ChatGPTクローン「Jan」を試す
ChatGPTクローンは随分前に色々試したことがあって、今となってはもう目新しいものでもないのだけど、ちょっと気になることがあって試してみる。
公式サイト
GitHubレポジトリ
公式ドキュメントの説明が一番わかりやすそう。
Jan
Janは、デスクトップで100%オフラインで動作する(近日中にモバイルにも対応予定)、ChatGPTの代替ツールです。私たちの目標は、プログラミングの知識の有無に関わらず、誰でもAIモデルを簡単にダウンロードし、完全な制御とプライバシーを確保しながら使用できるようにすることです。
Janは、OpenAI互換のAPIを提供するローカルAIエンジン「Llama.cpp」で動作しています。このAPIはデフォルトでバックグラウンドで実行され、
https://localhost:1337(またはカスタムポート)でアクセス可能です。これにより、ノートPCやデスクトップからAI機能を搭載したさまざまなアプリケーションを実行できます。例えば、 Continue や Cline などのローカルツールをJanに接続し、お気に入りのモデルで動作させることができます。Janはローカルにホストされたモデルに限定されません。つまり、お気に入りのモデルプロバイダーからAPIキーを作成し、設定ページ経由でJanに追加することで、お気に入りのモデルと通信を開始できます。
機能
- HuggingFace Model Hub から人気のオープンソースLLM(Llama3、Gemma3、Qwen3 など)をダウンロードするか、ローカルに保存されているGGUFファイル(llama.cpp で使用されるモデル形式)をインポートできます
- クラウドサービス(OpenAI、Anthropic、Mistral、Groq など)に接続できます
- 直感的なインターフェースを通じてAIモデルとチャットし、そのパラメーターをカスタマイズできます
- OpenAI相当のAPIを備えたローカルAPIサーバーを使用して、他のアプリを駆動できます。
哲学
Jan はユーザー所有を前提に設計されています。つまり、Jan は以下の特徴を備えています:
- Apache 2.0 ライセンスによる真のオープンソース
- データはローカルに保存され、多くのローカルファースト原則の 1 つに従っています
- インターネットはオプションであり、Jan は 100% オフラインで動作可能です
- ローカルおよびクラウドベースの AI モデルを自由に選択可能
- 当社はユーザーデータを収集または販売しません。プライバシーポリシーをご覧ください。
インスピレーション
Jan は、Calm Computing(穏やかなコンピューティング)および Disappearing Computer(消えるコンピュータ)のコンセプトからインスピレーションを得ています。
インストール&モデルのダウンロード
Janは、Mac・Windows・Linuxでそれぞれバイナリが用意されている。今回はM2 Macで行うので、以下より.dmgをダウンロードしてインストールするだけ。
起動するとこんな画面になる。右下に統計情報を共有するか?が表示されるがお好みで。インストール直後は何もモデルがないので、モデルをセットアップする。左下の "Hub" または 真ん中に表示されている "Setup local model"をクリック。
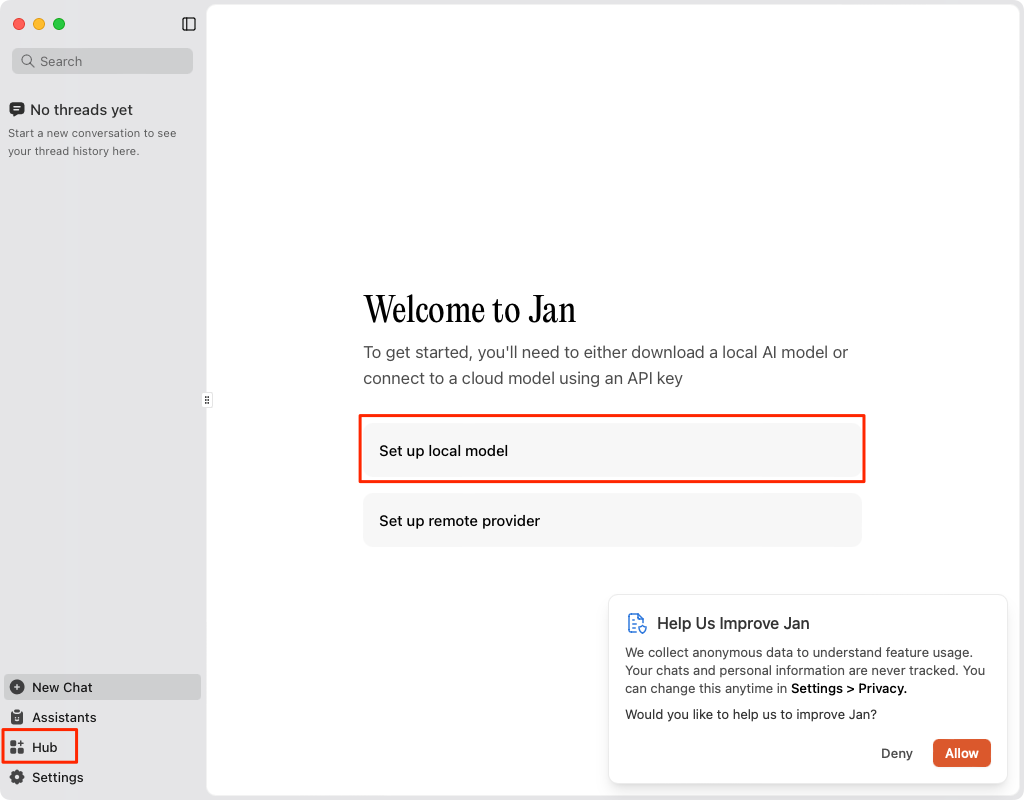
利用可能なモデルの一覧が表示される。ここでダウンロードすれば使えるようになる。今回はGemma3をダウンロードしてみる。

ダウンロード完了までしばし待つ。

ダウンロード完了したので使ってみる。

チャットしてみる。



ちょっと英語交じりだが、一応チャットできてる。ただ、IMEの変換確定のENTERで送信されてしまうのだよなぁ・・・もはやあるあるだけども、ちょっとつらい。気が向いたらPRできるかは後で見てみる。
アシスタントの設定
で、この英語混じりで返答を返すような振る舞いは、どうやらデフォルトの「アシスタント」設定によるものらしい。この設定を変更するには、上の"Jan"と表示されている箇所の設定アイコンをクリックする。

デフォルトでは「Jan」というアシスタントが設定されており、ここにある説明や指示を元に返答が生成されているみたい。あとはパラメータなんかも設定できるみたい。

これを変更すればよいのだが、「アシスタント」はどうやら複数登録できる様子。一旦この画面を閉じる。
左下の"Assitants"を開く。

ここでアシスタントを追加できる。先ほど見ていたビルトインで用意されていたアシスタント"Jan"もここにあるのがわかる。

こんな感じで、元のアシスタントの設定を単純に日本語化したものを設定して、登録。

登録された。最初にお試ししたチャットのスレッドに戻ってみる。

作成したアシスタントに切り替え。ここなんかうまく切り替わらない場合がある・・・

チャットを続けてみるとこんな感じで、今度は日本語で回答が返ってきているのがわかる。

なお、アシスタント設定時にいくつかtemperature等のパラメータが指定できたが、これはモデル側でも設定できる。モデル名の横にある設定アイコンをクリック。

以下のようなパラメータが設定できる。

リモートモデルの設定
Janでは、ローカルモデルだけでなく、OpenIAやClaudeなどプロプライエタリなモデルも使用できる。
左下の"Settings"から

"Model Provider"のメニューで、利用できるプロバイダの有効・無効を設定できる。右上でプロバイダそのものを追加することも出来そう。今回はOpenAIを使えるようにしてみる。各プロバイダに表示されている設定アイコンをクリック。
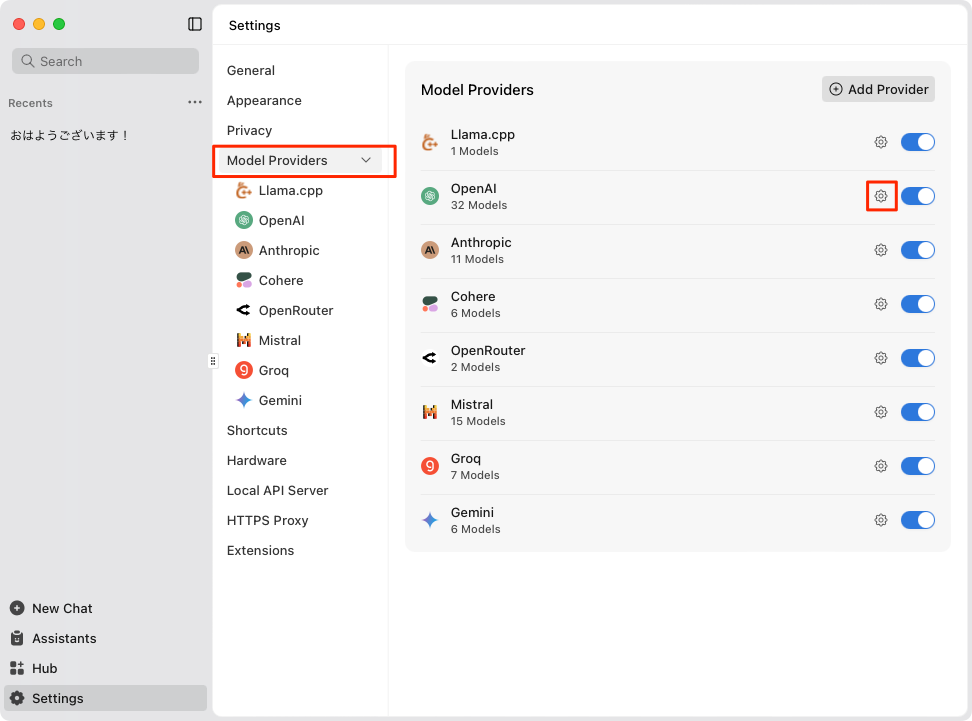
APIキーを入力すればOK

チャットに戻って、入力欄のところにあるモデル名をクリックすると切り替えることができる。

切り替えてチャット。

なお、プロバイダそのものの追加はOpenAI互換APIが想定されている様子。



Ollamaやllama.cpp、vLLMなど、すでにOpenAI互換APIが別で動いているならば、それを指定することも出来ると思う。
MCP
JanはMCPにも対応しているが、まだExperimentalなステータスみたいで、デフォルトでは無効になっている。
"Settings" → "General" で、"Experimental features" を有効にすると、メニューに "MCP Servers" が表示される。
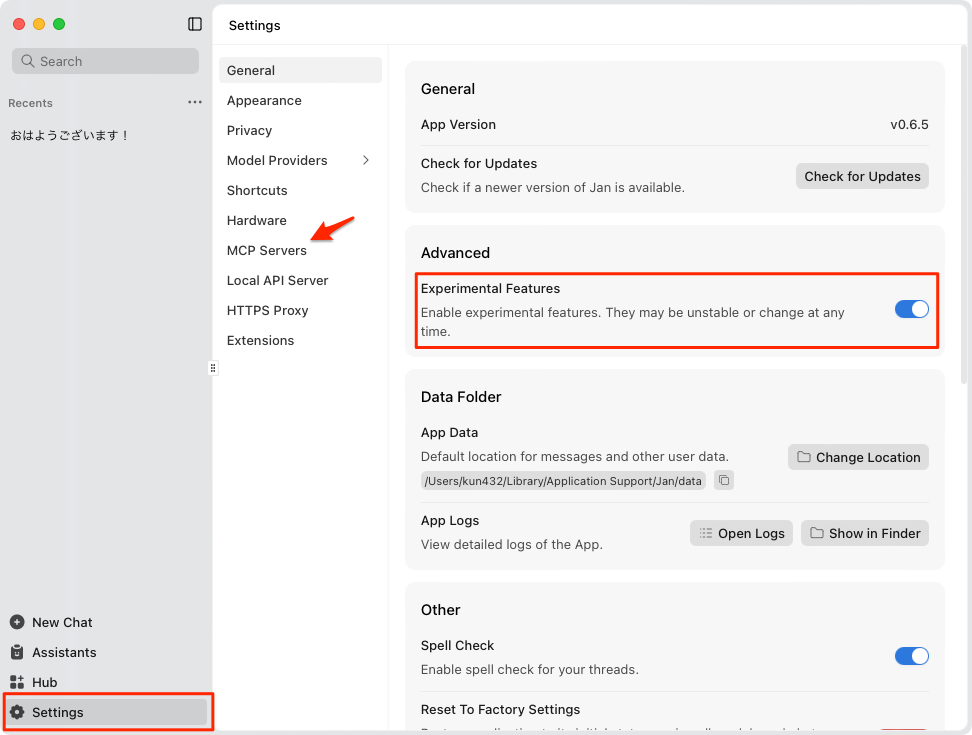
"MCP Servers" を見ると、すでにいくつかのMCPサーバが登録されている様子(ただし個別に設定が必要かも)。あとはMCPツール実行時の自動許可なんかも設定できるみたい。これ以外のMCPサーバを登録する場合は、右上の"+"をクリックすれば良い。

例えばGitHub MCPだとこんな感じで登録する。

設定に問題がなければ以下のように追加されて有効になる。

チャットに戻るとツールが使えるようになっているのがわかる。

あとはこんな感じで普通に使える。



なお、MCPサーバの登録時はコマンドや各パラメータ等をちまちま設定する必要があるるけど、一旦登録すればJSONで編集もできる。


適当に登録して(一回エラーにはなるけど)JSONコピペとかでもいいかもね。
HTTPサーバ
Jan自身をOpenAI互換APIサーバとして使うこともできる。
"Settings" → "Local API Server" で、"Start Server"をクリック

・・・するもどうやらローカルAPIサーバに接続する際に使用するAPIキーの設定は必須みたい。

APIキーを設定したら起動した。デフォルトはlocalhost:1337 がAPIエンドポイントになる。

curlで試してみる。
curl "http://localhost:1337/v1/models" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy" | jq -r .
{
"data": [
{
"ai_template": "<|im_end|>\n<|im_start|>assistant\n",
"created": 0,
"ctx_len": 4096,
"dynatemp_exponent": 1.0,
"dynatemp_range": 0.0,
"engine": "llama-cpp",
"files": [
"models/cortex.so/gemma3/1b/model.gguf"
],
"frequency_penalty": 0.0,
"gpu_arch": "",
"id": "gemma3:1b",
"ignore_eos": false,
"max_tokens": 4096,
"min_keep": 0,
"min_p": 0.05,
"mirostat": false,
"mirostat_eta": 0.1,
"mirostat_tau": 5.0,
"model": "gemma3:1b",
"n_parallel": 1,
"n_probs": 0,
"name": "gemma3:1b",
"ngl": 27,
"object": "",
"os": "",
"owned_by": "",
"penalize_nl": false,
"precision": "",
"presence_penalty": 0.0,
"prompt_template": "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n",
"quantization_method": "",
"repeat_last_n": 64,
"repeat_penalty": 1.0,
"seed": -1,
"size": 806059053,
"status": "downloaded",
"stop": [
"<|im_end|>"
],
"stream": true,
"system_template": "<|im_start|>system\n",
"temperature": 0.7,
"text_model": false,
"tfs_z": 1.0,
"top_k": 40,
"top_p": 0.9,
"typ_p": 1.0,
"user_template": "<|im_end|>\n<|im_start|>user\n",
"version": "1"
}
],
"object": "list",
"result": "OK"
}
curl -X POST "http://localhost:1337/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy" \
-d '{
"model": "gemma3:1b",
"messages": [
{
"role": "user",
"content": "競馬の楽しみ方を5つ簡潔にリストアップして。"
}
]
}'
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "競馬の楽しみ方を5つ簡潔にリストアップしますね。\n\n1. **レース結果を追いかける:** 予想と実際の結果を比較し、勝敗を予測する。\n2. **馬やジョクのデータをチェック:** 過去のレースデータや騎手の評価などを参考に、予想に役立てる。\n3. **コースや天候を考慮する:** レースの状況に合わせた戦略を立てる。\n4. **予想だけでなく、レースの雰囲気も楽しむ:** 騎手のコメントや馬の調子などを参考に、レースの雰囲気を味わう。\n5. **楽しむことを優先する:** 競馬は勝敗よりも、レース自体を楽しむことが大切。\n\nこれらのポイントを参考に、競馬を楽しんでください!",
"role": "assistant"
}
}
],
"created": 1752915936,
"id": "chatcmpl-kBbMDbTo0F5eLgWCxqh1ZsLf3sGzUz7w",
"model": "gemma3:1b",
"object": "chat.completion",
"system_fingerprint": "b1-f3471ce",
"timings": {
"predicted_ms": 1535.0740000000001,
"predicted_n": 160,
"predicted_per_second": 104.22950294252915,
"predicted_per_token_ms": 9.5942125000000011,
"prompt_ms": 87.415999999999997,
"prompt_n": 1,
"prompt_per_second": 11.439553399835271,
"prompt_per_token_ms": 87.415999999999997
},
"usage": {
"completion_tokens": 160,
"prompt_tokens": 22,
"total_tokens": 182
}
}
さすがに、OpenAI等のリモートモデルについては、このサーバで使えるわけではなさそう。/v1/models でもでてこないし。
なお、localhost:1337 にブラウザでアクセスすると、APIドキュメントやAPIプレイグラウンドにアクセスできる。どうやらScalarというのものを使っているみたい。

ただ、実際にここからAPIアクセスしようとすると、デフォルトで表示されているポートが違うポートだったりして、個別にエンドポイントURLを追加しないといけなかったり、あと、ブラウザでプレイグラウンドアクセスするたびにドキュメント追加しろ?と言ってきたり、ちょっと使い方がいまいちわからん・・・・まあドキュメント見れる、程度でいいのかも。
Janオリジナルのモデル
Janは独自のモデルも提供している。実はこれに興味があってJanを動かしてみたのだった。
Jan Nano
なぜ Jan Nano なのか?
ほとんどの言語モデルは、強力な機能を実現するには多大な計算リソースが必要という根本的なトレードオフに直面しています。Jan Nano は、すべてを知ることを目指すのではなく、何でも見つける方法に長けるという、焦点を絞った設計哲学によってこの制約を打破しています。
Jan Nano とは何ですか?
Jan Nanoは、深層学習研究タスク向けに特別に設計・トレーニングされたコンパクトな40億パラメーター言語モデルです。このモデルはModel Context Protocol(MCP)サーバーとのシームレスな連携を最適化しており、多様な研究ツールやデータソースとの効率的な統合を可能にします。
モデルとそのバリエーションはすべてJanで完全にサポートされています。
Jan-Nano-128k
拡張された文脈理解により、より深い研究を可能にします。
Jan-Nano-128k は、さまざまなアプリケーション向けのコンパクトな言語モデルにおいて、著しい進歩を遂げたものです。Jan-Nano-32k の成功を基盤に、この強化版は、文脈拡張手法に通常伴うパフォーマンスの低下を招くことなく、より深く、より包括的な研究機能を可能にするネイティブの 128k 文脈ウィンドウを特徴としています。
ざっと見た感じ、MCP等との連携が強化され検索やリサーチに強い4Bモデル、ということかな。ただしReasoningモデルではないと記載があった。
なお、これらは別にJanで動かさなくてもHuggingFaceで公開されている。vLLM向けとGGUF向けで提供されているようなので、それらの環境があれば直接利用もできる。Apache-2.0ライセンスみたい。
Janからこれらのモデルを使ってみる。

32Kのほうでまず試してみた。結構推論時間はかかるのと、なんかうまく行ってない感じなので途中で諦めた。

128Kの方も結構時間がかかる様子で、同じ結果に・・・

日本語でも普通のやりとりはできそうなんだけど、かなり遅い・・・

使い所がいまいちわからないな・・・
ドキュメントを見るとモデルサイズの割に要件は高めに思える。なお、デフォルトだとiQ4_XSが使用されていた。
システム要件
- 最小要件:
- 8GB RAM (iQ4_XS 量子化時)
- 12GB VRAM (Q8 量子化時)
- CUDA 対応 GPU
- 推奨環境:
- 16GB 以上の RAM
- 16GB 以上の VRAM
- 最新の CUDA ドライバー
- RTX 30/40 シリーズまたはそれ以降
あとドキュメントで紹介されている例は
- Serper APIを使ったWeb検索のMCPを使用
- Deep Research的な使い方
となっていた。んー、NVIDIA GPUで試してみたくなる。
ちなみに、Jan-Nanoのドキュメントやモデルカードにはベンチマーク結果がある。
32K
評価
Jan-Nano は、当社の MCP ベースベンチマーク手法を用いて SimpleQA ベンチマークで評価され、そのモデルサイズにおいて優れたパフォーマンスを発揮しました。
referred from https://huggingface.co/Menlo/Jan-nano#evaluation評価は、当社のMCPベースのベンチマークアプローチを使用して実施されました。このアプローチは、モデルのSimpleQAタスクにおける性能を評価しつつ、そのネイティブMCPサーバー統合機能を活用しています。この手法は、ツール強化型研究モデルとしてのJan-Nanoの現実世界での性能をより正確に反映し、事実の正確性およびMCP対応環境における有効性を検証しています。

128K
評価
Jan-Nano-128k は、当社の MCP ベースの方法論を用いて SimpleQA ベンチマークで厳格に評価され、その前身と比較して優れたパフォーマンスを発揮しました。
referred from https://huggingface.co/Menlo/Jan-nano-128k#evaluation

SimpleQAがどのようなものか?を理解していないけど、MCPでおそらく検索などが使えてモデルの知識を超えて回答が出せるようになる。なので、軽量モデル+MCPあり、が、巨大モデル+MCPなし、よりもスコアが上がる、ってのはまああり得るのかもとは思う。
その上でDeepSeek+MCPに勝っているというのが、そういうふうに最適化している、ってことなのかな?モデルサイズの違いが大きすぎて、ほんとか???とやや懐疑的に感じてしまうけども。
まとめ
以前にもGitHubのトレンドでちょいちょい見かけていたのだけど、ChatGPTクローンはもう使ってないのでスルーしていた。今回調べてみようと思ったきっかけは以下のRedditの記事
1.7Bでモバイルでも動かせる超軽量Reasoningモデル「Lucy」というのが紹介されていて、「Jan-Nano」のライバルになる、みたいなところから、Jan-Nanoとはなんぞや?でJanにたどり着いて、これかー、となった次第。
Janそのものは、シンプルに使えるチャットアプリって感じだけど、MCPサポートやローカルAPIサーバ機能があったり、ChatGPTでいうところのカスタム指示的な機能もあって、結構いいんじゃないかなという気はする。まあ日本語のIME確定Enterが考慮されていないのは海外製ツールあるあるで使いにくいんだけども、音声入力だったりするとあんまり気にならなかったりするし、そのうち誰かが直すだろうと思う。
また、今後、API・Web・モバイルがすべて使えるようなプラットフォームを計画しているらしいので、よりいろいろなユースケースで使いやすくなるかもしれない。
なお、この「Lucy」も開発元は「Jan-Nano」と同じ「Menro Research」というシンガポールの企業みたいで、他にも音声周りで「Ichigo」などをやっていて、なかなか興味深い企業だと感じた。
イメージ的には、OllamaにGUIがついて諸々使いやすくなったもの、って感じかな。逆にCLIはない感じ。
余談
ただ、IMEの変換確定のENTERで送信されてしまうのだよなぁ・・・もはやあるあるだけども、ちょっとつらい。
まあ日本語のIME確定Enterが考慮されていないのは海外製ツールあるあるで使いにくいんだけども、
これ、以前に以下のPRで修正されているのだが
該当のコードが含まれるファイルは存在せず、2025/07/20時点の最新コミットだと以下の別のファイルに処理が写っているようなので、おそらくどこかのタイミングでファイル構成とかが変わってしまったのではないか?と思われる。
なので、IME向けの対応は存在しないことになるのだけど、修正できるかなと思ってまずはローカルでビルドして確認してみた。この時点では何も修正していない。
- Mac(macOS Sonoma 14.7.6 + Google日本語入力): NG
- Linux(Ubuntu 22.04 + Mozc): OK
自分はWeb周りに詳しくないのでわからないけど、どうやらOSによって挙動が違ってそう(もしかするとIMEも関係する?)。で、Enter不具合のあるMacの場合はこんな感じに書き直せばいけた。
onKeyDown={(e) => {
if (e.key === 'Enter' && !e.shiftKey) {
if (e.nativeEvent.isComposing || e.keyCode === 229) {
return
}
e.preventDefault()
if (prompt.trim()) {
handleSendMesage(prompt)
}
}
}}
このIME変換中のEnterキー入力を拾うの、過去にもいくつかのプロジェクトでPRなげたことがあるのだけど、だいたいReact state使えば問題なかった。が、今回はそれもダメ、なんなら上記のnativeEvent.isComposingもダメで、両方ともIME確定時のEnterでisComposingがfalseになってしまい送信されてしまう。
JanはTauriで作られたネイティブアプリだけど、内部的にはWebView上で動くようなので、OSが使用しているWebViewに依存しているってことなんだろう。少なくとも自分のMac上だと keyCode === 229 を使用する必要があった。
で、このkeyCode はどうやら deprecated らしい・・・
と言いながらもこんなことも書いてある
Firefox 65 以降、CJKT ユーザー向けのクロスブラウザの互換性を改善するため、入力メソッドエディタの入力中に keydown イベントと keyup イベントが発生するようになりました (Firefox バグ 354358)。入力の一部である keydown イベントをすべて無視するには、次のようにします (229 は、IME によって処理されたイベントに関連する keyCode に設定された特別な値です)。
WebKitのBugzillaにもバグ報告があるけどずっとOpenのままみたい・・・
ちょっと自分のWeb周りの知識・経験だとどうすべきか?が判断できないので、PRは保留・・・Issueだけ上げとくかな・・・
まあ勉強になったのでそれは良かった。