LlamaIndexのQuery Pipelineを試す
Function Callingをいろいろ触ってみた感じ、LLMにツール/実行フローの選択をお任せするよりも、これらを外側からある程度意図的に制御できるような、ワークフローエンジンに近いものが良いのではないかと感じている。
LangChainだとLangGraphとかLCELとか
PromptFlow
AWSでBedrockならStep FunctionとかAmazon Managed Workflows for Apache Airflowとか
いっそGUIだとこの辺
FlowiseとLlamaIndexの組み合わせ
n8nなんかも
いずれにせよ、このあたりをなるだけコードで書きやすく、またできれば視覚的に確認できるオプションがあるものが欲しい。
自分の場合、LlamaIndexをメインで触っているのだけども、LlamaIndexだとQuery Pipelineというのが同じ雰囲気。
なお、Query Pipelineは、以前に少しだけ触れているが、今回はサンプルのnotebookをもう少し触ってみようと思う。
前提
DAGとステートマシン
Claude調べ
DAG(Directed Acyclic Graph、有向非巡回グラフ)とステートマシンはどちらもシステムやプロセスを表現するために使用される概念ですが、それぞれ異なる特徴と用途があります。
DAG
- DAGは、nodes(ノード)とedges(エッジ)で構成される有向グラフです。
- エッジは常に一方向で、サイクル(循環)がありません。つまり、あるノードから出発し、エッジをたどっていくと、決して出発点に戻ることはできません。
- DAGは、タスクの依存関係、データの流れ、あるいは因果関係を表現するのに適しています。
- 例えば、ビルドシステム、タスクスケジューリング、バージョン管理システムなどで使用されます。
ステートマシン
- ステートマシンは、システムが取り得る状態(state)と、それらの状態間の遷移(transition)で構成されます。
- 各状態では、システムは特定の動作を行うか、次の状態への遷移を待ちます。
- 遷移は、特定のイベントや条件に応じて発生します。
- ステートマシンは、システムの振る舞いを表現し、状態に基づいて動作を制御するのに適しています。
- 例えば、UI設計、通信プロトコル、ゲームの敵AIなどで使用されます。
主な違い
- DAGはタスクや依存関係の静的な構造を表現するのに対し、ステートマシンはシステムの動的な振る舞いを表現します。
- DAGでは、ノード間の関係は一方向で、サイクルは許されませんが、ステートマシンでは、状態間の遷移は双方向で、サイクルが存在することもあります。
- DAGは主にデータの流れや因果関係に焦点を当てるのに対し、ステートマシンは状態に基づくシステムの制御に焦点を当てます。
それぞれの概念は、システムやプロセスのモデル化に使用されますが、DAGは静的な構造を、ステートマシンは動的な振る舞いを表現するという点で異なります。
DAGとステートマシンは、どちらもワークフローを作成するようなユースケースで広く使用されています。それぞれの特徴を活かして、ワークフローのモデル化や実装に役立てられています。
DAGを使ったワークフローの例
- データ処理パイプライン: データの取り込み、変換、集約、出力など、一連の処理ステップをDAGで表現します。
- ビルドシステム: ソースコードのコンパイル、テスト、パッケージング、デプロイなどの依存関係をDAGで表現します。
- バッチ処理: 複数のタスクを特定の順序で実行する必要がある場合、DAGを使って依存関係を表現します。
ステートマシンを使ったワークフローの例
- 承認フロー: ドキュメントやリクエストの承認プロセスを、ステートマシンで表現します。各状態は承認の状況を表し、遷移は承認や却下などのアクションに対応します。
- 注文処理: 注文の受付、支払い処理、在庫確認、発送など、一連の処理をステートマシンで表現します。
- ドキュメント管理: ドキュメントの作成、レビュー、承認、公開など、ドキュメントのライフサイクルをステートマシンで表現します。
これらは一例ですが、DAGとステートマシンは、様々な業界や分野でワークフローを表現するために使用されています。ワークフローの要件や特性に応じて、適切な方法を選択することが重要です。
また、ワークフローを管理するためのツールやプラットフォームの多くは、DAGやステートマシンの概念を取り入れています。例えば、Apache Airflow、AWS Step Functions、Kubernetesなどは、ワークフローの定義、実行、監視などを行うために、DAGやステートマシンを活用しています。これらのツールを使うことで、ワークフローの管理を効率化することができます。
LLMのRAG(Retrieval-Augmented Generation)やエージェントなどのパイプラインにおいて、DAGやステートマシンは重要な役割を果たしています。これらの手法は、複雑なタスクを複数のステップに分解し、それらのステップ間の依存関係や実行順序を管理するために使用されます。
RAGにおけるDAGの使用
- RAGは、大規模なコーパスから関連する情報を検索し、その情報を使って回答を生成するアプローチです。
- RAGパイプラインは、通常、検索、フィルタリング、統合、生成などの複数のステップで構成されます。
- これらのステップの依存関係は、DAGを使って表現されます。例えば、検索の結果を使ってフィルタリングを行い、フィルタリングの結果を使って統合を行うといった具合です。
- DAGを使うことで、各ステップを独立に開発、テスト、実行できるようになり、パイプライン全体の管理が容易になります。
エージェントにおけるステートマシンの使用
- エージェントは、与えられたタスクを達成するために、複数のアクションを実行するシステムです。
- エージェントの動作は、しばしばステートマシンを使って表現されます。各状態はエージェントの現在の状況を表し、遷移はアクションの実行や環境の変化に対応します。
- 例えば、質問応答エージェントの場合、質問の受け取り、関連情報の検索、回答の生成、回答の提示などの状態を持つステートマシンで表現できます。
- ステートマシンを使うことで、エージェントの振る舞いを明確に定義し、制御することができます。
RAGやエージェントのパイプラインでは、DAGとステートマシンを組み合わせて使用することもあります。例えば、RAGパイプラインの各ステップをステートマシンで表現し、ステップ間の依存関係をDAGで表現するといった具合です。
これらの手法を使うことで、LLMを使った複雑なシステムを構築する際に、モジュール性、再利用性、管理容易性などを向上させることができます。また、エラーハンドリングや回復機能など、システムの堅牢性を高めるためにも、DAGやステートマシンは重要な役割を果たします。
DAGとステートマシンの違いを可視化してみましょう。以下は、シンプルな例を使って、それぞれの特徴を示しています。
DAG(有向非巡回グラフ)の例
この例では、タスクAが完了すると、タスクBとタスクCが並行して実行され、それらが完了すると、タスクDが実行されます。矢印は依存関係を表しており、サイクルがないことがわかります。
ステートマシンの例
この例では、ワークフローが以下のステップで構成されています:
- 受付: 申請を受け付ける状態です。
- 承認待ち: 申請が提出され、承認を待っている状態です。
- 承認済み: 申請が承認された状態です。
- 却下: 申請が却下された状態です。却下された申請は、再申請することで受付状態に戻ります。
- 処理中: 承認済みの申請が処理されている状態です。
- 完了: 処理が完了した状態です。完了後、新規申請を受け付けるために受付状態に戻ります。
この例では、ステートマシンにループが含まれています:
- 却下された申請が再申請される際のループ(却下 -> 受付)
- 完了後に新規申請を受け付ける際のループ(完了 -> 受付)
これにより、ステートマシンがワークフローの継続的な実行を表現していることがわかります。
このようにステートマシンを使うことで、申請の状態遷移とそれに伴うアクションを明確に定義し、ループを含む複雑なワークフローを表現することができます。
DAGとステートマシンの図の主な違いをまとめると以下のようになります:
- 図の要素:
- DAG: ノード(タスク)と有向エッジ(依存関係)で構成されます。
- ステートマシン: 状態(ステート)と遷移(トランジション)で構成されます。
- 依存関係と遷移:
- DAG: エッジは、タスク間の依存関係を表します。あるタスクの完了が、別のタスクの開始条件になります。
- ステートマシン: 遷移は、ある状態から別の状態へ移る条件やトリガーを表します。遷移は、イベントやアクションによって引き起こされます。
- 実行順序:
- DAG: タスクの実行順序は、依存関係によって決まります。依存関係を満たしたタスクから順に実行されます。
- ステートマシン: 状態の遷移は、遷移条件が満たされたときに発生します。現在の状態と遷移条件によって、次の状態が決まります。
- サイクル:
- DAG: サイクルは許されません。タスク間の依存関係に循環があってはいけません。
- ステートマシン: サイクルが存在することがあります。ある状態から出発し、最終的に同じ状態に戻ってくることができます。
- 表現対象:
- DAG: 主に、タスクの依存関係や実行順序を表現するのに適しています。
- ステートマシン: 主に、システムの状態遷移や振る舞いを表現するのに適しています。
- 適用例:
- DAG: データ処理パイプライン、ビルドシステム、バッチ処理など。
- ステートマシン: 承認フロー、注文処理、ドキュメント管理など。
これらの違いを理解することで、DAGとステートマシンをワークフローの要件に応じて適切に使い分けることができます。また、両者を組み合わせて使用することで、複雑なワークフローを効果的に表現し、管理することも可能です。
ちなみにLlamaIndexのQuery PipelineはDAG。
公式のブログ記事
日本語に訳されている記事
元記事で紹介されている記事
6つのnotebookが用意されている。
順にやっていく。なお、今回はローカルのjupyter labで試す。
Pandasデータフレームを使ったQuery Pipeline
Pandasのデータフレームに対して、「構造化された処理」つまり、LLMで「一連の操作」を行うQuery Pipelineの例。
パッケージインストール。Arise Phoenixを使ってトレーシングができるようにしておく。PyGraphvizはQuery Pipelineの可視化のため。
!pip install llama-index-llms-openai llama-index-callbacks-arize-phoenix python-dotenv pygraphviz
なおPyGraphvizには以下が事前に必要になる。
$ sudo apt-get install -y graphviz graphviz-dev
トレーシングを有効化
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
APIキーを読み込み
from dotenv import load_dotenv
load_dotenv(verbose=True)
インポート
from llama_index.core.query_pipeline import QueryPipeline, Link, InputComponent
from llama_index.core.query_engine.pandas import PandasInstructionParser
from llama_index.llms.openai import OpenAI
from llama_index.core import PromptTemplate
タイタニックのデータセットをダウンロードしてPandasのデータフレームに読み込み。
!wget 'https://raw.githubusercontent.com/jerryjliu/llama_index/main/docs/docs/examples/data/csv/titanic_train.csv' -O 'titanic_train.csv'
import pandas as pd
df = pd.read_csv("./titanic_train.csv")
プロンプトを設定。単純に機械翻訳で日本語化した。最終的にどんなプロンプトが生成されているかはトレーシングで確認する。
instruction_str = """\
1. Pandasを使ってクエリを実行可能なPythonコードに変換してください。
2. コードの最終行は、`eval()`関数で呼び出せるPython式にしてください。
3. コードはクエリの解を表してください。
4. 式だけを出力して下さい。
5. 式を引用しないでください。 \
"""
pandas_prompt_str = """\
Pythonでpandasのデータフレームを操作しています。
データフレームの名前は'df'です。
`print(df.head())`の結果はこれです:
{df_str}
以下の指示に従ってください:
{instruction_str}
質問: {query_str}
式: \
"""
response_synthesis_prompt_str = """\
入力された質問に対して、クエリー結果から回答を生成して下さい。
質問: {query_str}
Pandasへの命令(オプション):
{pandas_instructions}
Pandasの出力t: {pandas_output}
回答: \
"""
pandas_prompt = PromptTemplate(pandas_prompt_str).partial_format(
instruction_str=instruction_str, df_str=df.head(5)
)
pandas_output_parser = PandasInstructionParser(df)
response_synthesis_prompt = PromptTemplate(response_synthesis_prompt_str)
Query Pipelineを作成。
pandas_output_parser = PandasInstructionParser(df)
llm = OpenAI(model="gpt-3.5-turbo")
qp = QueryPipeline(
modules={
"input": InputComponent(),
"pandas_prompt": pandas_prompt,
"llm1": llm,
"pandas_output_parser": pandas_output_parser,
"response_synthesis_prompt": response_synthesis_prompt,
"llm2": llm,
},
verbose=True,
)
qp.add_chain(["input", "pandas_prompt", "llm1", "pandas_output_parser"])
qp.add_links(
[
Link("input", "response_synthesis_prompt", dest_key="query_str"),
Link(
"llm1", "response_synthesis_prompt", dest_key="pandas_instructions"
),
Link(
"pandas_output_parser",
"response_synthesis_prompt",
dest_key="pandas_output",
),
]
)
qp.add_link("response_synthesis_prompt", "llm2")
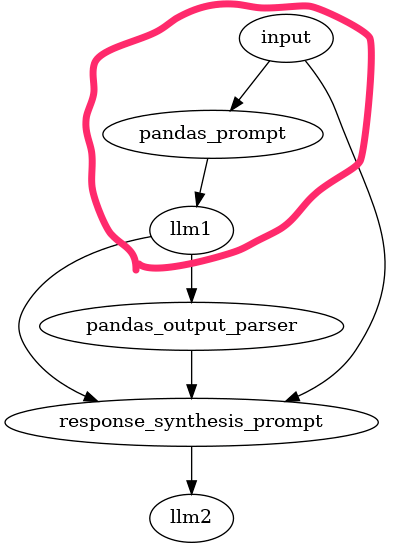
Query Pipelineを可視化してみる。
from networkx.drawing.nx_agraph import to_agraph
from IPython.display import Image
agraph = to_agraph(qp.dag)
agraph.layout(prog="dot")
agraph.draw('pandas_dag.png')
display(Image('pandas_dag.png'))

ではクエリを与えて実行。
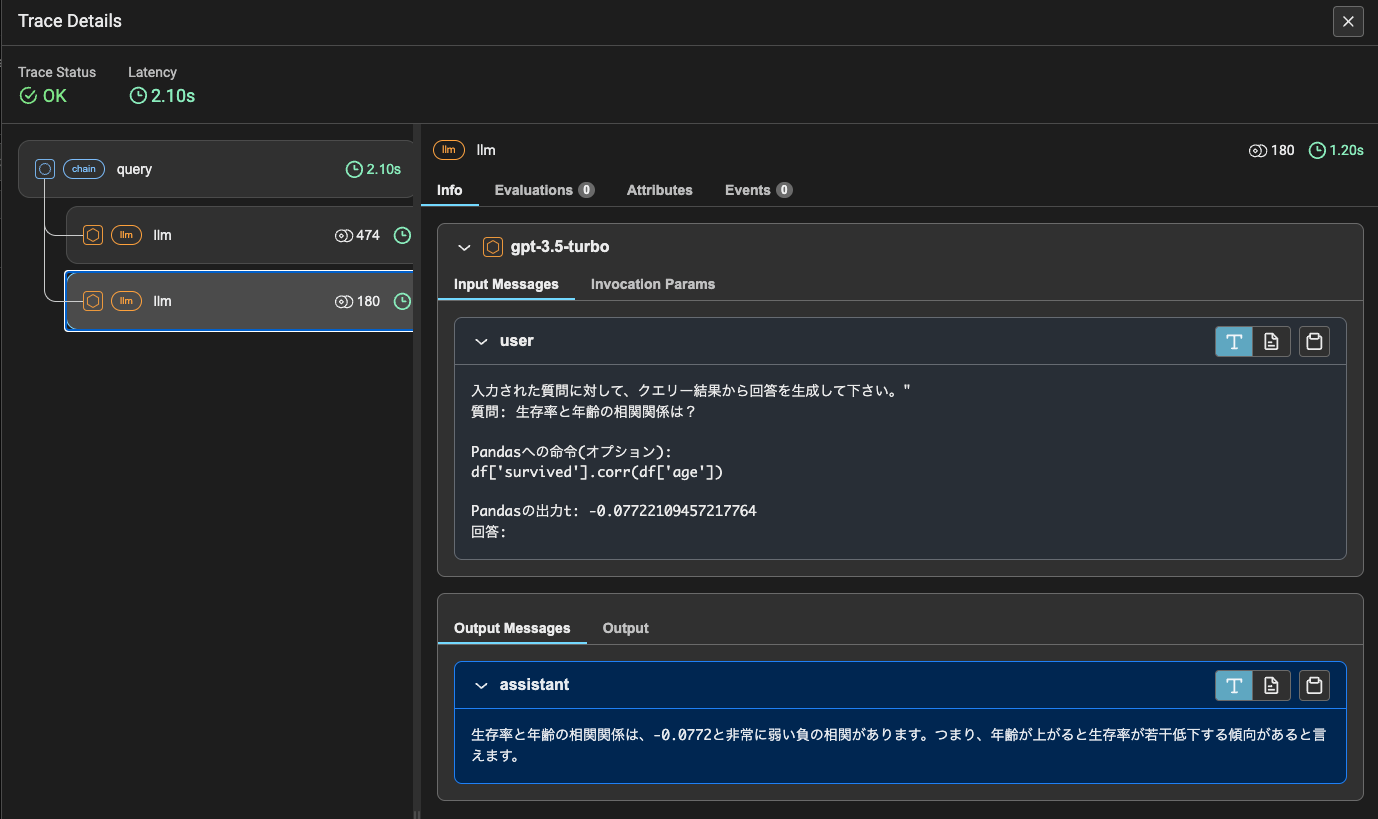
response = qp.run(query_str="生存率と年齢の相関関係は?")
print(response.message.content)
生存率と年齢の相関関係は、-0.0772と非常に弱い負の相関があります。つまり、年齢が上がると生存率が若干低下する傾向があると言えます。
トレース結果を見つつ処理を見てみる。
まずクエリとpandasのデータフレームの概要(df.head(5))を与えてプロンプトを作成し、LLMにクエリの内容を取得するためのpandasのコードを生成させる。

この部分。
次にここで生成されたコード、その実行結果、最初のクエリを元にプロンプトを作成して、LLMに最終的な回答を生成させる。
この部分。
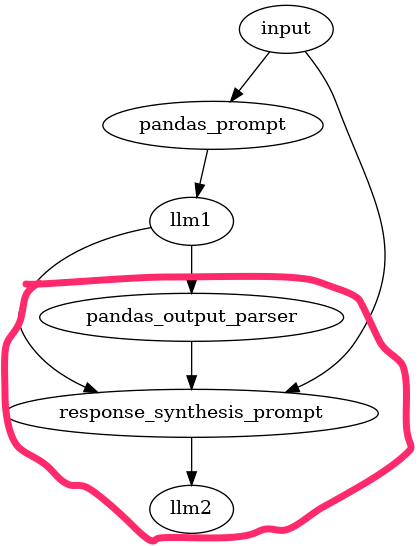
ちょっとプロンプトの組み立ても複雑になるのでパイプラインの設計が難しそうな感はあるけど、Text-to-SQLみたいなのにも適用できそうで、パターンとして覚えておくと良いかも。
ちなみにこれをまるっとやってくれるのがPandasQueryEngineになる。
Text-to-SQLのためのQuery Pipeline
試してみたけどちょっといろいろエラーが出たりするので気が向いたらやる。
Query Pipelineで非同期・並列処理
複数のRAGクエリエンジンを用意して、同時にクエリを送信して非同期に実行、最後に結果を集約して要約するQuery Pipelineの例。
パッケージインストール。今回はllama-index-embeddings-openaiを追加している。
!pip install llama-index-llms-openai llama-index-embeddings-openai llama-index-callbacks-arize-phoenix python-dotenv pygraphviz
トレーシングを有効化
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
APIキーを読み込み
from dotenv import load_dotenv
load_dotenv(verbose=True)
ポール・グレアムのエッセイをドキュメントとして読み込み。
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt' -O pg_essay.txt
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(input_files=["pg_essay.txt"])
documents = reader.load_data()
このドキュメントからクエリエンジンを作成。ここでは、チャンクサイズが異なるクエリエンジンを作成する。
from llama_index.llms.openai import OpenAI
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import VectorStoreIndex
llm = OpenAI(model="gpt-3.5-turbo")
chunk_sizes = [128, 256, 512, 1024]
query_engines = {}
for chunk_size in chunk_sizes:
splitter = SentenceSplitter(chunk_size=chunk_size, chunk_overlap=0)
nodes = splitter.get_nodes_from_documents(documents)
vector_index = VectorStoreIndex(nodes, show_progress=True)
query_engines[str(chunk_size)] = vector_index.as_query_engine(llm=llm)
試しにretrievalしてみる。
for i in query_engines:
print(f"===== {i} =====")
response = query_engines[i].retrieve("著者はYC時代に何をしていたのか?日本語で簡潔に回答して。")
print(response[0])
===== 128 =====
Node ID: ab9b9821-fd06-4774-91b5-9378bd6a9f53
Text: When I was dealing with some urgent problem during YC, there was
about a 60% chance it had to do with HN, and a 40% chance it had do
with everything else combined. [17] As well as HN, I wrote all of
YC's internal software in Arc. But while I continued to work a good
deal in Arc, I gradually stopped working on Arc, partly because I
didn't have t...
Score: 0.780
===== 256 =====
Node ID: 516079d9-d722-4cff-8291-dff7720bbd18
Text: Whereas I was like someone who was in pain while running a
marathon not from the exertion of running, but because I had a blister
from an ill-fitting shoe. When I was dealing with some urgent problem
during YC, there was about a 60% chance it had to do with HN, and a
40% chance it had do with everything else combined. [17] As well as
HN, I wrot...
Score: 0.781
===== 512 =====
Node ID: eab4e6a8-c14a-404c-a3d3-92fad0fc87f6
Text: In the summer of 2006, Robert and I started working on a new
version of Arc. This one was reasonably fast, because it was compiled
into Scheme. To test this new Arc, I wrote Hacker News in it. It was
originally meant to be a news aggregator for startup founders and was
called Startup News, but after a few months I got tired of reading
about noth...
Score: 0.774
===== 1024 =====
Node ID: 31b333aa-1105-4640-ae8b-18f74351cc71
Text: [17] As well as HN, I wrote all of YC's internal software in
Arc. But while I continued to work a good deal in Arc, I gradually
stopped working on Arc, partly because I didn't have time to, and
partly because it was a lot less attractive to mess around with the
language now that we had all this infrastructure depending on it. So
now my three pr...
Score: 0.790
パイプライン作成
from llama_index.core.query_pipeline import (
QueryPipeline,
InputComponent,
ArgPackComponent,
)
from llama_index.core.response_synthesizers import TreeSummarize
from llama_index.core.schema import NodeWithScore, TextNode
p = QueryPipeline(verbose=True)
module_dict = {
**query_engines,
"input": InputComponent(),
"summarizer": TreeSummarize(),
"join": ArgPackComponent(
convert_fn=lambda x: NodeWithScore(node=TextNode(text=str(x)))
),
}
p.add_modules(module_dict)
for chunk_size in chunk_sizes:
p.add_link("input", str(chunk_size))
p.add_link(str(chunk_size), "join", dest_key=str(chunk_size))
p.add_link("join", "summarizer", dest_key="nodes")
p.add_link("input", "summarizer", dest_key="query_str")
from networkx.drawing.nx_agraph import to_agraph
from IPython.display import Image
agraph = to_agraph(p.dag)
agraph.layout(prog="dot")
agraph.draw('rag_dag.png')
display(Image('rag_dag.png'))
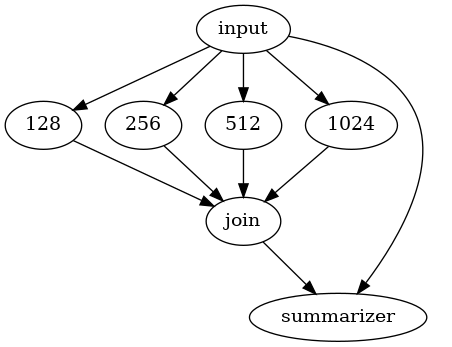
では、まず普通に実行してみる。
import time
start_time = time.time()
response = p.run(input="著者はYC時代に何をしていたのか?日本語で回答して。")
print(str(response))
end_time = time.time()
print(f"Time taken: {end_time - start_time}")
著者はYC時代に、スタートアップの問題に取り組んでおり、Arcという言語でYCの内部ソフトウェアを書いていました。また、Hacker Newsの運営やYC内のソフトウェアの開発も行っていました。
Time taken: 11.517963409423828
verboseされている内容を見ていても各クエリエンジンの実行がシーケンシャルに実行されているのがわかる。
では非同期・並列でやってみる。
import time
start_time = time.time()
response = await p.arun(input="著者はYC時代に何をしていたのか?日本語で回答して。") # ここ
print(str(response))
end_time = time.time()
print(f"Time taken: {end_time - start_time}")
著者はYC時代に、スタートアップの問題に取り組んでおり、内部ソフトウェアをArcで書いたり、新しいArcのバージョンの開発を行っていました。また、スタートアップの選定や支援、Hacker Newsの運営にも携わっていました。
Time taken: 3.7985827922821045
verboseの出力を見ていれば各クエリエンジンの実行が同時に行われているのがわかると思う。
トレースを見てみる。シーケンシャルに実行された場合も非同期・並列で実行された場合もトレースの内容自体は同じ。
各クエリエンジンに対してクエリを送信して、retrieval+generateが行われる。
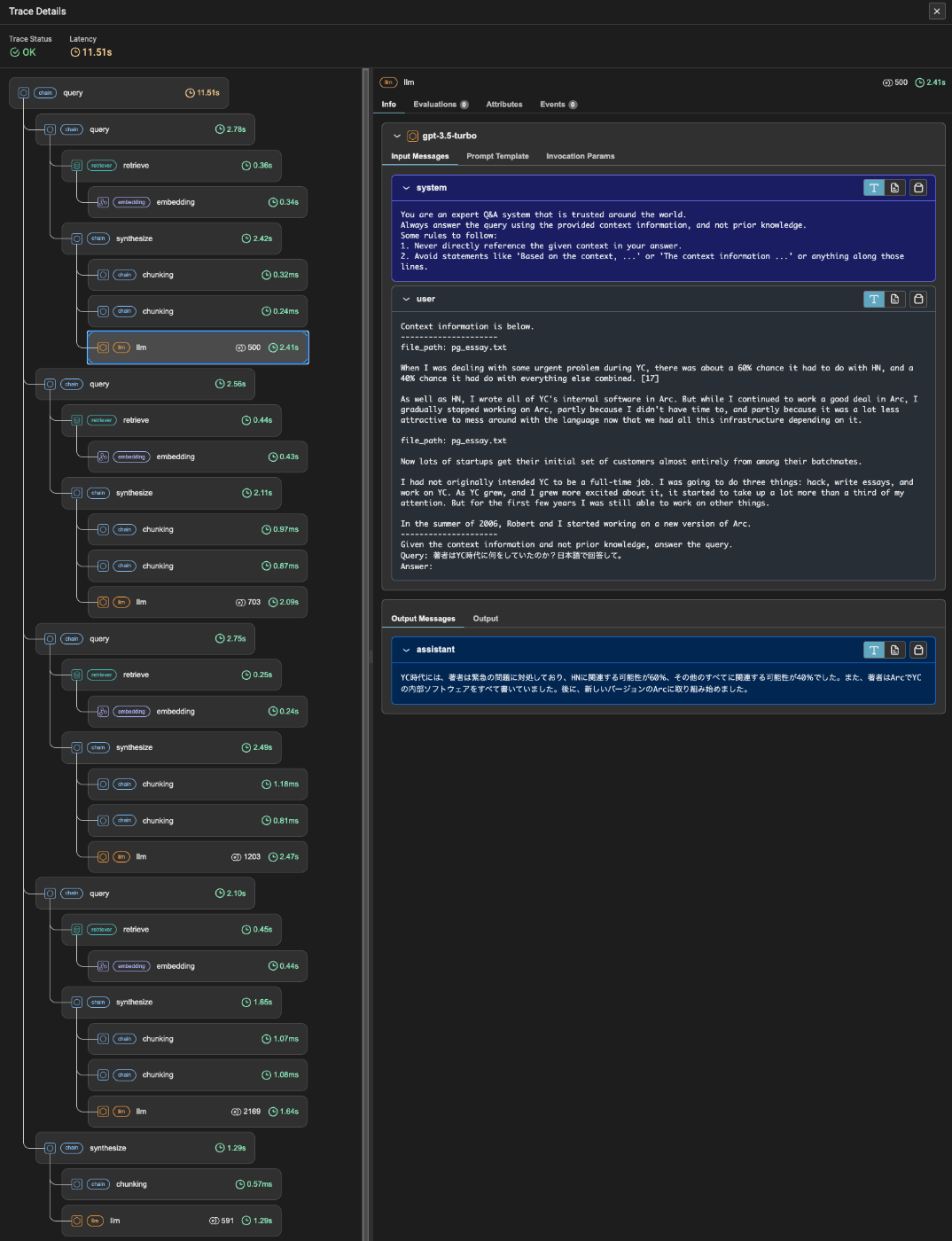
各クエリエンジンの生成結果を最後にまとめて再度回答を生成させている。
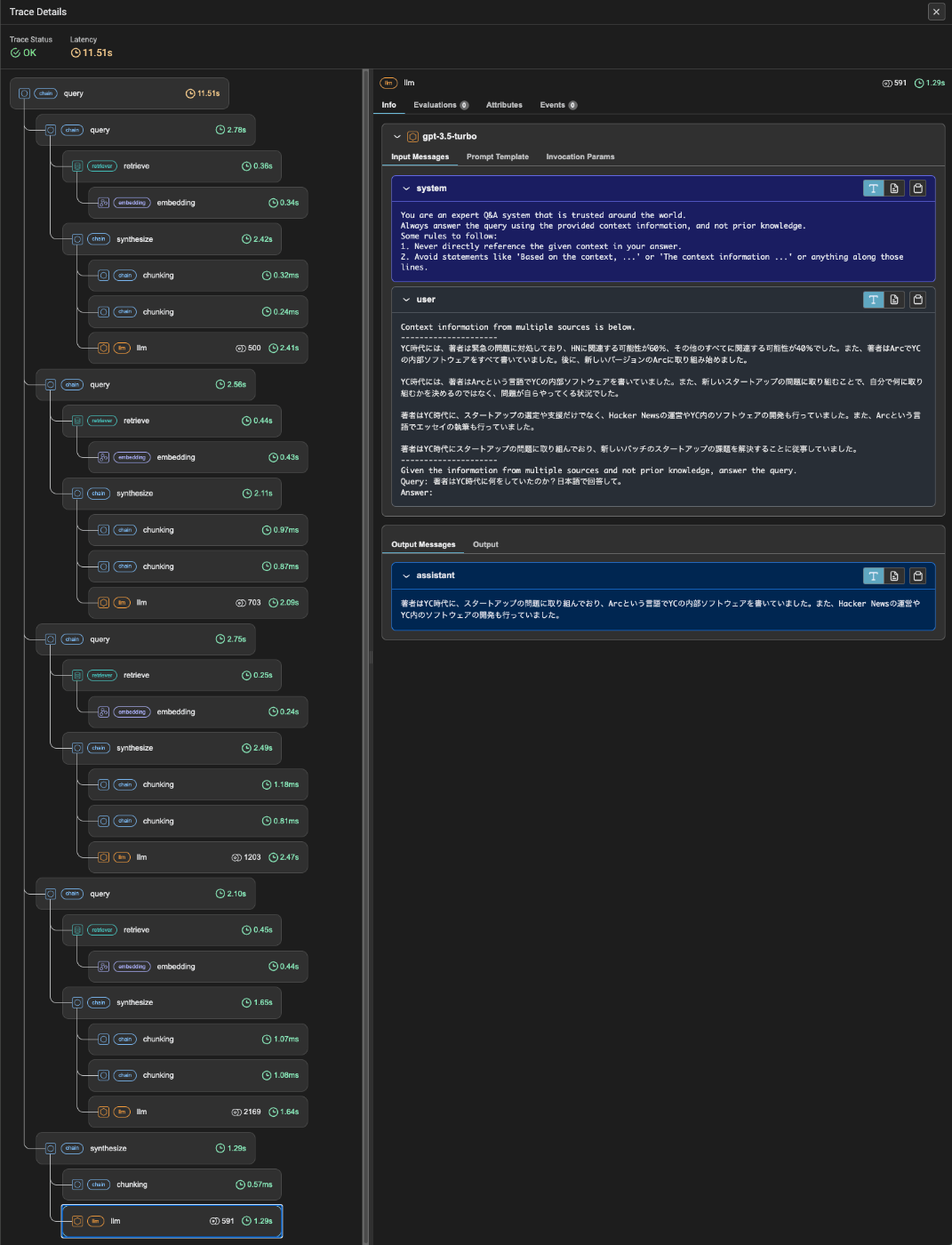
上の出力の繰り返しになるけど、実行時間が大きく異なる。

レスポンスタイム短縮のためにはとても重要な使い方だと思う。
Query Pipelineとルーティングを組み合わせる
Query Pipelineの中で分岐処理的なルーティングを行う例。RouterQueryEngineを使って、クエリの内容に応じて、単純な質問に答えるクエリエンジンと要約を必要とするクエリエンジンに分岐する。
パッケージインストール
!pip install llama-index-llms-openai llama-index-embeddings-openai llama-index-callbacks-arize-phoenix python-dotenv pygraphviz
トレーシングを有効化
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
APIキーを読み込み
from dotenv import load_dotenv
load_dotenv(verbose=True)
ポール・グレアムのエッセイをドキュメントとして読み込み。
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt' -O pg_essay.txt
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(input_files=["pg_essay.txt"])
documents = reader.load_data()
各コンポーネントを定義
from llama_index.llms.openai import OpenAI
from llama_index.core import PromptTemplate
from llama_index.core import VectorStoreIndex, SummaryIndex
from llama_index.core.response_synthesizers import TreeSummarize
# HyDEのプロンプトテンプレート定義
hyde_str = '''\
以下の質問に答える文章を書いてください。
できるだけ多くの重要な詳細を含めるようにしてください。
質問: {query_str}
文章: """
'''
hyde_prompt = PromptTemplate(hyde_str)
# LLMの定義
llm = OpenAI(model="gpt-3.5-turbo")
# シンセサイザーの定義
summarizer = TreeSummarize(llm=llm)
# VectorStoreIndexを使ったクエリエンジンの定義
vector_index = VectorStoreIndex.from_documents(documents)
vector_query_engine = vector_index.as_query_engine(similarity_top_k=2)
# SummaryIndexを使用した、プロンプトテンプレートおよびクエリエンジンの定義
summary_index = SummaryIndex.from_documents(documents)
summary_qrewrite_str = """\
質問:{query_str}
あなたは、与えられたコンテキストで質問に答えようとするエージェントに質問を送る責任があります。
文脈は関係あるかもしれませんし、ないかもしれません。事実を強調するために質問を書き直してください。
コンテキストの一部だけが(あるいは全く)関連しているかもしれないという事実を強調するように質問を書き換えてください。
"""
summary_qrewrite_prompt = PromptTemplate(summary_qrewrite_str)
summary_query_engine = summary_index.as_query_engine()
パイプラインを作成
from llama_index.core.query_pipeline import RouterComponent
from llama_index.core.selectors import LLMSingleSelector
vector_chain = QueryPipeline(chain=[vector_query_engine])
summary_chain = QueryPipeline(
chain=[summary_qrewrite_prompt, llm, summary_query_engine], verbose=True
)
choices = [
"このツールは、文書に関する特定の質問に答えます(文書全体の要約的な質問ではありません)",
"このツールは、文書に関する要約的な質問に答えます(特定の質問ではありません)",
]
selector = LLMSingleSelector.from_defaults()
router_c = RouterComponent(
selector=selector,
choices=choices,
components=[vector_chain, summary_chain],
verbose=True,
)
qp = QueryPipeline(chain=[router_c], verbose=True)
ここはちょっと複雑なのだけども、
- 特定な質問に答えるクエリエンジン(vector_query_engine)のパイプライン
- 要約を行うクエリエンジン(summary_chain)のパイプライン
- 上記をルーティングするパイプライン(qp)
という階層構造になっている。
ではシンプルな質問をしてみる。
response = qp.run("著者はYC時代に何をしていたのか?日本語で回答して。")
print(str(response))
YC時代に著者は天使投資家として活動していました。
このときverboseに出力されているように、特定の質問ということで"component 0" が選択されているのがわかる。
Selecting component 0: The first choice is most relevant as it mentions answering specific questions related to the document, which would include providing information about what the author was doing during the YC era..
では要約的な質問にしてみる。
response = qp.run("この文書の趣旨は何?日本語で回答して。")
print(str(response))
この文書は、VCファームとエンジェル投資家の違い、そしてそれらが創業者をどのように支援しているかについて述べています。創業者が最初の段階でどれだけ無力であるかを理解し、それに対処するためにY Combinatorが設立された経緯が描かれています。
verboseされているログから"component 1"が選択されているのがわかる。
Selecting component 1: Choice 2 is more relevant as it mentions answering summary questions related to the document, which aligns with the question asking for the main idea or summary of the document..
RouteQueryEngineをあまり触ってないのでわかってなかったのだけど、LLMSingleSelectorとかRouterComponentというのが突然でてきてこれは何?になった。
SelectorはRouterQueryEngineで使用するモジュールのことで、具体的にどうやって分岐判断させるかというもの。LLMSingleSelectorは複数の選択肢から1つの選択をLLMに行わせるものらしい。これ以外にも、
-
LLMMultiSelector: LLMを使って複数の選択肢から複数の選択を行わせる。 -
PydanticSingleSelector/PydanticMultiSelector: Pydanticを使って関数定義を行い、FunctionCallingで選択させる。Single/Multiは上と同じ。
があるみたい。
で、これをQueryPipelineで使えるようにコンポーネント化したのがRouterComponentみたいなんだけども、RouterQueryEngineそのままでは使えないのかな?ちょっとRouters周りは全然触ってないから調べ直してみよう。
あとQuery Pipelineのコンポーネントはここを見ていたけども、
1つ前の例に出てきた InputComponent とか ArgPackComponent とかみたいなコンポーネントもあるみたいで、この辺ドキュメントには記載がないのよな。これも後で見てみる。
Query Pipelineを使ったチャットエンジン
チャットエンジン、つまりはメモリと連携させたQuery Pipelineの例。
パッケージインストール。ちょっと公式のnotebookから、リランキングをColbertからCohereに変えた。
!pip install llama-index-llms-openai llama-index-embeddings-openai llama-index-postprocessor-cohere-rerank llama-index-readers-web llama-index-callbacks-arize-phoenix python-dotenv pygraphviz
トレーシングを有効化
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
APIキーを読み込み
from dotenv import load_dotenv
load_dotenv(verbose=True)
ドキュメントを用意。今回の例ではBeautifulSoupを使ってAnthropicのFunction Callingのドキュメントをスクレイプして使用している。
from llama_index.readers.web import BeautifulSoupWebReader
reader = BeautifulSoupWebReader()
documents = reader.load_data(
["https://docs.anthropic.com/claude/docs/tool-use"]
)
lines = documents[0].text.split("\n")
# 空行が2行以上続くセクションを削除する
fixed_lines = [lines[0]]
for idx in range(1, len(lines)):
if lines[idx].strip() == "" and lines[idx - 1].strip() == "":
continue
fixed_lines.append(lines[idx])
documents[0].text = "\n".join(fixed_lines)
ドキュメントからインデックスを作成
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
index = VectorStoreIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(
model="text-embedding-3-large", embed_batch_size=256
),
show_progress=True
)
プロンプトやLLM、retrieverなどQuery Pipelineで使用するコンポーネントを定義
from llama_index.core.query_pipeline import (
QueryPipeline,
InputComponent,
ArgPackComponent,
)
from llama_index.core.prompts import PromptTemplate
from llama_index.llms.openai import OpenAI
from llama_index.postprocessor.cohere_rerank import CohereRerank
# まず、ユーザークエリを取り込むための入力コンポーネントを作成する。
input_component = InputComponent()
# 次に、LLMを使ってユーザークエリを書き換える。
rewrite = '''\
現在の会話を使って、セマンティック検索エンジンへのクエリを書いてください。
{chat_history_str}
最新のメッセージ: {query_str}
クエリ: """\
'''
rewrite_template = PromptTemplate(rewrite)
# LLMの定義
llm = OpenAI(
model="gpt-3.5-turbo",
temperature=0.2,
)
# 2回取得するので、取得したノードを1つのリストにまとめる必要がある。
argpack_component = ArgPackComponent()
# それを使って検索を行う
retriever = index.as_retriever(similarity_top_k=6)
# 後処理としてCohereでリランクする
reranker = CohereRerank(model="rerank-multilingual-v2.0", top_n=3)
会話履歴をプロンプトに含めてLLMに送るカスタムコンポーネントを作成。なるほど、カスタムコンポーネントを作る場合の参考になる。
# 最後に、ノードとチャット履歴を使用してレスポンスを作成する必要がある
from typing import Any, Dict, List, Optional
from llama_index.core.bridge.pydantic import Field
from llama_index.core.llms import ChatMessage
from llama_index.core.query_pipeline import CustomQueryComponent
from llama_index.core.schema import NodeWithScore
DEFAULT_CONTEXT_PROMPT = """\
以下は以下は、関連しそうなコンテキストです:"
----
{node_context}
----
上記のコンテキストを使って、以下の質問に対する回答を書いてください:
{query_str}\
"""
class ResponseWithChatHistory(CustomQueryComponent):
llm: OpenAI = Field(..., description="OpenAI LLM")
system_prompt: Optional[str] = Field(
default=None, description="System prompt to use for the LLM"
)
context_prompt: str = Field(
default=DEFAULT_CONTEXT_PROMPT,
description="Context prompt to use for the LLM",
)
def _validate_component_inputs(
self, input: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate component inputs during run_component."""
# NOTE: this is OPTIONAL but we show you where to do validation as an example
return input
@property
def _input_keys(self) -> set:
"""Input keys dict."""
# NOTE: These are required inputs. If you have optional inputs please override
# `optional_input_keys_dict`
return {"chat_history", "nodes", "query_str"}
@property
def _output_keys(self) -> set:
return {"response"}
def _prepare_context(
self,
chat_history: List[ChatMessage],
nodes: List[NodeWithScore],
query_str: str,
) -> List[ChatMessage]:
node_context = ""
for idx, node in enumerate(nodes):
node_text = node.get_content(metadata_mode="llm")
node_context += f"Context Chunk {idx}:\n{node_text}\n\n"
formatted_context = self.context_prompt.format(
node_context=node_context, query_str=query_str
)
user_message = ChatMessage(role="user", content=formatted_context)
chat_history.append(user_message)
if self.system_prompt is not None:
chat_history = [
ChatMessage(role="system", content=self.system_prompt)
] + chat_history
return chat_history
def _run_component(self, **kwargs) -> Dict[str, Any]:
"""Run the component."""
chat_history = kwargs["chat_history"]
nodes = kwargs["nodes"]
query_str = kwargs["query_str"]
prepared_context = self._prepare_context(
chat_history, nodes, query_str
)
response = llm.chat(prepared_context)
return {"response": response}
async def _arun_component(self, **kwargs: Any) -> Dict[str, Any]:
"""Run the component asynchronously."""
# NOTE: Optional, but async LLM calls are easy to implement
chat_history = kwargs["chat_history"]
nodes = kwargs["nodes"]
query_str = kwargs["query_str"]
prepared_context = self._prepare_context(
chat_history, nodes, query_str
)
response = await llm.achat(prepared_context)
return {"response": response}
response_component = ResponseWithChatHistory(
llm=llm,
system_prompt="あなたはQ&Aシステムです。ユーザーからのメッセージに答えるために、以前のチャット履歴や関連するコンテキストが提供されます。"
)
パイプラインを作成
pipeline = QueryPipeline(
modules={
"input": input_component,
"rewrite_template": rewrite_template,
"llm": llm,
"rewrite_retriever": retriever,
"query_retriever": retriever,
"join": argpack_component,
"reranker": reranker,
"response_component": response_component,
},
verbose=False,
)
# HyDE的なクエリーと本物のクエリーの両方のretrieverを実行
pipeline.add_link(
"input", "rewrite_template", src_key="query_str", dest_key="query_str"
)
pipeline.add_link(
"input",
"rewrite_template",
src_key="chat_history_str",
dest_key="chat_history_str",
)
pipeline.add_link("rewrite_template", "llm")
pipeline.add_link("llm", "rewrite_retriever")
pipeline.add_link("input", "query_retriever", src_key="query_str")
# argpackコンポーネントへの各入力には、destキーが必要 - なんでもよい
# そして、argpackコンポーネントはすべての入力を1つのリストにまとめる。
pipeline.add_link("rewrite_retriever", "join", dest_key="rewrite_nodes")
pipeline.add_link("query_retriever", "join", dest_key="query_nodes")
# rerankerは、パックされたノードとクエリー文字列を必要とする
pipeline.add_link("join", "reranker", dest_key="nodes")
pipeline.add_link(
"input", "reranker", src_key="query_str", dest_key="query_str"
)
# synthesizerは、リランク付けされたノードとクエリ文字列を必要とする
pipeline.add_link("reranker", "response_component", dest_key="nodes")
pipeline.add_link(
"input", "response_component", src_key="query_str", dest_key="query_str"
)
pipeline.add_link(
"input",
"response_component",
src_key="chat_history",
dest_key="chat_history",
)
可視化。
from networkx.drawing.nx_agraph import to_agraph
from IPython.display import Image
agraph = to_agraph(pipeline.dag)
agraph.layout(prog="dot")
agraph.draw('chat_memory.png')
display(Image('chat_memory.png'))
結構複雑だなー
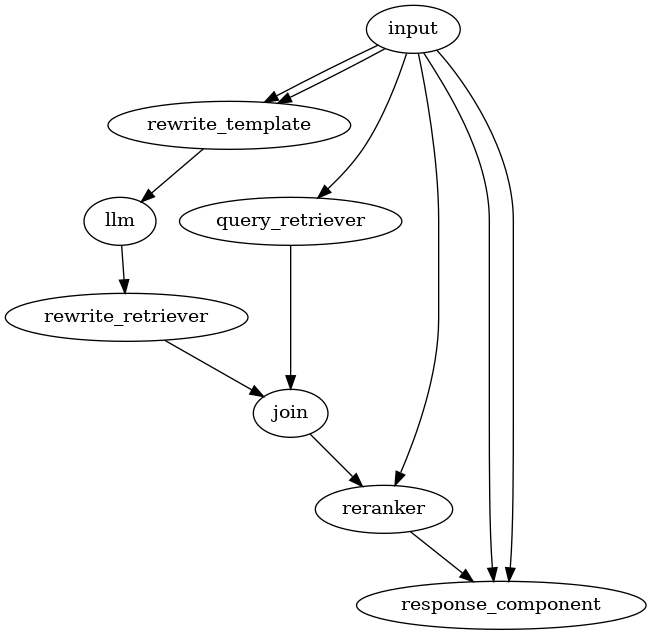
でも、なるほど、普通にパイプラインを組むと、前の出力が次の入力になるパターンが多いけど、元のクエリを必要とするものが多いので、その場合にinputコンポーネントを使うと、元のクエリを複数のコンポーネントに渡せるって感じなのかも。、argpackコンポーネントは逆に複数の出力を1つ(のリスト)に束ねるという感じに見える。
会話履歴用のメモリを作成。
from llama_index.core.memory import ChatMemoryBuffer
# メモリを初期化
pipeline_memory = ChatMemoryBuffer.from_defaults(token_limit=8000)
ではチャットのやりとりを仮想的にやってみる。
user_inputs = [
"こんにちは!",
"Claude-3でのtool-useの使い方は?",
"どのモデルがそれをサポートしていますか?",
"ありがとう、それを知りたかったんだ!",
]
for msg in user_inputs:
# メモリを取得
chat_history = pipeline_memory.get()
# 会話履歴を入力文字列に変換
chat_history_str = "\n".join([str(x) for x in chat_history])
# パイプライン実行
response = pipeline.run(
query_str=msg,
chat_history=chat_history,
chat_history_str=chat_history_str,
)
# メモリを更新
user_msg = ChatMessage(role="user", content=msg)
pipeline_memory.put(user_msg)
print(str(user_msg))
pipeline_memory.put(response.message)
print(str(response.message))
print()
user: こんにちは!
assistant: こんにちは!どのようにお手伝いできますか?
user: Claude-3でのtool-useの使い方は?
assistant: Claude-3でのtool-useの使い方は、以下の手順に従います:
- Claudeにツールとユーザープロンプトを提供する(APIリクエスト):
- Claudeがアクセスできるツールのセットを定義します。これには、ツールの名前、説明、および入力スキーマが含まれます。
- ユーザープロンプトを提供します。これは、例えば「サンフランシスコの天気はどうですか?」など、1つ以上のツールの使用を必要とするかもしれません。
- Claudeがツールを使用する(APIレスポンス):
- Claudeはユーザープロンプトを評価し、利用可能なツールがユーザーのクエリやタスクに役立つかどうかを判断します。役立つ場合、どのツールを使用し、どの入力を使用するかも決定します。
- 適切にフォーマットされたツール使用リクエストを構築します。APIレスポンスには、Claudeが外部ツールを使用したいということを示すstop_reasonが含まれます。
- ツールの入力を抽出し、コードを実行し、結果を返す(APIリクエスト):
- クライアント側で、Claudeのツール使用リクエストからツール名と入力を抽出します。
- クライアント側で実際のツールコードを実行します。
- ツール結果を返します。これは、新しいユーザーメッセージを含むツール結果コンテンツブロックを使用して会話を継続します。
- Claudeがツール結果を使用して応答を形成する(APIレスポンス):
- ツール結果を受け取った後、Claudeはその情報を使用して元のユーザープロンプトに対する最終的な応答を形成します。
これらの手順に従うことで、Claude-3でのtool-useを効果的に活用することができます。
user: どのモデルがそれをサポートしていますか?
assistant: 上記のコンテキストによると、Claude-3 Opusモデルが"chain of thought tool use"(思考の連鎖を示すツール使用)をサポートしています。この機能により、Claudeは問題を分解し、どのツールを使用するかを決定するためのステップバイステップの推論を表示します。SonnetモデルやHaikuモデルもこの機能を使用することができますが、デフォルトではOpusモデルほど頻繁に使用されません。
user: ありがとう、それを知りたかったんだ!
assistant: このコンテキストに基づいて、Claude-3のツール使用に関する情報を提供しました。Claude-3では、Opusモデルを使用して複雑なツール使用をナビゲートすることが推奨されています。Opusは最も多くの同時ツールを処理でき、他のモデルと比較して欠落している引数をキャッチする能力があります。また、Haikuモデルは、単純なツールを扱う場合に適しています。これらの情報を活用して、Claudeのツール使用を効果的に設計し、Claudeの機能を拡張することができます。
メモリの中身も更新されている。
for i in pipeline_memory.get_all():
print(i.json(ensure_ascii=False))
{"role": "user", "content": "こんにちは!", "additional_kwargs": {}}
{"role": "assistant", "content": "こんにちは!どのようにお手伝いできますか?", "additional_kwargs": {}}
{"role": "user", "content": "Claude-3でのtool-useの使い方は?", "additional_kwargs": {}}
{"role": "assistant", "content": "Claude-3でのtool-useの使い方は、以下の手順に従います:\n\n1. Claudeにツールとユーザープロンプトを提供する(APIリクエスト):\n - Claudeがアクセスできるツールのセットを定義します。これには、ツールの名前、説明、および入力スキーマが含まれます。\n - ユーザープロンプトを提供します。これは、例えば「サンフランシスコの天気はどうですか?」など、1つ以上のツールの使用を必要とするかもしれません。\n\n2. Claudeがツールを使用する(APIレスポンス):\n - Claudeはユーザープロンプトを評価し、利用可能なツールがユーザーのクエリやタスクに役立つかどうかを判断します。役立つ場合、どのツールを使用し、どの入力を使用するかも決定します。\n - 適切にフォーマットされたツール使用リクエストを構築します。APIレスポンスには、Claudeが外部ツールを使用したいということを示すstop_reasonが含まれます。\n\n3. ツールの入力を抽出し、コードを実行し、結果を返す(APIリクエスト):\n - クライアント側で、Claudeのツール使用リクエストからツール名と入力を抽出します。\n - クライアント側で実際のツールコードを実行します。\n - ツール結果を返します。これは、新しいユーザーメッセージを含むツール結果コンテンツブロックを使用して会話を継続します。\n\n4. Claudeがツール結果を使用して応答を形成する(APIレスポンス):\n - ツール結果を受け取った後、Claudeはその情報を使用して元のユーザープロンプトに対する最終的な応答を形成します。\n\nこれらの手順に従うことで、Claude-3でのtool-useを効果的に活用することができます。", "additional_kwargs": {}}
{"role": "user", "content": "どのモデルがそれをサポートしていますか?", "additional_kwargs": {}}
{"role": "assistant", "content": "上記のコンテキストによると、Claude-3 Opusモデルが\"chain of thought tool use\"(思考の連鎖を示すツール使用)をサポートしています。この機能により、Claudeは問題を分解し、どのツールを使用するかを決定するためのステップバイステップの推論を表示します。SonnetモデルやHaikuモデルもこの機能を使用することができますが、デフォルトではOpusモデルほど頻繁に使用されません。", "additional_kwargs": {}}
{"role": "user", "content": "ありがとう、それを知りたかったんだ!", "additional_kwargs": {}}
{"role": "assistant", "content": "このコンテキストに基づいて、Claude-3のツール使用に関する情報を提供しました。Claude-3では、Opusモデルを使用して複雑なツール使用をナビゲートすることが推奨されています。Opusは最も多くの同時ツールを処理でき、他のモデルと比較して欠落している引数をキャッチする能力があります。また、Haikuモデルは、単純なツールを扱う場合に適しています。これらの情報を活用して、Claudeのツール使用を効果的に設計し、Claudeの機能を拡張することができます。", "additional_kwargs": {}}
やっぱりちょっと複雑だなー、というか会話履歴を踏まえたRAGってそもそもコンテキストを会話履歴に含めるか含めないかもあるし。
ちょっと気になったのは会話履歴を配列と文字列の両方で渡しててなにしてんのかなーと。会話履歴をプロンプトに埋め込んだりしてないよね?というのをトレースで見てみる。
一応一番最後のところは会話履歴をきちんとmessagesオブジェクトで渡しているように見える。
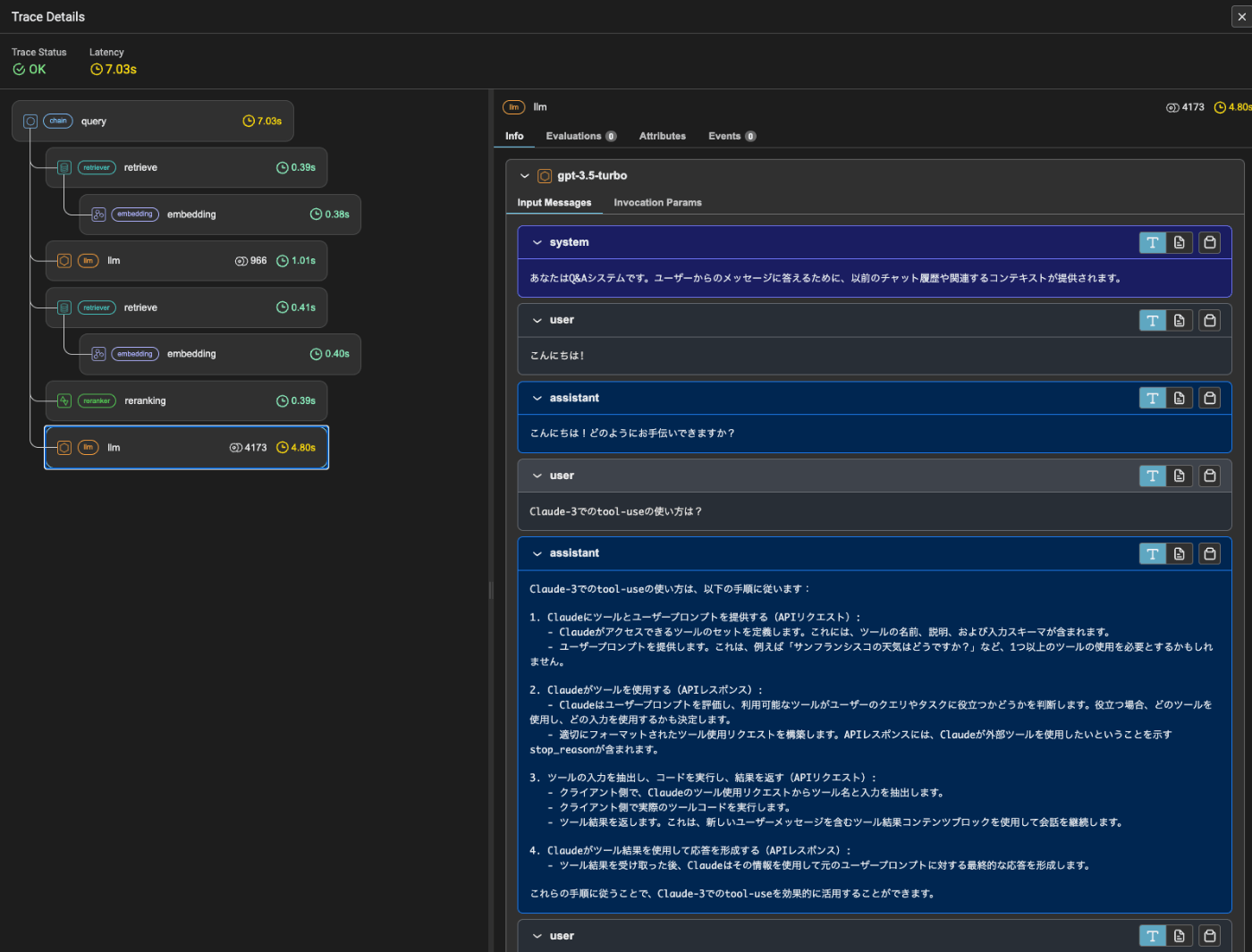
じゃあ文字列にしたやつは何してるかというとここ。
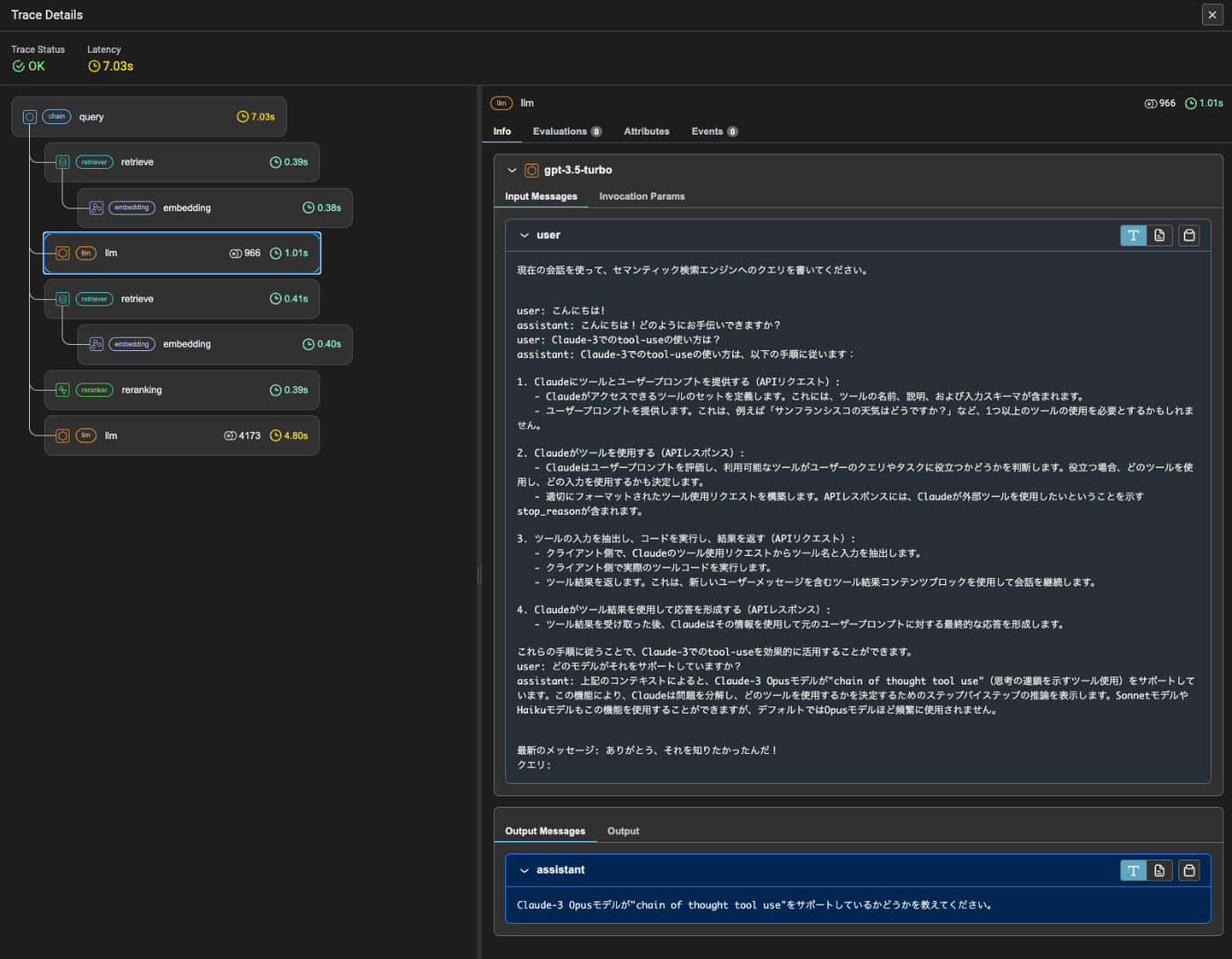
過去の会話履歴を渡してクエリを生成している。これをベクトル検索に渡すってことかな。元とは全然違うクエリになっているけれども。
でベクトル検索

その結果をリランキング
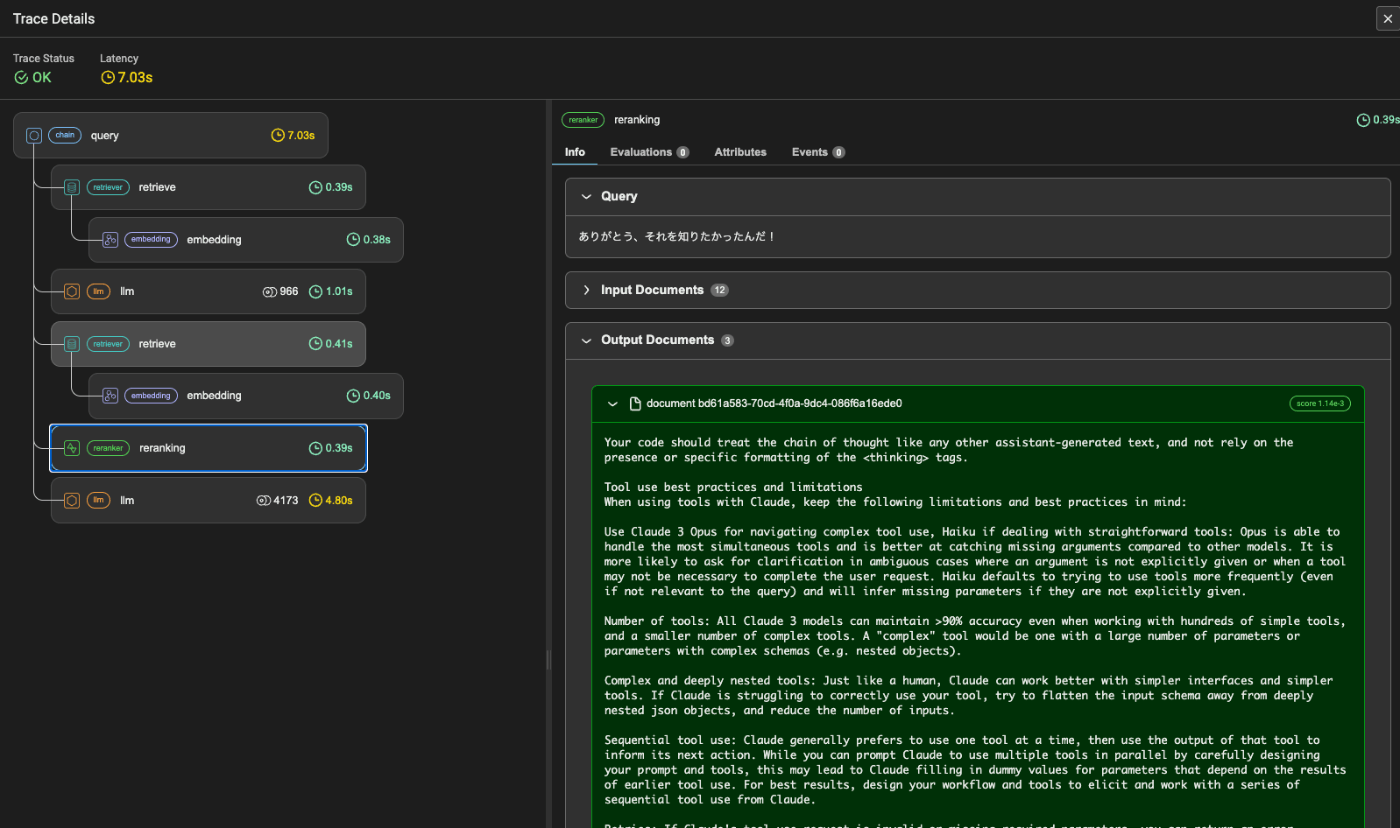
最終的な回答を生成させるためのコンテキストで使っている。なるほど、ここは元のクエリのまま。
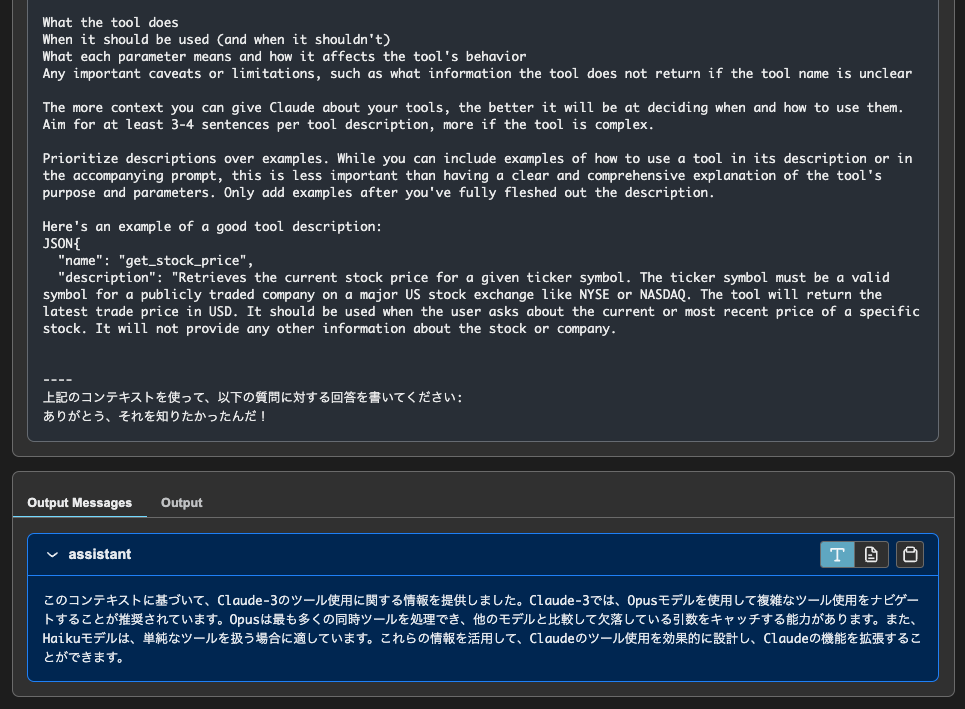
とりあえずちゃんと会話履歴は会話履歴として扱っていることは確認できた。それでも複雑になりすぎてるなーとは思うけど。
Query Pipelineを使ったエージェント
最初にも書いたけど、Query PipelineはDAGであって、ステートマシンではない。つまり基本的にはループを使ったReActのようなことはできない(ように思える)。これをエージェントを使うことで実現する。
2つのエージェントの例が紹介されている
- ReActエージェントを使ったツールの取捨選択
- エージェントを使ってText-to-SQLクエリエンジンにリトライをシンプルに実装する
ちょっとエージェント周りはまだよくわかってないけども、翻訳しつつ進める。
パッケージインストール
!pip install llama-index-llms-openai llama-index-callbacks-arize-phoenix python-dotenv pygraphviz
トレーシングを有効化
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
APIキーを読み込み
from dotenv import load_dotenv
load_dotenv(verbose=True)
サンプルとしてchinookデータベースを使う。
!curl "https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip" -O ./chinook.zip
!unzip ./chinook.zip
from llama_index.core import SQLDatabase
from sqlalchemy import (
create_engine,
MetaData,
Table,
Column,
String,
Integer,
select,
column,
)
engine = create_engine("sqlite:///chinook.db")
sql_database = SQLDatabase(engine)
このデータベースを使うクエリエンジンおよびそれをエージェントから使うためのツールを定義する。
from llama_index.core.query_engine import NLSQLTableQueryEngine
from llama_index.core.tools import QueryEngineTool
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
sql_query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["albums", "tracks", "artists"],
llm=llm,
verbose=True,
)
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
name="sql_tool",
description=(
"Useful for translating a natural language query into a SQL query"
),
)
軽く試してみる。クエリエンジンの場合。
response = sql_query_engine.query("いくつのデータが存在しますか?")
print(response)
データベースには347件のアルバムデータが存在します。
ReActエージェントの場合
from llama_index.core.agent.react import ReActAgent
sample_agent = ReActAgent.from_tools([sql_tool], llm=llm, verbose=True)
response = sample_agent.query("いくつのデータが存在しますか?")
print(response)
データベースには合計347枚のアルバムが存在します。
verboseはこんな感じ
Thought: The current language of the user is: Japanese. I need to use a tool to help me answer the question.
Action: sql_tool
Action Input: {'input': 'SELECT COUNT(*) FROM table_name'}
Observation: There are a total of 347 albums in the database.
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: データベースには合計347枚のアルバムが存在します。
動作確認ができたところで、ではまずReActエージェントをQuery Pipelineで実装してみる。
流れとしては以下となる。
- エージェントの入力を取り込む
- 次のアクション/ツールを生成するために、LLMを使用してReActプロンプトを呼び出す(もしくはレスポンスをそのまま返す)。
- ツール/アクションが選択された場合、ツールパイプラインを呼び出してツールを実行、結果を取得
- レスポンスが生成されたら取得
エージェントの場合は通常のクエリパイプラインと異なり、エージェント専用のコンポーネントを使用して、これらがQueryPipelineAgentWorkerで使用される。
-
AgentInputComponent
- エージェントの入力(タスク、ステートの辞書)をクエリパイプラインの入力セットに変換する。
-
AgentFnComponent
- 現在のタスク、ステート、任意の入力を取り込んで、出力を返す一般的なプロセッサ。
- このnotebookでは、ReActプロンプトをフォーマットする関数コンポーネントの定義に定義する。
- どこにでも配置できる。
-
CustomAgentComponent
-
AgentFnComponentと同様に、_run_componentを実装して、タスクとステートにアクセスして独自のロジックを定義することができる。 - より冗長だが、
AgentFnComponentよりも柔軟(例えば、init変数を定義でき、コールバックはベースクラスにある)。 - このnotebookでは使用しない。
-
注意は2点。
- AgentFnComponentにAgentInputComponentに渡される関数は、タスク(
task)とステート(state)を入力として受け取る必要がある。これらはエージェントから渡されるため。 - エージェントを使ったクエリパイプラインの出力は
Tuple[AgentChatResponse, bool]である必要がある。- クエリパイプラインに
verbose=Trueをつけると見れる。
- クエリパイプラインに
エージェントが実行するステップの最初に呼び出される、エージェント入力コンポーネントの定義。ここで入力を受けると同時に初期化やステートの変更を行う。
from llama_index.core.agent.react.types import (
ActionReasoningStep,
ObservationReasoningStep,
ResponseReasoningStep,
)
from llama_index.core.agent import Task, AgentChatResponse
from llama_index.core.query_pipeline import (
AgentInputComponent,
AgentFnComponent,
CustomAgentComponent,
QueryComponent,
ToolRunnerComponent,
)
from llama_index.core.llms import MessageRole
from typing import Dict, Any, Optional, Tuple, List, cast
## エージェント入力コンポーネント
## 他のコンポーネント用にエージェント入力を生成するコンポーネント
## 初期化ロジックをここに置くこともできる
def agent_input_fn(task: Task, state: Dict[str, Any]) -> Dict[str, Any]:
"""Agent input function.
Returns:
出力キーと値の辞書。
このコンポーネントと他のコンポーネント間のリンクを定義する際に`src_key`を指定する場合は、
src_keyと指定された output_key と一致することを確認すること。
"""
# 現在の推論状態を初期化
if "current_reasoning" not in state:
state["current_reasoning"] = []
reasoning_step = ObservationReasoningStep(observation=task.input)
state["current_reasoning"].append(reasoning_step)
return {"input": task.input}
agent_input_component = AgentInputComponent(fn=agent_input_fn)
ReActプロンプトを生成するエージェントコンポーネントを定義。出力はLLMで生成され、構造化オブジェクトとしてパースされる。
from llama_index.core.agent import ReActChatFormatter
from llama_index.core.query_pipeline import InputComponent, Link
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool
## ReActプロンプト関数の定義
def react_prompt_fn(
task: Task, state: Dict[str, Any], input: str, tools: List[BaseTool]
) -> List[ChatMessage]:
# 入力を推論に追加
chat_formatter = ReActChatFormatter()
return chat_formatter.format(
tools,
chat_history=task.memory.get() + state["memory"].get_all(),
current_reasoning=state["current_reasoning"],
)
react_prompt_component = AgentFnComponent(
fn=react_prompt_fn, partial_dict={"tools": [sql_tool]}
)
エージェントの出力パーサとツールパイプラインの定義。
LLMが出力を生成すると、ここで判断分岐が行われる。
- 回答が与えられたら、そのまま出力
- アクションが与えられたら、特定のツールにパラメータを与えて実行、結果を出力
ツールの呼び出しはToolRunnerComponentモジュールが行う。``ToolRunnerComponent`モジュールは、ツールのリストを受け取る単純なラッパーモジュールで、ツール名とアクションを指定してツールを実行する。
これらをCustomAgentComponentから派生させたクラスとしてOutputAgentComponentを作成、ツールランナーのサブモジュールに高レベルのコールバック・マネージャーを渡すためにsub_query_componentsも作成している。
from typing import Set, Optional
from llama_index.core.agent.react.output_parser import ReActOutputParser
from llama_index.core.llms import ChatResponse
from llama_index.core.agent.types import Task
def parse_react_output_fn(
task: Task, state: Dict[str, Any], chat_response: ChatResponse
):
"""Parse ReAct output into a reasoning step."""
output_parser = ReActOutputParser()
reasoning_step = output_parser.parse(chat_response.message.content)
return {"done": reasoning_step.is_done, "reasoning_step": reasoning_step}
parse_react_output = AgentFnComponent(fn=parse_react_output_fn)
def run_tool_fn(
task: Task, state: Dict[str, Any], reasoning_step: ActionReasoningStep
):
"""Run tool and process tool output."""
tool_runner_component = ToolRunnerComponent(
[sql_tool], callback_manager=task.callback_manager
)
tool_output = tool_runner_component.run_component(
tool_name=reasoning_step.action,
tool_input=reasoning_step.action_input,
)
observation_step = ObservationReasoningStep(observation=str(tool_output))
state["current_reasoning"].append(observation_step)
# TODO: get output
return {"response_str": observation_step.get_content(), "is_done": False}
run_tool = AgentFnComponent(fn=run_tool_fn)
def process_response_fn(
task: Task, state: Dict[str, Any], response_step: ResponseReasoningStep
):
"""Process response."""
state["current_reasoning"].append(response_step)
response_str = response_step.response
# Now that we're done with this step, put into memory
state["memory"].put(ChatMessage(content=task.input, role=MessageRole.USER))
state["memory"].put(
ChatMessage(content=response_str, role=MessageRole.ASSISTANT)
)
return {"response_str": response_str, "is_done": True}
process_response = AgentFnComponent(fn=process_response_fn)
def process_agent_response_fn(
task: Task, state: Dict[str, Any], response_dict: dict
):
"""Process agent response."""
return (
AgentChatResponse(response_dict["response_str"]),
response_dict["is_done"],
)
process_agent_response = AgentFnComponent(fn=process_agent_response_fn)
これらを最上位のエージェントパイプラインとして作成する。エージェント入力 -> ReActプロンプト -> LLM -> ReAct出力と流れて、最後にサブコンポーネントを呼び出すかどうかの分岐が行われる。
# Reactプロンプトへの入力を、パースされたレスポンスにリンクする
qp.add_chain(["agent_input", "react_prompt", "llm", "react_output_parser"])
# ReActの出力からツール呼び出しを判断するためのリンクを追加
qp.add_link(
"react_output_parser",
"run_tool",
condition_fn=lambda x: not x["done"],
input_fn=lambda x: x["reasoning_step"],
)
# ReActの出力から最終回答を判断するためのリンクを追加
qp.add_link(
"react_output_parser",
"process_response",
condition_fn=lambda x: x["done"],
input_fn=lambda x: x["reasoning_step"],
)
# レスポンス処理かツール出力処理かにかかわらず、最終的なエージェントレスポンスへのリンクを追加
qp.add_link("process_response", "process_agent_response")
qp.add_link("run_tool", "process_agent_response")
可視化
from networkx.drawing.nx_agraph import to_agraph
from IPython.display import Image
agraph = to_agraph(qp.dag)
agraph.layout(prog="dot")
agraph.draw('agent.png')
display(Image('agent.png'))
図はシンプルだけどやってることは結構複雑だよなー
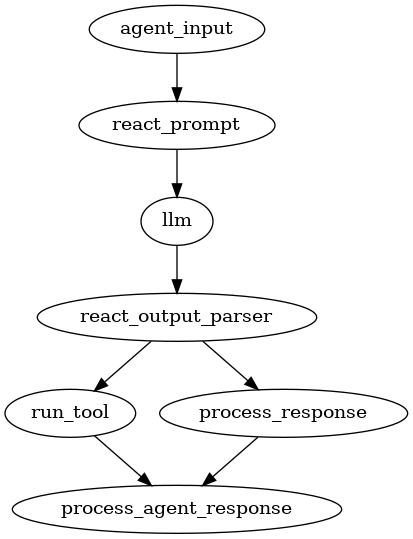
で、これらをエージェントでラップする。
from llama_index.core.agent import QueryPipelineAgentWorker, AgentRunner
from llama_index.core.callbacks import CallbackManager
agent_worker = QueryPipelineAgentWorker(qp)
agent = AgentRunner(
agent_worker, callback_manager=CallbackManager([]), verbose=True
)
実行
agent.reset()
response = agent.chat(
"アーティストAC/DCの楽曲を教えて下さい?3曲まで。"
)
AC/DCの楽曲の中で、"For Those About To Rock (We Salute You)", "Put The Finger On You", そして "Let's Get It Up" があります。
でエージェントの場合はステップごとに確認ができるっぽい。
一旦初期化。
agent.reset()
タスクを作成。
task = agent.create_task(
"アーティストAC/DCの楽曲を教えて下さい?3曲まで。"
)
タスクをステップ実行
step_output = agent.run_step(task.task_id)
step_output.is_last
verboseの出力はこんな感じ。
> Running step 34b5dca4-7445-40f7-9d64-e615ef074530. Step input: アーティストAC/DCの楽曲を教えて下さい?3曲まで。
> Running module agent_input with input:
state: {'sources': [], 'memory': ChatMemoryBuffer(token_limit=3000, tokenizer_fn=functools.partial(<bound method Encoding.encode of <Encoding 'cl100k_base'>>, allowed_special='all'), chat_store=SimpleChatSto...
task: task_id='00668449-5f01-477a-a1de-61524cd3a324' input='アーティストAC/DCの楽曲を教えて下さい?3曲まで。' memory=ChatMemoryBuffer(token_limit=3000, tokenizer_fn=functools.partial(<bound method Encoding.encode of <Encoding '...
> Running module react_prompt with input:
input: アーティストAC/DCの楽曲を教えて下さい?3曲まで。
> Running module llm with input:
messages: [ChatMessage(role=<MessageRole.SYSTEM: 'system'>, content='You are designed to help with a variety of tasks, from answering questions to providing summaries to other types of analyses.\n\n## Tools\n\n...
> Running module react_output_parser with input:
chat_response: assistant: Thought: The current language of the user is: Japanese. I need to use a tool to help me answer the question.
Action: sql_tool
Action Input: {"input": "SELECT song_name FROM artists_songs WH...
> Running module run_tool with input:
reasoning_step: thought='The current language of the user is: Japanese. I need to use a tool to help me answer the question.' action='sql_tool' action_input={'input': "SELECT song_name FROM artists_songs WHERE artist...
> Running module process_agent_response with input:
response_dict: {'response_str': 'Observation: {\'output\': ToolOutput(content=\'Some of AC/DC\\\'s songs are "For Those About To Rock (We Salute You)", "Put The Finger On You", and "Let\\\'s Get It Up".\', tool_name...
False
最後にタスクの状態が表示されるが、まだ終わっていない。
これを何度か繰り返すとTrueになる。ちなみにgpt-3.5-turboだとこのループが結構続くので、エージェント的な判断にはgpt-4の方が良いというのはまあそうなんだろうと思う。
Trueになったら、最終回答を確認
response = agent.finalize_response(task.task_id)
print(str(response))
AC/DCの曲の中から3曲は、「For Those About To Rock (We Salute You)」、「Put The Finger On You」、「Let's Get It Up」です。
もう一つの例として、Text-to-SQLクエリエンジンにリトライを行うシンプルなエージェントの例。
上の続きから。ここはサラッと。
LLMの定義
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-0125")
エージェント入力コンポーネントの定義
from llama_index.core.agent import Task, AgentChatResponse
from typing import Dict, Any
from llama_index.core.query_pipeline import (
AgentInputComponent,
AgentFnComponent,
)
def agent_input_fn(task: Task, state: Dict[str, Any]) -> Dict:
"""Agent input function."""
if "convo_history" not in state:
state["convo_history"] = []
state["count"] = 0
state["convo_history"].append(f"User: {task.input}")
convo_history_str = "\n".join(state["convo_history"]) or "None"
return {"input": task.input, "convo_history": convo_history_str}
agent_input_component = AgentInputComponent(fn=agent_input_fn)
SQL実行がうまくいかなかった場合のリトライを行うプロンプトコンポーネントの定義。
from llama_index.core import PromptTemplate
retry_prompt_str = """\
あなたは、ユーザ入力から適切な自然言語クエリを生成しようとしています。
このクエリは、クエリをSQL文に変換する下流のtext-to-SQLエージェントによって解釈されます。
エージェントがエラーをトリガーした場合、現在の会話履歴に反映されます(下記参照)。
会話履歴がNoneの場合、ユーザ入力を使用します。
Noneでない場合は、前のSQLクエリの問題を回避した新しいSQLクエリを生成します。
入力: {input}
会話履歴 (失敗した試み):
{convo_history}
新しい入力: """
retry_prompt = PromptTemplate(retry_prompt_str)
SQL実行を行うためプロンプトと出力用のコンポーネントの定義
from llama_index.core import Response
from typing import Tuple
validate_prompt_str = """\
与えられたユーザークエリから、推論されたSQLクエリとクエリ実行によるレスポンスが正しいかどうか、そしてクエリに答えれているかかどうかを検証してください。
結果は YES または NO で回答してください。
クエリ: {input}
推論されたSQLクエリ: {sql_query}
SQLの結果: {sql_response}
結果: """
validate_prompt = PromptTemplate(validate_prompt_str)
MAX_ITER = 3
def agent_output_fn(
task: Task, state: Dict[str, Any], output: Response
) -> Tuple[AgentChatResponse, bool]:
"""Agent output component."""
print(f"> Inferred SQL Query: {output.metadata['sql_query']}")
print(f"> SQL Response: {str(output)}")
state["convo_history"].append(
f"Assistant (inferred SQL query): {output.metadata['sql_query']}"
)
state["convo_history"].append(f"Assistant (response): {str(output)}")
# レスポンスを得るために小さなチェーンを実行する
validate_prompt_partial = validate_prompt.as_query_component(
partial={
"sql_query": output.metadata["sql_query"],
"sql_response": str(output),
}
)
qp = QP(chain=[validate_prompt_partial, llm])
validate_output = qp.run(input=task.input)
state["count"] += 1
is_done = False
if state["count"] >= MAX_ITER:
is_done = True
if "YES" in validate_output.message.content:
is_done = True
return AgentChatResponse(response=str(output)), is_done
agent_output_component = AgentFnComponent(fn=agent_output_fn)
パイプラインの作成。
from llama_index.core.query_pipeline import (
QueryPipeline as QP,
Link,
InputComponent,
)
qp = QP(
modules={
"input": agent_input_component,
"retry_prompt": retry_prompt,
"llm": llm,
"sql_query_engine": sql_query_engine,
"output_component": agent_output_component,
},
verbose=True,
)
qp.add_link("input", "retry_prompt", src_key="input", dest_key="input")
qp.add_link(
"input", "retry_prompt", src_key="convo_history", dest_key="convo_history"
)
qp.add_chain(["retry_prompt", "llm", "sql_query_engine", "output_component"])
可視化
from networkx.drawing.nx_agraph import to_agraph
from IPython.display import Image
agraph = to_agraph(qp.dag)
agraph.layout(prog="dot")
agraph.draw('agent_retry.png')
display(Image('agent_retry.png'))
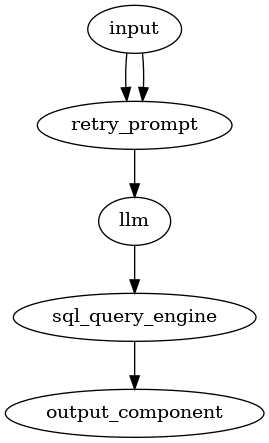
ではエージェントを作成して実行。
from llama_index.core.agent import QueryPipelineAgentWorker, AgentRunner
from llama_index.core.callbacks import CallbackManager
agent_worker = QueryPipelineAgentWorker(qp)
agent = AgentRunner(
agent_worker, callback_manager=CallbackManager(), verbose=False
)
response = agent.chat(
"「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)"
)
print(str(response))
「Restless and Wild」を書いたアーティストはAcceptというバンドで、1枚のアルバムをリリースしています。
verboseを見ると、最初に生成したSQLがうまくいかなかったので、再度SQLを生成し直しているのがわかる。
> Running module input with input:
state: {'sources': [], 'memory': ChatMemoryBuffer(token_limit=3000, tokenizer_fn=functools.partial(<bound method Encoding.encode of <Encoding 'cl100k_base'>>, allowed_special='all'), chat_store=SimpleChatSto...
task: task_id='f1d6032a-4963-46ca-97ca-31aa8678c9a3' input='「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)' memory=ChatMemoryBuffer(token_limit=3000, tokenizer_fn=functools.partial(<bound method...
> Running module retry_prompt with input:
input: 「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)
convo_history: User: 「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)
> Running module llm with input:
messages: あなたは、ユーザ入力から適切な自然言語クエリを生成しようとしています。
このクエリは、クエリをSQL文に変換する下流のtext-to-SQLエージェントによって解釈されます。
エージェントがエラーをトリガーした場合、現在の会話履歴に反映されます(下記参照)。
会話履歴がNoneの場合、ユーザ入力を使用します。
Noneでない場合は、前のSQLクエリの問題を回避した新しいSQLクエリを生成します...
> Running module sql_query_engine with input:
input: assistant: 「Restless and Wild」を書いたアーティストのアルバム数は何枚ですか?
> Running module output_component with input:
output: I'm sorry, but there was an error in running the SQL query to find out how many albums the artist who wrote "Restless and Wild" has. Unfortunately, I am unable to provide you with the specific number ...
> Inferred SQL Query: SQL Query to run:
SELECT artists.Name, COUNT(albums.AlbumId) AS AlbumCount
FROM artists
JOIN albums ON artists.ArtistId = albums.ArtbumId
WHERE albums.Title = "Restless and Wild"
GROUP BY artists.Name
> SQL Response: I'm sorry, but there was an error in running the SQL query to find out how many albums the artist who wrote "Restless and Wild" has. Unfortunately, I am unable to provide you with the specific number of albums at this time.
> Running module input with input:
state: {'sources': [], 'memory': ChatMemoryBuffer(token_limit=3000, tokenizer_fn=functools.partial(<bound method Encoding.encode of <Encoding 'cl100k_base'>>, allowed_special='all'), chat_store=SimpleChatSto...
task: task_id='f1d6032a-4963-46ca-97ca-31aa8678c9a3' input='「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)' memory=ChatMemoryBuffer(token_limit=3000, tokenizer_fn=functools.partial(<bound method...
> Running module retry_prompt with input:
input: 「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)
convo_history: User: 「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)
Assistant (inferred SQL query): SQL Query to run:
SELECT artists.Name, COUNT(albums.AlbumId) AS AlbumCount
FROM artists
JOIN albums ON...
> Running module llm with input:
messages: あなたは、ユーザ入力から適切な自然言語クエリを生成しようとしています。
このクエリは、クエリをSQL文に変換する下流のtext-to-SQLエージェントによって解釈されます。
エージェントがエラーをトリガーした場合、現在の会話履歴に反映されます(下記参照)。
会話履歴がNoneの場合、ユーザ入力を使用します。
Noneでない場合は、前のSQLクエリの問題を回避した新しいSQLクエリを生成します...
> Running module sql_query_engine with input:
input: assistant: 「Restless and Wild」を書いたアーティストは何枚のアルバムをリリースした?(答えはゼロではないはず)
> Running module output_component with input:
output: 「Restless and Wild」を書いたアーティストはAcceptというバンドで、1枚のアルバムをリリースしています。
> Inferred SQL Query: SELECT artists.Name, COUNT(albums.AlbumId) AS AlbumCount
FROM artists
JOIN albums ON artists.ArtistId = albums.ArtistId
WHERE albums.Title = "Restless and Wild"
GROUP BY artists.Name
> SQL Response: 「Restless and Wild」を書いたアーティストはAcceptというバンドで、1枚のアルバムをリリースしています。
「Restless and Wild」を書いたアーティストはAcceptというバンドで、1枚のアルバムをリリースしています。
エージェントになるとだいぶ複雑になるよなー。ちょっと現時点の自分には難しすぎる。
エージェントまで行くとちょっとしんどいけど、こういうパイプラインをフロー的に定義できる仕組みはやっぱりいいよなぁと思っている。Query Pipelineは抽象化の度合いがきついよなぁと思っていたのだけども、むしろコンポーネント単位になるので積極的に使うほうがいい気がしている。わかりやすいし。
とりあえずもう少し調べたいこと。
- Routersは、過去にLlamaIndex一通り触った時にはスキップしていたので改めて触っておきたい。
- Query Pipelineで使えるモジュールをもう少し確認。QueryEngineとかRetrieverみたいな単体で使えるモジュールだけじゃなくて、ユーティリティ的なモジュールについて。
- ちょっとQuery Pipelineでしんどいなと思ったところ
- 会話履歴扱うだけでこんな面倒なことしないといけないのかな?ChatEngine使ってもっとライトにできないのかな?
- ただ正直LlamaIndexの会話履歴周りはLangChainに比べると弱い感はある。いまでもファイルベースかRedisしかないので。LangChainのインテグレーションが山程あるのに比べるとかなり弱い。
あと久々にLangChain触りたくなった。LCELはQuery Pipelineと同等のものだと思うし、LCEL使うならば、LangChainで抽象度がーとかいろいろ言われているようなこともある程度緩和できる気がしている。