DeepEvalを試す
気になったのはこれ
2024/05/20 元記事なくなってた
評価ツール比較記事。TruLens、Ragas、DeepEval、UpTrainの4つを評価してて、この方の評価ではDeepEvalを一番評価してる。
DeepEval公式の評価手法に関する記事
日本語で試された方の記事
Prompt AlignmentとかRole Adherenceとかよさそうだなぁ
あらためてちょっと触ってみようかな
GitHubレポジトリ
DeepEval.
LLM 評価フレームワーク
DeepEval は、LLM システムの評価とテストのための、使いやすいオープンソースの評価フレームワークです。Pytest に似ていますが、LLM の出力のユニットテストに特化しています。DeepEval は、G-Eval、ハルシネーション、回答関連性、RAGAS などのメトリクスを用いて最新の研究を取り入れ、ローカルで実行 される LLM やその他の NLP モデルを使用して評価を行います。
RAG パイプライン、チャットボット、AI エージェントを LangChain や LlamaIndex を介して実装している場合でも、DeepEval がサポートします。これにより、最適なモデル、プロンプト、アーキテクチャを簡単に判定し、RAG パイプラインやエージェントワークフローを改善したり、プロンプトのドリフトを防止したり、OpenAI から独自ホストの Deepseek R1 への移行も自信を持って行えます。
重要
DeepEval のテストデータを保存する場所が必要ですか?🏡❤️ DeepEval プラットフォームにサインアップ して、LLM アプリのテストレポートを生成・共有しましょう。LLM 評価について話したり、メトリクスの選定に悩んでいたり、ただ挨拶したいだけですか?Discord に参加 しましょう。
🔥 メトリクスと機能
🥳 DeepEval のテスト結果を Confident AI のクラウド上で共有できるようになりました!
- エンドツーエンド評価とコンポーネント単位評価の両方に対応
- ANY LLM、自身のマシンで動作する統計手法や NLP モデルを用いた多彩な評価メトリクス(解説付き):
- G-Eval
- DAG(deep acyclic graph)
- RAG メトリクス:
- Answer Relevancy
- Faithfulness
- Contextual Recall
- Contextual Precision
- Contextual Relevancy
- RAGAS
- エージェントメトリクス:
- Task Completion
- Tool Correctness
- その他:
- Hallucination
- Summarization
- Bias
- Toxicity
- 会話メトリクス:
- Knowledge Retention
- Conversation Completeness
- Conversation Relevancy
- Role Adherence
- など
- カスタムメトリクスの作成・DeepEval への自動統合が可能
- 評価用の合成データセットの生成
- ANY CI/CD 環境とのシームレスな統合
- 40 種類以上のセーフティ脆弱性を数行のコードでテスト可能(レッドチーミング入門):
- Toxicity
- Bias
- SQL Injection
- など、10 種類以上の攻撃強化戦略を活用
- 人気ベンチマークを 10 行以下のコードで簡単ベンチマーク:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 100% Confident AI 統合で評価ライフサイクルを完結:
- クラウドで評価データセットのキュレーション・注釈付け
- データセットを使ったベンチマークと前回比較
- カスタム結果向けメトリクス調整
- LLM トレースで評価結果をデバッグ
- 製品中の LLM 応答をモニタリング・評価し実データでデータセットを改善
- 完璧になるまで繰り返し
[!注意]
Confident AI は DeepEval プラットフォームです。アカウントはこちらから作成。🔌 統合
- 🦄 LlamaIndex(CI/CD での RAG アプリ単体テスト)
- 🤗 Hugging Face(LLM ファインチューニング中のリアルタイム評価)
ライセンス
DeepEval は Apache 2.0 ライセンスです。詳細は LICENSE.md をご覧ください。
クラウドサービスもやっている。どうやらこちらだと、データの永続化とか見やすいGUIがある、って感じなのかな?
料金はこちら。無料プランもあるけど、1プロジェクト・テスト5回・データ保持は1週間という制約があるみたい。
Getting Started
公式ドキュメントのGetting Startedに従って進める。
環境はM2 Macで。DeepEvalのクラウドサービスでできることも知りたいので、アカウントも事前に作成しておくこと。
ではuvで仮想環境を作成。
uv init -p 3.12 deepeval-work && cd $_
パッケージインストール。
uv add deepeval
+ deepeval==3.1.8
DeepEvalのテストはローカルで行えるが、テスト結果をクラウドに保持できる。今回はクラウドのアカウントも作成しているので、ログインしておく。
uv run deepeval login
ブラウザが開くので、プロジェクトのAPIキーを確認。アカウント作成時にも表示されていたと思うが、どうやら最初に作成されるデフォルトのプロジェクトのAPIキーみたい。


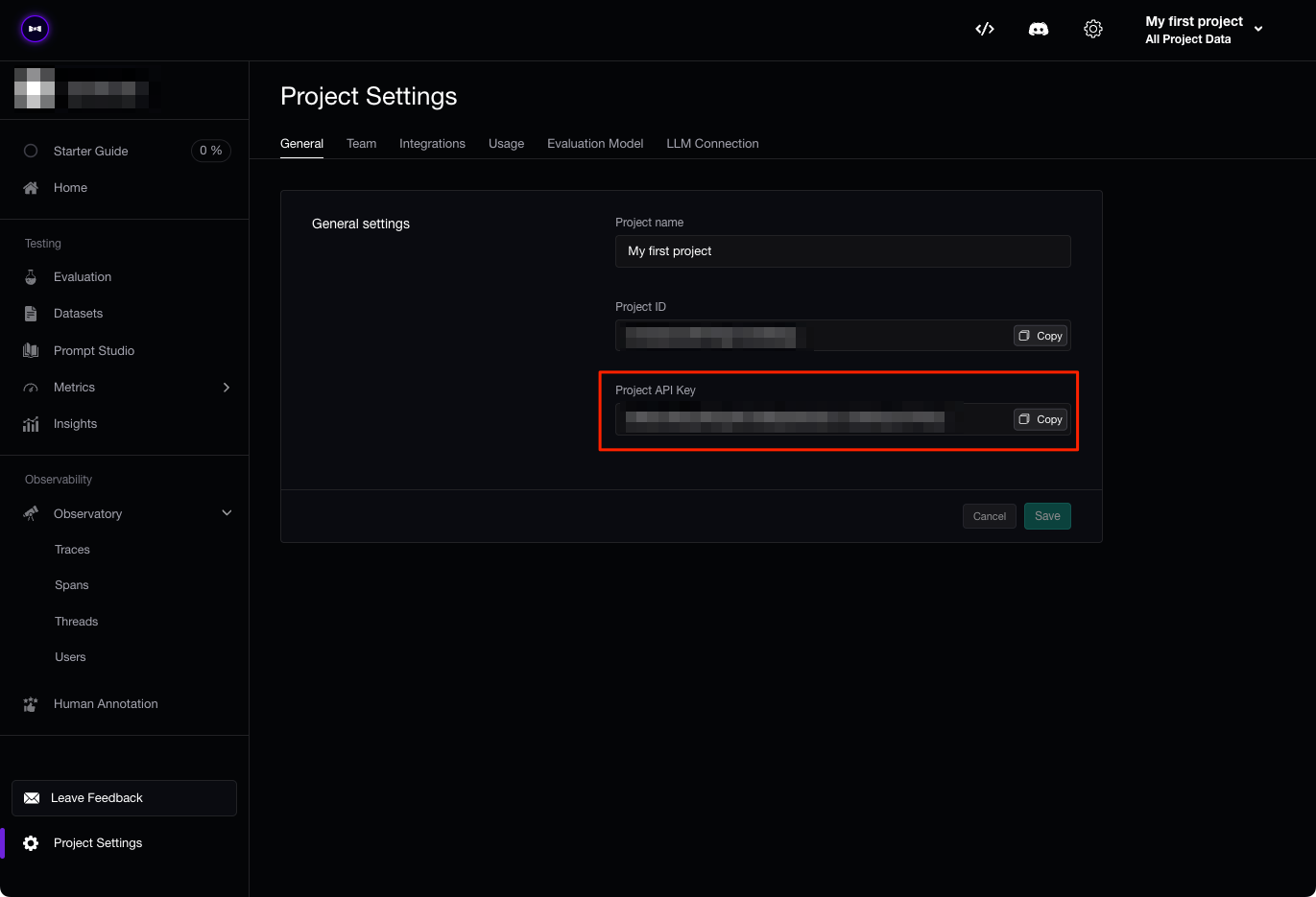
ターミナルに戻ってAPIキーを入力。
🥳 Welcome to Confident AI, the DeepEval cloud platform 🏡❤️
/$$$$$$$ /$$$$$$$$ /$$
| $$__ $$ | $$_____/ | $$
| $$ \ $$ /$$$$$$ /$$$$$$ /$$$$$$ | $$ /$$ /$$ /$$$$$$ | $$
| $$ | $$ /$$__ $$ /$$__ $$ /$$__ $$| $$$$$| $$ /$$/|____ $$| $$
| $$ | $$| $$$$$$$$| $$$$$$$$| $$ \ $$| $$__/ \ $$/$$/ /$$$$$$$| $$
| $$ | $$| $$_____/| $$_____/| $$ | $$| $$ \ $$$/ /$$__ $$| $$
| $$$$$$$/| $$$$$$$| $$$$$$$| $$$$$$$/| $$$$$$$$\ $/ | $$$$$$$| $$
|_______/ \_______/ \_______/| $$____/ |________/ \_/ \_______/|__/
| $$
| $$
|__/
/$$$$$$ /$$ /$$
/$$__ $$| $$ | $$
| $$ \__/| $$ /$$$$$$ /$$ /$$ /$$$$$$$
| $$ | $$ /$$__ $$| $$ | $$ /$$__ $$
| $$ | $$| $$ \ $$| $$ | $$| $$ | $$
| $$ $$| $$| $$ | $$| $$ | $$| $$ | $$
| $$$$$$/| $$| $$$$$$/| $$$$$$/| $$$$$$$
\______/ |__/ \______/ \______/ \_______/
(open this link if your browser did not opend: https://app.confident-ai.com)
🔐 Enter your API Key:
以下のように表示されればOK。
🎉🥳 Congratulations! You've successfully logged in! 🙌
You're now using DeepEval with Confident AI. Follow our quickstart tutorial here:
https://documentation.confident-ai.com/getting-started/installation
では最初のend-to-endのテストをやってみる。test_example.pyを作成。
from deepeval import assert_test
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
def test_correctness():
correctness_metric = GEval(
name="Correctness",
criteria="'actual output' が 'expected output' に基づいて、正しいかどうかを判断しなさい。",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="私は咳と発熱がずっと続いています。大丈夫でしょうか?",
# 以下を実際のLLMの実行結果に置き換える
actual_output=(
"持続的な咳や発熱は、ウイルス感染症やより深刻な病気の可能性があります。症状が悪化したり、数日たっても"
"改善が見られない場合は、医師の診察を受けてください。"
),
expected_output=(
"持続的な咳や発熱は、軽度のウイルス感染症から肺炎やCOVID-19などのより深刻な疾患まで、さまざまな病気"
"の兆候である可能性があります。症状が悪化したり、数日以上持続したり、呼吸困難、胸の痛み、その他の懸念"
"される症状を伴う場合は、医療機関を受診してください。"
)
)
assert_test(test_case, [correctness_metric])
見れば分かる通り、
-
input: ユーザー入力 -
actual_output: この入力に対してLLMが出力した結果 -
expected_output: 与えられた入力に対して期待する出力結果
となっていて、actual_outputがexpected_outputをどれだけ満たしているか?的な感じで評価する。評価のメトリクスとして使用されているGEvalは、DeepEvalの研究による独自メトリクスらしく、LLM の出力を任意のカスタムメトリクスで人間のような精度で評価できる、らしい。
また上記の例では、評価メトリクスの基準(criteria)は「正しさ」(Correctness)となっており、この基準に基づいて 0〜1 の範囲でスコアリングされる。 テストにPASSしたかFAILしたかはthresholdでスコアの閾値を指定する。
なお、この例ではシングルターンのテストになっていて、会話のようなマルチターンのテストは別のやり方になるみたい。
テストを実行するにはOpenAIのAPIキーをセットする必要がある。
export OPENAI_API_KEY=XXXXXX
テスト実行
uv run deepeval test run test_example.py
テスト結果が出力される。スコア0.54ということで、閾値が0.5なので、低めではあるけど、一応PASSしているみたい。
.Running teardown with pytest sessionfinish...
==================================================== slowest 10 durations =====================================================
5.79s call test_example.py::test_correctness
(2 durations < 0.005s hidden. Use -vv to show these durations.)
1 passed, 3 warnings in 5.79s
Test Results
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Overall Success Rate ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ test_correctness │ │ │ │ 100.0% │
│ │ Correctness (GEval) │ 0.54 (threshold=0.5, evaluation │ PASSED │ │
│ │ │ model=gpt-4o, reason=The actual │ │ │
│ │ │ output partially aligns with the │ │ │
│ │ │ expected output by mentioning │ │ │
│ │ │ persistent cough and fever as │ │ │
│ │ │ potential signs of viral │ │ │
│ │ │ infections or more serious │ │ │
│ │ │ illnesses. However, it lacks │ │ │
│ │ │ specific details such as the │ │ │
│ │ │ mention of pneumonia, COVID-19, │ │ │
│ │ │ and additional symptoms like │ │ │
│ │ │ breathing difficulties and chest │ │ │
│ │ │ pain. The structure is similar, │ │ │
│ │ │ but the omission of these details │ │ │
│ │ │ impacts the accuracy and │ │ │
│ │ │ completeness of the information │ │ │
│ │ │ provided., error=None) │ │ │
│ Note: Use Confident AI with │ │ │ │ │
│ DeepEval to analyze failed test │ │ │ │ │
│ cases for more details │ │ │ │ │
└───────────────────────────────────┴─────────────────────┴───────────────────────────────────┴────────┴──────────────────────┘
Total estimated evaluation tokens cost: 0.0035050000000000003 USD
✓ Done 🎉! View results on
https://app.confident-ai.com/project/XXXXXXXXXX/evaluation/test-runs/XXXXXXXXXX/test-cases
またブラウザも起動して、テストの結果が表示される。

テストの詳細も確認
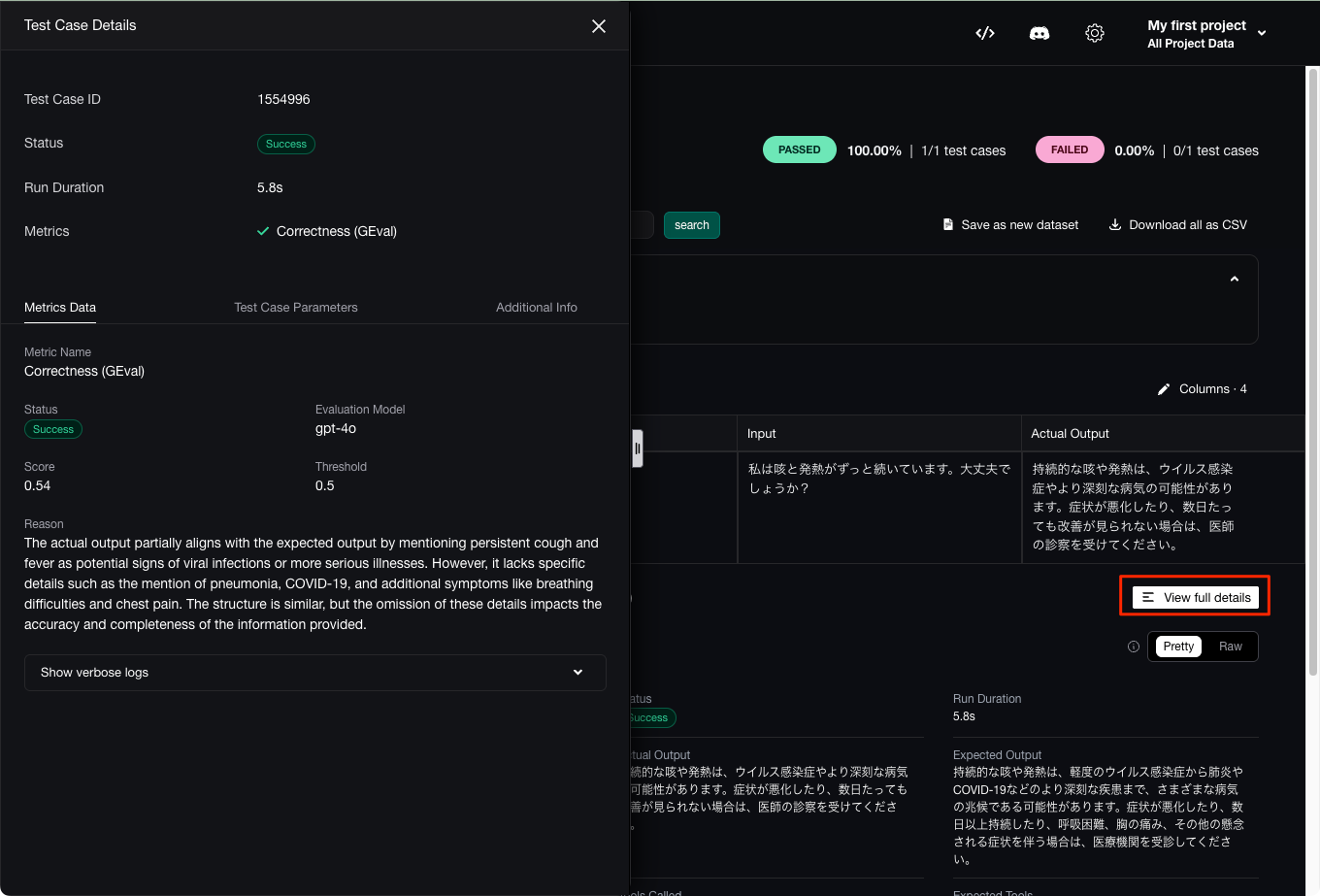
スコアの理由を日本語に訳すとこんな感じだった。DeepL使用。
実際の出力は、持続的な咳や発熱をウイルス感染症やより重篤な疾患の潜在的な兆候として言及している点で、期待される出力と部分的に一致しています。しかし、肺炎、COVID-19、呼吸困難や胸痛などの追加症状に関する具体的な詳細が欠けています。構造は類似していますが、これらの詳細が省略されているため、提供される情報の正確性と完全性に影響があります。
まあ例文だと期待する結果に対して出力された結果は確かに情報量が少ないので、まあそうかという感じ。
今回はテスト結果をクラウドに保存しているけども、ローカルにも保存できる。環境変数DEEPEVAL_RESULTS_FOLDERを設定すれば良い。
export DEEPEVAL_RESULTS_FOLDER=./result
actual_outputを少し修正して再度テストしてみる。これは実際にChatGPTに生成してもらったもの。
actual_output=(
"咳と発熱が長引く場合は自己判断せず医療機関を受診してください。特に一週間以上症状が続く、三日以上熱が"
"下がらない、呼吸困難や胸痛、血痰が見られる、あるいは糖尿病や心疾患などの基礎疾患がある場合は、内科"
"もしくは呼吸器内科への受診が必要です。お大事になさってください。"
),
再実行
uv run deepeval test run test_example.py
今度は失敗。長いので省略しているけど、ほんとにpytestっぽい感じで出力される。
FRunning teardown with pytest sessionfinish...
========================================================== FAILURES ===========================================================
______________________________________________________ test_correctness _______________________________________________________
(snip)
.venv/lib/python3.12/site-packages/deepeval/evaluate/evaluate.py:169: AssertionError
==================================================== slowest 10 durations =====================================================
8.31s call test_example.py::test_correctness
(2 durations < 0.005s hidden. Use -vv to show these durations.)
=================================================== short test summary info ===================================================
FAILED test_example.py::test_correctness - AssertionError: Metrics: Correctness (GEval) (score: 0.48179029509151006, threshold: 0.5, strict: False, error: None, reas...
1 failed, 3 warnings in 8.41s
Test Results
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Overall Success Rate ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ test_correctness │ │ │ │ 0.0% │
│ │ Correctness (GEval) │ 0.48 (threshold=0.5, evaluation │ FAILED │ │
│ │ │ model=gpt-4o, reason=The actual │ │ │
│ │ │ output and expected output both │ │ │
│ │ │ emphasize the importance of │ │ │
│ │ │ seeking medical attention for │ │ │
│ │ │ persistent cough and fever, and │ │ │
│ │ │ mention specific symptoms that │ │ │
│ │ │ warrant a doctor's visit. │ │ │
│ │ │ However, the actual output lacks │ │ │
│ │ │ the broader context of potential │ │ │
│ │ │ diseases like pneumonia or │ │ │
│ │ │ COVID-19 mentioned in the │ │ │
│ │ │ expected output. Additionally, │ │ │
│ │ │ the actual output includes more │ │ │
│ │ │ specific guidance on when to see │ │ │
│ │ │ a specialist, which is not │ │ │
│ │ │ present in the expected output. │ │ │
│ │ │ This results in structural and │ │ │
│ │ │ content discrepancies, affecting │ │ │
│ │ │ completeness and alignment., │ │ │
│ │ │ error=None) │ │ │
│ Note: Use Confident AI with │ │ │ │ │
│ DeepEval to analyze failed test │ │ │ │ │
│ cases for more details │ │ │ │ │
└───────────────────────────────────┴─────────────────────┴───────────────────────────────────┴────────┴──────────────────────┘
Total estimated evaluation tokens cost: 0.0040625 USD
Results saved in ./result as 20250625_003021
✓ Done 🎉! View results on
https://app.confident-ai.com/project/XXXXXXXXXX/evaluation/test-runs/XXXXXXXXXX/compare-test-resu
lts
結果がローカルにも出力されている。
tree result/
result/
└── 20250625_003021
1 directory, 1 file
結果ファイルはJSONで記載されている。
cat result/20250625_003021 | jq -r .
{
"testFile": "test_example.py",
"testCases": [
{
"name": "test_correctness",
"input": "私は咳と発熱がずっと続いています。大丈夫でしょうか?",
"actualOutput": "咳と発熱が長引く場合は自己判断せず医療機関を受診してください。特に一週間以上症状が続く、三日以上熱が下がらない、呼吸困難や胸痛、血痰が見られる、あるいは糖尿病や心疾患などの基礎疾患がある場合は、内科もしくは呼吸器内科への受診が必要です。お大事になさってください。",
"expectedOutput": "持続的な咳や発熱は、軽度のウイルス感染症から肺炎やCOVID-19などのより深刻な疾患まで、さまざまな病気の兆候である可能性があります。症状が悪化したり、数日以上持続したり、呼吸困難、胸の痛み、その他の懸念される症状を伴う場合は、医療機関を受診してください。",
"success": false,
"metricsData": [
{
"name": "Correctness (GEval)",
"threshold": 0.5,
"success": false,
"score": 0.48179029509151006,
(snip)
クラウド上にテスト結果が貯まると、以下のようにそれぞれのテスト結果を横に並べて比較することができる。

あと、テストの成功・失敗の回数といった概要的なものもクラウドでは表示される。

Getting Startedの続きを読んでみたのだけど、「動く」コードがなくて、説明だけになってるように思える・・・(Getting Startedには動くコードを用意してほしい・・・・)
ドキュメントを色々見てみるとどうやら以下にチュートリアルがある様子。
こちらの方で進めてみるかな。
メトリクス
評価ツールではどういうメトリクスが使えるかは気になるので、チュートリアルの前にそこだけ軽く。
DeepEvalには、すぐに使えるビルトインのデフォルトメトリクスを使うこともできるし、自分で評価基準を設定したカスタムメトリクスも作成することができる。
デフォルトで用意されているメトリクスは以下に記載がある。
ざっとこんな感じ。
| カテゴリ | メトリクス | 内容 |
|---|---|---|
| 汎用 | G-Eval | カスタム基準に基づいてCoTで評価するフレームワーク |
| DAG | デシジョンツリーを構築して評価を行うためのメトリクス | |
| RAG | Answer Relevancy | 回答の関連性。入力に対して出力がどの程度関連したものになっているか。 |
| Faithfulness | 忠実度。検索コンテキストに対して出力がどの程度事実に一致しているか。 | |
| Contextual Relevancy | 文脈の関連性。入力に対して検索結果が全体的にどの程度関連しているものになっているか。 | |
| Contextual Precision | 文脈の再現率。入力に対して検索結果が関連するものが上位に来ているか。 | |
| Contextual Recall | 文脈の再現率。検索結果に対して回答がどの程度一致しているか。 | |
| エージェント | Tool Correctness | ツールの正確性。使用が予想されるツールが実際に呼び出されたか。 |
| Task Completion | タスクの完了度。入力されたタスクをどの程度効果的に達成したか。 | |
| チャットボット (会話エージェント) |
Conversational G-Eval | G-Evalの会話版。会話「全体」をカスタム基準に基づいて評価する |
| Knowledge Retention | 知識の保持度。チャットボットが会話中に得た事実をどの程度記憶できているか。 | |
| Role Adherence | 役割の遵守度。チャットボットが与えられた役割をどの程度遵守できているか。 | |
| Conversation Completeness | 会話の完全性。チャットボットが会話を通じてユーザニーズを満たした会話を完了できているか。 | |
| Conversation Relevancy | 会話の関連性 | |
| その他 | Json Correctness | JSONの正確度。正しいJSONスキーマで出力できているか。 |
| Ragas | RAGASで使用される4つのメトリクス(RAGASAnswerRelevancyMetric、RAGASFaithfulnessMetric、RAGASContextualPrecisionMetric、RAGASContextualRecallMetric)の平均値。 |
|
| Hallucination | ハルシネーション。与えられたコンテキストに対して、出力が正しい情報を生成できているか。 | |
| Toxicity | 毒性。出力が毒性(攻撃や憎悪など)を含んだものになっていないか。 | |
| Bias | 偏見。出力が性別・人種・政治的意見などのバイアスを含んだものになっていないか。 | |
| Summarization | 要約。入力に対して出力が必要な詳細と事実をカバーした要約を生成できているか。 |
で、カスタムなメトリクスは、上の表にもある「G-Eval」と「DAG」を使うことで作成できるということみたい。
チュートリアル
Getting Startedで試せるのはほんの触りだけで、それ以降は読み物感が強かったため、チュートリアルを進めることにする。
チュートリアルは、簡単なLLMアプリをDeepEvalを使って実際に評価していくというようなものなっているみたいで、3つのテーマが用意されている。
- 法的文書の要約
- RAG QAエージェント
- 医療チャットボット
とりあえず法的文書の要約から試していく。
チュートリアル: 法的文書の要約
このチュートリアルのシナリオは以下となっている
- 法的文書のテキストを入力し、重要なポイントを抽出して要約する
- 要約のゴール
- 不必要に詳細が含まれていないこと
- 重要事項・義務・法的ニュアンスが、誤解がなく保持されていること
なお、チュートリアル内で使用されているモデルは gpt-3.5 となっているが、今更感もあるので gpt-4o あたりで試そうと思う。
また、要約で使用されているプロンプトは以下となっている。DeepLで日本語訳。
あなたは、法律文書を簡潔かつ正確に要約するAIアシスタントです。
以下の法律文書から、要点を捉えた要約を生成してください。
不必要な詳細は省き、中立性を保ち、提供されたテキスト以外の解釈は避けてください。
要約の評価基準を定義する
要約の評価を行うにあたりその評価の基準をまず定義する必要がある。つまり、要約の何に重きを置くか?ということになるが、一口に要約といっても、ユースケースによって求める基準は異なるため。
ダミーの要約を作成してみる。こんな感じで。(うーん、チュートリアルですら、動作するコードが用意されていないのか・・・)
from openai import OpenAI
client = OpenAI()
class Llm:
def __init__(
self,
system_prompt: str = """
あなたは、法律文書を簡潔かつ正確に要約するAIアシスタントです。
以下の法律文書から、要点を捉えた要約を生成してください。
不必要な詳細は省き、中立性を保ち、提供されたテキスト以外の解釈は避けてください。
""",
model: str = "gpt-4o-mini"
):
self.model = model
self.system_prompt = system_prompt
def summarize(self, input: str) -> str:
response = client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": input}
]
)
return response.choices[0].message.content
document_content = """
サービス契約本書サービス契約(以下「本契約」といいます)は、2025年1月28日に、デラウェア州に
登記された株式会社Acme Solutions, Inc.(以下「提供者」といいます)と、カリフォルニア州に
登記された有限責任会社BetaCorp LLC(以下「クライアント」といいます)との間で締結されます。
1. サービス: 提供者は、別紙Aに定めるソフトウェア開発およびコンサルティングサービスを提供
します。サービスは2025年2月1日に開始され、書面による延長がない限り、2025年8月1日までに
完了するものとします。
2. 報酬: クライアントは、プロバイダーに対し、$50,000の固定料金を支払います。支払いは、
2025年2月1日を初回として、毎月1日に$10,000ずつ、5回に分けて支払われます。
...
...
...
署名:
Acme Solutions, Inc.
BetaCorp LLC
"""
llm = Llm()
summary = llm.summarize(document_content)
print(summary)
結果
サービス契約(以下「本契約」といいます)は、2025年1月28日に株式会社Acme Solutions, Inc.(提供者)と有限責任会社BetaCorp LLC(クライアント)との間で締結されます。
1. **サービス内容**: 提供者は別紙Aに基づくソフトウェア開発およびコンサルティングサービスを提供し、2025年2月1日に開始、2025年8月1日までに終了します。
2. **報酬**: クライアントは提供者に対し、固定料金$50,000を支払い、2025年2月1日から毎月1日に$10,000ずつ5回に分けて支払います。
署名欄にはそれぞれの企業名が記載されます。
この要約結果に対して、仮に以下の点が問題だと感じたとする。
- 長過ぎる。元のテキストが430文字に対して、要約されたテキストが293文字とそこそこある。
- 契約の「延長」がもし重要だった場合、これは情報の欠落を示している。
これらを踏まえると評価基準は以下となる
- 要約は 簡潔でなければならない。
- 要約は 完全でなければならない。
上記を踏まえて評価指標を選択する
要約評価指標の選択
上記の評価基準を踏まえて、要約の評価指標、メトリクスを選択する。要約に関しては、ビルトインでSummarizationメトリクスも用意されているが、ここではGEvalを使ってカスタムなメトリクスを作成する。Getting Startedでも少し触れているが、GEvalを使うと自然言語でメトリクスの定義を行うことができる。
まず1つ目の 簡潔さについて。やや完全性な項目も含まれているが、評価のパラメータにINPUTが含まれていないので、より文章としての簡潔さに注目しているのだと思う。
from deepeval import assert_test
from deepeval.test_case import LLMTestCaseParams
from deepeval.metrics import GEval
concision_metric = GEval(
name="Concision",
criteria="'actual output' が 必要な情報を全て保持しながら簡潔であるかどうかを評価してください。",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
threshold=0.5
)
そして完全性についても。こちらは必要な情報の有無を判断するために、パラメータに入力・出力の両方が指定されている。
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
completeness_metric = GEval(
name="Completeness",
criteria="実際の出力が入力からの重要な情報をすべて保持しているかどうかを評価します。",
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT],
)
ではこれを使って実際の評価を行う。
評価の実行
で、実際の評価なのだけども、チュートリアルではPDFからデータセットを構築している。で今回のチュートリアルのテーマとなっている「法的文書」についての日本語のデータセットは見当たらない。そこで、以下の英語の契約書データセット「CUAD」を日本語翻訳してデータセットを作ることとした。
ここの手順は本題ではないので興味があれば。
CUADデータセットの日本語翻訳手順
CUADデータセットのレポジトリをダウンロードして、データセットを展開
git clone https://github.com/TheAtticusProject/cuad && cd cuad
unzip data.zip
データセットには今回は不要なQAなども含まれているため、ミニマムなデータだけ残したJSONLを作成
jq -c '
.data
| to_entries[]
| {
id: .key,
title: .value.title,
context: .value.paragraphs[0].context
}
' CUADv1.json > CUDAv1.jsonl
llama.cppで Gemma3-12b を使って、翻訳を行う。
./build/bin/llama-server \
-hf ggml-org/gemma-3-12b-it-GGUF \
--host 0.0.0.0 \
-ngl 99 \
--ctx-size 16000
翻訳スクリプトを実行。
uv add pandas
import string
import pandas as pd
from openai import OpenAI
from tqdm.auto import tqdm
prompt = """\
You are an excellent English-Japanese translator.
Please translate the given texts into Japanese.
You MUST output only the translation. DO NOT include any explanation or other texts.
## Sentence:
${text}
## Translation:
"""
prompt_template = string.Template(prompt)
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="dummy"
)
def translate(text: str) -> str:
response = client.chat.completions.create(
model="ggml-org/gemma-3-12b-it-GGUF",
messages=[
{"role": "user", "content": prompt_template.substitute(text=text)},
]
)
return response.choices[0].message.content
tqdm.pandas()
df = pd.read_json("CUDAv1.jsonl", lines=True)[:5] # テスト用に5件だけ
df["context_ja"] = df["context"].progress_apply(translate)
df.to_json(
path_or_buf="../CUDAv1_ja.jsonl",
orient="records",
lines=True,
force_ascii=False
)
cd ..
これでCUDAv1_ja.jsonlというファイルができる。
ではデータセットで要約の評価を行う。
from deepeval import evaluate
from deepeval.test_case import LLMTestCaseParams, LLMTestCase
from deepeval.metrics import GEval
from deepeval.dataset import EvaluationDataset
from openai import OpenAI
import pandas as pd
client = OpenAI()
class Llm:
def __init__(
self,
system_prompt: str = """
あなたは、法律文書を簡潔かつ正確に要約するAIアシスタントです。
以下の法律文書から、要点を捉えた要約を生成してください。
不必要な詳細は省き、中立性を保ち、提供されたテキスト以外の解釈は避けてください。
""",
model: str = "gpt-4o-mini"
):
self.model = model
self.system_prompt = system_prompt
def summarize(self, input: str) -> str:
response = client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": input}
]
)
return response.choices[0].message.content
# 評価指標の定義
concision_metric = GEval(
name="Concision",
criteria="'actual output' が 必要な情報を全て保持しながら簡潔であるかどうかを飄香してください。",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
threshold=0.5
)
completeness_metric = GEval(
name="Completeness",
criteria="実際の出力が入力からの重要な情報をすべて保持しているかどうかを評価します。",
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT],
)
# データセットの読み込み
df = pd.read_json("CUDAv1_ja.jsonl", lines=True)
docs = df["context_ja"].tolist() # context_jaカラムに日本語の契約書テキストが入っている。
# ドキュメントをLLMで要約して、テストケースに変換
llm = Llm() # 要約するLLMのインスタンスを作成
test_cases = [LLMTestCase(input=doc, actual_output=llm.summarize(doc)) for doc in docs]
# 評価データセットを作成
dataset = EvaluationDataset(test_cases=test_cases)
# 評価を実行
evaluate(dataset, metrics=[concision_metric, completeness_metric])
実行。ちょっと時間がかかる。
uv run test_summary.py
こんな感じで進捗が表示される。どうやら並列で行われる様子。
✨ You're running DeepEval's latest Concision (GEval) Metric! (using gpt-4o, strict=False, async_mode=True)...
✨ You're running DeepEval's latest Completeness (GEval) Metric! (using gpt-4o, strict=False, async_mode=True)...
Evaluating 5 test case(s) in parallel ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0% 0:00:06
🎯 Evaluating test case #0 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0% 0:00:06
🎯 Evaluating test case #1 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 50% 0:00:06
🎯 Evaluating test case #2 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0% 0:00:06
🎯 Evaluating test case #3 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 50% 0:00:06
🎯 Evaluating test case #4 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0% 0:00:05
どうやら今回は全てPASSしている様子。
======================================================================
Overall Metric Pass Rates
Concision (GEval): 100.00% pass rate
Completeness (GEval): 100.00% pass rate
======================================================================
✓ Tests finished 🎉! Run 'deepeval view' to analyze, debug, and save evaluation results on Confident AI.
DeepEvalのUIでも見てみる。


わかりやすく失敗してくれたら次を進めやすかったんだけど、まあまあこんな感じで。
一応結果についてスコアだけまとめておく。
| テストケースNo | Concisionスコア | Completenessスコア |
|---|---|---|
| 0 | 0.91 | 0.85 |
| 1 | 0.77 | 0.74 |
| 2 | 0.94 | 0.81 |
| 3 | 0.86 | 0.68 |
| 4 | 0.83 | 0.90 |
ハイパーパラメータの反復
上のテストでは一通りPASSはしているものの、まだ改善の余地はある。要約のハイパーパラメータ(モデルとプロンプト)を変更して、スコアがどのように改善するかを試してみる。
前回使用したモデルはgpt-4o-miniで、プロンプトは以下となっていた。
あなたは、法律文書を簡潔かつ正確に要約するAIアシスタントです。
以下の法律文書から、要点を捉えた要約を生成してください。
不必要な詳細は省き、中立性を保ち、提供されたテキスト以外の解釈は避けてください。
この「不必要な詳細は省き、」という箇所はもしかすると必要な詳細をLLMが不要と判断してしまったかもしれない。そこで以下のように修正する。
あなたは、法的文書を簡潔かつ正確に要約する AI アシスタントです。
以下の法律文書から、要点を捉えた要約を作成してください。
できるだけ簡潔に、ただし文書から詳細を一切省略しないでください。
中立性を保ち、提供されたテキスト以外の解釈は避けてください。
先ほどのテストスクリプトを変更して、評価を再実行する。この場合、データセットは同じデータを使用する必要がある。ここは
model = "gpt-4o-mini"
system_prompt = """
あなたは、法的文書を簡潔かつ正確に要約する AI アシスタントです。
以下の法律文書から、要点を捉えた要約を作成してください。
できるだけ簡潔に、ただし文書から詳細を一切省略しないでください。
中立性を保ち、提供されたテキスト以外の解釈は避けてください。
"""
llm = Llm(model=model, system_prompt=system_prompt)
(snip)
また評価を行うevaluateにハイパーパラメータを付与しておくことで、テストにおけるスコアの変化とパラメータを紐づけることができる。
(snip)
evaluate(
dataset,
metrics=[concision_metric, completeness_metric],
hyperparameters={
"model": model,
"system_prompt": system_prompt
}
)
再度テストを実行
uv run test_summary.py
一応今回も結果は全てPASS
======================================================================
Overall Metric Pass Rates
Concision (GEval): 100.00% pass rate
Completeness (GEval): 100.00% pass rate
======================================================================
スコアを見てみる
| テストケースNo | Concisionスコア | Completenessスコア |
|---|---|---|
| 0 | 0.90 | 0.72 |
| 1 | 0.85 | 0.85 |
| 2 | 0.93 | 0.82 |
| 3 | 0.93 | 0.88 |
| 4 | 0.87 | 0.91 |
一応スコアは改善されているね。あと、ハイパーパラメータとテストの紐づけなんだけど、Overviewのページではこうなってる。

ハイパーパラメータの指定がない場合は以下のようになっているので、一応渡ってはいるみたいなんだけどな・・・

んー、ちょっとドキュメントの指定と違ってた事に気づいた。prompt_templateじゃなくてsystem_promptというキーにしてた。ただ、これを直しても状況は変わらなかった。
(snip)
evaluate(
dataset,
metrics=[concision_metric, completeness_metric],
hyperparameters={
"model": model,
"prompt_template": system_prompt
}
)
プロンプト テンプレートの変更によるリグレッションの検出
同じデータセットで複数回のテストを実施した場合、過去のテストとの比較ができる。
プロジェクトの "Evaluation" メニューをクリックすると、テストの推移が見える。1回目より2回目でスコアが上がっているのがわかる。

で、最新(2回目)のテストをクリック。
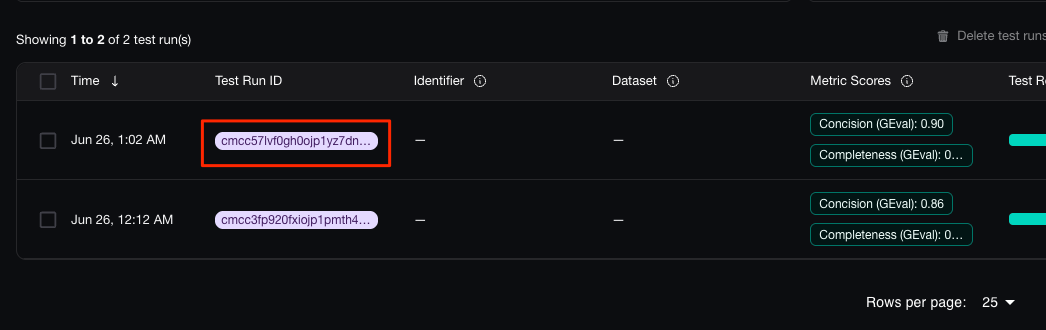
"Compare Test Results" をクリック。

上のメニューのところで、1回目のテストの実行IDを選択。

それぞれのテスト結果を横並びで比較することができる。

なお、1回目と2回目のテスト結果が異なる(PASSとFAIL)の場合にはさらに詳細(スコア理由)も横並びでチェックできるみたいだけど、今回は両方ともPASSしているので比較ができない・・・
ここはあえて失敗するようにシステムプロンプトを書き換えて、再度評価を実行してみた。実際にはこんな事しないと思うけど。
(snip)
system_prompt = """
あなたは、文書を適当に要約する AI アシスタントです。
以下の文書から、雑な要約を作成してください。あえて嘘を入れてください。
"""
(snip)
CompletenessにFAILが含まれている結果となった。
======================================================================
Overall Metric Pass Rates
Concision (GEval): 100.00% pass rate
Completeness (GEval): 20.00% pass rate
======================================================================
これを前回の結果と比較してみるとこうなる。で評価結果が異なっているところをクリック。

それぞれの理由としてはこう。
FAILとなった最新のテストの理由。「あえて嘘を入れてください。」ってのを入れたのでまあ当然の結果。
回答には、関係当事者、イリノイ州における独占販売権、10年間の契約期間、および販売代理店が販売目標を達成する義務といった重要な要素が一部含まれています。ただし、両当事者の具体的な義務、ライセンス条件、および販売代理店の権利が再評価される条件といった重要な詳細が欠落しています。さらに、「ハムスターの輸送」という言及は誤りであり、入力内容には存在しません。これは、詳細の誤解または捏造を示しています。
PASSしていた前回の理由
実際の出力には、入力から、関係当事者、契約日、販売代理店の役割と義務、契約期間、解約条件などの重要な情報が保持されます。ただし、製品の販売数量やライセンスおよび独占権の詳細な条件などの具体的な詳細は省略されます。言語や文脈は保持されますが、ニュアンスや詳細の一部が失われるため、要約の完全性に若干の影響があります。
これらを踏まえて、再度プロンプトを見直したり、モデルを変更したり、ということを繰り返していくことになる。
データセットの管理
DeepEvalではデータセットの管理もできる。データセットの作成は以下の2通り。
- CSVをアップロードして作成
- 完了したテスト結果から、使用したデータセットをそのまま作成
後者の場合、先ほど行ったテスト結果のページから"Save as new dataset"で作成できる様子。

データセット名を入力して作成。なお、メッセージにもあるように、actual_outputは保存されない。

ただ、面倒なことに、どうも有料プランじゃないとデータセットは複数作れない&画面内のチュートリアルを進めないと普通に使えない、らしく、無料トライアルを始めろ、と表示され、ここから進めなくて詰む・・・正直ありがた迷惑である・・・

ということで、これはまあDeepEvalのクラウドサービスでのみ使用できる機能と考えて良さそう。
あとは一応データセットの編集とか登録したデータセットをダウンロードしたり、ってことができるみたい。
他のチュートリアルも興味があれば試すと良いと思うし、今回はやってないけど、コンポーネントごとにトレーシングして評価みたいなのは良さそう。
まとめ
なるほど、pytestっぽく書けるっていうのは良さそう。あと、個人的にこういうのはあらかじめ用意されたメトリクスがどれだけ充実しているか、みたいなイメージを持っていて、カスタムなメトリクス作るのは大変なのでは?と思っていたのだけど、DeepEvalだと非常に簡単にできるのは良さそう。
ただ、
- 見やすいGUIを使いたかったら有償のクラウドを利用せざるを得ない、あといろいろなところでビジネス誘導するような流れがあって、それが不便さをうんでいるのがなんとも・・・
- ドキュメントはざっと見た限り説明は豊富なんだけども、動くサンプルコードみたいなものがほとんどない。初手はちょっとハードル高そう。
あたりはちょっと使いにくいかなぁというところ。有償クラウド使わずにOSSの範囲内で使うならば、統合評価環境として継続的に・・・みたいな感じはちょっと厳しそうで、やっぱりpytestっぽい都度都度テストクリアしてるよね、みたいな使い方になりそうな感じがした。
まあそれで十分ならいいのかも。
DeepEvalの良い点は、各スコアの根拠(reason)が取得できるところです。
これを活用してknowledgeの修正や、評価LLMの精度向上(例:追加のファインチューニング)につなげることが可能です。
まあ確かにこれはある。他のツールではそういう機能なかったっけ?ちょっと調べてみよう。
あと上の方にも書いてるけど、結果をローカルでも出力はできるので、
今回はテスト結果をクラウドに保存しているけども、ローカルにも保存できる。環境変数
DEEPEVAL_RESULTS_FOLDERを設定すれば良い。
結果がローカルにも出力されている。
結果ファイルはJSONで記載されている。
結果を蓄積して自分で可視化すればまあそれでもいいかという気もする。あらかじめ用意されてるならそのほうが嬉しいのはあるとしても。
色々考えてるけど、もう使わない、と捨ててしまうにはまだ惜しい感がある。もう少し見てみようか。
個人的に気になっているメトリクスは
- Role Adherence
- Prompt Alignment
だったのだけど、使用されているプロンプトは以下辺り