「GPT-SoVITS」を試す
GitHubレポジトリ
GPT-SoVITS-WebUI
強力なFew-shot音声変換およびテキスト読み上げ(TTS)WebUI。
機能
ゼロショットTTS:5秒間の音声サンプルを入力するだけで即座にテキスト読み上げを体験可能。
Few-shot TTS:わずか1分のトレーニングデータでモデルを微調整し、音声の類似性とリアルさを向上。
クロスリンガル対応:異なる言語での推論に対応。現在は英語、日本語、韓国語、広東語、中国語をサポート。
WebUIツール群:音声と伴奏の分離、自動トレーニングセット分割、中国語ASR、テキストラベリングなどの統合ツールにより、初心者でも簡単にトレーニングデータやGPT/SoVITSモデルを作成可能。
最初にローカルのMacでPython環境作って試してみたのだけども、pyopenjtalkが元々入っているcmakeのバージョンと合わないみたいで、ビルドが通らず断念。Ubuntu-22.04サーバ(GPU: RTX4090)に変更。
依存しているOSパッケージを追加。soxはいらないのだけど、過去入れたつもりになっていて、入れてなかったのでついでに。
sudo apt install -y ffmpeg libsox-dev sox
レポジトリクローン
git clone https://github.com/RVC-Boss/GPT-SoVITS && cd GPT-SoVITS
uvでPython仮想環境を作成する。READMEを見る限り3.10が良さそう。
uv init -p 3.10
uv venv
パッケージインストール
uv pip install -r extra-req.txt --no-deps
uv pip install -r requirements.txt
モデル周りは何が必要で何が不要なのかは現時点ではわかっていないが、記載どおりインストールしていく。日本語に関係ありそうなものだけ。
事前学習モデルをGPT_SoVITS/pretrained_modelsにダウンロードする
cd GPT_SoVITS/pretrained_models
git lfs install
git clone https://huggingface.co/lj1995/GPT-SoVITS
mv GPT-SoVITS/* .
rmdir GPT-SoVITS
cd ../..
ボーカル音声だけを抽出するUVR5の重みをtools/uvr5/uvr5_weightsにダウンロード。かなり時間がかかる。
cd tools/uvr5/uvr5_weights
git clone --filter=blob:none --no-checkout https://huggingface.co/lj1995/VoiceConversionWebUI
cd VoiceConversionWebUI
git sparse-checkout init
git sparse-checkout set uvr5_weights/
git checkout
mv uvr5_weights/* ../.
cd ..
rm -rf VoiceConversionWebUI
cd ../../..
日本語ASRのためにFaster Whisper Large V3をtools/asr/modelsにダウンロード。他のモデルも使えるみたいだけど、どういうパス構造にしたらいいのかわからないので、とりあえずまるっとダウンロードだけ。
cd tools/asr/models
git clone https://huggingface.co/Systran/faster-whisper-large-v3
cd ../../..
ではまず推論から。WebGUIを立ち上げる。
uv run webui.py ja_JP
READMEを読む限り、G2PWモデルについては中国語のみ、と思っていたがどうやら必要なようで、自動でダウンロードされた。
Downloading g2pw model...
Extracting g2pw model...
以下のように表示されればOK。
Running on local URL: http://0.0.0.0:9874
ブラウザでアクセス。

メニューが豊富すぎて使い方がわからない。調べてみたら以下がとてもわかりやすい、というか内容が新しいのとインストール手順がほぼ載ってた。ここを最初に見とけばよかった。
TTS(Zero-shot)
TTSは、「1-GPT-SoVITS-TTS」タブ→「1C-推論」タブ→「有効化TTS推論WebUI」で表示される・・・
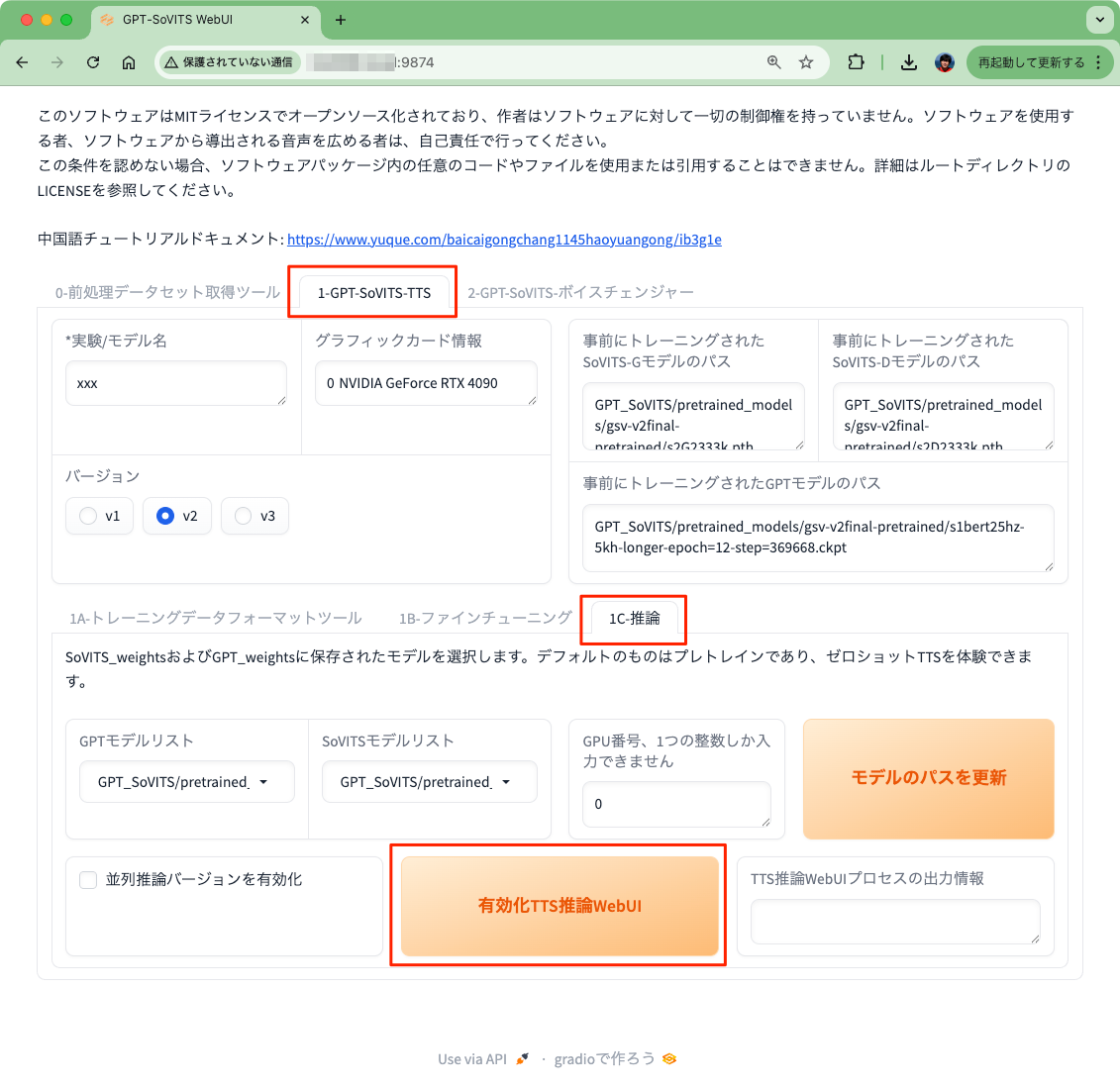
ようなのだが、「TTS推論WebUI有効化しました」と表示されボタンにも「閉じるTTS推論WebUI」と変わっているのに、何も表示されない・・・
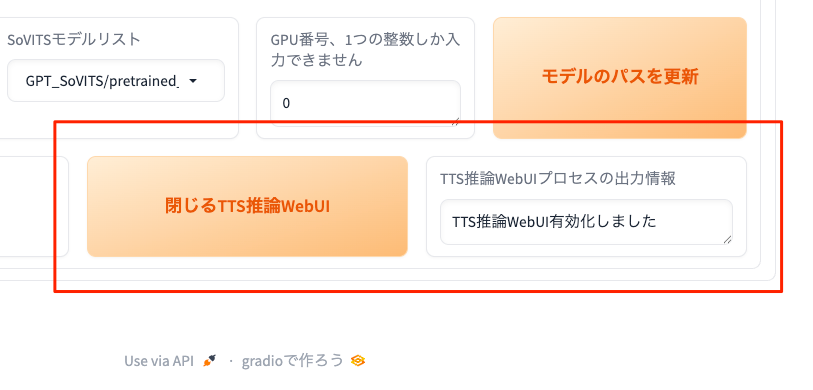
コンソールの出力を見ると以下のようなログが出ていた。
"/XXX/GPT-SoVITS/.venv/bin/python3" GPT_SoVITS/inference_webui.py "ja_JP"
loading sovits_v1 <All keys matched successfully>
Running on local URL: http://0.0.0.0:9872
なるほど、別ポートでUIが立ち上がっているようなので、そちらにアクセスする、もしくはゼロショットTTSだけで良いなら、GPT_SoVITS/inference_webui.pyを起動すればいいのかも知れない。
あと、loading sovits_v1となっているが、確かGPT-SoVITSはv3が最新のはず・・・とりあえずそこは後で考えることにする。
ブラウザで別タブを開いて9872番ポートにアクセスすると、TTSの画面が表示された。
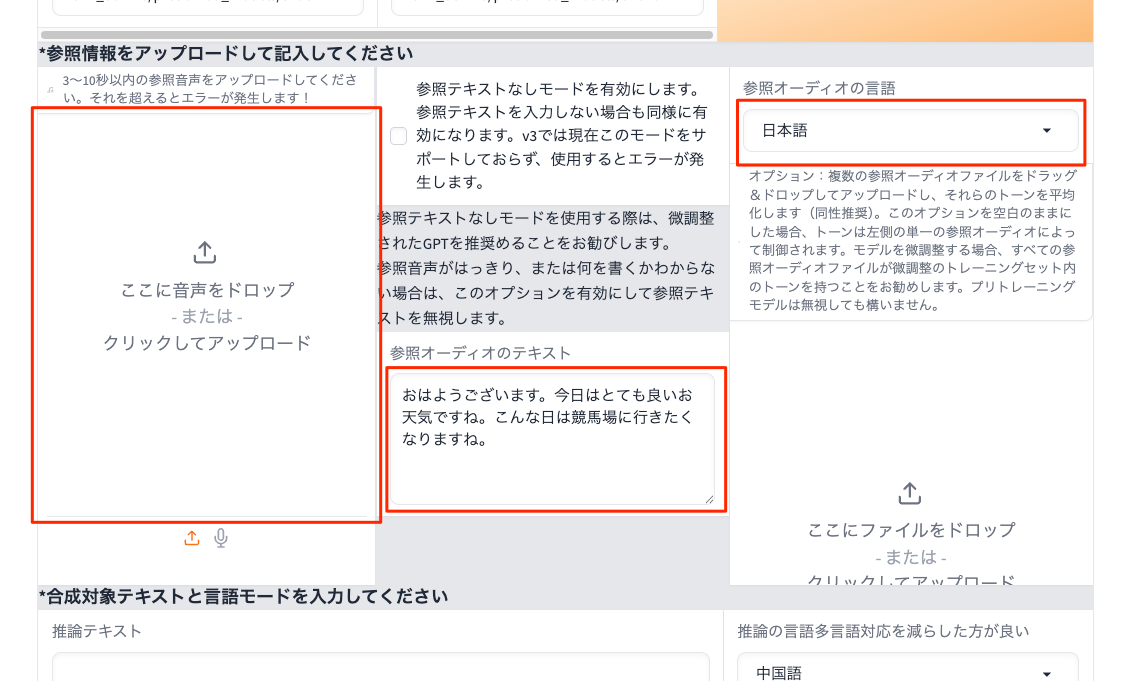
とりあえずZero-shot用の音声データを用意する。UIには「3〜10秒以内」と記載されている。マイクで自分の音声を録音してWAVファイルにした。文章はこんな感じ。
おはようございます。今日はとても良いお天気ですね。こんな日は競馬場に行きたくなりますね。
参照情報載の設定。以下のように設定してWAVファイルをアップロード。
次に生成の設定。以下のように設定して「推論を開始」をクリック。なお、文章はここにあったものを参照させてもらった。
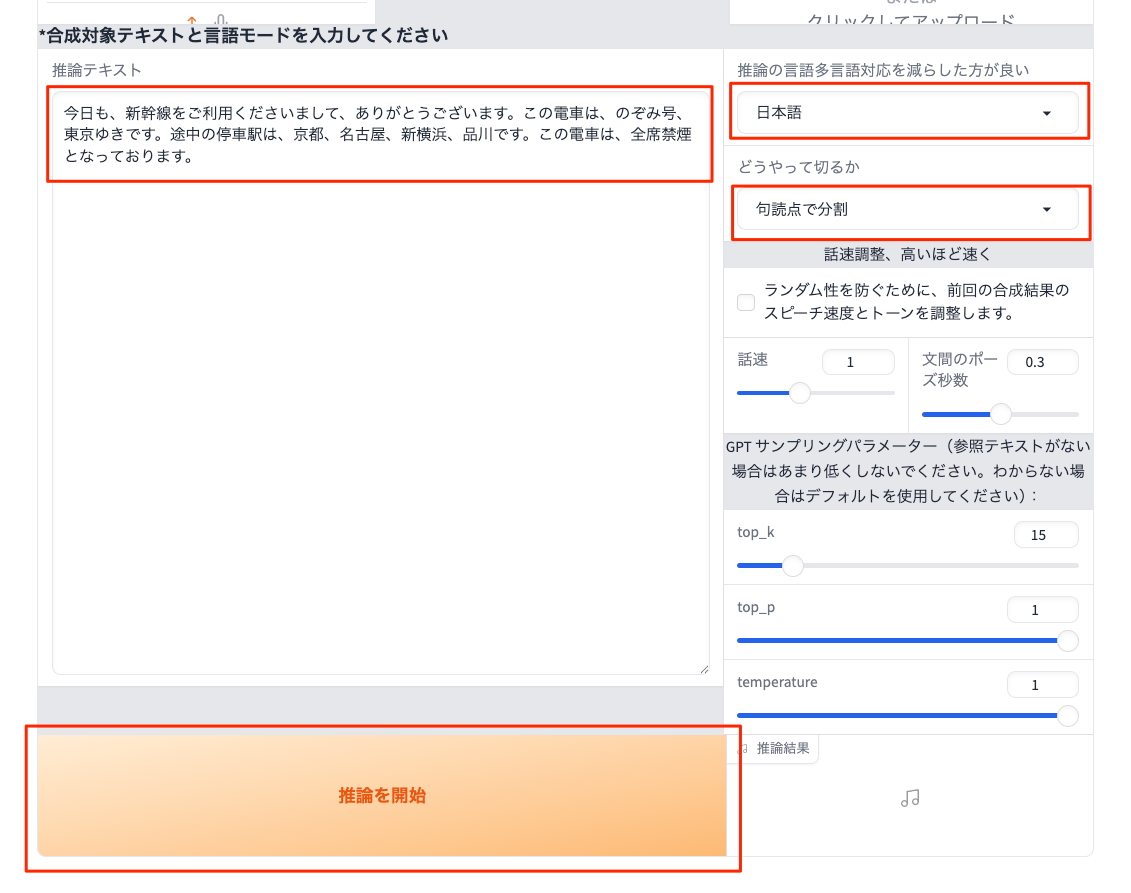
できたものはこんな感じ。なかなか厳しい・・・
で、
あと、
loading sovits_v1となっているが、確かGPT-SoVITSはv3が最新のはず・・・とりあえずそこは後で考えることにする。
のところが気になったので、上部にあるモデルリストを見てみる。

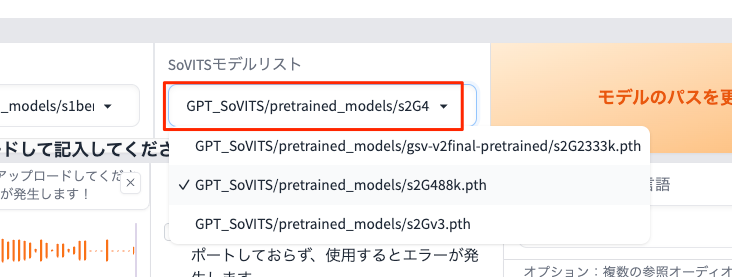
GPT-SoVITSの記事を色々確認してみたところ、
- v1
- GPTモデル: `GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt
- SoVITSモデル:
GPT_SoVITS/pretrained_models/s2G488k.pth
- v2
- GPTモデル:
GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt - SoVITSモデル:
GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth
- GPTモデル:
のようで、おそらく残りが最も新しいv3になるのだと思う。名前にもv3って入ってるし。
- v3
- GPTモデル:
GPT_SoVITS/pretrained_models/s1v3.ckpt - SoVITSモデル:
GPT_SoVITS/pretrained_models/s2Gv3.pth
- GPTモデル:
つまりさっきの設定だとv1で生成していたことになるのだね。じゃあv2とv3でそれぞれ設定してみるとどう違うか?ということで生成してみた。
v2
v3。なお、v3はUIが少し異なる様子。
少なくともv1よりもv2・v3のほうが良いように思う。v2とv3でそれほど違いがあるかどうかは微妙なところ・・・いずれにせよ、自分の元の声とも違ってるし、あまり良いクオリティには思えないな。
で、上で紹介したPC Watchの記事を見ると以下とある。
実際に聞いてみると抑揚は小さく、いくつかの箇所のイントネーションもおかしい印象が強い。というか声だけだとほぼ別人な気がする。ちなみにひたすら暗い声に聞こえるのは、純粋にモデル(データじゃなくてテストデータを録音した人という意味のモデル)が悪いのだろう。これについては最初のデータをもっと明るく録れば良かったのだろうか。
最近は利用の自由度が高い音声データが数多く公開されている。フリー素材キャラクター「つくよみちゃん」が無料公開している「 つくよみちゃんコーパス(CV.夢前黎) 」もそんなデータの1つだ。
自分の声との差は歴然である。元のモデルが良いとそれだけ結果も良くなる。そんな正論が時に人を傷つけることがあることを、もっと考えてから試すべきだった。
自分もとあるコーパスの音声で試してみたが、元の音声とはやや違うような部分もありつつも、上記の記事と同じく、全然品質が良い結果となった。なるほど、リファレンスとなる音声データの品質は重要になるということか。
このタブは閉じて、元の画面で「閉じる〜」をクリックするとTTS推論用のWebUIのプロセスは終了する。

TTS推論WebUIプロセスが終了しました
ファインチューニング(Few-shot)
こちらも以下の記事に記載があるので、それに従えば良さそう。
手順の流れも記載されている。助かる。
実際に順を追って手順を紹介しよう。先に伝えておくと、次のような手順になる。
- 1分以上の音声データを生成する
- それを数秒ごとのデータに分割する
- 各データのノイズを除去する
- 各データごとに発言内容を記載したラベルデータを作成する
- トレーニング用のメタデータを作成する
- データからSoVITSのトレーニングを行なう
- データからGPTのトレーニングを行なう
でひと通り試してみたけど、自分はFaster Whisperを使ったラベルデータの自動作成が普通にできたので、モデルのダウンロード手順はあっていた。
日本語ASRのためにFaster Whisper Large V3をtools/asr/modelsにダウンロード。他のモデルも使えるみたいだけど、どういうパス構造にしたらいいのかわからないので、とりあえずまるっとダウンロードだけ。
cd tools/asr/models git clone https://huggingface.co/Systran/faster-whisper-large-v3 cd ../../..
こんな感じでモデルを選択して「有効化音声認識」をクリックすればよい。で、ASRでラベリングされたファイルはoutput/asr_opt/slicer_opt.listに出力されていたので、これをラベル付けファイルのパスに指定して、ラベリングWebUIを起動する。

ラベリングWebUIは9871番ポートで開く。
Running on local URL: http://0.0.0.0:9871
音声とラベルを確認して必要なら修正して反映するという感じ。

記事にもある通り、あらかじめ内容がわかっている、もしくは既存のデータセットを使う、ならば、ここは自分で全部用意することもできそう。
あとは手順通りに進めていけば良い。記事ではエラーになっていたGPTトレーニングについても、自分の手元ではエラーにならなかったので、やはりDockerの方はいろいろ追いついていないのではないかと思われる。
肝心の結果の方はFew-shotで使用したデータの品質があまり良くないせいもあってか、まあこんなものか、というところ。ただv3にしたら結構自分の声には近くなった感がある。
Few−shotもZero-shotも、しっかりとしたデータを用意する必要はありそう。
まとめ
ひと通り試しただけなので、まだなんともではあるが、とりあえず品質の良いデータをきちんと用意した上で再度試してみたい。データの品質はやはり重要であるということを今回あらためて感じた。
個人的にこれをStyle-Bert-VITS2の学習用データの合成に使えないかなと考えている。以下あたりも参考になる。