拡散モデルを使った音声のインペインティングができる「PlayDiffusion」を試す
ここで見つけた
GitHubレポジトリ
PlayDiffusion
(訳注: デモ動画はGitHubレポジトリ参照)
Hugging Face Gradio とチェックポイント
はじめに
自己回帰型トランスフォーマーモデルは、テキストから音声を合成する上で非常に有効であることが実証されています。しかし、それらには重大な制約があります。生成済みの音声の一部を修正(インペインティングと呼ばれる)したり、離散的なアーティファクトを残さずに削除したりすることは標準的な機能では不可能です。したがって、より汎用的な音声編集ツールには異なるアプローチが必要です。以下の文を考えてみてください:
「The answer is out there, Neo. Go grab it!」
この生成後に🔴「Neo」を🟢「Trinity」に変更したいとします。従来のARモデルでは、選択肢は限られています。
- 文全体を再生成する: 計算コストが高く、プロソディ(抑揚)や話速に変動が生じることが多いです。
- 「Neo」という単語だけを置き換える: 単語の境界で明らかなアーティファクトやミスマッチが発生します。
- 中間地点から再生成する: 例えば「Trinity. Go grab it!」から再生成しますが、未編集部分(「Go grab it」)のプロソディが変わり、話速に望ましくない変動が生じる可能性があります。
これらのアプローチはすべて、音声の一貫性と自然性を損なうものです。代わりに、これらのタイプの音声編集ツールには、非自己回帰型アプローチが好まれます [1, 2]。
PlayDiffusion モデル
Play.AI では、この問題に対して音声編集のための新しい拡散ベースのアプローチを提案しました。以下がその仕組みです:
- まず、音声シーケンスを離散空間にエンコードし、波形をよりコンパクトな表現に変換します。この表現内の各単位をトークンと呼びます。このプロセスは、実際の音声と、テキスト音声合成モデルによって生成された音声の両方で機能します。
- 編集が必要なセグメントをマスクします。
- 更新されたテキストを条件として、拡散モデルを用いてマスクされた領域をデノイズします。
- 周囲のコンテキストはシームレスに保持され、遷移部や話者特性が一貫して維持されます。
- 得られた出力トークンシーケンスを、BigVGAN デコーダーモデルを用いて再び音声波形に変換します。
非自己回帰型拡散モデルを使用することで、編集境界でのコンテキストをよりよく維持でき、高品質で一貫性のある音声編集が可能になります。これは音声編集機能における大きな前進であり、動的かつ細かな音声修正への道を開きます。
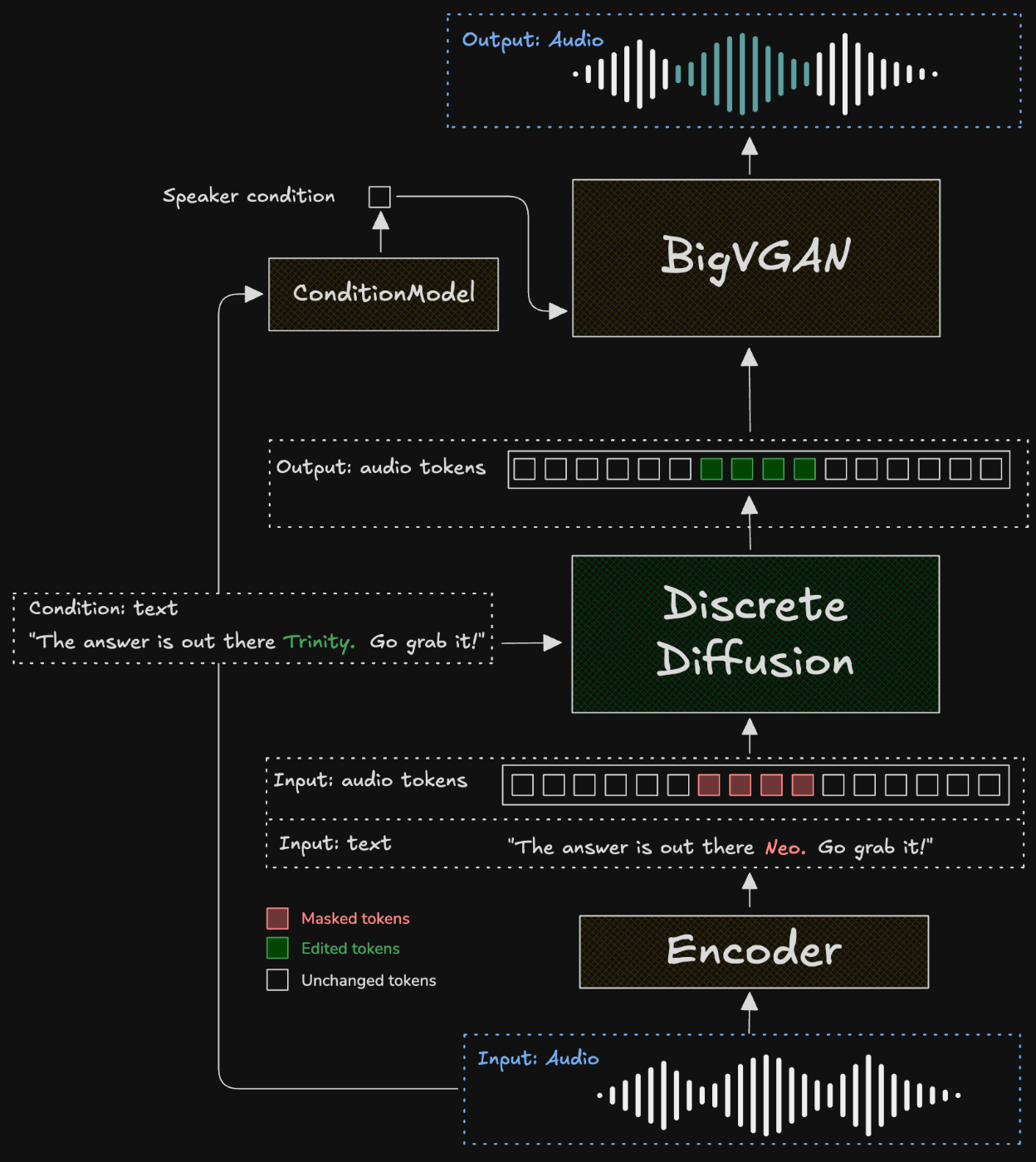
全体のプロセスは図1に示されています。
図 1. PlayDiffusion モデル。
- 「The answer is out there Neo. Go grab it!」という音声を含む入力音声を離散オーディオトークンにエンコードします。
- 編集対象の音声に対応するトークンをマスクします。ここでは「Neo」に対応するトークンをマスクしています。
- 更新されたテキストと、マスクされたトークンおよびマスクされていないトークンを含む入力トークンシーケンスを条件として、PlayDiffusion モデルが編集後の出力シーケンスを生成します。
- 出力シーケンスを、元のクリップから抽出した話者埋め込みを条件として BigVGAN によって波形に変換します。
なるほど、拡散モデルを使った音声におけるインペインティング、ってことね。
モデル
HuggingFace Spaceのデモ
ところで、これはどういうユースケースが考えられるだろうか?
今回はローカルのUbuntu−22.04サーバでやる(RTX4090)
レポジトリクローン
git clone https://github.com/playht/playdiffusion && cd playdiffusion
uvでPython仮想環境作成
uv venv -p 3.11
uv pip install pip
source .venv/bin/activate
パッケージインストール
pip install '.[demo]'
ASRと発話タイミング取得のためにOpenAI APIキーが必要とある。おそらくWhisperを使うのだろう。
export OPENAI_API_KEY="XXXXXXXX"
Gradioデモを起動。初回はモデルがダウンロードされるので時間がかかる。あと、普通に起動すると127.0.0.1のみLISTENする。うちはLAN内のリモートサーバなのでGRADIO_SERVER_NAME=0.0.0.0をつける
GRADIO_SERVER_NAME=0.0.0.0 python demo/gradio-demo.py
エラー
ModuleNotFoundError: No module named 'pkg_resources'
setuptoolsを追加
pip install setuptools
再度起動
GRADIO_SERVER_NAME=0.0.0.0 python demo/gradio-demo.py
起動した
* Running on local URL: http://0.0.0.0:7860
HuggingFace Spacesのデモと同じGradioのWebUIになってる。

このデモでできるのは、
- Inpaintによる音声の一部分の変更
- 音声クローン
の2種類みたい。あとメッセージにもあるが、現状は英語のみが想定されている様子。

VRAM消費は9GBぐらい
Wed Jun 4 09:55:53 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 53C P8 17W / 450W | 8919MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
```
ではまず、Inpaintから。ほんとはリアルな音声データを使いたいところだけど、手頃なものが見つからなかったので、今回は以前Orpheus TTSを試した際に生成した合成データを使用する。
音声ファイルをアップロードして「Run ASR」を実行
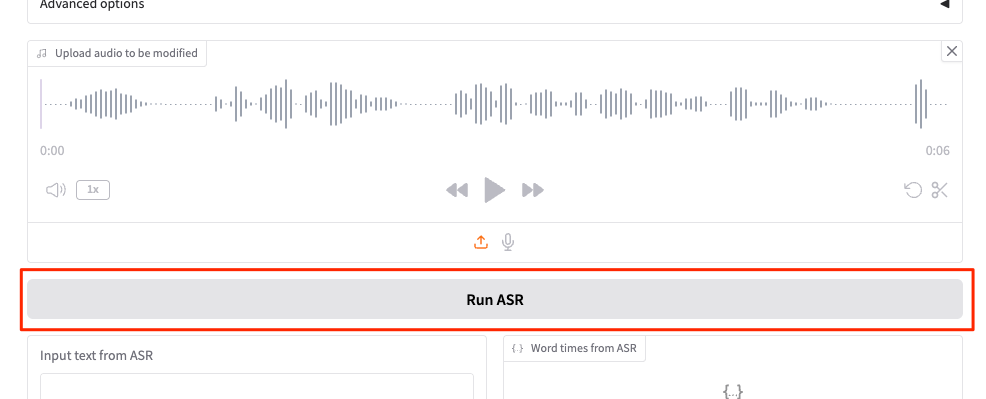
こんな感じで文字起こしされると同時に、単語レベルのタイムスタンプが生成される。
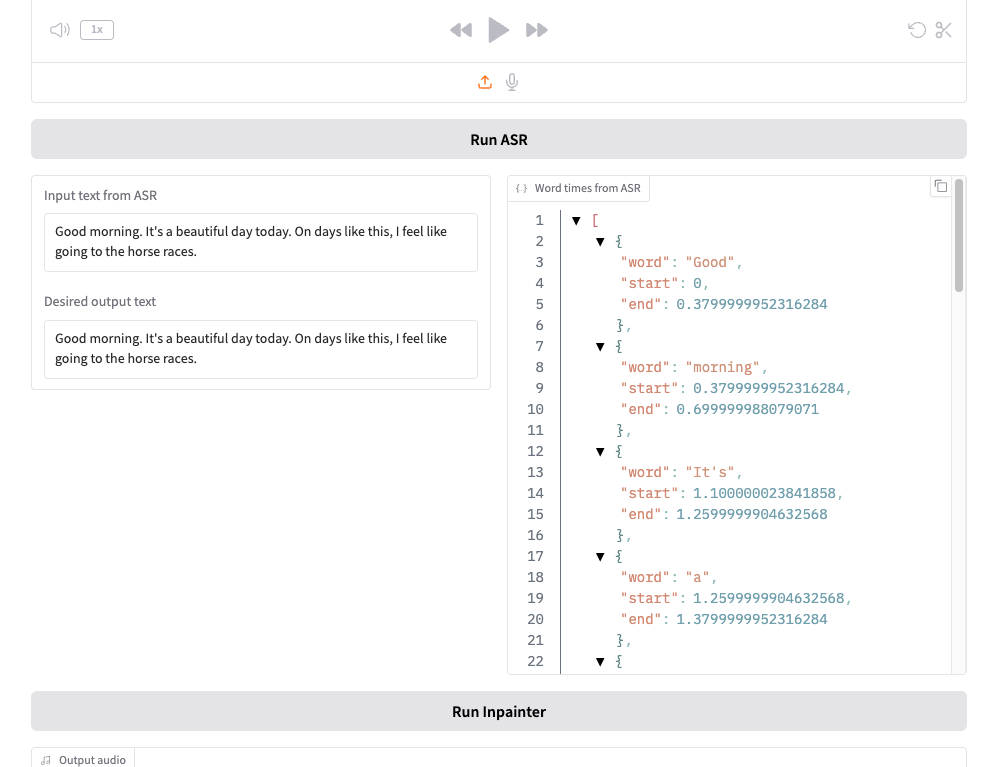
では文字起こしの一部を修正する。以下は音声から抽出された文字起こし。
Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races.
"Desired output text"にも同じ文字が入力されているので、少しだけ修正する。
Good morning. It's the best day ever. On days like this, I feel like going to the ball park.
~~~~~~~~~~~~~~~~~ ~~~~~~~~~
そして「Run Inpainter」をクリック
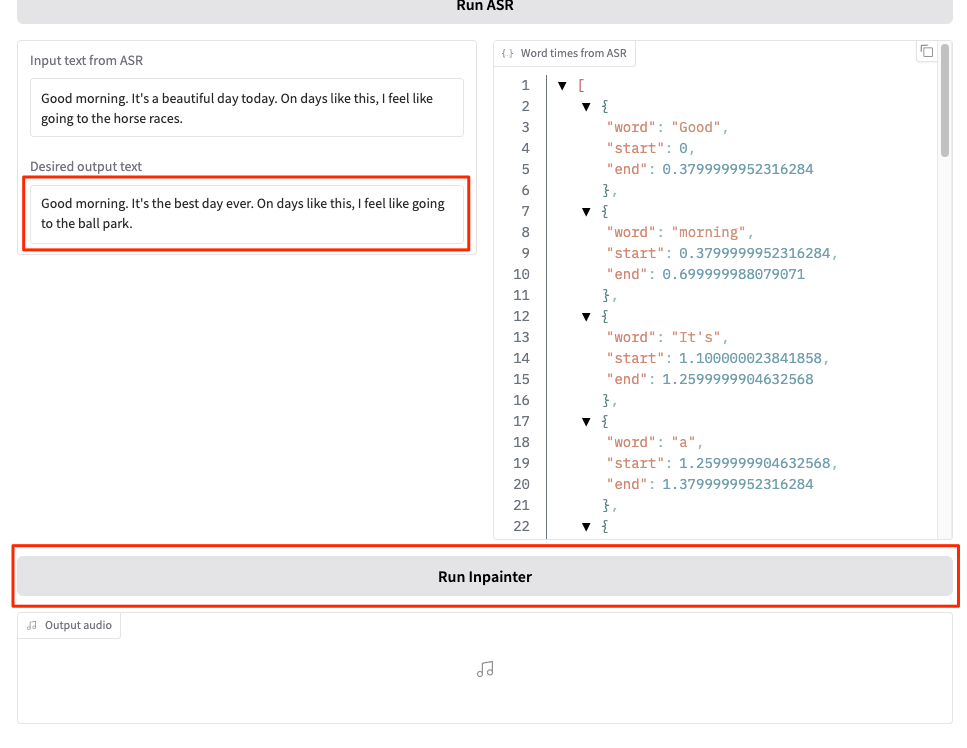
生成された

実際に生成されたものはこちら。元の音声と聴き比べてみると良い。
合成音声なので何がどう嬉しいのかわかりにくいかも。音声クローンの方と比較してみると違いがわかると思う。
同じリファレンス音声で、上の部分的に書き換えたテキストを発話させたものが以下。
元の声質は維持されているが、発話の感じが全く異なっていることがわかる。つまり、Inpaintingだと変更箇所以外はすべて維持されるということになる。
まとめ
ゼロショットの音声クローンはいろいろあって、最近のものは元の音声にかなり近しいものが生成されるが、完全に元の発話と同じようにコントロールするのは難しいのではないかと思う。PlayDiffusiionのInpaintを使うと元の発話を完全に維持しつつ一部分だけの修正が可能になるということになる。
どういうユースケースで嬉しいのかな?と思って考えてみた。
- 元の音声・口調を活かしつつ、データセットなどのバリエーションを増やす
- 合成データセットなどで上手くいかなかった部分だけを修正する
とかあたりかな?
開発元はTTSのホスティングサービスもやっている。日本語にも対応しているし、WebSocketで高速な生成にも対応してて、前からちょっと気にはなっている