point, color, thickness)
- 他と重複しているものは割愛
-
start_point/end_point- 長方形の始点・左上(
(x1, y1))と終点・右下((x2, y2))を指定。 - x軸は画像の水平方向・列方向
- y軸は画像の垂直方向・行方向
- 長方形の始点・左上(
imageRectangle = img.copy()
# 始点・終点の座標を指定
start_point =(300,115)
end_point =(475,225)
# rectangle() 関数を使用して長方形を描画
cv2.rectangle(imageRectangle, start_point, end_point, (0, 0, 255), thickness=5, lineType=cv2.LINE_AA)
cv2_imshow(imageRectangle)

こちらもthickness=-1で塗りつぶし
cv2.rectangle(imageRectangle, start_point, end_point, (0, 0, 255), thickness=1, lineType=cv2.LINE_AA)
cv2_imshow(imageRectangle)

楕円の描画
楕円はelipse()を使う
ellipse(image, centerCoordinates, axesLength, angle, startAngle, endAngle, color, thickness)
circle()と似ているんだけど、追加で以下を指定する必要がある。
-
axesLength- 楕円の長軸と短軸の長さ(
(長軸の長さ, 短軸の長さ))
- 楕円の長軸と短軸の長さ(
-
angle- 回転角度
-
startAngle/endAngle- 楕円の開始角度と終了角度
- これらを指定することで、円弧の一部分だけを描画することができる
imageEllipse = img.copy()
# 楕円の中心点
ellipse_center = (415,190)
# 楕円の長軸と短軸
axis1 = (90,40)
axis2 = (125,50)
#水平方向に青い楕円を描画
cv2.ellipse(imageEllipse, ellipse_center, axis1, 0, 0, 360, (255, 0, 0), thickness=3)
#垂直方向(水平方向から90度回転させる)に赤い楕円を描画
cv2.ellipse(imageEllipse, ellipse_center, axis2, 90, 0, 360, (0, 0, 255), thickness=3)
cv2_imshow(imageEllipse)

startAngle / endAngle がわかりにくいけど、楕円の弧の部分をどれだけ描画するかって感じみたい。上の例では startAngleが0、endAngleが360 になっていて、これだとフルの楕円になる。endAngleを180にしてみるとこうなる。
cv2.ellipse(imageEllipse, ellipse_center, axis1, 0, 0, 270, (255, 0, 0), thickness=3)
cv2.ellipse(imageEllipse, ellipse_center, axis2, 90, 0, 270, (0, 0, 255), thickness=3)
cv2_imshow(imageEllipse)

さらに startAngleを90にしてみる。
#水平方向に楕円を描画
cv2.ellipse(imageEllipse, ellipse_center, axis1, 0, 90, 270, (255, 0, 0), thickness=3)
#垂直方向に楕円を描画
cv2.ellipse(imageEllipse, ellipse_center, axis2, 90, 90, 270, (0, 0, 255), thickness=3)
cv2_imshow(imageEllipse)

うーん、わかりにくいけど、楕円のデフォルトが水平(角度0)とするならば、右端から右回りに考えれば良いってことなのかな?
半楕円の描画
半楕円の描画は上記のstartAngle/ endAngle をそれぞれ0 / 180 に設定すれば良い。塗りつぶしも有効にする。
halfEllipse = img.copy()
ellipse_center = (415,190)
axis = (90,40)
cv2.ellipse(halfEllipse, ellipse_center, axis, 0, 0, 180, (255, 0, 0), thickness=-1)
cv2_imshow(halfEllipse)

テキストの追加
テキストを追加するにはputText()を使う。
putText(image, text, org, font, fontScale, color)
- 他と重複するものは割愛
-
text- 追加するテキスト
-
org- テキスト文字列の左上隅の開始位置を指定。
-
font- フォントのスタイル
- フォントはHarsheyフォントが使用され、以下のスタイルの指定が可能
- Hershey
-
cv2.FONT_HERSHEY_SIMPLEX/0 -
cv2.FONT_HERSHEY_PLAIN/1 -
cv2.FONT_HERSHEY_DUPLEX/2 -
cv2.FONT_HERSHEY_COMPLEX/3 -
cv2.FONT_HERSHEY_TRIPLEX/4 -
cv2.FONT_HERSHEY_COMPLEX_SMALL/5 -
cv2.FONT_HERSHEY_SCRIPT_SIMPLEX/6 -
cv2.FONT_HERSHEY_SCRIPT_COMPLEX/7 -
cv2.FONT_ITALIC/16
-
-
fontScale- フォントを拡大・縮小するためのスケール係数
imageText = img.copy()
# 画像に表示したいテキスト
text = 'I am a Happy Dog!'
# テキストを配置したい位置
org = (50,350)
# 画像にテキストを書き込み
cv2.putText(imageText, text, org, fontFace = cv2.FONT_HERSHEY_COMPLEX, fontScale = 1.5, color = (250,225,100))
cv2_imshow(imageText)

なんかドキュメントとはフォントが違う気がするなぁ・・・
日本語だとこうなる。
text = '私は幸せな犬です!'
org = (50,350)
cv2.putText(imageText, text, org, fontFace = cv2.FONT_HERSHEY_COMPLEX, fontScale = 1.5, color = (250,225,100))
cv2_imshow(imageText)

ググってみると山ほど出てくるけど、基本的にPILで描画するという感じかな。