高速AI推論「Groq」を試す
Groq
ちなみにイーロンがやってるのはGro"k"
トップページはいきなりチャットになっている
この辺を見るのが良さそう
Groqは世界最速のAI推論技術を構築する
Q: Groqとは?
A: Groqは、世界最速のAI推論技術を構築するAIインフラ企業である。GroqのLPU™推論エンジンは、卓越した計算速度、品質、エネルギー効率を実現するハードウェアとソフトウェアのプラットフォームである。
Groqはシリコンバレーに本社を置き、AIアプリケーション向けにクラウドとオンプレミスのソリューションを大規模に提供している。LPUと関連システムは北米で設計、製造、組み立てられる。
Q: LPU推論エンジン™とは?
A:LPU推論エンジンは、LPU(Language Processing Unit™)を意味し、卓越した計算速度、品質、エネルギー効率を実現するハードウェアとソフトウェアのプラットフォームである。 この新しいタイプのエンド・ツー・エンドのプロセッシング・ユニット・システムは、大規模言語モデル(LLM)のようなAI言語アプリケーションのような、シーケンシャルなコンポーネントを持つ計算集約的なアプリケーションに最速の推論を提供する。
Q: LLMやAIにおける利用で、なぜそんなにGPUよりも速いのか?
A: LPUは、LLMの2つのボトルネックである演算密度とメモリ帯域幅を克服するように設計されている。LPUは、LLMに関してGPUやCPUよりも大きな計算能力を持つ。これにより、1単語あたりの計算時間が短縮され、テキストシーケンスの生成がより高速に行えるようになる。さらに、外部メモリのボトルネックを排除することで、LPU推論エンジンは、GPUと比較してLLMで桁違いの性能を発揮することができる。LPUのアーキテクチャに関する詳細な技術情報については、ISCAで受賞した2020年および2022年の論文をダウンロードのこと。
Q: Groqは標準的な機械学習フレームワークを実行できるか?
A: Groqは、推論のためにPyTorch、TensorFlow、ONNXなどの標準的な機械学習(ML)フレームワークをサポートしている。Groqは現在、LPU推論エンジンによるML学習をサポートしていない。カスタム開発については、Groq Compilerを含むGroqWare™スイートが、モデルを素早く立ち上げて実行するためのプッシュボタン体験を提供する。ワークロードの最適化については、Groqアーキテクチャにコードを渡す機能と、GroqChip™プロセッサのきめ細かな制御機能を提供しており、顧客はカスタムアプリケーションを開発し、そのパフォーマンスを最大化することができる。
Q: Groqを使い始めるには?
A: Groqを始めたいとお考えいただき、大変嬉しく思う。Groqを始めるための最速の方法を紹介する:開発者
開発者アクセスは、GroqCloud上のPlaygroundから完全にセルフサービスで取得できる。Playground上でAPIキーを取得し、ドキュメントや利用規約にアクセスすることができます。Discordコミュニティへの参加はこちらから。
現在OpenAIのAPIを利用している場合、Groqに移行するために必要なものは以下の3つです:
- Groq APIキー
- エンドポイント
- モデル
パッケージ&エンタープライズソリューション
データセンター規模で最速の推論が必要?必要であればチャットしましょう:
- 24/7 サポート
- SLA
- 専任のアカウント担当者
お客様のニーズに合ったソリューションを提供できるよう、ぜひご相談ください。こちらのドロップダウンフォームに必要事項をご記入の上、プロジェクトについてお聞かせください。送信後、Groqsterから折り返しご連絡いたします。
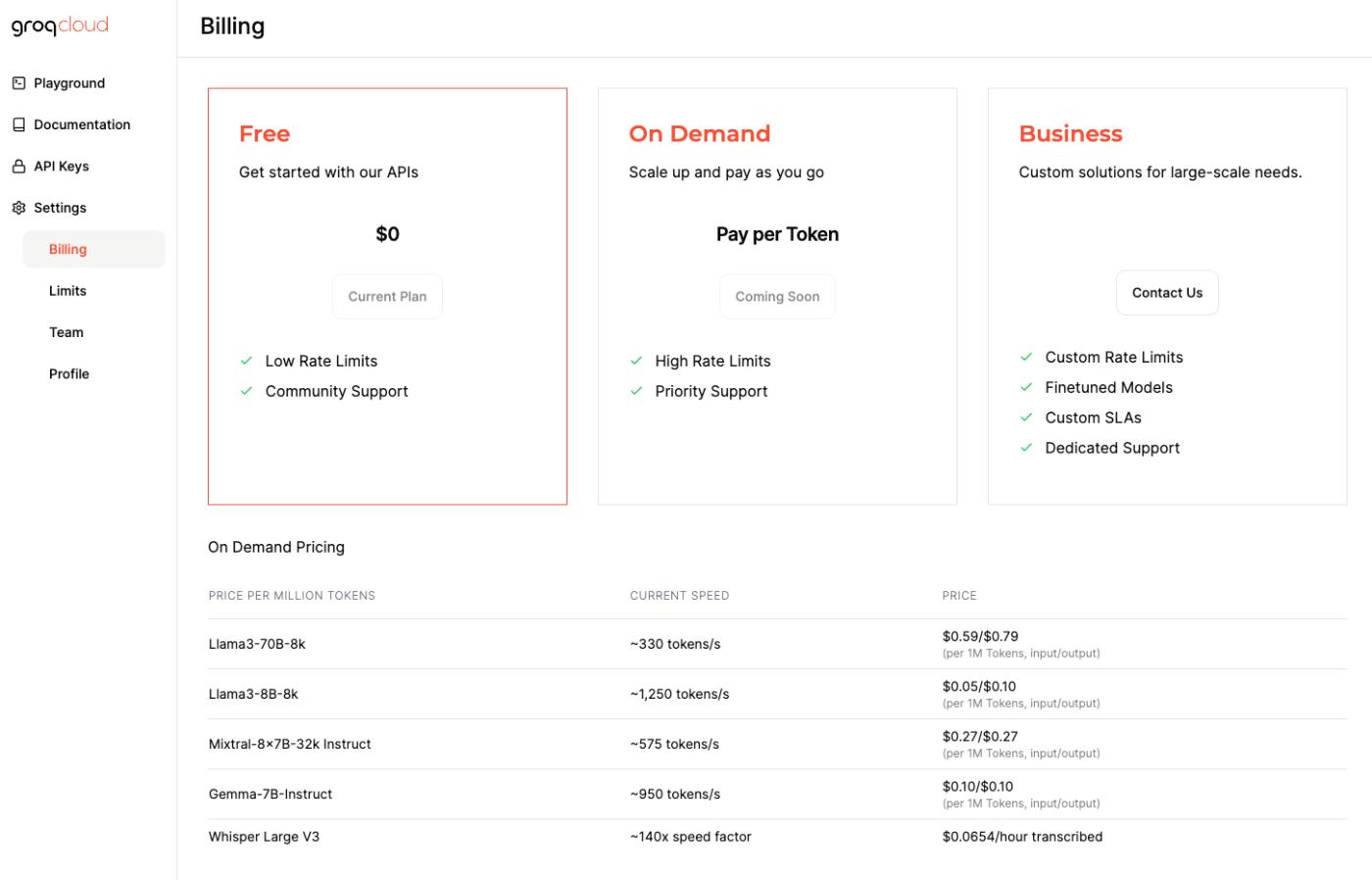
料金とサポートしているモデル
※2024/06/20時点
| モデル | 速度 | 入力料金(1Mトークン) | 出力料金(1Mトークン) |
|---|---|---|---|
| Meta Llama 3 70B (8Kコンテキスト長) | ~330 トークン/秒 | $0.59 | $0.79 |
| Mistral Mixtral 8x7B SMoE (32Kコンテキスト長) | ~575 トークン/秒 | $0.24 | $0.24 |
| Meta Llama 3 8B (8Kコンテキスト長) | ~1250 トークン/秒 | $0.05 | $0.08 |
| Google Gemma 7B (8Kコンテキスト長) | ~950 トークン/秒 | $0.07 | $0.07 |
| OpenAI Whisper Large V3(ファイルサイズ25MB) | ~172倍 スピードファクター | $0.03/1時間の文字起こし |
GroqCloudのコンソールでみると、現在は無料、ってことでよいのかな?
データの取扱
気になるところ。ざっと斜め読み。実際に利用する際にはしっかり確認すること。
Terms of Use
- Generative AI
本規約に加え、本ウェブサイトを通じて利用可能なジェネレーティブAIモデル(以下「ジェネレーティブAIサービス」)の使用およびアクセスには、ジェネレーティブAIモデルの所有者が指定する規約が適用される。お客様は、これらのモデルのいずれかを使用する場合、https://console.groq.com/docs/models で特定される生成AIモデルのモデルカードに指定される追加条件に従うことに同意するものとする。
第4条「本サービスを通じて利用可能なコンテンツ」に定める使用許諾の制限にかかわらず、ユーザーデータは、お客様が所有するものとし、本契約に基づく生成AIサービスの実施以外にGroqが保持または使用することはないものとする。ユーザーデータには、プロンプトおよびトレーニングデータと同様に、プロンプトに応答してジェネレーティブAIサービスによって生成されたあらゆるコンテンツ(以下「アウトプット」) が含まれる。「プロンプト」とは、アウトプットを生成するために、お客様がジェネレーティブAIサービスに与えるあらゆる指示、クエリー、視覚的またはテキスト的な合図と定義される。「トレーニングデータ」とは、モデルの微調整またはカスタマイズのためにユーザーが提供するデータであり、意味のある、首尾一貫した、応答性のあるアウトプットを生成するために必要なコンテキスト、知識、インスピレーションをモデルに提供するテキスト、ビジュアル、および/またはマルチメディアデータのコレクションで構成される。
プロンプト、微調整、またはお客様の特定のニーズまたは使用ケースに生成AIサービスをカスタマイズする目的でお客様がトレーニングデータを提供する場合、Groqは、お客様のために生成AIサービスを実行する目的以外にトレーニングデータを使用しない。Groqは、プロンプト、出力またはお客様のトレーニングデータをサーバーに永久に保持しない。
- GroqカスタマーポータルまたはGroq Playgroundにアップロードされたお客様提供のコンテンツ
Groqカスタマーポータルは、Groqが顧客にサービスおよびサポートを提供することを可能にする。ソースコード、モデル、ドキュメンテーション、またはデータを含むが、個人を特定できる情報(Groqが要求するお客様のユーザー認証情報を除く)を除く、お客様のコンテンツ(「お客様のコンテンツ」)をアップロードするためにGroqカスタマーポータルを使用することにより、お客様は、Groqが、お客様のコンテンツを新たなGroqが生成した素材と組み合わせることにより、Groqハードウェア製品上で実行するためにお客様のコンテンツ(ソースコード等)を修正することを許諾することに同意するものとする。Groqは、当該新しいGroq生成物のすべての所有権を保持するが、Groqハードウェア製品上でお客様のコンテンツと共に新しいGroq生成物を使用するための永続的かつ使用料無料のライセンスをお客様に付与する。書面による別段の合意がない限り、この変更サービスには料金がかからない。Groqは、Groqが生成した新しい素材に、修正内容を説明する明確なテキスト情報および必要に応じて著作権表示を含めることができる。お客様がアップロードしたコンテンツは、Groqにより機密情報または専有情報として扱われる。ただし、お客様のコンテンツがGroq Playgroundに投稿され、適切なライセンス(ApacheライセンスまたはMITライセンスなどのオープンソースライセンス)の下でGroqまたは他者によって使用される可能性があることをお客様が書面で指定した場合を除く。
一応このあたりだけ読むと、入力したデータは学習には使用されないように思えるのだけども、以下から辿れるPrivacy PolicyのPDFもみてみる。
- 当社が収集する個人情報
当社は、以下のさまざまな情報源からお客様の個人情報を収集することがある。(snip)お客様から提供される情報:
(snip)
- 当社サービスの利用: お客様がGroqChat又はAPI等の当社サービスを利用する場合に、お客様によって提示れるかもしれない、お客様の個人情報(又は他人の個人情報)又はお客様が当社サービスに提供する入力、ファイルのアップロード若しくはフィードバックに含まれる個人情報(以下「ユーザーデータ」という。)
- 個人情報の利用目的
当社は、お客様の個人情報を以下の目的で利用することがある:サービス: 当社は、個人情報またはユーザーデータを使用して、当社のサービスを改善し、新しい製品やサービスを開発することができる。
ここはちょっとどう読んだらいいのかな?直接的にトレーニングには使わないけど、何かしらの改善に使用される可能性はあるってことかな。
まあいずれにせよ実サービスで使ったりする場合はより詳細な確認が必要。
前フリが長くなったけど、Quick Startに従ってやってみる。Colaboratoryで。事前にアカウントを作成してAPIキーを発行しておくこと。
パッケージインストール
!pip install groq
APIキーを読み込み
from google.colab import userdata
import os
os.environ["GROQ_API_KEY"] = userdata.get('GROQ_API_KEY')
Chat Completions
OpenAIと全く同じ書き方。
import os
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "あなたは日本語で答える親切なアシスタントです。",
},
{
"role": "user",
"content": "日本の総理大臣は誰?回答は日本語で。",
}
],
model="llama3-8b-8192",
)
print(chat_completion.choices[0].message.content)
現在の日本の内閣総理大臣は、岸田文雄閣総理大臣です。
Chat Completionsのドキュメントはここ。
見た感じはOpenAIと殆ど変わらないけど、違う部分については以下に記載されている。
ではもう少しいろいろ。
ストリーミング
import os
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
stream = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "あなたは日本語で答える親切なアシスタントです。",
},
{
"role": "user",
"content": "日本の総理大臣は誰?回答は日本語で。",
}
],
model="llama3-8b-8192",
stream=True,
)
for chunk in stream:
print(chunk.choices[0].delta.content, end="\n")
😊
現在
の
日本
の
総
理
大
臣
は
、
岸
田
文
雄
(
K
ish
ida
F
um
io
)
です
。
None
非同期
import os
import asyncio
from groq import AsyncGroq
# notebook向け
import nest_asyncio
nest_asyncio.apply()
async def main():
client = AsyncGroq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": "あなたは日本語で答える親切なアシスタントです。",
},
{
"role": "user",
"content": "日本の総理大臣は誰?回答は日本語で。",
}
],
model="llama3-8b-8192",
stream=False,
)
print(chat_completion.choices[0].message.content)
asyncio.run(main())
現在の日本の内閣総理大臣は、岸田文雄(Kishida Fumio)さんです。
非同期・ストリーミング
import os
import asyncio
from groq import AsyncGroq
# notebook向け
import nest_asyncio
nest_asyncio.apply()
async def main():
client = AsyncGroq(
api_key=os.environ.get("GROQ_API_KEY"),
)
stream = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": "あなたは日本語で答える親切なアシスタントです。",
},
{
"role": "user",
"content": "日本の総理大臣は誰?回答は日本語で。",
}
],
model="llama3-8b-8192",
stream=True,
)
async for chunk in stream:
print(chunk.choices[0].delta.content, end="\n")
asyncio.run(main())
こんにちは
!
日本
の
総
理
大
臣
は
、
菅
義
偉
(
K
ish
ida
F
um
io
)
です
。
現在
、
第
100
代
総
理
大
臣
として
着
任
しています
。
None
JSON mode
import os
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
system_prompt = """
あなたは日本語で答える親切なアシスタントです。JSONで応答を返します。JSONスキーマは以下:
{
"answer": "string",
"metadatas": {
"confidence_score": "number (0-1)",
"category": "text"
}
}
}
"""
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": "日本の総理大臣は誰?回答は日本語で。",
}
],
model="llama3-8b-8192",
response_format={"type": "json_object"},
)
print(chat_completion.choices[0].message.content)
{
"answer": "岸田文雄",
"metadatas": {
"confidence_score": 1.0,
"category": " Politics"
}
}
Function Calling
Function Callingに対応しているのは以下のモデル。
- llama3-70b
- llama3-8b
- mixtral-8x7b
- gemma-7b-it
ただし、Groqの推奨は llama3-70b のみらしい。あと、Llama3であればParallel Function Callingに対応しているとのこと。
from groq import Groq
import os
import json
client = Groq(api_key = os.getenv('GROQ_API_KEY'))
MODEL = 'llama3-70b-8192'
# NBAの試合のスコアを返すようにハードコードされたダミー関数の例
def get_game_score(team_name):
"""NBAの試合の現在のスコアを取得する。"""
if "ウォリアーズ" in team_name or "レイカーズ" in team_name:
return json.dumps({
"game_id": "401585601",
"status": 'Final',
"home_team": "ロサンゼルス・レイカーズ",
"home_team_score": 121,
"away_team": "ゴールデンステイト・ウォリアーズ",
"away_team_score": 128
}, ensure_ascii=False)
elif "ナゲッツ" in team_name or "ヒート" in team_name:
return json.dumps({
"game_id": "401585577",
"status": 'Final',
"home_team": "マイアミ・ヒート",
"home_team_score": 88,
"away_team": "デンバー・ナゲッツ",
"away_team_score": 100
}, ensure_ascii=False)
else:
return json.dumps({
"team_name": team_name,
"score": "unknown"
})
def run_conversation(user_prompt):
# ステップ1: 会話と利用可能な関数をモデルに送る
messages=[
{
"role": "system",
"content": "あなたは、関数を呼び出すLLMです。get_game_score関数から抽出したデータを使って、NBAの試合スコアに関する質問に答えます。回答にはチームと対戦相手を含めてください。回答は常に日本語で答えるようにしてください。"
},
{
"role": "user",
"content": user_prompt,
}
]
tools = [
{
"type": "function",
"function": {
"name": "get_game_score",
"description": "与えられたNBAの試合スコアを取得する",
"parameters": {
"type": "object",
"properties": {
"team_name": {
"type": "string",
"description": "NBAチームの名前(例: 'ゴールデンステート・ウォリアーズ')",
}
},
"required": ["team_name"],
},
},
}
]
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools,
tool_choice="auto",
max_tokens=4096
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
# ステップ2: モデルが関数を呼び出したいかどうかをチェックする
if tool_calls:
# ステップ3: 関数を呼び出す
# 注意: JSONレスポンスは常に有効であるとは限らない; 必ずエラーを処理すること
available_functions = {
"get_game_score": get_game_score,
} # この例では関数は1つだけだが、複数の関数を使うこともできる。
messages.append(response_message) # extend conversation with assistant's reply
# ステップ4: 各関数の呼び出しとレスポンスの情報をモデルに送信する
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(
team_name=function_args.get("team_name")
)
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
) # 関数のレスポンスで会話を拡張する
second_response = client.chat.completions.create(
model=MODEL,
messages=messages
) # モデルから新しいレスポンスを受け取り、関数のレスポンスを確認する
return second_response.choices[0].message.content, messages
user_prompt = "ウォリアーズの試合結果を教えて?"
response, messages = run_conversation(user_prompt)
print(response)
print("---")
print(messages)
ウォリアーズの最新の試合結果は、ロサンゼルス・レイカーズとの対戦で、ウォリアーズが128-121で勝利したようです!
---
[
{
'role': 'system',
'content': 'あなたは、関数を呼び出すLLMです。get_game_score関数から抽出したデータを使って、NBAの試合スコアに関する質問に答えます。回答にはチームと対戦相手を含めてください。回答は常に日本語で答えるようにしてください。'
},
{
'role': 'user',
'content': 'ウォリアーズの試合結果を教えて?'
},
ChatCompletionMessage(content=None,
role='assistant',
function_call=None,
tool_calls=[
ChatCompletionMessageToolCall(id='call_ah4t',
function=Function(arguments='{"team_name":"ゴールデンステート・ウォリアーズ"}',
name='get_game_score'),
type='function')
]
),
{
'tool_call_id': 'call_ah4t',
'role': 'tool',
'name': 'get_game_score',
'content': '{"game_id": "401585601", "status": "Final", "home_team": "ロサンゼルス・レイカーズ", "home_team_score": 121, "away_team": "ゴールデンステイト・ウォリアーズ", "away_team_score": 128}'
}
]
Parallelの場合
from groq import Groq
import os
import json
client = Groq(api_key = os.getenv('GROQ_API_KEY'))
MODEL = 'llama3-70b-8192'
def get_temperature(city: str):
if city == "マドリード":
return 35
elif city == "東京":
return 18
elif city == "パリ":
return 20
else:
return 15
tools = [
{
"type": "function",
"function": {
"name": "get_temperature",
"description": "与えられた都市の気温を摂氏で返す",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "都市の名前。日本語で指定すること。",
}
},
"required": ["city"],
},
},
}
]
def run_conversation(user_prompt):
messages = [
{
"role": "system",
"content": "あなたは親切な日本語のアシスタントです。"
},
{
"role": "user",
"content": user_prompt,
},
]
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools,
tool_choice="auto",
max_tokens=4096
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
if tool_calls:
messages.append(
{
"role": "assistant",
"tool_calls": [
{
"id": tool_call.id,
"function": {
"name": tool_call.function.name,
"arguments": tool_call.function.arguments,
},
"type": tool_call.type,
}
for tool_call in tool_calls
],
}
)
available_functions = {
"get_temperature": get_temperature,
}
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(**function_args)
# 各ツールコールに個別のツールコールメッセージを作成することに注意。
# モデルは、tool_call_idによってツールコールの結果を識別できる。
messages.append(
{
"role": "tool",
"content": json.dumps(function_response, ensure_ascii=False),
"tool_call_id": tool_call.id,
}
)
response = client.chat.completions.create(
model=MODEL, messages=messages, tools=tools, tool_choice="auto", max_tokens=4096
)
return response.choices[0].message.content, messages
user_prompt = "パリと東京とマドリードの気温を教えて。"
response, messages = run_conversation(user_prompt)
print(response)
print("---")
print(messages)
パリの気温は20度、東京の気温は18度、マドリードの気温は35度です。
---
[
{
'role': 'system',
'content': 'あなたは親切な日本語のアシスタントです。'
},
{
'role': 'user',
'content': 'パリと東京とマドリードの気温を教えて。'
},
{
'role': 'assistant',
'tool_calls': [
{
'id': 'call_2gtj',
'function': {
'name': 'get_temperature',
'arguments': '{"city":"パリ"}'
},
'type': 'function'
},
{
'id': 'call_a4wd',
'function': {
'name': 'get_temperature',
'arguments': '{"city":"東京"}'
},
'type': 'function'
},
{
'id': 'call_d5r8',
'function': {
'name': 'get_temperature',
'arguments': '{"city":"マドリード"}'
},
'type': 'function'
}
]
},
{
'role': 'tool',
'content': '20',
'tool_call_id': 'call_2gtj'
},
{
'role': 'tool',
'content': '18',
'tool_call_id': 'call_a4wd'
},
{
'role': 'tool',
'content': '35',
'tool_call_id': 'call_d5r8'
}
]
Speech-To-Text
以下のデータセットを使用した。
!pip install datasets
from datasets import load_dataset
ds = load_dataset("reazon-research/reazonspeech", "tiny", trust_remote_code=True)
一番発話時間が長そうなデータを探してみた。
for idx, data in enumerate(ds["train"]["transcription"]):
if len(data) > 200:
print(idx, len(data))
870 203
3626 206
該当のファイルのパスと文字起こしを拾ってみる。データセットから特定のデータを拾うのが結構重いので、ここで変数にいれている。
text = ds["train"]["transcription"][3626]
file_path = ds["train"]["audio"][3626]["path"]
print(text[:10] + "...")
print(file_path)

ではこれをSTTしてみる。
%%time
import os
from groq import Groq
client = Groq(
api_key = os.getenv('GROQ_API_KEY')
)
with open(file_path, "rb") as file:
transcription = client.audio.transcriptions.create(
file=(file_path, file.read()),
model="whisper-large-v3",
prompt="Specify context or spelling", # オプション
response_format="json", # オプション
language="ja", # オプション
temperature=0.0 # オプション
)
print(transcription.text)
彼女の青春はどう(snip)
CPU times: user 86.1 ms, sys: 1.76 ms, total: 87.9 ms
Wall time: 848 ms
冒頭の「あの」はなくなっていたり、句読点はなくなってしまったけど、ほぼ完璧な精度だった。
同じことをOpenAIのWhisperでやってみた。
%%time
from openai import OpenAI
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
client = OpenAI()
with open(file_path, "rb") as file:
transcription = client.audio.transcriptions.create(
file=(file_path, file.read()),
model="whisper-1",
prompt="Specify context or spelling",
response_format="json",
language="ja",
temperature=0.0
)
print(transcription.text)
彼女の青春はどう(snip)
CPU times: user 112 ms, sys: 8.27 ms, total: 121 ms
Wall time: 3.88 s
何回かやってみたけど確かにGroqのほうが速い。
ということで、Chat Completionsの方も計測してみる。ただGroqで使えるモデルの比較対象がないので、あくまで参考までにということで。コードは以下を流用。
import os
import time
from functools import wraps
import statistics
from tqdm.auto import tqdm
from groq import Groq
def timing_decorator(repeats=1):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
times = []
results = []
for _ in tqdm(range(repeats), desc="Processing"):
start_time = time.time()
result = func(*args, **kwargs)
results.append(result)
end_time = time.time()
times.append(end_time - start_time)
avg_time = round(sum(times) / len(times),2)
max_time = round(max(times),2)
min_time = round(min(times),2)
median_time = round(statistics.median(times),2)
timing_info = {
'avg': avg_time,
'max': max_time,
'min': min_time,
'med': median_time,
'times': [round(t, 2) for t in times]
}
return results[0] if repeats == 1 else results, timing_info
return wrapper
return decorator
@timing_decorator(repeats=10)
def groq_completion(client, model, messages):
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=0
)
return completion.choices[0].message.content
models = ["llama3-8b-8192", "llama3-70b-8192", "mixtral-8x7b-32768", "gemma-7b-it"]
max_model_length = max(len(model) for model in models)
format_string = "{:<20} : {:>10} {:>10} {:>10} {:>10}"
client = Groq(
api_key = os.getenv('GROQ_API_KEY')
)
messages = [
{"role": "system", "content": "あなたは詩的なアシスタントで、複雑なプログラミングのコンセプトをクリエイティブなセンスで説明することに長けている。"},
{"role": "user", "content": "プログラミングにおける再帰の概念を説明する詩を作ってください。日本語で。"}
]
for model in models:
res = groq_completion(client, model, messages)[1]
print(format_string.format("Model", "AVG", "MIN", "MAX", "MED"))
print(format_string.format(model, res["avg"], res["min"], res["max"], res["med"]))
print()
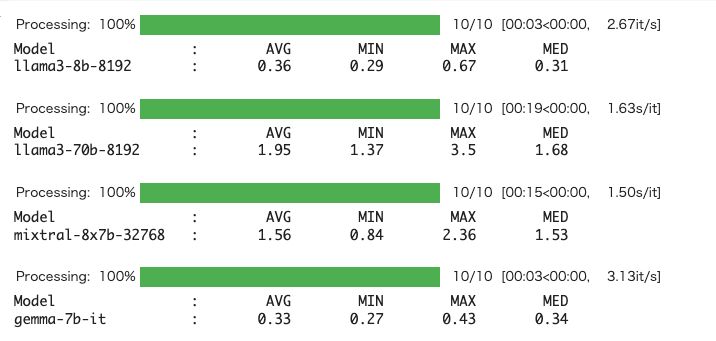
ちなみに、最近改めてOpenAIのレスポンス速度も取り直してみたので参考までに。

まとめ
- OpenAIライクに使える
- ChatCompletionsは比較対象がないので比較ができないけど、レスポンス速度見る限りは速いし、Whisperは確かに本家より速い。
個人的にはLlama3こんなに日本語行けるとは思ってなかった。ただそれほど多く確認したわけではないし、7Bだとちょっと足りない(中国語の漢字とかになったりすることはまあある)ように思ったので、使うなら70Bかな。
OpenAIのライブラリに慣れていればなんの違和感も感じないし、LangChainやLlamaIndexでもインテグレーションあるので、サラッと使えそう。