Closed6
OpenAI DevDay 2023セッション: "A Survey of Techniques for Maximizing LLM Performance"におけるRAGの精度改善手法まとめ
RAG回りのところだけポイントをまとめた。
15:12〜18:32
- ユーザーの質問に基づいて複数の知識ベースのどちらを使用するかを決定するRAGパイプライン
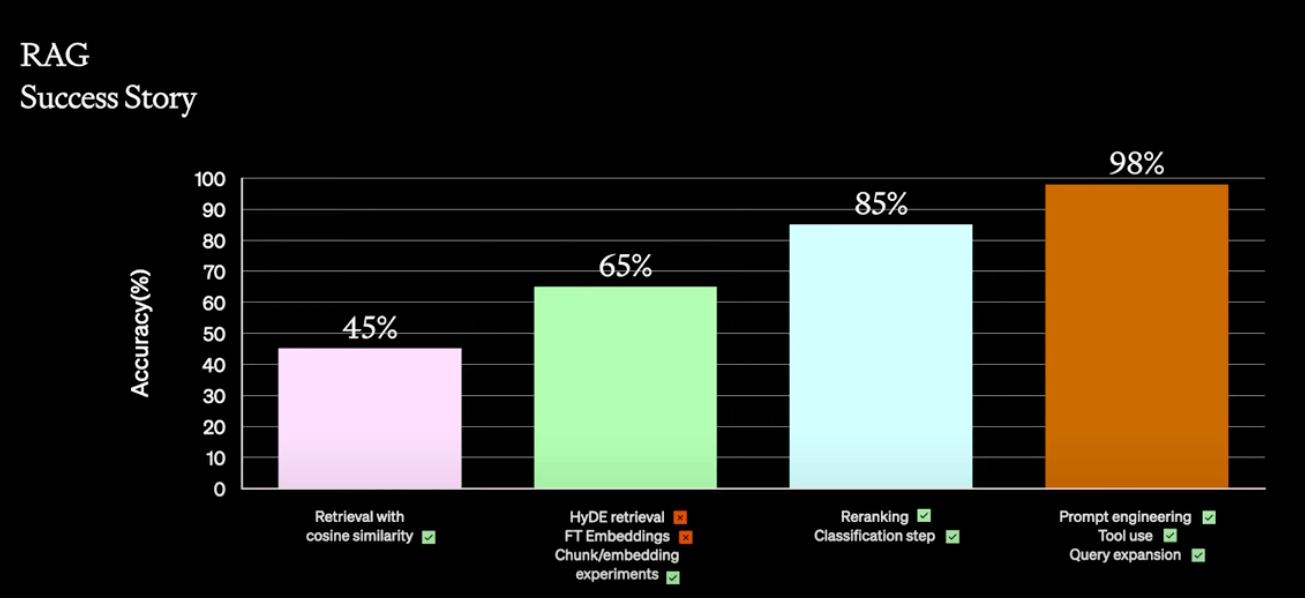
- パイプラインのベースライン精度は45%だった。
- 仮説的文書埋め込み(HyDE)を導入し、精度を65%まで向上。しかし、特定のユースケースではうまく機能せず。
- 埋め込みの微調整も試みられたが、高コストと遅さのために採用されず。
- 様々なサイズの情報チャンク、様々なコンテンツの埋め込みを行い、関連性の高い情報の識別が可能になり、20%の改善が見られたが、まだ十分ではなかった。20回ほど繰り返した。
- クロスエンコーダやルールベースのリランキングにより、パフォーマンスが大幅に向上。
- モデルにドメインの分類を判断させてプロンプトにメタデータを追加することで、85%の精度を達成。
- プロンプトエンジニアリングに戻り、質問のカテゴリーを分析し、ツールを導入。SQLデータベースへのアクセスを可能にし、構造化データの問題を解決。
- クエリ拡張を行い、複数の質問を組み合わせて同時に実行し、精度を98%に向上。
- このプロセスではファインチューニングは使用せず、コンテキストの正確な提供が重要であることが示された。
実際のベンチマークでの事例
39:45〜43:14
- 自然言語による質問とデータベーススキーマが与えられたときに、その質問に答える構文的に正しいSQLクエリを作成できるかというベンチマーク
- プロンプトエンジニアリングとRAGからスタート。RAGは最もシンプルな、質問のコサイン類似検索。
- 埋め込みフォーマットの変更やプロンプトエンジニアリングを少し試したがそれほど効果はなかった。
- HyDEを使用して、仮説的なSQLクエリを生成して類似検索を実施、大幅に改善
- シンプルなフィルタで文脈的なリトリーバルも実施。受け取った質問の難易度をランク付け、RAGで等しい難易度の例だけを取り出すことでわずかに改善。
- これにいくつかの高度な技術を試す
- Chain Of Thoughtで、カラムを特定、テーブルを特定、するプロセスを経てから、クエリを作成
- Self Consistencyで、生成したクエリを実行、間違えた場合はエラーや注釈を追加
- 最終的にはSelf Consistencyを採用
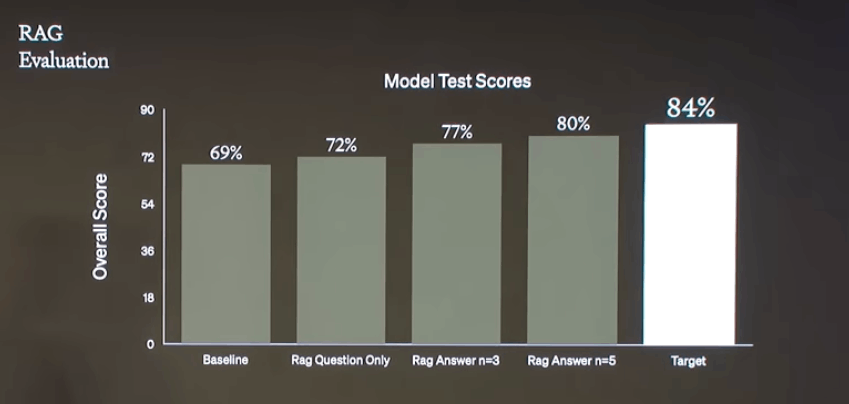
- 69%から開始
- few shotでいくらか改善。これによりRAGがさらなる改善をもたらす可能性があることがわかる。質問を試してみて、3%のパフォーマンス向上。
- 回答を使用したHyDEでさらに5%の向上
- 実際に入力された質問ではなく、仮説的な質問での検索ににより大きなパフォーマンス向上
- few shotの数を増やしてSOTAアプローチにわずか4ポイントまで迫った
- プロンプトエンジニアリングからRAGという基本的なアプローチでパフォーマンスを引き出せることを示している
所感
個人的に思ったことを雑に書く。
- HyDEがマッチするような適切なユースケースの判断は難しいので、あまりこのテクニックは使えないと思っていた。ユースケース判断するぐらいなら検索サイドで頑張る方が良い(ハイブリッドとか)と思っていたけど、マッチする場合にはプロダクションでも使えるぐらい効果があるというのがわかったのは良かった。
- Retrieval
- コンテキストをどうチャンクするか、どのコンテキストを埋め込みにするか、他の用途で使うためのメタデータをどうするか、というところは難しい。ここは試行錯誤で最適値を見つける必要がある。
- リランキングはそうだよね、特にハイブリッドだと重要になると思っている。
- フィルタリングは具体的にわからなかったのだけど、結局のところは以下にノイズを減らしてシグナルを増やすかという取り組みが必要ってことだよね。
- なんとなくReader-Retrieverみたいに役割を明確に分けるのはRAGで精度を上げるにはちょっと難しいのかなという気がした。RAGはなんというかこのあたりが密になってる気がしてる。
- 試行錯誤を繰り返すためにも評価のフレームワークを用意しておくべき。RAGASちょっと試してみよう。
- ちょっと残念だなと思ったのは以下あたりの話がなかったこと
- ハイブリッドの話
- 入力された質問から、直接は関係しないけど関連しそうなコンテキストを拾うことで、より回答をリッチにするみたいな話
上記のLangChainによる実装
npaka先生の記事
いつの間にか公式ドキュメントにも載ってた
このスクラップは2023/11/15にクローズされました