LangChainのQAボットの評価にAuto-evaluatorを使う
Streamlitを使ってGUIで、LangChainのQAボットの評価ができるサードパーティのツール。
準備
何はともあれdevcontainer環境を構築。自分で作りたくない場合は以下をcloneするなりforkするなりしてもらえれば。
以下は自分でdevcontainer環境を作る場合。
とりま公式レポジトリをforkしてcloneしておく。
で、cloneしたレポジトリ直下に以下を作成する。
{
"name": "Python 3",
"image": "mcr.microsoft.com/devcontainers/python:0-3.11",
"customizations": {
"vscode": {
"extensions": [
"ms-python.python"
]
}
},
"workspaceFolder": "/workspace",
"workspaceMount": "source=${localWorkspaceFolder},target=/workspace,type=bind,consistency=cached",
"mounts": [
"source=${localEnv:HOME}/.gitconfig,target=/home/vscode/.gitconfig,type=bind,consistency=cached",
"source=${localEnv:HOME}/.langchainenv,target=/workspace/.env,type=bind,consistency=cached",
],
"onCreateCommand": "pip install -r requirements.txt"
}
上記で2つローカルマシンからマウントしている。
- ~/.gitconfig
- ~/.langchainenv
.gitconfigはdevcontainer内からgitを叩くために、.langchainenvはOpenAIのAPIキーとかをレポジトリには含めたくないけど必要になるので.envとしてマウントするようにしている。これらは予めローカルマシン側で設定しておく。
OPENAI_API_KEY=xxxxxxxxx
その他はこんな感じ。このへんはお好みで。
{
"aws.telemetry": false,
"terminal.integrated.shellIntegration.history": 999999,
"files.insertFinalNewline": true
}
あと .gitignore は以下で作成した。
でこのディレクトリをVSCodeで開いてdevcontainerで開き直せばOK。
あとStreamlit向けに設定を追加しておく。
[general]
email=""
[browser]
gatherUsageStats = false
では起動。.envを読み込むようにauto-evaluator.pyを修正しても良さそうだけどとりあえずこんな感じで。
$ source ./.env
$ export OPENAI_API_KEY
$ streamlit run auto-evaluator.py
ブラウザが立ち上がって(もしくはhttp://localhost:8501/にアクセス)以下の画面が表示されればOK。
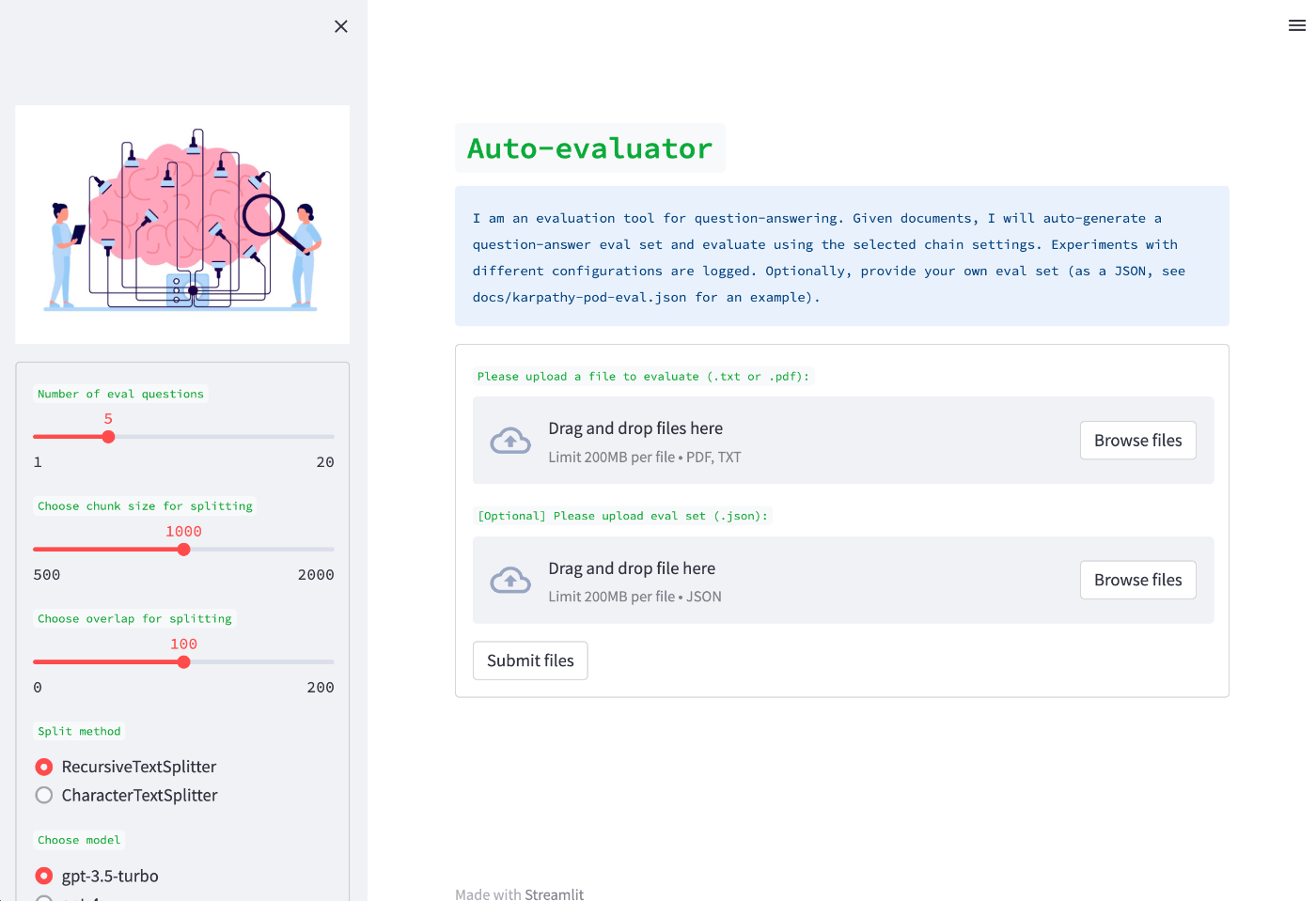
実際の使い方はまた今度。
では実際に使ってみる。
用意しないといけないものは一応2つ。
- QAのベースとなる「ドキュメント」
- 上記ドキュメントを元に自分で作成したQAの「評価セット」
一応2はオプションで、指定しない場合は1から自動的に作成してくれるのだけど、日本語の場合は以下の問題がある。
- ドキュメントからの評価データ作成にはQAGenerationChainが使用されるが、ドキュメントの分割単位等はデフォルトでハードコードされており、日本語のドキュメントの場合にはトークン数上限を超える場合がある。
- QAGenerationChainのデフォルトのプロンプトだと、評価データが日本語以外の言語で生成される可能性がある。
これを踏まえると、2についてauto-evaluatorを使うのはちょっと厳しそうなので、別の方法で生成しておいたほうが良いと思う。QAGenerationChainでの評価データ作成については以下を参照。
いろいろ試してみたのだけど、
- OpenAIの"That model is currently overloaded with other requests"にやられたり、タイム・アウトしたり。
- textsplitterのセパレータやらチャンクサイズやらをかなり小さくしないとすぐにトークン量上限のエラーになる。
- 遅い(まあQAごとにループするので当然といえば当然)
とまあ、いろいろ複合的に問題が重なって、かつ、いろいろハードコートされてるところとかも直さないと日本語ではちょっと厳しい、と感じたので一旦諦め・・・・
gpt-4だけじゃなくて3.5-turboもなんだよね・・・